1. Introduction
Many sectors, such as health care, the automotive industry, the aerospace industry and weather forecasting, deal with time-series data in their operations. Knowledge about what will happen in the future is essential for making genuine decisions, and accurately forecasting future values is key to their success. A huge body of research is therefore dedicated to addressing the forecasting problem. An overview of various studies on the forecasting problem is provided in [
1]. Currently, the field is dominated by point prediction methods, which are easy to understand. However, these deterministic models report the mean of possible outcomes and cannot reflect the inherent uncertainty that exists in the real world. The probabilistic forecast models are devised to rectify these shortcomings. These models try to quantify the uncertainty of the predictions by forming a probability distribution over possible outcomes [
2].
In this paper, we propose ProbCast, a new probabilistic forecast model for multivariate time series based on Conditional Generative Adversarial Networks (GANs). Conditional GANs are a class of NN-based generative models that enable us to learn conditional probability distribution given a dataset. ProbCast is trained using a Conditional GAN setup to learn the probability distribution of future values conditioned on the historical information of the signal.
While GANs are powerful methods for learning complex probability distributions, they are notoriously hard to train. The training process is very unstable and quite dependent on careful selection of the model architecture and hyperparameters [
3]. In addition to ProbCast, we suggest a framework for transforming an existing deterministic forecaster—which is comparatively easy to train—into a probabilistic one that exceeds the performance of its predecessor. By using the proposed framework, the space for searching the GAN’s architecture becomes considerably smaller. Thus, this framework provides an easy way to adapt highly accurate deterministic models to construct useful probabilistic models, without compromising the accuracy, by exploiting the potential of GANs.
In summary, the main contributions of this article are as follows:
We introduce ProbCast, a novel probabilistic model for multivariate time-series forecasting. Our method employs a conditional GAN setup to train a probabilistic forecaster.
We suggest a framework for transforming a point forecast model into a probabilistic model. This framework eases the process of replacing the deterministic model with probabilistic ones.
We conduct experiments on two publicly available datasets and report the results, which show the superiority of ProbCast. Furthermore, we demonstrate that our framework is capable of transforming a point forecast method into a probabilistic model with improved accuracy.
2. Related Work
Due to the lack of a standard evaluation method for GANs, initially they were applied to domains in which their results are intuitively assessable, for example, images. However, recently, they have been applied to time-series data. Currently, GANs are applied to various domains for generating realistic time-series data including health care [
4,
5,
6,
7,
8], finance [
9,
10] and the energy industry [
11,
12,
13]. In [
14], the authors combine GAN and auto-regressive models to improve sequential data generation. Ramponi et al. [
15] condition a GAN on timestamp information to handle irregular sampling.
Furthermore, researchers have used conditional GANs to build probabilistic forecasting models. Koochali et al. [
16] used a Conditional GAN to build a probabilistic model for univariate time-series. They used Long Short Term Memory (LSTM) in the GAN’s component and tested their method on a synthetic dataset as well as on two publicly available datasets. In [
17], the authors utilized LSTM and Multi-Layer Perceptron (MLP) in a conditional GAN structure to forecast the daily closing price of stocks. The authors combined the Mean Square Error (MSE) with the generator loss of a GAN to improve performance. Zhou et al. [
18] employed LSTM and a convolutional neural network (CNN) in an adversarial training setup to forecast the high-frequency stock market. To guarantee satisfying predictions, this method minimizes the forecast error in the form of Mean absolute error (MAE) or MSE during training in conjunction with the GAN value function. Lin et al. [
19] proposed a pattern sensitive forecasting model for traffic flow, which can provide accurate predictions in unusual states without compromising its performance in its usual states. This method uses conditional GAN with MLP in its structure and adds two error terms to the standard generator loss. The first term specifies forecast error and the second term expresses reconstruction error. Kabir et al. [
20] make use of adversarial training for quantifying the uncertainty of the electricity price with a prediction interval. This line of research is more aligned with the method we presented in this article; however, the methods suggested in [
17,
18,
19] include a point-wise loss function in the GAN loss function. Minimizing suggested loss functions would decrease the statistical error values such as RMSE, MAPE and MSE. However, they encourage the model to learn the mean of possible outcomes instead of the probability distribution of future value. Hence, their probabilistic forecast can be misleading despite the small statistical error.
3. Background
Here, we work with a multivariate time-series , where each is a vector with size f equal to the number of features. In this paper, refers to the data point at time step t of feature f and points to the feature vector at time step t. The goal is to model , the probability distribution for given historical information .
3.1. Mean Regression Forecaster
To address the problem of forecasting, we can take the predictive view of regression [
2]. Ultimately, the regression analysis aims to learn the conditional distribution of a response given a set of explanatory variables [
21]. The mean regression methods are deterministic methods, which are concerned with accurately predicting the mean of the possible outcome, that is,
. There is a broad range of mean regression methods available in the literature; however, all of them are unable to reflect uncertainty in their forecasts. Hence, their results can be unreliable and misleading in some cases.
3.2. Generative Adversarial Network
In 2014, Goodfellow et al. [
22] introduced a powerful generative model called the Generative Adversarial Network (GAN). GAN can implicitly learn probability distribution, which describes a given dataset, that is,
with high precision. Hence, it is capable of generating artificial samples with high fidelity. The GAN architecture is composed of two neural networks, namely generator and discriminator. These components are trained simultaneously in an adversarial process. In the training process, first, a noise vector
z is sampled from a known probability distribution
and is fed into a generator. Then, the generator transforms
z from
to a sample, which follows
. On the other hand, the discriminator checks how well the generator is performing by comparing the generator’s outputs with real samples from the dataset. During training, this two-player minimax game is set in motion by optimizing the following value function:
However, GAN’s remarkable performance is not acquired easily. The training process is quite unstable and the careful selection of GAN’s architecture and hyperparameters is vital for stabilizing the training process [
3]. Since we should search for the optimal architecture of the generator and discriminator simultaneously, it is normally a cumbersome and time-consuming task to find a perfect combination of structures in a big search space.
3.3. Conditional GAN
Conditional GAN [
23] enables us to incorporate auxiliary information, called the condition, into the process of data generation. In this method, we provide an extra piece of information, such as labels, to both the generator and the discriminator. The generator must respect the condition while synthesizing a new sample because the discriminator considers the given condition while it checks the authenticity of its input. The new value function
for this setting is:
After training a Conditional GAN, the generator learns implicitly the probability distribution of the given condition of the data, that is, .
4. Methodology
4.1. ProbCast: The Proposed Multivariate Forecasting Model
In this article, we consider Conditional GAN as a method for training a probabilistic forecast model using adversarial training. In this perspective, the generator is our probabilistic model (i.e., ProbCast) and the discriminator provides the required gradient for optimizing ProbCast during training. To learn
, the historical information
is used as the condition of our Conditional GAN and the generator is trained to generate
. Hence, the probability distribution, which is learned by the generator, corresponds to
, that is, our target distribution. The value function, which we used for training the ProbCast (indicated as PC), is:
4.2. The Proposed Framework for Converting Deterministic Model to Probabilistic Model
By stepping into the realm of multivariate time-series, other challenges also need to be addressed. In the multivariate setting, we require more complicated architecture to figure out dependencies between features and to forecast the future with high accuracy. Furthermore, as previously mentioned, GANs require precise hyperparameter tuning to have a stable training process. Considering required network complexity for handling multivariate time-series data, it is very cumbersome, or in some cases impossible, to find suitable generator and discriminator architecture concurrently which performs accurately. To address this problem, we propose a new framework for building a probabilistic forecaster based on a deterministic forecaster using GAN architecture.
In this framework, we build the generator based on the architecture and hyper-parameters of the deterministic forecaster and train it using appropriate discriminator architecture. In this fashion, we can perform the task of finding an appropriate generator and discriminator architecture separately, which results in simplification of the GAN architecture search process. In other words, by using this framework, we can transform an existing accurate deterministic model into a probabilistic model with increased precision and better alignment with the real world.
4.3. Train Pipeline
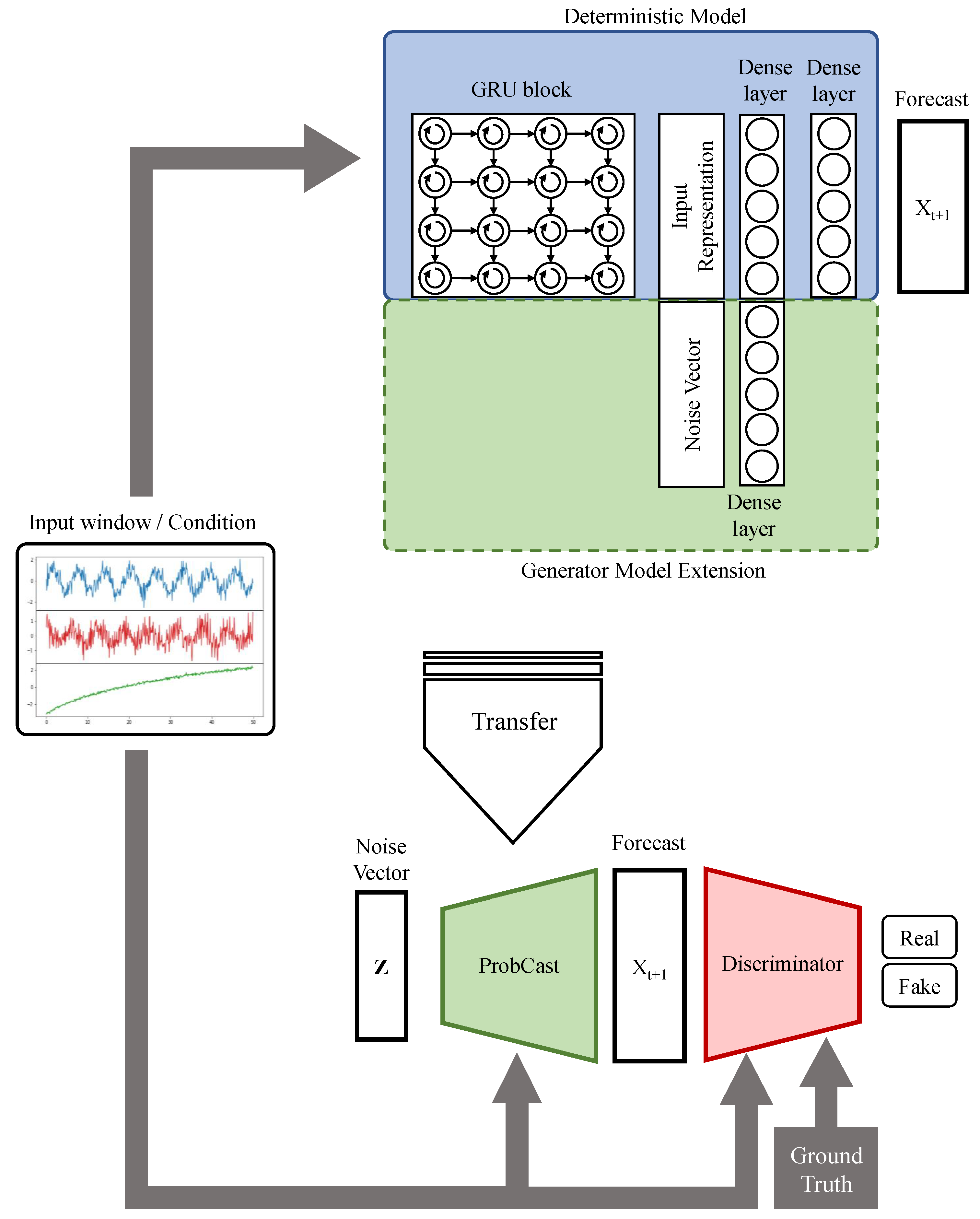
Figure 1 demonstrates the proposed framework, as well as the conditional GAN setup, for training ProbCast. First, we build an accurate point forecast model by searching for the optimal architecture of the deterministic model. In the case that a precise point forecast model exists, we can skip the first step and use an existing model. Then, we need to integrate the noise vector
z into the deterministic model architecture. In our experiments, we obtain the best results when we insert the noise vector into the later layers of the network, letting earlier layers of the network learn the representation of the input window. Finally, we train this model using adversarial training to acquire our probabilistic forecast model, that is, ProbCast.
With the generator architecture at hand, we only need to search for an appropriate time-series classifier to serve as the discriminator during the training of GAN. By reducing the search space of GAN architecture to the discriminator only, we can efficiently find a discriminator structure that is capable of training the ProbCast with a superior performance in comparison to the deterministic model. The following steps summarize the framework:
Employ an accurate deterministic model;
- (a)
Either use an existing model;
- (b)
Or search for an optimal deterministic forecaster;
Structure the generator based on deterministic model architecture and incorporate the noise vector into the network, preferably into later layers;
Search for an optimal discriminator structure and train the generator using it.
5. Experiment
5.1. Datasets
We tested our method on two publicly available datasets—electricity and exchange-rate datasets (we used datasets from
https://github.com/laiguokun/multivariate-time-series-data as they were prepared by the authors of [
24]). The electricity dataset consists of the electricity consumption of 321 clients in KWh, which was collected every 15 min between 2012 and 2014. The dataset was converted to reflect hourly consumption. The exchange-rate dataset contains the daily exchange-rate of eight countries, namely Australia, Great Britain, Canada, Switzerland, China, Japan, New Zealand, and Singapore, which was collected between 1990 and 2016.
Table 1 lists the properties of these two datasets.
For our experiments, we used of the datasets for training, for validation and for testing.
5.2. Setup
In each of our experiments, first we ran an architecture search to find an accurate deterministic model. For training the deterministic model, we employed MAE as a loss function. In
Figure 1, the architecture of the deterministic model is indicated. We used a Gated recurrent unit (GRU) [
25] block to learn the representation of the input window. Then, the representation passed through two dense layers to map from the representation to the forecast. We adopted the architecture of the most precise deterministic model, which we found in order to build the ProbCast by concatenating the noise vector to the GRU block output (i.e., representation) and extending the MLP block as shown in
Figure 1. Finally, we searched for the optimal architecture of the discriminator (
Figure 2) and trained the ProbCast. The discriminator concatenated
to the end of the input window and constructed
. Then it utilized a GRU block followed by two layers of MLP to inspect the consistency of this window. We used the genetic algorithm to search for the optimal architecture. We coded our method using Pytorch [
26].
5.3. Evaluation Metric
To report the performance of the ProbCast, we used the negative form of the Continuous Ranked Probability Score [
27] (denoted by
) as the metric. The
reflects the sharpness and calibration of a probabilistic method. It is defined as follows:
where
X and
are independent copies of a random variable from probabilistic forecaster
F and
x is the ground truth. The
provides a direct way to compare deterministic and probabilistic models. In the case of the deterministic forecaster, the
reduces to Mean Absolute Error (MAE), which is a commonly used point-wise error metric.
In other words, in a deterministic setting, the
is equivalent to MAE:
where
x is the ground truth and
is the point forecast. After the GAN training concluded, we calculated the
of the ProbCast and the deterministic model. To calculate
for ProbCast using Equation (
4), we sampled it 200 times (100 times for each random variable).
6. Results and Discussion
Table 2 presents the optimal hyperparameters we found for each dataset using our framework during the experiments, and
Table 3 summarizes our experiments’ results presenting the
of the best deterministic model and the ProbCast for each dataset.
In the experiment with the electricity dataset, the ProbCast was more accurate than the deterministic model despite having an almost identical structure. Furthermore, this experiment showed that our model can provide precise forecasts for multivariate time-series even when the number of features is substantial. In the exchange-rate experiment, the ProbCast outperforms its deterministic predecessor, again despite structural similarities. We can also observe that our method works well even though the dataset is considerably smaller in comparison to that of the previous experiment.
Furthermore, it confirms that our framework is capable of transforming a deterministic model to a probabilistic model that is more accurate than its predecessor. The question now arises: Considering the sensitivity of GAN to the architecture of its components, why does employing the deterministic model architecture to define the ProbCast work well, when it is borrowed from a totally different setup? We think that the deterministic model provides us an architecture that is capable of learning a good representation from the input time window. Since the model is trained to learn the mean of possible outcomes, these representations contain a distinctive indicator of where the target distribution is located. With the help of these indicators, the MLP block learns to accurately transform the noise vector z to the probability distribution of future values.
7. Conclusion and Future Works
In this paper, we present ProbCast, a probabilistic model for forecasting one step ahead of a multivariate time-series. We employ the potential of conditional GAN in a learning conditional probability distribution to model the probability distribution of future values given past values, that is, .
Furthermore, we propose a framework to efficiently find the optimal architecture of GAN’s components. This framework builds the probabilistic model upon a deterministic model to improve its performance. Hence, it enables us to search for the optimal architecture of a generator and a discriminator separately. Furthermore, it can transform an existing deterministic model into a probabilistic model with increased precision and better alignment with the real world.
We assess the performance of our method on two publicly available datasets. The exchange-rate dataset is a small dataset with few features, while the electricity dataset is bigger with a considerably larger number of features. We compare the performance of the ProbCast with its deterministic equivalent. In both experiments, our method outperforms its counterpart. The results of the experiments demonstrate that the ProbCast can learn patterns precisely from a small set of data and at the same time, it is capable of figuring out the dependencies between many features, and can forecast future values accurately in the presence of a big dataset. Furthermore, the results of the experiments indicate the successful application of our framework, which paves the way for a systematic and straightforward approach to exchanging currently used deterministic models with a probabilistic model to improve accuracy and obtain realistic forecasts.
The promising results of our experiments signify great potential for probabilistic forecasting using GANs and suggest many new frontiers for further pushing the research in this direction. For instance, we employ vanilla GAN for our research and there have been a lot of modifications suggested for improving GANs in recent years. One possible direction is to apply these modifications and inspect the improvement in the performance of the ProbCast. The other direction is experimenting with more sophisticated architectures for the generator and the discriminator. Finally, we only use the knowledge from the deterministic model to shape the generator. It would be interesting to push this direction and try to incorporate more knowledge from the deterministic model into the GAN training process to improve and optimize the probabilistic model.






{kind=link}
{kind=link}