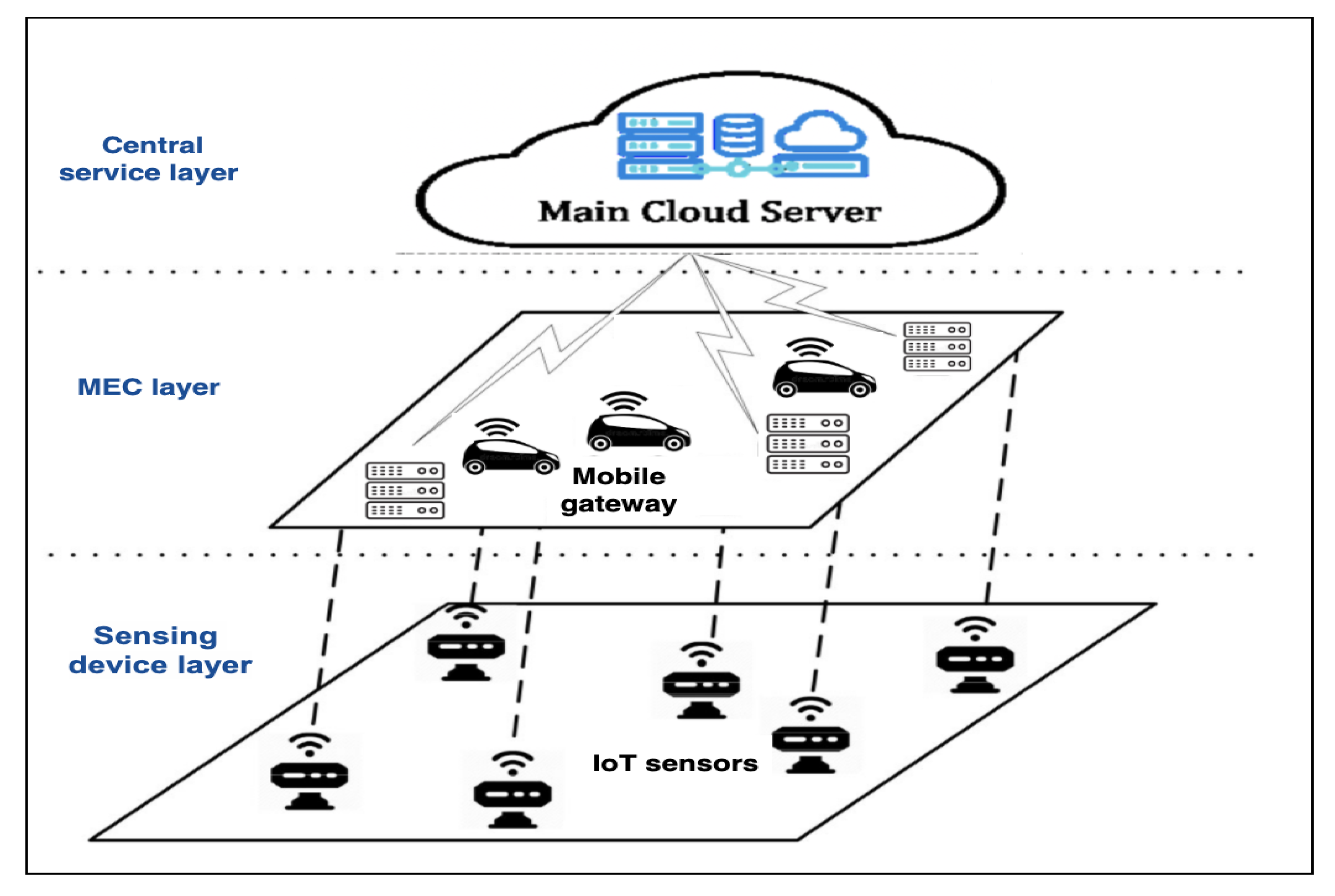
In this section, we used synthetic datases to simulate tasks’ popularities, while the data overlapping experiment has been carried out on real datasets using analytics queries. Finally, the CloudSim Plus simulator has been used to measure the impact of our mechanism on upload/download data rate for each task and resource utilization.
6.1. Tasks’ Popularities and Data Overlapping Experimental Setup
In this context, we deal with two types of datasets: real datasets and synthetic datases. The real datasets are collected by four Unmanned Surface Vehicles (USVs) working as nodes
to collect data from sensors in a coastal area (
http://www.dcs.gla.ac.uk/essence/funding.html#GNFUV, accessed on 20 October 2020). Each USV node
has a neighborhood
of directly communicating nodes
. Moreover, node
communicates end-users/applications in order to collect data and store them locally in their datasets
for predictive analytic tasks. These data includes two features: sea surface temperature and humidity, i.e.,
. There is one node
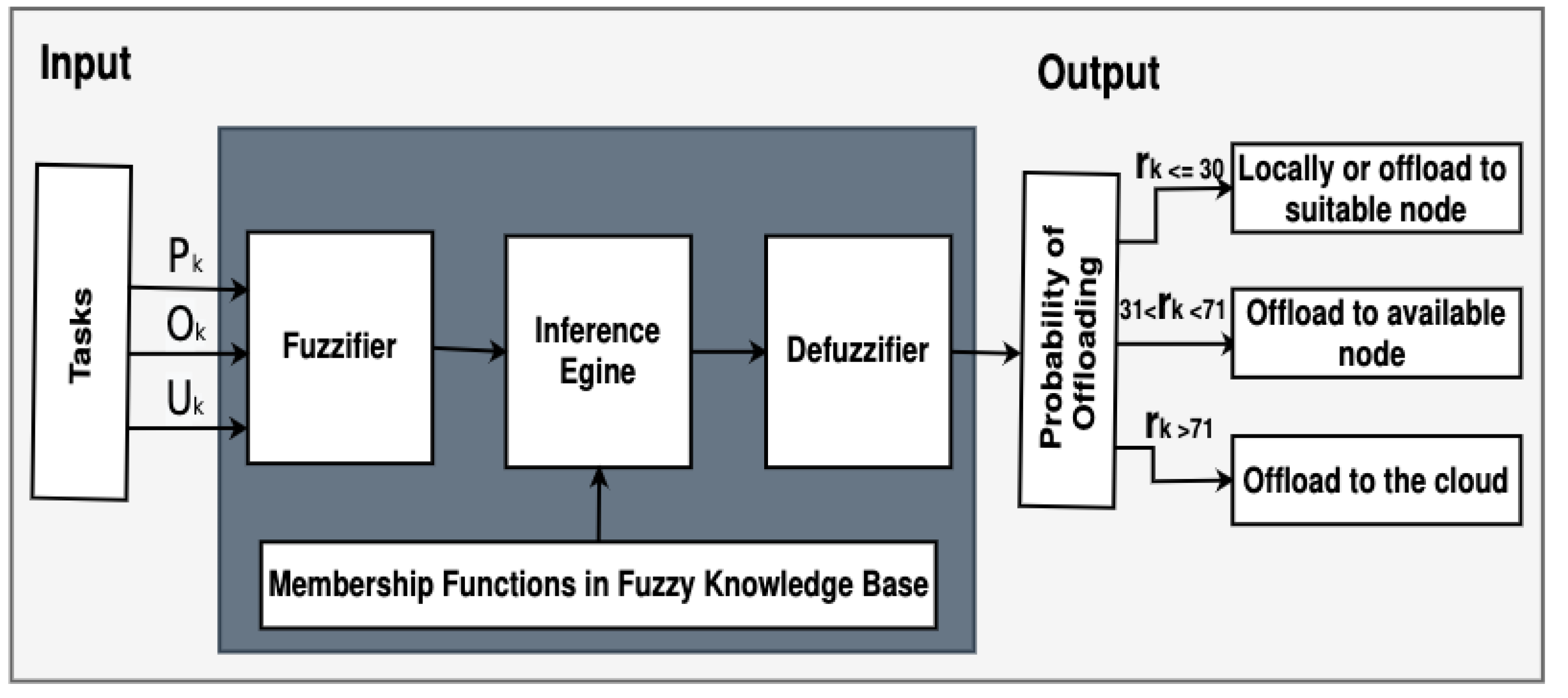
acting as the leader that receives a set of analytic tasks
and follows a specific mechanism in order to decide the following: whether
should execute locally (action
) or offload (action
). We have assumed that leader
has received ten analytic tasks and is investigating three factors (
,
, and
) for each task
. Regarding popularity (
), we have generated a synthetic dataset of task demands for each task
according to different rates (
) during a time window of size
by using Poisson distribution. Poisson distribution is considered as common tool to generate set of requests according to specific rate. After constructing the requests vector
for each task
, we have adapted the Subtractive clustering algorithm over tasks
demands in order to group the demands according to the similarity between them. Then, the cluster density
for each cluster
C has been calculated according to Equation (
1). The leader
obtains
’s popularity, as shown in the second column
Table 3.
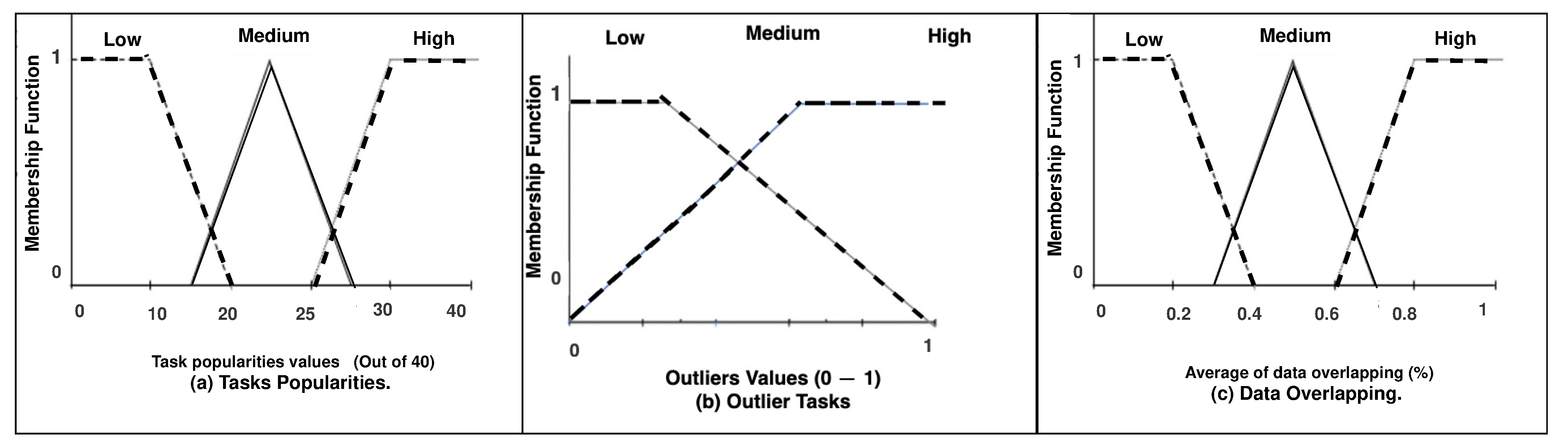
Regarding the outliers indicators
, we use the statistical threshold
, where
can generate the two sets of outliers and not outliers, as shown in the third column in
Table 3. In order to obtain the task’s data overlapping
, we have defined for each local dataset
, the feature boundaries max and min values:
. Then, we generated queries
uniformly at random ten tasks such that
for each task
in order to obtain the data subspace needed for the execution of analytic task
, as shown in
Table 4.
Evidently, there are some tasks with high data overlapping (e.g., ); reaches 98%, while there are tasks with low , such as and . Therefore, by executing tasks with high such as locally, it is expected to reduce the percentages of data offloading from 100% to 2%. In contrast, by executing tasks with low locally such as , it is expected to increase data offloading percentages to almost 95%, which is obviously inefficient.
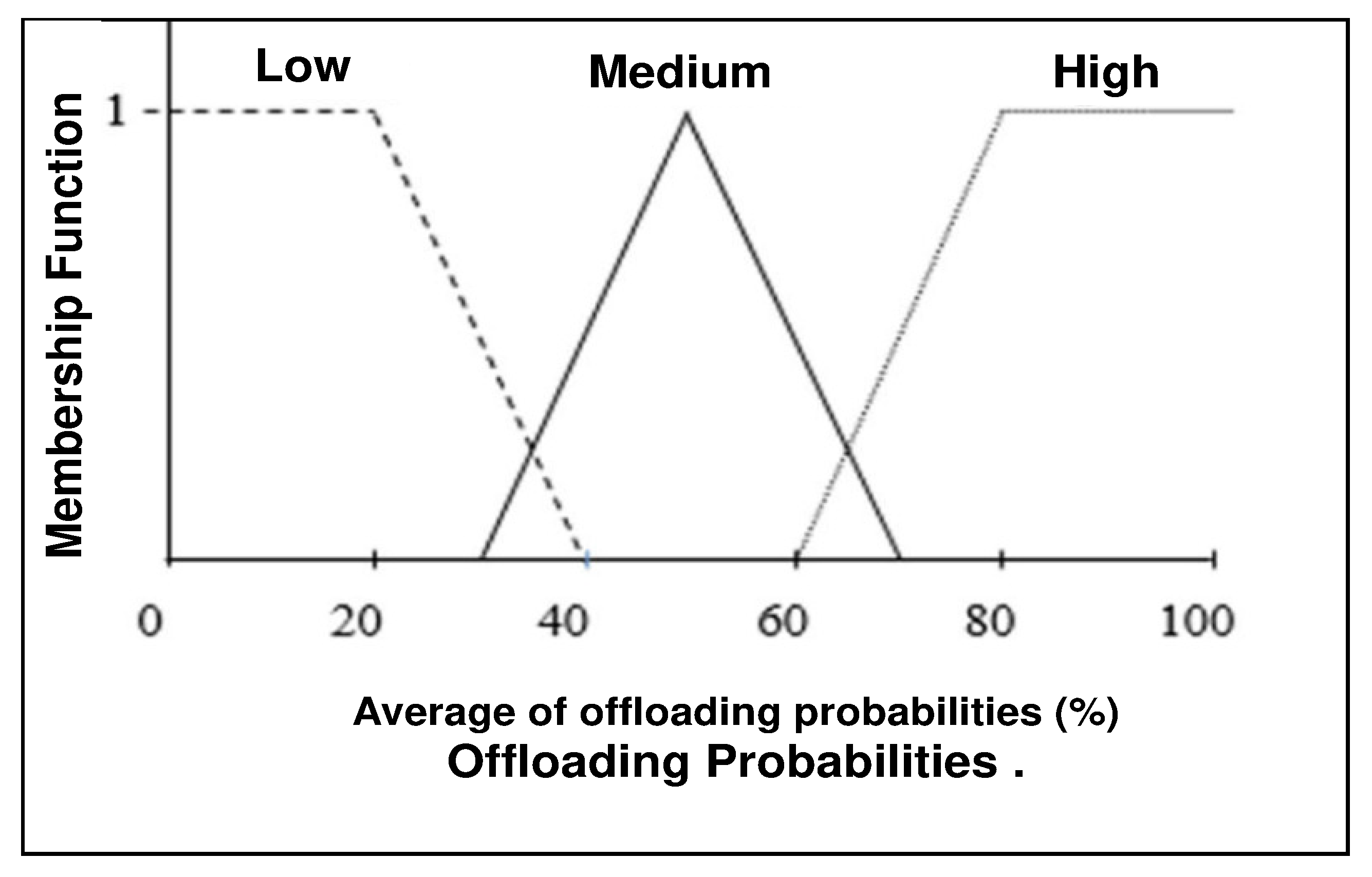
The FL engine has been developed in MATLAB considering the popularity
of tasks
between [1, 40] and outlier
either 0 or 1, while the percentages of data overlapping
are between [0%, 100%]. All these are inputs to the FL system, while the probability of offloading
is the output in [0%, 100%]. As shown in
Figure 5A, increasing
and
for task
leads to a decrease in the probability of offloading
. This implies an increase in the probability of executing this locally (action
). On the other hand, in
Figure 5B, decreasing
and
for task
leads to increasing the probability of offloading
. This means that increasing the probability of offloading
either to another node (action
) or to the cloud (action
).
For task information update, we deal with ten tasks
, six of them should be offloaded (action
) according to
Table 5. In order to determine the most suitable node
for each task
, information (
,
, and
) is updated.
During
, leader
will have the task information as shown in
Table 5. The output of S2 is
for each task in
.
is applied with the same steps as in
. According to the results,
,
,
, and
will offload to
(action
), while
will offload to
(action
), if there are available resources. However, task
and
have almost very high offloading probability; therefore, they will be offloaded to the cloud (action
).
6.2. Simulation Setup
CloudSim Plus has been utilized to create the considered scenarios and to evaluate the performance of our mechanism. In this experiment, two types of parameters have been considered: data-driven task characteristics and MEC/cloud parameters. Data-driven tasks characteristics vary according to the nature of tasks. Some tasks are affected by delays, while others are not; some tasks could execute on MEC nodes, while others are beyond MEC node’s capabilities and should be offloaded to the cloud. To simulate real-life scenarios, ten different data-driven tasks (applications) have been used. To decide the application types, we looked at the most common data-driven tasks (weather prediction, air pollution prediction, traffic jam prediction, compute-intensive tasks, and health apps, etc.).
Table 6 contains tasks information chosen based on [
16]. The upload/download data size represents the type of data sent/received from EC/Cloud since it could increase or decrease according to data overlapping percent, and this is what distinguishes our mechanism against other task offloading mechanisms. For instance, (50,000 MB, 100 MB) denotes the size of uploaded data (humidity, temperature, wind, etc.) that will be used to build a ML model, and downloads depict the model that the application will receive as a result of data collection and training in EC/cloud computing. According to our mechanism, if the data overlapping percentage is high (e.g., 90% or more) the uploading data could be reduced from 50,000 MB to 10 MB. Task length determines the number of Million Instructions (MI) and the required CPU resource to complete a data-driven task. We considered ten tasks arriving at
with specific features, which include task length and upload/download data. According to data overlapping, we made the range of this parameter fluctuate from low values with some tasks to high values with others, while resource consumption and task delay sensitivity have been set up according to the applications indicated in [
16].
Other simulation parameters that reflect the computational capabilities of MEC/Cloud servers, such as bandwidth, the number of Virtual Machines(VM), and host MIPS, are listed in
Table 7.
6.3. Comparative Assessment
In this section, we present two types of results that reflect our mechanism’s performance:
First, in terms of considering both factors (tasks polarities
and data overlapping
), we compare the suggested mechanism’s efficiency to the effectiveness of two alternative mechanisms that deal with the same tasks and datasets. The first mechanism (
) takes only tasks popularity
and outlier
into consideration when it makes the offloading decision. The second mechanism (
) only takes the percentages of data overlapping
between the tasks
and nodes
. The experimental results in
Table 8 show the performance of the mechanism, coined here as (
), which is the highest according to the optimal solution (OS) in the last column at the same table. As we can see, (
) focuses on investigating task popularity
in each node, while data overlapping
is completely ignored. That means
mechanism will distribute tasks
among
regardless of whether task
is offloaded to the suitable node
that could reduce the response time and resource consumption or not. On the other hand, (
) only focuses on the percentages of data overlapping
. (
) uses the node’s data in an efficient manner regardless of whether tasks
are popular or not. As a consequence, the popular/urgent tasks
could offload to the cloud (action 12) or could wait in the execution queue, because they have lower data overlapping
with
. (
) attempts to balance between the both sides of popularity
and data overlapping
. Based on the results, (
) can provide an accurate offloading probabilities
close to
according to
boundaries, while (
) and (
) provide accuracies reaching
and
, respectively.
Second, in terms of resource utilization: We compare the effectiveness of our mechanism against two alternative mechanisms over the same task’s simulation conditions. The first one, cloud-based mechanism [
11], where the MEC nodes have been used to collect sensors data and sent them to the cloud to reduce sensors’ energy consumption that would happen if data have been sent directly to the cloud. The second mechanism, a MEC-based mechanism, has been suggested in many studies, such as [
16,
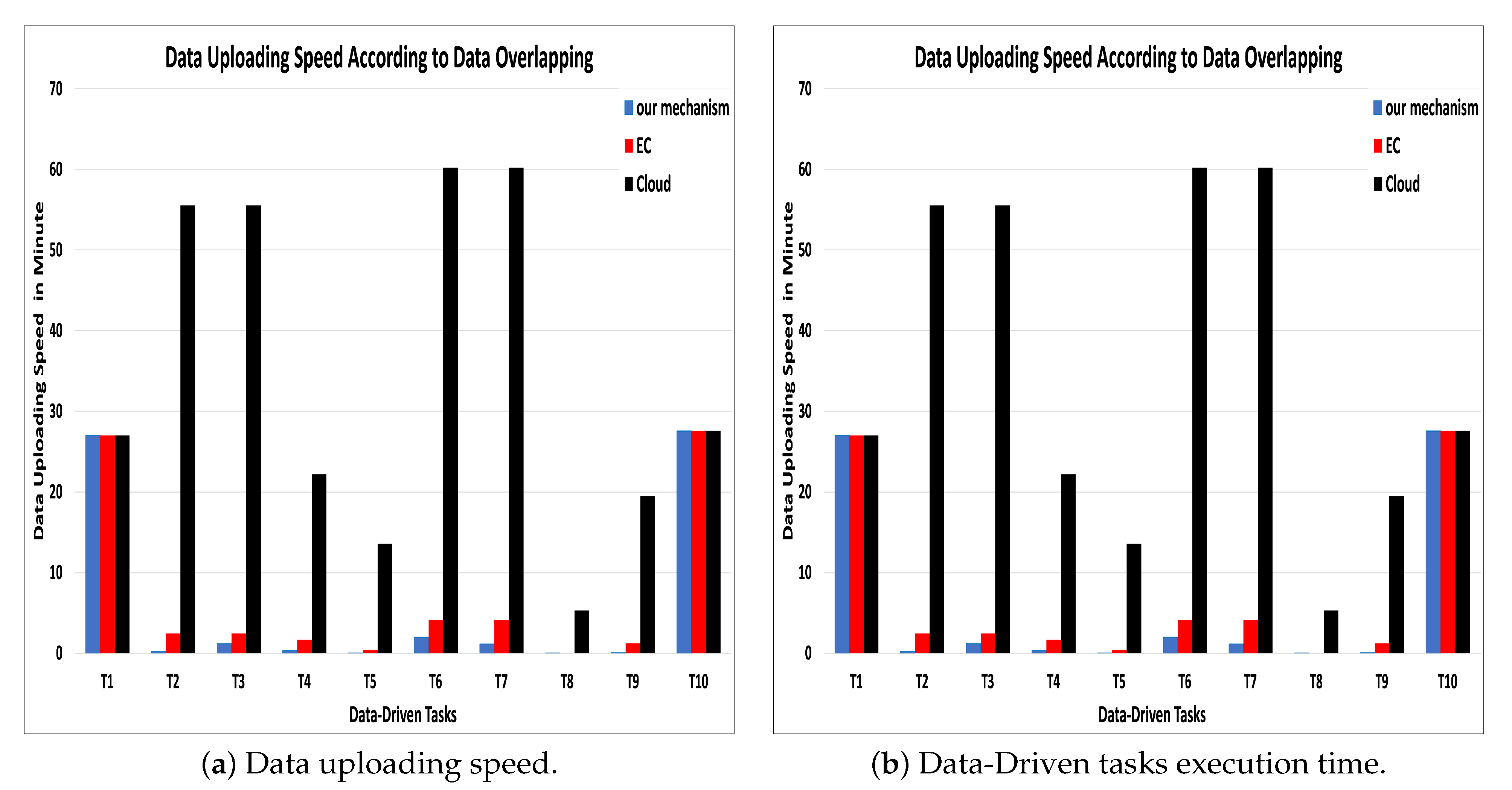
20], where the tasks are sent to the MEC node that has the highest availability, bandwidth, and task delay sensitivity. Simulating our mechanism resulted in a high data uploading speed between one to ten minutes, while the uploading speed in the cloud-based model is between 28 to 60 min. whereas the uploading speed in MEC-based mechanisms, which has not considered data overlapping, is almost double the speed we obtained with our mechanism (see
Figure 6a).
In terms of execution time, we have considered data offloading time in addition to the main execution time because, in the data-driven tasks, data are considered an integral part of the task execution.
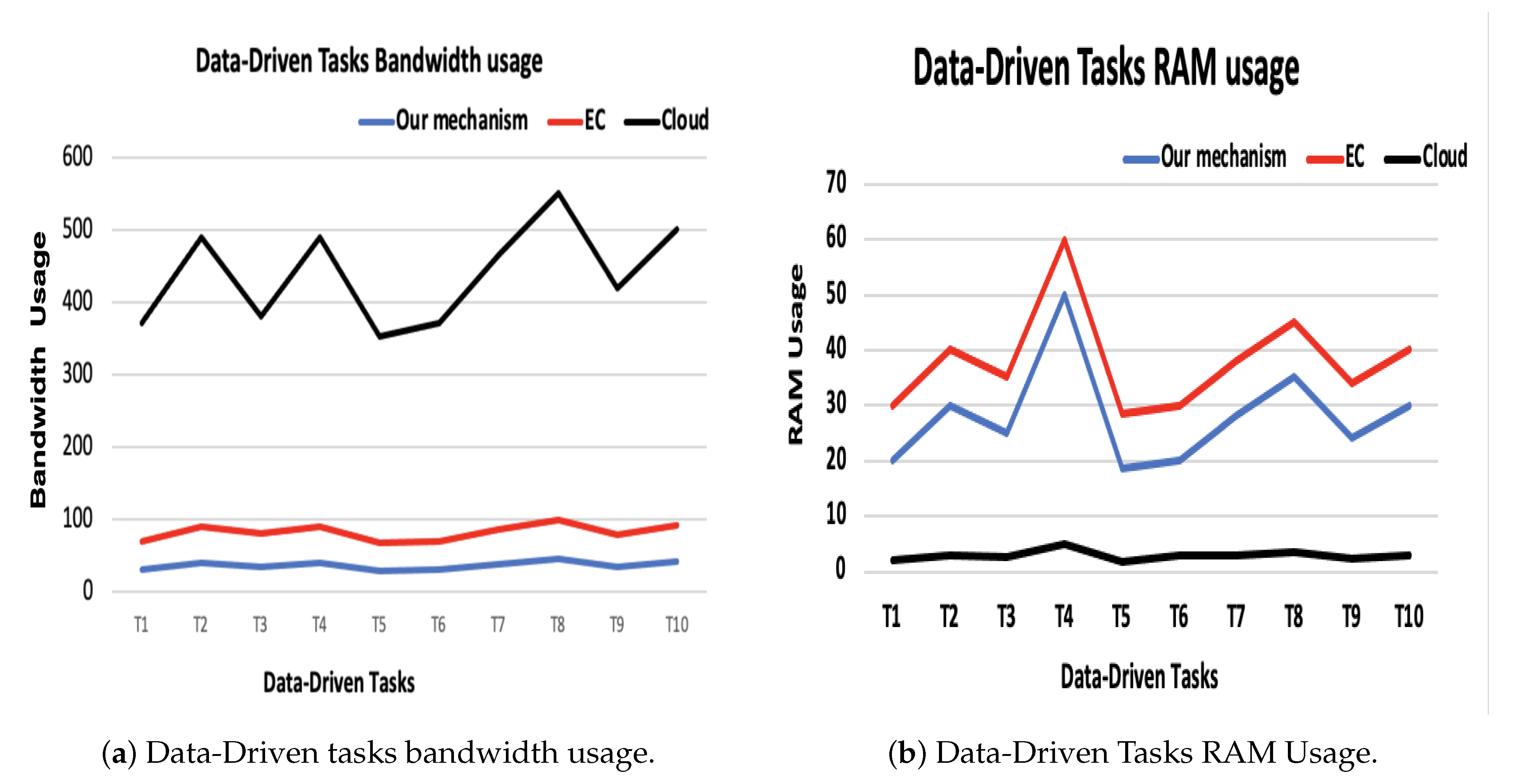
Figure 6b shows that the execution time is extremely minimized compered to the cloud-based model. Moreover, we can observe that the bandwidth is reduced as well. The results of cloud (WAN) and MEC (MAN) bandwidth measurements are shown in
Figure 7. The blue line represents the bandwidth usage percent according to our mechanism, which is considered to be very low compared to the other mechanisms. The red line represents the bandwidth usage according to the MEC-based mechanism, which is considered almost double our mechanism usage. Meanwhile, the black line shows bandwidth usage in order to execute these ten tasks on the cloud, which is very high usage compared to ours and MEC-based (see
Figure 7a).
According to resource usage, Cloud-based mechanism produced the best performance compared to our mechanism and EC-based mechanism as it has unlimited resources (
Figure 7b).


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}