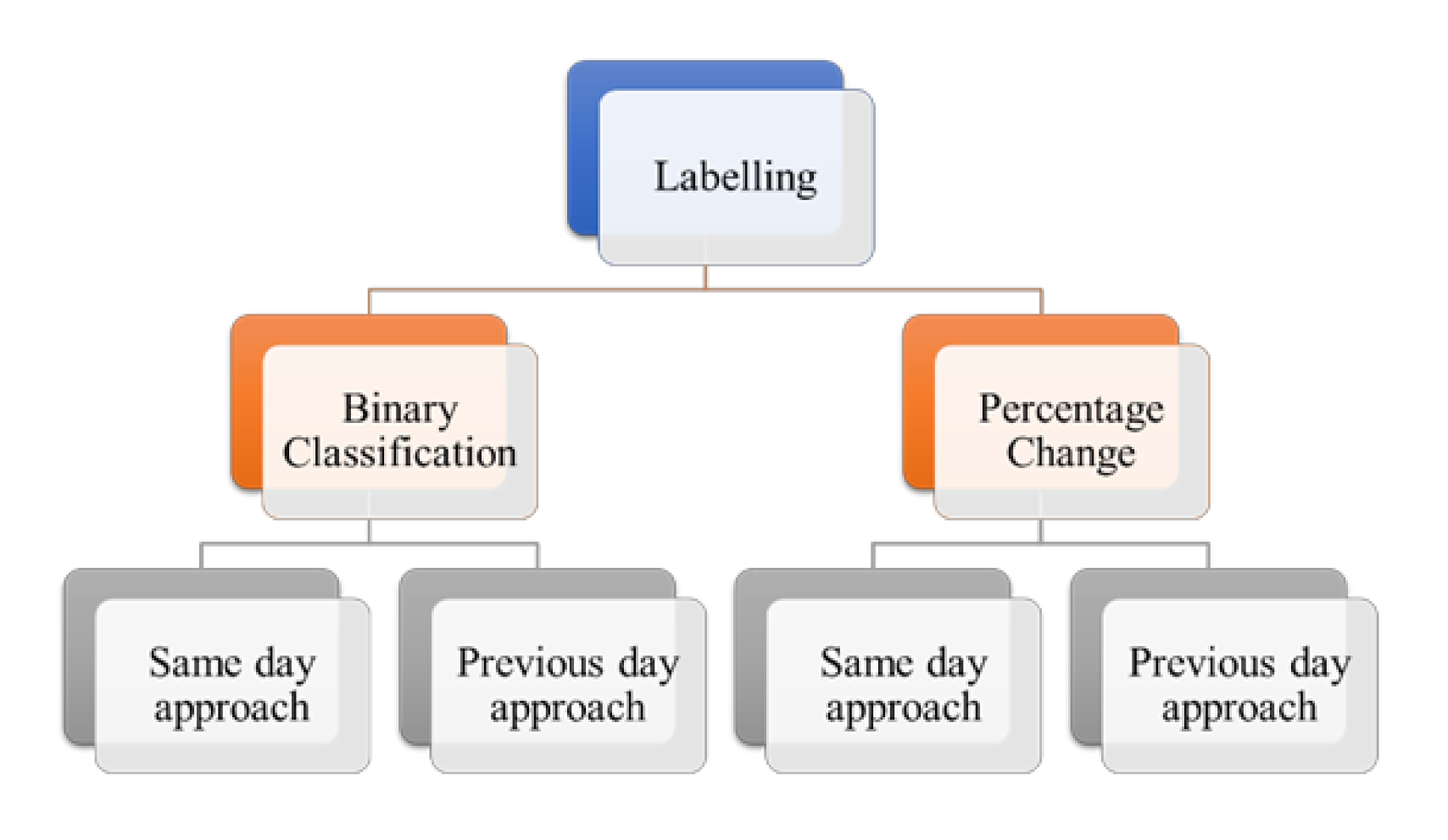
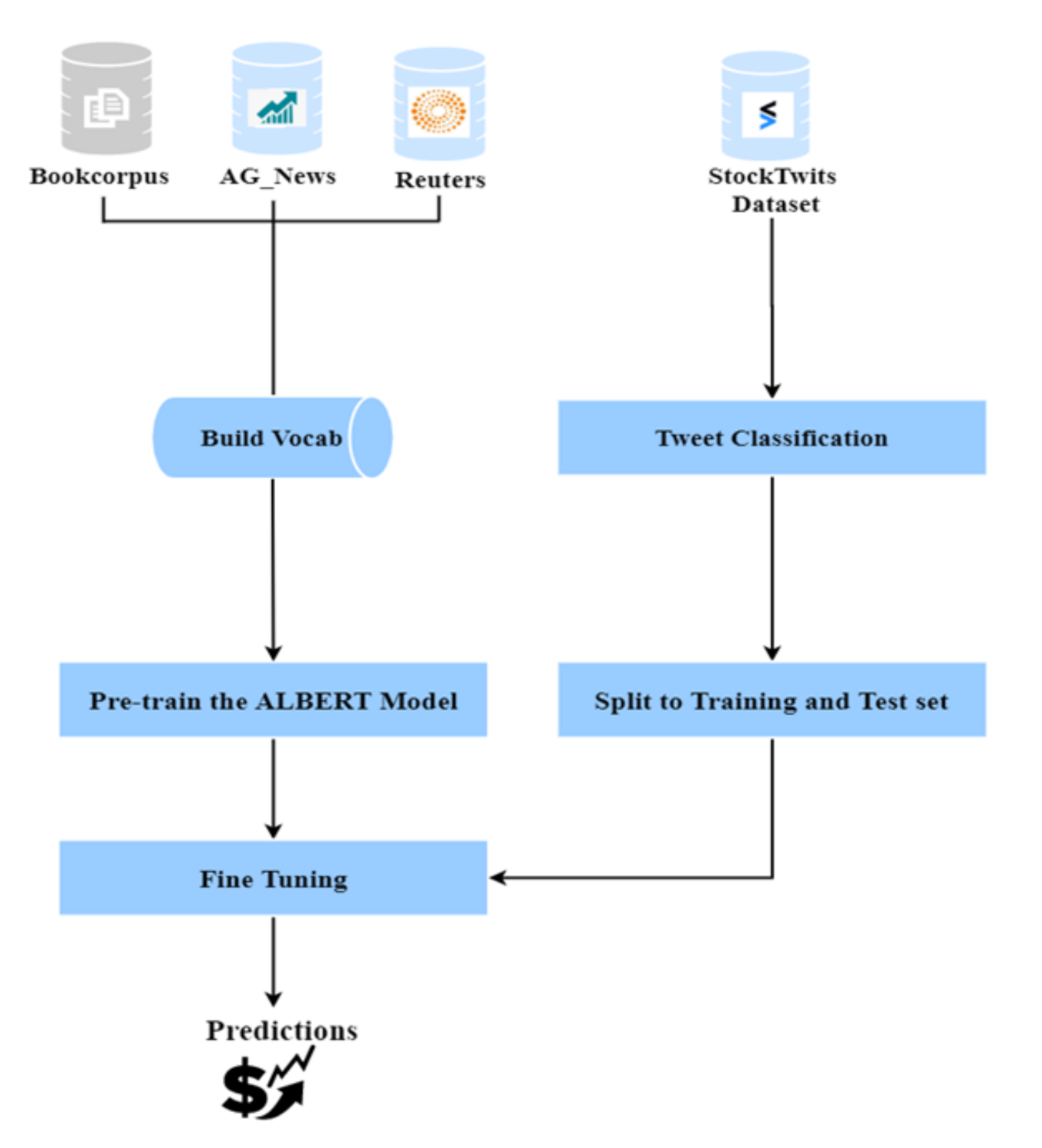
The main contribution for this study is a stock movement prediction model which is trained on unsupervised data labelled using the changes in stock prices. A strong correlation exists between the stock price changes and the public sentiments posted as messages on different social media platforms [
21]. There are a few models currently available in the market which are based on this correlation. These models check if there are a greater number of positive tweets for a particular day that would mean the stock is performing well and there would be an increase in the price. The main issue in the training of such models is classified as Twitter dataset. In most of them, the tweets are classified (or labelled) by experts or by sentiment analysis tools like VADER, SentiWordNet, TextBlob, etc. The manually tagging of tweets is time-consuming and requires a lot of resources. Our model uses new labelling techniques where the messages are classified into positive, negative, and neutral based on the increase or decrease in the stock price. It makes use of the correlation and works on the assumption that if the price for a stock increased on a particular day then for that stock the tweets would be positive, and thus can be labelled as positive and vice-versa. Apart from this, we proposed a new model FinALBERT, which is ALBERT model trained on financial datasets. Another major limitation of currently available stock movement prediction models available today is that they are missing financial dataset, which would include the financial jargons required for appropriate predictions. Thus, the proposed FinALBERT model is pre-trained using a combination of three datasets (Reuters-21578, which consists of data for money supply or exchanges, AG News which consists of data for the Business category and Bookcorpus which is collection of text taken from Wikipedia) which would help in building a financial specific pre-trained model. We fine-tuned this pre-trained model with different size on the provided StockTwits dataset and experimented with various hyperparameters. For comparison, we experimented with various other traditional machine learning algorithms and transformer-based models.
6.2. Model Evaluation
As stated earlier, we experimented with various traditional machine learning algorithms, transformer-based models, and neural network with different word embeddings on all three labelling techniques. Overall, out of all the models experimented with the best results were given by the transformer model BERT and Naïve Bayes algorithm across one year and two years of data for all the labelling techniques.
Among transformer models, BERT model outperforms FinBERT and the proposed FinALBERT model. FinALBERT model did not give the desired results mainly because of the pre-trained model. We used Reuters-21578, AG News and 10% of Book Corpus dataset. The default number of training steps for Albert pre-training equal 1,25,000 [
14], but we were able to pre-train the model only on 10,000 steps. As the pre-trained model size was small, we tried improving the model performance by changing hyperparameter values (learning rate, batch sizes, training for more epochs). But even with these changes, the model performance did not improve. We noticed that the FinALBERT model is very sensitive to hyperparameters, and it was initially giving a labelling bias issue because of these parameters. Labelling bias here means that after model training, all the tweets were getting classified as positive (class 1) in the testing dataset. After extensive research, we found that for FinALBERT model to perform well and not have labelling bias, it requires a combination of appropriate training data size and aligned hyperparameters values. Once we aligned the data size and hyperparameter values according to Stanford Sentiment Treebank (SST-2) dataset in ALBERT by [
14], we were able to get the desired model results and fix the labelling bias issue. The hyperparameters used for this data in the paper are learning rate as 1.00E-05 and batch size as 32. When we experimented by changing the learning rate to 2.00E-05 or 5.00E-05, we again saw a drop in macro average and labelling bias issue. We also found that to fix labelling bias, we had to add a parameter known as weight decay in the AdamW optimiser. This parameter helps in reducing the overfitting of the model, and the generalisation of the model is improved [
31].
While the BERT model outperformed other transformer models because the bert-base-uncased pre-trained model is made up of large Wikipedia data, which consists of approximately 2,500 million words and a book corpus which includes 800 million words; thus, the vocabulary is large and includes common English words. Whereas as mentioned earlier, for the pre-training FinALBERT model, we used a smaller dataset and a smaller number of training steps. Additionally, on further research, we found that ALBERT had outperformed BERT in Stanford Sentiment Treebank (SST-2), a sentiment analysis dataset only when the pre-trained model was albert-xxlarge (not in the case of albert-base). While for pre-training FinALBERT we used the architecture of albert-base as the albert-xxlarge model is computationally very expensive due to its very large structure (large hidden size and more attention heads). We cannot pre-train FinALBERT using albert-xxlarge because of hardware limitations. Thus, the performance of BERT model was more than that of FinALBERT model.
FinBERT performed better than FinALBERT model in all the three labelling techniques. For pre-training, the FinBERT model the TRC2-financial data was added to the bert-base-uncased model. This data consists of about 29 million words and is familiar with financial jargon. Thus, here also the pre-training data was large as compared to our pre-trained FinALBERT model. FinALBERT, when fine-tuned with FinancialPhraseBank dataset gives exceptional results. It consists of 2264 English sentences selected from Financial news. These sentences are manually annotated by 16 professionals from the business and finance world. The gold standard labels in FinancialPhraseBank are based on sentiments of each financial sentence, which helped us infer that FinALBERT can perform well with sentiment analysis as it contains financial domain vocabulary along with generic English vocab. The results outperform when compared to the stock price-based labels for the same reason.
Among the traditional models, the Naïve Bayes model outperforms all other models as it performs well for the large dataset and works well with the categorical dataset. It works well with the large dataset because every feature is considered independently, and probability is calculated for individual categories before predicting the one with the highest. Additionally, the time taken for training the Naïve Bayes model was drastically less when compared to transformer models.
In the traditional models, TF-IDF vectoriser performed better than count vectoriser. To test this, we implement the traditional models using Grid Search using k-fold cross-validation. For all the models, with 5-fold cross-validation Grid Search gave the best parameter as use TF-IDF from the pipeline function. Additionally, TF-IDF vectoriser assigns weight to a word based on the count of the word in a document (term frequency) with its inverse frequency which means its occurrence across all the documents (tweets in our case) while count vectoriser assigns weight by simply counting the words (Stop words like “the”, “a” would be given more weightage). Thus, all the traditional models have used TF-IDF for feature extraction.
We also noticed that the model performance did not improve when we used different embedding techniques for feature extraction and training it on neural network models. The neural network-based models like BiLSTM are designed to analyse the sequence of inputs, and our data is not classified based on the sentences but on the price. Because of this reason, these models did not perform well. Additionally, because of the same reason, the attention layer over the BiLSTM was not able to improve the performance. Among all the experiments BiLSTM with FinALBERT word-embeddings performed considerably well with one exception where Word2Vec with BiLSTM performed the best with percentage change two labels among the neural network-based models.
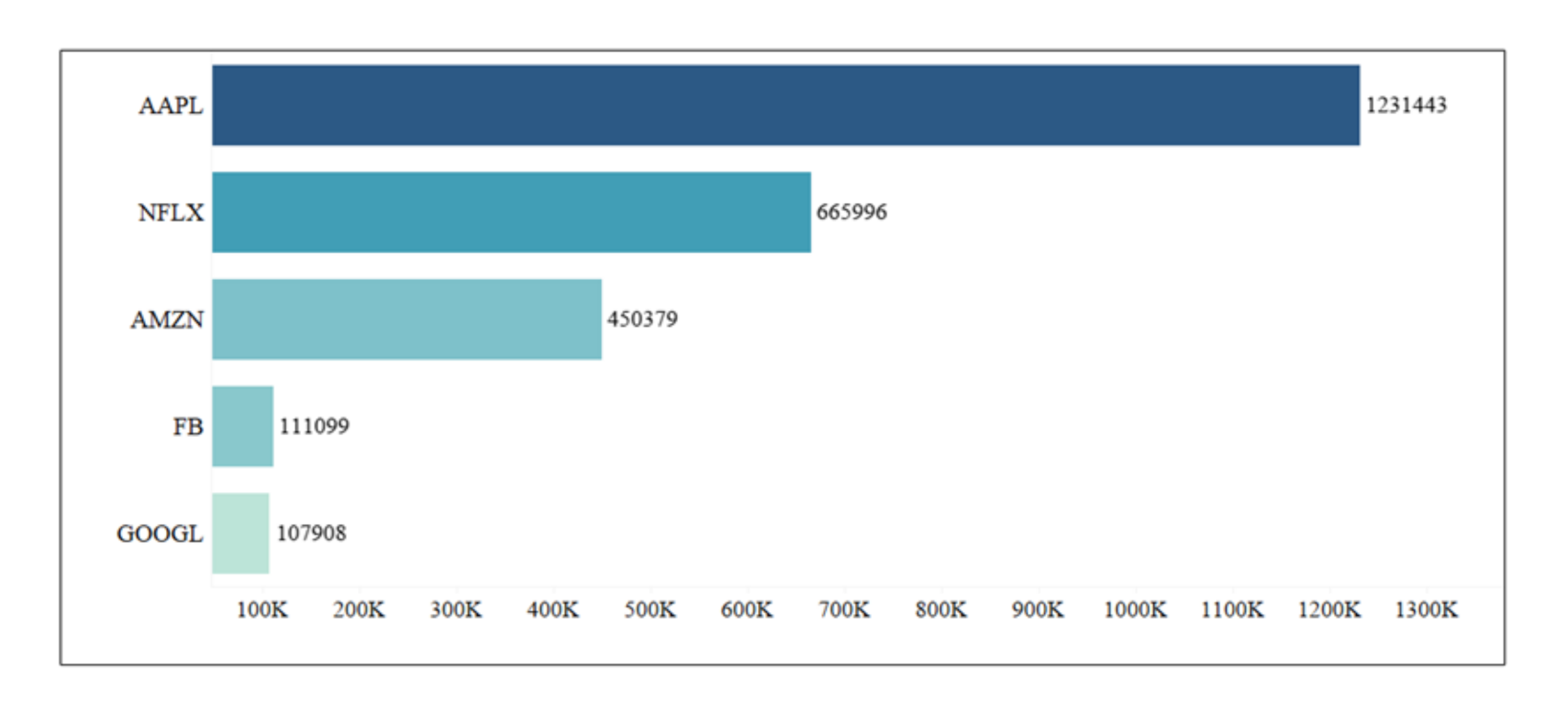
Overall, we only saw a 1% difference in model performance between Naïve Bayes the traditional machine learning model and the transformer-based model BERT. However, as shown in the figure below while comparing the average training times for all models, Naïve Bayes takes approximately 5 min to train, while the BERT model, on the other hand, takes 9 h as transformer-based models have large architectures and are computationally expensive. Thus, as our labelling techniques are based on stock price and not the sentiments of a sentence (or sequence of the sentence), we believe that the implementation of transformer models on this labelled dataset did not help in improving the model performance. Training time for different models are compared and shown in
Figure 7. BERT has the highest computation time whereas Naïve bayes has the lowest.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}