
Artificial Intelligence for Text-Based Vehicle Search, Recognition, and Continuous Localization in Traffic Videos



Abstract
:1. Introduction
- (a)
- a hashgraph algorithm is introduced for automatically computing the search query from the input text at high speed;
- (b)
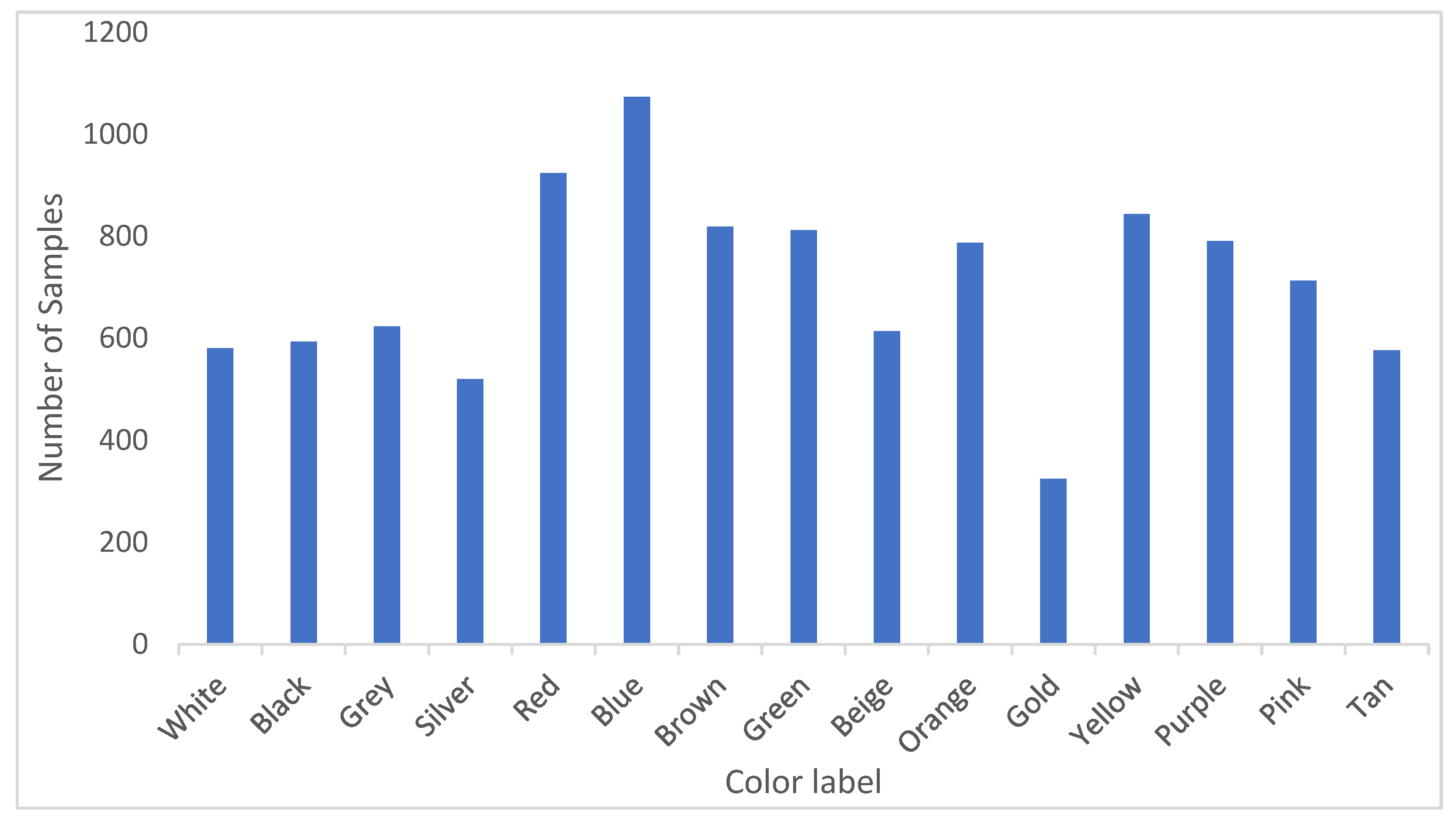
- a large scale and diverse vehicle color recognition dataset (VCoR) with 15 color classes and more than 10k images samples is proposed to facilitate training finer-grain vehicle recognition including a color description component. The creation of the VCoR dataset was motivated by the fact that the largest existing vehicle color dataset only has eight color classes, and as such will limit the localization capability (specificity) of the proposed framework.
- (c)
- V-Localize, a deep learning-based framework for text-based vehicle search and continuous localization, is proposed. A finer-grain VMMYC (Vehicle Make Model Year and Color) recognition model is trained for efficiently matching valid search targets. The training procedure is designed to account for real-world traffic scenarios and ultimately address limitations of the existing models, which are best suited for still image inputs.
- (d)
- A first of its kind VRiV (Vehicle Recognition in Video) testbench dataset for benchmarking the performance of automatic vehicle recognition models in video feeds is introduced. This dataset is aimed at addressing the lack of such testbench video datasets, which are required to drive research for vehicle recognition models more suited for live video input.
- (e)
- Lastly, because there currently exist no metrics for adequately accessing the robustness and efficiency of recognition and continuous localization models, novel metrics are intuitively proposed to address this shortcoming. These metrics establish a foundation for qualitatively benchmarking and comparing future models on recognition tasks on live video.
2. Related Work
3. Materials and Methodology
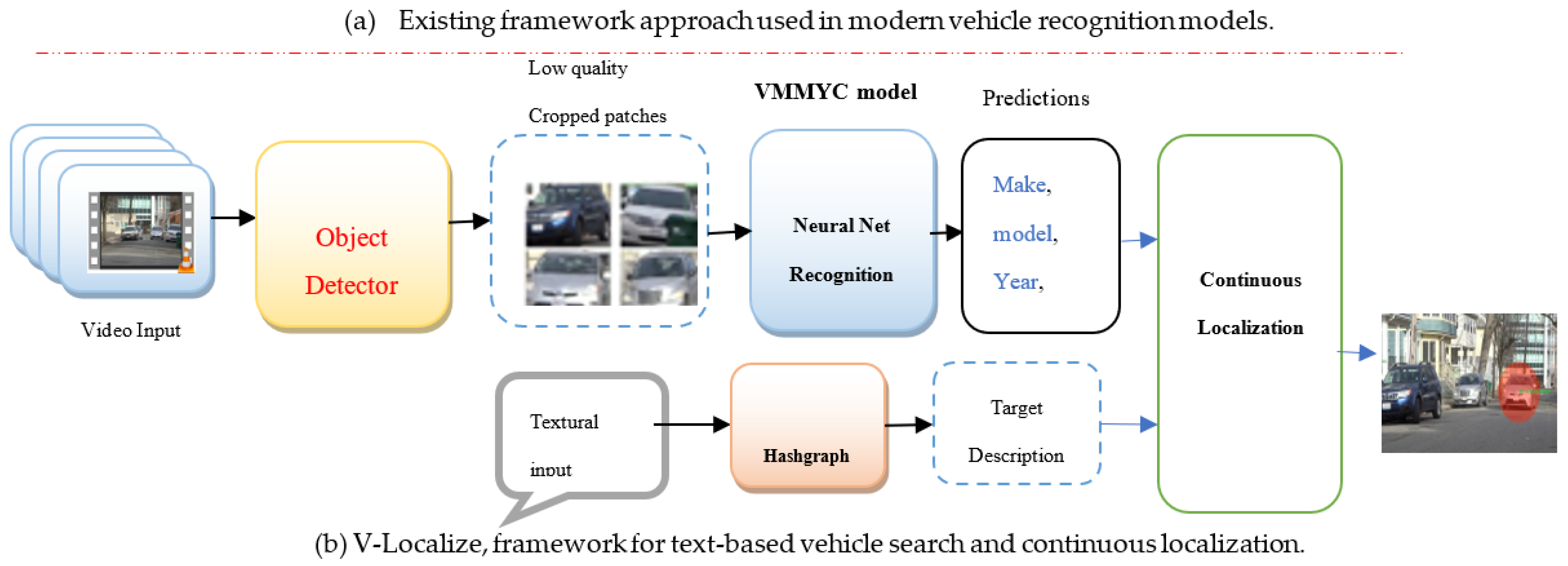
3.1. System Flow
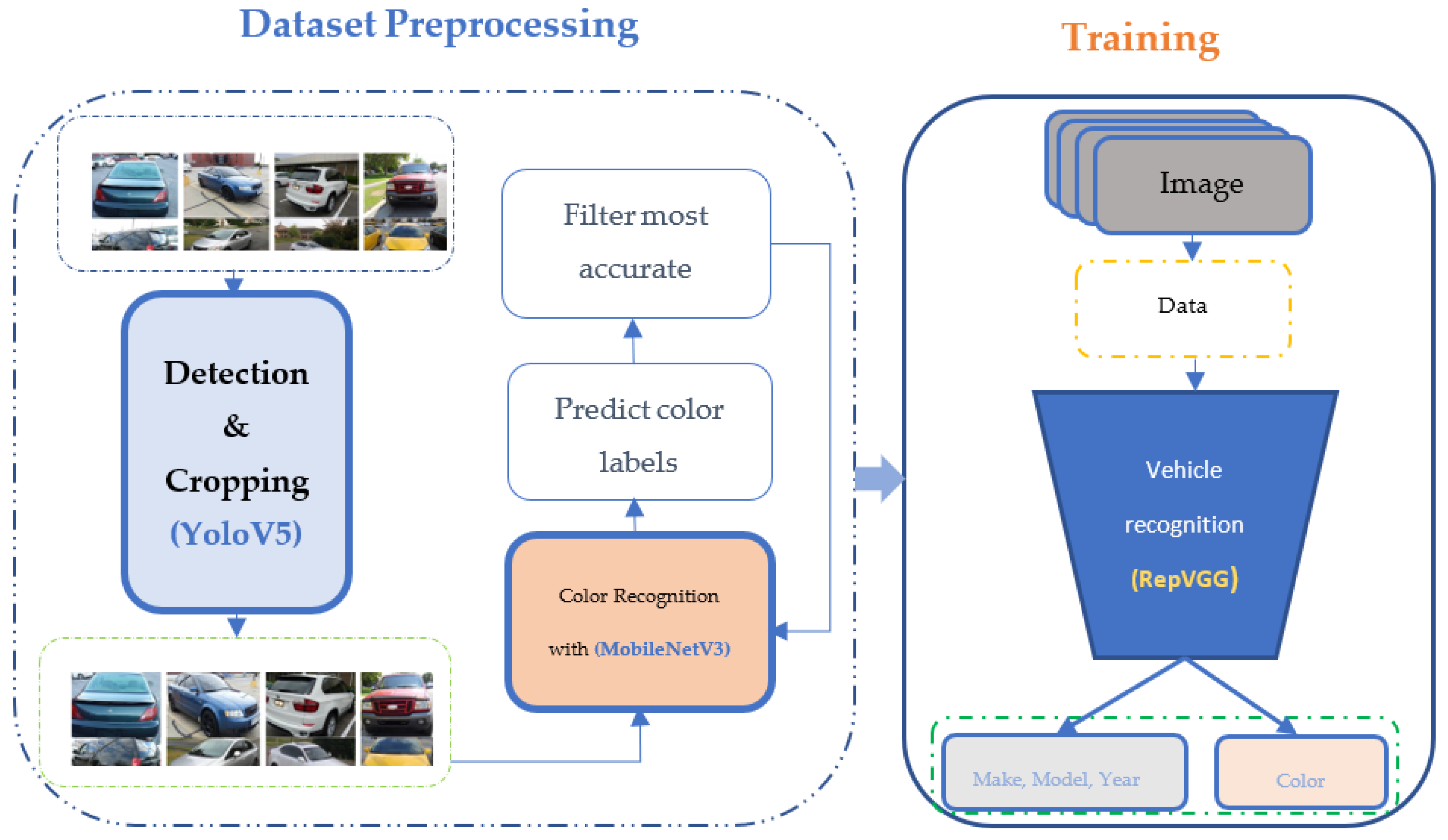
3.2. Training Pipeline for the Finer-Grain Vehicle Recognition Model
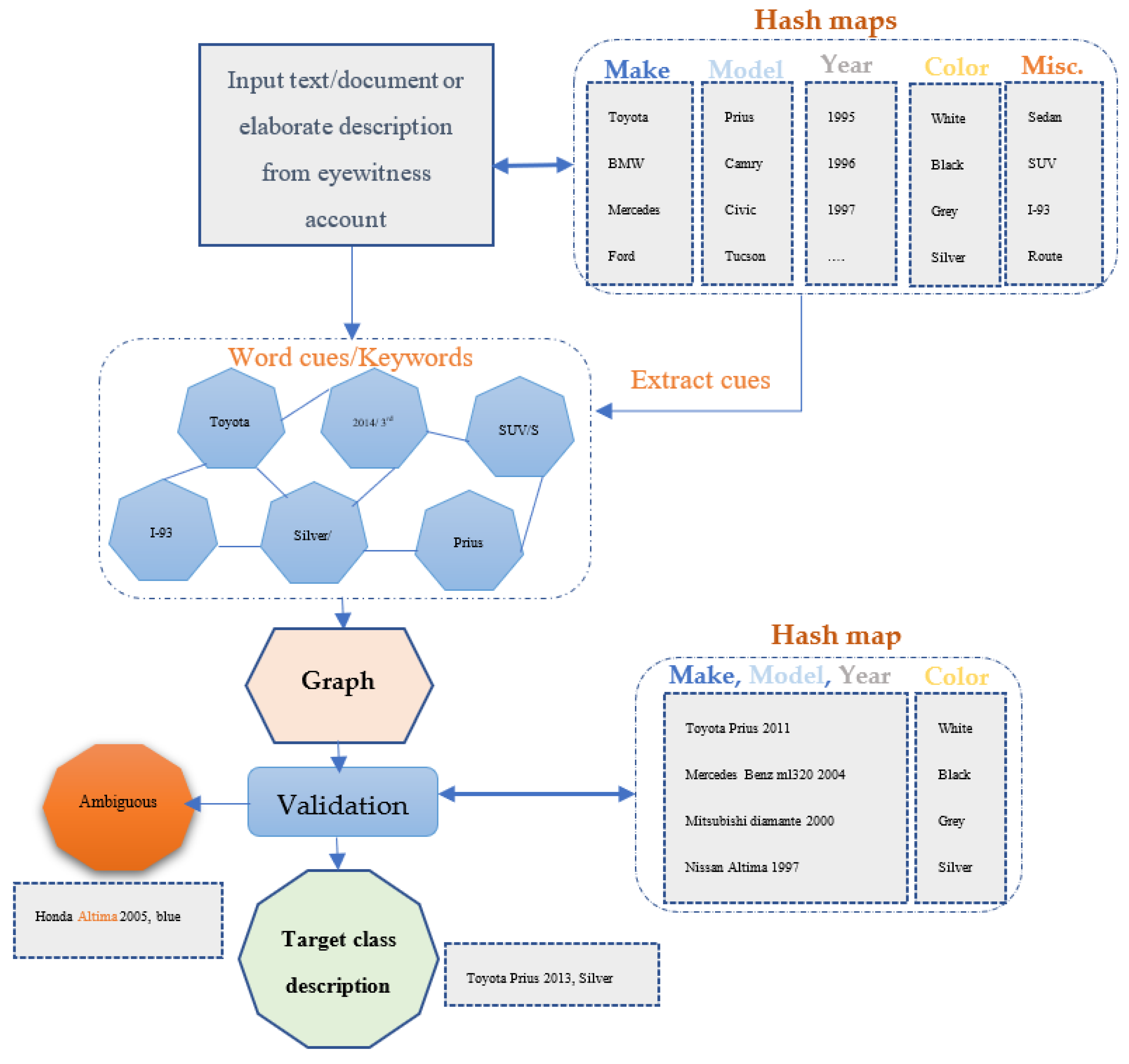
3.3. Hashgraph for Converting Textural Input to Valid Search Target
4. VRiV Video Testbench Dataset and Proposed Evaluation Metrics
4.1. VRiV (Vehicle Recognition in Video) Dataset
4.2. Evaluation Metrics
5. Experimental Results and Discussions
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manzoor, M.A.; Morgan, Y.; Bais, A. Real-Time Vehicle Make and Model Recognition System. Mach. Learn. Knowl. Extr. 2019, 1, 611–629. [Google Scholar] [CrossRef] [Green Version]
- Vehicle Make Model Recognition with Color|Plate Recognizer ALPR. Available online: https://platerecognizer.com/vehicle-make-model-recognition-with-color/ (accessed on 5 April 2021).
- Chan, F.-H.; Chen, Y.-T.; Xiang, Y.; Sun, M. Anticipating Accidents in Dashcam Videos. In Proceedings of the 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 136–153. [Google Scholar] [CrossRef]
- Shah, A.P.; Lamare, J.-B.; Nguyen-Anh, T.; Hauptmann, A. CADP: A Novel Dataset for CCTV Traffic Camera based Accident Analysis. In Proceedings of the 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Sultani, W.; Chen, C.; Shah, M. Real-World Anomaly Detection in Surveillance Videos. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. Available online: http://crcv.ucf.edu/projects/real-world/ (accessed on 5 April 2021).
- Siddiqui, A.J.; Mammeri, A.; Boukerche, A. Real-Time Vehicle Make and Model Recognition Based on a Bag of SURF Features. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3205–3219. [Google Scholar] [CrossRef]
- Kezebou, L.; Oludare, V.; Panetta, K.; Agaian, S.S. Joint image enhancement and localization framework for vehicle model recognition in the presence of non-uniform lighting conditions. In Multimodal Image Exploitation and Learning 2021; International Society for Optics and Photonics: Bellingham, DC, USA, 2021. [Google Scholar] [CrossRef]
- Kezebou, L.; Oludare, V.; Panetta, K.; Agaian, S.S. A deep neural network approach for detecting wrong-way driving incidents on highway roads. In Multimodal Image Exploitation and Learning 2021; International Society for Optics and Photonics: Bellingham, DC, USA, 2021. [Google Scholar] [CrossRef]
- Tafazzoli, F.; Frigui, H.; Nishiyama, K. A Large and Diverse Dataset for Improved Vehicle Make and Model Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 874–881. [Google Scholar] [CrossRef]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Yang, L.; Luo, P.; Loy, C.C.; Tang, X. A large-scale car dataset for fine-grained categorization and verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3973–3981. [Google Scholar] [CrossRef] [Green Version]
- Boonsim, N.; Prakoonwit, S. Car make and model recognition under limited lighting conditions at night. Pattern Anal. Appl. 2017, 20, 1195–1207. [Google Scholar] [CrossRef] [Green Version]
- Pearce, G.; Pears, N. Automatic make and model recognition from frontal images of cars. In Proceedings of the 2011 8th IEEE International Conference on Advanced Video and Signal Based Surveillance, Klagenfurt, Austria, 30 August–2 September 2011; pp. 373–378. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.J.; Ullah, I.; Wan, W.; Gao, Y.; Fang, Z. Real-Time Vehicle Make and Model Recognition with the Residual SqueezeNet Architecture. Sensors 2019, 19, 982. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Computer Vision—ECCV 2006, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar] [CrossRef] [Green Version]
- Suykens, J.A.K.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Support Vector Machines—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/svm.html (accessed on 15 May 2021).
- Sklearn.cluster.k_means—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.k_means.html?highlight=k means#sklearn.cluster.k_means (accessed on 15 May 2021).
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Sklearn.Ensemble.RandomForestClassifier—Scikit-Learn 0.24.2 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html (accessed on 15 May 2021).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size, February 2016. Available online: http://arxiv.org/abs/1602.07360 (accessed on 6 April 2021).
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. PMLR. 2019. Available online: http://proceedings.mlr.press/v97/tan19a.html (accessed on 13 May 2021).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. 2015. Available online: http://www.robots.ox.ac.uk/ (accessed on 6 April 2021).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 779–788. Available online: http://arxiv.org/abs/1506.02640 (accessed on 6 April 2021).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Kazemi, F.M.; Samadi, S.; Poorreza, H.R.; Akbarzadeh, T.M.-R. Vehicle Recognition Using Curvelet Transform and SVM. In Proceedings of the Fourth International Conference on Information Technology (ITNG’07), Las Vegas, NV, USA, 2–4 April 2007; pp. 516–521. [Google Scholar] [CrossRef]
- Manzoor, M.A.; Morgan, Y. Vehicle Make and Model classification system using bag of SIFT features. In Proceedings of the th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, L.; Chen, X. A Vehicle Recognition Algorithm Based on Deep Transfer Learning with a Multiple Feature Subspace Distribution. Sensors 2018, 18, 4109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fang, J.; Zhou, Y.; Yu, Y.; Du, S. Fine-Grained Vehicle Model Recognition Using A Coarse-to-Fine Convolutional Neural Network Architecture. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1782–1792. [Google Scholar] [CrossRef]
- Ma, X.; Boukerche, A. An AI-based Visual Attention Model for Vehicle Make and Model Recognition. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Singapore, 2018; Volume 11211, pp. 3–19. Available online: http://arxiv.org/abs/1807.06521 (accessed on 15 May 2021).
- Understanding Random Forest. How the Algorithm Works and Why it Is…|by Tony Yiu|Towards Data Science. Available online: https://towardsdatascience.com/understanding-random-forest-58381e0602d2 (accessed on 15 May 2021).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Hartwig, A. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. Available online: http://arxiv.org/abs/1704.04861 (accessed on 6 April 2021).
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2021; pp. 13728–13737. [Google Scholar] [CrossRef]
- Chen, P.; Bai, X.; Liu, W. Vehicle Color Recognition on Urban Road by Feature Context. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2340–2346. [Google Scholar] [CrossRef]
- Rachmadi, R.F.; Purnama, I.K.E. Vehicle Color Recognition Using Convolutional Neural Network. arXiv 2015, arXiv:1510.07391. Available online: http://arxiv.org/abs/1510.07391 (accessed on 19 April 2021).
- Li, X.; Zhang, G.; Fang, J.; Wu, J.; Cui, Z. Vehicle Color Recognition Using Vector Matching of Template. In Proceedings of the Third International Symposium on Electronic Commerce and Security, Nanchang, China, 29–31 July 2010; pp. 189–193. [Google Scholar] [CrossRef]
- Hu, C.; Bai, X.; Qi, L.; Chen, P.; Xue, G.; Mei, L. Vehicle Color Recognition With Spatial Pyramid Deep Learning. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2925–2934. [Google Scholar] [CrossRef]
- Which Car Color Is Most Popular in Your State?|CarMax. Available online: https://www.carmax.com/articles/car-color-popularity (accessed on 16 May 2021).
- CarMax—Browse Used Cars and New Cars Online. Available online: https://www.carmax.com/ (accessed on 16 May 2021).
- Godbole, S.; Sarawagi, S. Discriminative Methods for Multi-labeled Classification. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 26–28 May 2004; pp. 22–30. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
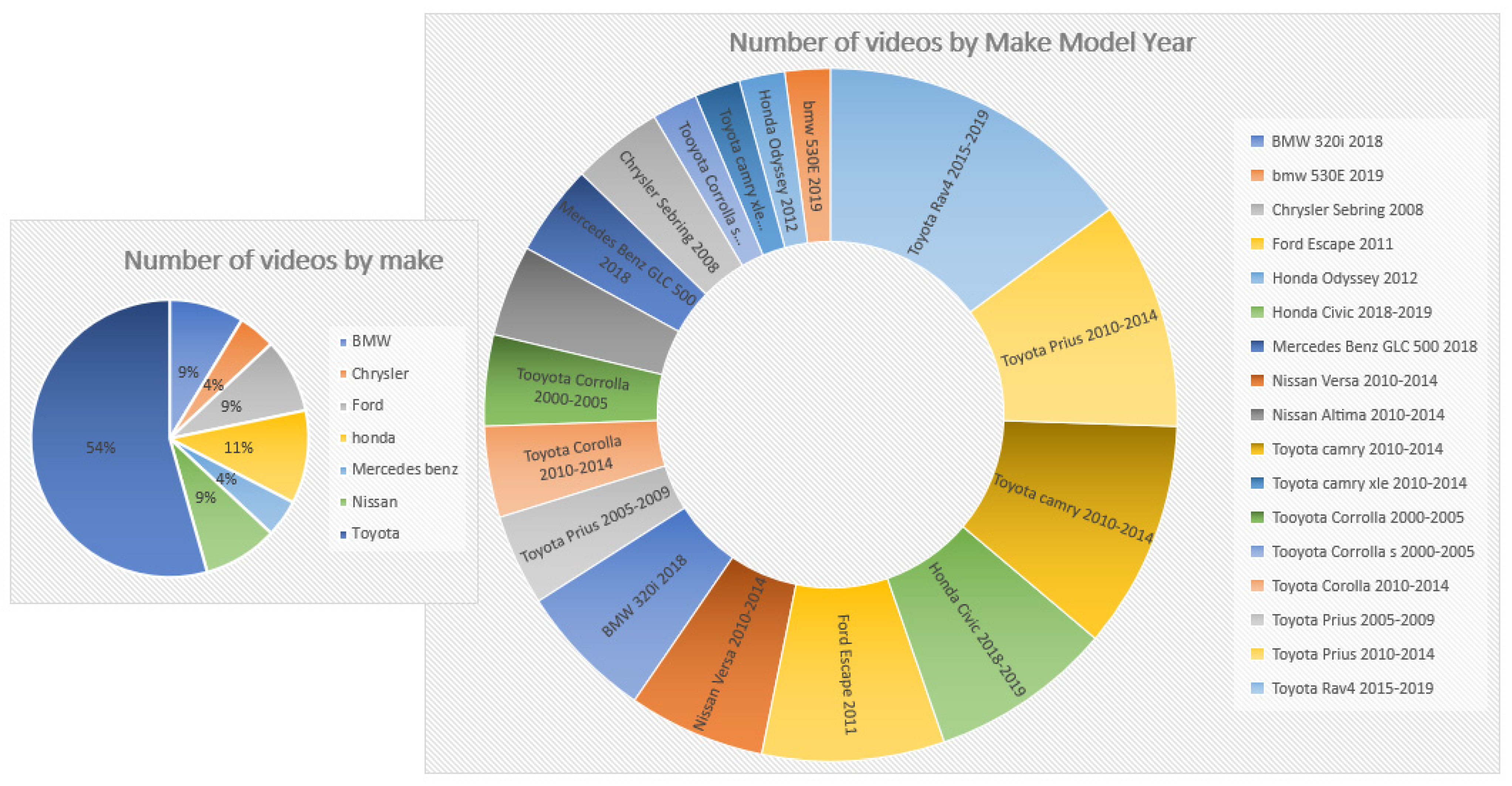{kind=link}
{kind=link}
| Make Model Year | Color | |||
|---|---|---|---|---|
| Top 1 Accuracy (%) | Top 3 Accuracy (%) | Top 1 Accuracy (%) | Top 3 Accuracy (%) | |
| ResNet-CBAM | 83.28 | 97.42 | 90.68 | 96.95 |
| ResNet50 | 82.40 | 95.23 | 89.22 | 95.12 |
| MobileNetV3 | 76.72 | 90.72 | 87.65 | 93.3 |
| RepVGG | 85.59 | 98.10 | 91.60 | 97.54 |
| VGG16 | 75.27 | 90.15 | 85.29 | 93.11 |
| Make Model Year Color | ||
|---|---|---|
| Top 1 Accuracy (%) | Top 3 Accuracy (%) | |
| ResNet-CBAM | 86.823 | 97.184 |
| ResNet50 | 85.674 | 95.175 |
| MobileNetV3 | 81.822 | 91.992 |
| RepVGG | 88.493 | 97.819 |
| VGG16 | 79.967 | 91.606 |
| Performance Metrics for V-Localize (Search, Recognition and Continuous Localization Framework) | ||||
|---|---|---|---|---|
| AMMR (%) ↓ | FLR (%) ↓ | MLR (%) ↓ | ATFD ↓ | CALR ↑ |
| 3.23 | 0.03 | 26.22 | 0.268 | 0.262 |
| Performance Metrics for V-Localize (Search, Recognition and Continuous Localization Framework) | |||||
|---|---|---|---|---|---|
| BACKBONE | AMMR (%) ↓ | FLR (%) ↓ | MLR (%) ↓ | ATFD ↓ | CALR ↑ |
| RepVGG | 3.23 | 0.03 | 26.22 | 0.268 | 0.262 |
| ResNet-CBAM | 3.21 | 0.08 | 29.55 | 0.295 | 0.253 |
| ResNet50 | 3.28 | 0.07 | 30.69 | 0.294 | 0.249 |
| MobileNetV3 | 3.47 | 0.11 | 35.22 | 0.314 | 0.223 |
| VGG16 | 4.81 | 0.17 | 36.71 | 0.310 | 0.206 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panetta, K.; Kezebou, L.; Oludare, V.; Intriligator, J.; Agaian, S. Artificial Intelligence for Text-Based Vehicle Search, Recognition, and Continuous Localization in Traffic Videos. AI 2021, 2, 684-704. https://doi.org/10.3390/ai2040041
Panetta K, Kezebou L, Oludare V, Intriligator J, Agaian S. Artificial Intelligence for Text-Based Vehicle Search, Recognition, and Continuous Localization in Traffic Videos. AI. 2021; 2(4):684-704. https://doi.org/10.3390/ai2040041
Chicago/Turabian StylePanetta, Karen, Landry Kezebou, Victor Oludare, James Intriligator, and Sos Agaian. 2021. "Artificial Intelligence for Text-Based Vehicle Search, Recognition, and Continuous Localization in Traffic Videos" AI 2, no. 4: 684-704. https://doi.org/10.3390/ai2040041
APA StylePanetta, K., Kezebou, L., Oludare, V., Intriligator, J., & Agaian, S. (2021). Artificial Intelligence for Text-Based Vehicle Search, Recognition, and Continuous Localization in Traffic Videos. AI, 2(4), 684-704. https://doi.org/10.3390/ai2040041