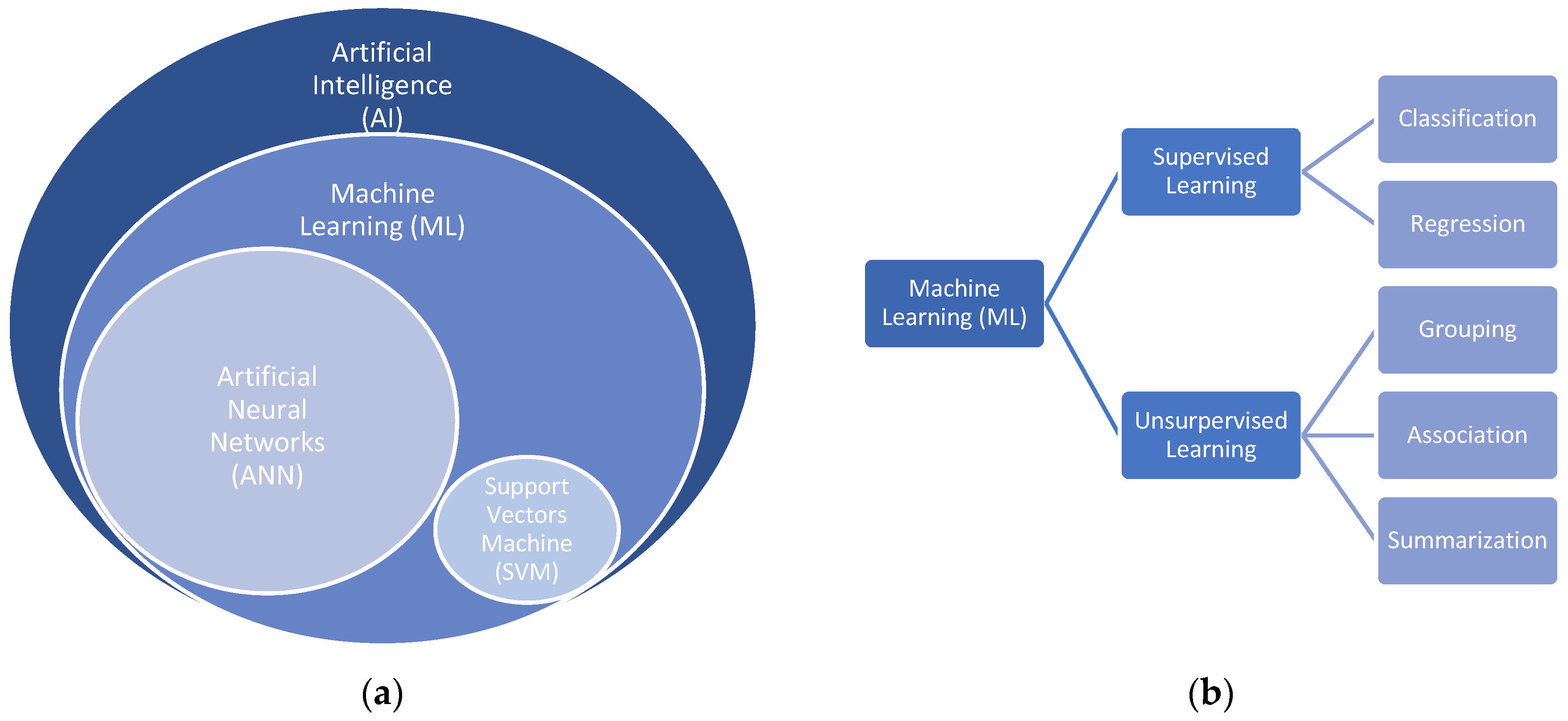
The dataset defined before was used to train a model that aimed to predict the correct outputs based on the inputs. The prediction model was composed of the training data and a learning algorithm (ANN or SVM) that would be used to emulate the physical system. The development of the intelligent prediction model involved different tasks, with different levels of complexity. Following, a brief resume of the most significant aspects is presented. The topics are numbered, allowing a clear interpretation of the development procedure of the prediction model.
4.2.1. Input Variables Definition
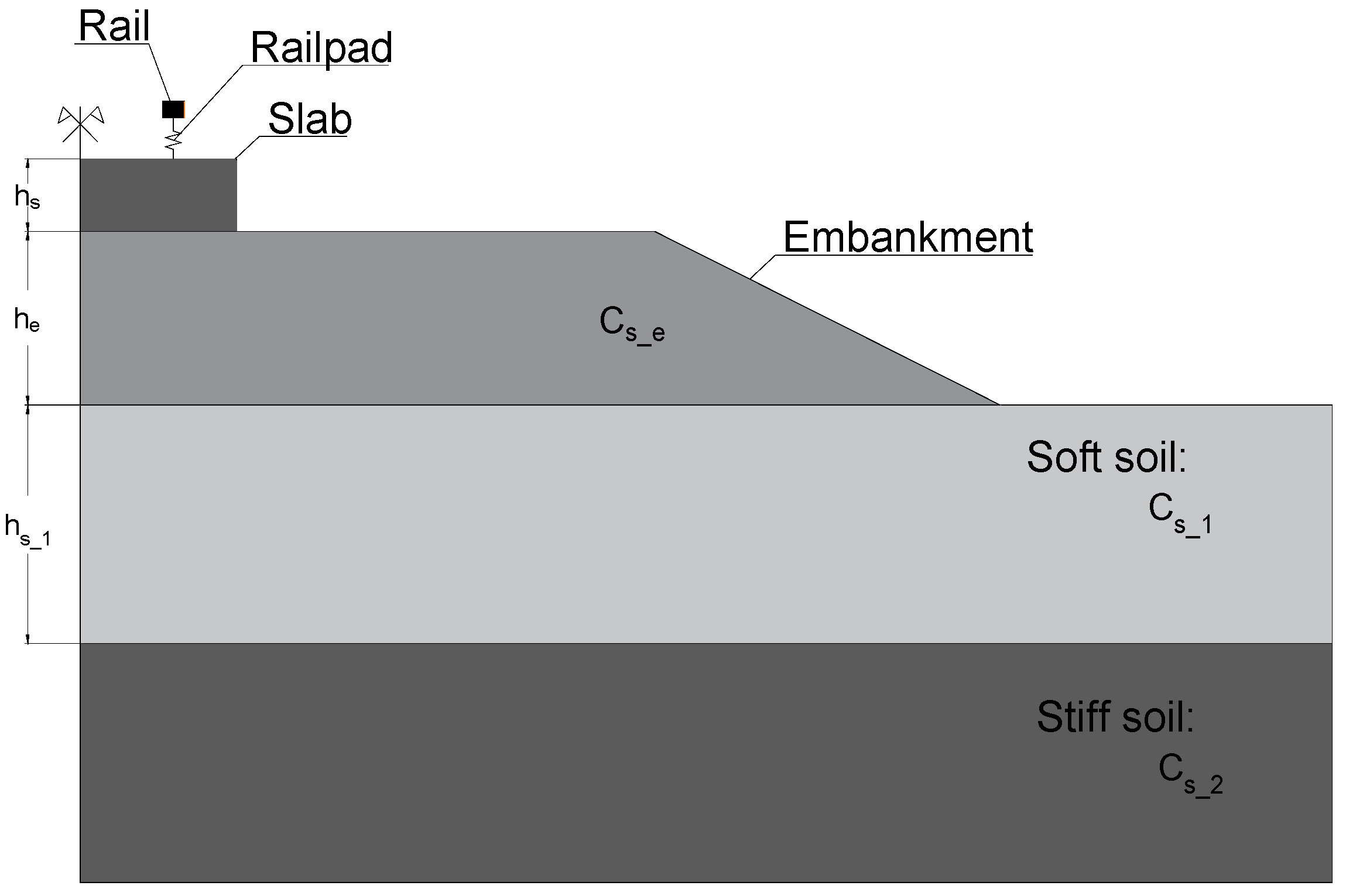
The selection of the input variables was a common task of the different learning algorithms and their underlying engineering considerations in order to identify the most influential parameters in the critical speed of railway tracks. According to the previous information, a total of six input variables were defined, involving properties of the track, embankment and ground:
Track: slab thickness, hslab (m);
Embankment: embankment thickness, hembankment (m) and stiffness (Young modulus), Eembankment (MPa);
Ground: first layer, shear wave velocity CS,1 (m/s) and thickness h1 (m); half-space: shear wave velocity CS,inf (m/s).
Regarding the neural networks, data normalization (or scaling) was an essential process, allowing to improve the backpropagation dynamics and, consequently, the optimization procedure. In this way, all the input variables, and correspondent output, were normalized in the interval between 0 and 1.
4.2.2. Parameters
The global behavior of ANN is determined by how its individual elements are connected and by the strength, or weights, assigned to those connections. These weights are automatically adjusted during the training process, following a specified learning rule until the neural network performs the desired task correctly. The learning process is a kind of spontaneous weight change. The number of neurons and hidden layers is essential for the performance of the neural network. Based on the dataset specificities, different combinations can lead to different results. Thus, it is essential to perform a sensibility study in order to identify an adequate combination. As the ANN model performance can only be evaluated after the training phase, the definition of the number of neurons and hidden layers corresponds to an iterative procedure.
Regarding SVM, there are two parameters that can influence the model and obtain results. These parameters can be adjusted and are usually called hyperparameters.
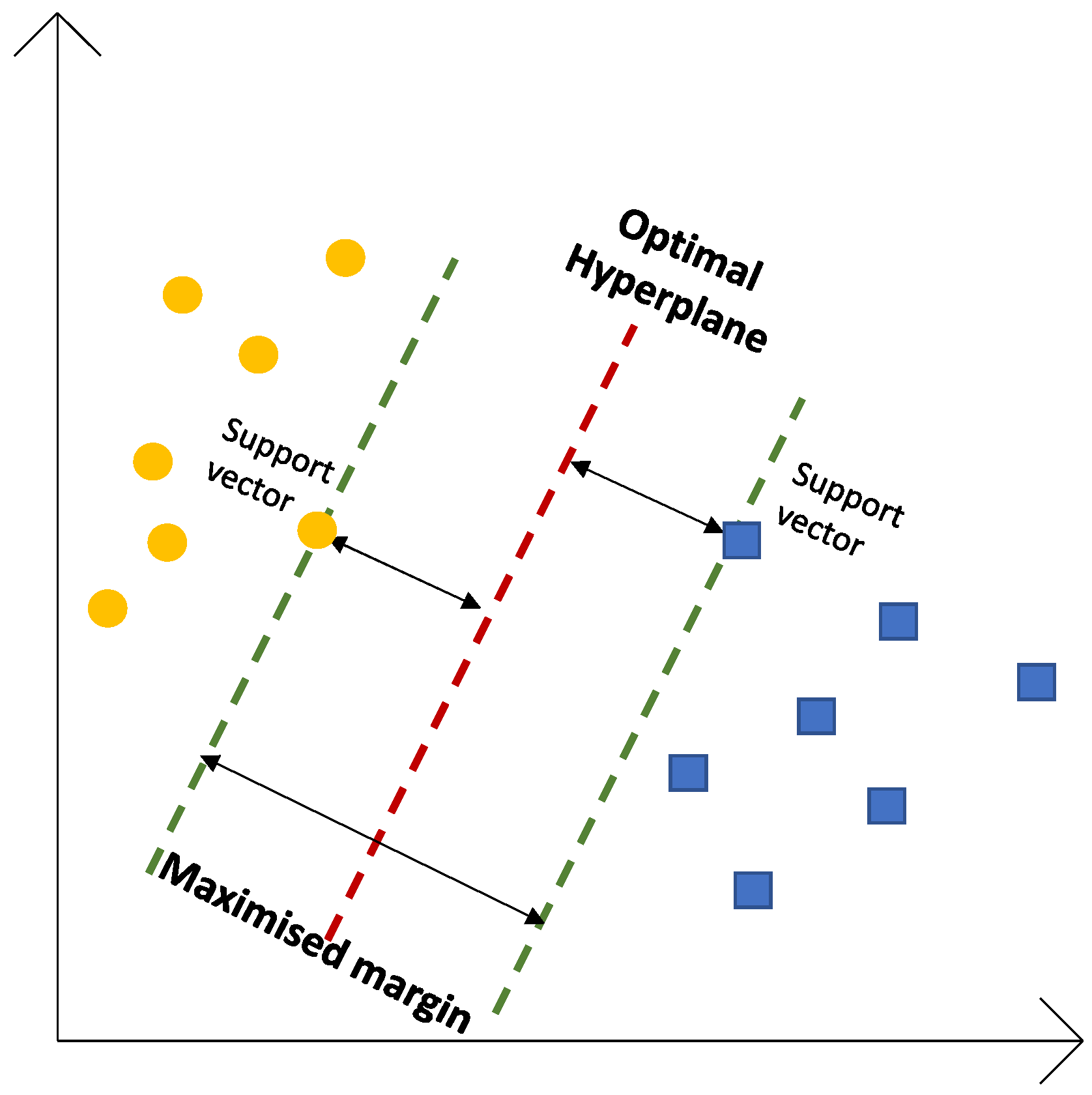
C and gamma are two hyperparameters. In order to obtain a high accuracy of the model, it is essential to find the best values. They are very critical in building robust and accurate models. Indeed, striking the right balance between bias and variance is paramount to preventing the model from either overfitting or underfitting. Firstly, it is important to understand that the SCV establishes a decision boundary, which makes a distinction between two or more classes (
Figure 3), in the case of a classification problem. The most critical aspect of SVM lies in determining the placement of the decision boudnary, especially when dealing with noisy data. In such scenarios, the decision boundary may need to be positioned very close to a particular class to accurately label all points within the training set. However, this proximity to the class can lead to reduced accuracy, as the decision boundary becomes highly sensitive to noise and minor fluctuations in the independent variables. Conversely, a decision boundary might be placed as far as possible for each class, costing some misclassified exceptions. This trade-off is effectively controlled by the parameter
C. C can be defined as a hyperparameter in SVM to control errors. Thus, a low value of
C means a low error. On the other hand, a large
C means a large error. However, a low
C or lower error does not mean a better decision boundary or a good model, that will depend upon the dataset’s nature.
The gamma parameter is used with the Gaussian RBF (radial bases function) kernel. This kernel was selected to perform this analysis. In fact, in the case of linear or polynomial kernels, it is only necessary to use or define the C hyperparameter. In situations where the data points are not linearly separable, kernel functions are employed for transformation, and the gamma hyperparameter determines the curvature in a decision boundary. A high gamma value results in more curvature, while a low gamma value means less curvature. Once again, the choice between a low or high gamma value depends upon the dataset. Both parameters should be set before the training model. Therefore, it is important to identify the optimal combination of C and gamma. In cases where the value of gamma is large, the influence of C becomes negligible. Conversely, when gamma is small, C affects the model just as it affects a linear model. In this case, the best combination of C and gamma was selected.
4.2.3. Training
In this analysis, the holdout and the cross-validation approaches were used. The holdout approach was only used for the neural network and the cross-validation approach was used for the SVM and neural network. In the holdout approach, the training dataset was divided, considering a proportion into training (p) and test (1 − p). In this case, a p = 70% was adopted, which was close to the value usually recommended in the bibliography (p = 2/3). The cross-validation method usually shows very good results. In this approach, the observations were divided into k subsets randomly with equal size. One of the folds was the holdout set (or the validation set) and the observations of the k − 1 partitions were used in the training process. This process was repeated k times, using, in each cycle, a different partition to test. The final performance of the predictor was given by the mean of the observed performance over each subset of the test. However, the results did not significantly improve when the cross-validation method was used in the case of the neural network. In this case, k-fold cross validation was adopted. The parameter k referred to the number of different subsets or folds into which given data were divided during the k-fold cross-validation. In this analysis, a value of k = 10 was selected.
4.2.4. Performance and Optimization
The last step of the intelligent prediction model implementation corresponded to the evaluation of its performance. For that, it was necessary that the quantification of the error associated with the training step. The following metrics were used: root mean squared error (RMSE), mean absolute error (MAE), mean square error (MSE), R2 (coefficient of determination) and standard deviation (STD) between predicted and target values.
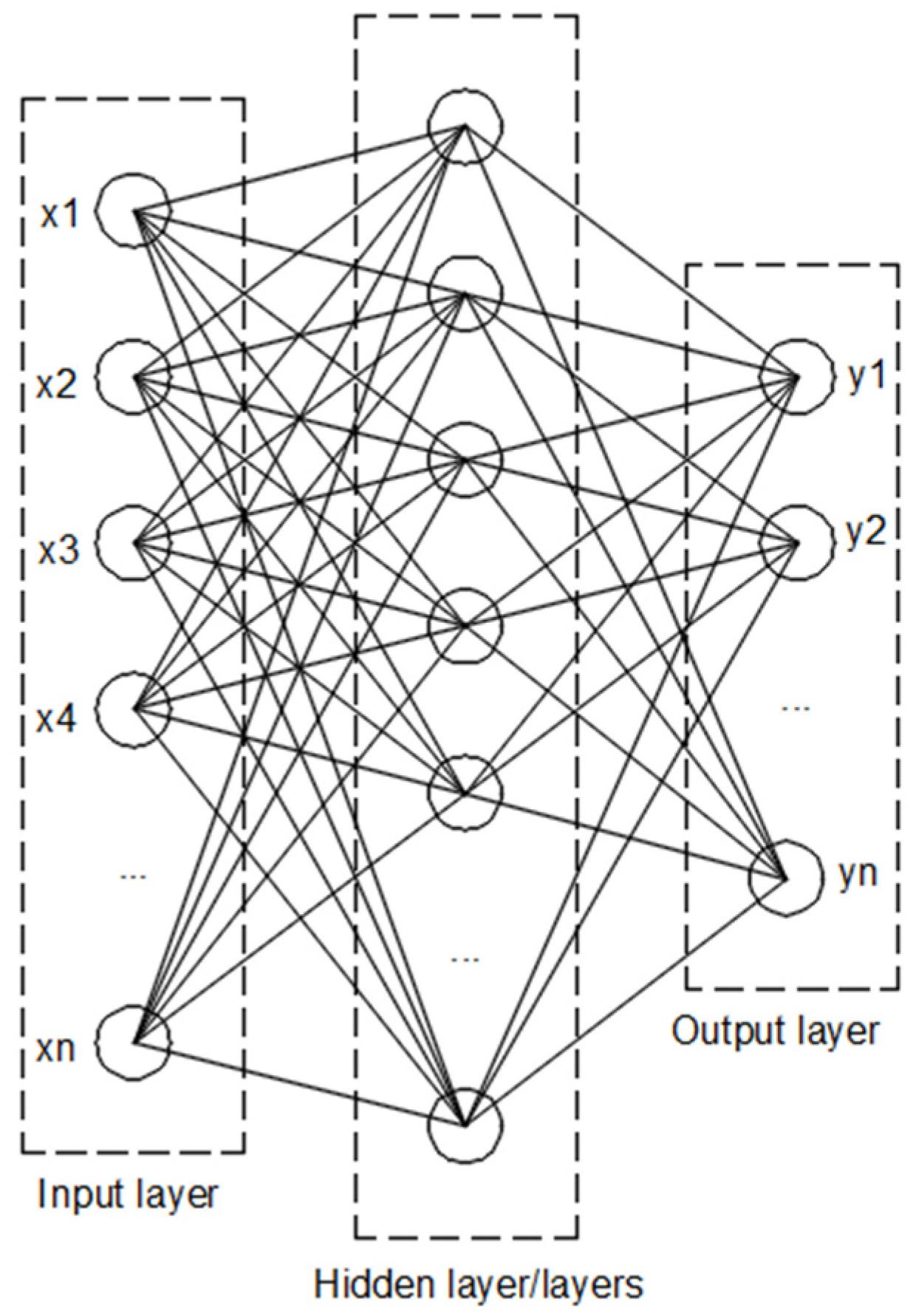
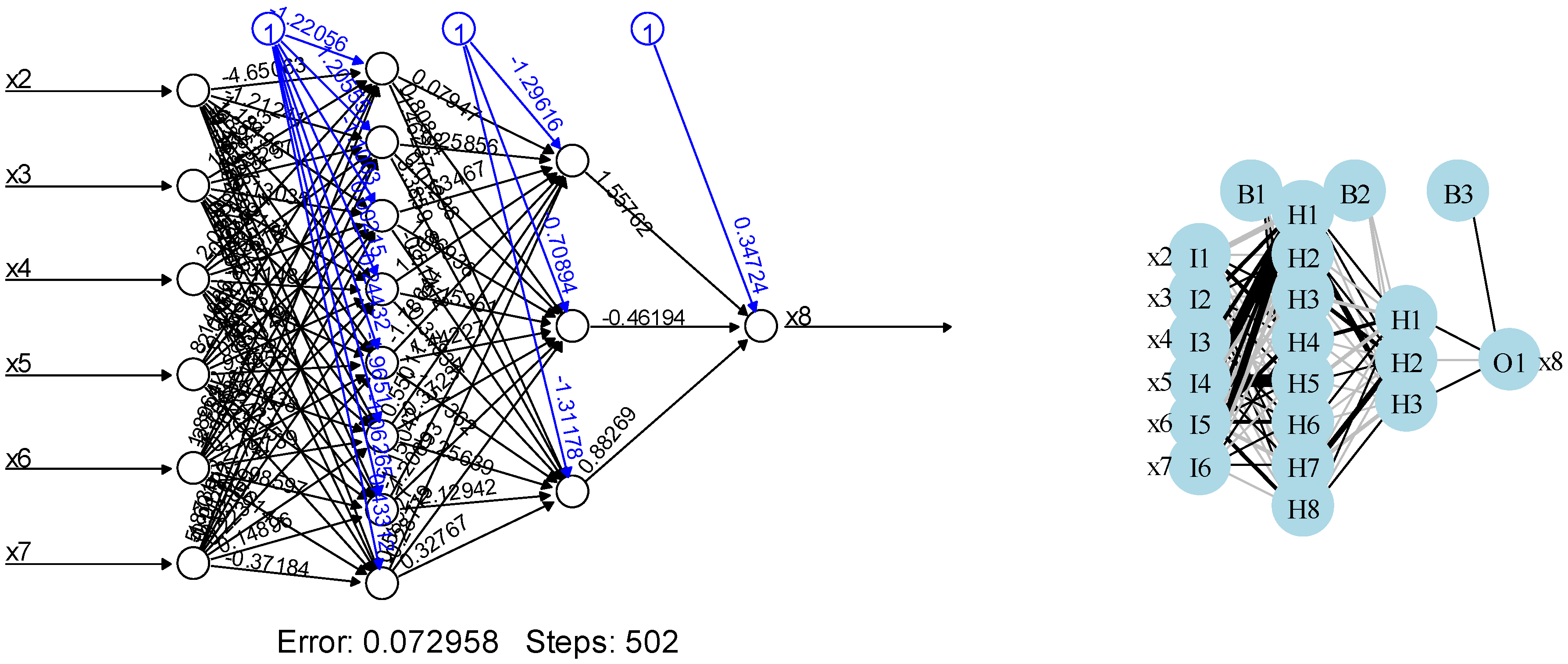
Based on that, and regarding the ANN model, an iterative study could be performed to identify the best combination of the number of neurons and hidden layers that led to the minimum error. From the studies developed, the combination hidden = (8, 3) was considered. This option meant that we had two layers with eight neurons plus three neurons. The output of the ANN is represented in
Figure 7, where it is possible to detect the input variables, hidden layers and output variables.
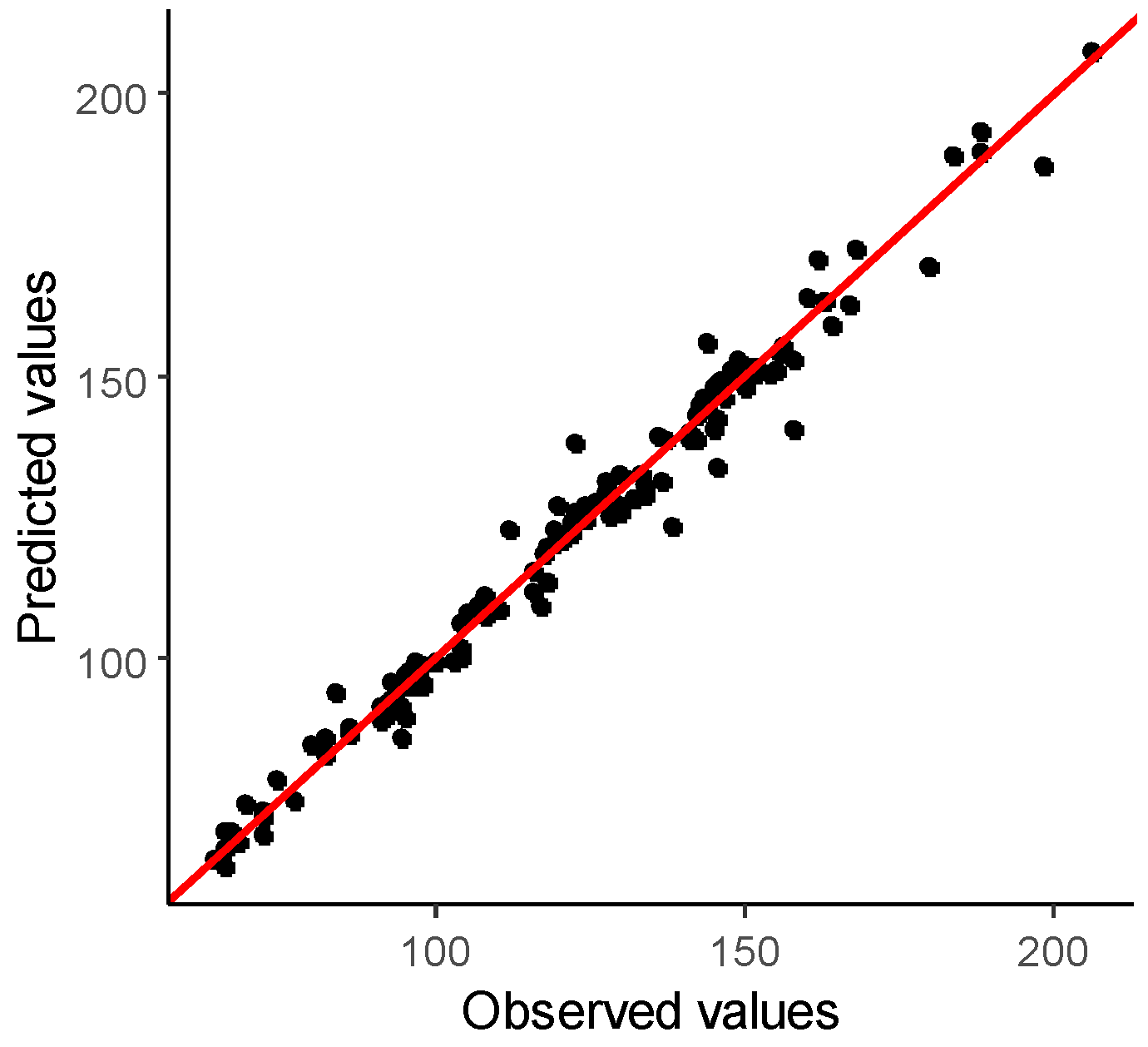
The global behavior of the ANN model for the considerations above can be seen in
Table 3, where a mark on the line drawn in black means a perfect correspondence between the predicted output and the corresponding target (observed values). The results are presented based on a scatter plot. The results show a good agreement between the predicted and observed values of the critical speed, reflected by the error metrics, such as R and RMSE.
To try to improve the results, the k cross-validation method was implemented and used. Indeed, a good way to identify overfitting issues was to separate the dataset into three subsets, including training, testing and validation. The training and testing set were used for the cross-validation process. The validation set was left untouched during the entire model development process. This validation set was used to validate and tune the model.
As mentioned previously, in this analysis, a value of
k = 10 was adopted. From the application of this approach, the results show that the RMSE slightly increased (RMSE = 4.55), as well as the MAE (3.23). This phenomenon may have been due to the significant dimension of the dataset, which had more than 400 inputs. The scatter plot of the observed results versus the predicted results of critical speed is depicted in
Figure 8.
Based on the obtained results, it is important to mention that the model showed no indications of overfitting problems. In this case, the training data had a low error rate, as well as the test data. Moreover, cross-validation could be a powerful preventative measure against overfitting. Thus, the model showed high training accuracy and high validation accuracy. The validation results regarding the RMSE were: 3.79, 3.43, 5.31, 5.14, 4.59, 5.20, 4.37, 2.85, 3.73 and 4.77.
Despite the good results when applying the artificial neural network, the SVM algorithm was also tested and analyzed in detail. In what concerns the SVM, an iterative study was performed to identify the best combination of the
C and gamma parameters that led to the minimum error. From the studies developed, the best combination corresponded to the pair of values (0.03, 16), where the first value corresponded to the
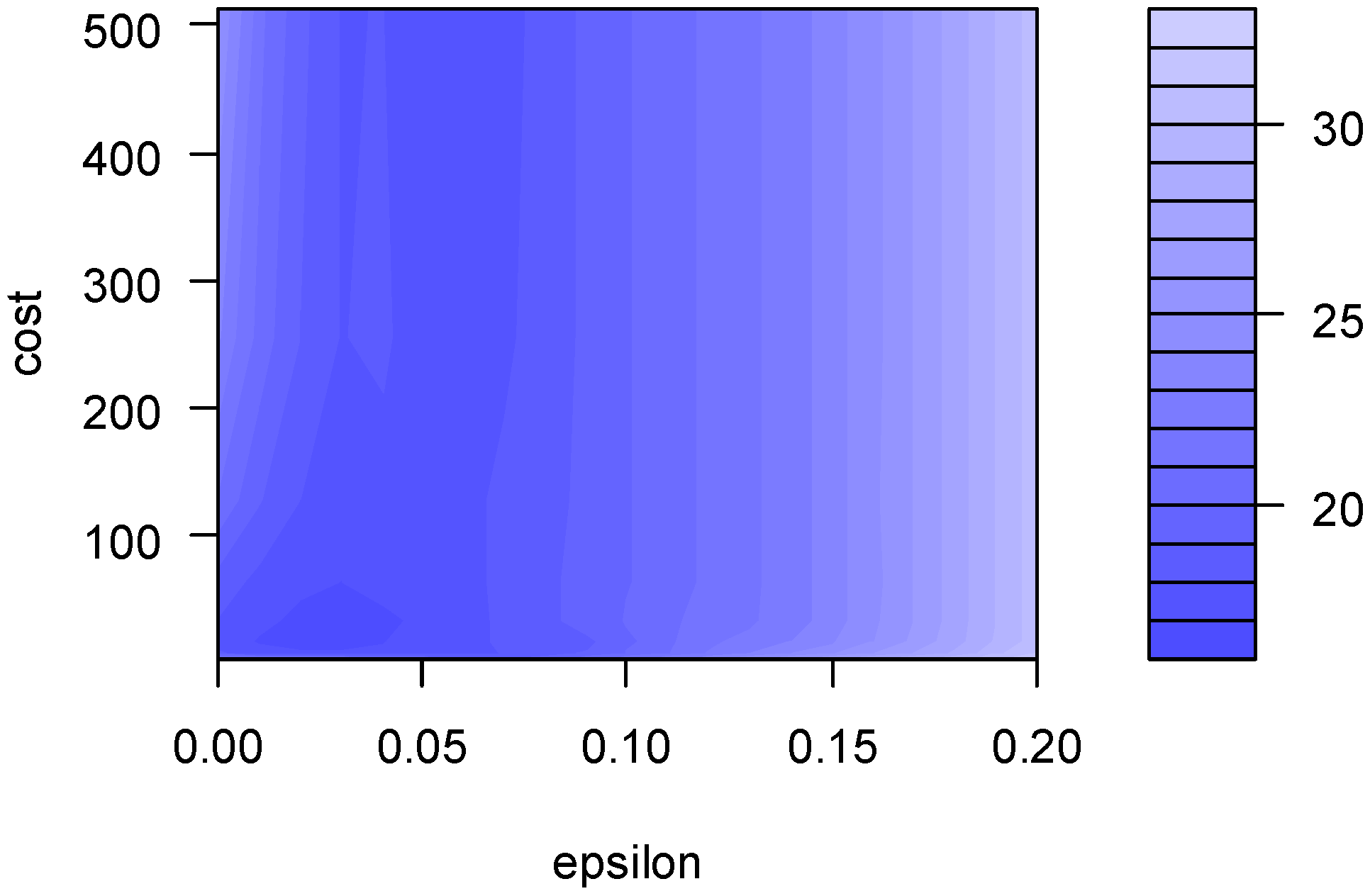
C parameter and the second one to the gamma parameter. The results of the hyperparametrization can be found in
Figure 9.
Figure 9 shows the relationship between epsilon and cost. The value of epsilon determined the width of the tube around the estimated function (hyperplane): points that fell inside this tube were considered as correct predictions and were not penalized by the algorithm. The literature recommended an epsilon between 1 × 10
−3 and 1. The global behavior of the SVM model (considering the previous premises) can be seen in
Table 4, where a mark on the line drawn in black meant a perfect correspondence between the predicted output and the corresponding target. Once again, the results are presented based on a scatter plot. The results show a very good agreement between the predicted and observed values, which were reflected by very low values of the error metrics. Indeed, for example, the RMSE of the SVM model was lower than the ANN model, which indicated the very good performance of this algorithm considering this dataset.
Based on the previous results (metrics and scatter plots), it was possible to conclude that the model developed by the SVM algorithm led to better results. The model presented a very low value of RMSE and MAE and the scatter plot showed that the predicted values of the critical speed were very close to the observed values. It is important to mention that the high values of R did not mean an overfitting problem. The model showed a low error rate in the train, validation and test sets. This meant that the data variance was also low. Moreover, in SVM, to avoid overfitting, some data points were able to enter the margin intentionally (soft margin) in order to prevent the overfitting problem. The gamma parameter also allowed to control this problem.




 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



