
Applications and Extensions of Metric Stability Analysis


Abstract
:1. Introduction
- Variability associated with the inherently probabilistic nature of item response models, captured by the model-implied information and standard errors of trait estimates.
- Variability associated with a particular trait estimation method.
- Variability associated with item parameter estimate.
- Variability associated with imperfect match of a model to data.
1.1. Metric Stability Analysis Using Multiple Imputation
1.2. Bayesian Metric Stability Analysis
2. Methods
2.1. Data for Illustration
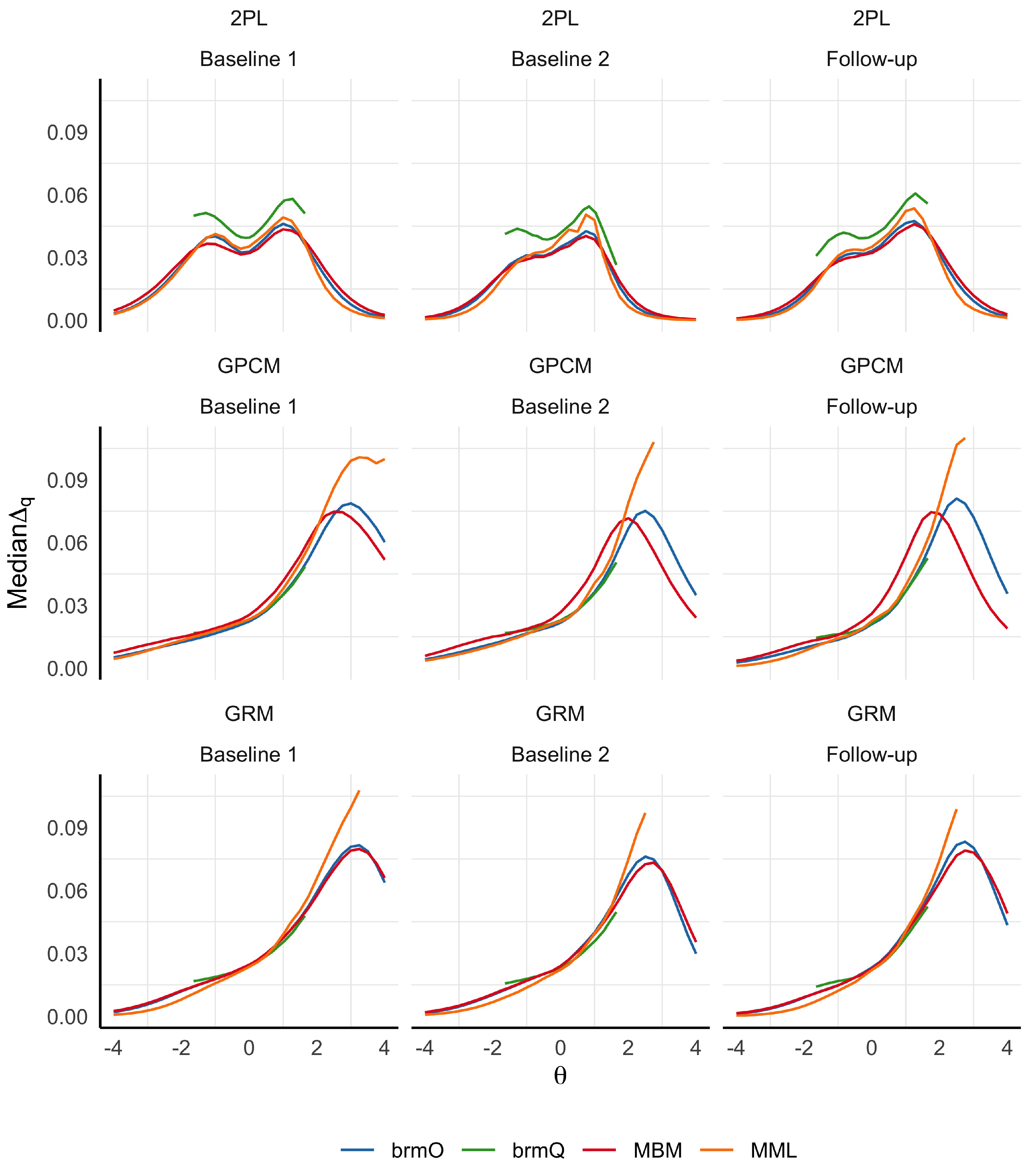
2.2. MSA at Each Time Point
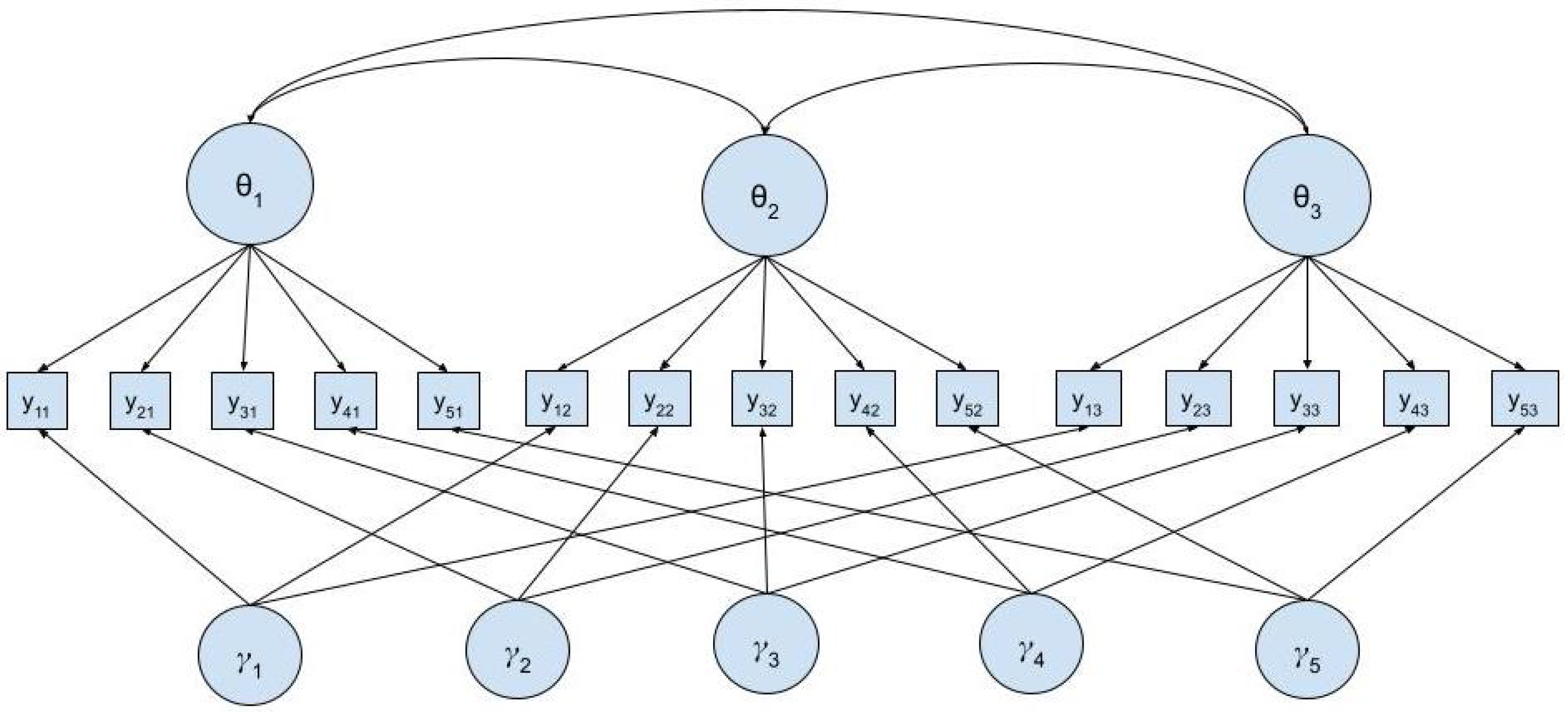
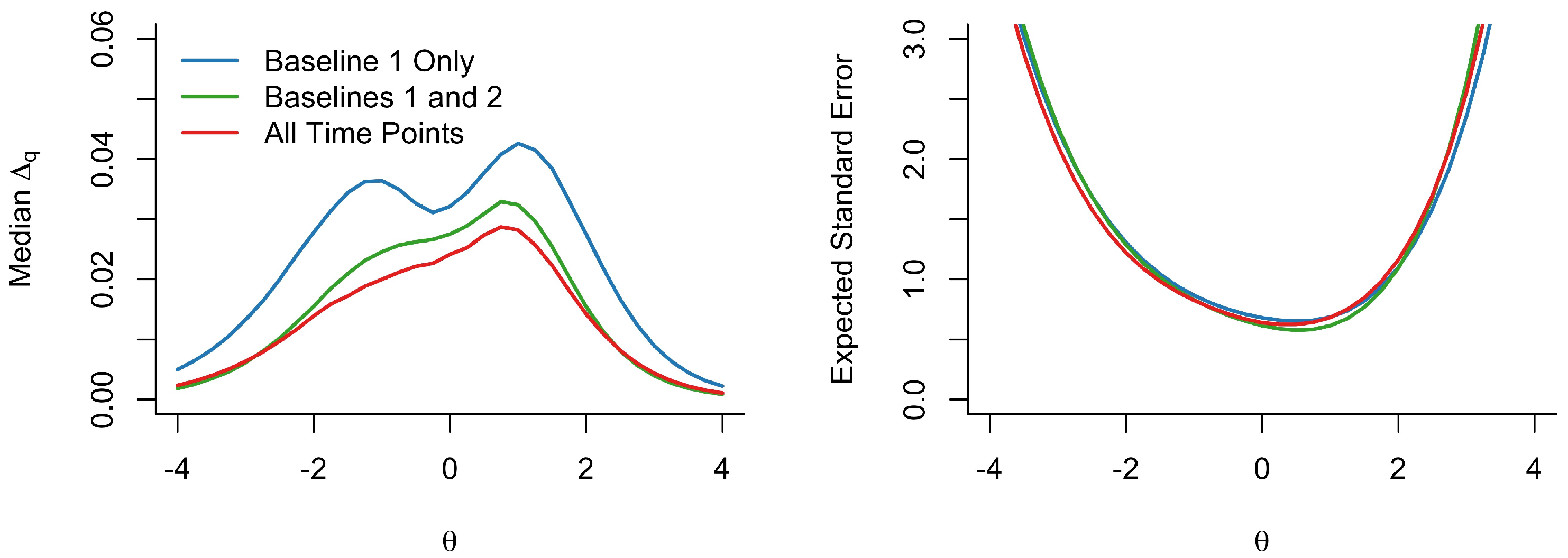
2.3. Longitudinal Analyses
3. Results
3.1. Metric Stability at Each Time Point
3.2. Longitudinal Measurement Stability
4. Discussion
5. Conclusions
Supplementary Materials
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 2PL | Two-parameter logistic item response model |
| GPCM | Generalized partial credit model |
| GRM | Graded response model |
| IRT | Item response theory |
| MBM | Marginal Bayes model estimation |
| MCMC | Markov Chain Monte Carlo |
| MH-RM | Metropolis–Hastings Robbins–Monro |
| MI | Multiple imputations |
| MML | Marginal maximum likelihood estimation |
| MSA | Metric stability analysis |
| OHIP-5 | Five-item short form of the Oral Health Impact Profile |
| OHIP-G | Oral Health Impact Profile, German version |
References
- Jones, D.H.; Wainer, H.; Kaplan, B. Estimating ability with three item response models when the models are wrong and their parameters are inaccurate. ETS Res. Rep. Ser. 1984, 1984, i-50. [Google Scholar] [CrossRef]
- Feuerstahler, L.M. Sources of error in IRT trait estimation. Appl. Psychol. Meas. 2018, 42, 359–375. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Yuan, K.H. The impact of fallible item parameter estimates on latent trait recovery. Psychometrika 2010, 75, 280–291. [Google Scholar] [CrossRef] [PubMed]
- Hoshino, T.; Shigemasu, K. Standard errors of estimated latent variable scores with estimated structural parameters. Appl. Psychol. Meas. 2008, 32, 181–189. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, J.S. Bootstrap-calibrated interval estimates for latent variable scores in item response theory. Psychometrika 2018, 83, 333–354. [Google Scholar] [CrossRef]
- Mislevy, R.J.; Wingersky, M.S.; Sheehan, K.M. Dealing with uncertainty about item parameters: Expected response functions. ETS Res. Rep. Ser. 1994, 1994, i-20. [Google Scholar]
- Patton, J.M.; Cheng, Y.; Yuan, K.H.; Diao, Q. Bootstrap standard errors for maximum likelihood ability estimates when item parameters are unknown. Educ. Psychol. Meas. 2014, 74, 697–712. [Google Scholar] [CrossRef]
- Tsutakawa, R.K.; Johnson, J.C. The effect of uncertainty of item parameter estimation on ability estimates. Psychometrika 1990, 55, 371–390. [Google Scholar] [CrossRef]
- Yang, J.S.; Hansen, M.; Cai, L. Characterizing sources of uncertainty in item response theory scale scores. Educ. Psychol. Meas. 2012, 72, 264–290. [Google Scholar] [CrossRef]
- Baldwin, P. A strategy for developing a common metric in item response theory when parameter posterior distributions are known. J. Educ. Meas. 2011, 48, 1–11. [Google Scholar] [CrossRef]
- Pashley, P.J. Graphical IRT-based DIF analyses. ETS Res. Rep. Ser. 1992, 1992, i-20. [Google Scholar] [CrossRef]
- Scrams, D.J.; McLeod, L.D. An expected response function approach to graphical differential item functioning. J. Educ. Meas. 2000, 37, 263–280. [Google Scholar] [CrossRef]
- Sheehan, K.M.; Mislevy, R.J. Some consequences of the uncertainty in IRT linking procedures. ETS Res. Rep. Ser. 1988, 1988, i-40. [Google Scholar] [CrossRef]
- Feuerstahler, L.M. Metric stability in item response models. Multivar. Behav. Res. 2022, 57, 94–111. [Google Scholar] [CrossRef] [PubMed]
- Thissen, D.; Wainer, H. Confidence Envelopes for Monotonic Functions: Principles, Derivations, and Examples; Technical Report; Mcfann Gray and Associates Inc.: San Antonio, TX, USA, 1983. [Google Scholar]
- Thissen, D.; Wainer, H. Confidence envelopes for item response theory. J. Educ. Stat. 1990, 15, 113–128. [Google Scholar] [CrossRef]
- Chalmers, R.P. mirt: A multidimensional item response theory package for the R environment. J. Stat. Softw. 2012, 48, 1–29. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023. [Google Scholar]
- Bürkner, P.C. brms: An R package for Bayesian multilevel models using Stan. J. Stat. Softw. 2017, 80, 1–28. [Google Scholar] [CrossRef]
- JO, R. A geometrical approach to item response theory. Behaviormetrika 1996, 23, 3–16. [Google Scholar]
- Lord, F.M. The ‘ability’scale in item characteristic curve theory. Psychometrika 1975, 40, 205–217. [Google Scholar] [CrossRef]
- Chalmers, R.P. Numerical approximation of the observed information matrix with Oakes’ identity. Br. J. Math. Stat. Psychol. 2018, 71, 415–436. [Google Scholar] [CrossRef]
- Stan Development Team, RStan: The R Interface to Stan. R Package, Version 2.26.15; Stan Development Team, 2016.
- Cai, L. Metropolis-Hastings Robbins-Monro algorithm for confirmatory item factor analysis. J. Educ. Behav. Stat. 2010, 35, 307–335. [Google Scholar] [CrossRef]
- John, M.T.; Patrick, D.L.; Slade, G.D. The German version of the Oral Health Impact Profile–translation and psychometric properties. Eur. J. Oral Sci. 2002, 110, 425–433. [Google Scholar] [CrossRef] [PubMed]
- John, M.T.; Reißmann, D.R.; Szentpetery, A.; Steele, J. An approach to define clinical significance in prosthodontics. J. Prosthodont. Implant. Esthet. Reconstr. Dent. 2009, 18, 455–460. [Google Scholar] [CrossRef] [PubMed]
- John, M.T.; Miglioretti, D.L.; LeResche, L.; Koepsell, T.D.; Hujoel, P.; Micheelis, W. German short forms of the oral health impact profile. Community Dent. Oral Epidemiol. 2006, 34, 277–288. [Google Scholar] [CrossRef] [PubMed]
- Slade, G.D.; Spencer, A.J. Development and evaluation of the oral health impact profile. Community Dent. Health 1994, 11, 3–11. [Google Scholar]
- Joanes, D.N.; Gill, C.A. Comparing measures of sample skewness and kurtosis. J. R. Stat. Soc. Ser. D 1998, 47, 183–189. [Google Scholar] [CrossRef]
- Samejima, F. Graded response model. In Handbook of Modern Item Response Theory; Springer: Berlin/Heidelberg, Germany, 1997; pp. 85–100. [Google Scholar]
- Muraki, E. A generalized partial credit model: Application of an EM algorithm. ETS Res. Rep. Ser. 1992, 1992, i-30. [Google Scholar]
- Cai, L. A two-tier full-information item factor analysis model with applications. Psychometrika 2010, 75, 581–612. [Google Scholar] [CrossRef]
- Thissen, D.; Wainer, H. Some standard errors in item response theory. Psychometrika 1982, 47, 397–412. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| OHIP-49 Number | Shortened Item | Time | Mean | Skewness |
|---|---|---|---|---|
| 1. | Difficulty chewing | B1 | 1.48 | 0.42 |
| B1 | 1.34 | 0.61 | ||
| F | 1.01 | 0.80 | ||
| 10. | Painful aching | B1 | 1.02 | 0.61 |
| B1 | 1.06 | 0.54 | ||
| F | 0.84 | 1.01 | ||
| 22. | Uncomfortable about appearance | B1 | 0.85 | 0.86 |
| B1 | 0.75 | 1.24 | ||
| F | 0.40 | 1.90 | ||
| 26. | Less flavor in food | B1 | 0.50 | 1.97 |
| B1 | 0.48 | 2.06 | ||
| F | 0.40 | 1.93 | ||
| 43. | Difficulty doing jobs | B1 | 0.30 | 2.36 |
| B1 | 0.37 | 2.10 | ||
| F | 0.26 | 1.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feuerstahler, L. Applications and Extensions of Metric Stability Analysis. Psych 2023, 5, 376-385. https://doi.org/10.3390/psych5020025
Feuerstahler L. Applications and Extensions of Metric Stability Analysis. Psych. 2023; 5(2):376-385. https://doi.org/10.3390/psych5020025
Chicago/Turabian StyleFeuerstahler, Leah. 2023. "Applications and Extensions of Metric Stability Analysis" Psych 5, no. 2: 376-385. https://doi.org/10.3390/psych5020025
APA StyleFeuerstahler, L. (2023). Applications and Extensions of Metric Stability Analysis. Psych, 5(2), 376-385. https://doi.org/10.3390/psych5020025