

A Penetration Method for UAV Based on Distributed Reinforcement Learning and Demonstrations


Abstract
:1. Introduction
- (a)
- Introduction. This section mainly describes the research status of UAV penetration strategies, summarizes the existing problems, and then leads to the theme and purpose of this paper.
- (b)
- Problem Description. This section first introduces the application scenario of UAV penetration in detail, and then describes the modeling of the UAV guidance system. On this basis, it describes and models the UAV penetration problem from the perspective of Reinforcement Learning.
- (c)
- CPL Algorithm for UAV penetration. This section derives the theoretical formula of the proposed algorithm. The related algorithms mainly include a pre-training algorithm—Adversarial Inverse Reinforcement Learning (AIRL), distributed reinforcement learning algorithm—Asynchronous Advantage Actor-Critic (A3C), and the Combination Policy Learning (CPL) algorithm, formed by combining the former two.
- (d)
- Environmental results and discussion. This section mainly analyzes and discusses the experimental results. For the CPL algorithm and other related algorithms, this section conducts training and testing experiments and compares the results, so as to conduct a detailed analysis of the sample requirements, convergence efficiency, success rate of penetration, and other indicators of each algorithm.
- (e)
- Conclusions and future work. This section mainly summarizes the full text and prospects for future work in this paper.
2. Problem Description
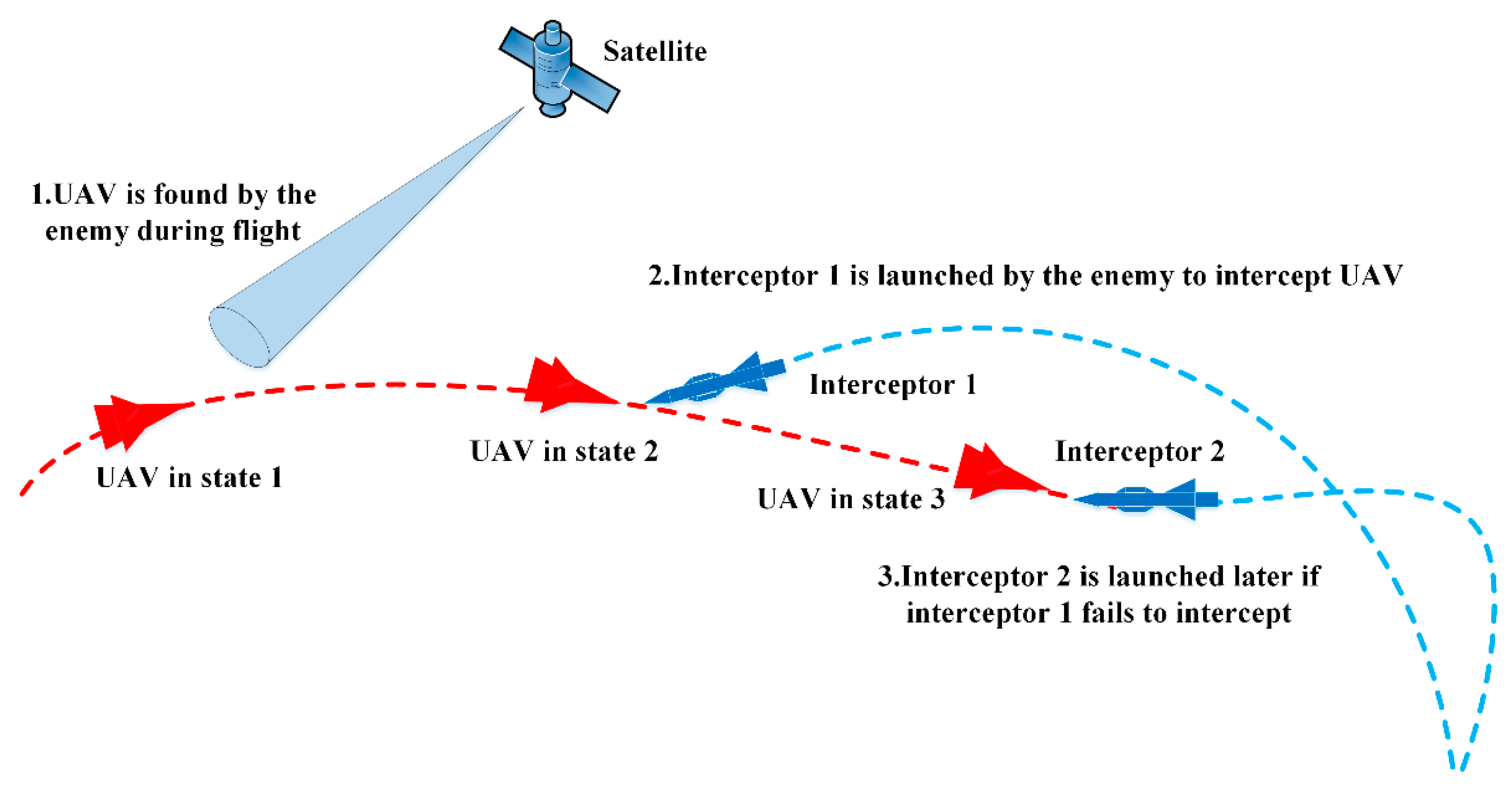
2.1. UAV Penetration
2.2. Modeling of the UAV Guidance System
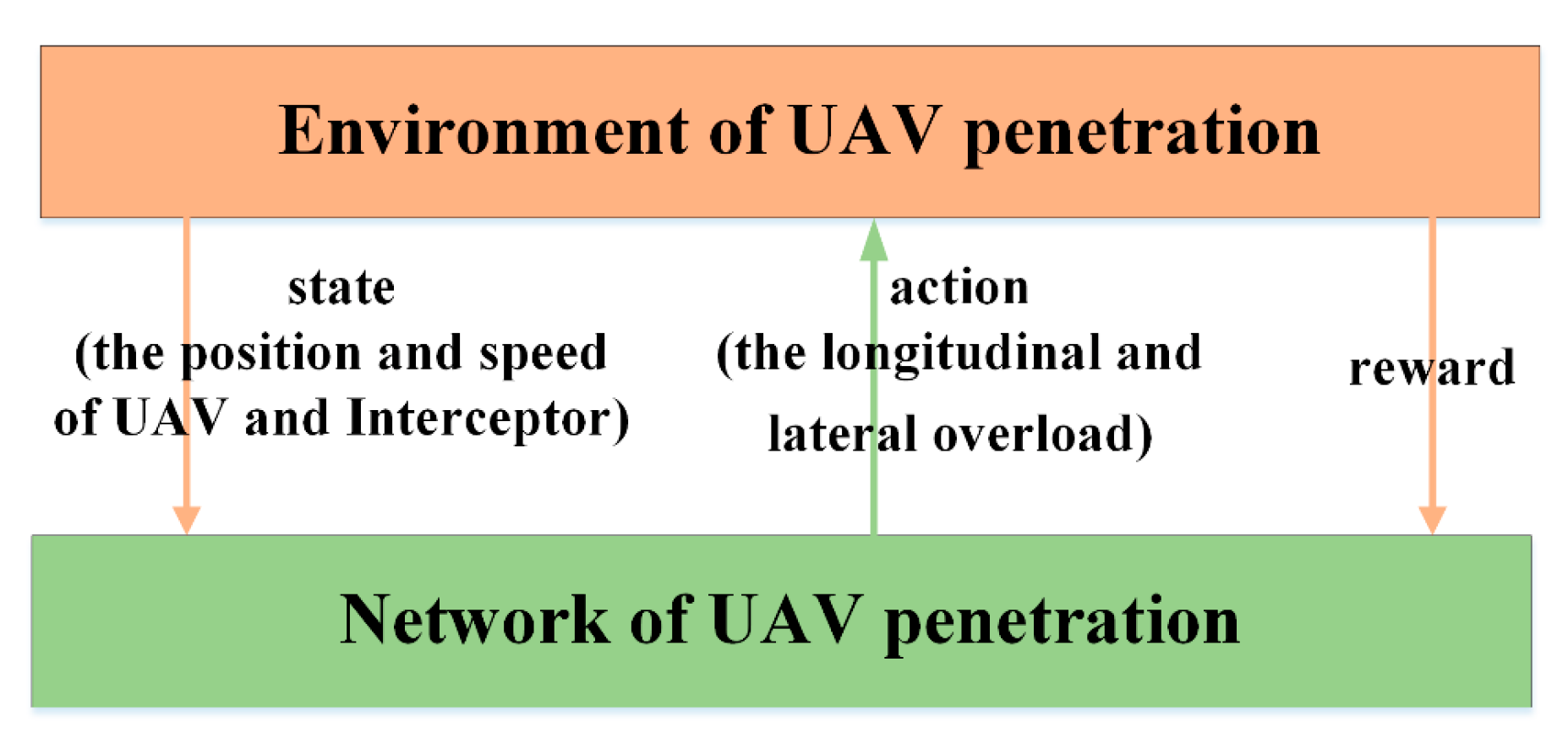
2.3. Reinforcement Learning for UAV Penetration
3. CPL Algorithm for UAV Penetration
3.1. Pre-Training Algorithm
| Algorithm 1. Pre-training algorithm (AIRL) Algorithm. |
| Obtain expert demonstrations |
| Initialize policy and discriminator |
| for step t in do |
| Collect trajectories by executing . |
| Train via binary logistic regression to classify expert data from sample |
| Update reward |
| Update with respect to using any policy optimization method. |
| end for |
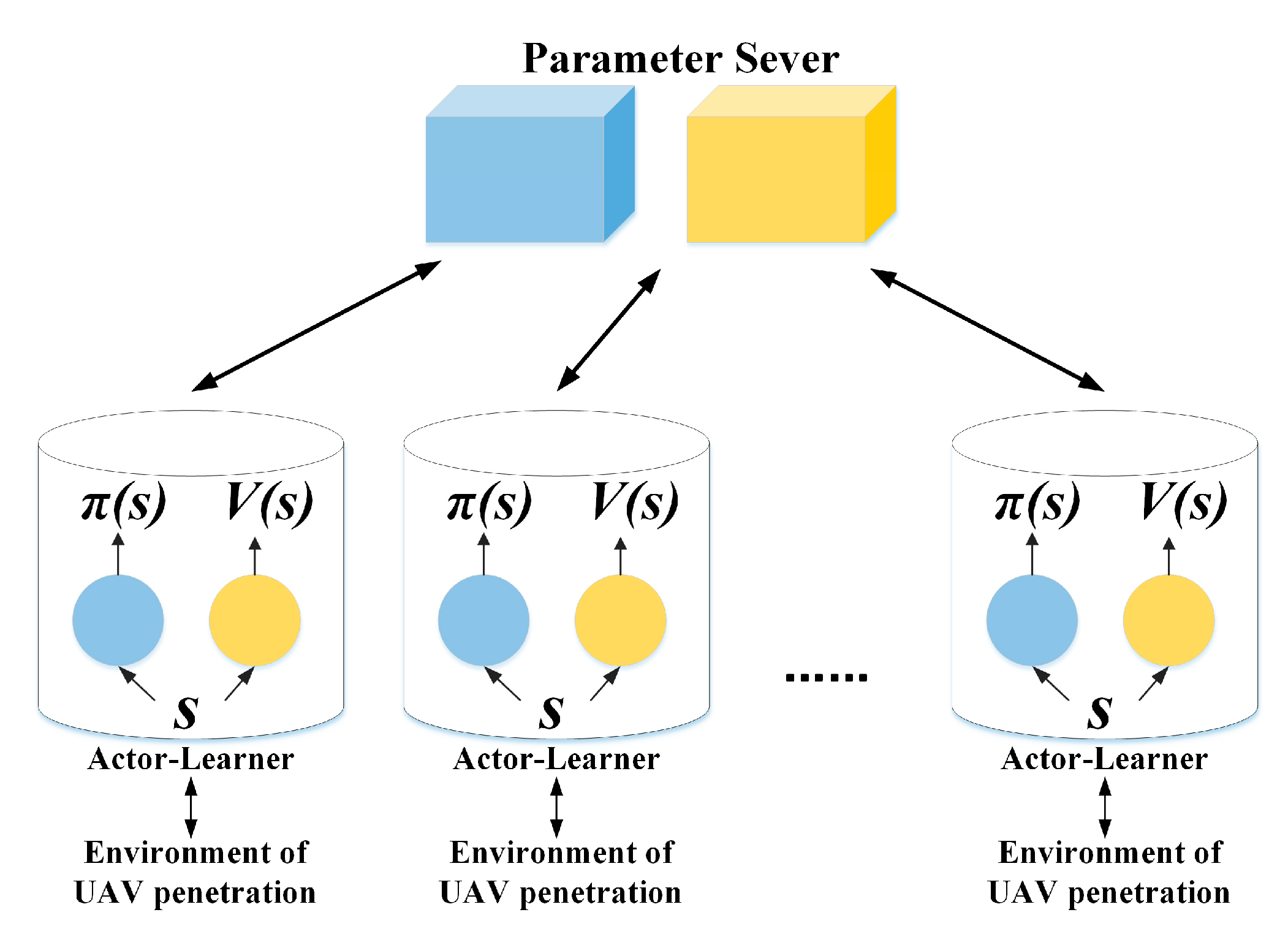
3.2. A3C Algorithm
| Algorithm 2. Asynchronous Advantage Actor-Critic (A3C). |
| Initialize total number of exploration steps , number of exploration steps in each cycle |
| Initialize thread step counter |
| while do |
| Initialize network parameter gradient: , |
| Keep synchronization with the parameter server: , |
| Set the initial state of each exploration cycle to |
| while the end state is reached or do |
| Select decision behavior based on decision strategy |
| Executing in the environment and get reward and the next state |
| end while |
| if the end state is reached, then |
| else |
| end if |
| for do |
| Update discount rewards |
| Cumulative parameter gradient , |
| Cumulative parameter gradient , |
| end for |
| Asynchronous update and based on gradient and |
| end while |
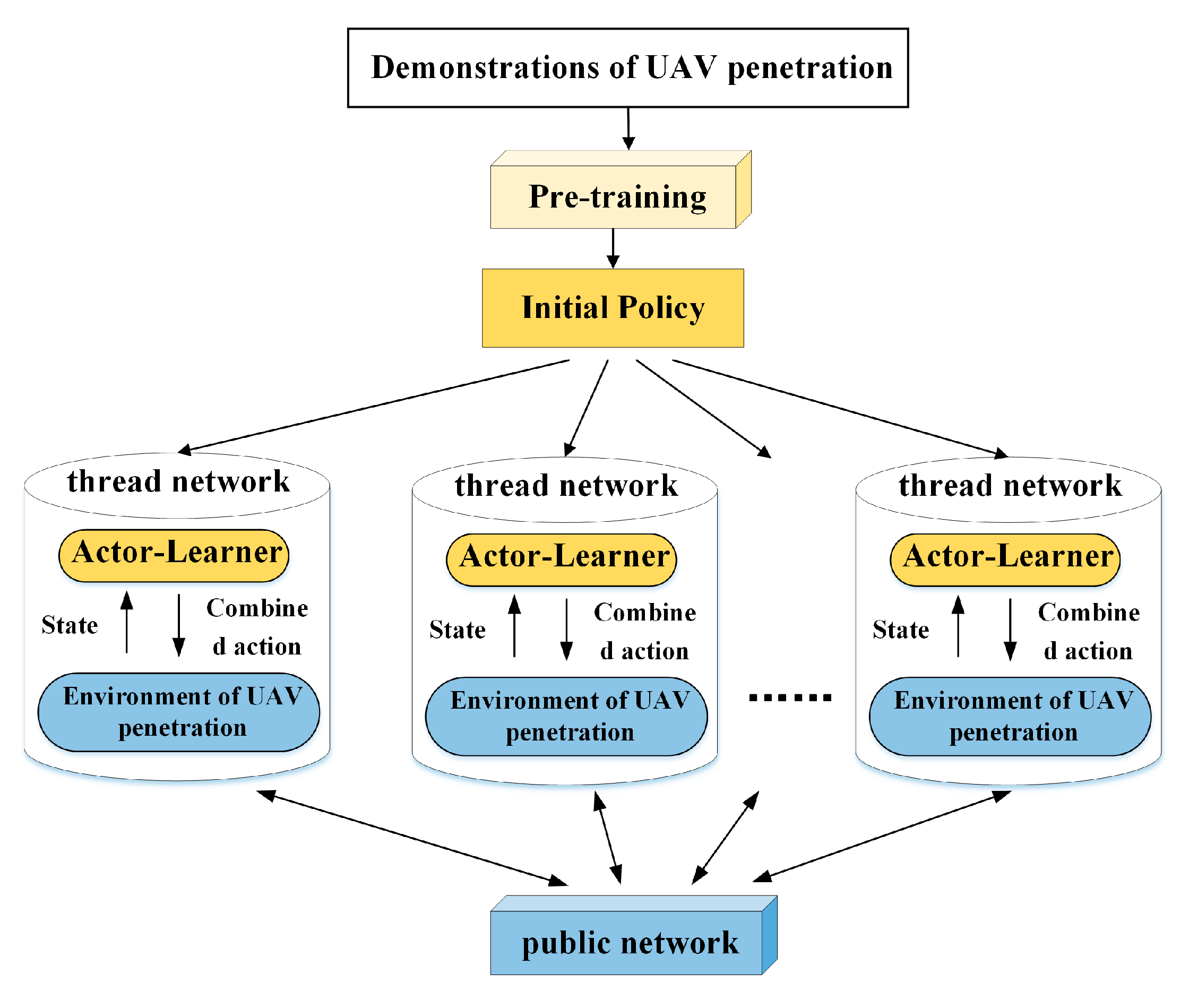
3.3. CPL Algorithm
- (a)
- Initialize all networks in the A3C algorithm in the way of combination policy learning;
- (b)
- Let the actor-learner interact with the environment. The action is the combination of the initial policy and target policy, i.e., formula (11), and the samples are stored in the form of ;
- (c)
- Sample from the replay buffer and get , then update the Target Policy ;
- (d)
- Repeat steps (b) and (c) above until the UAV penetration strategy converges to near optimal.
| Algorithm 3. Combination Policy Learning (CPL) Algorithm. |
| Obtain expert demonstrations |
| Initialize policy and discriminator |
| for step t in do |
| Collect trajectories by executing |
| Train via binary logistic regression to classify expert demonstrations from sample |
| Update reward |
| Update with respect to using any policy optimization method end for |
| Obtain the initial policy from the above training, and obtain its corresponding neural network parameters |
| Initialize total number of exploration steps , number of exploration steps in each cycle |
| while do |
| Initialize network parameter gradient: , |
| Keep synchronization with the parameter server: , |
| Set the initial state of each exploration cycle to |
| while the end state is reached or do |
| Take decision behavior in the environment and get reward and the |
| next state |
| end while |
| if the end state is reached, then |
| else |
| end if |
| for do |
| Update discount rewards , where is the discount factor |
| Cumulative parameter gradient , |
| Cumulative parameter gradient , |
| end for |
| Asynchronous update and based on gradient and |
| end while |
4. Environmental Results and Discussion
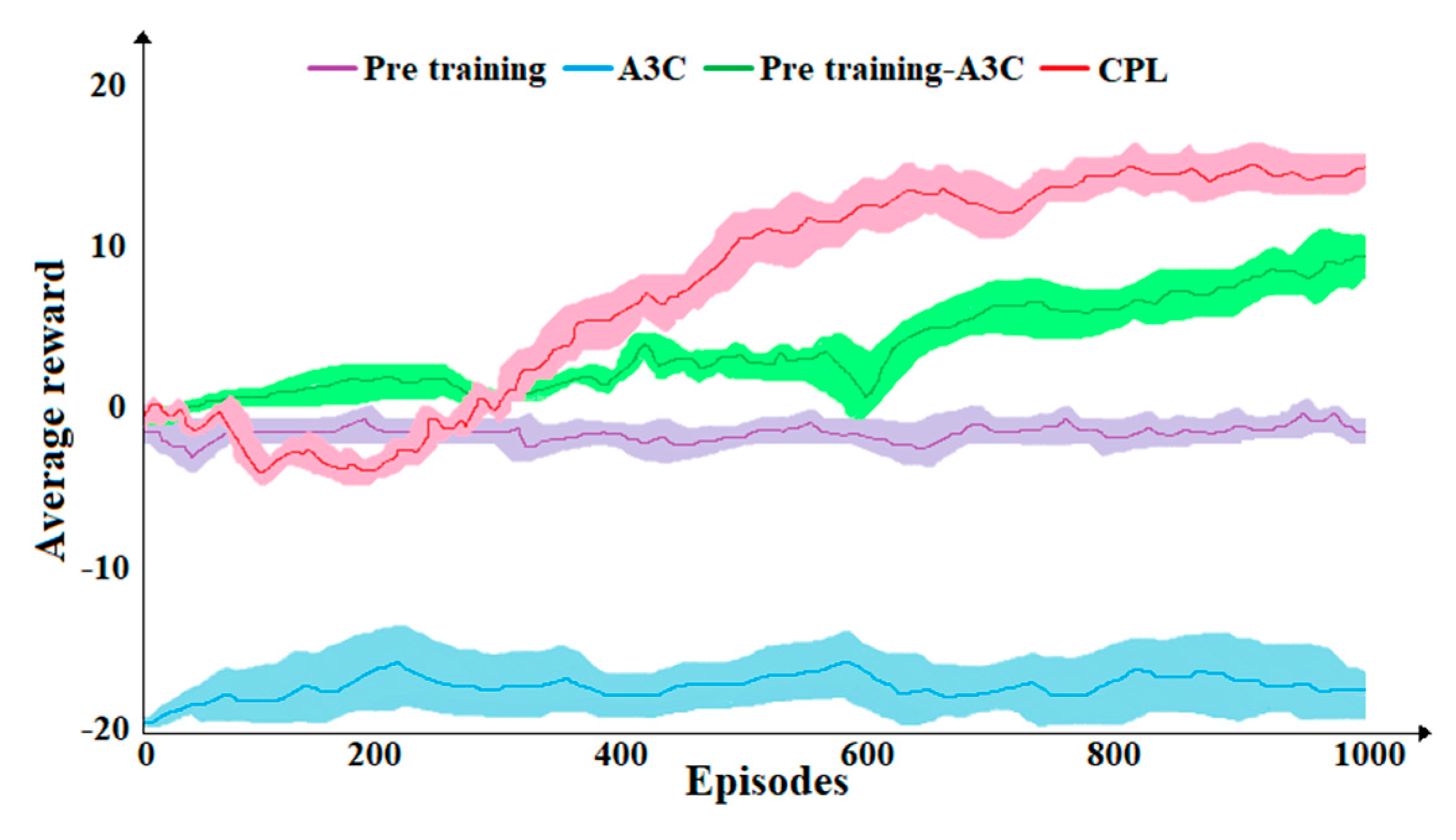
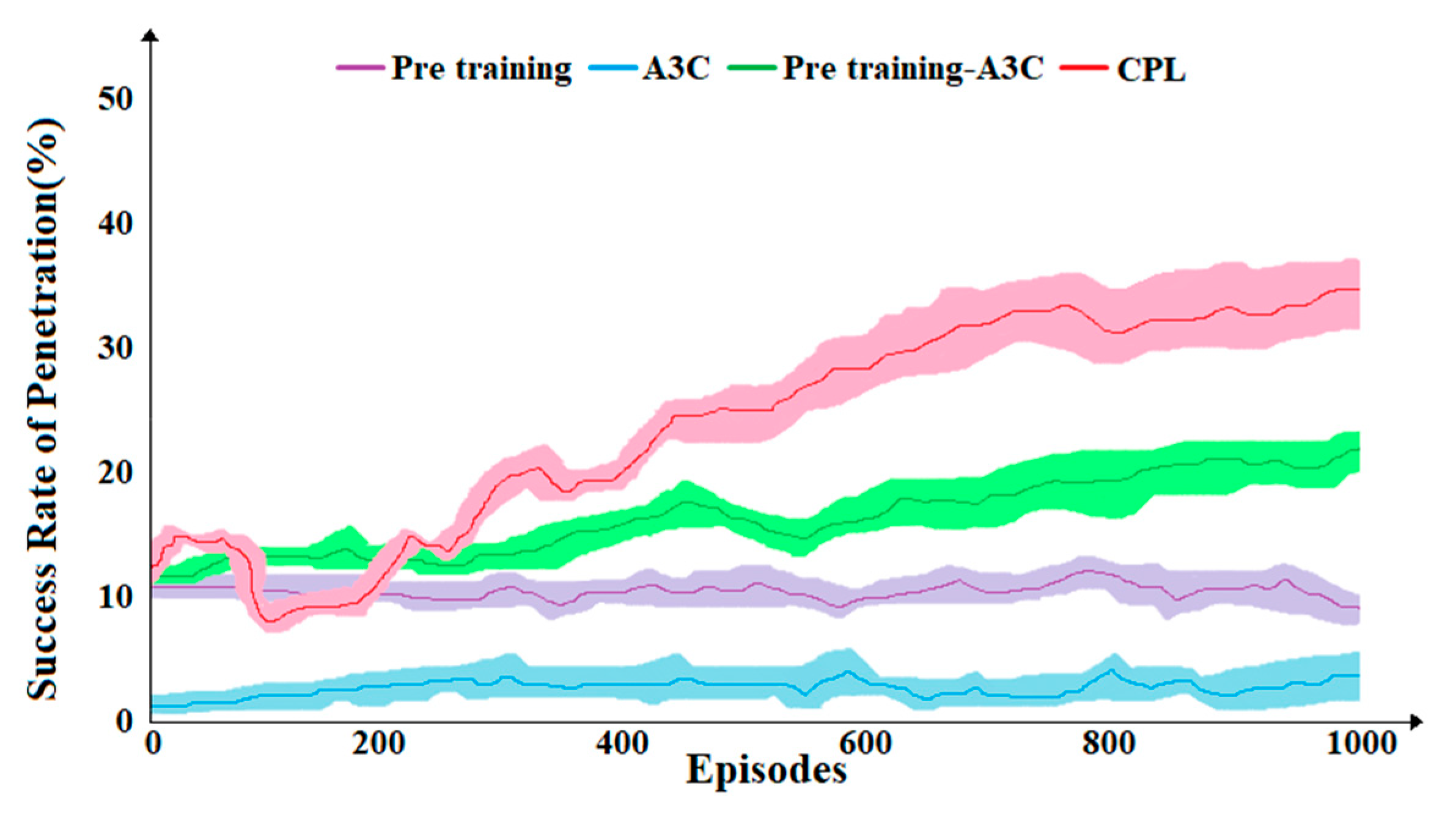
4.1. Training Experiment
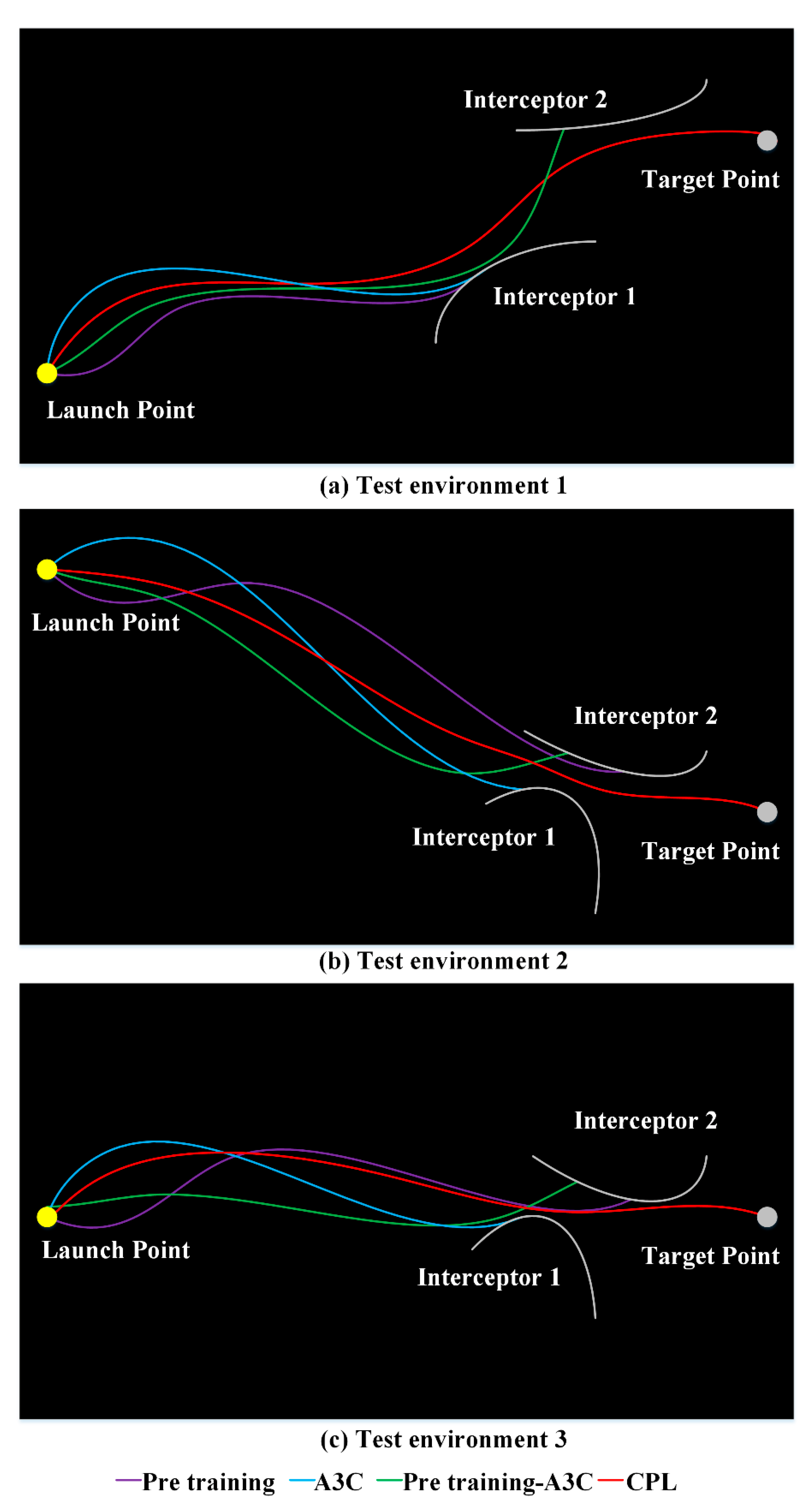
4.2. Test Experiment
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiang, L.; Nan, Y.; Zhang, Y.; Li, Z.H. Anti-Interception Guidance for Hypersonic Glide Vehicle: A Deep Reinforcement Learning Approach. Aerospace 2022, 9, 21. [Google Scholar] [CrossRef]
- Han, S.C.; Bang, H.; Yoo, C.S. Proportional Navigation-Based Collision Avoidance for UAVs. Int. J. Control Autom. Syst. 2009, 7, 553–565. [Google Scholar] [CrossRef]
- Singh, L. Autonomous missile avoidance using nonlinear model predictive control. In Proceedings of the AIAA Guidance Navigation, and Control Conference and Exhibit, Providence, RI, USA, 16–19 August 2004; p. 4910.3. [Google Scholar] [CrossRef]
- Gagnon, E.; Rabbath, C.; Lauzon, M. Receding horizons with heading constraints for collision avoidance. In Proceedings of the AIAA Guidance Navigation, and Control Conference and Exhibit, San Francisco, CA, USA, 15–18 August 2005; p. 6369. [Google Scholar] [CrossRef]
- Watanabe, Y.; Calise, A.; Johnson, E.; Evers, J. Minimum-effort guidance for vision-based collision avoidance. In Proceedings of the AIAA Atmospheric Flight Mechanics Conference and Exhibit, Keystone, CO, USA, 21–24 August 2006; p. 6641. [Google Scholar] [CrossRef]
- Smith, N.E.; Cobb, R.; Pierce, S.J.; Raska, V. Optimal collision avoidance trajectories via direct orthogonal collocation for unmanned/remotely piloted aircraft sense and avoid operations. In Proceedings of the AIAA Guidance Navigation, and Control Conference, National, Harbor, MD, USA, 13–17 January 2014; p. 0966. [Google Scholar] [CrossRef]
- Acton, J.M. Hypersonic boost-glide weapons. Sci. Glob. Secur. 2015, 23, 191–219. [Google Scholar] [CrossRef]
- Li, G.H.; Zhang, H.B.; Tang, G.J. Maneuver characteristics analysis for hypersonic glide vehicles. Aerosp. Sci. Technol. 2015, 43, 321–328. [Google Scholar] [CrossRef]
- Li, S.J.; Lei, H.M.; Shao, L.; Xiao, C.H. Multiple Model Tracking for Hypersonic Gliding Vehicles with Aerodynamic is Modeling and Analysis. IEEE Access 2019, 7, 28011–28018. [Google Scholar] [CrossRef]
- Liu, X.D.; Zhang, Y.; Wang, S.; Huang, W.W. Backstepping attitude control for hypersonic gliding vehicle based on a robust dynamic inversion approach. Proc. Inst. Mech. Eng. Part I-J Syst. Control Eng. 2014, 228, 543–552. [Google Scholar] [CrossRef]
- Karabag, O.; Bulut, O.; Toy, A.O. Markovian Decision Process Modeling Approach for Intervention Planning of Partially Observable Systems Prone to Failures. In Proceedings of the 4th International Conference on Intelligent and Fuzzy Systems (INFUS), Izmir, Turkey, 19–21 July 2022; Springer International Publishing Ag: Izmir, Turkey, 2022; pp. 497–504. [Google Scholar] [CrossRef]
- Sackmann, M.; Bey, H.; Hofmann, U.; Thielecke, J. Modeling driver behavior using adversarial inverse reinforcement learning. In Proceedings of the 33rd IEEE Intelligent Vehicles Symposium (IEEE IV), Aachen, Germany, 5–9 June 2022; IEEE: Aachen, Germany, 2022; pp. 1683–1690. [Google Scholar] [CrossRef]
- Li, W.X.; Hsueh, C.H.; Ikeda, K. Imitating Agents in A Complex Environment by Generative Adversarial Imitation Learning. In Proceedings of the IEEE Conference on Games, Osaka, Japan, 24–27 August 2020; pp. 702–705. [Google Scholar]
- Chen, H.; Wang, Y.H.; Lagadec, B.; Dantcheva, A.; Bremond, F. Joint Generative and Contrastive Learning for Unsupervised Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 2004–2013. [Google Scholar] [CrossRef]
- Tiong, T.; Saad, I.; Teo, K.T.K.; Bin Lago, H. Autonomous Valet Parking with Asynchronous Advantage Actor-Critic Proximal Policy Optimization. In Proceedings of the IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 334–340. [Google Scholar]
- Maeda, R.; Mimura, M. Automating post-exploitation with deep reinforcement learning. Comput. Secur. 2021, 100, 13. [Google Scholar] [CrossRef]
- Clark-Turner, M.; Begum, M. Deep Reinforcement Learning of Abstract Reasoning from Demonstrations. In Proceedings of the 13th Annual ACM/IEEE International Conference on Human-Robot Interaction (HRI), Chicago, IL, USA, 5–8 March 2018; Assoc Computing Machinery: Chicago, IL, USA, 2018; p. 372. [Google Scholar] [CrossRef]
- Nair, A.; McGrew, B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Overcoming Exploration in Reinforcement Learning with Demonstrations. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE Computer Society: Brisbane, Australia, 2018; pp. 6292–6299. [Google Scholar]
- Liang, X.D.; Wang, T.R.; Yang, L.N.; Xing, E.R. In CIRL: Controllable Imitative Reinforcement Learning for Vision-Based Self-driving. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer International Publishing: Munich, Germany, 2018; pp. 604–620. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.D.; Gao, C.S.; Li, J.L.; Jing, W.X.; Li, Z. Novel trajectory prediction algorithms for hypersonic gliding vehicles based on maneuver mode on-line identification and intent inference. Meas. Sci. Technol. 2021, 32, 20. [Google Scholar] [CrossRef]
- Wang, Z.; Cheng, X.X.; Li, H. Hypersonic skipping trajectory planning for high L/D gliding vehicles. In Proceedings of the 21st AIAA International Space Planes and Hypersonics Technologies Conference, Xiamen, China, 6–9 March 2017; p. 2135. [Google Scholar]
- Wan, J.Q.; Zhang, Q.; Zhang, H.; Liu, J.N. A Midcourse Guidance Method Combined with Trajectory Prediction for Antinear-Space-Gliding Vehicles. Int. J. Aerosp. Eng. 2022, 2022, 4528803. [Google Scholar] [CrossRef]
- Bhatta, P. Nonlinear Stability and Control of Gliding Vehicles. PhD Thesis, Princeton University, Princeton, NJ, USA, 2006. [Google Scholar]
- Hu, Y.D.; Gao, C.S.; Jing, W.X. Joint State and Parameter Estimation for Hypersonic Glide Vehicles Based on Moving Horizon Estimation via Carleman Linearization. Aerospace 2022, 9, 20. [Google Scholar] [CrossRef]
- Li, M.J.; Zhou, C.J.; Shao, L.; Lei, H.M.; Luo, C.X. A Trajectory Generation Algorithm for a Re-Entry Gliding Vehicle Based on Convex Optimization in the Flight Range Domain and Distributed Grid Points Adjustment. Appl. Sci. 2023, 13, 21. [Google Scholar] [CrossRef]
- Yu, W.B.; Chen, W.C.; Jiang, Z.G.; Liu, M.; Yang, D.; Yang, M.; Ge, Y.J. Analytical entry guidance for no-fly-zone avoidance. Aerosp. Sci. Technol. 2018, 72, 426–442. [Google Scholar] [CrossRef]
- Zhang, J.B.; Xiong, J.J.; Lan, X.H.; Shen, Y.N.; Chen, X.; Xi, Q.S. Trajectory Prediction of Hypersonic Glide Vehicle Based on Empirical Wavelet Transform and Attention Convolutional Long Short-Term Memory Network. IEEE Sens. J. 2022, 22, 4601–4615. [Google Scholar] [CrossRef]
- King, L. Model Predictive Control and Reinforcement Learning Control for Hypersonic Gliding Vehicles and Spacecraft Docking. Available online: https://www.osti.gov/biblio/1863484 (accessed on 24 March 2022).
- Tripathi, A.K.; Patel, V.V.; Padhi, R. Autonomous Landing of Fixed Wing Unmanned Aerial Vehicle with Reactive Collision Avoidance. In Proceedings of the 5th IFAC Conference on Advances in Control and Optimization of Dynamical Systems (ACODS), Hyderabad, India, 18–22 February 2018; Elsevier: Hyderabad, India, 2018; pp. 474–479. [Google Scholar] [CrossRef]
- Xu, J.J.; Dong, C.H.; Cheng, L. Deep Neural Network-Based Footprint Prediction and Attack Intention Inference of Hypersonic Glide Vehicles. Mathematics 2023, 11, 24. [Google Scholar] [CrossRef]
- Zhang, J.B.; Xiong, J.J.; Li, L.Z.; Xi, Q.S.; Chen, X.; Li, F. Motion State Recognition and Trajectory Prediction of Hypersonic Glide Vehicle Based on Deep Learning. IEEE Access 2022, 10, 21095–21108. [Google Scholar] [CrossRef]
- Zhao, K.; Cao, D.Q.; Huang, W.H. Maneuver control of the hypersonic gliding vehicle with a scissored pair of control moment gyros. Sci. China-Technol. Sci. 2018, 61, 1150–1160. [Google Scholar] [CrossRef]
- Chai, R.; Tsourdos, A.; Savvaris, A.; Chai, S.; Xia, Y. Trajectory Planning for Hypersonic Reentry Vehicle Satisfying Deterministic and Probabilistic Constraints. Acta Astronaut. 2020, 177, 30–38. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
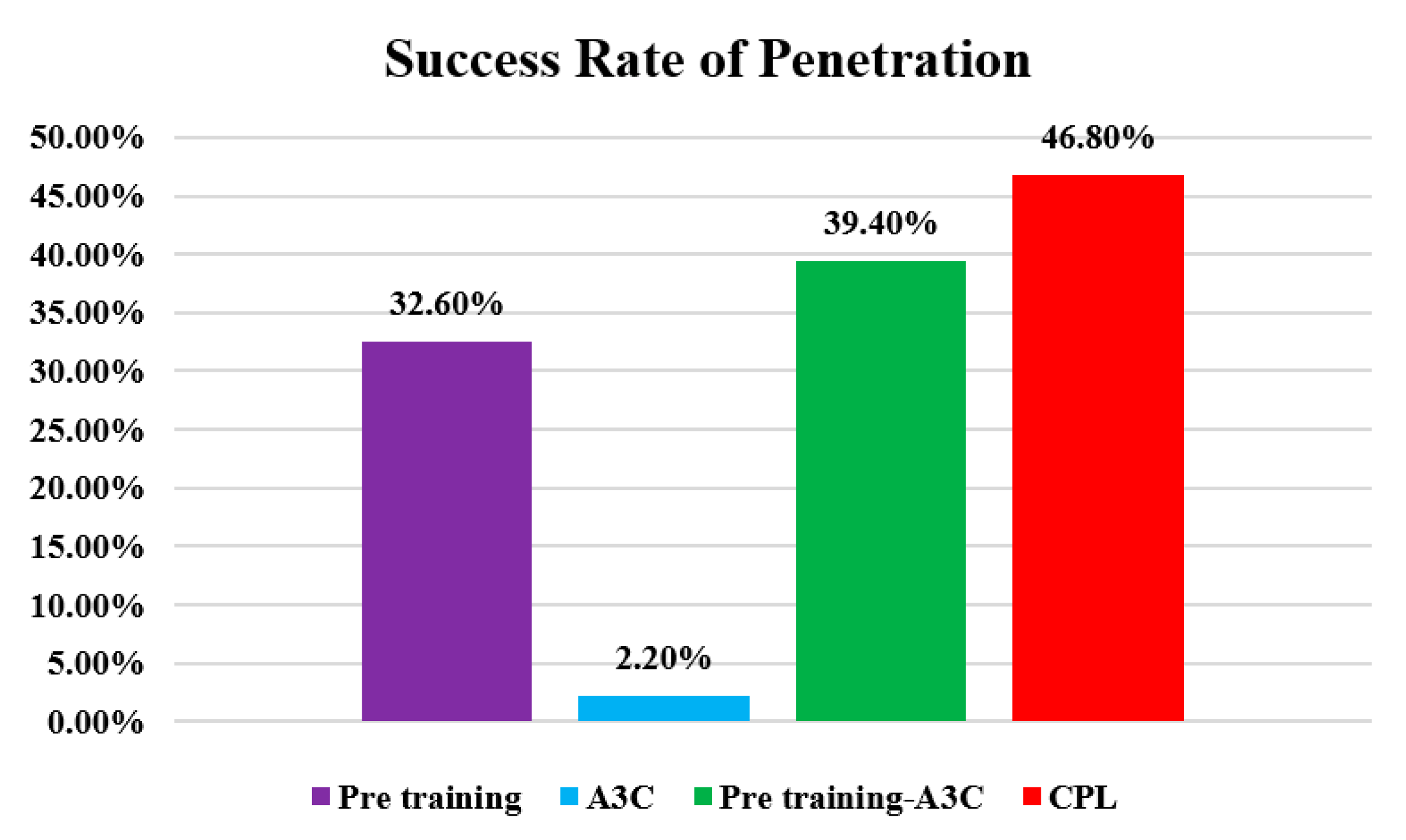
| Algorithm | NT | NP1 | NP2 | SRP |
|---|---|---|---|---|
| Pre-training | 500 | 178 | 163 | 32.6% |
| A3C | 500 | 19 | 11 | 2.2% |
| Pre-training-A3C | 500 | 234 | 197 | 39.4% |
| CPL | 500 | 273 | 234 | 46.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Wang, Y.; Zhuang, X.; Yin, H.; Liu, X.; Li, H. A Penetration Method for UAV Based on Distributed Reinforcement Learning and Demonstrations. Drones 2023, 7, 232. https://doi.org/10.3390/drones7040232
Li K, Wang Y, Zhuang X, Yin H, Liu X, Li H. A Penetration Method for UAV Based on Distributed Reinforcement Learning and Demonstrations. Drones. 2023; 7(4):232. https://doi.org/10.3390/drones7040232
Chicago/Turabian StyleLi, Kexv, Yue Wang, Xing Zhuang, Hao Yin, Xinyu Liu, and Hanyu Li. 2023. "A Penetration Method for UAV Based on Distributed Reinforcement Learning and Demonstrations" Drones 7, no. 4: 232. https://doi.org/10.3390/drones7040232
APA StyleLi, K., Wang, Y., Zhuang, X., Yin, H., Liu, X., & Li, H. (2023). A Penetration Method for UAV Based on Distributed Reinforcement Learning and Demonstrations. Drones, 7(4), 232. https://doi.org/10.3390/drones7040232