
Attention-Based Wildland Fire Spread Modeling Using Fire-Tracking Satellite Observations

 , ,
, , 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Observation-Based Model Inputs
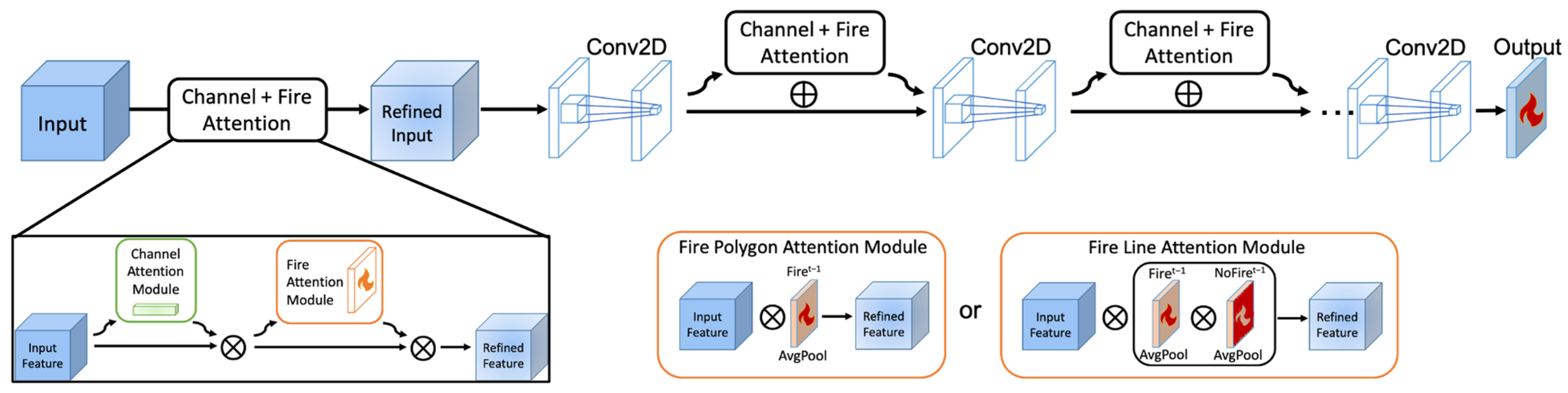
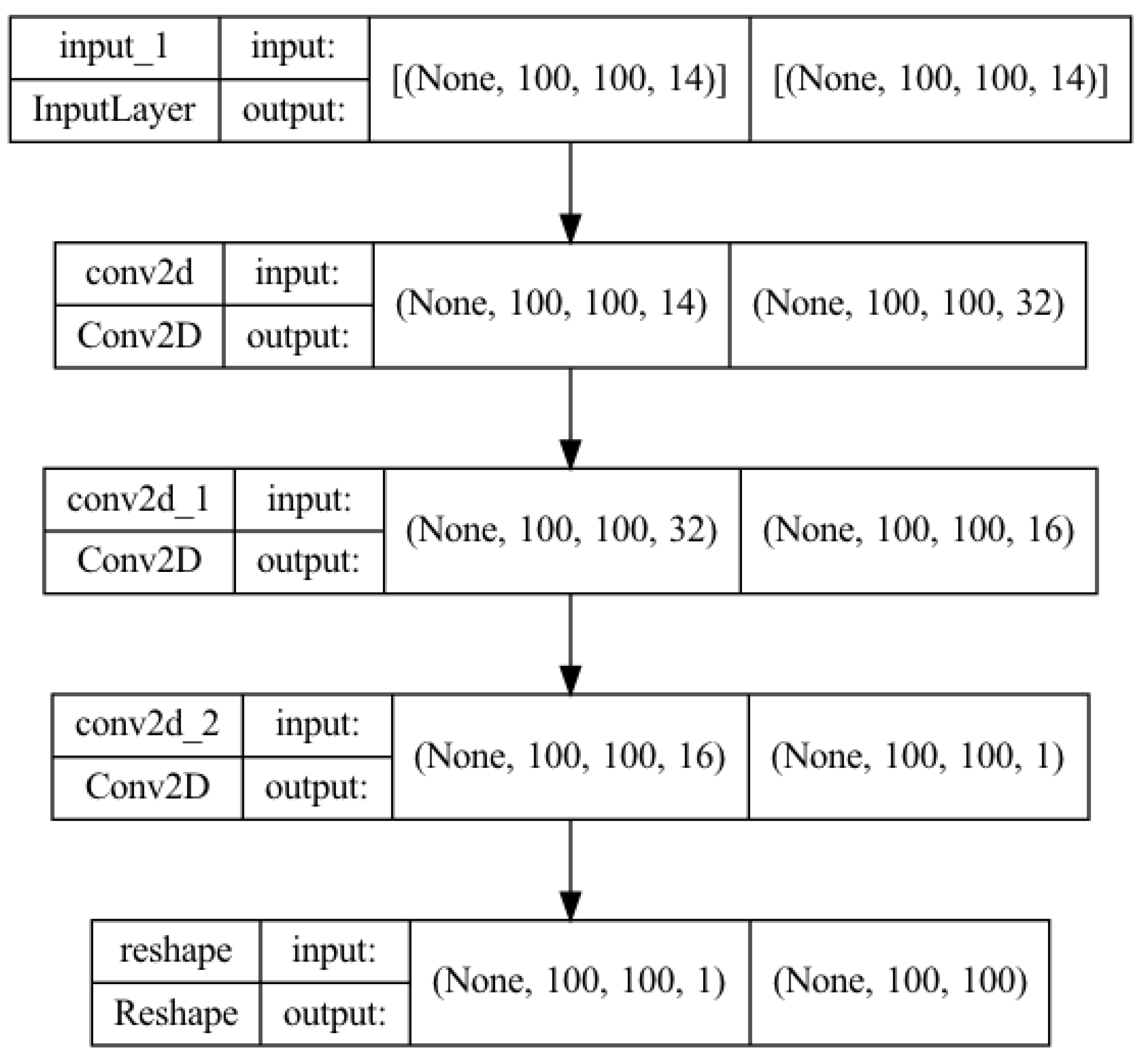
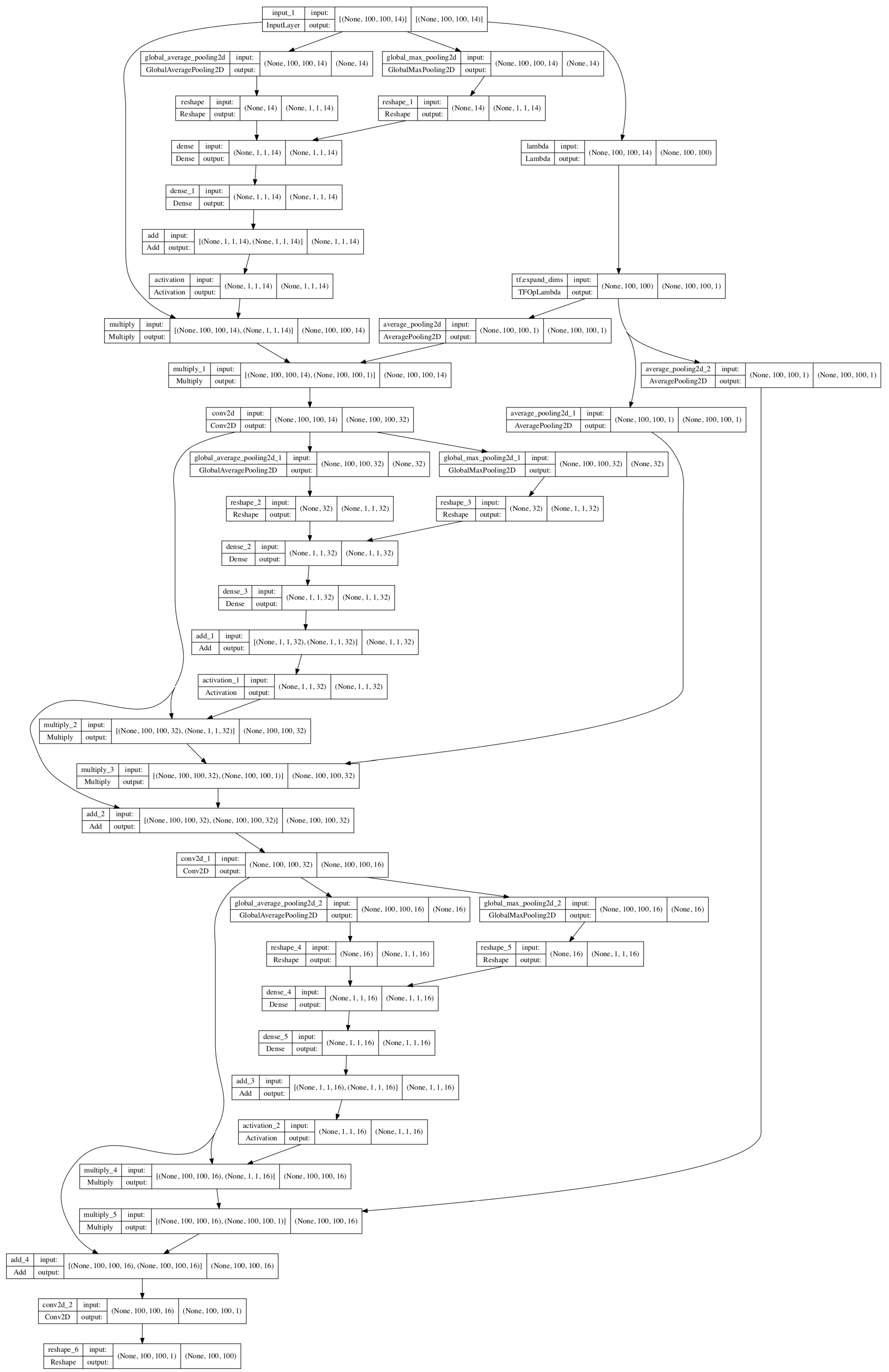
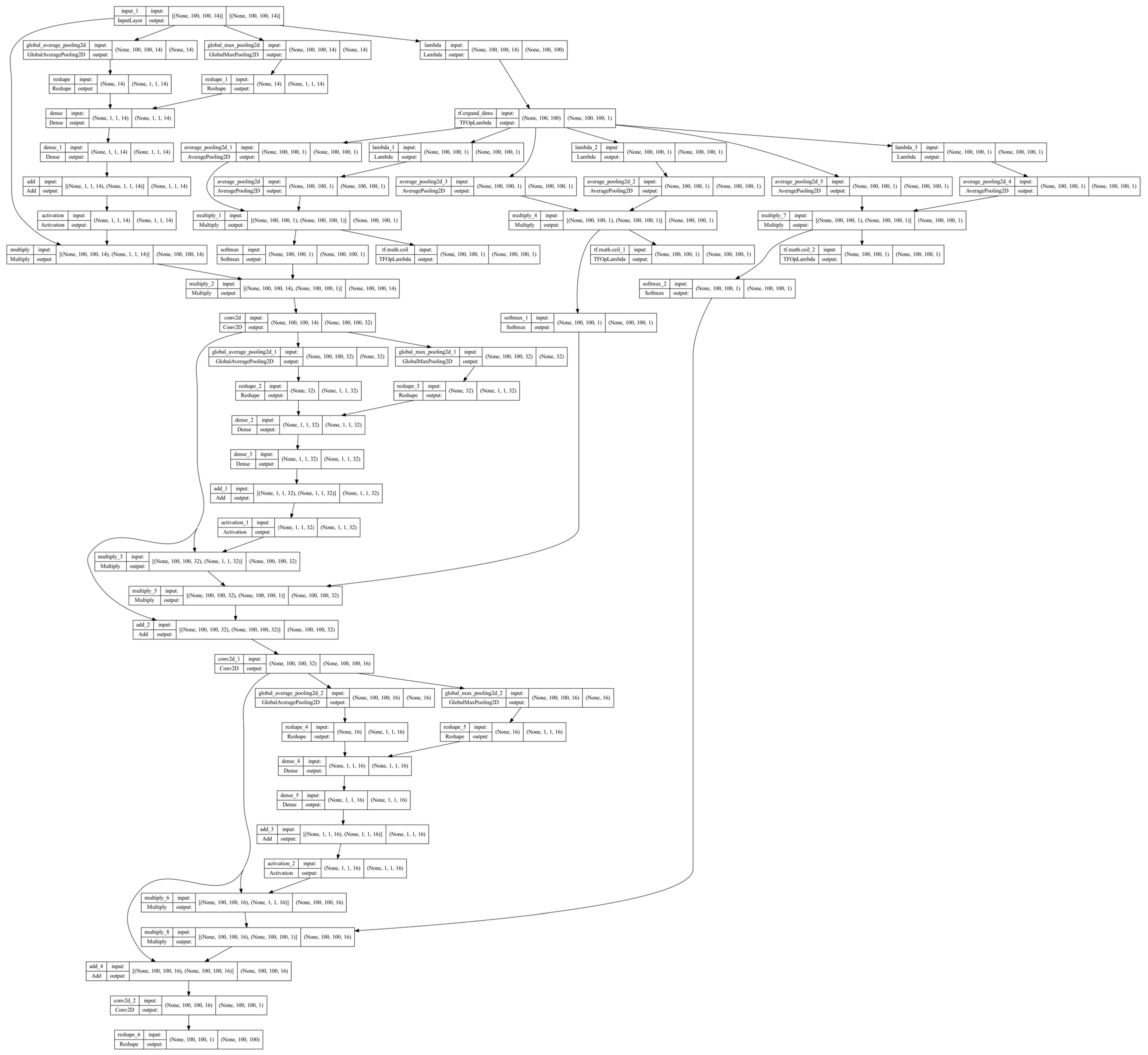
2.2. Model Architectures
2.3. Model Training, Validation, and Testing Methods
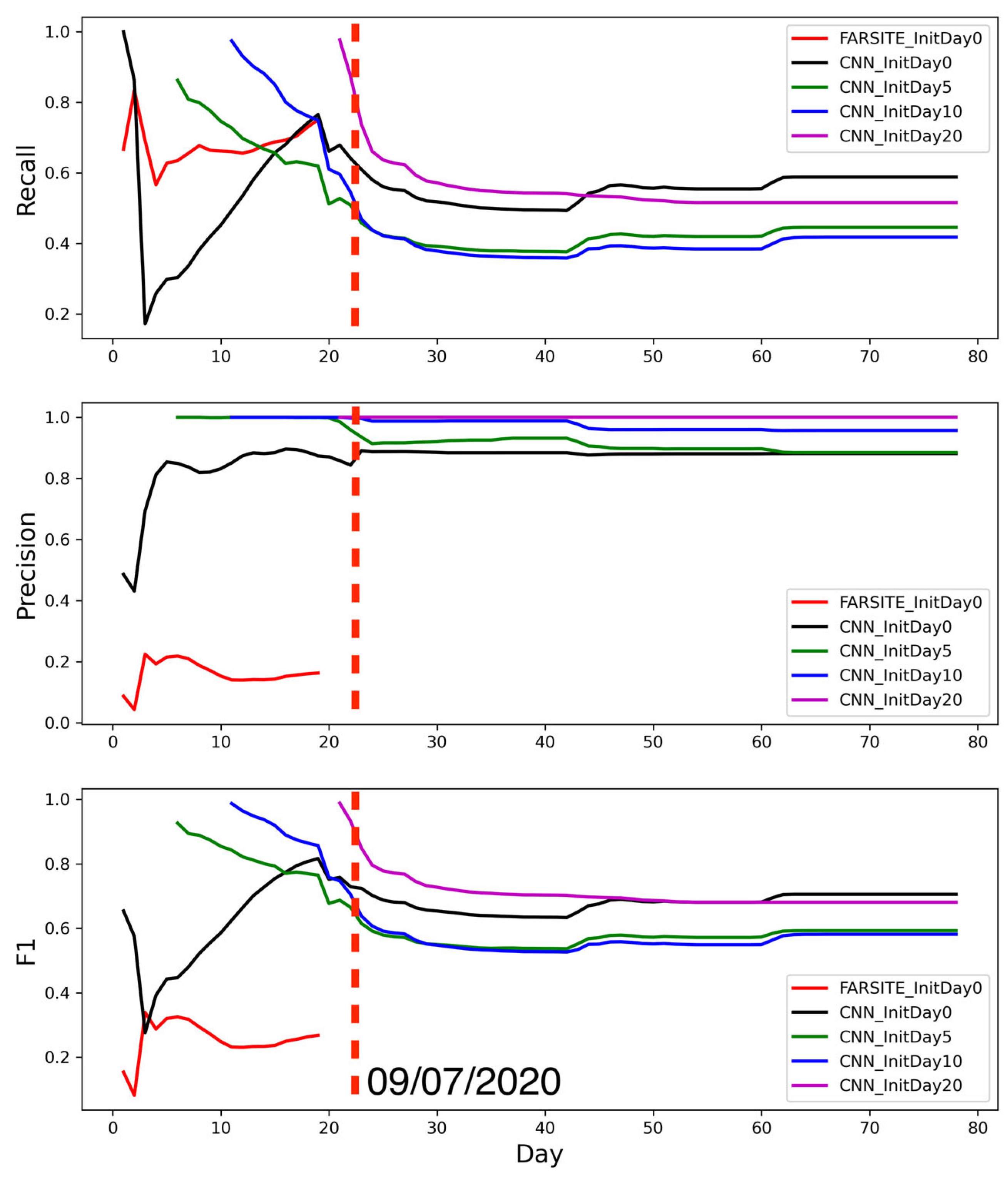
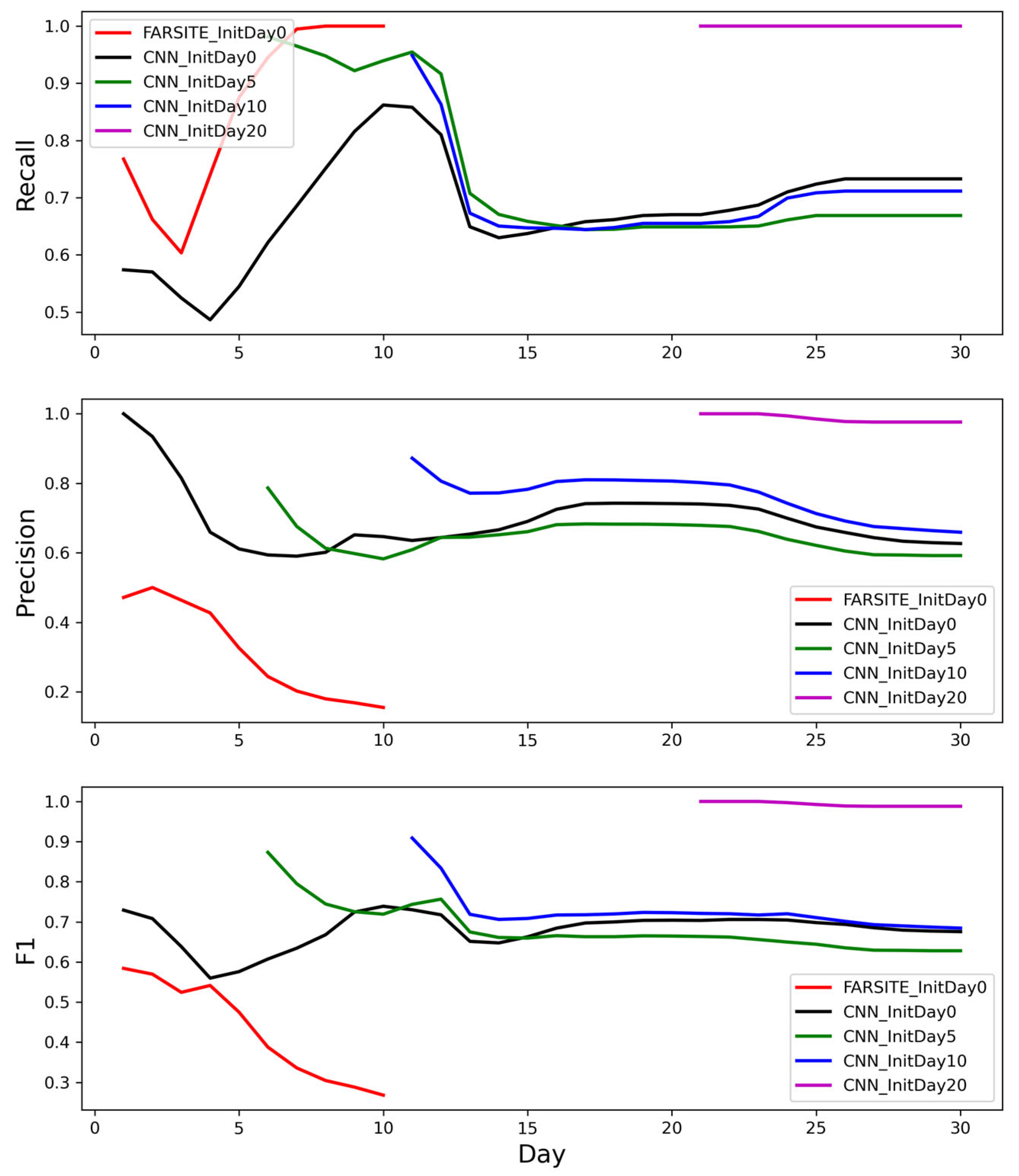
3. Results
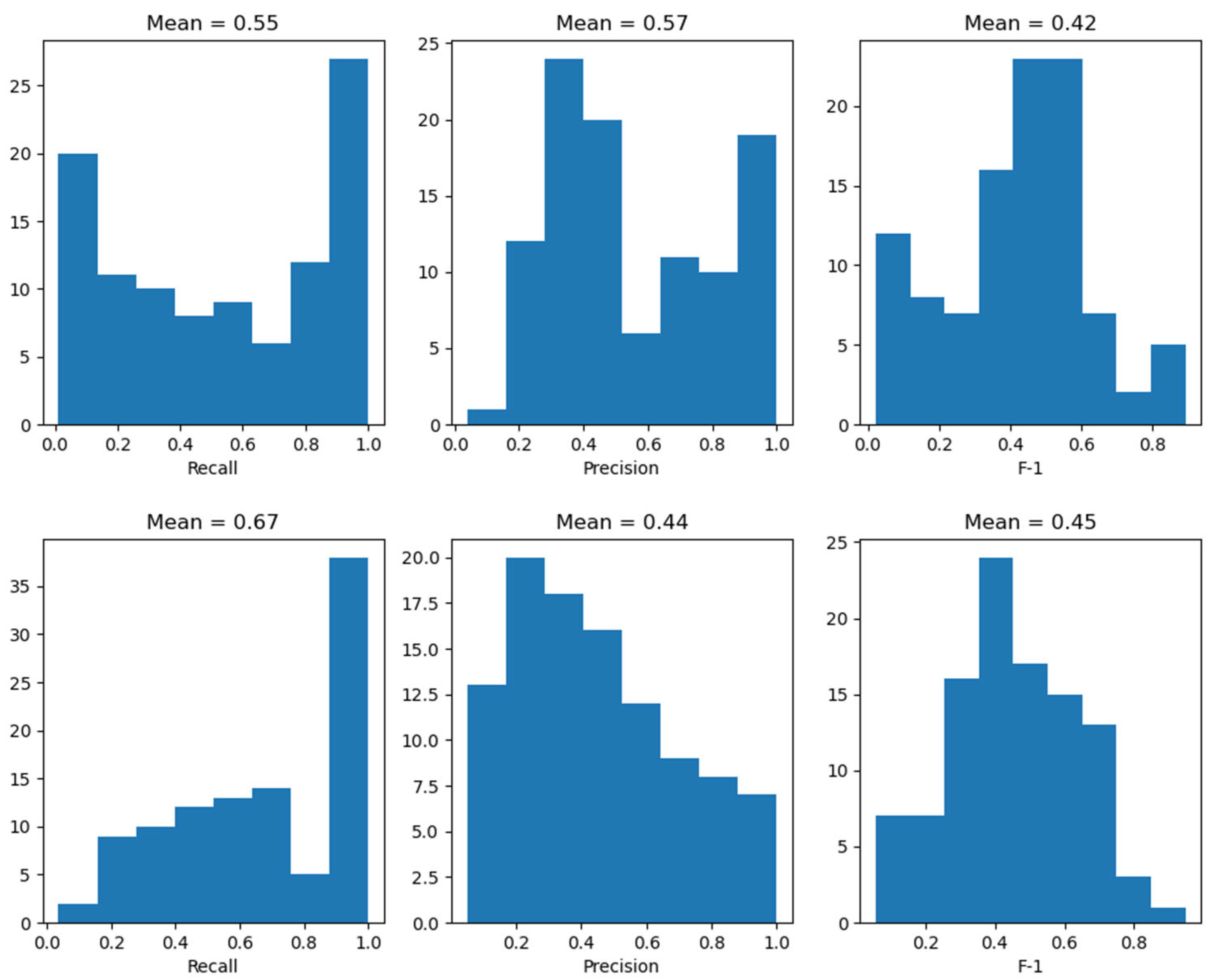
3.1. Metric Scores of Fire Spread Models
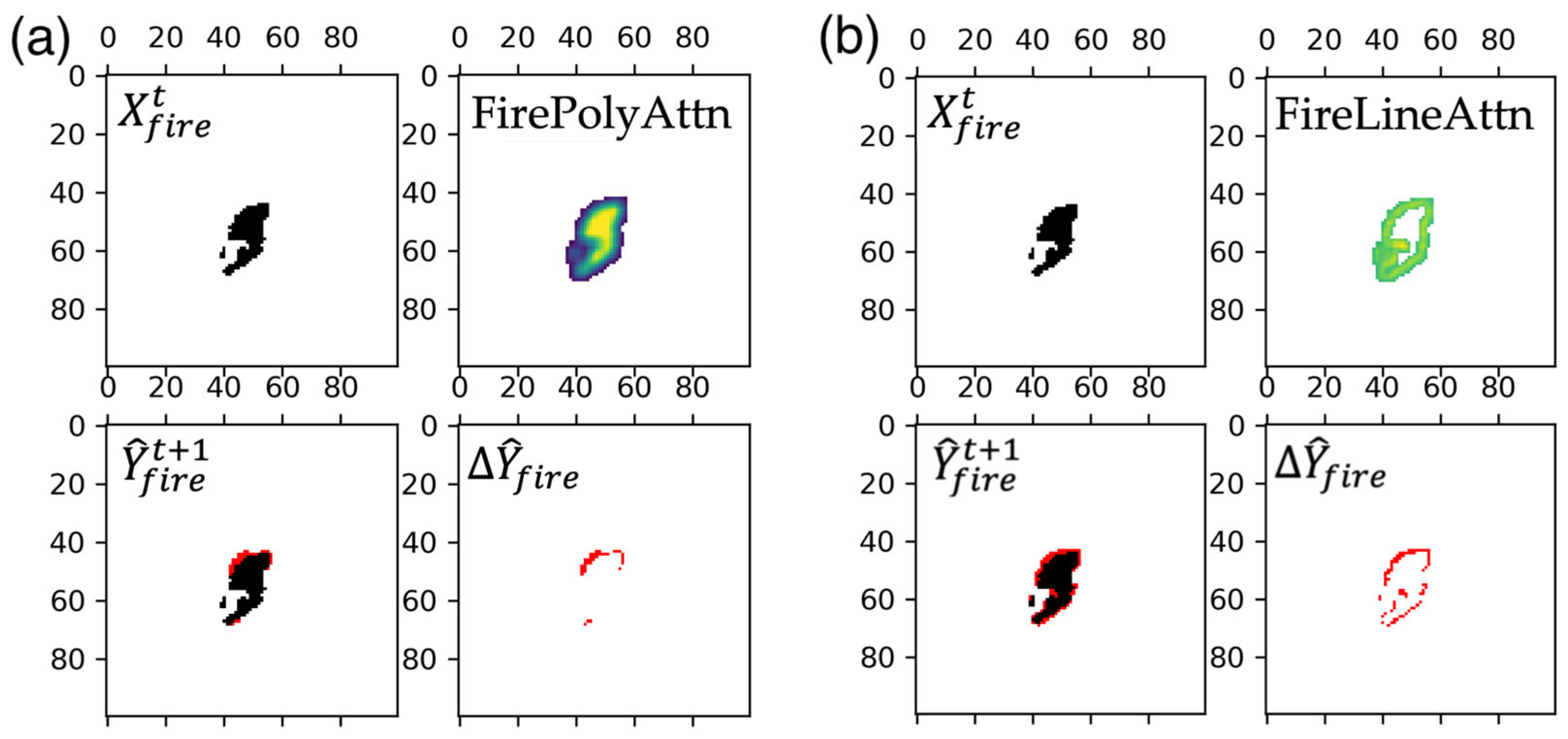
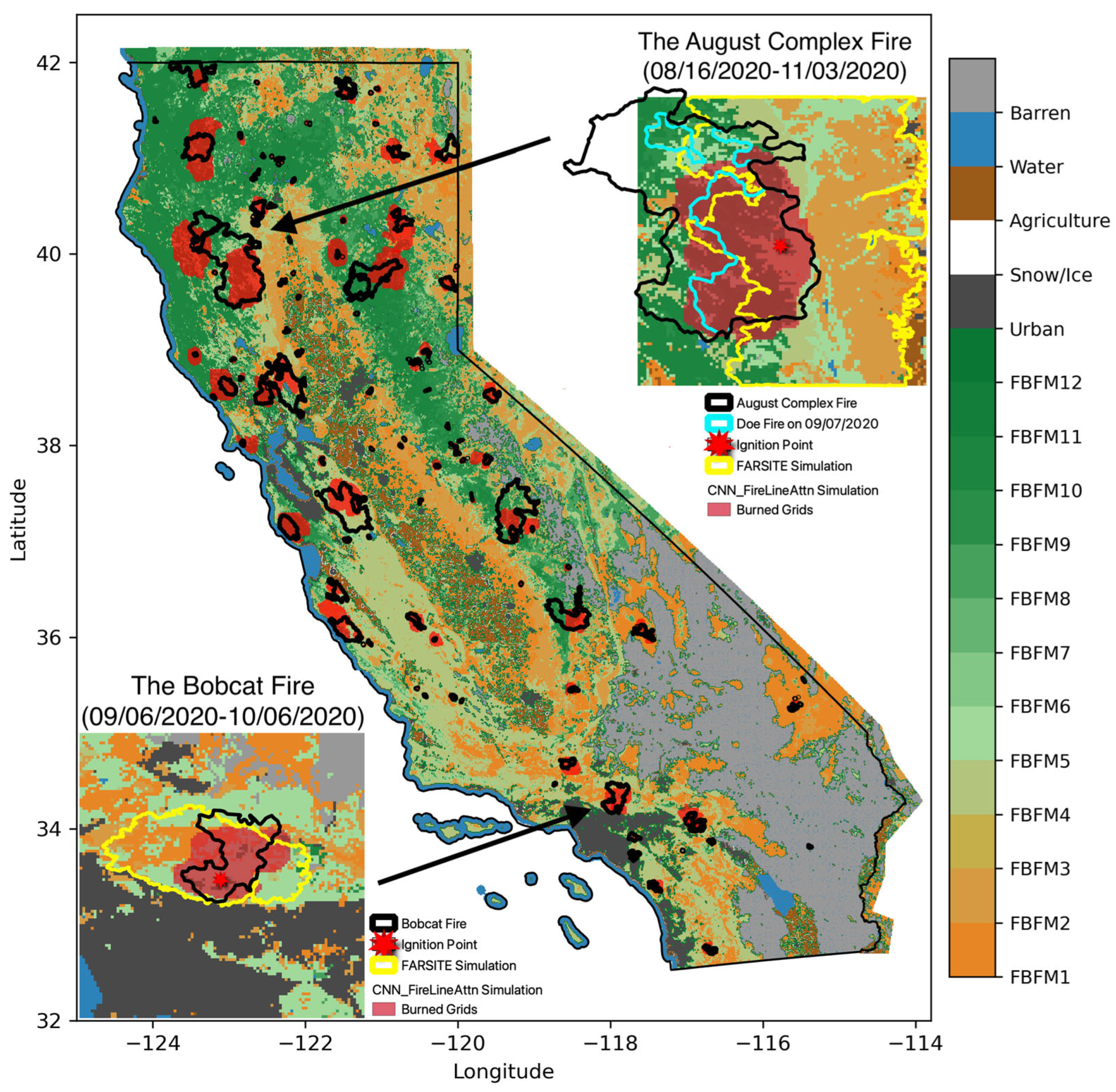
3.2. Spatial Distributions and Temporal Variations in Fire Simulations
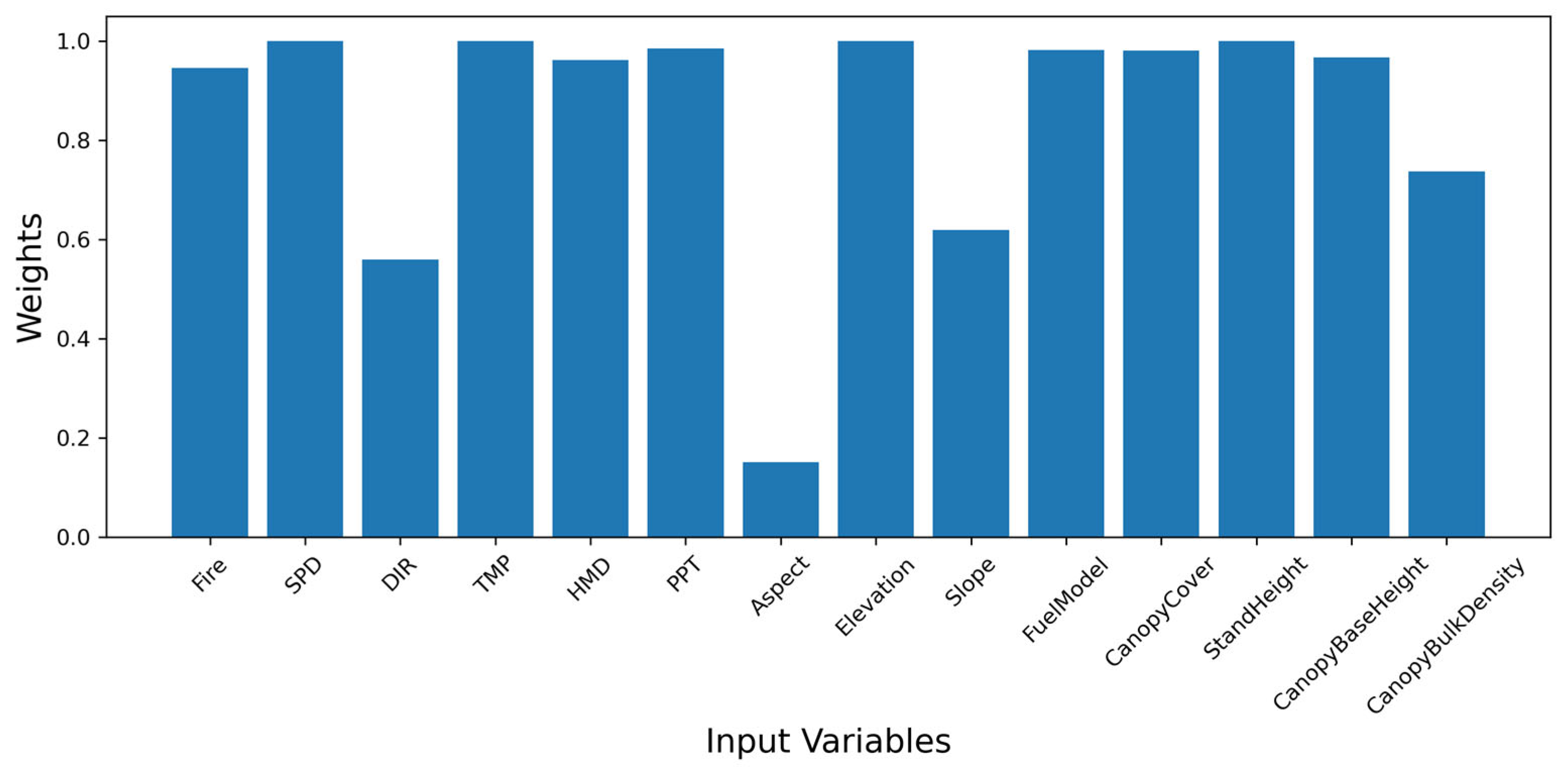
3.3. Feature Importance of Fire Simulations
4. Discussion
- (1)
- Increasing the sample size and resolution for model training and testing. Currently, there are 735 fires from 2012 to 2020 available for model training and evaluation. Although this dataset can be augmented by data rotation, more training samples at higher spatiotemporal resolutions across more diversified landscapes and fire regimes could benefit the improvement of modeling performance, as we saw in the experiments of this study. Meanwhile, the data quality of the corresponding fuel, terrain, and weather conditions influencing fire spread should also be improved to provide sufficient information for models to learn complex fire behavior.
- (2)
- Adding new features as model inputs to take into account human effects on fire control and suppression. The model inputs considered in this study are natural factors representing terrain, fuel, and weather conditions. However, human activity and land segmentation such as road and stream networks can also affect fire spread in multiple ways. The human suppression effect is particularly significant in WUI areas given the high prioritization of protecting people via firefighting activities. Currently, such a suppression effect is implicitly learned by the model from observed fire progression. More explicit model input features associated with human effects might further improve the modeling capability in this regard.
- (3)
- Refining the model architectures with improved model interpretability. The current attention modules, especially the fire line attention module, enable the model to focus on actively burning areas that are critical for fire spread. This learning approach is also consistent with actual burning processes guided by the laws of combustion chemistry and physics. Further refinement can be informed by a more comprehensive consideration of nonlinear physical fire progression processes in the model to improve modeling performance and interpretability simultaneously.
- (4)
- Integrating the model with other complementary models, such as fire ignition [37], duration, and vulnerability models, for comprehensive fire risk assessment. Recognizing that fire spread is part of the entire burning process, it is essential to incorporate this model into a broader modeling framework to simulate complete fire events, encompassing all burning processes from ignition to burnout. This integrated modeling approach allows for scenario analysis in short-term fire spread prediction and fire risk assessment at broader spatiotemporal scales, such as generating large numbers of simulated fire events using Monte Carlo approaches and estimating fire losses with a consideration for spatially heterogeneous vulnerability. Given the scarcity of extreme fire events in observed history, this capability to model catastrophic extreme events is particularly beneficial for tail risk analysis in the insurance industry.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Truth | Prediction False | |
|---|---|---|
| Ground truth | TP | FN |
| Ground false | FP | TN |
| Metrics | Model Parameters | Next-Step Prediction | Recursive Prediction | ||||
|---|---|---|---|---|---|---|---|
| Model Name | Recall | Precision | F-1 | Recall | Precision | F-1 | |
| Autoencoder | 5.5M | 0.68 | 0.72 | 0.65 | 0.38 | 0.74 | 0.40 |
| CNN_NonAttn | 8.8k | 0.67 | 1.0 | 0.71 | 0.08 | 0.98 | 0.13 |
| CNN_FirePolyAttn | 12k | 0.84 | 0.86 | 0.81 | 0.49 | 0.67 | 0.43 |
| CNN_FireLineAttn | 12k | 0.90 | 0.69 | 0.71 | 0.63 | 0.51 | 0.41 |
| CNN_FirePolyAttn_R * | 12k | 0.82 | 0.87 | 0.81 | 0.45 | 0.71 | 0.43 |
| CNN_FireLineAttn_R * | 12k | 0.88 | 0.71 | 0.74 | 0.70 | 0.46 | 0.47 |
References
- Dennison, P.E.; Brewer, S.C.; Arnold, J.D.; Moritz, M.A. Large wildfire trends in the western United States, 1984–2011. Geophys. Res. Lett. 2014, 41, 2928–2933. [Google Scholar] [CrossRef]
- Iglesias, V.; Balch, J.K.; Travis, W.R. US fires became larger, more frequent, and more widespread in the 2000s. Sci. Adv. 2022, 8, eabc0020. [Google Scholar] [CrossRef]
- Strader, S.M. Spatiotemporal changes in conterminous US wildfire exposure from 1940 to 2010. Nat. Hazards 2018, 92, 543–565. [Google Scholar] [CrossRef]
- Burke, M.; Driscoll, A.; Heft-Neal, S.; Xue, J.; Burney, J.; Wara, M. The changing risk and burden of wildfire in the United States. Proc. Natl. Acad. Sci. USA 2021, 118, e2011048118. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, Y.; Fu, R.; Santer, B.D.; Dickinson, R.E.; Hall, A. Quantifying contributions of natural variability and anthropogenic forcings on increased fire weather risk over the western United States. Proc. Natl. Acad. Sci. USA 2021, 118, e2111875118. [Google Scholar] [CrossRef] [PubMed]
- Westerling, A.L.; Hidalgo, H.G.; Cayan, D.R.; Swetnam, T.W. Warming and earlier spring increase western US forest wildfire activity. Science 2006, 313, 940–943. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abatzoglou, J.T.; Williams, A.P. Impact of anthropogenic climate change on wildfire across western US forests. Proc. Natl. Acad. Sci. USA 2016, 113, 11770–11775. [Google Scholar] [CrossRef] [Green Version]
- Williams, A.P.; Abatzoglou, J.T.; Gershunov, A.; Guzman-Morales, J.; Bishop, D.A.; Balch, J.K.; Lettenmaier, D.P. Observed impacts of anthropogenic climate change on wildfire in California. Earth’s Future 2019, 7, 892–910. [Google Scholar] [CrossRef] [Green Version]
- Balch, J.K.; Bradley, B.A.; Abatzoglou, J.T.; Nagy, R.C.; Fusco, E.J.; Mahood, A.L. Human-started wildfires expand the fire niche across the United States. Proc. Natl. Acad. Sci. USA 2017, 114, 2946–2951. [Google Scholar] [CrossRef]
- Radeloff, V.C.; Helmers, D.P.; Kramer, H.A.; Mockrin, M.H.; Alexandre, P.M.; Bar-Massada, A.; Butsic, V.; Hawbaker, T.J.; Martinuzzi, S.; Syphard, A.D. Rapid growth of the US wildland-urban interface raises wildfire risk. Proc. Natl. Acad. Sci. USA 2018, 115, 3314–3319. [Google Scholar] [CrossRef] [Green Version]
- Busenberg, G. Wildfire management in the United States: The evolution of a policy failure. Rev. Policy Res. 2004, 21, 145–156. [Google Scholar] [CrossRef]
- Moritz, M.A.; Batllori, E.; Bradstock, R.A.; Gill, A.M.; Handmer, J.; Hessburg, P.F.; Leonard, J.; McCaffrey, S.; Odion, D.C.; Schoennagel, T.; et al. Learning to coexist with wildfire. Nature 2014, 515, 58–66. [Google Scholar] [CrossRef] [PubMed]
- Sullivan, A.L. Wildland surface fire spread modelling, 1990–2007. 1: Physical and quasi-physical models. Int. J. Wildland Fire 2009, 18, 349–368. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, A.L. Wildland surface fire spread modelling, 1990–2007. 2: Empirical and quasi-empirical models. Int. J. Wildland Fire 2009, 18, 369–386. [Google Scholar] [CrossRef] [Green Version]
- Finney, M.A. FARSITE, Fire Area Simulator—Model Development and Evaluation; Research Paper RMRS-RP-4; US Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 1998.
- Finney, M.A. An Overview of FlamMap Fire Modeling Capabilities. In Fuels Management—How to Measure Success: Conference Proceedings; Andrews, P.L., Butler, B.W., Eds.; U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2006; pp. 213–220. [Google Scholar]
- Li, F.; Levis, S.; Ward, D.S. Quantifying the role of fire in the Earth system—Part 1: Improved global fire modeling in the Community Earth System Model (CESM1). Biogeosciences 2013, 10, 2293–2314. [Google Scholar] [CrossRef] [Green Version]
- Lautenberger, C. Wildland fire modeling with an Eulerian level set method and automated calibration. Fire Saf. J. 2013, 62, 289–298. [Google Scholar] [CrossRef]
- Mandel, J.; Beezley, J.D.; Kochanski, A.K. Coupled atmosphere-wildland fire modeling with WRF 3.3 and SFIRE 2011. Geosci. Model Dev. 2011, 4, 591–610. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W.L.; Wang, F.; Fang, L.; Zheng, X.; Qiao, X.; Li, Z.; Meng, Q. Modelling of wildland-urban interface fire spread with the heterogeneous cellular automata model. Environ. Model. Softw. 2021, 135, 104895. [Google Scholar] [CrossRef]
- Hodges, J.L.; Lattimer, B.Y. Wildland fire spread modeling using convolutional neural networks. Fire Technol. 2019, 55, 2115–2142. [Google Scholar] [CrossRef]
- Radke, D.; Hessler, A.; Ellsworth, D. FireCast: Leveraging Deep Learning to Predict Wildfire Spread. In Proceedings of the IJCAI 2019, Macao, China, 10–16 August 2019. [Google Scholar]
- Khennou, F.; Ghaoui, J.; Akhloufi, M.A. Forest fire spread prediction using deep learning. In Proceedings of the Geospatial Informatics XI, Online, 12–17 April 2021; p. 11733. [Google Scholar]
- Huot, F.L.; Hu, R.L.L.; Ihme, M.; Wang, Q.; Burge, J.; Lu, T.; Hickey, J.; Chen, Y.F.; Anderson, J. Deep learning models for predicting wildfires from historical remote-sensing data. arXiv 2021, arXiv:2010.07445v3. [Google Scholar]
- Chen, Y.; Hantson, S.; Andela, N.; Coffield, S.R.; Graff, C.A.; Morton, D.C.; Ott, L.E.; Foufoula-Georgiou, E.; Smyth, P.; Goulden, M.L.; et al. California wildfire spread derived using VIIRS satellite observations and an object-based tracking system. Sci. Data 2022, 9, 249. [Google Scholar] [CrossRef] [PubMed]
- LANDFIRE Topographic Products. Available online: https://landfire.gov/topographic.php (accessed on 10 March 2022).
- LANDFIRE Fuel Products. Available online: https://landfire.gov/fuel.php (accessed on 10 March 2022).
- Hashimoto, H.; Wang, W.; Melton, F.S.; Moreno, A.L.; Ganguly, S.; Michaelis, A.R.; Nemani, R.R. High-resolution mapping of daily climate variables by aggregating multiple spatial data sets with the random forest algorithm over the conterminous United States. Int. J. Climatol. 2019, 39, 2964–2983. [Google Scholar] [CrossRef]
- NASA GeoNEX Data Portal. Available online: https://data.nas.nasa.gov/geonex/geonexdata/NEX-GDM/ (accessed on 10 March 2022).
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 Hourly Data on Single Levels from 1940 to Present. Copernicus Climate Change Service (C3S) Climate Data Store (CDS). 2023. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=overview (accessed on 10 March 2022).
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. (CSUR) 2016, 49, 1–50. [Google Scholar] [CrossRef] [Green Version]
- Abraham, N.; Khan, N.M. A novel focal tversky loss function with improved attention u-net for lesion segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019. [Google Scholar]
- Safford, H.D.; Paulson, A.K.; Steel, Z.L.; Young, D.J.; Wayman, R.B. The 2020 California fire season: A year like no other, a return to the past or a harbinger of the future? Glob. Ecol. Biogeogr. 2022, 31, 2005–2025. [Google Scholar] [CrossRef]
- August Complex Fire. Available online: https://en.wikipedia.org/wiki/August_Complex_fire (accessed on 24 January 2023).
- Bobcat Fire. Available online: https://en.wikipedia.org/wiki/Bobcat_Fire (accessed on 24 January 2023).
- Liu, Y.; Le, S.; Zou, Y.; Sadgedhi, M.; Chen, Y.; Andela, N.; Gentine, P. A Simplified Machine Learning Based Wildfire Ignition Model from Insurance Perspective. In ICLR 2023 Workshop on Tackling Climate Change with Machine Learning. 2023. Available online: https://www.climatechange.ai/papers/iclr2023/23 (accessed on 20 June 2023).








| Metrics | Model Parameters | Next-Step Prediction | Recursive Prediction | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model Name | Recall | Precision | F-1 | PR-AUC | Recall | Precision | F-1 | PR-AUC | ||
| Persistent model | 0 | 0.79 | 1.0 | 0.82 | N/A ** | 0.04 | 1.0 | 0.08 | N/A ** | |
| Autoencoder | 5.5 M | 0.71 | 0.74 | 0.69 | 0.60 | 0.31 | 0.76 | 0.38 | 0.06 | |
| CNN_NonAttn | 8.8 k | 0.79 | 1.0 | 0.82 | 0.98 | 0.04 | 0.99 | 0.08 | 0.03 | |
| CNN_FirePolyAttn | 12 k | 0.88 | 0.93 | 0.89 | 0.98 | 0.40 | 0.72 | 0.41 | 0.07 | |
| CNN_FireLineAttn | 12 k | 0.91 | 0.81 | 0.83 | 0.95 | 0.55 | 0.57 | 0.42 | 0.08 | |
| CNN_FirePolyAttn_R * | 12 k | 0.87 | 0.93 | 0.89 | 0.98 | 0.35 | 0.76 | 0.39 | 0.06 | |
| CNN_FireLineAttn_R * | 12 k | 0.90 | 0.79 | 0.82 | 0.92 | 0.67 | 0.44 | 0.45 | 0.24 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, Y.; Sadeghi, M.; Liu, Y.; Puchko, A.; Le, S.; Chen, Y.; Andela, N.; Gentine, P. Attention-Based Wildland Fire Spread Modeling Using Fire-Tracking Satellite Observations. Fire 2023, 6, 289. https://doi.org/10.3390/fire6080289
Zou Y, Sadeghi M, Liu Y, Puchko A, Le S, Chen Y, Andela N, Gentine P. Attention-Based Wildland Fire Spread Modeling Using Fire-Tracking Satellite Observations. Fire. 2023; 6(8):289. https://doi.org/10.3390/fire6080289
Chicago/Turabian StyleZou, Yufei, Mojtaba Sadeghi, Yaling Liu, Alexandra Puchko, Son Le, Yang Chen, Niels Andela, and Pierre Gentine. 2023. "Attention-Based Wildland Fire Spread Modeling Using Fire-Tracking Satellite Observations" Fire 6, no. 8: 289. https://doi.org/10.3390/fire6080289
APA StyleZou, Y., Sadeghi, M., Liu, Y., Puchko, A., Le, S., Chen, Y., Andela, N., & Gentine, P. (2023). Attention-Based Wildland Fire Spread Modeling Using Fire-Tracking Satellite Observations. Fire, 6(8), 289. https://doi.org/10.3390/fire6080289