Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods



Abstract
:1. Introduction
2. Related Work
2.1. Feature Selection
Chi-Squared Feature Selection
2.2. Outlier Detection Method
2.2.1. DBSCAN
2.2.2. iForest
2.3. Oversampling Method for Imbalance Dataset
2.3.1. SMOTE
2.3.2. SMOTETomek
2.4. Random Forest
- Choose a value of n that shows the number of trees that will be increased in a forest;
- Generate n bootstrap samples with bagging technique of the training set;
- For each bootstrap dataset, grow a tree. If this training set would consist of M number of input variables, m<<M number of inputs are selected randomly out of M and the best split on these m attributes is used to split the node. The value of m will remain constant during forest growing;
- The tree will be grown to the largest possible level;
- The prediction results are obtained from the model (most frequent class) of each decision tree in the forest.
3. Dataset Description
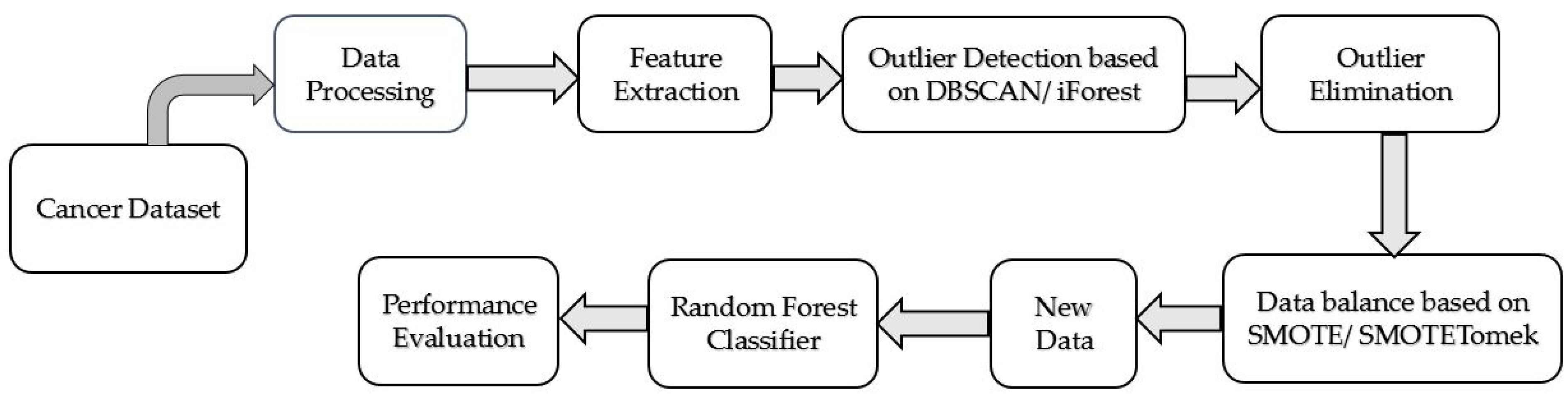
3.1. Prediction Model for Cervical Cancer
3.2. Evaluation Metrics
4. Results and Discussion
4.1. Feature Extraction Results
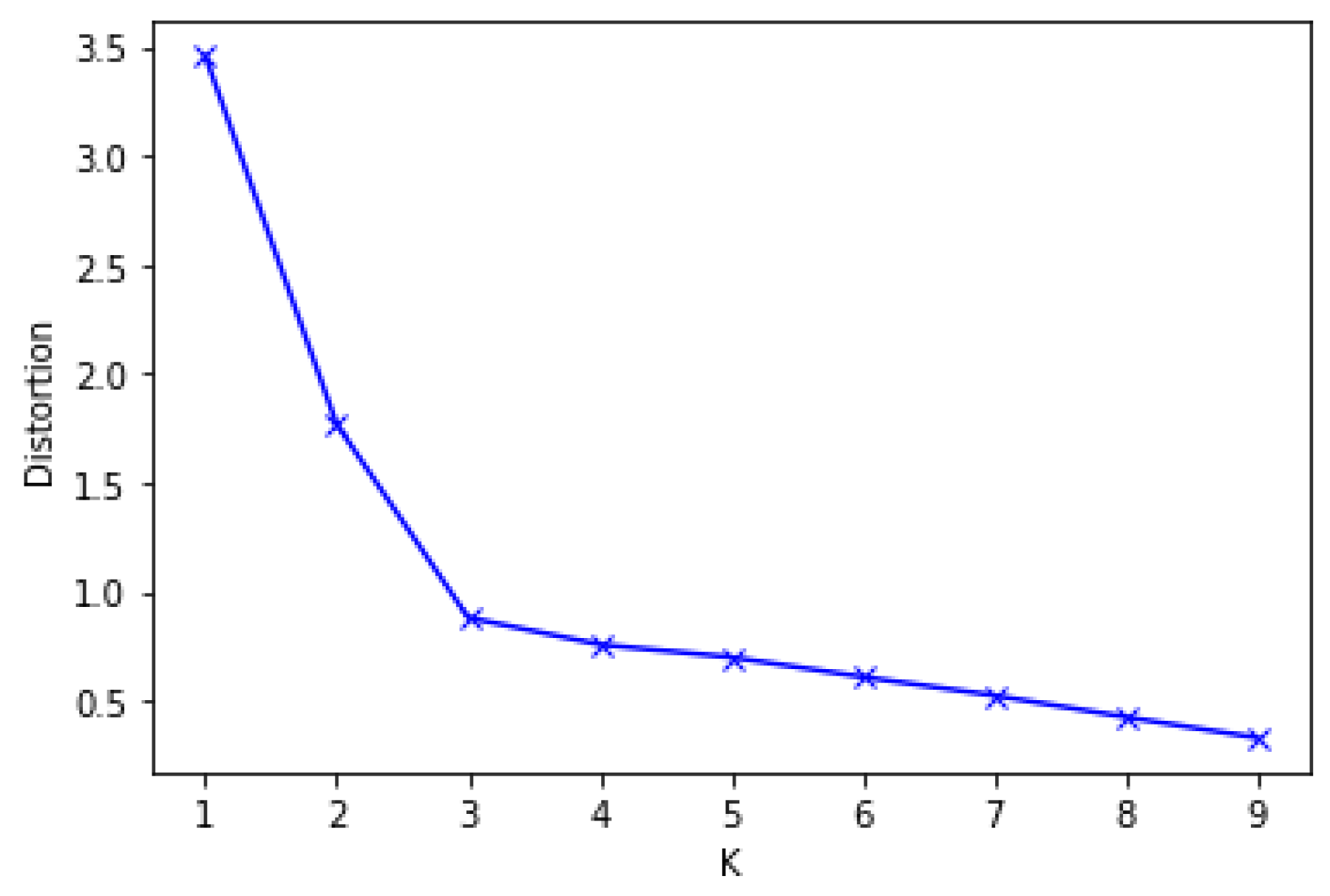
4.2. DBSCAN and iForest for Outlier Detection
4.3. SMOTE and SMOTETomek for Balancing the Dataset
4.4. Results of Target Variables: Biopsy, Schiller, Hinselmann, Cytology
4.5. Comparison with Previous Studies
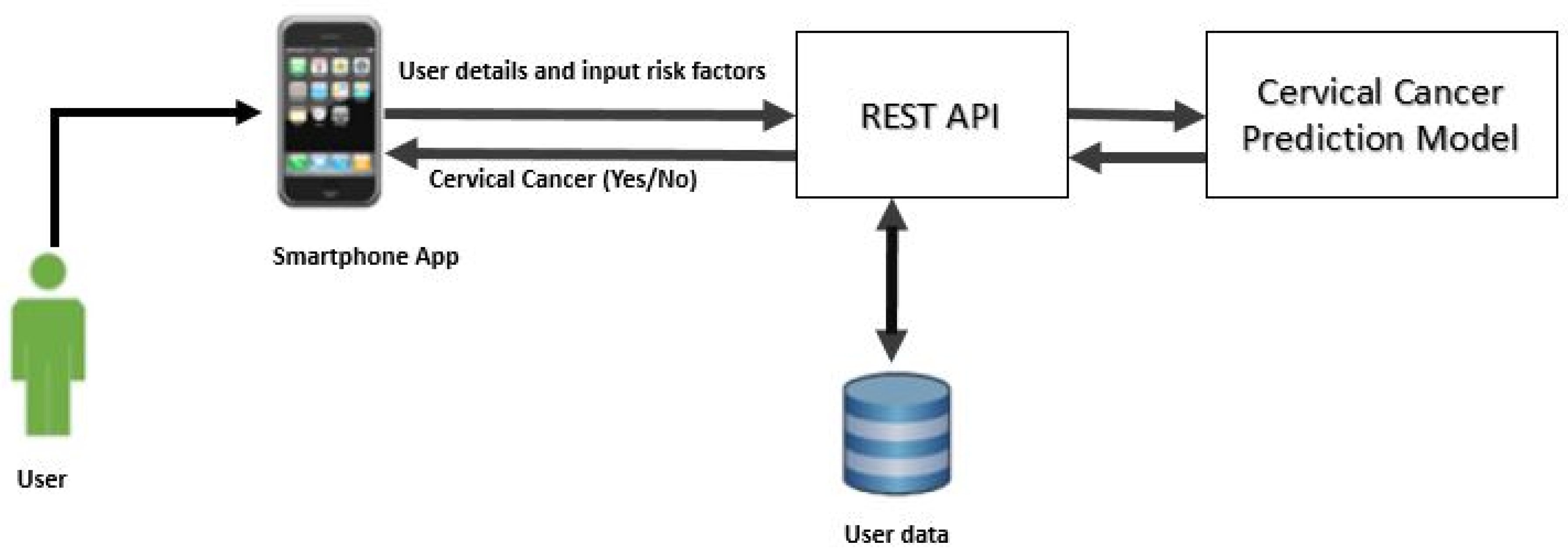
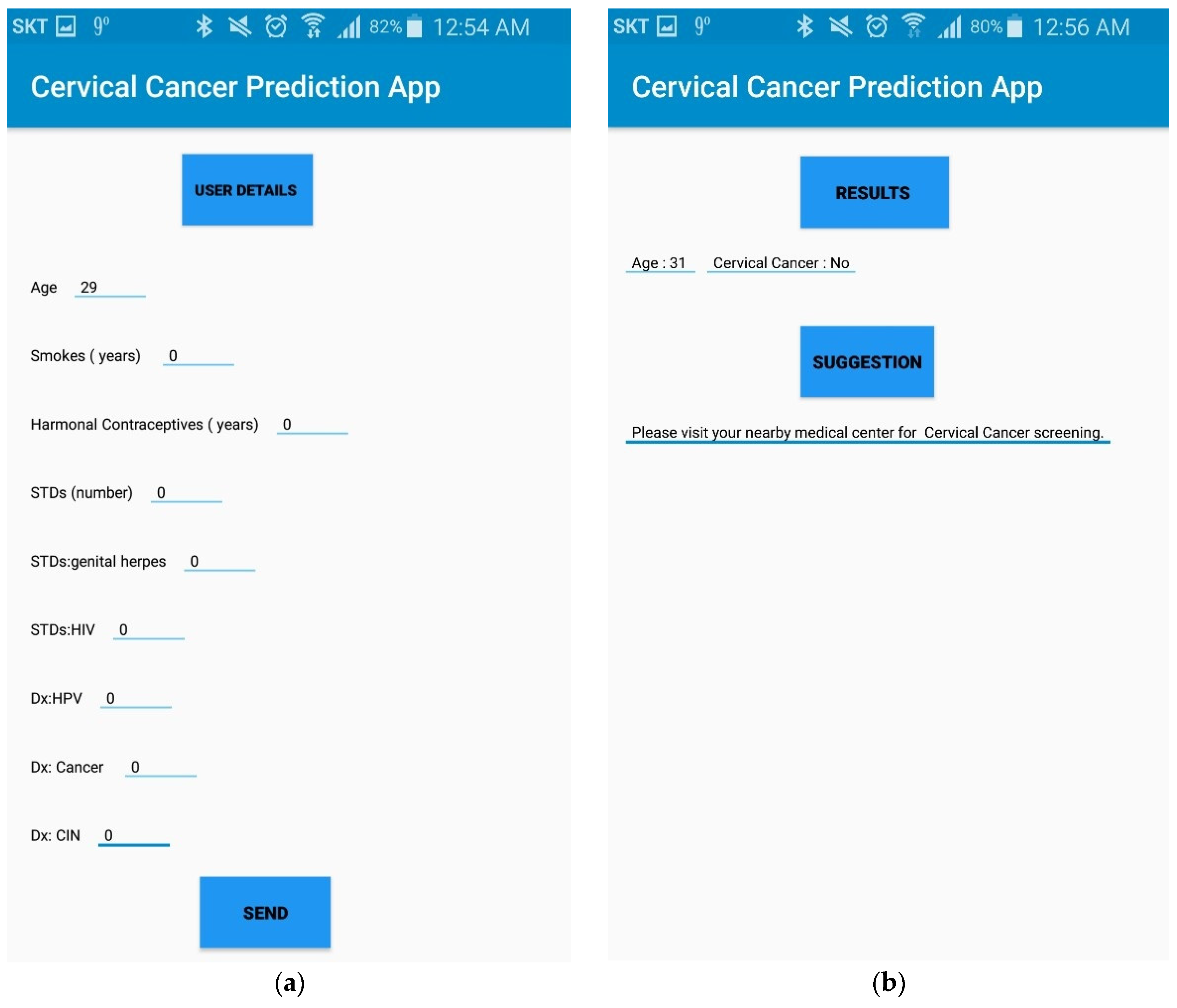
4.6. Practical Implications
5. Conclusions
Author Contributions
Data Availability
Funding
Conflicts of Interest
References
- Yang, X.; Da, M.; Zhang, W.; Qi, Q.; Zhang, C.; Han, S. Role of lactobacillus in cervical cancer. Cancer Manag. Res. 2018, 10, 1219–1229. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fitzmaurice, C.; Dicker, D.; Pain, A.; Hamavid, H.; Moradi-Lakeh, M.; MacIntyre, M.F.; Allen, C.; Hansen, G.; Woodbrook, R.; Wolfe, C.; et al. The global burden of cancer 2013. JAMA. Oncol. 2015, 1, 505–527. [Google Scholar] [CrossRef] [PubMed]
- Seo, S.-S.; Oh, H.Y.; Lee, J.-K.; Kong, J.-S.; Lee, D.O.; Kim, M.K. Combined effect of diet and cervical microbiome on the risk of cervical intraepithelial neoplasia. Clin. Nutr. 2016, 35, 1434–1441. [Google Scholar] [CrossRef] [PubMed]
- Suehiro, T.T.; Malaguti, N.; Damke, E.; Uchimura, N.S.; Gimenes, F.; Souza, R.P.; da Silva, V.R.S.; Consolaro, M.E.L. Association of human papillomavirus and bacterial vaginosis with increased risk of high-grade squamous intraepithelial cervical lesions. Int. J. Gynecol. Cancer 2019, 29, 242–249. [Google Scholar] [CrossRef]
- Khan, I.; Nam, M.; Kwon, M.; Seo, S.-S.; Jung, S.; Han, J.S.; Hwang, G.-S.; Kim, M.K. LC/MS-based polar metabolite profiling identified unique biomarker signatures for cervical cancer and cervical intraepithelial neoplasia using global and targeted metabolomics. Cancers 2019, 11, 511. [Google Scholar] [CrossRef] [Green Version]
- Luhn, P.; Walker, J.; Schiffman, M.; Zuna, R.E.; Dunn, S.T.; Gold, M.A.; Smith, K.; Mathews, C.; Allen, R.A.; Zhang, R.; et al. The role of co-factors in the progression from human papillomavirus infection to cervical Cancer. Gynecol. Oncol. 2013, 128, 265–270. [Google Scholar] [CrossRef] [Green Version]
- Cervical Cancer Prevention. 2015. Available online: https://www.Cancergov/types/cervical/hp/cervical-prevention-pdq (accessed on 22 April 2020).
- Exner, M.; Kühn, A.; Stumpp, P.; Höckel, M.; Horn, L.C.; Kahn, T.; Brandmaier, P. Value of diffusion-weighted MRI in diagnosis of uterine cervical cancer: A prospective study evaluating the benefits of DWI compared to conventional MR sequences in a 3T environment. Acta. Radiol. 2016, 57, 869–877. [Google Scholar] [CrossRef]
- McVeigh, P.Z.; Syed, A.M.; Milosevic, M.; Fyles, A.; Haider, M.A. Diffusion-weighted MRI in cervical Cancer. Eur. Radiol. 2008, 18, 1058–1064. [Google Scholar] [CrossRef]
- Wu, W.; Zhou, H. Data-driven diagnosis of cervical cancer with support vector machine-based approaches. IEEE Access 2017, 5, 25189–25195. [Google Scholar] [CrossRef]
- Yang, J.; Nolte, F.S.; Chajewski, O.S.; Lindsey, K.G.; Houser, P.M.; Pellicier, J.; Wang, Q.; Ehsani, L. Cytology and high risk HPV testing in cervical cancer screening program: Outcome of 3-year follow-up in an academic institute. Diagn. Cytopathol. 2018, 46, 22–27. [Google Scholar] [CrossRef]
- Cibula, D.; Pötter, R.; Planchamp, F.; Avall-Lundqvist, E.; Fischerova, D.; Meder, C.H.; Köhler, C.; Landoni, F.; Lax, S.; Lindegaard, J.C.; et al. The European society of Gynaecological Oncology/European society for radiotherapy and Oncology/European society of pathology guidelines for the management of patients with cervical cancer. Int. J. Gynecol. Cancer 2018, 28, 641–655. [Google Scholar] [CrossRef] [PubMed]
- Shi, P.; Zhang, L.; Ye, N. Sfterummetabolomic analysis of cervical cancer patients by gas chromatography-mass spectrometry. Asian J. Chem. 2015, 27, 547–551. [Google Scholar]
- Ghoneim, A.; Muhammad, G.; Hossain, M.S. Cervical cancer classification using convolutional neural networks and extreme learning machines. Future Gener. Comp. Syst. 2020, 102, 643–649. [Google Scholar] [CrossRef]
- Chandran, K.P.; Kumari, U.V.R. Improving cervical cancer classification on MR images using texture analysis and probabilistic neural network. Int. J. Sci. Eng. Technol. Res. 2015, 4, 3141–3145. [Google Scholar]
- Malli, P.K.; Nandyal, S. Machine learning technique for detection of cervical cancer using k-NN and artificial neural network. Int. J. Emerg. Trends Technol. Comput. Sci. 2017, 6, 145–149. [Google Scholar]
- Gupta, R.; Sarwar, A.; Sharma, V. Screening of cervical cancer by artificial intelligence based analysis of digitized papanicolaou-smear images. Int. J. Contemp. Med. Res. 2017, 4, 1108–1113. [Google Scholar]
- Zhang, L.; Lu, L.; Nogues, I.; Summers, R.M.; Liu, S.; Yao, J. DeepPap: Deep convolutional networks for cervical cell classification. IEEE J. Biomed. Health Inform. 2017, 21, 1633–1643. [Google Scholar] [CrossRef] [Green Version]
- Bora, K.; Chowdhury, M.; Mahanta, L.B.; Kundu, M.K.; Das, A.K. Pap smear image classification using convolutional neural network. In Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing, Bangalore, India, 18–22 December 2016; pp. 1–8. [Google Scholar]
- Adem, K.; Kilicarslan, S.; Comert, O. Classification and diagnosis of cervicalcancer with softmax classification with stacked autoencoder. Expert Syst. Appl. 2019, 115, 557–564. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. 2015, 13, 8–17. [Google Scholar] [CrossRef] [Green Version]
- Abdoh, S.F.; Rizka, M.A.; Maghraby, F.A. Cervical cancer diagnosis using random forest classifier with SMOTE and feature reduction techniques. IEEE. Access 2018, 6, 59475–59485. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Jörg, S.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, IAAI, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Sanguanmak, Y.; Hanskunatai, A. (2016, July). DBSM: The combination of DBSCAN and SMOTE for imbalanced data classification. In Proceedings of the 2016 13th International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016; pp. 1–5. [Google Scholar]
- Zhang, L.; Kong, H.; Chin, C.T.; Liu, S.; Fan, X.; Wang, T.; Chen, S. Automation-assisted cervical cancer screening in manual liquid-based cytology with hematoxylin and eosin staining. Cytom. Part A 2014, 85, 214–230. [Google Scholar] [CrossRef] [PubMed]
- Vink, J.P.; Van Leeuwen, M.B.; Van Deurzen, C.H.M.; De Haan, G. Efficient nucleus detector in histopathology images. J. Microsc. 2013, 249, 124–135. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tareef, A.; Song, Y.; Cai, W.; Huang, H.; Chang, H.; Wang, Y.; Fulham, M.; Feng, D.; Chen, M. Automatic segmentation of overlapping cervical smear cells based on local distinctive features and guided shape deformation. Neurocomputing 2017, 221, 94–107. [Google Scholar] [CrossRef]
- Ragothaman, S.; Narasimhan, S.; Basavaraj, M.G.; Dewar, R. Unsupervised segmentation of cervical cellimages using gaussian mixture model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 70–75. [Google Scholar]
- Zhao, L.; Li, K.; Wang, M.; Yin, J.; Zhu, E.; Wu, C.; Wang, S.; Zhu, C. Automatic cytoplasm and nuclei segmentation for color cervical smear image using an efficient gap-search MRF. Comput. Biol. Med. 2016, 71, 46–56. [Google Scholar] [CrossRef] [PubMed]
- Tareef, A.; Song, Y.; Cai, W.; Feng, D.D.; Chen, M. Automated three-stage nucleus and cytoplasmsegmentation of overlapping cells. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; pp. 865–870. [Google Scholar]
- Tseng, C.J.; Lu, C.J.; Chang, C.C.; Chen, G.D. Application of machine learning to predict the recurrence-proneness for cervical Cancer. Neural. Comput. Appl. 2014, 24, 1311–1316. [Google Scholar]
- Hu, B.; Tao, N.; Zeng, F.; Zhao, M.; Qiu, L.; Chen, W.; Tan, Y.; Wei, Y.; Wu, X.; Wu, X. A risk evaluation model of cervical cancer based on etiology and human leukocyte antigen allele susceptibility. Int. J. Infect. Dis. 2014, 28, 8–12. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S. Cervical cancer stage prediction using decision tree approach of machine learning. Int. J. Adv. Res. Comput. Commun. Eng. 2016, 5, 345–348. [Google Scholar]
- Sobar, S.; Machmud, R.; Wijaya, A. Behavior determinant based cervical cancer early detection with machine learning algorithm. Adv. Sci. Lett. 2016, 22, 3120–3123. [Google Scholar] [CrossRef]
- Le Thi, H.A.; Le, H.M.; Dinh, T.P. Feature selection in machine learning: An exact penalty approach using a difference of convex function algorithm. Mach. Learn. 2015, 101, 163–186. [Google Scholar] [CrossRef]
- Rehman, O.; Zhuang, H.; Muhamed Ali, A.; Ibrahim, A.; Li, Z. Validation of miRNAs as breast cancer biomarkers with a machine learning approach. Cancers 2019, 11, 431. [Google Scholar] [CrossRef] [PubMed]
- Jin, X.; Xu, A.; Bie, R.; Guo, P. Machine learning techniques and chi-square feature selection for cancerclassification using SAGE gene expression profiles. Lect. Notes Comput. Sci. 2006, 3916, 106–115. [Google Scholar]
- Rouzbahani, H.K.; Daliri, M.R. Diagnosis of Parkinson’s disease in human using voice signals. Basic Clin. Neurosci. 2011, 2, 12–20. [Google Scholar]
- Musa, P.; Sen, B.; Delen, D. Computer-aided diagnosis of Parkinson’s disease using complex-valued neural networks and mRMR feature selection algorithm. J. Healthc. Eng. 2015, 6, 281–302. [Google Scholar]
- Sicong, K.; Davison, B.D. Learning word embeddings with chi-square weights for healthcare tweet classification. Appl. Sci. 2017, 7, 846. [Google Scholar]
- Hao, S.; Zhou, X.; Song, H. A new method for noise data detection based on DBSCAN and SVDD. In Proceedings of the 2015 IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Shenyang, China, 8–12 June 2015; pp. 784–789. [Google Scholar]
- ElBarawy, Y.M.; Mohamed, R.F.; Ghali, N.I. Improving social network community detection using DBSCAN algorithm. In Proceedings of the 2014 World Symposium on Computer Applications & Research (WSCAR), Sousse, Tunisia, 18–20 January 2014; pp. 1–6. [Google Scholar]
- Abid, A.; Kachouri, A.; Mahfoudhi, A. Outlier detection for wireless sensor networks using density-based clustering approach. IET Wirel. Sens. Syst. 2017, 7, 83–90. [Google Scholar] [CrossRef]
- Tian, H.X.; Liu, X.J.; Han, M. An outlier’s detection method of time series data for soft sensor modeling. In Proceedings of the 2016 Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 3918–3922. [Google Scholar]
- Ijaz, M.F.; Alfian, G.; Syafrudin, M.; Rhee, J. Hybrid prediction model for type 2 diabetes and hypertension using dbscan-based outlier detection, synthetic minority over sampling technique (SMOTE), and random forest. Appl. Sci. 2018, 8, 1325. [Google Scholar] [CrossRef] [Green Version]
- Verbiest, N.; Ramentol, E.; Cornelis, C.; Herrera, F. Preprocessing noisy imbalanced datasets using SMOTE enhanced with fuzzy rough prototype selection. Appl. Soft. Comput. 2014, 22, 511–517. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Domingues, R.; Filippone, M.; Michiardi, P.; Zouaoui, J. A comparative evaluation of outlier detection algorithms: Experiments and analyses. Pattern Recognit. 2018, 74, 406–421. [Google Scholar] [CrossRef]
- Calheiros, R.N.; Ramamohanarao, K.; Buyya, R.; Leckie, C.; Versteeg, S. On the effectiveness of isolation-based anomaly detection in cloud data centers. Concurr. Comput. Pract. Eng. 2017, 29, 4169. [Google Scholar] [CrossRef]
- Bauder, R.; da Rosa, R.; Khoshgoftaar, T. Identifying Medicare Provider Fraud with Unsupervised Machine Learning. In Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration (IRI), Salt Lake City, UT, USA, 6–9 July 2018; pp. 285–292. [Google Scholar]
- Lorenzo, M.; Susto, G.A.; del Favero, S. Detection of insulin pump malfunctioning to improve safety in artificial pancreas using unsupervised algorithms. J. Diabetes Sci. Technol. 2019, 13, 1065–1076. [Google Scholar]
- Meneghetti, L.; Terzi, M.; del Favero, S.; Susto, G.A.; Cobelli, C. Data-driven anomaly recognition for unsupervised model-free fault detection in artificial pancreas. IEEE Trans. Control. Syst. Technol. 2020, 28, 33–47. [Google Scholar] [CrossRef]
- Dos Santos, H.D.P.; Ulbrich, A.H.D.P.S.; Woloszyn, V.; Vieira, R. DDC-Outlier: Preventing medication errors using unsupervised learning. IEEE J. Biomed. Health Inform. 2019, 23, 874–881. [Google Scholar] [CrossRef] [PubMed]
- Cheng, W.; Zhu, W. Predicting 30-Day Hospital Readmission for Diabetics Based on Spark. In Proceedings of the 2019 3rd International Conference on Imaging, Signal Processing and Communication (ICISPC), Singapore, 27–29 July 2019; pp. 125–129. [Google Scholar]
- Kurnianingsih; Nugroho, L.E.; Widyawan; Lazuardi, L.; Prabuwono, A.S. Detection of Anomalous Vital Sign of Elderly Using Hybrid K-Means Clustering and Isolation Forest. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju, Korea, 28–31 October 2018; pp. 913–918. [Google Scholar]
- Fallahi, A.; Jafari, S. An expert system for detection of breast cancer using data preprocessing and Bayesian network. Int. J. Adv. Sci. Technol. 2011, 34, 65–70. [Google Scholar]
- Wang, K.-J.; Makond, B.; Chen, K.-H.; Wang, K.-M. A hybrid classifier combining SMOTE with PSO to estimate 5-year survivability of breast cancer patients. Appl. Soft Comput. 2014, 20, 15–24. [Google Scholar] [CrossRef]
- Santos, M.S.; Abreu, P.H.; García-Laencina, P.J.; Simão, A.; Carvalho, A. A new cluster-based oversampling method for improving survival prediction of hepatocellular carcinoma patients. J. Biomed. Inform. 2015, 58, 49–59. [Google Scholar] [CrossRef] [Green Version]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newslett. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Goel, G.; Maguire, L.; Li, Y.; McLoone, S. Evaluation of Sampling Methods for Learning from Imbalanced Data. In Intelligent Computing Theories; Springer: Berlin/Heidelberg, Germany, 2013; pp. 392–401. [Google Scholar]
- Chen, T.; Shi, X.; Wong, Y.D. Key feature selection and risk prediction for lane-changing behaviors based on vehicles’ trajectory data. Accid. Anal. Prev. 2019, 129, 156–169. [Google Scholar] [CrossRef]
- Yan, Y.; Liu, R.; Ding, Z.; Du, X.; Chen, J.; Zhang, Y. A parameter-free cleaning method for smote in imbalanced classification. IEEE Access 2019, 7, 23537–23548. [Google Scholar] [CrossRef]
- Son, L.H.; Baik, S. A robust framework for self-care problem identification for children with disability. Symmetry 2019, 11, 89. [Google Scholar]
- Teixeira, V.; Camacho, R.; Ferreira, P.G. Learning influential genes on cancer gene expression data with stacked denoising autoencoders. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 1201–1205. [Google Scholar]
- Zeng, M.; Zou, B.; Wei, F.; Liu, X.; Wang, L. Effective prediction of three common diseases by combining SMOTE with Tomek links technique for imbalanced medical data. In Proceedings of the 2016 IEEE International Conference of Online Analysis and Computing Science (ICOACS), Chongqing, China, 28–29 May 2016; pp. 225–228. [Google Scholar]
- Kabir, M.F.; Ludwig, S. Classification of Breast Cancer Risk Factors Using Several Resampling Approaches. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1243–1248. [Google Scholar]
- Mohan, A.; Rao, M.D.; Sunderrajan, S.; Pennathur, G. Automatic classification of protein structures using physicochemical parameters. Interdiscip. Sci. Comput. Life Sci. 2014, 6, 176–186. [Google Scholar] [CrossRef] [PubMed]
- Seera, M.; Lim, C.P. A hybrid intelligent system for medical data classification. Expert Syst. Appl. 2014, 41, 2239–2249. [Google Scholar] [CrossRef]
- Fernandes, K.; Cardoso, J.S.; Fernandes, J. Transfer learning with partial observability applied to cervical cancer screening. In Iberian Conference on Pattern Recognition and Image Analysis; Springer: Cham, Switzerland, 2017; pp. 243–250. [Google Scholar]
- Wright, T.C., Jr. Chapter 10: Cervical cancer screening using visualization techniques. JNCI Monogr. 2003, 31, 66–71. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Liu, B. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Deng, X.; Luo, Y.; Wang, C. Analysis of Risk Factors for Cervical Cancer Based on Machine Learning Methods. In Proceedings of the 2018 5th IEEE International Conference on Cloud Computing and Intelligence Systems (CCIS), Nanjing, China, 23–25 November 2018. [Google Scholar]
- Nithya, B.; Ilango, V. Evaluation of machine learning based optimized feature selection approaches and classification methods for cervical cancer prediction. SN Appl. Sci. 2019, 1, 641. [Google Scholar] [CrossRef] [Green Version]
- Kearns, M.J. The Computational Complexity of Machine Learning; MIT Press: Cambridge, MA, USA, 1990. [Google Scholar]
- Papadimitriou, C.H. Computational Complexity; Addison-Wesley: Boston, MA, USA, 1994. [Google Scholar]
- Ian, C.; Sleightholme, J. An introduction to Algorithms and the Big O Notation. In Introduction to Programming with Fortran; Springer: Cham, Switzerland, 2015; pp. 359–364. [Google Scholar]
- Abdiansah, A.; Wardoyo, R. Time complexity analysis of support vector machines (SVM) in LibSVM. Int. Int. J. Comput. Appl. 2015, 128, 28–34. [Google Scholar] [CrossRef]
- Samy, N.; Abu, S. Big O Notation for Measuring Expert Systems Complexity. Islamic Univ. J. – Gaza 1999, 7, 57–68. [Google Scholar]
- Lee, H.Y.; Koopmeiners, J.S.; McHugh, J.; Raveis, V.H.; Ahluwalia, J.S. mHealth pilot study: Text messaging intervention to promote HPV vaccination. Am. J. Health Behav. 2016, 40, 67–76. [Google Scholar] [CrossRef] [Green Version]
- Weaver, K.E.; Ellis, S.D.; Denizard-Thompson, N.; Kronner, D.; Miller, D.P. Crafting appealing text messages to encourage colorectal cancer screening test completion: A qualitative study. JMIR. Mhealth. Uhealth 2015, 3, e100. [Google Scholar] [CrossRef] [PubMed]
- Jannis, M.; Brüngel, R.; Friedrich, C.M. Server-focused security assessment of mobile health apps for popular mobile platforms. J. Med Internet Res. 2019, 21, e9818. [Google Scholar]
- Mehrdad, A.; Black, M.; Yadav, N. Security Vulnerabilities in Mobile Health Applications. In Proceedings of the 2018 IEEE Conference on Application, Information and Network Security (AINS), Langkawi, Malaysia, 21–22 November 2018. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Attribute Name | Type | Missing Values |
|---|---|---|---|
| 1 | Age | Int | 0 |
| 2 | Number of sexual partners | Int | 26 |
| 3 | First sexual intercourse (age) | Int | 7 |
| 4 | Num of pregnancies | Int | 56 |
| 5 | Smokes | bool | 13 |
| 6 | Smokes (years) | bool | 13 |
| 7 | (Smokes (packs/year) | bool | 13 |
| 8 | Hormonal Contraceptives | bool | 108 |
| 9 | Hormonal Contraceptives (years) | Int | 108 |
| 10 | Intrauterine Device (IUD) | bool | 117 |
| 11 | IUD (years) | Int | 117 |
| 12 | Sexually Transmitted Disease (STD) | bool | 105 |
| 13 | STDs (number) | Int | 105 |
| 14 | STDs: condylomatosis | bool | 105 |
| 15 | STDs: cervical condylomatosis | bool | 105 |
| 16 | STDs: vaginal condylomatosis | bool | 105 |
| 17 | STDs: vulvo-perineal condylomatosis | bool | 105 |
| 18 | STDs: syphilis | bool | 105 |
| 19 | STDs: pelvic inflammatory disease | bool | 105 |
| 20 | STDs: genital herpes | bool | 105 |
| 21 | STDs: molluscum contagiosum | bool | 105 |
| 22 | STDs: AIDS | bool | 105 |
| 23 | STDs: HIV | bool | 105 |
| 24 | STDs: Hepatitis B | bool | 105 |
| 25 | STDs: HPV | bool | 105 |
| 26 | STDs: Number of diagnosis | Int | 0 |
| 27 | STDs: Time since first diagnosis | Int | 787 |
| 28 | STDs: Time since last diagnosis | Int | 787 |
| 29 | Dx: Cancer | bool | 0 |
| 30 | Dx: Cervical Intraepithelial Neoplasia (CIN) | bool | 0 |
| 31 | Dx: Human Papillomavirus (HPV) | bool | 0 |
| 32 | Diagnosis: Dx | bool | 0 |
| 33 | Hinselmann: target variable | bool | |
| 34 | Schiller: target variable | bool | |
| 35 | Cytology: target variable | bool | |
| 36 | Biopsy: target variable | bool |
| Performance Metric | Formula |
|---|---|
| Precision | |
| Recall/Sensitivity | |
| Specificity/True Negative Rate | TN/(TN + FP) |
| F1 Score | 2 × (Precision × Recall)/(Precision + Recall) |
| Accuracy |
| Predicted as “Yes” | Predicted as “No” | |
|---|---|---|
| Actual “Yes” | True Positive (TP) | False Negative (FN) |
| Actual “No” | False Positive (FP) | True Negative (TN) |
| No | Feature’s Name | Features Scores |
|---|---|---|
| 1 | Smokes (years) | 421.4689 |
| 2 | Hormonal Contraceptives (years) | 246.6243 |
| 3 | Sexually Transmitted Diseases (STDs) (number) | 87.28867 |
| 4 | STDs: genital herpes | 43.73654 |
| 5 | STDs: HIV | 29.35086 |
| 6 | STDs: Number of diagnosis | 21.74795 |
| 7 | Dx: Cancer | 21.74795 |
| 8 | Dx: cervical intraepithelial neoplasia (CIN) | 20.71644 |
| 9 | Dx: human papillomavirus (HPV) | 12.64184 |
| 10 | Dx | 12.44904 |
| Before SMOTE | After SMOTE | Before SMOTETomek | After SMOTETomek | ||||
|---|---|---|---|---|---|---|---|
| Minority (%) | Majority (%) | Minority (%) | Majority (%) | Minority (%) | Majority (%) | Minority (%) | Majority (%) |
| 55 (6.41%) | 803 (93.59%) | 803 (93.59%) | 803 (93.59%) | 55 (6.41%) | 803 (93.59%) | 803 (93.59%) | 803 (93.59%) |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 92.797 | 91.666 | 93.908 | 92.768 | 92.768 |
| MLP | 96.049 | 97.549 | 94.416 | 96.000 | 96.001 |
| Logistic Regression | 94.020 | 93.627 | 94.416 | 94.015 | 94.014 |
| Naïve Bayes | 93.666 | 96.568 | 90.355 | 93.506 | 93.516 |
| KNN | 94.289 | 98.039 | 89.847 | 94.001 | 94.014 |
| Proposed CCPM (Random Forest) | 97.025 | 98.039 | 95.939 | 97.006 | 97.007 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 94.692 | 93.782 | 95.544 | 94.682 | 94.683 |
| MLP | 95.697 | 95.854 | 95.544 | 95.696 | 95.696 |
| Regression | 95.697 | 95.854 | 95.544 | 95.696 | 95.696 |
| Naïve Bayes | 93.587 | 96.373 | 90.594 | 93.416 | 93.417 |
| KNN | 94.430 | 94.300 | 94.554 | 94.430 | 94.430 |
| Proposed CCPM (Random Forest) | 96.720 | 97.409 | 96.039 | 96.720 | 96.708 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy(%) |
|---|---|---|---|---|---|
| SVM | 95.501 | 90.957 | 99.456 | 95.154 | 95.161 |
| MLP | 96.432 | 93.085 | 99.456 | 96.233 | 96.236 |
| Regression | 96.131 | 93.085 | 98.913 | 95.965 | 95.967 |
| Naïve Bayes | 95.656 | 92.021 | 98.913 | 95.426 | 95.430 |
| KNN | 98.668 | 97.872 | 99.456 | 98.655 | 98.655 |
| Proposed CCPM (Random Forest) | 98.924 | 98.936 | 98.130 | 98.924 | 98.925 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 94.726 | 91.935 | 97.282 | 94.591 | 94.594 |
| MLP | 96.845 | 94.623 | 98.913 | 96.755 | 96.756 |
| Logistic Regression | 94.853 | 90.860 | 98.369 | 94.587 | 94.594 |
| Naïve Bayes | 94.619 | 90.322 | 98.369 | 94.316 | 94.324 |
| KNN | 97.302 | 96.774 | 97.826 | 97.297 | 97.297 |
| Proposed CCPM (Random Forest) | 98.918 | 98.924 | 98.913 | 98.918 | 98.919 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 95.582 | 96.292 | 94.807 | 95.572 | 95.572 |
| MLP | 97.759 | 96.825 | 95.710 | 96.759 | 97.662 |
| Logistic Regression | 95.297 | 91.594 | 98.498 | 95.096 | 95.106 |
| Naïve Bayes | 93.165 | 90.963 | 96.033 | 93.589 | 93.575 |
| KNN | 92.205 | 93.440 | 91.119 | 92.247 | 92.244 |
| Proposed CCPM (Random Forest) | 98.216 | 99.208 | 99.487 | 99.217 | 99.217 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 95.393 | 93.298 | 97.368 | 95.393 | 95.393 |
| MLP | 97.912 | 97.883 | 97.938 | 97.762 | 97.911 |
| Regression | 93.641 | 87.891 | 94.680 | 93.188 | 93.105 |
| Naïve Bayes | 93.587 | 96.373 | 90.594 | 93.416 | 93.417 |
| KNN | 94.580 | 97.387 | 91.150 | 94.261 | 91.260 |
| Proposed CCPM (Random Forest) | 99.509 | 99.484 | 99.463 | 99.474 | 99.479 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 96.613 | 94.623 | 97.563 | 96.141 | 96.143 |
| MLP | 98.771 | 97.291 | 98.677 | 98.774 | 97.724 |
| Regression | 94.497 | 91.714 | 96.938 | 94.363 | 94.373 |
| Naïve Bayes | 93.048 | 92.746 | 93.343 | 93.098 | 93.098 |
| KNN | 93.317 | 94.514 | 91.344 | 93.881 | 93.881 |
| Proposed CCPM (Random Forest) | 98.714 | 97.314 | 100.00 | 98.714 | 98.714 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 94.011 | 93.625 | 94.329 | 94.054 | 94.010 |
| MLP | 97.369 | 96.808 | 96.913 | 97.509 | 97.164 |
| Logistic Regression | 94.142 | 91.635 | 96.681 | 94.073 | 94.072 |
| Naïve Bayes | 93.085 | 92.000 | 95.172 | 93.866 | 93.866 |
| KNN | 94.762 | 94.707 | 91.344 | 93.072 | 93.072 |
| Proposed CCPM (Random Forest) | 98.463 | 98.907 | 98.074 | 98.499 | 98.495 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 98.500 | 98.492 | 98.507 | 98.500 | 98.500 |
| MLP | 98.759 | 100.00 | 98.760 | 98.759 | 98.759 |
| Logistic Regression | 97.796 | 98.994 | 96.568 | 97.766 | 97.766 |
| Naïve Bayes | 97.165 | 98.963 | 95.433 | 97.089 | 97.087 |
| KNN | 96.905 | 98.440 | 95.433 | 96.847 | 96.844 |
| Proposed CCPM (Random Forest) | 99.016 | 100.00 | 97.948 | 98.997 | 98.997 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 99.004 | 99.512 | 98.461 | 98.999 | 98.053 |
| MLP | 98.792 | 100.00 | 97.512 | 98.762 | 98.620 |
| Regression | 98.034 | 98.989 | 97.073 | 98.015 | 98.015 |
| Naïve Bayes | 93.587 | 96.373 | 90.594 | 93.416 | 93.417 |
| KNN | 97.580 | 98.507 | 96.550 | 97.561 | 97.560 |
| Proposed CCPM (Random Forest) | 99.509 | 100.00 | 98.963 | 99.504 | 99.504 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 99.514 | 97.012 | 97.024 | 98.509 | 98.530 |
| MLP | 98.771 | 96.050 | 98.677 | 98.774 | 98.270 |
| Regression | 98.537 | 97.014 | 98.058 | 98.533 | 98.533 |
| Naïve Bayes | 98.048 | 98.238 | 96.172 | 98.048 | 98.048 |
| KNN | 98.317 | 99.514 | 97.044 | 98.288 | 98.288 |
| Proposed CCPM (Random Forest) | 99.514 | 99.014 | 100.00 | 99.504 | 99.504 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 97.755 | 96.431 | 99.481 | 99.754 | 98.754 |
| MLP | 97.369 | 97.326 | 98.913 | 99.509 | 98.509 |
| Logistic Regression | 98.529 | 99.065 | 97.927 | 98.525 | 98.525 |
| Naïve Bayes | 97.085 | 98.000 | 96.172 | 97.066 | 97.066 |
| KNN | 97.782 | 98.507 | 97.044 | 97.772 | 97.772 |
| Proposed CCPM (Random Forest) | 98.514 | 100.00 | 98.974 | 99.509 | 99.509 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 94.475 | 99.519 | 87.807 | 93.852 | 93.872 |
| MLP | 91.759 | 90.465 | 92.710 | 94.759 | 94.682 |
| Logistic Regression | 84.999 | 80.000 | 89.393 | 84.637 | 84.635 |
| Naïve Bayes | 80.655 | 71.065 | 88.345 | 79.792 | 79.900 |
| KNN | 94.002 | 99.000 | 87.878 | 93.467 | 93.521 |
| Proposed CCPM (Random Forest) | 97.225 | 96.428 | 97.989 | 97.215 | 97.217 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 94.413 | 98.098 | 90.000 | 94.165 | 94.187 |
| MLP | 99.452 | 99.083 | 91.052 | 95.182 | 95.175 |
| Regression | 86.326 | 77.860 | 93.137 | 85.490 | 85.606 |
| Naïve Bayes | 81.145 | 84.882 | 85.912 | 80.123 | 80.128 |
| KNN | 91.111 | 90.952 | 80.888 | 89.560 | 89.620 |
| Proposed CCPM (Random Forest) | 97.228 | 97.428 | 97.989 | 97.715 | 97.716 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 94.333 | 97.963 | 90.293 | 94.041 | 94.043 |
| MLP | 93.771 | 94.291 | 93.677 | 91.774 | 91.724 |
| Regression | 83.098 | 79.487 | 87.980 | 84.671 | 84.641 |
| Naïve Bayes | 81.635 | 77.830 | 85.106 | 81.261 | 81.250 |
| KNN | 89.497 | 97.129 | 78.971 | 88.242 | 88.366 |
| Proposed CCPM (Random Forest) | 97.518 | 97.448 | 97.584 | 97.518 | 97.514 |
| Method | Precision (%) | Recall/Sensitivity (%) | Specificity (%) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| SVM | 93.231 | 99.038 | 85.556 | 92.512 | 92.537 |
| MLP | 91.998 | 92.788 | 94.913 | 92.523 | 92.234 |
| Logistic Regression | 85.784 | 77.669 | 92.422 | 84.093 | 84.900 |
| Naïve Bayes | 93.085 | 92.000 | 95.172 | 93.866 | 93.866 |
| KNN | 89.321 | 93.333 | 84.532 | 89.071 | 89.108 |
| Proposed CCPM (Random Forest) | 97.463 | 97.907 | 97.074 | 97.499 | 97.495 |
| Studies | Method | No of Features | Sensitivity (%) | Specificity (%) | Accuracy (%) |
|---|---|---|---|---|---|
| Wu and Zhu [10] | SVM-RFE | 6 | 100 | 87.32 | 92.39 |
| 18 | 100 | 90.05 | 94.03 | ||
| SVM-PCA | 8 | 100 | 89.09 | 93.45 | |
| 11 | 100 | 90.05 | 94.03 | ||
| Abdoh et al. [22] | Smote-RF-RFE | 6 | 94.94 | 95.52 | 95.23 |
| 18 | 94.42 | 97.26 | 95.87 | ||
| Smote-RF-PCA | 8 | 93.77 | 97.26 | 95.55 | |
| 11 | 94.16 | 97.76 | 95.74 | ||
| Present work | DBSCAN + SMOTETomek + RF | 10 | 97.409 | 96.039 | 96.708 |
| DBSCAN + SMOTE+ RF | 10 | 98.039 | 95.939 | 97.007 | |
| iForest + SMOTETomek + RF | 10 | 98.924 | 98.913 | 98.919 | |
| iForest + SMOTE + RF | 10 | 98.936 | 98.130 | 98.925 |
| Studies | Method | No of Features | Sensitivity (%) | Specificity (%) | Accuracy (%) |
|---|---|---|---|---|---|
| Wu and Zhu [10] | SVM-RFE | 7 | 98.73 | 84.46 | 90.18 |
| 18 | 98.73 | 84.63 | 90.18 | ||
| SVM-PCA | 6 | 98.99 | 83.14 | 89.49 | |
| 12 | 98.99 | 84.30 | 90.18 | ||
| Abdoh et al. [22] | Smote-RF-RFE | 7 | 93.24 | 90.31 | 91.73 |
| 18 | 93.51 | 92.35 | 92.91 | ||
| Smote-RF-PCA | 6 | 92.70 | 96.17 | 94.49 | |
| 12 | 92.03 | 97.58 | 94.88 | ||
| Present work | DBSCAN + SMOTETomek + RF | 10 | 99.48 | 99.46 | 99.48 |
| DBSCAN + SMOTE+ RF | 10 | 99.20 | 99.49 | 99.22 | |
| iForest + SMOTETomek + RF | 10 | 98.91 | 98.07 | 98.50 | |
| iForest + SMOTE + RF | 10 | 97.31 | 100 | 98.71 |
| Studies | Method | No of Features | Sensitivity (%) | Specificity (%) | Accuracy (%) |
|---|---|---|---|---|---|
| Wu and Zhu [10] | SVM-RFE | 5 | 100 | 84.63 | 90.77 |
| 15 | 100 | 84.49 | 93.69 | ||
| SVM-PCA | 5 | 100 | 84.63 | 92.09 | |
| 11 | 100 | 84.65 | 93.79 | ||
| Abdoh et al. [22] | Smote-RF-RFE | 5 | 96.52 | 93.80 | 95.14 |
| 15 | 96.65 | 95.14 | 95.88 | ||
| Smote-RF-PCA | 5 | 96.52 | 98.30 | 97.42 | |
| 11 | 96.52 | 98.42 | 97.48 | ||
| Present work | DBSCAN + SMOTETomek + RF | 10 | 100 | 98.96 | 99.50 |
| DBSCAN + SMOTE+ RF | 10 | 100 | 97.95 | 99.01 | |
| iForest + SMOTETomek + RF | 10 | 100 | 98.97 | 99.50 | |
| iForest + SMOTE + RF | 10 | 99.01 | 100 | 99.50 |
| Studies | Method | No of features | Sensitivity (%) | Specificity (%) | Accuracy (%) |
|---|---|---|---|---|---|
| Wu and Zhu [10] | SVM-RFE | 8 | 100 | 84.42 | 90.65 |
| 15 | 100 | 87.28 | 92.37 | ||
| SVM-PCA | 8 | 100 | 86.65 | 91.98 | |
| 11 | 100 | 87.44 | 92.46 | ||
| Abdoh et al. [22] | Smote-RF-RFE | 8 | 87.37 | 97.54 | 92.52 |
| 15 | 93.56 | 98.15 | 95.89 | ||
| Smote-RF-PCA | 8 | 95.58 | 97.17 | 96.39 | |
| 11 | 95.32 | 98.40 | 96.89 | ||
| Present work | DBSCAN + SMOTETomek + RF | 10 | 97.43 | 98.01 | 97.72 |
| DBSCAN + SMOTE+ RF | 10 | 96.43 | 98.01 | 97.22 | |
| iForest + SMOTETomek + RF | 10 | 97.91 | 97.08 | 97.50 | |
| iForest + SMOTE + RF | 10 | 97.45 | 97.58 | 97.51 |
| Model Name | Time Complexity | Space Complexity |
|---|---|---|
| KNN | O(knd) | O(nd) |
| Logistic Regression | O(nd) | O(d) |
| SVM | O(n²) | O(kd) |
| Naive Bayes | O(nd) | O(cd) |
| Random Forest | O(nlog(n)dk) | O(depth of tree ∗ k) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ijaz, M.F.; Attique, M.; Son, Y. Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods. Sensors 2020, 20, 2809. https://doi.org/10.3390/s20102809
Ijaz MF, Attique M, Son Y. Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods. Sensors. 2020; 20(10):2809. https://doi.org/10.3390/s20102809
Chicago/Turabian StyleIjaz, Muhammad Fazal, Muhammad Attique, and Youngdoo Son. 2020. "Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods" Sensors 20, no. 10: 2809. https://doi.org/10.3390/s20102809
APA StyleIjaz, M. F., Attique, M., & Son, Y. (2020). Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods. Sensors, 20(10), 2809. https://doi.org/10.3390/s20102809