
Forecasting Seasonal Sales with Many Drivers: Shrinkage or Dimensionality Reduction?




Abstract
:1. Introduction
- we propose a feasible solution to include relevant drivers, including promotions, into the statistical AutoRegressive Integrated Moving Average (ARIMA) and ExponenTial Smoothing (ETS) models based on automatically selected principal components;
- we comparatively evaluate dimensionality reduction and shrinkage approaches, identifying the benefits of each in the presence of promotion and prices changes in a retail setting;
- our approaches are completely automated and computationally efficient running without a need for human intervention and therefore scalable to address the retailers’ requirements, offering modelling guidelines to both retailers and software suppliers.
2. Retail Forecasting
3. Methods
3.1. Regression with AutoRegressive Integrated Moving Average Errors
3.1.1. Univariate AutoRegressive Integrated Moving Average Models
3.1.2. Inclusion of Explanatory Variables
3.1.3. Trigonometric Seasonality
3.2. Exponential Smoothing Models with Explanatory Variables
3.2.1. Univariate Exponential Smoothing Models
3.2.2. Incorporation of Explanatory Variables
3.2.3. Trigonometric Box-Cox ARMA Trend Seasonal Model
3.3. Dimensionality Reduction with Principal Components
3.4. Dynamic Regression with Shrinkage
4. Empirical Study
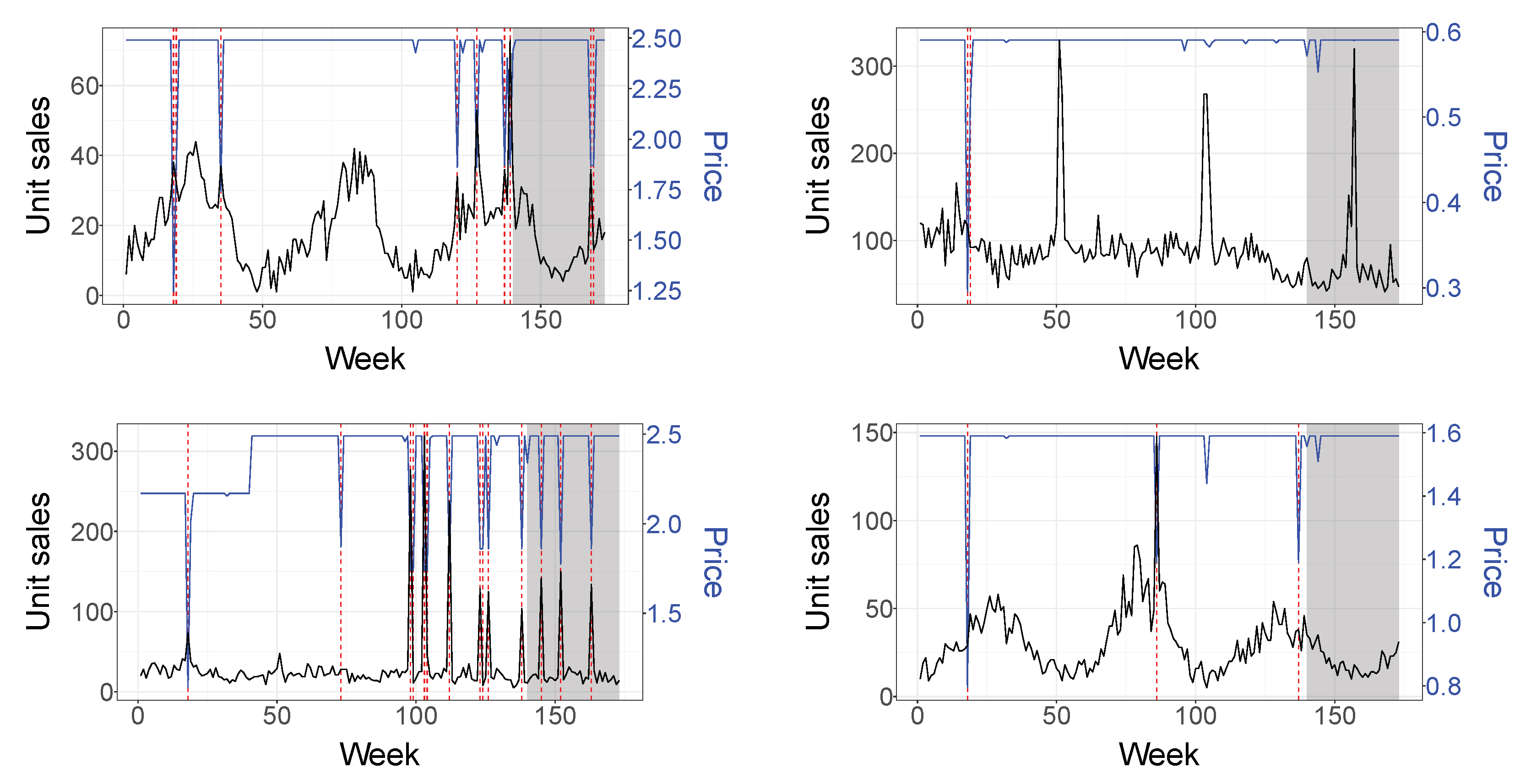
4.1. Dataset
- Price and a lag of order 1 (2 inputs).
- Days promoted per week and a lag of order 1 (2 inputs); this variable indicates how many days in the week the SKU is under promotion.
- Last week of the month and a lag of order 1 (24 inputs); this dummy variable captures the end of the month payday effect.
- Binary indicators representing the following calendar events (15 inputs): New Year’s Day, Carnival and the week before, Good Friday and Easter and the week before, Freedom’s Day, Labor’s Day, Corpus Christi week, Portugal’s day, Assumption Day, Republic’s day, All Saints’ Day, Restoration of the Independence, Christmas and the week before.
4.2. Evaluation Design
4.3. Evaluated Methods
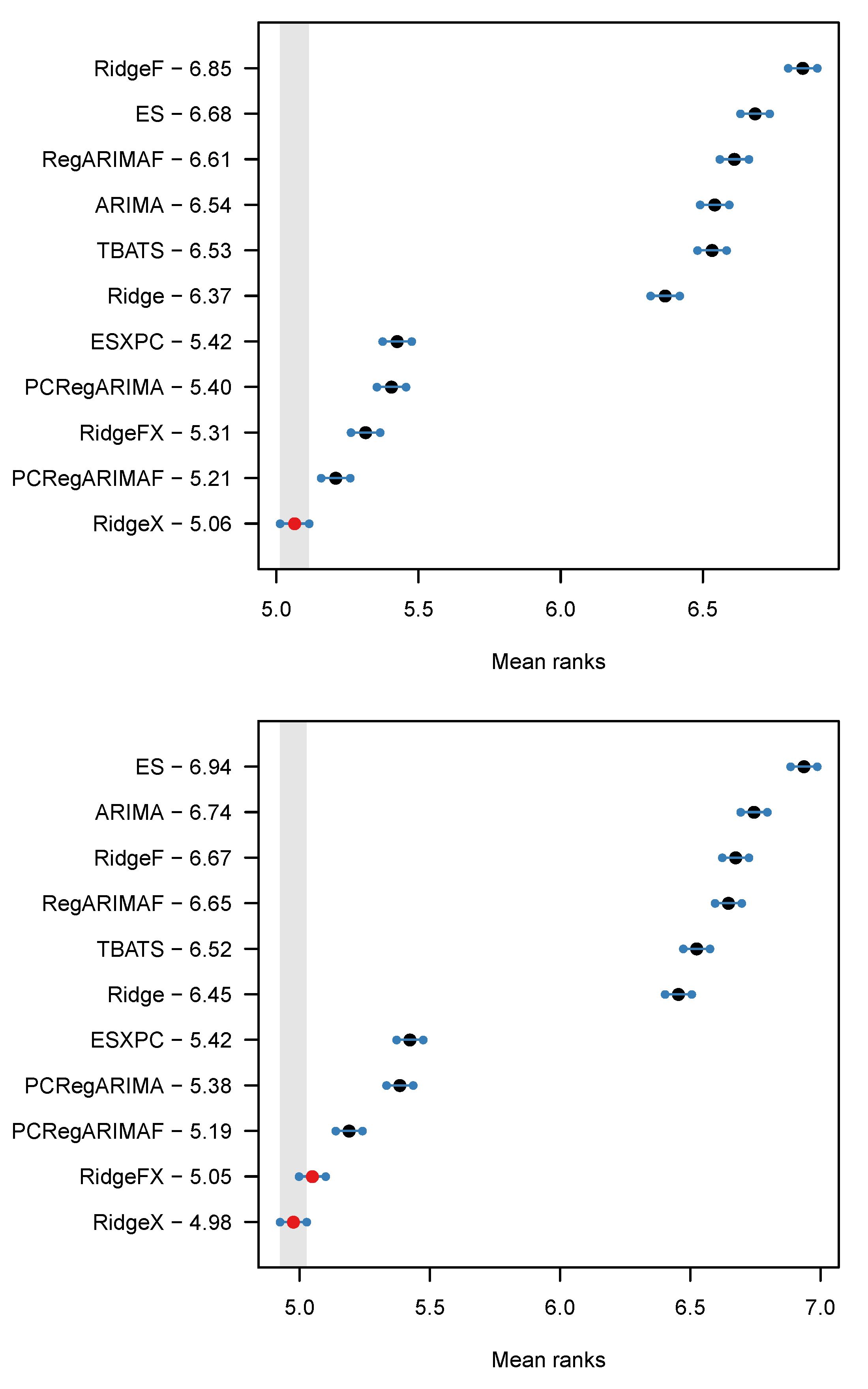
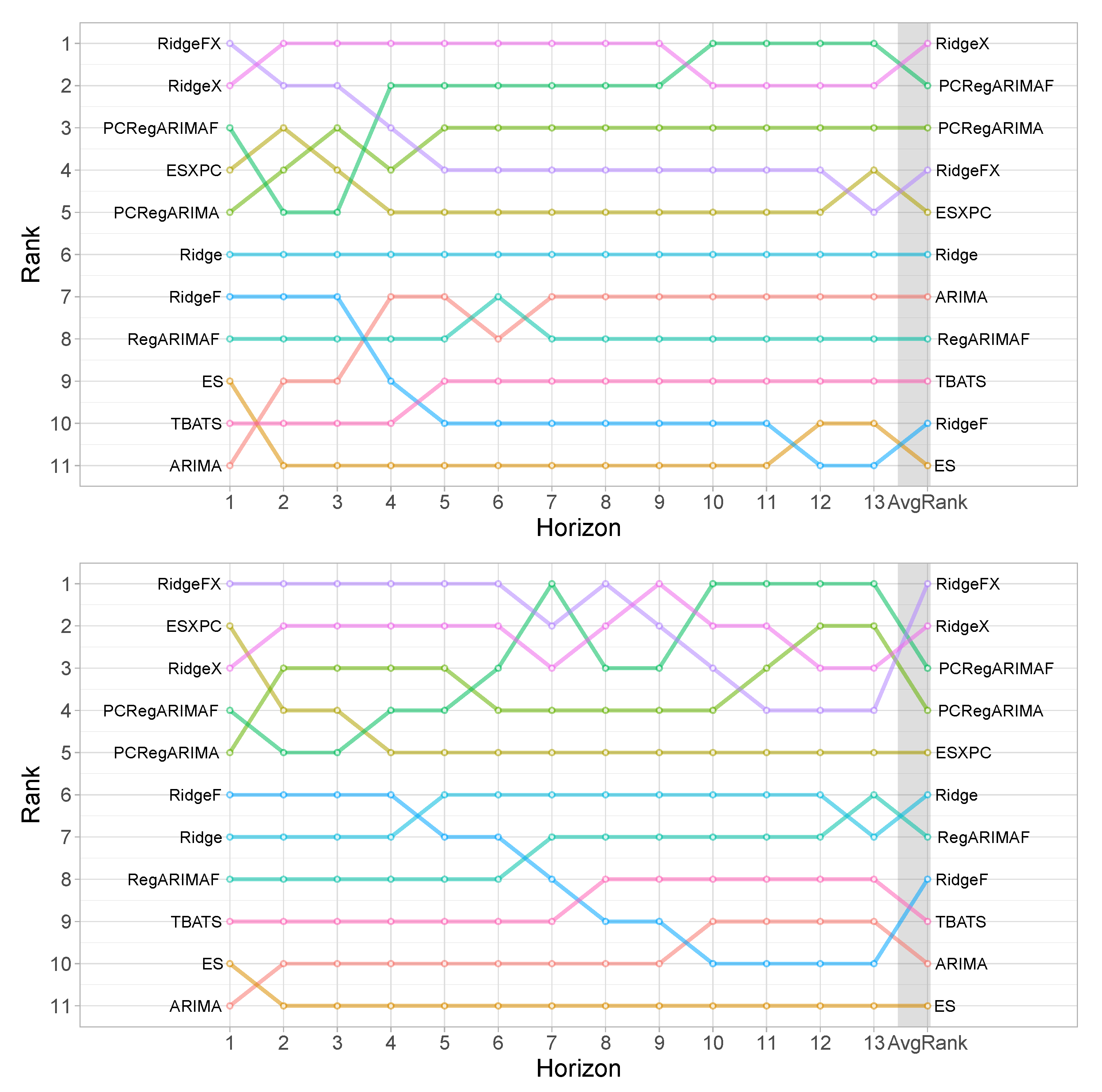
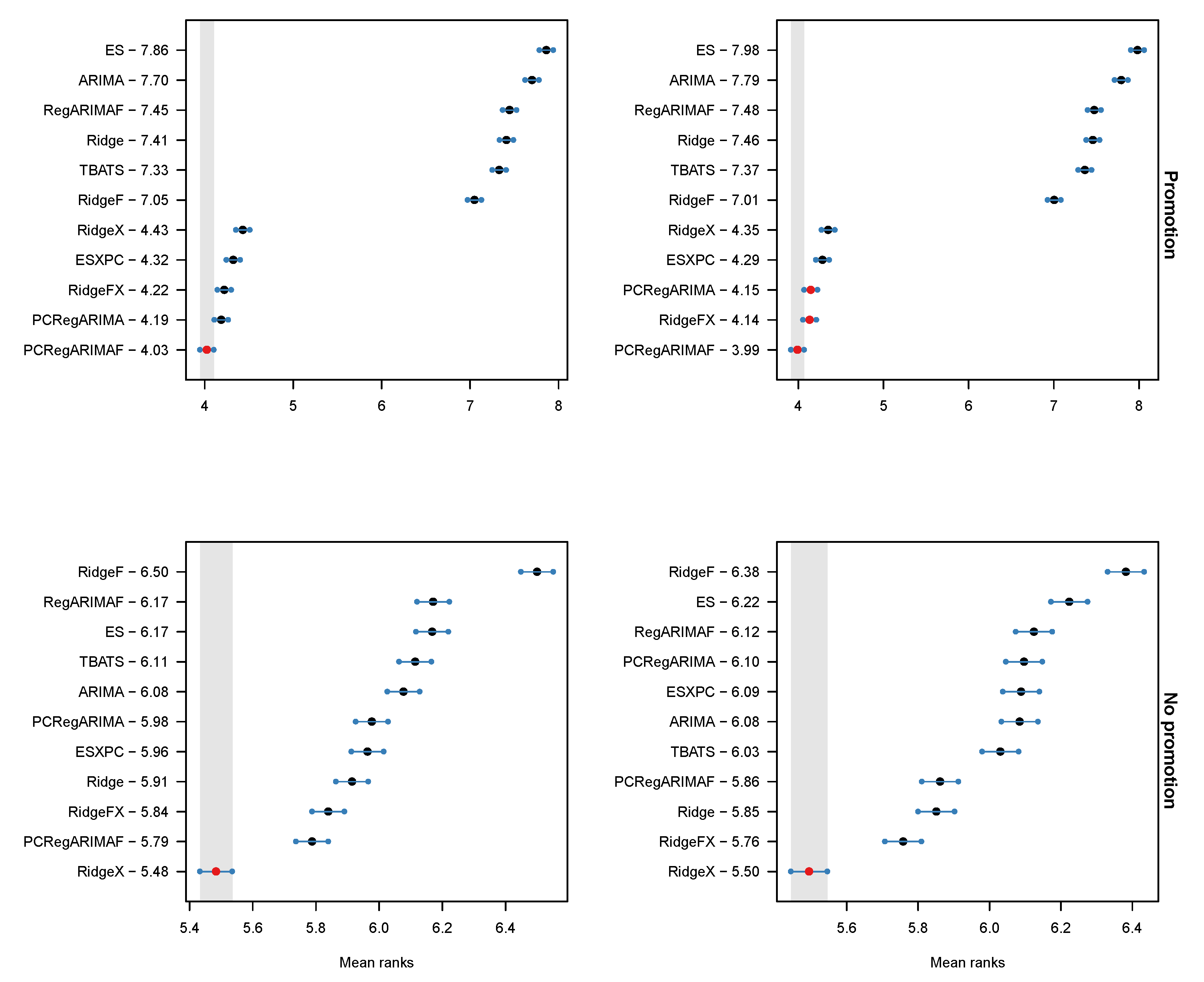
4.4. Results
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AICc | Akaike Information Criterion corrected |
| AR | AutoRegressive |
| ARIMA | AutoRegressive Integrated Moving Average |
| ARMA | AutoRegressive Moving Average |
| ES | Exponenial Smoothing |
| ESXPC | Exponenial Smoothing with eXplanatory variables as Principal Components |
| ETS | ExponenTial Smoothing |
| IRI | Information Resources, Inc. |
| LightGBM | Light Gradient-Boosting Machine |
| MA | Moving Average |
| MAE | Mean Absolute Error |
| MASE | Mean Absolute Scaled Error |
| MCB | Multiple Comparison with the Best |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| OLS | Ordinary Least Squares |
| PCA | Principal Component Analysis |
| PCRegARIMA | Principal Components Regression with ARIMA errors |
| PCRegARIMAF | Principal Components Regression with ARIMA errors and seasonality |
| as Fourier terms | |
| RegARIMAF | Regression with ARIMA errors and seasonality as Fourier terms |
| RidgeF | Ridge with seasonality as Fourier terms |
| RidgeX | Ridge with eXplanatory variables |
| RidgeFX | Ridge with eXplanatory variables and seasonality as Fourier terms |
| RMSSE | Root Mean Squared Scaled Error |
| SKU | Stock-Keeping Unit |
| TBATS | Trigonometric Box-Cox ARMA Trend Seasonal |
References
- Fildes, J.R.T.N.K.R. On the identification of sales forecasting models in the presence of promotions. J. Oper. Res. Soc. 2015, 66, 299–307. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, J.M.; Ramos, P. Assessing the Performance of Hierarchical Forecasting Methods on the Retail Sector. Entropy 2019, 21, 436. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fildes, R.; Ma, S.; Kolassa, S. Retail forecasting: Research and practice. Int. J. Forecast. 2019, 38, 1283–1318. [Google Scholar] [CrossRef] [Green Version]
- Seaman, B. Considerations of a retail forecasting practitioner. Int. J. Forecast. 2018, 34, 822–829. [Google Scholar] [CrossRef]
- Kalyanam, K.; Borle, S.; Boatwright, P. Deconstructing Each Item’s Category Contribution. Mark. Sci. 2007, 26, 327–341. [Google Scholar] [CrossRef]
- Corsten, D.; Gruen, T. Desperately Seeking Shelf Availability: An Examination of the Extent, the Causes, and the Efforts to Address Retail Out-of-Stocks. Int. J. Retail. Distrib. Manag. 2003, 31, 605–617. [Google Scholar] [CrossRef]
- Cooper, L.G.; Baron, P.; Levy, W.; Swisher, M.; Gogos, P. PromoCast™: A New Forecasting Method for Promotion Planning. Mark. Sci. 1999, 18, 301–316. [Google Scholar] [CrossRef] [Green Version]
- Van Donselaar, K.; Peters, J.; de Jong, A.; Broekmeulen, R. Analysis and forecasting of demand during promotions for perishable items. Int. J. Prod. Econ. 2016, 172, 65–75. [Google Scholar] [CrossRef]
- Pina, M.; Gaspar, P.D.; Lima, T.M. Decision Support System in Dynamic Pricing of Horticultural Products Based on the Quality Decline Due to Bacterial Growth. Appl. Syst. Innov. 2021, 4, 80. [Google Scholar] [CrossRef]
- European Parliament. Parliament Calls for Urgent Measures to Halve Food Wastage in the EU; Technical Report; European Commission: Luxembourg, 2012.
- Kourentzes, N.; Petropoulos, F. Forecasting with multivariate temporal aggregation: The case of promotional modelling. Int. J. Prod. Econ. 2016, 181, 145–153, SI: ISIR 2014. [Google Scholar] [CrossRef]
- Abolghasemi, M.; Beh, E.; Tarr, G.; Gerlach, R. Demand forecasting in supply chain: The impact of demand volatility in the presence of promotion. Comput. Ind. Eng. 2020, 142, 106380. [Google Scholar] [CrossRef] [Green Version]
- Abolghasemi, M.; Hurley, J.; Eshragh, A.; Fahimnia, B. Demand forecasting in the presence of systematic events: Cases in capturing sales promotions. Int. J. Prod. Econ. 2020, 230, 107892. [Google Scholar] [CrossRef]
- Holzer, P.S. The effect of time-varying factors on promotional activity in the German milk market. J. Retail. Consum. Serv. 2020, 55, 102090. [Google Scholar] [CrossRef]
- Verstraete, G.; Aghezzaf, E.H.; Desmet, B. A data-driven framework for predicting weather impact on high-volume low-margin retail products. J. Retail. Consum. Serv. 2019, 48, 169–177. [Google Scholar] [CrossRef]
- Alon, I.; Qi, M.; Sadowski, R.J. Forecasting aggregate retail sales: A comparison of artificial neural networks and traditional methods. J. Retail. Consum. Serv. 2001, 8, 147–156. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 2022, 38, 1346–1364. [Google Scholar] [CrossRef]
- Bojer, C.S.; Meldgaard, J.P. Kaggle forecasting competitions: An overlooked learning opportunity. Int. J. Forecast. 2021, 37, 587–603. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 1–9. [Google Scholar]
- Ma, S.; Fildes, R. Retail sales forecasting with meta-learning. Eur. J. Oper. Res. 2021, 288, 111–128. [Google Scholar] [CrossRef]
- Nikolopoulos, K.; Petropoulos, F. Forecasting for big data: Does suboptimality matter? Comput. Oper. Res. 2018, 98, 322–329. [Google Scholar] [CrossRef] [Green Version]
- Fry, C.; Brundage, M. The M4 forecasting competition—A practitioner’s view. Int. J. Forecast. 2020, 36, 156–160, M4 Competition. [Google Scholar] [CrossRef]
- Gilliland, M. The value added by machine learning approaches in forecasting. Int. J. Forecast. 2020, 36, 161–166, M4 Competition. [Google Scholar] [CrossRef]
- Bandara, K.; Bergmeir, C.; Smyl, S. Forecasting across time series databases using recurrent neural networks on groups of similar series: A clustering approach. Expert Syst. Appl. 2020, 140, 112896. [Google Scholar] [CrossRef] [Green Version]
- Januschowski, T.; Gasthaus, J.; Wang, Y.; Salinas, D.; Flunkert, V.; Bohlke-Schneider, M.; Callot, L. Criteria for classifying forecasting methods. Int. J. Forecast. 2020, 36, 167–177, M4 Competition. [Google Scholar] [CrossRef]
- Smyl, S. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 2020, 36, 75–85, M4 Competition. [Google Scholar] [CrossRef]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Mancuso, P.; Piccialli, V.; Sudoso, A.M. A machine learning approach for forecasting hierarchical time series. Expert Syst. Appl. 2021, 182, 115102. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V.; Semenoglou, A.A.; Mulder, G.; Nikolopoulos, K. Statistical, machine learning and deep learning forecasting methods: Comparisons and ways forward. J. Oper. Res. Soc. 2022, 0, 1–20. [Google Scholar] [CrossRef]
- Spiliotis, E.; Makridakis, S.; Kaltsounis, A.; Assimakopoulos, V. Product sales probabilistic forecasting: An empirical evaluation using the M5 competition data. Int. J. Prod. Econ. 2021, 240, 108237. [Google Scholar] [CrossRef]
- Spavound, S.; Kourentzes, N. Making Forecasts More Trustworthy. Foresight: Int. J. Appl. Forecast. 2022, 66, 21–25. [Google Scholar]
- Ghysels, E.; Osborn, D.R.; Sargent, T.J. The Econometric Analysis of Seasonal Time Series; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar] [CrossRef]
- Crone, S.F.; Kourentzes, N. Feature selection for time series prediction—A combined filter and wrapper approach for neural networks. Neurocomputing 2010, 73, 1923–1936. [Google Scholar] [CrossRef]
- Fildes, R.; Kolassa, S.; Ma, S. Post-script—Retail forecasting: Research and practice. Int. J. Forecast. 2021. [Google Scholar] [CrossRef] [PubMed]
- Gur Ali, O.; Sayın, S.; van Woensel, T.; Fransoo, J. SKU demand forecasting in the presence of promotions. Expert Syst. Appl. 2009, 36, 12340–12348. [Google Scholar] [CrossRef]
- Gur Ali, O.; Pinar, E. Multi-period-ahead forecasting with residual extrapolation and information sharing—Utilizing a multitude of retail series. Int. J. Forecast. 2016, 32, 502–517. [Google Scholar] [CrossRef]
- Huang, S.M.R.F.T. Demand forecasting with high dimensional data: The case of SKU retail sales forecasting with intra- and inter-category promotional information. Eur. J. Oper. Res. 2016, 249, 245–257. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Chen, Y.; Zhang, L. Exploring the influence of online reviews and motivating factors on sales: A meta-analytic study and the moderating role of product category. J. Retail. Consum. Serv. 2020, 55, 102107. [Google Scholar] [CrossRef]
- Fildes, S.M.R. A retail store SKU promotions optimization model for category multi-period profit maximization. Eur. J. Oper. Res. 2017, 260, 680–692. [Google Scholar] [CrossRef] [Green Version]
- Fildes, R.; Goodwin, P.; Lawrence, M.; Nikolopoulos, K. Effective forecasting and judgmental adjustments: An empirical evaluation and strategies for improvement in supply-chain planning. Int. J. Forecast. 2009, 25, 3–23. [Google Scholar] [CrossRef]
- Trapero, J.R.; Pedregal, D.J.; Fildes, R.; Kourentzes, N. Analysis of judgmental adjustments in the presence of promotions. Int. J. Forecast. 2013, 29, 234–243. [Google Scholar] [CrossRef] [Green Version]
- Sroginis, A.; Fildes, R.; Kourentzes, N. Use of Contextual and Model-Based Information in Behavioural Operations. Available SSRN 3466929. 2019. Available online: https://ssrn.com/abstract=3466929 (accessed on 6 December 2022). [CrossRef]
- Kourentzes, N.; Rostami-Tabar, B.; Barrow, D.K. Demand forecasting by temporal aggregation: Using optimal or multiple aggregation levels? J. Bus. Res. 2017, 78, 1–9. [Google Scholar] [CrossRef]
- Kourentzes, N.; Barrow, D.; Petropoulos, F. Another look at forecast selection and combination: Evidence from forecast pooling. Int. J. Prod. Econ. 2019, 209, 226–235. [Google Scholar] [CrossRef] [Green Version]
- Barrow, D.; Kourentzes, N.; Sandberg, R.; Niklewski, J. Automatic robust estimation for exponential smoothing: Perspectives from statistics and machine learning. Expert Syst. Appl. 2020, 160, 113637. [Google Scholar] [CrossRef]
- Soopramanien, T.H.R.F.D. The value of competitive information in forecasting FMCG retail product sales and the variable selection problem. Eur. J. Oper. Res. 2014, 237, 738–748. [Google Scholar] [CrossRef]
- Soopramanien, T.H.R.F.D. Forecasting retailer product sales in the presence of structural change. Eur. J. Oper. Res. 2019, 279, 459–470. [Google Scholar] [CrossRef]
- Rebelo, P.R.N.S.R. Performance of state space and ARIMA models for consumer retail sales forecasting. Robot. Comput.-Integr. Manuf. 2015, 34, 151–163. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, P.R.J.M. A procedure for identification of appropriate state space and ARIMA models based on time-series cross-validation. Algorithms 2016, 4, 76. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 1998. [Google Scholar] [CrossRef]
- Ahrens, N.S.A.D. A hybrid seasonal autoregressive integrated moving average and quantile regression for daily food sales forecasting. Int. J. Prod. Econ. 2015, 170, 321–335. [Google Scholar] [CrossRef]
- Wang, H.; Li, G.; Tsai, C.L. Regression coefficient and autoregressive order shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2007, 69, 63–78. [Google Scholar] [CrossRef]
- Fildes, R.; Petropoulos, F. Simple versus complex selection rules for forecasting many time series. J. Bus. Res. 2015, 68, 1692–1701. [Google Scholar] [CrossRef]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1989. [Google Scholar] [CrossRef]
- Barrow, D.; Kourentzes, N. The impact of special days in call arrivals forecasting: A neural network approach to modelling special days. Eur. J. Oper. Res. 2018, 264, 967–977. [Google Scholar] [CrossRef] [Green Version]
- Snyder, A.M.D.L.R.J.H.R.D. Forecasting time series with complex seasonal patterns using exponential smoothing. J. Am. Stat. Assoc. 2011, 106, 1513–1527. [Google Scholar] [CrossRef] [Green Version]
- Ord, J.K.; Fildes, R.; Kourentzes, N. Principles of Business Forecasting, 2nd ed.; Wessex Press Publishing Co.: London, UK, 2017. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015. [Google Scholar]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 26, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Koehler, A.B.; Snyder, R.D.; Grose, S. A state space framework for automatic forecasting using exponential smoothing methods. Int. J. Forecast. 2002, 18, 439–454. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2002. [Google Scholar] [CrossRef]
- Miller, D.M.; Williams, D. Shrinkage estimators of time series seasonal factors and their effect on forecasting accuracy. Int. J. Forecast. 2003, 19, 669–684. [Google Scholar] [CrossRef]
- Kourentzes, N.; Petropoulos, F.; Trapero, J.R. Improving forecasting by estimating time series structural components across multiple frequencies. Int. J. Forecast. 2014, 30, 291–302. [Google Scholar] [CrossRef] [Green Version]
- Hanssens, D.M.; Parsons, L.J.; Schultz, R.L. Market Response Models: Econometric and Time Series Analysis; International Series in Quantitative Marketing; Springer: New York, NY, USA, 2001; Volume 12. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Athanasopoulos, G.; Kourentzes, N. On the evaluation of hierarchical forecasts. Int. J. Forecast. 2022, in press. [Google Scholar] [CrossRef]
- Koning, A.J.; Franses, P.H.; Hibon, M.; Stekler, H. The M3 competition: Statistical tests of the results. Int. J. Forecast. 2005, 21, 397–409. [Google Scholar] [CrossRef]
- Hollander, M.; Wolfe, D.A.; Chicken, E. Nonparametric Statistical Methods; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Kourentzes, N. tsutils: Time Series Exploration, Modelling and Forecasting, R package version 0.9.2; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Svetunkov, I. Smooth: Forecasting Using Smoothing Functions, R package version 2.4.0; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Hyndman, R.; Athanasopoulos, G.; Bergmeir, C.; Caceres, G.; Chhay, L.; O’Hara-Wild, M.; Petropoulos, F.; Razbash, S.; Wang, E.; Yasmeen, F.; et al. Forecast: Forecasting Functions for Time Series and Linear Models, R package version 8.15; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Friedman, J.H.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. Artic. 2010, 33, 1–22. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seasonal Component | |||
|---|---|---|---|
| N | A | ||
| Slope Component | N | ||
| A | |||
| Ad | |||
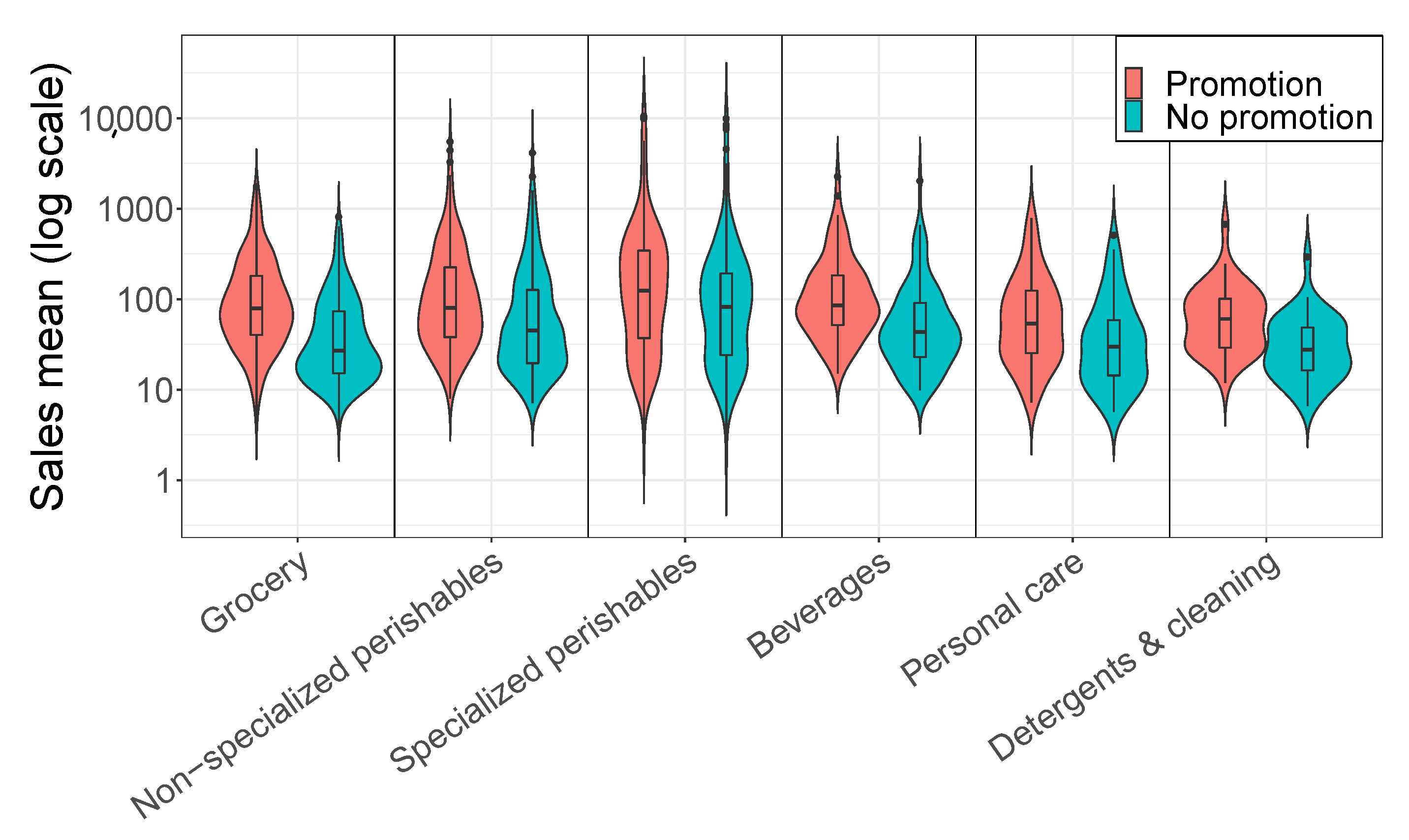
| Category | Promotion | No Promotion | No. of SKUs | ||||
|---|---|---|---|---|---|---|---|
| Mean | Median | Percentage | Mean | Median | |||
| Grocery | 162.3 | 79.0 | 4.9% | 63.0 | 27.1 | 309 | |
| Non-specialized perishables | 238.6 | 80.2 | 5.5% | 144.6 | 45.3 | 287 | |
| Specialized perishables | 492.6 | 124.1 | 11.1% | 342.0 | 81.9 | 193 | |
| Beverages | 179.7 | 84.9 | 8.8% | 99.4 | 43.3 | 103 | |
| Personal care | 107.3 | 53.5 | 4.9% | 61.6 | 29.8 | 59 | |
| Detergents & cleaning | 87.9 | 60.5 | 2.7% | 40.9 | 27.8 | 37 | |
| Model Name | Seasonality | Covariates | ||
|---|---|---|---|---|
| Usual | Trigonometric | Raw | PCA | |
| Univariate | ||||
| ES | ✓ | |||
| TBATS | ✓ | |||
| ARIMA | ✓ | |||
| RegARIMAF | ✓ | |||
| Ridge | ✓ | |||
| RidgeF | ✓ | |||
| With explanatories | ||||
| ESXPC | ✓ | ✓ | ||
| PCRegARIMA | ✓ | ✓ | ||
| PCRegARIMAF | ✓ | ✓ | ||
| RidgeX | ✓ | ✓ | ||
| RidgeFX | ✓ | ✓ | ||
| Model | 1–4 | 5–8 | 9–13 | 1–13 | ||
|---|---|---|---|---|---|---|
| MASE | ||||||
| RidgeX | 0.793 | 0.822 | 0.881 | 0.932 | 0.883 | |
| PCRegARIMAF | 0.795 | 0.833 | 0.883 | 0.929 | 0.886 | |
| PCRegARIMA | 0.804 | 0.834 | 0.894 | 0.942 | 0.894 | |
| RidgeFX | 0.792 | 0.827 | 0.898 | 0.960 | 0.900 | |
| ESXPC | 0.797 | 0.834 | 0.904 | 0.966 | 0.906 | |
| Ridge | 0.894 | 0.924 | 0.982 | 1.035 | 0.985 | |
| ARIMA | 0.908 | 0.936 | 0.992 | 1.040 | 0.993 | |
| RegARIMAF | 0.900 | 0.933 | 0.993 | 1.044 | 0.994 | |
| TBATS | 0.906 | 0.940 | 0.998 | 1.048 | 0.999 | |
| RidgeF | 0.896 | 0.933 | 1.009 | 1.079 | 1.012 | |
| ES | 0.904 | 0.944 | 1.018 | 1.081 | 1.019 | |
| RMSSE | ||||||
| RidgeX | 0.767 | 0.792 | 0.825 | 0.852 | 0.839 | |
| PCRegARIMAF | 0.767 | 0.820 | 0.830 | 0.850 | 0.854 | |
| PCRegARIMA | 0.770 | 0.799 | 0.836 | 0.856 | 0.847 | |
| RidgeFX | 0.762 | 0.788 | 0.822 | 0.854 | 0.837 | |
| ESXPC | 0.764 | 0.804 | 0.844 | 0.872 | 0.858 | |
| Ridge | 0.883 | 0.910 | 0.941 | 0.966 | 0.955 | |
| ARIMA | 0.895 | 0.922 | 0.957 | 0.980 | 0.970 | |
| RegARIMAF | 0.886 | 0.915 | 0.947 | 0.969 | 0.960 | |
| TBATS | 0.888 | 0.918 | 0.950 | 0.976 | 0.964 | |
| RidgeF | 0.876 | 0.905 | 0.945 | 0.981 | 0.961 | |
| ES | 0.894 | 0.929 | 0.975 | 1.006 | 0.988 | |
| Model | Promotion | No Promotion | ||
|---|---|---|---|---|
| MASE | RMSSE | MASE | RMSSE | |
| RidgeX | 3.148 | 2.096 | 0.742 | 0.632 |
| PCRegARIMAF | 2.947 | 2.031 | 0.754 | 0.652 |
| PCRegARIMA | 2.865 | 1.937 | 0.762 | 0.658 |
| RidgeFX | 3.011 | 2.006 | 0.763 | 0.638 |
| ESXPC | 2.924 | 1.982 | 0.772 | 0.666 |
| Ridge | 4.181 | 2.667 | 0.762 | 0.640 |
| ARIMA | 4.191 | 2.683 | 0.774 | 0.661 |
| RegARIMAF | 4.173 | 2.665 | 0.776 | 0.651 |
| TBATS | 4.174 | 2.667 | 0.782 | 0.659 |
| RidgeF | 4.091 | 2.606 | 0.797 | 0.657 |
| ES | 4.257 | 2.726 | 0.798 | 0.677 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramos, P.; Oliveira, J.M.; Kourentzes, N.; Fildes, R. Forecasting Seasonal Sales with Many Drivers: Shrinkage or Dimensionality Reduction? Appl. Syst. Innov. 2023, 6, 3. https://doi.org/10.3390/asi6010003
Ramos P, Oliveira JM, Kourentzes N, Fildes R. Forecasting Seasonal Sales with Many Drivers: Shrinkage or Dimensionality Reduction? Applied System Innovation. 2023; 6(1):3. https://doi.org/10.3390/asi6010003
Chicago/Turabian StyleRamos, Patrícia, José Manuel Oliveira, Nikolaos Kourentzes, and Robert Fildes. 2023. "Forecasting Seasonal Sales with Many Drivers: Shrinkage or Dimensionality Reduction?" Applied System Innovation 6, no. 1: 3. https://doi.org/10.3390/asi6010003
APA StyleRamos, P., Oliveira, J. M., Kourentzes, N., & Fildes, R. (2023). Forecasting Seasonal Sales with Many Drivers: Shrinkage or Dimensionality Reduction? Applied System Innovation, 6(1), 3. https://doi.org/10.3390/asi6010003