



A Sampling-Based Distributed Exploration Method for UAV Cluster in Unknown Environments


Abstract
:1. Introduction
- A Distributed Next-Best-Path and Terminal framework for real-time path planning for UAV cluster unknown environment exploration.
- A multistep selective sampling method for the initial generation of the exploration path with the calculation method of progress and terminal gain.
- An improved Discrete Binary Particle Swarm Optimization algorithm to generate the best exploration path.
2. Framework and Model Establishment
2.1. System Framework
2.2. Exploration Model in Unknown Environments
2.3. Construction of the Evaluation Function
3. Method and Algorithm
3.1. Multistep Selective Sampling Algorithm
| Algorithm 1 Multistep selective sampling |
| Input: Grid Map, initial state , sample space , other states Parameters: planning horizon , number of samples , , safe distance Output: aggregate of terminal state sequence with path |
| update sampling random m in , generate , while is not empty select the best sequences with length < update uniform sampling in based on the selected sequences , update the evalution value of //according to the Equation (11) if then else if the th best in better than the best in then break select the best n in as output |
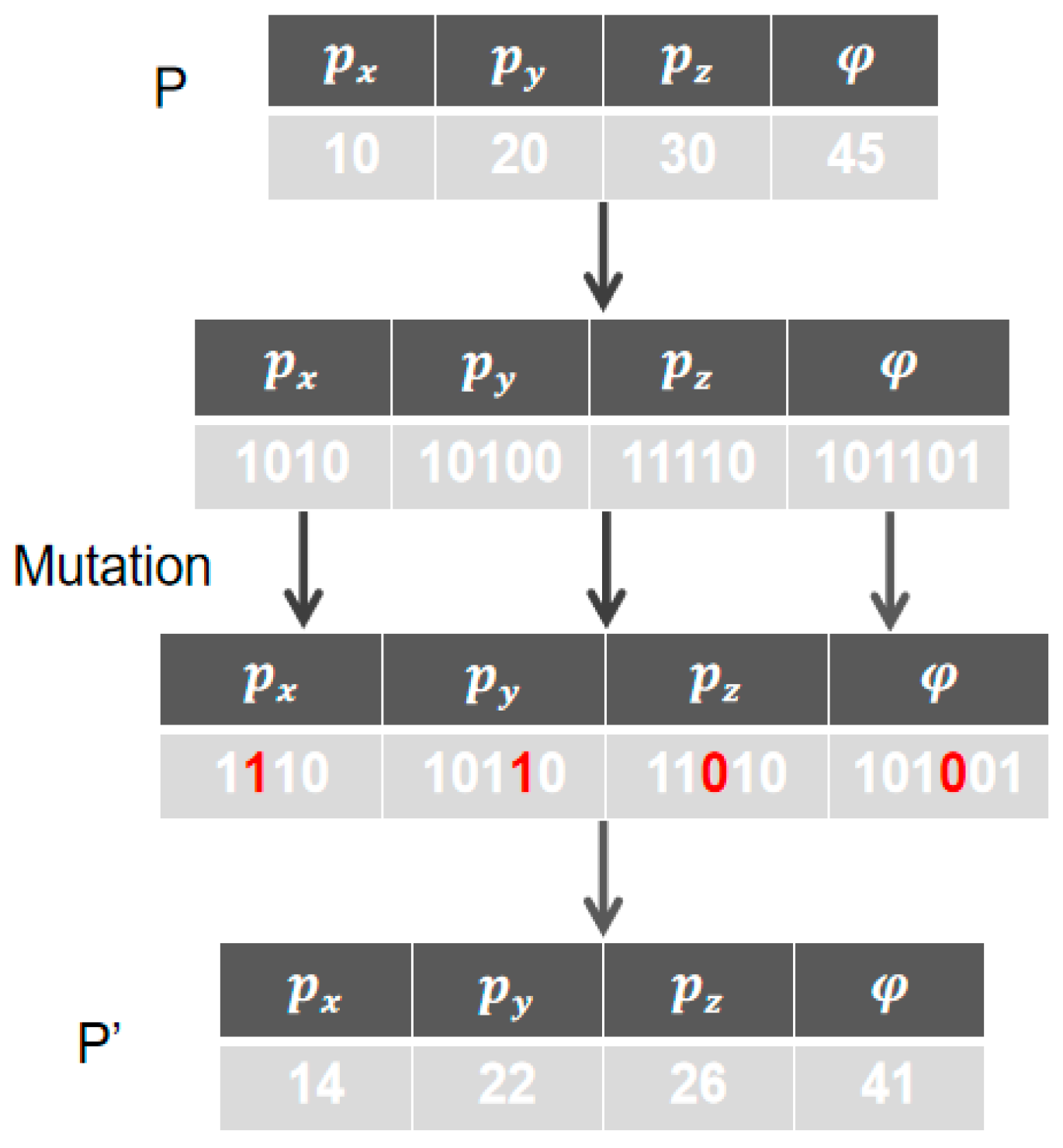
3.2. Improved Discrete Binary Particle Swarm Optimization Algorithm
| Algorithm 2 Mutation strategy |
| Input: Pop(swarm), , (size of the population), (threshold of age) Output: NewPop(new swarm) |
| for = 1 : do if > Ta then Mutation() Fitness ← CalculateFitness() //according to the Equation (12) if fitness() > fitness() then 0 else + 1 end if end for return NewPop |
| Algorithm 3 Improved DBPSO |
| Input: original Pop, size of the population , maximal generation number maxgen Output: (optimal sequence of terminal state with path) |
| P ← InitializeParticles() Age ← InitializeAge() Fitness ← CalculateFitness() While NCT (Number of current iterations) <= maxgen do for = 1 : do ←SelectGbest(Pop) Pop ← Updateparticles(N) //according to the Equations (13)–(15) Mutation() Fitness ← CalculateFitness(N) //according to the Equation (12) Pop ← NewPop ← SelectGbest(Pop) end for end while return |
4. Simulation and Analysis
4.1. Simulation in Fixed-Obstacle Scenes
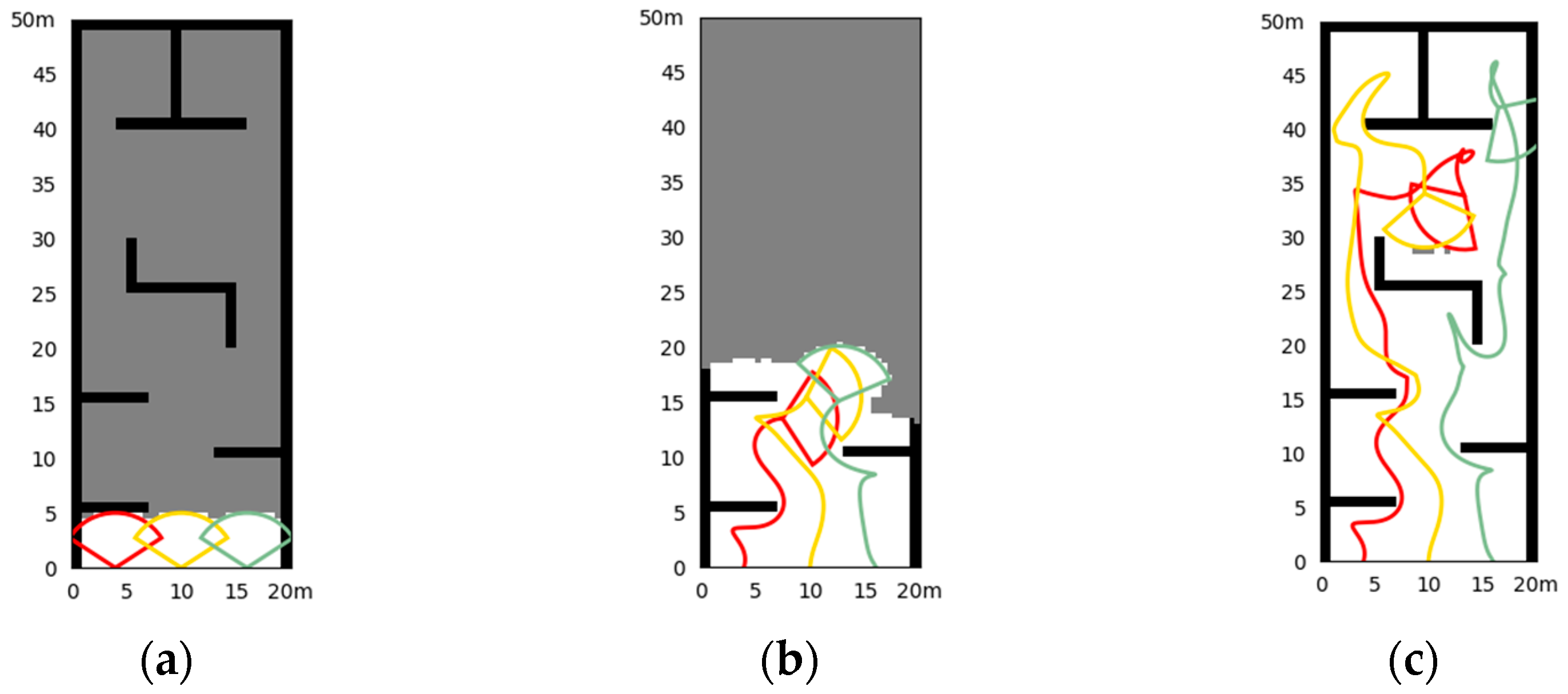
- Simulation in Scene I
- 2.
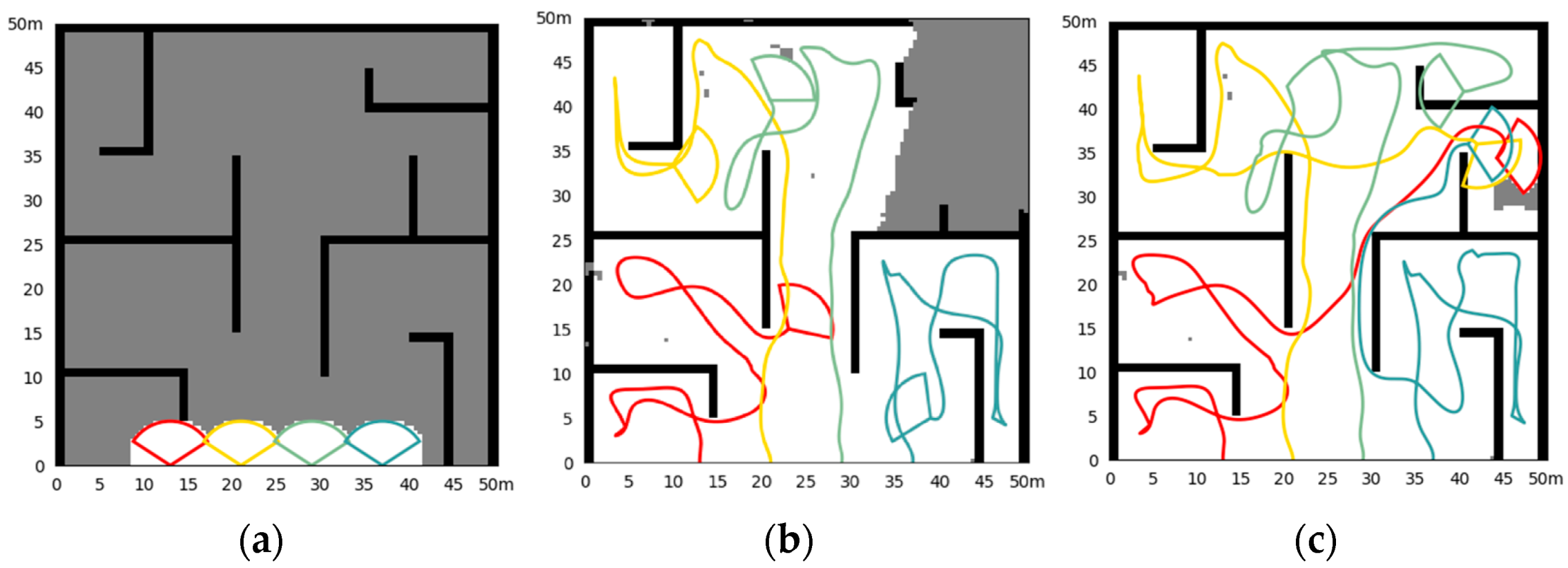
- Simulation in Scene II
- 3.
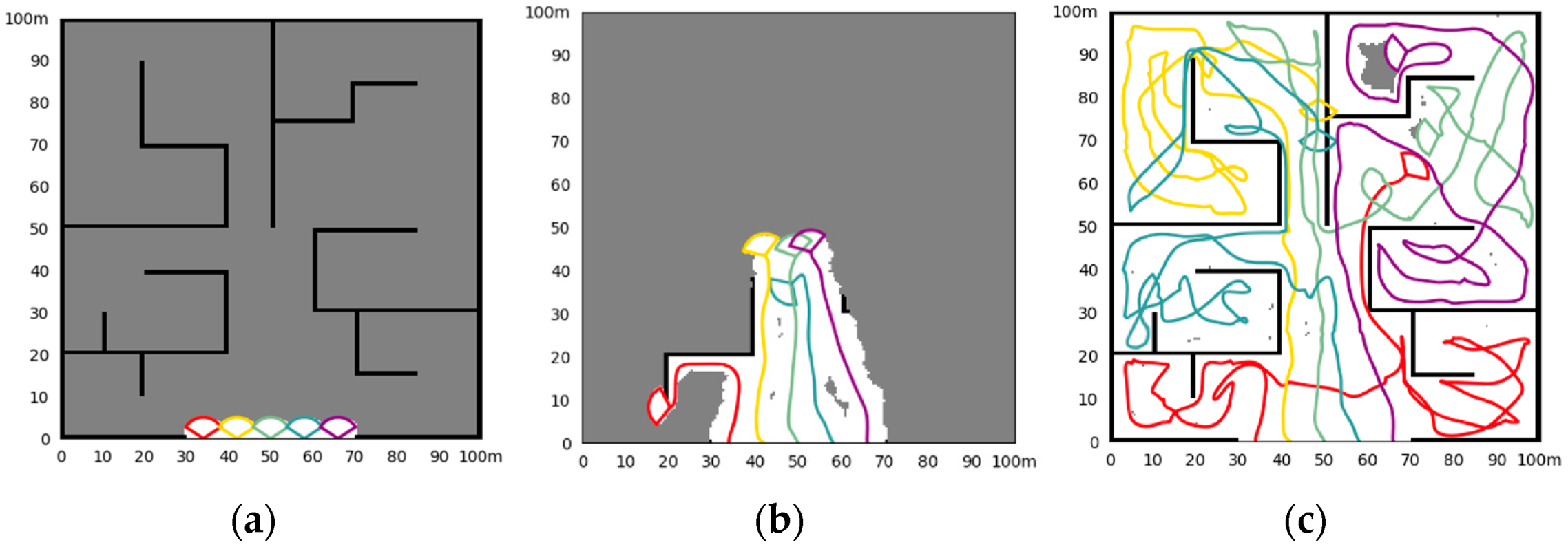
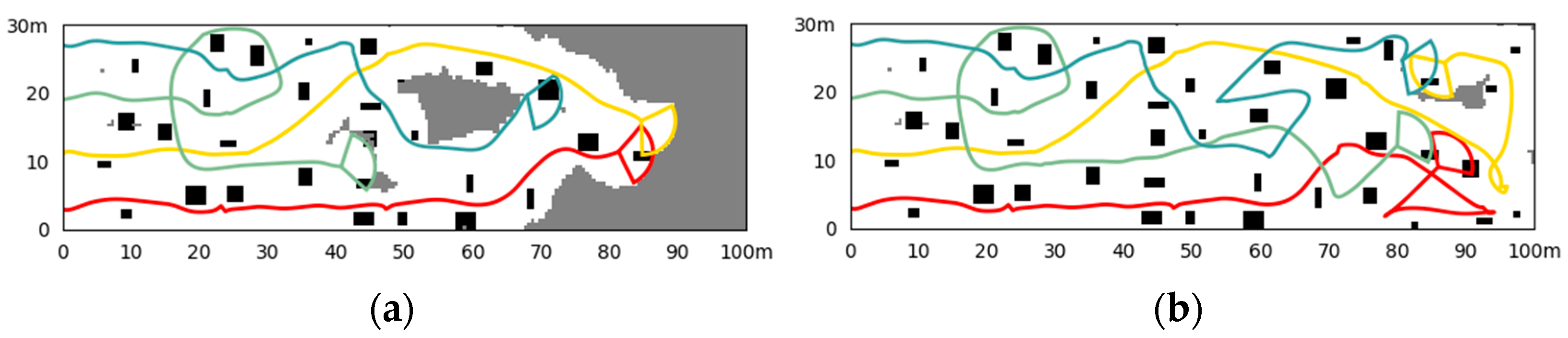
- Simulation in Scene III
- 4.
- Comparing the methods in three scenes
4.2. Simulation in Random-Obstacle Scenes
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, Y.-J.; Du, Y.-C.; Ling, H.-F.; Sheng, W.-G.; Chen, S.-Y. Evolutionary Collaborative Human-UAV Search for Escaped Criminals. IEEE Trans. Evol. Comput. 2019, 24, 217–231. [Google Scholar] [CrossRef]
- Unal, G. Visual Target Detection and Tracking Based on Kalman Filter. J. Aeronaut. Space Technol. 2021, 14, 251–259. [Google Scholar]
- Alotaibi, E.T.; Alqefari, S.S.; Koubaa, A. Lsar: Multi-uav Collaboration for Search and Rescue Missions. IEEE Access 2019, 7, 55817–55832. [Google Scholar] [CrossRef]
- Yang, Y.; Xiong, X.; Yan, Y. UAV Formation Trajectory Planning Algorithms: A Review. Drones 2023, 7, 62. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, Q.; Shang, X.; Wu, Z.; Wang, J. Multi-UAV Autonomous Path Planning in Reconnaissance Missions Considering Incomplete Information: A Reinforcement Learning Method. Drones 2022, 7, 10. [Google Scholar] [CrossRef]
- Chi, W.; Ding, Z.; Wang, J.; Chen, G.; Sun, L. A Generalized Voronoi Diagram-based Efficient Heuristic Path Planning Method for RRTs in Mobile Robots. IEEE Trans. Ind. Electron. 2021, 69, 4926–4937. [Google Scholar] [CrossRef]
- Sun, Y.; Tan, Q.; Yan, C.; Chang, Y.; Xiang, X.; Zhou, H. Multi-UAV Coverage through Two-Step Auction in Dynamic Environments. Drones 2022, 6, 153. [Google Scholar] [CrossRef]
- Cheng, L.; Yuan, Y. Adaptive Multi-player Pursuit–evasion Games with Unknown General Quadratic Objectives. ISA Trans. 2022, 131, 73–82. [Google Scholar] [CrossRef]
- Elsisi, M. Improved Grey wolf Optimizer Based on Opposition and Quasi Learning Approaches for Optimization: Case Study Autonomous Cehicle Including Vision System. Artif. Intell. Rev. 2022, 55, 5597–5620. [Google Scholar] [CrossRef]
- Batinovic, A.; Petrovic, T.; Ivanovic, A.; Petric, F.; Bogdan, S. A Multi-resolution Frontier-based Planner for Autonomous 3D Exploration. IEEE Robot. Autom. Lett. 2021, 6, 4528–4535. [Google Scholar] [CrossRef]
- Gomez, C.; Hernandez, A.C.; Barber, R. Topological Frontier-based Exploration and Map-building Using Semantic Information. Sensors 2019, 19, 4595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, C.; Sun, R.; Yu, S.; Chen, L.; Zheng, J. Autonomous Indoor Mobile Robot Exploration Based on Wavefront Algorithm. In Intelligent Robotics and Applications: 12th International Conference, ICIRA 2019, Shenyang, China, 8–11 August 2019; Proceedings, Part V 12, 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 338–348. [Google Scholar]
- Ahmad, S.; Mills, A.B.; Rush, E.R.; Frew, E.W.; Humbert, J.S. 3d Reactive Control and Frontier-based Exploration for Unstructured Environments. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2289–2296. [Google Scholar]
- Cieslewski, T.; Kaufmann, E.; Scaramuzza, D. Rapid Exploration with Multi-rotors: A Frontier Selection Method for High Speed Flight. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2135–2142. [Google Scholar]
- Zhou, B.; Zhang, Y.; Chen, X.; Shen, S. Fuel: Fast Uav Exploration Using Incremental Frontier Structure and Hierarchical Planning. IEEE Robot. Autom. Lett. 2021, 6, 779–786. [Google Scholar] [CrossRef]
- Ashutosh, K.; Kumar, S.; Chaudhuri, S. 3d-nvs: A 3D Supervision Approach for Next View Selection. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3929–3936. [Google Scholar]
- Kim, J.; Bonadies, S.; Lee, A.; Gadsden, S.A. A Cooperative Exploration Strategy with Efficient Backtracking for Mobile Robots. In Proceedings of the 2017 IEEE International Symposium on Robotics and Intelligent Sensors (IRIS), Ottawa, ON, Canada, 5–7 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 104–110. [Google Scholar]
- Palazzolo, E.; Stachniss, C. Effective Exploration for MAVs Based on the Expected Information Gain. Drones 2018, 2, 9. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Li, C.; Chen, T.; Zhang, Y. Improved RRT Algorithm for AUV Target Search in Unknown 3D Environment. J. Mar. Sci. Eng. 2022, 10, 826. [Google Scholar] [CrossRef]
- Vasquez-Gomez, J.I.; Troncoso, D.; Becerra, I.; Sucar, E.; Murrieta-Cid, R. Next-best-view Regression Using a 3D Convolutional Neural Network. Mach. Vis. Appl. 2021, 32, 1–14. [Google Scholar]
- Duberg, D.; Jensfelt, P. Ufoexplorer: Fast and Scalable Sampling-based Exploration with a Graph-based Planning Structure. IEEE Robot. Autom. Lett. 2022, 7, 2487–2494. [Google Scholar] [CrossRef]
- Wang, J.; Li, T.; Li, B.; Meng, M.Q.-H. GMR-RRT*: Sampling-based path Planning Using Gaussian Mixture Regression. IEEE Trans. Intell. Veh. 2022, 7, 690–700. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Q.; Zhao, D. Deep Reinforcement Learning-based Automatic Exploration for Navigation in Unknown Environment. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2064–2076. [Google Scholar] [CrossRef]
- Ramezani Dooraki, A.; Lee, D.-J. An End-to-end Deep Reinforcement Learning-based Intelligent Agent Capable of Autonomous Exploration in Unknown Environments. Sensors 2018, 18, 3575. [Google Scholar] [CrossRef] [Green Version]
- Niroui, F.; Zhang, K.; Kashino, Z.; Nejat, G. Deep Reinforcement Learning Robot for Search and Rescue Applications: Exploration in Unknown Cluttered Environments. IEEE Robot. Autom. Lett. 2019, 4, 610–617. [Google Scholar] [CrossRef]
- Garaffa, L.C.; Basso, M.; Konzen, A.A.; de Freitas, E.P. Reinforcement Learning For Mobile Robotics Exploration: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, J.; Tang, J.; Qiu, J.; Wang, J.; Shen, Y.; Wang, Y.; Yang, H. In Explore-bench: Data Sets, Metrics and Evaluations for Frontier-based and Deep-reinforcement-learning-based Autonomous Exploration. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6225–6231. [Google Scholar]
- Elmokadem, T.; Savkin, A.V. Computationally-Efficient Distributed Algorithms of Navigation of Teams of Autonomous UAVs for 3D Coverage and Flocking. Drones 2021, 5, 124. [Google Scholar] [CrossRef]
- Unal, G. Fuzzy Robust Fault Estimation Scheme for Fault Tolerant Flight Control Systems Based on Unknown Input Observer. Aircr. Eng. Aerosp. Technol. 2021, 93, 1624–1631. [Google Scholar] [CrossRef]
- Kilic, U.; Unal, G. Aircraft Air Data System Fault Detection and Reconstruction Scheme Design. Aircr. Eng. Aerosp. Technol. 2021, 93, 1104–1114. [Google Scholar] [CrossRef]
- Hong, Y.; Kim, S.; Kim, Y.; Cha, J. Quadrotor Path Planning Using A* Search Algorithm and Minimum Snap Trajectory Generation. ETRI J. 2021, 43, 1013–1023. [Google Scholar] [CrossRef]
- Unal, G. Integrated Design of Fault-tolerant Control for Flight Control Systems Using Observer and Fuzzy logic. Aircr. Eng. Aerosp. Technol. 2021, 93, 723–732. [Google Scholar] [CrossRef]
- Amoozegar, M.; Minaei-Bidgoli, B. Optimizing Multi-objective PSO Based Feature Selection Method Using a Feature Elitism Mechanism. Expert Syst. Appl. 2018, 113, 499–514. [Google Scholar] [CrossRef]
- Yuan, Q.; Sun, R.; Du, X. Path Planning of Mobile Robots Based on an Improved Particle Swarm Optimization Algorithm. Processes 2022, 11, 26. [Google Scholar] [CrossRef]
- Han, F.; Chen, W.-T.; Ling, Q.-H.; Han, H. Multi-objective Particle Swarm Optimization with Adaptive Strategies for Feature Selection. Swarm Evol. Comput. 2021, 62, 100847. [Google Scholar] [CrossRef]
- Han, F.; Wang, T.; Ling, Q. An Improved Feature Selection Method Based on Angle-guided Multi-objective PSO and Feature-label Mutual Information. Appl. Intell. 2023, 53, 3545–3562. [Google Scholar] [CrossRef]
- Shaikh, P.W.; El-Abd, M.; Khanafer, M.; Gao, K. A Review on Swarm Intelligence and Evolutionary Algorithms for Solving the Traffic Signal Control Problem. IEEE Trans. Intell. Transp. Syst. 2020, 23, 48–63. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene I |
| Map Parameters: map size: 20 m 50 m, resolution: 0.25 m 0.25 m Initialization *: UAV1:(4,0,90), UAV2:(10,0,90), UAV3:(16,0,90) detection radius: 5 m, Fov: 104°, : 3 m, max velocity: 2.5 m/s, end rate: 99.5% |
| Scene II |
| Map Parameters: map size: 50 m 50 m, resolution: 0.4 m 0.4 m Initialization *: UAV1:(13,0,90), UAV2:(21,0,90), UAV3:(29,0,90), UAV4:(37,0,90) detection radius: 5 m, Fov: 104°, : 3 m, max velocity: 2.5 m/s, end rate: 99% |
| Scene III |
| Map Parameters: map size: 100 m 100 m, resolution: 0.5 m 0.5 m Initialization *: UAV1:(34,0,90), UAV2:(42,0,90), UAV3:(50,0,90), UAV4:(58,0,90), UAV5:(66,0,90) detection radius: 5 m, Fov: 104°, : 3 m, max velocity: 2.5 m/s, end rate: 99% |
| Parameters | Value |
|---|---|
| predict horizon | = 5 |
| sample num | = 10, = 50 |
| weight distribution | = 0.1, = 0.1, = 0.5, = 0.2, = 0.1 |
| learning factor | , = 1.46 |
| threshold of age | |
| population size | = 50 |
| max number of generations | maxgen = 100 |
| simulation step | = 0.2 s |
| Exploration Time (s) | ||||||
|---|---|---|---|---|---|---|
| Initial | Method | Mean | Best | Worst | Std | |
| Scene I | Fixed | Proposed | 32.6 | 26.4 | 38.8 | 3.0 |
| Frontier-based | 61.2 | - | - | - | ||
| NBV | 44.3 | 36.8 | 62.6 | 6.0 | ||
| Random | Proposed | 35.9 | 30.4 | 42.0 | 3.1 | |
| Frontier-based | 61.6 | 39.2 | 75.6 | 6.6 | ||
| NBV | 47.8 | 39.6 | 68.6 | 6.9 | ||
| Scene II | Fixed | Proposed | 65.9 | 60.8 | 76.4 | 4.0 |
| Frontier-based | 136.4 | - | - | - | ||
| NBV | 89.5 | 74.2 | 107.0 | 6.7 | ||
| Random | Proposed | 70.5 | 61.6 | 80.8 | 4.6 | |
| Frontier-based | 147.1 | 95.2 | 185.6 | 16.9 | ||
| NBV | 95.7 | 80.8 | 112.4 | 7.4 | ||
| Scene III | Fixed | Proposed | 205.4 | 188.2 | 221.0 | 8.9 |
| Frontier-based | 456.2 | - | - | - | ||
| NBV | 280.5 | 247.4 | 302.6 | 14.7 | ||
| Random | Proposed | 211.9 | 193.2 | 249.2 | 10.0 | |
| Frontier-based | 475.5 | 296.2 | 700.4 | 43.1 | ||
| NBV | 283.9 | 251.8 | 305.8 | 14.6 | ||
| Exploration Time (s) | |||||
|---|---|---|---|---|---|
| Initial | Method | Mean | Best | Worst | Std |
| Fixed | Proposed | 73.7 | 60.0 | 82.8 | 6.1 |
| Frontier-based | 101.3 | 90.2 | 131.4 | 9.7 | |
| NBV | 92.4 | 82.8 | 109.2 | 9.0 | |
| Random | Proposed | 74.8 | 64.8 | 86.4 | 6.2 |
| Frontier-based | 104.8 | 91.4 | 138.8 | 10.9 | |
| NBV | 93.3 | 80.4 | 114.6 | 8.3 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, X.; Zhuang, X.; Li, F.; Liang, Y. A Sampling-Based Distributed Exploration Method for UAV Cluster in Unknown Environments. Drones 2023, 7, 246. https://doi.org/10.3390/drones7040246
Wang Y, Li X, Zhuang X, Li F, Liang Y. A Sampling-Based Distributed Exploration Method for UAV Cluster in Unknown Environments. Drones. 2023; 7(4):246. https://doi.org/10.3390/drones7040246
Chicago/Turabian StyleWang, Yue, Xinpeng Li, Xing Zhuang, Fanyu Li, and Yutao Liang. 2023. "A Sampling-Based Distributed Exploration Method for UAV Cluster in Unknown Environments" Drones 7, no. 4: 246. https://doi.org/10.3390/drones7040246
APA StyleWang, Y., Li, X., Zhuang, X., Li, F., & Liang, Y. (2023). A Sampling-Based Distributed Exploration Method for UAV Cluster in Unknown Environments. Drones, 7(4), 246. https://doi.org/10.3390/drones7040246