Spherical Minimum Description Length



Abstract
:1. Introduction
2. Related Works
3. Bayesian Approach to Model Selection
3.1. Comparing Models
3.2. An Inappropriate Prior
3.3. Geometry of Probabilistic Models
3.4. Fisher Information
3.5. An Appropriate Prior
4. Asymptotic MDL in
5. Spherical MDL
5.1. Derivation of the Spherical MDL Criterion
5.2. Riemannian Volume of a Hypersphere
6. Case Study: Spherical MDL for Histograms
6.1. Theoretical Development
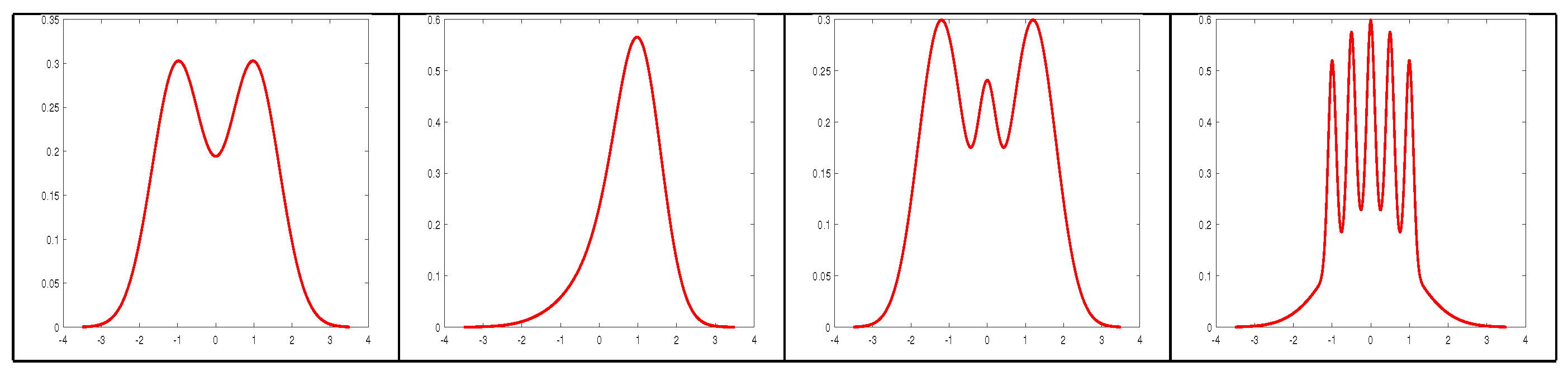
6.2. Experimental Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rissanen, J. Modeling by shortest data description. Automatica 1978, 14, 465–471. [Google Scholar] [CrossRef]
- Rissanen, J. A universal prior for integers and estimation by minimum description length. Ann. Stat. 1983, 11, 416–431. [Google Scholar] [CrossRef]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Selected Papers of Hirotugu Akaike; Parzen, E., Tanabe, K., Kitagawa, G., Eds.; Springer: New York, NY, USA, 1998; pp. 199–213. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Hodges, J.S.; Sargent, D.J. Counting degrees of freedom in hierarchical and other richly parameterised models. Biometrika 1988, 88, 367–379. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Pan, W. Bootstrapping likelihood for model selection with small samples. J. Comput. Gr. Stat. 1999, 8, 687–698. [Google Scholar]
- Rissanen, J. Stochastic complexity. J. R. Stat. Soc. 1987, 49, 223–239. [Google Scholar]
- Rissanen, J. Fisher information and stochastic complexity. IEEE Trans. Inf. Theory 1996, 42, 40–47. [Google Scholar] [CrossRef]
- Grünwald, P. A tutorial introduction to the minimum description length principle. In Advances in Minimum Description Length: Theory and Applications; Grünwald, P., Myung, I., Pitt, M., Eds.; The MIT Press: Cambridge, MA, USA, 2005; pp. 55–58. [Google Scholar]
- Balasubramanian, V. Statistical inference, Occam’s razor, and statistical mechanics on the space of probability distributions. Neural Comput. 1997, 9, 349–368. [Google Scholar] [CrossRef]
- Kent, J.T. The Fisher–Bingham distribution on the sphere. J. R. Stat. Soc. 1982, 44, 71–80. [Google Scholar]
- Boothby, W.M. An Introduction to Differentiable Manifolds and Riemannian Geometry; Academic Press: San Diego, CA, USA, 2002. [Google Scholar]
- Barron, A.; Rissanen, J.; Yu, B. The minimum description length principle in coding and modeling. IEEE Trans. Inf. Theory 1998, 44, 2743–2760. [Google Scholar] [CrossRef] [Green Version]
- Rissanen, J. MDL denoising. IEEE Trans. Inf. Theory 2000, 46, 2537–2543. [Google Scholar] [CrossRef]
- Wallace, C.S.; Dowe, D.L. Refinements of MDL and MML coding. Comput. J. 1999, 42, 330–337. [Google Scholar] [CrossRef]
- Wallace, C.S.; Boulton, D.M. An information measure for classification. Comput. J. 1968, 11, 185–194. [Google Scholar] [CrossRef]
- Wallace, C.S. Statistical and Inductive Inference by Minimum Message Length; Information Science and Statistics; Springer: New York, NY, USA, 2005. [Google Scholar]
- Lebanon, G. Metric learning for text documents. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 497–508. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Srivastava, A.; Jermyn, I.; Joshi, S. Riemannian analysis of probability density functions with applications in vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; IEEE Press: Piscataway, NJ, USA, 2007; pp. 1–8. [Google Scholar]
- Peter, A.; Rangarajan, A. Information geometry for landmark shape analysis: Unifying shape representation and deformation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 337–350. [Google Scholar] [CrossRef] [PubMed]
- Peter, A.; Rangarajan, A. Maximum likelihood wavelet density estimation with applications to image and shape matching. IEEE Trans. Image Process. 2008, 17, 458–468. [Google Scholar] [CrossRef] [PubMed]
- Bingham, C. Distributions on the Sphere and on the Projective Plane. Ph.D. Thesis, Yale University, New Haven, CT, USA, 1964. [Google Scholar]
- Parthasarathy, B.; Kadane, J.B. Laplace approximations to posterior moments and marginal distributions on circles, spheres, and cylinders. Can. J. Stat. 1991, 19, 67–77. [Google Scholar]
- Kume, A. Saddlepoint approximations for the Bingham and Fisher-Bingham normalising constants. Biometrika 2005, 92, 465–476. [Google Scholar] [CrossRef]
- Hall, P.; Hannan, E. On stochastic complexity and nonparametric density estimation. Biometrika 1988, 75, 705–714. [Google Scholar] [CrossRef]
- Kontkanen, P. Computationally Efficient Methods for MDL-Optimal Density Dstimation and Data Clustering. Ph.D. Thesis, University of Helsinki, Helsinki, Finland, 2009. [Google Scholar]
- Davies, L.; Gather, U.; Nordman, D.; Weinert, H. A comparison of automatic histogram constructions. ESAIM 2009, 13, 181–196. [Google Scholar] [CrossRef] [Green Version]
- McKay, D. A practical Bayesian framework for backpropation networks. Neural Comput. 1992, 4, 448–472. [Google Scholar] [CrossRef]
- Stigler, S.M. The History of Statistics: The Measurement of Uncertainty before 1900; Harvard University Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Rao, C.R. Information and accuracy attainable in estimation of statistical parameters. Bull. Calcutta Math. Soc. 1945, 37, 81–91. [Google Scholar]
- Jeffreys, H. Theory of Probability, 3rd ed.; Oxford University Press: New York, NY, USA, 1961. [Google Scholar]
- Kass, R.E. The geometry of asymptotic inference. Stat. Sci. 1989, 4, 188–234. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.; Cox, D.; Reid, N. The role of differential geometry in statistical theory. Int. Stat. Rev. 1986, 54, 83–96. [Google Scholar] [CrossRef]
- Amari, S.I.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Providence, RI, USA, 2001. [Google Scholar]
- Cover, T.; Thomas, J. Elements of Information Theory, 2nd ed.; Wiley Interscience: New York, NY, USA, 2006. [Google Scholar]
- Laplace, P. Memoir on the probability of the causes of events. Stat. Sci. 1986, 1, 364–378, Translated from Mémoire sur la probabilité des causes par les événemens, Mémoires de l’Académie royale des sciences de Paris (Savants étrangers), t. VI. pp. 621–656; 1774. Oeuvres 8, pp. 27–65. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Nonlinear Programming, 2nd ed.; Athena Scientific: Belmont, MA, USA, 1999; pp. 291–293. [Google Scholar]
- Berry, A.C. The accuracy of the Gaussian approximation to the sum of independent variates. Trans. Am. Math. Soc. 1941, 49, 122–136. [Google Scholar] [CrossRef]
- Robert, C.; Casella, G. Monte Carlo Statistical Methods, 2nd ed.; Springer: New York, NY, USA, 2004. [Google Scholar]
- Heck, D.W.; Moshagen, M.; Erdfelder, E. Model selection by minimum description length: Lower-bound sample sizes for the Fisher information approximation. J. Math. Psychol. 2014, 60, 29–34. [Google Scholar] [CrossRef]
- Navarro, D.J. A note on the applied use of MDL approximations. Neural Comput. 2004, 16, 1763–1768. [Google Scholar] [CrossRef] [PubMed]
- Peter, A.; Rangarajan, A. An information geometry approach to shape density minimum description length model selection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Barcelona, Spain, 6–13 November 2011; IEEE Press: Piscataway, NJ, USA, 2011; pp. 1432–1439. [Google Scholar]
- Taylor, C. Akaike’s information criterion and the histogram. Biometrika 1987, 74, 636–639. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables; Dover Publications: Mineola, NY, USA, 1965. [Google Scholar]
- Marron, S.J.; Wand, M.P. Exact mean integrated squared error. Ann. Stat. 1992, 20, 712–736. [Google Scholar] [CrossRef]
- Wand, M.P.; Jones, M.C. Comparison of smoothing parameterizations in bivariate kernel density estimation. J. Am. Stat. Assoc. 1993, 88, 520–528. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| AIC | BIC | MDL2 | MDL | |
|---|---|---|---|---|
| Bimodal | 1407 | 221 | 1372 | 4 |
| Skew | 1441 | 200 | 1349 | 9 |
| Trimodal | 1478 | 197 | 1323 | 3 |
| Claw | 1569 | 257 | 1471 | 6 |
| Total | 5895 | 875 | 5515 | 22 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herntier, T.; Ihou, K.E.; Smith, A.; Rangarajan, A.; Peter, A. Spherical Minimum Description Length. Entropy 2018, 20, 575. https://doi.org/10.3390/e20080575
Herntier T, Ihou KE, Smith A, Rangarajan A, Peter A. Spherical Minimum Description Length. Entropy. 2018; 20(8):575. https://doi.org/10.3390/e20080575
Chicago/Turabian StyleHerntier, Trevor, Koffi Eddy Ihou, Anthony Smith, Anand Rangarajan, and Adrian Peter. 2018. "Spherical Minimum Description Length" Entropy 20, no. 8: 575. https://doi.org/10.3390/e20080575
APA StyleHerntier, T., Ihou, K. E., Smith, A., Rangarajan, A., & Peter, A. (2018). Spherical Minimum Description Length. Entropy, 20(8), 575. https://doi.org/10.3390/e20080575