
STL Decomposition of Time Series Can Benefit Forecasting Done by Statistical Methods but Not by Machine Learning Ones †


Abstract
:1. Introduction
2. Methods
2.1. Existing Benchmarks in M4 Competitions
- Naïve 1. Naïve 1 assumes future values are identical to the last observation.
- Naïve S. Naïve S assumes future values are identical to the values from the last known period, which, in our case, is 12 months.
- Naïve 2. Naïve 2 is similar to Naïve 1, except the data are seasonally adjusted by a conventional multiplicative decomposition if tested seasonal. We performed a 90% autocorrelation test at lag 12 for each series.
- Simple Exponential Smoothing (SES). SES forecasts future values as exponentially decayed weighted averages of past observations [7].
- Holt. Holt’s linear trend method extends SES for data with a trend [7].
- Damped. The damped model dampens the trend in Holt’s method [7].
2.2. Conventional Decomposition and STL Decomposition
2.2.1. Conventional Decomposition
- Compute the trend component using a simple moving average method.
- Detrend the time series: .
- Compute the seasonal component by averaging the corresponding season’s detrended values and then adjusting to ensure that they add to m.
- Compute the remainder component : .
2.2.2. STL Decomposition
- Detrending. Calculate a detrended series . For the first pass, .
- Cycle-Subseries Smoothing. Use LOESS to smooth the subseries of values at each position of the seasonal cycle. The result is marked as .
- Low-Pass Filtering of Smoothed Cycle-Subseries. This procedure consists of two MA filters and a LOESS smoother. The result is marked as .
- Detrending of Smoothed Cycle-Subseries. .
- Deseasonalizing. .
- Trend Smoothing. Use LOESS to smooth the deseasonalized series to get the trend component of this pass .
2.3. ARIMA, ETS, and Theta
- ARIMA. An ARIMA model assumes future values to be linear combinations of past values and random errors, contributing to the AR and MA terms, respectively [2]. SARIMA (Seasonal ARIMA) is an extension of ARIMA that explicitly supports time series data with a seasonal component. Once STL decomposition is applied, SARIMA models degenerate into regular ARIMA models as STL handles the seasonal part.
- ETS. The ETS models are a family of time series models with an underlying state space model consisting of a level component, a trend component (T), a seasonal component (S), and an error term (E). Forecasts produced using exponential smoothing methods are weighted averages of past observations, with the weights decaying exponentially as the observations get older [7]. After concatenating STL on the ETS model, the full ETS model degenerates into Holt’s method [7] as the seasonal equation is handled by STL.
- Theta Method. The Theta method, initially proposed in 2000 by Assimakopoulos et al. [9], performed exceptionally well in the M3 Competition and was used as a benchmark in the M4 Competition. The Theta method is based on the concept of modifying the local curvature of the time series through a coefficient , which is applied directly to the second difference of the data [9]. Hyndman demonstrated that the h-step-ahead forecast obtained by the Theta method is equivalent to an SES with drift depending on the smoothing parameter value of SES, the horizon h, and the data [11].
2.4. Machine Learning Methods
- -NN.k-NN is a non-parametric method used for classification and regression. In both cases, the input consists of the k closest training examples in the feature space. In k-NN regression, the output is the property value for the object. This value is the average of the values of k nearest neighbors based on the Euclidian distances.
- SVR. Support Vector Machine (SVM) is a successful method that tries to find a separation hyperplane to maximize the margin between two classes, while SVR seeks a hyperplane to minimize the margin between the support vectors and the hyperplane.
- CART. CART is one of the most generally used machine learning methods and can be used for classification and regression. CART dichotomizes each feature recursively and divides the input space into several cells. CART computes the probability distributions of the corresponding prediction in it.
- RF. RF is an ensemble learning algorithm based on the Decision Tree [26]. Similar to CART, Random Forest can be used for both classification and regression. It operates by constructing many decision trees at training time and calculating the average predictions from the individual trees.
- GP. A GP is a generalization of the Gaussian probability distribution [27]. It uses a measure of homogeneity between points as a kernel function to predict an unknown point’s value from the input training data. The result of its prediction contains the value of the point and the uncertainty information, i.e., its one-dimensional Gaussian distribution [22].
2.5. Deep Learning Methods
- CNN-LSTM. We use a 1D CNN to handle univariate time series. It has a hidden convolutional layer iterating over a 1D sequence and follows a pooling layer to extract the most salient features, which is then interpreted by a fully connected layer. Then, we stack it with some LSTM layers, which is a widely used RNNs model that provides a solution to the vanishing gradient problem for RNNs. It was proposed by Sepp Hochreiter et al. in 1997 [29].
- Convolutional LSTM (ConvLSTM). ConvLSTM is an RNNs with convolutional structures in both the input-to-state and state-to-state transitions. It determines the future state of a certain cell in the grid by its local neighbors’ inputs and past states. This is achieved using a convolution operator in the state-to-state and input-to-state transitions [28]. Rather than reading and extracting the features with a CNN and then interpreting them by an LSTM, ConvLSTM reads and interprets them at a time.
3. Experimentation Setup
3.1. Dataset
3.2. Pipeline for Machine Learning and Deep Learning Methods
3.2.1. Data Preprocessing
- Deseasonalizing: A 90% autocorrelation test at lag 12 is performed to decide whether the series is seasonal. We perform a conventional multiplicative decomposition or an STL decomposition if the series is seasonal and extract the seasonal part.
- Detrending: A one-order differencing is performed to eliminate the trend.
- Scaling: A standardization step is applied to remove the mean and scale the features to unit variance.
3.2.2. Supervised Learning Setting
3.2.3. Results Post-Processing
- Rescaling: A rescaling step is performed by inverting the standardization.
- Retrending: A cumulated summing is conducted to bring back the trend.
- Reseasonalizing: A reseasonalization step is executed to integrate the seasonal component into the prediction.
3.3. Pipeline for Statistical Methods
- Deseasonalizing. Compute the deseasonalized series by extracting the seasonal component calculated by STL decomposition.
- Point forecasting. Construct the ARIMA, ETS, and Theta models on the seasonally adjusted data and calculate the forecasting values.
- Reseasonalizing. Integrate the seasonal component back to calculate the final forecasting results.
3.4. Implementation and Parameters Tuning
3.4.1. Statistical Methods
3.4.2. Machine Learning Methods
3.4.3. Deep Learning Methods
3.5. Evaluation Metrics
4. Results and Discussion
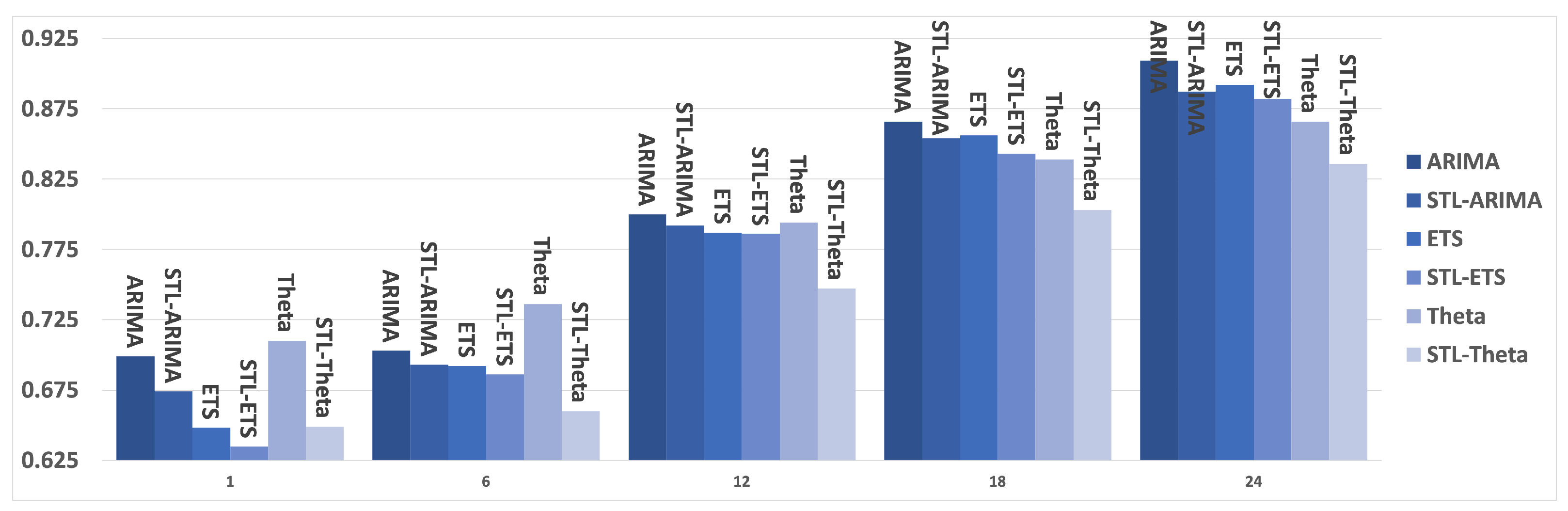
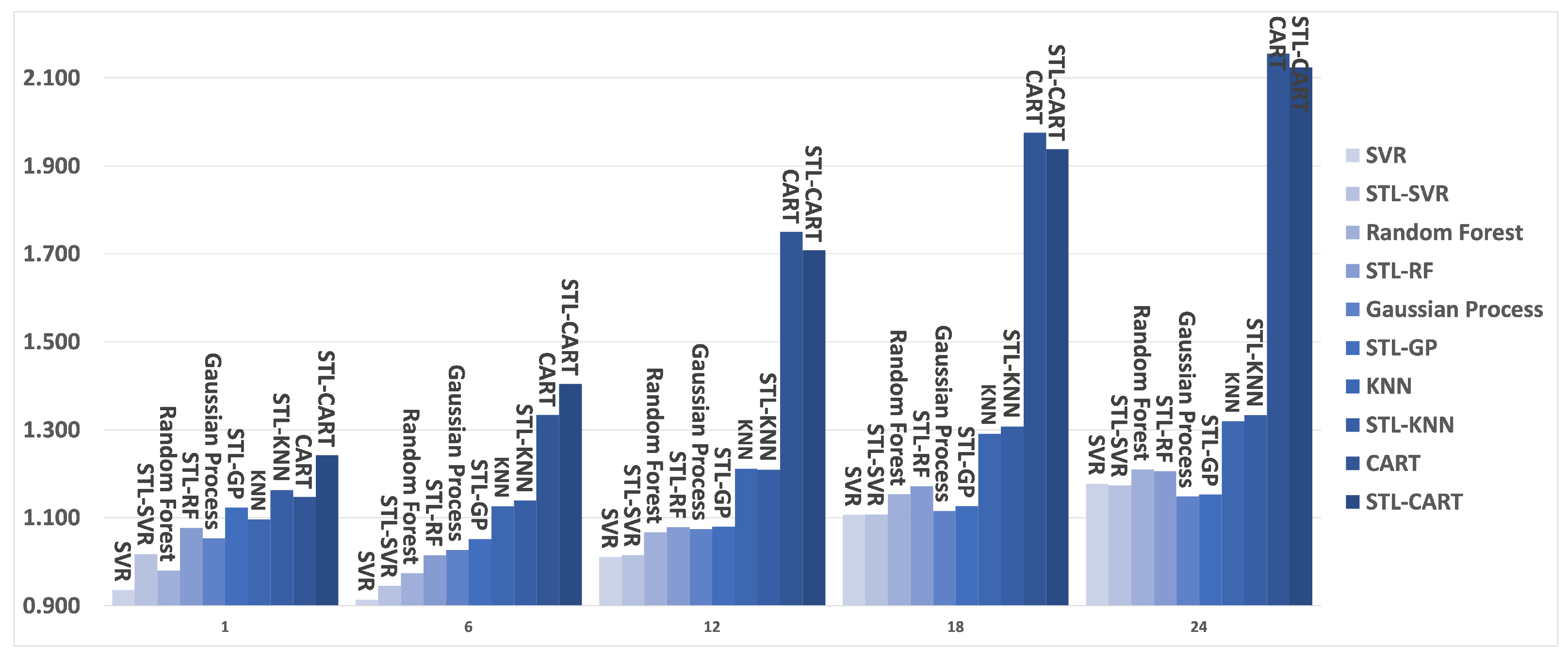
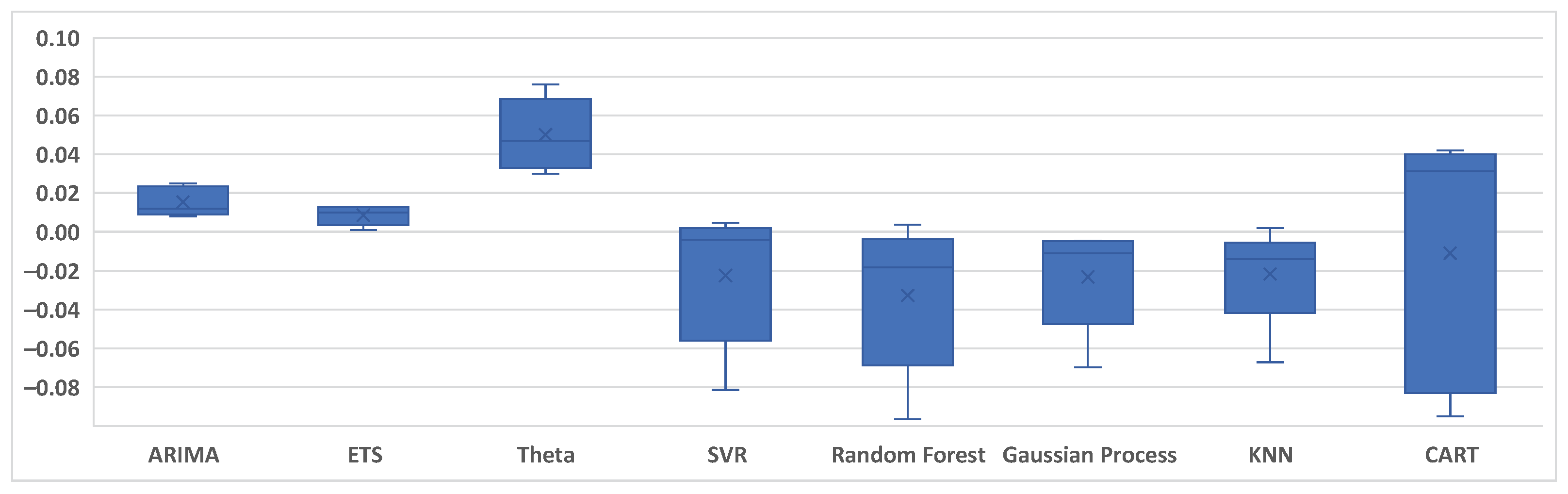
4.1. Results
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, G. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2004; Volume 20. [Google Scholar]
- Kihoro, J.; Otieno, R.; Wafula, C. Seasonal time series forecasting: A comparative study of ARIMA and ANN models. Afr. J. Sci. Technol. 2004, 5. [Google Scholar] [CrossRef] [Green Version]
- Brown, R.G. Statistical Forecasting for Inventory Control; McGraw/Hill: New York, NY, USA, 1959. [Google Scholar]
- Holt, C.C. Forecasting seasonals and trends by exponentially weighted moving averages. Int. J. Forecast. 2004, 20. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting sales by exponentially weighted moving averages. Manag. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Hyndman, R.J. A brief history of forecasting competitions. Int. J. Forecast. 2020, 36, 7–14. [Google Scholar] [CrossRef]
- Assimakopoulos, V.; Nikolopoulos, K. The theta model: A decomposition approach to forecasting. Int. J. Forecast. 2000, 16, 521–530. [Google Scholar] [CrossRef]
- Thomakos, D.D.; Nikolopoulos, K. Forecasting multivariate time series with the theta method. J. Forecast. 2015, 34, 220–229. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Billah, B. Unmasking the Theta method. Int. J. Forecast. 2003, 19, 287–290. [Google Scholar] [CrossRef]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A seasonal-trend decomposition. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2; Curran Associates Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- Graves, A. Supervised sequence labelling. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1; Curran Associates Inc.: Red Hook, NY, USA, 2012. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2; Curran Associates Inc.: Red Hook, NY, USA, 2014. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Lapedes, A.; Farber, R. Nonlinear Signal Processing Using Neural Networks: Prediction and System Modelling; Technical Report (No. LA-UR-87-2662; CONF-8706130-4); Los Alamos National Laboratory: Los Alamos, NM, USA, 1987. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Ahmed, N.K.; Atiya, A.F.; Gayar, N.E.; El-Shishiny, H. An empirical comparison of machine learning models for time series forecasting. Econom. Rev. 2010, 29. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [Green Version]
- Theodosiou, M. Forecasting monthly and quarterly time series using STL decomposition. Int. J. Forecast. 2011, 27, 1178–1195. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Bontempi, G.; Taieb, S.B.; Le Borgne, Y.A. Machine learning strategies for time series forecasting. In European Business Intelligence Summer School; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.E. Gaussian processes in machine learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1; Curran Associates Inc.: Red Hook, NY, USA, 2015. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27. [Google Scholar] [CrossRef] [Green Version]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference (SciPy 2010), Austin, TX, USA, 28 June–3 July 2010. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Löning, M.; Bagnall, A.; Ganesh, S.; Kazakov, V.; Lines, J.; Király, F.J. sktime: A unified interface for machine learning with time series. arXiv 2019, arXiv:1909.07872. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 13 October 2020).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 13 October 2020).
- Makridakis, S. Accuracy measures: Theoretical and practical concerns. Int. J. Forecast. 1993, 9, 527–529. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Statistical | h = 1 | h = 6 | h = 12 | h = 18 | h = 24 | ||||||||||
| sMAPE | MASE | OWA | sMAPE | MASE | OWA | sMAPE | MASE | OWA | sMAPE | MASE | OWA | sMAPE | MASE | OWA | |
| Naive | 12.536 | 1.006 | 1.071 | 16.011 | 1.280 | 1.177 | 16.238 | 1.312 | 1.152 | 17.480 | 1.395 | 1.153 | 18.044 | 1.456 | 1.143 |
| sNaive | 12.464 | 0.882 | 1.002 | 12.001 | 0.874 | 0.842 | 12.726 | 0.925 | 0.857 | 14.088 | 1.033 | 0.891 | 14.689 | 1.094 | 0.894 |
| Naive2 | 11.704 | 0.939 | 1.000 | 13.813 | 1.071 | 1.000 | 14.374 | 1.118 | 1.000 | 15.431 | 1.189 | 1.000 | 16.053 | 1.254 | 1.000 |
| SES | 9.277 | 0.723 | 0.781 | 11.386 | 0.844 | 0.806 | 12.376 | 0.931 | 0.847 | 13.640 | 1.017 | 0.870 | 14.397 | 1.092 | 0.884 |
| Holt | 9.734 | 0.741 | 0.810 | 11.669 | 0.865 | 0.826 | 13.522 | 1.004 | 0.920 | 15.710 | 1.161 | 0.997 | 17.197 | 1.293 | 1.051 |
| Damped | 9.288 | 0.720 | 0.780 | 11.388 | 0.844 | 0.806 | 12.572 | 0.942 | 0.859 | 13.985 | 1.036 | 0.889 | 14.740 | 1.110 | 0.902 |
| ARIMA | 8.643 | 0.623 | 0.701 | 10.037 | 0.730 | 0.704 | 11.824 | 0.873 | 0.802 | 13.581 | 1.015 | 0.867 | 14.794 | 1.127 | 0.910 |
| ETS | 7.805 | 0.591 | 0.648 | 9.875 | 0.716 | 0.692 | 11.718 | 0.849 | 0.787 | 13.608 | 0.987 | 0.856 | 14.751 | 1.085 | 0.892 |
| Theta | 8.645 | 0.640 | 0.710 | 10.668 | 0.749 | 0.736 | 11.862 | 0.854 | 0.794 | 13.403 | 0.962 | 0.839 | 14.399 | 1.047 | 0.866 |
| STL-ARIMA | 8.245 | 0.604 | 0.674 | 9.915 | 0.717 | 0.693 | 11.755 | 0.856 | 0.792 | 13.457 | 0.993 | 0.854 | 14.481 | 1.093 | 0.887 |
| STL-ETS | 7.760 | 0.569 | 0.635 | 9.882 | 0.704 | 0.686 | 11.728 | 0.845 | 0.786 | 13.433 | 0.969 | 0.843 | 14.552 | 1.074 | 0.882 |
| STL-Theta | 7.963 | 0.580 | 0.649 | 9.502 | 0.678 | 0.660 | 11.177 | 0.801 | 0.747 | 12.817 | 0.921 | 0.803 | 13.891 | 1.011 | 0.836 |
| ML & DL | h = 1 | h = 6 | h = 12 | h = 18 | h = 24 | ||||||||||
| sMAPE | MASE | OWA | sMAPE | MASE | OWA | sMAPE | MASE | OWA | sMAPE | MASE | OWA | sMAPE | MASE | OWA | |
| KNN | 13.636 | 0.965 | 1.096 | 16.070 | 1.166 | 1.126 | 17.781 | 1.326 | 1.212 | 20.421 | 1.497 | 1.291 | 21.741 | 1.610 | 1.319 |
| STL-KNN | 15.318 | 1.077 | 1.228 | 18.359 | 1.390 | 1.313 | 17.980 | 1.306 | 1.210 | 22.513 | 1.698 | 1.444 | 22.154 | 1.610 | 1.332 |
| SVR | 11.253 | 0.855 | 0.936 | 12.732 | 0.971 | 0.914 | 14.712 | 1.116 | 1.011 | 17.485 | 1.284 | 1.107 | 19.526 | 1.429 | 1.178 |
| STL-SVR | 12.978 | 1.006 | 1.090 | 15.285 | 1.225 | 1.125 | 14.919 | 1.109 | 1.015 | 19.338 | 1.484 | 1.251 | 19.589 | 1.410 | 1.172 |
| CART | 14.080 | 1.025 | 1.147 | 19.081 | 1.377 | 1.334 | 25.490 | 1.930 | 1.750 | 30.934 | 2.314 | 1.975 | 35.956 | 2.596 | 2.155 |
| STL-CART | 15.820 | 1.191 | 1.310 | 21.715 | 1.660 | 1.561 | 25.157 | 1.862 | 1.708 | 32.285 | 2.446 | 2.075 | 35.715 | 2.537 | 2.124 |
| RF | 11.756 | 0.898 | 0.980 | 13.668 | 1.027 | 0.974 | 15.432 | 1.186 | 1.067 | 17.831 | 1.369 | 1.153 | 19.692 | 1.496 | 1.210 |
| STL-RF | 13.667 | 1.054 | 1.145 | 16.401 | 1.289 | 1.195 | 15.880 | 1.177 | 1.079 | 20.237 | 1.581 | 1.321 | 19.947 | 1.465 | 1.205 |
| GP | 12.540 | 0.972 | 1.053 | 14.268 | 1.093 | 1.027 | 15.528 | 1.195 | 1.075 | 17.395 | 1.313 | 1.116 | 18.720 | 1.418 | 1.148 |
| STL-GP | 14.163 | 1.120 | 1.201 | 16.950 | 1.351 | 1.244 | 15.782 | 1.187 | 1.080 | 19.624 | 1.526 | 1.278 | 18.974 | 1.408 | 1.152 |
| CNN-LSTM | 13.105 | 0.985 | 1.084 | 15.439 | 1.176 | 1.108 | 16.233 | 1.213 | 1.107 | 17.811 | 1.332 | 1.137 | 18.821 | 1.423 | 1.154 |
| ConvLSTM | 12.976 | 0.929 | 1.049 | 16.257 | 1.235 | 1.165 | 17.121 | 1.283 | 1.169 | 18.926 | 1.399 | 1.202 | 19.372 | 1.441 | 1.178 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, Z.; Ravier, P.; Jabloun, M. STL Decomposition of Time Series Can Benefit Forecasting Done by Statistical Methods but Not by Machine Learning Ones. Eng. Proc. 2021, 5, 42. https://doi.org/10.3390/engproc2021005042
Ouyang Z, Ravier P, Jabloun M. STL Decomposition of Time Series Can Benefit Forecasting Done by Statistical Methods but Not by Machine Learning Ones. Engineering Proceedings. 2021; 5(1):42. https://doi.org/10.3390/engproc2021005042
Chicago/Turabian StyleOuyang, Zuokun, Philippe Ravier, and Meryem Jabloun. 2021. "STL Decomposition of Time Series Can Benefit Forecasting Done by Statistical Methods but Not by Machine Learning Ones" Engineering Proceedings 5, no. 1: 42. https://doi.org/10.3390/engproc2021005042
APA StyleOuyang, Z., Ravier, P., & Jabloun, M. (2021). STL Decomposition of Time Series Can Benefit Forecasting Done by Statistical Methods but Not by Machine Learning Ones. Engineering Proceedings, 5(1), 42. https://doi.org/10.3390/engproc2021005042