1. Introduction
dexter is an R [
1] package for the management and analysis of data from educational tests first published on CRAN in 2017. At that time, all its four authors, Gunter Maris, Timo Bechger, Ivailo Partchev, and Jesse Koops, were employed at Cito, one of the largest and oldest test companies in Europe. Robert Zwitser and Maarten Marsman, whose contributions are often cited in this paper, were doctoral students of Gunter Maris at Cito and the University of Amsterdam. Last but not least,
dexter is inspired in many ways by OPLM [
2], a model and a software developed 30 years ago at Cito by Norman D. Verhelst and colleagues.
The package is easy to use and scales well, from small problems to large scale (inter)national projects. However, it was designed primarily for the larger projects found in high stakes exams and in educational surveys. Consequently, it has some features not found in other packages (rigorous data management, advanced diagnostic tools) while it lacks features readily found elsewhere (notably, any psychometric models without sufficient statistics for the item and person parameters). Both the inclusions and the omissions are important seeing that they are based on extensive practical experience and some rather definite ideas of what matters most in high stakes exams.
dexter and its companion packages,
dextergui and
dexterMST, are freely available from CRAN. There is a GitHub
package page, which includes a blog. The blog contains, along with release notes and some fun entries, many articles on specific features or technical details of
dexter.
An anonymous reviewer has asked for a more detailed comparison between
dexter and alternative programs. This is not very easy, especially as there are so many of them.
dexter is one of those packages that offer comprehensive support for practical assessment and survey projects, which makes it most similar, most likely, to TAM [
3]. It differs considerably in purpose from, say, mirt [
4], which supports a very large number of IRT models, an invaluable feature in academic projects. However, we know that not all testing companies in the world have been eager to embrace IRT, let alone its most advanced models, and that very many tests are still scored with the sum score and then equated with some of the methods in [
5] (the recent proliferation of books on classical equating techniques [
5,
6,
7,
8] is an indirect proof that the professional community remains rather conservative). We try to improve on this reality while remaining compatible with it. There is a limited range of IRT models in
dexter, and they all retain a sound relation with the sum score.
Most modern testing projects incorporate incomplete designs, such that different subsets of items (traditionally called booklets) are administered to different subsets of examinees. Given such a design, we may distinguish between calibration models and evaluation models. The calibration model is applied to all booklets simultaneously; this effectively translates the sum scores gained on different booklets onto a common psychometric scale. Evaluation models (a non-standard term we have coined for the occasion) can be applied within booklets to estimate the quality of the items, reliability and, as we shall see, goodness of fit.
dexter provides several evaluation models and one calibration model: a particular adaptation of the nominal response model [
9] called the extended nominal response model (
enorm). This will be discussed in detail in the paper; the hurried user will not be very wrong to think of it as a model that defaults to the Rasch model [
10] for the dichotomous items, and to the partial credit model [
11] for the polytomous items.
Is this too restrictive? For research purposes, most likely, but high stakes tests are not scientific research. Nobody has expressed the dilemma better than Paul W. Holland when he spoke of tests as a measurement problem (for psychometricians) and a contest (for the examinees) [
12]. In high-stakes situations, the natural desire to perfect our methods of measurement is held in check by the need for clear and transparent rules that are known in advance and perceived as fair by the stakeholders. Looking at sport contests, we observe an enormous effort to cover any foreseeable situation with such rules. Thus, we might read that ‘[A]thletes may compete barefoot or with footwear on one or both feet.’ Four subsequent pages specify what constitutes acceptable footwear—thus, all shoe models that have not been on the market for a certain time are excluded as a potential source of unfair advantage [
13]. The speed of wind is measured and its influence on whether the results will be “scored” as a world record or just a gold medal carefully determined, and so on.
Similar rules exist for high stakes exams as well, covering the test administration in considerable detail—there are clear protocols on how to detect and treat copying, for example. However, if we score the exams with one of the more complicated models expected to achieve better model fit, even the relatively simple 2PL model (two-parameter logistic, [
14]), the scoring rule for the individual item is determined after the contest and based on the data. Even worse, this rule is not transparent: we cannot explain to the examinees why one particular item should bring much more credit than another, especially as we do not know ourselves—all we can do is explain general principles and offer tentative explanations. Neither can we recognize a highly discriminating item from a less discriminating one by just looking at its content, the way we can do with easy and difficult items, let alone write items with a predetermined discrimination. We are not sure that many sports associations would be prepared to consider such scoring rules. In large-scale assessment projects, which are more research and measurement than testing, there is also discussion about the usefulness of models with multiple item parameters [
15].
It is largely for these reasons that we have given preference to models that originate from the scoring rule (the sum score) over models where the scoring rule originates from the model. Conveniently, the sum score happens to be a sufficient statistic for the ability that we are searching to characterize, which opens the way for a number of important theoretical and practical advantages. We mention but three:
Conditional maximum likelihood (CML) estimation is very fast and stable, and does not need any distributional assumptions about the trait being measured;
We have access to powerful diagnostic tools of item fit based on observable data; this avoids the circularity of judgement that may arise if we test the fit of a model based on ability estimates from the model;
Multi-stage tests with routing rules based on sum scores can be estimated with CML as in the companion package, dexterMST, with no or very little item exposure prior to the actual testing; this makes it possible to introduce adaptivity in high stakes situations.
One final remark related to what can or cannot be done with dexter: CML estimation is only applicable to tests with a connected design. Connected designs can be constructed by including either anchor items or groups of examinees taking two booklets. dexter will check whether the design is connected, and dextergui will visualize it with a bipartite graph. It follows that dexter cannot be used to analyze tests with unconnected designs, and is not appropriate for data from conventional computerized adaptive tests.
2. Using the Package
The package can be used either in R programming or over the GUI provided by dextergui. Graphical interfaces are generally thought to be easier but the truth is that dexter is easy to use in both modes. The GUI is particularly handy for interactive exploration of item functioning: all tables are sortable on every column, the graphs are arranged in carousels (HTML widgets that make browsing really easy), and clicking on the appropriate table cells will show the corresponding graphs. Programming mode may be more convenient when starting new projects, preparing the data, and for more advanced work. It is also easier to explain in a paper, which is why we prefer it here.
The help screen for the package lists about 60 items but, discounting the service functions, the generic plot, coef, and print functions, and the data examples, the user will mostly deal with about 12 functions. For a package of this size, this is quite a modest number. All functions have been designed to output objects that can be passed right away to other functions, and typically accept ‘predicates’ to subset the data on any combination of person and/or item properties. The data is supposed to come from a dexter data base channel, but any object containing admissible data will be accepted. Admittedly, it takes some practice to learn what data is admissible in a given situation, and going over all the steps in creating a dexter project (i.e., data base) and populating it with data is time well spent, as it will help a lot against involuntary mistakes and data issues. Many functions either produce plots or are equipped with generic plot functions, as we put much value in visual control and evaluation.
The functions can be grouped loosely in seven categories:
Functions to start, open, or close a dexter project, input data, define person and item properties, or get information on booklets, items, persons, test design, scoring rules, etc;
Functions to evaluate item quality and test reliability. These are typically applied per booklet and include tia_tables, distractor_plot, fit_inter, and fit_domains;
A single function, fit_enorm, to ‘calibrate’ the test, i.e., estimate item parameters for the test as a whole;
Functions to estimate person proficiency. These fall into two groups: functions such as ability and ability_tables will be more useful when dealing with high stakes tests, while functions such as plausible_values and plausible_scores are more adapted for (large scale) survey research. Function individual_differences, which provides a formal test against the hypothesis that all persons have the same latent ability, also belongs in this group;
Functions that deal with interactions between person and/or item properties, e.g., DIF, profiles, latent_cor;
A variety of functions grouped under the name ‘functions of theta’ compute expected scores (expected_score) or test and item information functions (information), simulate responses (r_score), and so on;
All other functions, for example those providing support for standard setting.
The following short example should provide an idea of the workflow and highlight some of the more interesting features.
2.1. Data Entry
dexter can be used in a casual way, but to benefit from all data controls and diagnostic tools, it is best to start by creating a data base. This is done with the function start_new_project, which requires the user to provide an exhaustive list of all items in the test, all admissible responses, and the score that will be assigned to each response. This is simply a data frame with three columns: item_id, response, and item_score (as in several other functions, the column names matter but the order is arbitrary). Creating it can be boring when the test is large, but the information will usually be available in some form and can be reshaped as necessary.
All scores must be integers, and the minimum score for each item must be 0. They need not be consecutive numbers. dexter will check that every item has at least two distinct scores, that the minimum score is 0, and that there are no duplicate score definitions. Should the data contain a response not specified in the rules, there are two options. The default behavior is to exit with an error message; as an alternative, all unknown responses will be treated as missing value indicators, added to the known rules, and automatically assigned zero scores. Obviously, the latter is not good practice. Getting explicit with the score rule definitions pays off in many ways. For example, it is possible to implement some forms of formula scoring, e.g., score non-response as 1, a wrong response as 0, and a correct response as 4. In addition, it is possible to define different indicators for ‘omitted’ and ‘not reached’, score the former as 0 (or something else) and omit the latter with an appropriate predicate in the functions that will calibrate the model and estimate person parameters. The thing to remember is that, whenever dexter knows that an item is supposed to be administered to a person by design, it expects to see a response; if that is coded as missing or actually missing (possible when the data is in long format), the default behavior is to assign automatically a score of 0, unless a different score is specified explicitly in the scoring rules.
Items that are scored by human raters can be handled with trivial scoring rules where the score is the same as the response. dexter saves only the original responses and the scoring rules, while scores are assigned on the fly; this makes it easy to correct wrong keys by just editing the scoring rule with function touch_rules.
As a small example, we use a small data set from another R package, irtoys [
16]. The
Unscored matrix contains the original responses to 18 multiple choice items from 472 persons. To create a new database, we will turn the matrix into a data frame, apply the
keys_to_rules helper function to generate the scoring rules table, and pass that to function
start_new_project. The R function
sprintf is useful in creating sortable variable names. The data base will be saved to memory, which is specified with the special syntax
:memory:; for permanent storage, provide a file name instead. Once the project has been created, simply add the data with function
add_booklet, where
’one’ is an arbitrary booklet ID that can be referenced in later function calls.
data = as.data.frame(irtoys::Unscored)
names(data) = sprintf(’item%02d’,1:ncol(data))
keys = data.frame(
item_id=names(data),
noptions=4,
key=c(2,3,1,1,4,1,2,1,2,3,3,4,3,4,2,2,4,3))
rules = dexter::keys_to_rules(keys, TRUE)
db = dexter::start_new_project(rules, ’:memory:’)
dexter::add_booklet(db, data, ’one’)
Our data set only contains the responses. dexter will assign unique person IDs automatically. It is possible to supply person properties, including user-defined IDs, but they must be declared with the start_new_project function; any variables in the data frame that are not known items or declared person properties will be ignored quietly. Person properties can also be added later with the add_person_properties function (an occasion where the user’s own person IDs might be handy), and there is a similar function to add item properties.
More booklets can be added by calling add_booklet repeatedly. dexter will deduce the test design, and functions get_design and design_info will provide information about it. In particular, the latter function will check whether the design is connected. In today’s practice, and especially with computer-based testing, the data may contain a large number of distinct booklets or already be in long shape; function add_response_data (see below) will be more convenient in such cases.
2.2. Tidy Data Structures, Querying, and Subsetting Data
dexter is fully compatible with the data structures and general philosophy that became more popular thanks to the ‘opinionated collection of R packages’, tidyverse [
17]. Test data is represented essentially as person-item-score triples while person properties, item properties, test design, etc., are kept in appropriately indexed separate tables.
Users who already have the test data in long format can input it directly, but they will need to specify the test design. To save typing, we will cheat a bit, using objects that we already have: we will query the design with the get_design function, show how it looks, pivot the original data to long shape with the appropriate function from the tidyr package, and input the result into a new project.
ds = dexter::get_design(db)
head(ds)
# booklet_id item_id item_position
# 1 one item01 1
# 2 one item02 2
# 3 one item03~3
data$person_id = 1:nrow(data) # must have person IDs for pivoting
data = tidyr::pivot_longer(data, cols=1:18,
names_to=’item_id’, values_to=’response’)
data$booklet_id = ’one’
head(dat)
# A tibble: 6 x 4
# person_id item_id response booklet_id
# <int> <chr> <int> <chr>
# 1 1 item01 2 one
# 2 1 item02 3 one
# 3 1 item03 1~one
db = dexter::start_new_project(rules, ’:memory:’)
dexter::add_response_data(db, data, design=ds, auto=TRUE)
A bunch of functions with names starting in get_ return information about the booklets, the items and their properties (if any have been supplied), the persons and their properties, the scoring rules, or simply query the data base for responses or test scores. Of particular interest is the function get_variables, which returns the list of all variables available for analysis, whether technical, item properties, or person properties. A great advantage of having the proper (tidy) data structures is that all variables, whether on the person or on the item side, are treated on equal basis and can be freely combined.
Most of the functions in dexter accept predicates as a parameter: any logical expression, possibly rather complicated, of any of the available variables. This allows the user to extract subsets of the data in a very flexible way. As subsetting can be applied to the functions independently, we can, e.g., estimate a model on one subset of examinees and then use the item parameters to generate plausible values for a different subset of persons.
2.3. Item and Test Diagnostics
There are several useful tools used to examine the quality of test items. Function
tia_tables returns a list of data frames containing the well-known classical test theory (CTT) statistics at item and booklet level; these can be easily prettified with packages such as huxtable [
18] or used in programming. We highly value visual tools to explore how items ‘behave’ and how well the calibration model fits the data. Basically, there are two of them: the
distractor plot, which can be produced with the
distractor_plot function, and the
item-total regressions obtained by applying the generic
plot function to the output of function
fit_inter. This is a phase of analysis where the companion package, dextergui, can be very handy because it combines tabular and graphical output into an easy-to-navigate whole.
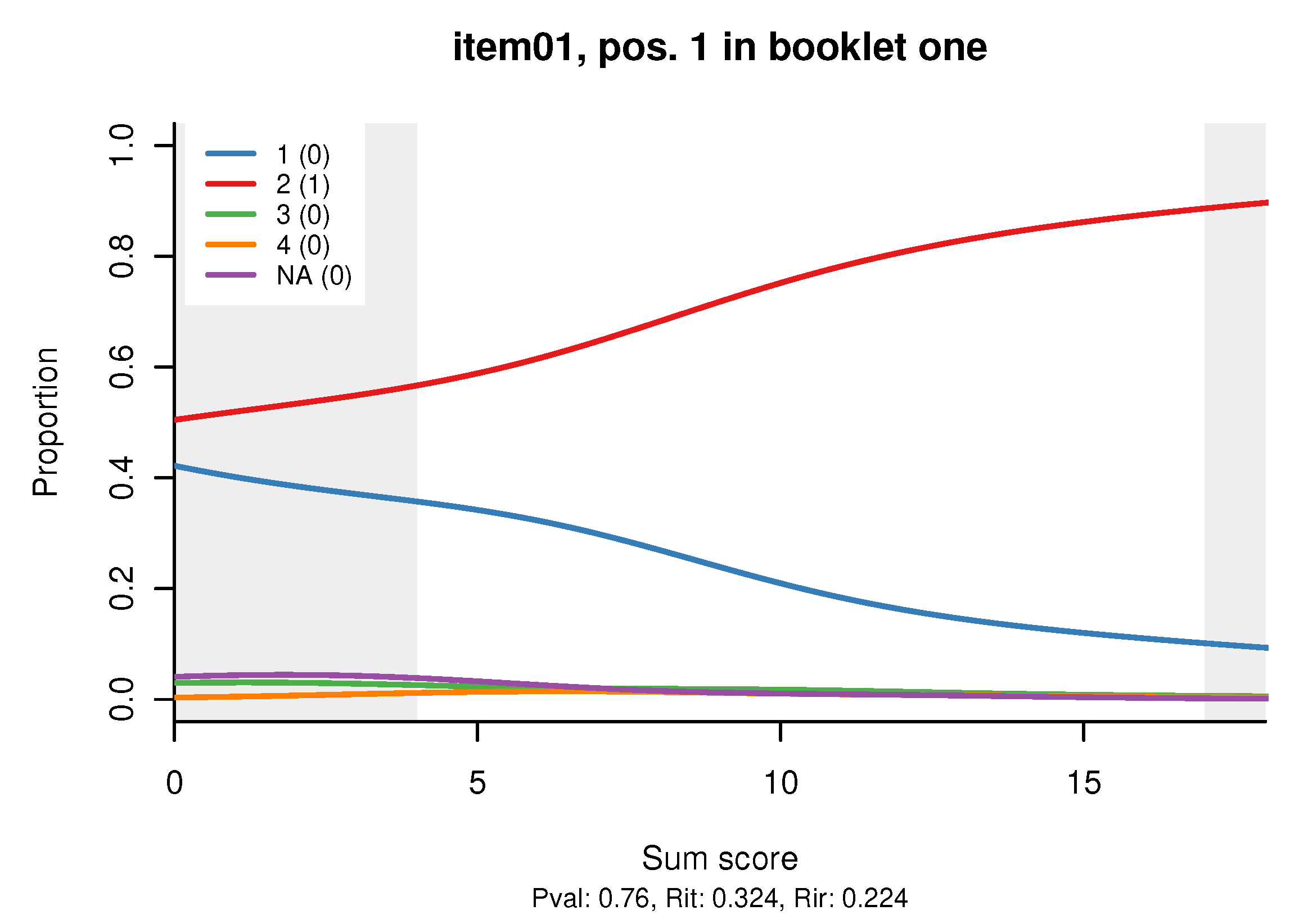
The distractor plot shows a non-parametric regression of the relative frequency of each response alternative, including non-response, on the sum score for the booklet. A separate plot is produced for each booklet that contains the item. The distractor plot for the first item in our small example is shown on
Figure 1. The title of the plot shows the item ID, in what booklet the item is featured, and in what position. At the bottom, we see the basic CTT statistics: proportion correct (Pval), item-total correlation (Rit), and item-rest correlation (Rir); the strange acronyms come from practice, including the irritating habit of calling the proportion of correct responses ‘
p-value’. The legend shows the responses and the scores that they are assigned—in our example, 2 is the correct response earning an item score of 1, while all other responses are scored 0.
In a well-constructed multiple choice item, the line for the correct response is expected to be monotone increasing (more or less, since it is produced by density estimation of real data). The lines for the wrong responses (the ‘distractors’) should be decreasing, preferably monotone decreasing. The distractor plot makes it easy to spot items with wrong keys, an error that can be corrected easily and without data loss with the
touch_rules function. Furthermore, we expect all distractors to ‘work’, i.e., have some plausibility for examinees who do not know the correct response. The item on
Figure 1 is badly written, because responses 3 and 4 are too obviously wrong for all examinees, effectively turning the item into a toss-a-coin affair for those of low ability.
The light gray areas, which we call curtains, cover the bottom and the top 5% of the observed data, helping the eye concentrate on the central 90% (there is a parameter to change the 5% to a user-specified value).
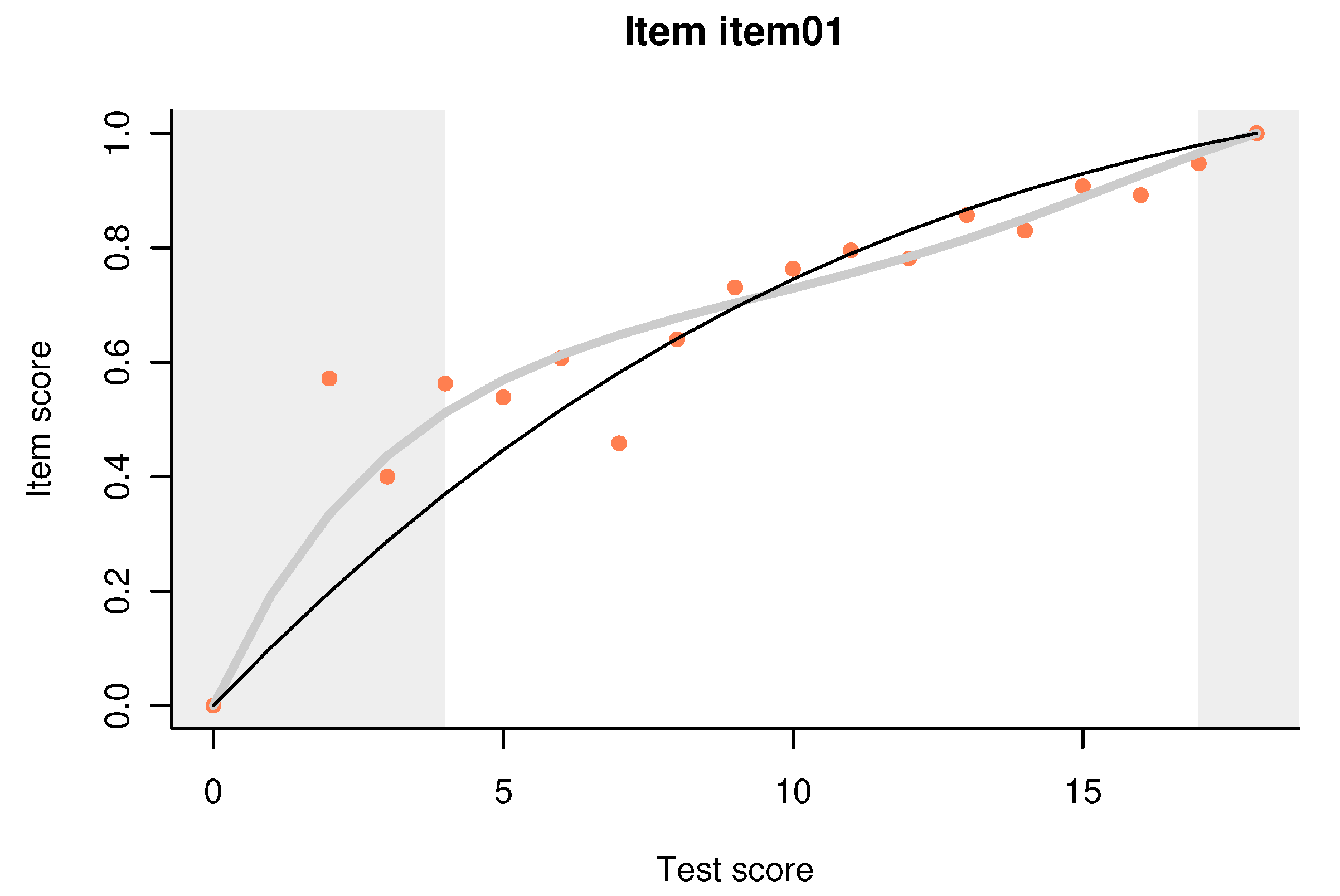
Unlike the distractor plot, the item-total regression plot is model-based. An example using the same Item 1 is shown on
Figure 2. To produce such plots, we apply the
fit_inter to the data for a specific booklet, and then we pass its output to the generic plot function. The plot compares three item-total regressions. The observed one, shown with light pink dots, is merely the proportion of correct responses to the item among persons with a given total score on the booklet. The thin black line represents the regression predicted by the
enorm–the model that will be used to estimate the item parameters for the test as a whole, but here applied locally to just the data for the specific booklet. The thick gray line depicts a similar regression predicted by Haberman’s interaction model [
19]. The two models are discussed in some mathematical detail in
Section 3; here we provide a brief and intuitive description.
The calibration model in
dexter is the extended nominal response model (
enorm). This is a nominal response model [
9] with known integer score parameters. From the user’s perspective,
enorm is not much different from the Rasch model (RM) for the dichotomous items, and the partial credit model (PCM) otherwise. There are some important improvements under the hood, the most visible of which is that we can have partial credit items whose categories are not necessarily coded with adjacent integers. Tests of language proficiency, for example, are abound in such items, and there are situations in longitudinal or comparative surveys when some response categories are not observed in some waves but observed in others.
enorm provides an elegant solution to producing consistent (in the general sense) estimates of the item parameters in such situations.
In the original formulation by Haberman, the interaction model (IM) is essentially a Rasch model with the assumption of conditional independence relaxed. When the Rasch model does not fit the data well, there are two options: preserve conditional independence but give up the sufficiency of the sum score (the 2PL model), or give up conditional independence but preserve sufficiency (the IM). The IM is thus a parametric, exponential family model that reproduces the item difficulties, the correlations of the item scores with the total scores on the test, and the total score distribution. In other words, it captures all aspects of the data that are psychometrically relevant, leaving out mostly random noise. It is intuitively clear that the comparison between the two model-based regressions can help us concentrate on systematic differences; in
Section 3, we relate it to a long tradition in assessing the goodness of fit in Rasch models.
Note that both axes in
Figure 2 refer to observable quantities. In addition, all regressions are pegged to the lower left and upper right corners because all persons with a test score of zero must have an item score of 0, and similar logic applies to the perfect test score. One consequence of this is that the curve for the IM resembles a cubic polynomial when it is flatter in the middle compared to the
enorm curve. In our long practice, we have not seen a plot where the pink dots did not cluster around the IM curve: as the sample size increases, the observed regressions get estimated more precisely and the dots get closer and closer to the IM line.
Our example item is dichotomous. We have generalized the IM to polytomous items. The default behavior in that case is to plot the item score in place of the proportion correct, but there is an option to show regressions for the category probabilities instead.
2.4. IRT Analysis: Estimating the Calibration Model
This is easy:
fit_enorm(db),
, done. Additional flexibility can be achieved by using a predicate. We have already mentioned one possible use: to exclude items not reached from the calibration, but one can think of many others. By popular demand, there is the possibility to fix the parameters for some items to prespecified values. Last but not least, there is a choice between two estimation models: CML [
20] or Bayesian estimation through a Gibbs sampler [
21]. The function returns an object that is best passed directly and as a whole to other functions, notably the ones that estimate person parameters. Its structure depends slightly on the choice of estimation technique. When CML estimation is used, there is a single set of parameter estimates; if the user chooses Bayesian estimation instead, there will be a set of samples from the posterior distribution of the item parameters. Applied to the output object, the generic coef function will show the parameter estimates and their standard errors; in the case of Bayesian estimation, the output contains the posterior means, the posterior standard deviations, and the 95% highest posterior density intervals. Other statistics can be produced easily: for example, the posterior medians and the medians of absolute deviation (MAD) can be computed as:
m = dexter::fit_enorm(db, method=“Bayes”)
pmed = coef(m, what=’posterior’) |> apply(2, median)
pmad = coef(m, what=’posterior’) |> apply(2, mad)
The generic function plot will produce familiar-looking plots of item fit with the latent variable on the horizontal axis.
2.5. IRT Analysis: Estimating Student Ability
Arguably, IRT has two main practical advantages, and they both relate to the ultimate purpose of educational tests: personal assessment. One is an optimal, theoretically grounded method used to equate the scores gained on similar but distinct test forms, and it is of crucial importance to high-stakes summative assessment. The other is the ability to obtain random samples from a person’s true distribution of (latent) ability given their responses and the item parameter estimates; known as
plausible values, these play a vital role in large scale educational surveys [
22]. Although related, the two approaches do not mix very well: plausible values are not appropriate in assessment because of the random variability they contain, while the traditional ability estimates are suboptimal in the study of student (sub)populations.
dexter tries to be useful in both situations. For assessment, there are the ability and the ability_tables functions, and for research one can use the plausible_values and plausible_scores function. However, before looking at them, why not ask the more basic question: what if there are no true individual differences in ability? This is similar to an IRT-based test as the reliability is zero, which can be performed with function individual_differences:
dexter::individual_differences(db)
# Chi-Square Test for the hypothesis that all respondents
# have the same ability:
# Chi-squared test for given probabilities with simulated p-value
# (based on 2000 replicates)
# X-squared = 328433, df = NA, p-value = 0.0004998
Function
ability takes as minimum arguments a data source and a set of item parameters, and returns a data frame of four variables: the booklet ID, the person ID, the sum score, and the ability estimate. The default estimation method is MLE; the other choices are EAP (expected a posteriori) [
23] or Warm’s weighted maximum likelihood estimator (WLE) [
24].
Function ability_tables returns a data frame with the booklet ID, the (unequated) booklet sum score, the corresponding (equated) ability estimate, and the standard error of the latter. If grade reporting is done on equated scores, the correspondence can be established easily from the table.
Before proceeding to plausible values and scores and thus to the world of surveys, let us discuss briefly two other functions related to equating and standard setting. Given a reference test with a specified threshold score to pass, function
probability_to_pass estimates the equivalent score in a target test, based on ideas from ROC analysis [
25,
26]. Use the generic coef method to extract the probability to pass for each booklet and score, and the generic plot function to display plots of the probabilities, sensitivity and specificity, and the ROC. This is another method unique to
dexter and of interest beyond psychometrics because it extends the popular ROC analysis to situations where a large part of the data is missing by design.
The data driven direct consensus (3DC) method of standard setting was invented by Gunter Maris for the First European Survey of Language Competencies [
27]; see also Ref. [
28]. The method can be applied traditionally using paper forms, or (preferably) the standard setting sessions may be computerized, in which case the we advise to use the free digital 3DC application available from the Cito website.
dexter has functions to support both paper-based and computerized standard setting.
In research or survey settings, the preferred way to approach ability is through plausible values. In spite of the great popularity resulting from their ubiquitous use in large scale assessment projects, it would be wrong to think that plausible values can be computed in one single (and well documented) way. To understand how surveys such as PISA or TIMSS produce them, it is best to go back to the original description [
29]. With the parameters of the IRT model (common across countries), the test responses, and the persons’ background variables all being constant, the only factor that makes the plausible values for a given person different is apparently a random sampling from the (multivariate normal) distribution of the regression coefficients of ability on the background variables. This makes it easier to understand why background variables play such an important role in the methodology of these surveys.
dexter takes a different approach to generating plausible values: it uses a highly efficient Gibbs sampler based on composition and rejection algorithms [
30]. It does not place so much emphasis on background variables because theory shows that the algorithm will converge to the true distribution of the latent trait—but more efficiently if we can start with a prior that is a reasonably good guess. The package vignette on plausible values discusses an example in which the true distribution of ability is grotesquely bimodal. The sampler will converge to the true distribution with a shorter test if it starts with an appropriate prior; however, with a test of sufficient length the true distribution will be reproduced even if we use a standard normal prior. Currently,
dexter offers three kinds of priors:
A common normal prior for all persons;
A mixture of two normal distributions not related to any background variable but expected to accommodate many situations (asymmetry, heavy tails, etc.) more flexibly than a normal prior;
A hierarchical normal prior with a group for each category of one or more nominal background variables.
Similar to ability and ability_tables, the plausible_values function can take the object returned by fit_enorm as one of the parameters. If item parameters have been estimated by CML, the single set of estimates are held constant. A special feature in dexter that, to the best of our knowledge, is not available in any other package, is the ability to condition each draw from the posterior distribution of ability (i.e., each PV) on a different draw from the posterior distribution of item parameters. We believe that this approach better captures all sources of uncertainty inherent to the measurement.
There is also a
plausible_scores function. In a design with planned missingness, it produces plausible scores for all items: the person’s actual scores on the administered items are retained, and scores for the ones not administered are predicted based on plausible values. Ref. [
31] showed how plausible scores can be used to relax the IRT model in international surveys by applying the market basket approach.
2.6. Measurement Invariance
dexter has two functions to investigate for measurement invariance: DIF is more exploratory and useful when there are known groups (defined by a categorical person property) but no a priori hypotheses on the item side, while profile_plot is applicable when both a person property (groups) and an item property (domains) are known in advance and of interest. Both functions are rather different from the techniques found in other packages, so we need to describe them in some detail.
Arguably, the original problem of differential item functioning (DIF) has subsided over time as item writers have gotten better and better at producing culturally neutral items. However, there are new challenges. On the substantive side, large-scale assessment projects have wider coverage than ever, aiming to compare the output of widely different educational systems. In such a situation, it may be more rewarding to study measurement invariance than merely try to overcome it. On the methodological size, conceptualizing DIF has proved to be more challenging than expected, such that there is still active work on the topic [
32].
One of the issues with many techniques used to detect DIF is that they are not invariant to the choice of identification constraints in the IRT model. Imagine a plot of item difficulties estimated in two groups; say boys and girls. The plot will reveal some structure and that structure will not change if we set the difficulty of one or another item to zero for identification purposes. The problem is that the conclusion about
which items have DIF can depend dramatically on that arbitrary and fully admissible choice. To avoid this pitfall, Bechger and Maris [
33] proposed to concentrate on the structure of DIF rather than the individual item. The idea is to consider, instead of the inter-group differences in item difficulties, the inter-group differences between the matrices of inter-item differences—thus, to turn the study of differential item functioning into a study of differential
item pair functioning. Such an approach not only eliminates the impact of the arbitrary identification constraints but also offers additional insight into the structure of DIF by identifying groups of items that ‘behave’ in a similar way.
We will illustrate with a well-known data set on verbal aggression [
34], which is available in many R packages, including
dexter. A total of 243 women and 73 men answered on a 3-point scale (‘yes’, ‘perhaps’, or ‘no’) how likely they are to become verbally aggressive in 4 different frustrating situations. Further facets include whether the situation was caused by others or by themselves, the intensity of the verbal reaction (curse, scold, or shout); finally, the variable mode indicates whether the verbal behavior would actually be activated or just desired.
The syntax to compute the DIF statistics is shown below. Note that gender is declared as a person property when the project is created. gender="unknown" defines a default value that will be overwritten by the actual values. The output is an object that contains an overall DIF statistic and two square, skew-symmetric matrices, Delta_R and DIF_pair. Delta_R is computed as the difference between the two square matrices of pairwise differences between the item difficulties, as estimated for men and women separately. DIF_pair is obtained by dividing each element of Delta_R by its estimated variance; thus, it is the matrix of standardized differences, or effect sizes.
dich = dexter::verbAggrRules # provided with the package
dich$item_score[dich$item_score==2] = 1 # dichotomize the items
db = dexter::start_new_project(dich, ":memory:",
person_properties=list(gender="unknown"))
dexter::add_booklet(db, verbAggrData, "agg")
d = dexter::DIF(db, ’gender’)
str(d)
# List of 5
# $ DIF_overall :List of 3
# ..$ stat: num 68.8
# ..$ df : num 23
# ..$ p : num 1.86e-06
# $ DIF_pair : num [1:24, 1:24] 0 -0.819 1.005 1.43 1.347 ...
# $ Delta_R : num [1:24, 1:24] 0 -0.391 0.484 0.688 0.632 ...
# $ $ group_labels: chr [1:2] "Female" "Male"
# $ items :’data.frame’: 24 obs. of 2 variables:
# ..$ item_id : chr [1:24] "S1DoCurse" "S1DoScold" ...
# ..$ item_score: int [1:24] 1 1 1 1 1 1 1 1 1 1 ...
# - attr(*, "class")= chr [1:2] "DIF_stats" "list"
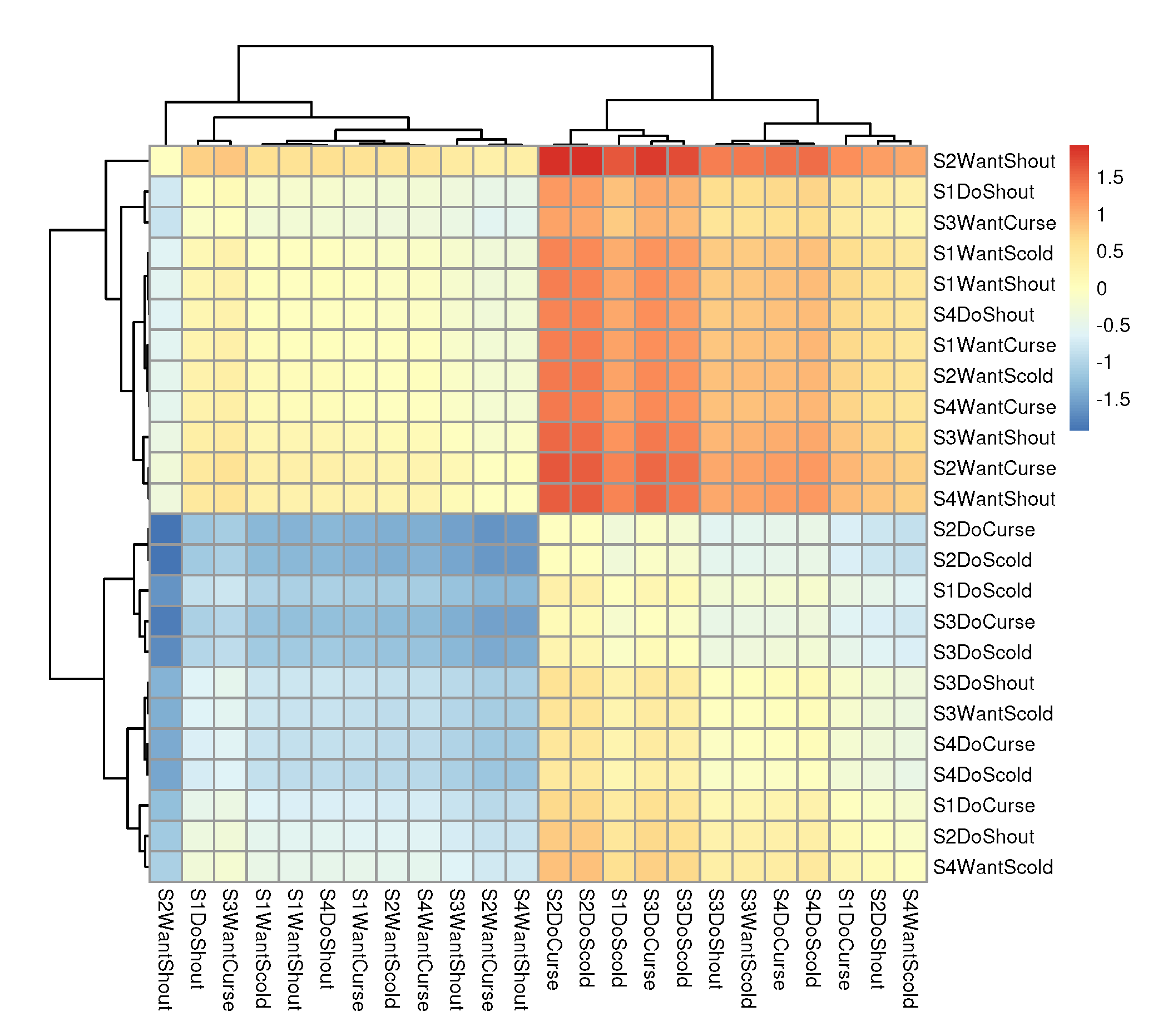
The easiest way to understand these matrices is by plotting them as heatmaps. For example,
Figure 3 displays a heatmap of the unstandardized differences (
Delta_R) produced with the code below. The default clustering of rows and columns readily reveals two groups of items defined primarily by the mode of behavior: ‘Do’ vs. ‘Want’. The relative difficulty of Do and Want items is different for men and women.
rownames(d$Delta_R) = colnames(d$Delta_R) = d$items$item_id
library(pheatmap)
pheatmap::pheatmap(d$Delta_R)
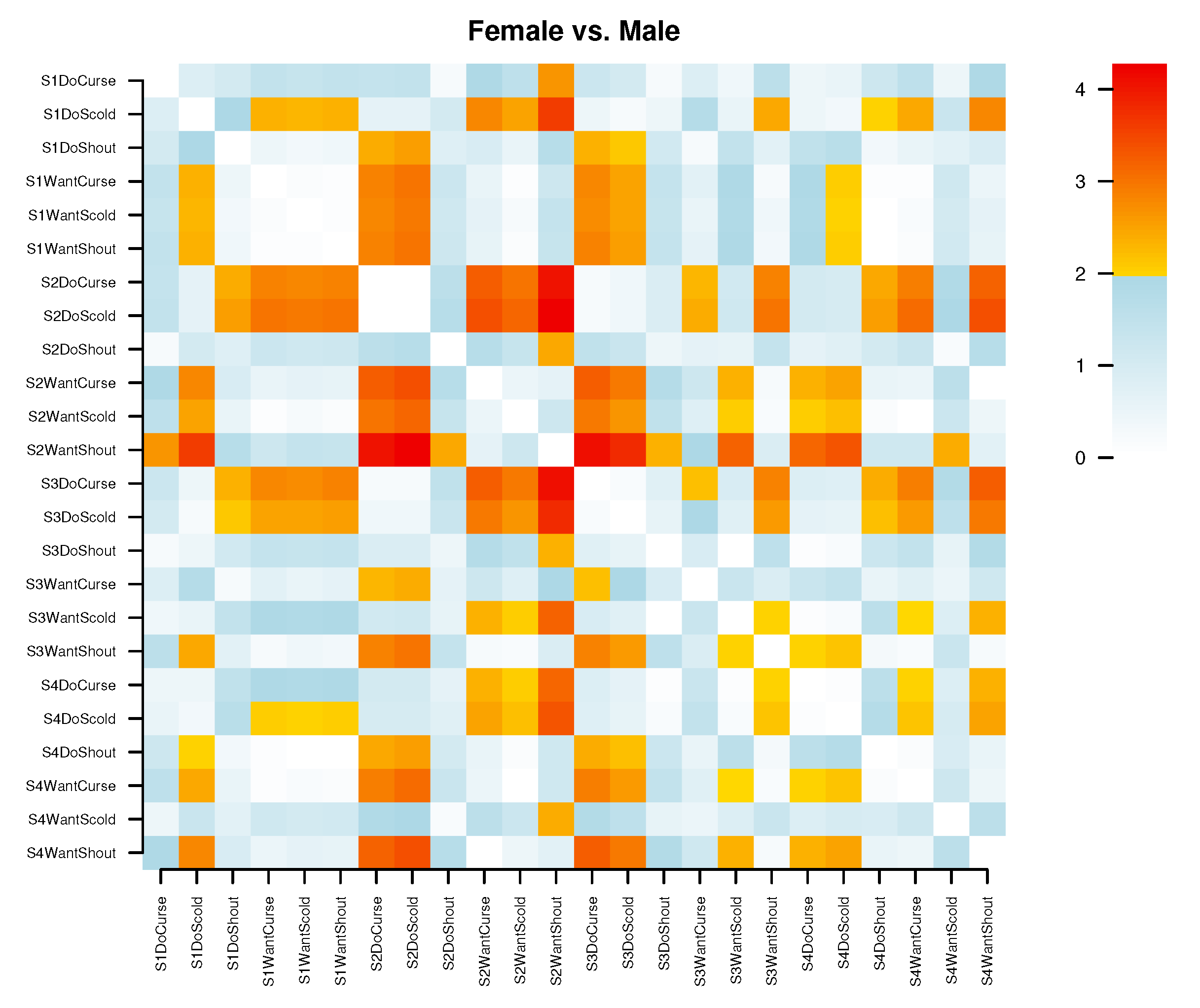
The generic
plot function produces a somewhat different display as shown on
Figure 4. This is based on the absolute values of the effect sizes (the skew-symmetric matrix becomes symmetric), and the color scheme is calibrated such that values between 0 and 1.96 are shown in shades of blue while those exceeding the critical value progress from yellow to red (the critical value can be changed with parameter
alpha). The plot is not clustered but it can be rearranged by passing the item IDs in any desired order: alphabetically, by some item property, sorted by cluster analysis etc.
The generic print function prints the overall DIF statistic, which is highly significant for this example:
print(d)
# Test for DIF: Chi-square = 68.798, df = 23, p = < 0.0006
These plots are exploratory with respect to the item grouping while the person groups are assumed known. When there are predefined groups of persons
and items, a more useful tool is provided by the
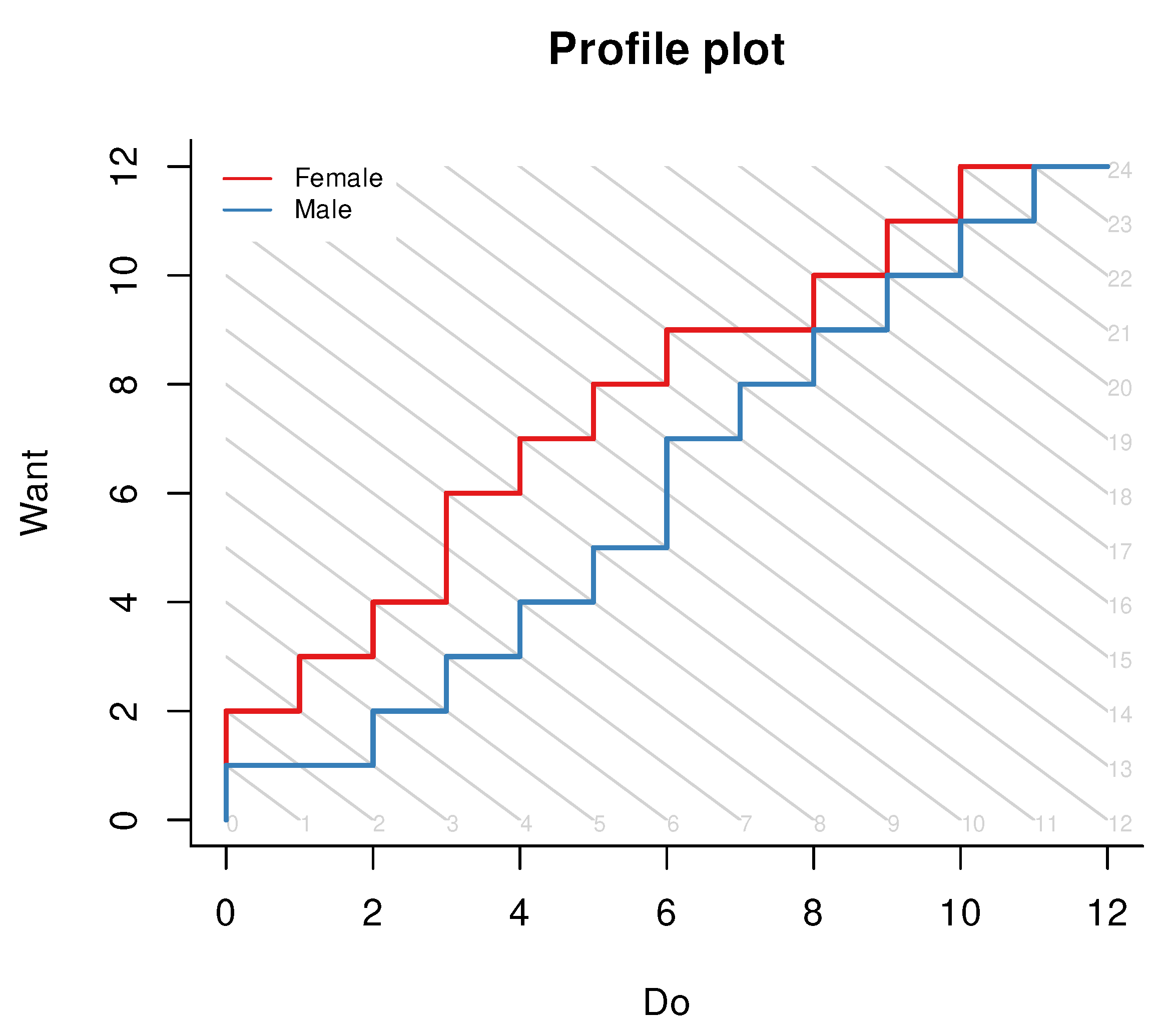
profiles and
profile_plot functions. These follow the logic of profile analysis as proposed by Verhelst [
35] although we do not compute all the statistics therein. Profile analysis is an intuitive and robust diagnostic test, and it can be very helpful when the test is not perfectly unidimensional. For example, if we have items on algebra, geometry, and probability, it is our choice (and responsibility) whether to produce three unidimensional tests, a multidimensional test, or at least perform profile analysis as a kind of residuals analysis within the univariate test covering the three domains. Conditional on the overall sum score gained by the person, profile analysis estimates expected domain scores, which can be compared with the observed domain scores. The vector of observed domain scores is called the observed profile, the vector of expected domain scores is called the expected profile, and the vector of their differences is called the deviation profile. If the profiles are purely individual, the deviations can be expected to cancel when aggregating over teachers, schools, or countries; otherwise, they can provide useful information on systematic effects due to differences in teaching quality or policy.
Continuing with the verbal aggression example, we add the item property, mode, to the data base, and we compute the profiles as follows:
dexter::add_item_properties(db, verbAggrProperties)
f = dexter::fit_enorm(db)
p = dexter::profiles(db, f, ’behavior’)
The output is a data frame with the person ID, booklet ID, test score, item property, and observed and expected domain score. Verhelst’s original software, Profile-G, will aggregate individual profiles over groups and provide a covariance matrix. We have not implemented all these features, but profiles can be summarized and analyzed easily in R, for example:
dexter::profiles(db, f, ’mode’) |>
dplyr::inner_join(get_persons(db)) |>
dplyr::group_by(gender,mode) |>
dplyr::summarize(os=mean(domain_score),
es=mean(expected_domain_score),dv=os-es) |>
tidyr::pivot_wider(id_cols=’gender’,names_from=’mode’,values_from=’dv’)
# gender Do Want
# <chr> <dbl> <dbl>
# 1 Female -0.191 0.191
# 2 Male 0.635 -0.635
When the item property has two categories (or has been dichotomized in a sensible way), we can use the
profile_plot function to build a profile plot similar to the one shown on
Figure 5. The two axes show the two domain scores while the gray lines join the points where the two domain scores add up to the same sum scores. For each person group, there is a stairlike line joining the modal (most frequent) combination of domain scores for the person group at each test score. This may sound convoluted, but a single glance at our example plot immediately reveals that, at any overall level of verbal aggressiveness, women “do” less than they “want” as compared to men.
4. A More Extensive Example
As a larger example of
dexter in action, we analyze the cognitive data from the test of mathematics, PISA 2012. We download and parse the data, create a
dexter data base, estimate the IRT model, compute five plausible values per examinee, and apply the market basket approach described in Ref. [
31].
Note that this is not a tour of dexter or a demonstration of the complete workflow: for example, we omit the test and item diagnostics, which have been discussed already, and which would be the starting point in practice. The purpose is to show dexter in action on a larger project, and to follow up the possible consequences of adopting a different approach to the generation of plausible values or allowing the IRT model to differ across countries.
Analyzing more recent waves of PISA or TIMSS is possible but more tedious because of an unfortunate decision to make the data available in the form of huge binary files for SPSS or SAS; these contain the original and the scored responses, response times, other variables and, of course, an enormous amount of missing data indicators. 2012 is the last year when data was available as ASCII files and syntax files for SPSS and SAS. We use the SAScii package [
48] to parse and interpret the SAS syntax; this makes reading the data into R quite easy.
library(dexter)
library(dplyr)
library(tidyr)
library(readr)
library(SAScii)
oecd = "http://www.oecd.org/pisa/pisaproducts/"
url1 = paste0(oecd, "INT_COG12_S_DEC03.zip")
url2 = paste0(oecd, "PISA2012_SAS_scored_cognitive_item.sas")
zipfile = tempfile(fileext=’.zip’)
utils::download.file(url1, zipfile)
fname = utils::unzip(zipfile, list=TRUE)$Name[1]
utils::unzip(zipfile, files = fname, overwrite=TRUE)
unlink(zipfile) # erase from~disk
dict_scored = SAScii::parse.SAScii(sas_ri = url2)
All mathematics items have variable names starting with PM, so it is easy to select them. We change the codes for missing values (7 for N/A and 8 for ‘not reached’) to NA, because distinguishing between them is beyond the scope of this example. The same applies to the careful diagnostic analysis of the responses with CTT and other tools, which is always necessary in practice, and for which dexter is well equipped.
data_scored = readr::read_fwf(
file = fname,
col_positions = fwf_widths(dict_scored$width,
col_names = dict_scored$varname)) |>
dplyr::select(CNT, SCHOOLID, STIDSTD, BOOKID, starts_with(’PM’))
unlink(fname) # erase from~disk
data_scored$BOOKID = sprintf(’B%02d’, data_scored$BOOKID)
data_scored[data_scored==7] = NA
data_scored[data_scored==8] = NA
Now, start a new dexter project and add the data. First we need to declare all items and their admissible scores in a rules object, which is passed to the start_new_project function.
rules = tidyr::gather(data_scored, key=’item_id’, value=’response’,
starts_with(’PM’)) |>
dplyr::distinct(item_id, response) |>
dplyr::mutate(item_score = ifelse(is.na(response), 0, response))
db = dexter::start_new_project(rules, "pisa2012.db",
person_properties=list(
cnt = ’<unknown country>’,
schoolid = ’<unknown country>’,
stidstd = ’<unknown student>’
)
)
Add the data for the 21 booklets in a loop. Conveniently, this will deduce the test design automatically:
for(bkdata in split(data_scored, data_scored$BOOKID))
{
# remove columns that only have NA values
bkrsp = bkdata[,apply(bkdata,2,function(x) !all(is.na(x)))]
dexter::add_booklet(db, bkrsp, booklet_id = bkdata$BOOKID[1])
}
rm(data_scored)
For later use, we compute a binary item property that indicates whether an item has been asked in all participating countries, and we add it to the data base:
item_by_cnt = dexter::get_responses(db, columns=c(’item_id’, ’cnt’)) |>
dplyr::distinct()
market_basket = Reduce(intersect, split(item_by_cnt$item_id,
item_by_cnt$cnt))
dexter::add_item_properties(db,
dplyr::tibble(item_id = market_basket, in_basket = 1),
default_values = list(in_basket = 0L))
When programmed properly, CML estimation tends to be fast—about 10 s on a rather unpretentious laptop, with most of the time used to fetch the data:
system.time({item_parms = dexter::fit_enorm(db)})
# user system elapsed
# 10.80 0.63 11.07
Generating the plausible values is also fast: less than 12 s for almost half a million cases:
system.time({pv = dexter::plausible_values(db, parms=item_parms, nPV=5)})
dim(pv)
# user system elapsed
# 11.44 0.50 11.93
# [1] 485490 8
Comparing against PISA is more work. We need to download a very large data file that contains all the background variables from the student questionnaire, the plausible values, and the sampling and replicate weights necessary to compute the estimates and their standard errors. This necessitated to adjust the timeout option, without which the download may time out. From the large file, we retain only the country identifier and the plausible values.
url3 = paste0(oecd, ’INT_STU12_DEC03.zip’)
url4 = paste0(oecd, ’PISA2012_SAS_student.sas’)
zipfile = tempfile(fileext=’.zip’)
options(timeout = max(300, getOption("timeout")))
utils::download.file(url3, zipfile)
fname = utils::unzip(zipfile, list=TRUE)$Name[1]
utils::unzip(zipfile, files = fname, overwrite=TRUE)
dict_quest = SAScii::parse.SAScii(sas_ri = url4)
dict_quest = SAScii::parse.SAScii(sas_ri = url4) |>
dplyr::mutate(end = cumsum(width), beg = end - width + 1) |>
dplyr::filter(grepl(’CNT|PV.MATH’, varname))
data_quest = readr::read_fwf(file = fname,
fwf_positions(dict_quest$beg, dict_quest$end, dict_quest$varname))
unlink(zipfile)
unlink(fname)
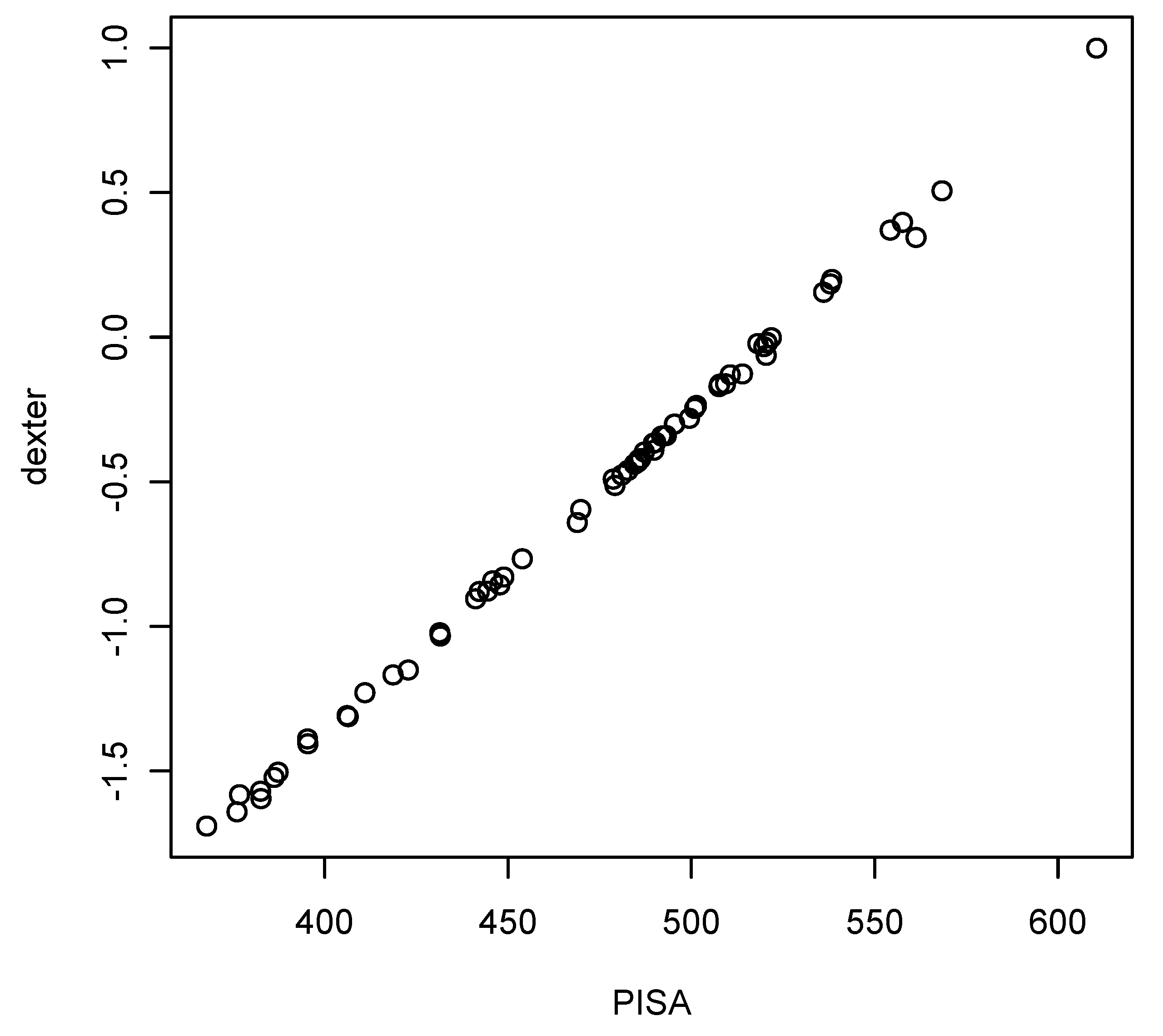
Figure 7 compares the country means of one set of plausible values as estimated by PISA and by
dexter. Given that PISA estimates item parameters by MML while
dexter uses CML, and that plausible values are computed by different methods (both of which involve random numbers), the correspondence is more than decent.
The country means compared on the plot are calculated from plausible values obtained from a common IRT model for all participating countries. Numerous studies such as Refs. [
49,
50] have found evidence of DIF in large scale international assessments, and some of them have been quite critical of the current practice, which typically involves fitting country-specific IRT model, removing items with DIF exceeding some prespecified criteria, and then fitting a common model for further analysis and comparison. Zwitser et al. [
31] argue that DIF is a natural result from the national efforts to improve education, and its study may be a more rewarding exploit than obtaining a completely DIF-free comparison. They propose an approach using country-specific IRT models that is easy to realize in
dexter with the
plausible_scores function. The following code selects responses to items that have been asked in all participating countries, fits a different IRT model in each country, and computes plausible scores (there are also some trivial adjustments for items that did not have any correct responses in a few countries). As explained in Section 1, plausible scores are sum scores over all items, where item scores for the items actually asked to the person under the incomplete design are retained ‘as is’, while item scores for the remaining items are simulated from plausible values.
basket = dexter::get_items(db) |>
dplyr::filter(in_basket == 1) |>
dplyr::pull(item_id)
basket = setdiff(basket, c(’PM828Q01’,’PM909Q01’, ’PM985Q03’))
resp = dexter::get_responses(db,
predicate = item_id %in% basket,
columns=c(’person_id’, ’item_id’, ’item_score’, ’cnt’))
ps = resp |>
dplyr::filter (item_id %in% basket) |>
dplyr::group_by(cnt) |>
dplyr::do({dexter::plausible_scores(., dexter::fit_enorm(.), nPS=1)})
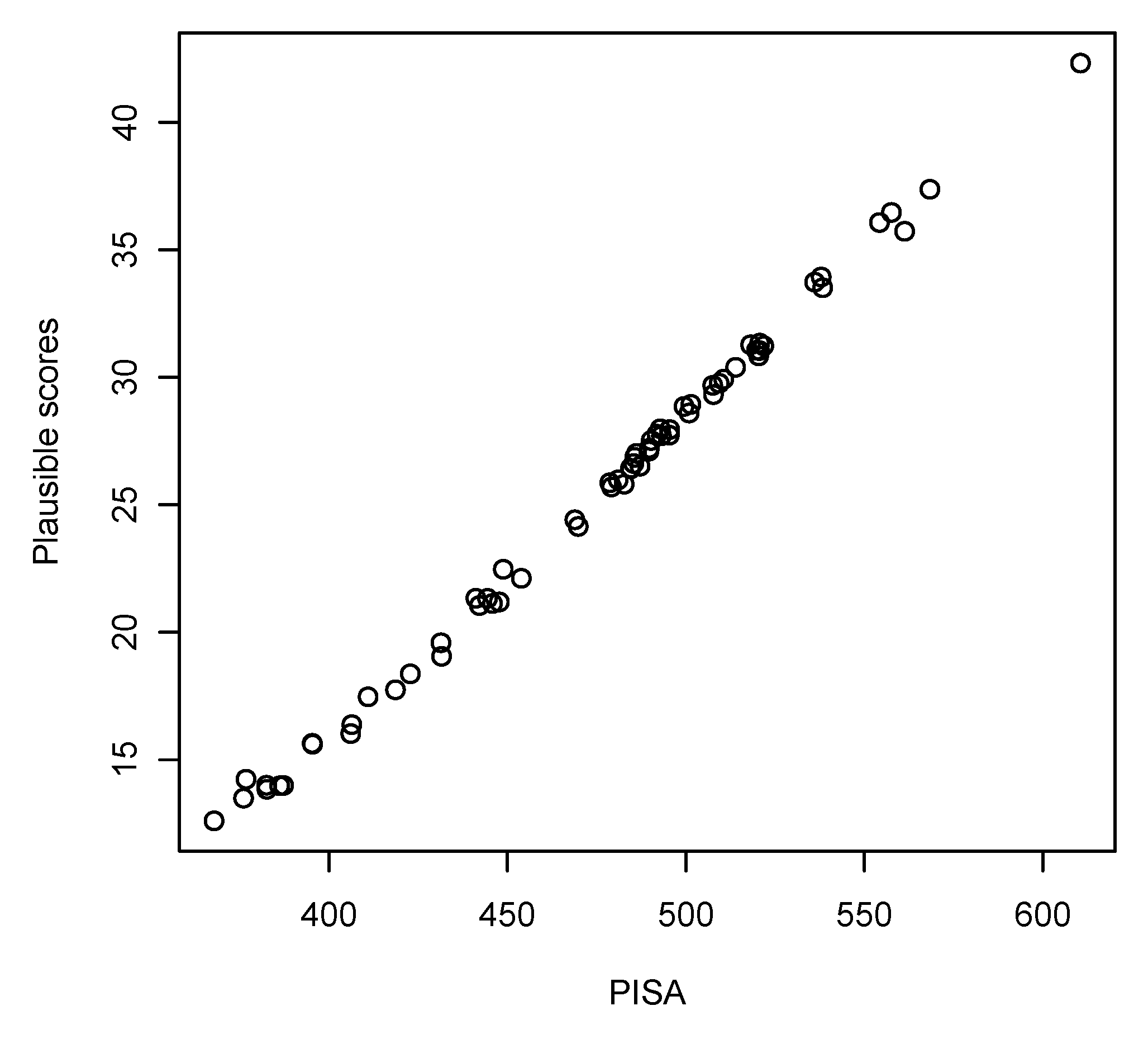
Figure 8 shows country means of a set of plausible scores produced with
dexter from country-specific IRT models against the country means of PISA’s first plausible value. The correspondence is quite decent, so it seems that using 68 country-specific IRT models instead of a common model does not make a huge difference. Of course, the items have already been screened for DIF by PISA and their number has been cut in half by the requirement to use only items that have been administered in all countries.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







