1. Introduction
Condition assessment of civil engineering structures for its safety and remaining lifetime has been in focus for the past couple of decades. Mostly, it consisted of harnessing dynamic response by attaching acceleration and displacement sensors with further post-processing of the data to evaluate the presence of damage in those structures. This method provides the global behavioral pattern of the structure which may sometimes provide local damage indications depending on the kind of structure and the spatial density of the sensors.
On the other hand, local assessment of structural damage is mostly carried out by visual inspection by experts. Otherwise, by placing contact-based strain sensors or by carrying out acoustic-based non-destructive testing. Sun et al. [
1] present a detailed review of structural health monitoring methods based on the big data and artificial intelligence algorithms for bridges, as well as identifies challenges associated with them. However, given the size of the structure itself, the whole process becomes time-consuming and prone to human errors. In addition, in some regions of the structure, it is difficult for human beings to gain access. Contact-based sensors also suffer from high maintenance due to the wrath of the exterior environment they are exposed to.
Recent advances in the application of non-contact camera-based structural health monitoring got huge incentive with the development in high-resolution cameras coupled with robust computer vision algorithms. Some of the real-life applications of such computer vision algorithms include face detection in mobile cameras, motion detection for surveillance, traffic sign, and pedestrian detection in autonomous cars. Similar technologies can be customized to detect local damages on structural surfaces using video measurements. Video acquired from surveillance cameras installed on important structures, like bridges, is a valuable source of data for damage detection. Moreover, fast and automatic damage inspection of large scale structures can be performed using the unmanned aerial vehicle (UAV) equipped with a digital camera and onboard microprocessor. Koch et al. [
2] present a review of computer vision algorithms that have been used for damage detection and condition assessment of civil infrastructure.
The previously reported methods for detecting cracks on concrete surfaces from its image can be broadly classified into two categories: image processing and machine learning. Some of the earlier works involve application of image processing techniques to identify the edges in the image which corresponds to presence of crack patterns. Among various methods of edge detection from images, like Sobel filter, Canny edge detector, Fast Fourier Transform (FFT), and Fast Haar Transform (FHT), Abdel-Qader et al. [
3] found FHT to be superior among them. Yamaguchi and Hashimoto [
4] identified crack pixels in an image using the technique of iterative percolation. Hutchinson and Chen [
5] obtained the optimal thresholding parameters of Canny edge detection and FHT using Bayesian decision theory.
Methods based on only image processing rely on the efficient extraction of predefined visual crack features, which does not require supervised learning using extensive labeled image data. Image processing involves extracting preset features from an image that can visually identify damages in structures in a qualitative sense. However, the methods are less robust as the preset features that are looked for do not encompass extensive variability that real images offer, like luminescence, surface texture, shadow, scale, and rotation invariance, as well as noise content. A large amount of dataset in form of images of both cracked and uncracked concrete surfaces is utilized to extract quantitative features. Such a bag of features, along with the binary labels of cracked or uncracked, are used to train a classification model that can predict whether an image of the concrete surface has the presence of cracks or not. Jahanshahi et al. [
6] trained nearest-neighbor model, a polynomial kernel support vector machines (SVMs) model, and an artificial neural network model for binary image classification using morphological features of the detected objects. Chen et al. [
7] trained an SVMs binary classification model using local binary patterns (LBP) as features. Concrete surfaces consist of minor cracks due to its thermal expansion. Several kinds of superficial breathing cracks are also present on its surface which opens and closes due to varying loads. The continuous monitoring of structures subjected to cyclic loadings [
8] will provide valuable insights not only regarding deterioration and fracture processes but also in the planning of maintenance and repair. Therefore, the mere detection of cracks is not sufficient for damage detection. It is imperative to constantly monitor concrete surfaces for crack initiation and its propagation. Yang and Nagarajaiah [
9] proposed the method of dynamic tracking of damages on concrete surfaces. Bhowmick and Nagarajaiah [
10] further developed the method to detect and quantify multiple damages on concrete surface from its video.
The previously described methods of binary classification using machine learning depend on the extraction of relevant features from the images. This step of feature engineering is skipped while using methods based on deep convolution neural network (D-CNN) as it can adaptively learn relevant features of the images in its training phase.But, the main benefit of D-CNN models is the significant improvement of the accuracy they provide over the other machine learning methods [
11,
12,
13], given large labeled image dataset is available. Cha et al. [
14] trained a D-CNN model using 40 k manually annotated images of dimension
for detecting the presence or absence of cracks in images of concrete surfaces. Chen and Jahanshahi [
15] used 5326 manually annotated images of pixel size
which were extensively augmented to increase the data size to more than 250 k by rotating, flipping and varying brightness of the images to train D-CNN which was augmented with Naive Bayes classifier to separate out cracks from non-cracks using results of consecutive frames of a video. In both the methods, the trained network takes as input an image of the concrete surface of the specific pixel size as it is trained for and outputs a label of crack or non-crack. For an image of a concrete surface larger than the image size with which the network is trained, the method first extracts cropped image patches of required dimension using the technique of sliding window. The individual extracted patches are further predicted as damaged or not; if damaged, then a square bounding box is drawn around the patch in the original image. Thus, for a large image of a concrete surface or video sequence, the detected cracks are marked with a bounding box. The results on the validation set show excellent performance of the classification algorithm, but the method fails to reveal more information such as length, width, and area of the crack apart from its detection.
Although the technique of image classification using CNN could satisfactorily detect the presence of cracks by generating a bounding box, further information required to quantify the damage could not be processed from the obtained bounding box. Hence, the technique of image segmentation is utilized to classify the presence of cracks in the pixel level of an image. Very recently, deep neural network architectures are trained using pixel-level annotated images of concrete cracks to obtained an image segmentation model of concrete cracks. Ni et al. [
16] trained a modified GoogLeNet architecture [
17] with hand-labeled images of concrete cracks to propose a crack segmentation model. Kim and Cho [
18] trained a mask region-based CNN with hand-labeled concrete crack images to obtain a crack segmentation model and further measured the crack width of cracks present in a concrete wall using the output of the model. Liu et al. [
19] proposed DeepCrack, a deep neural network architecture for segmentation of concrete cracks. Liu et al. [
20] used U-Net architecture [
21] for image segmentation and showed that U-Net can achieve higher accuracy score of crack segmentation with less number of training images compared to previously reported segmentation networks. The pixel-level labeling of cracks from the concrete surface image is time-consuming and labor-intensive work. Hence, it is beneficial to use a CNN algorithm that requires less training set images to achieve high accuracy in segmentation score. In this study, the U-Net architecture is chosen for obtaining an image segmentation model that needs less number of pixel-annotated ground truth images to achieve high segmentation. The model is trained using only 346 images obtained from two different sources which include both the training and validation set, but the dataset is expanded using data augmentation to add variability in the training images. The efficacy and robustness of the trained model are experimentally verified on an 8-foot-long concrete beam pseudo-statically loaded till its failure. The whole experiment is video recorded using a camera mounted on a UAV. The video is processed using the trained segmentation model which detects the initiation and propagation of multiple cracks at different instants of time on the concrete beam. The image of the concrete beam used in experimental verification does not form part of the dataset used to train and validate the U-Net segmentation model. This makes the trained U-Net model completely unbiased towards the outcome of the segmentation results, as well as confirms the robustness of the model in segmenting unseen images of concrete surfaces in different environmental conditions. The segmented images of cracks are further processed to obtain geometric measurements of the cracks as they evolve with time.
The output of an image segmentation model to detect crack is also an image. Hence, further processing of the predicted image is needed to obtain the geometrical quantities which are essential for addressing condition assessment of concrete structures. Zhu et al. [
22] proposed morphological operations on crack map of concrete surface to obtain geometrical properties of cracks. Jahanshahi et al. [
6] proposed similar morphological operations to compute crack properties on concrete surface. Adhikari et al. [
23] proposed a method of retrieving crack length and width from its image. The geometrical properties of cracks are converted to physical units using a scaling factor obtained from a known dimension of a structural element within the acquired image [
6,
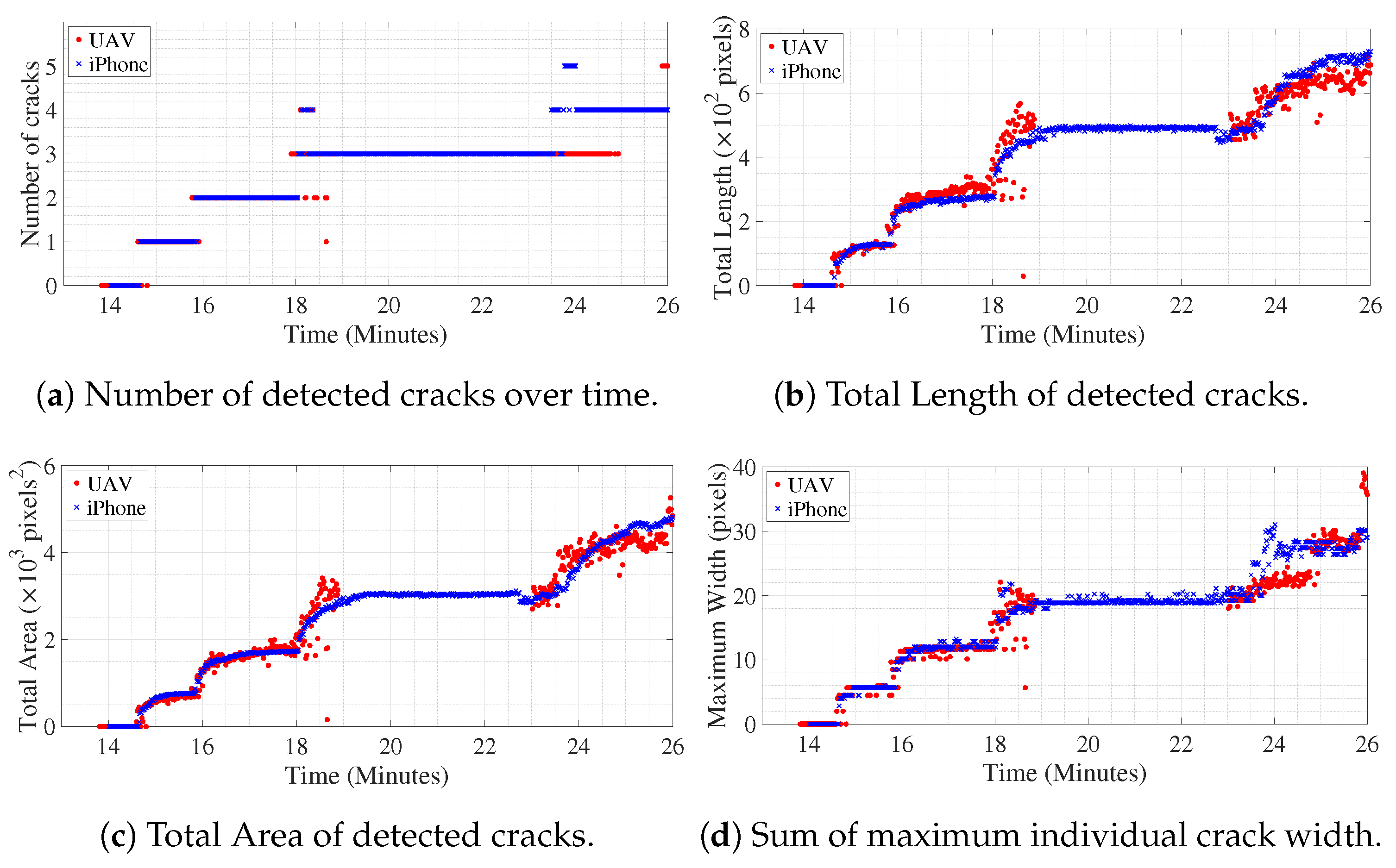
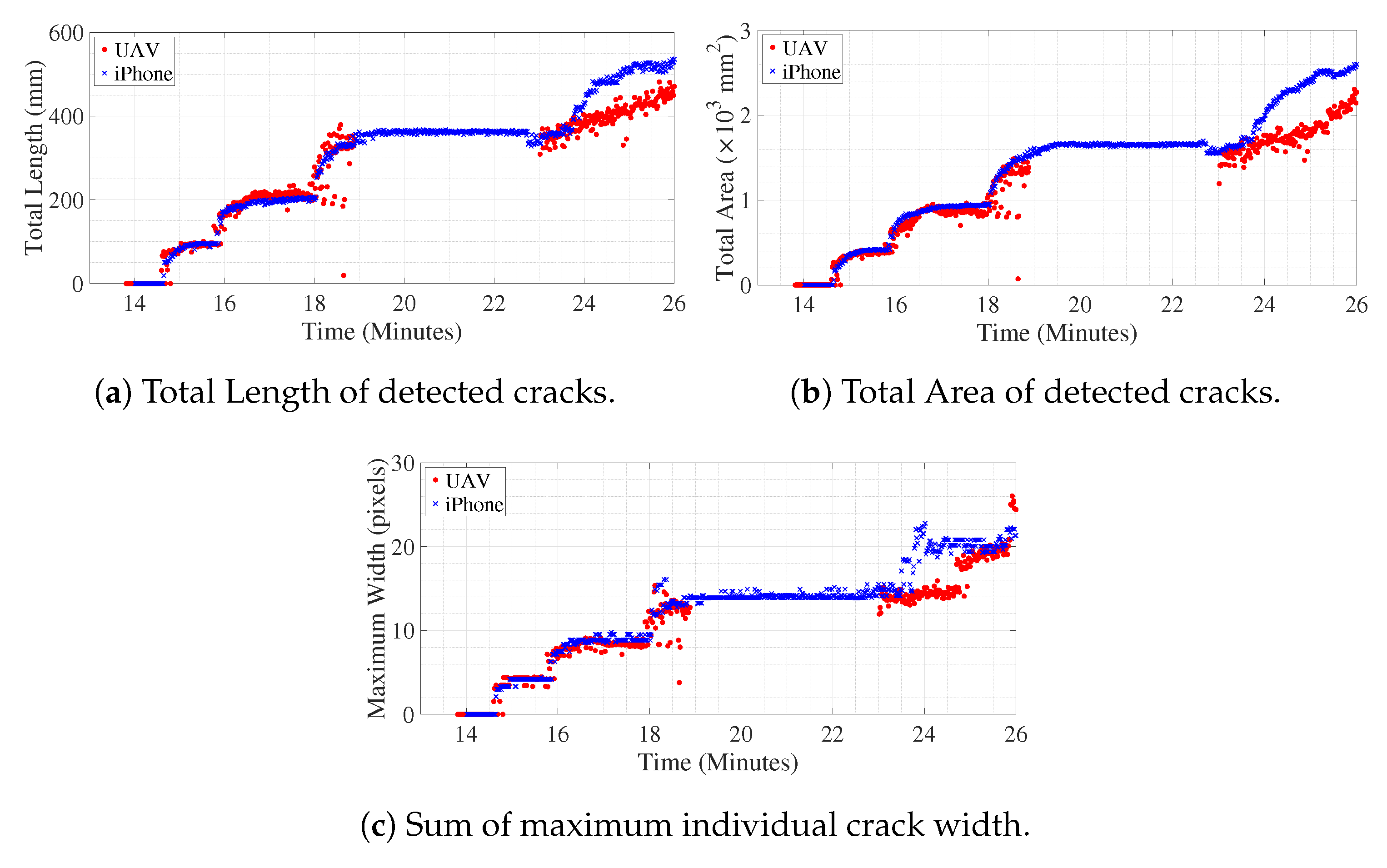
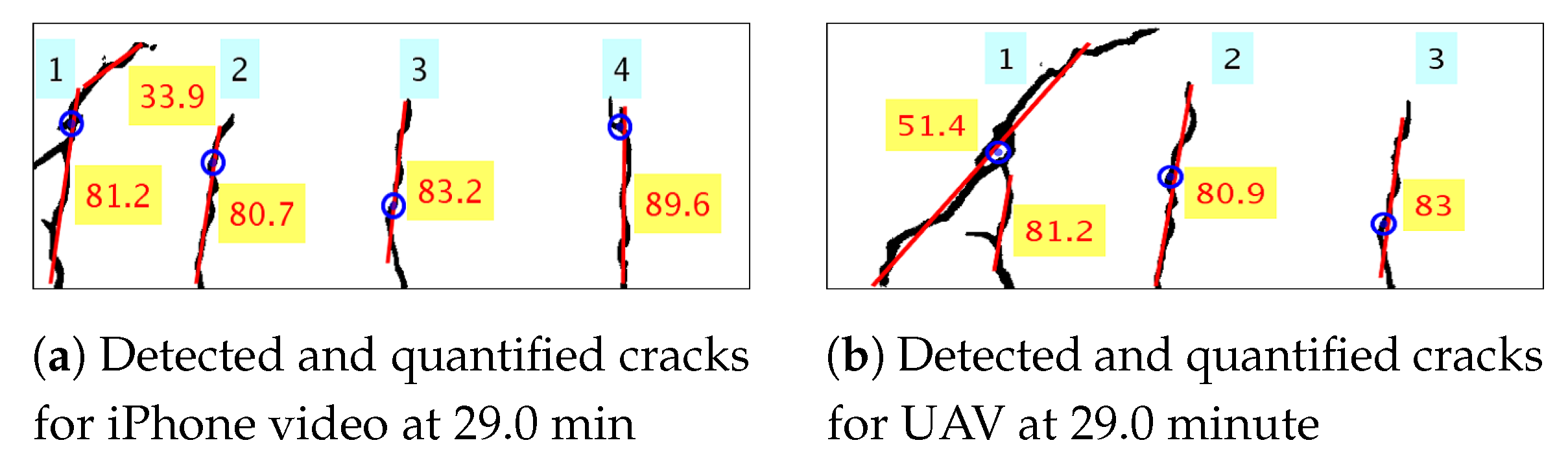
18]. However, the proposed operations are designed to compute length and the maximum width of single crack from an image of crack present in the concrete surface. In this paper, the crack quantification methodology extends to detect multiple cracks in each frame of the UAV video of the concrete surface. The length of individual cracks is measured, as well as the dense measurement of its width, along the length of the crack. The maximum crack width and its location in the image are identified in the image from the spatially dense measurement of crack width, along its length. The previous studies have fitted a straight line to the skeleton of the crack to measure its orientation. But, in real-life scenarios for concrete structures, one crack may divide to form multiple others, or several small cracks may join together to form a single crack. During the inspection of concrete structures, an expert infers the nature of crack from its dominant orientation, i.e., whether it is flexure or shear crack. Hence, the simple fitting of a straight line to those complex cracks does not provide a dominant orientation of the cracks, in turn, it does not provide required inference about the nature of the crack. In this study, the dominant orientation of multiple cracks are extracted individually and quantified such that proper inference about the cracks nature is possible. The method could track the evolution and propagation of multiple cracks by quantifying individual crack’s length, width, area, and dominant orientation. The qualitative nature of cracks is inferred using the measured dominant orientation of cracks throughout the course of the experiment, which confirms the evolution of initial flexure cracks to the formation of shear cracks near failure. To the best knowledge of the authors, such dense quantitative and qualitative inference of multiple crack propagation and evolution on a concrete surface from UAV video has not been presented before.
The final aim of implementing damage detection algorithms where input is an image of the concrete surface is to automate the process of structural inspection using Unmanned Aerial Vehicle (UAV) equipped with a video camera. But, some practical considerations need to be addressed in the overall framework from video acquisition to the quantification of damage. The video frames will not only capture the concrete surface but also contain other objects and background. In addition, mere detection of damages will not be enough if its quantification is required to complete the condition assessment of the structure. We propose the following steps for automatic detection of cracks and quantification of damage of concrete structure as an efficient substitute to manual inspection:
Monitoring of concrete structure using video measurements from high resolution camera mounted on UAV equipped with LiDAR (Light Detection and Ranging) system which can be used to create 3D mapping of the whole structure.
Segmentation of pixels belonging to structural surface from non-structural objects in each frame of the video.
Within pixels belonging to concrete surface, further segmentation of damages, like crack or spalling of concrete from non-damaged concrete surface pixels.
Quantification of the geometric properties of damages, along with its localization from the 3D mapping of the structure, will provide sufficient information to assess condition of the structure.
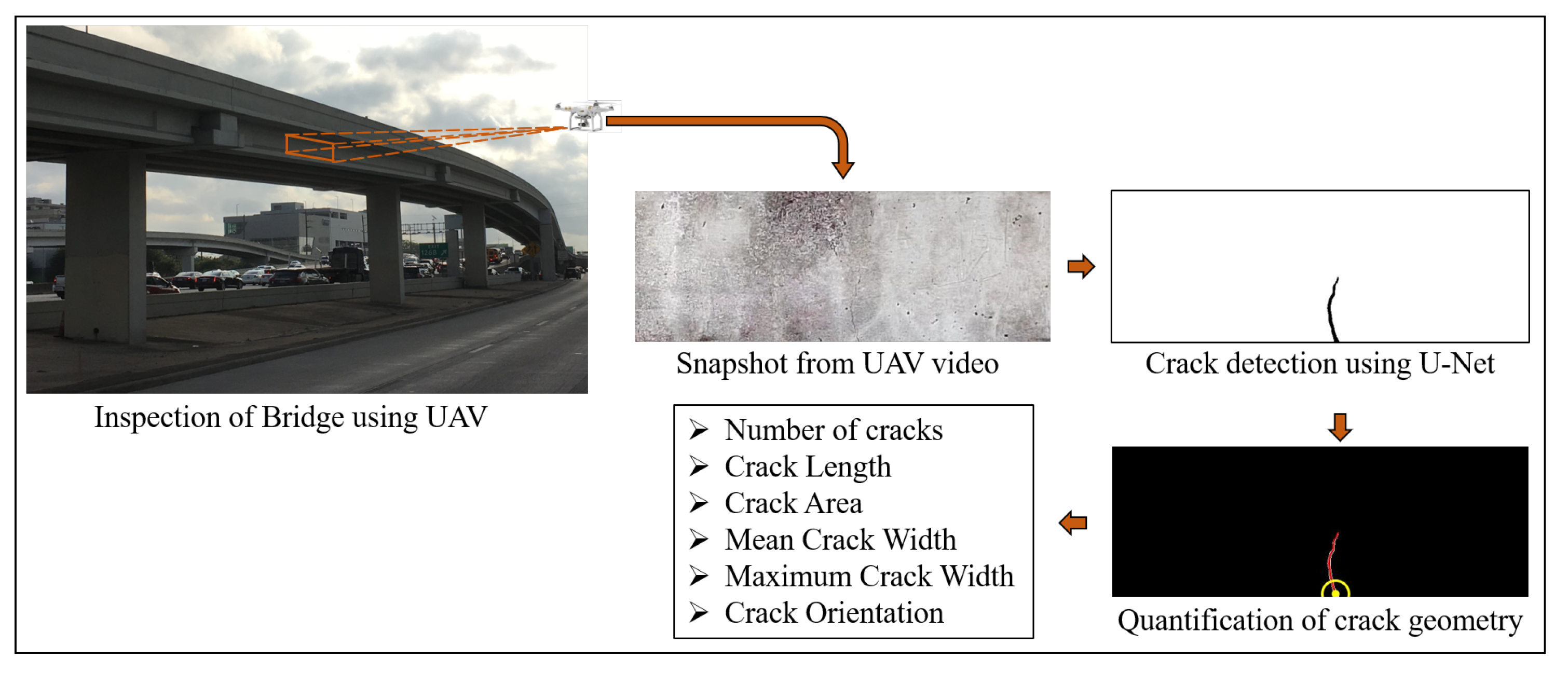
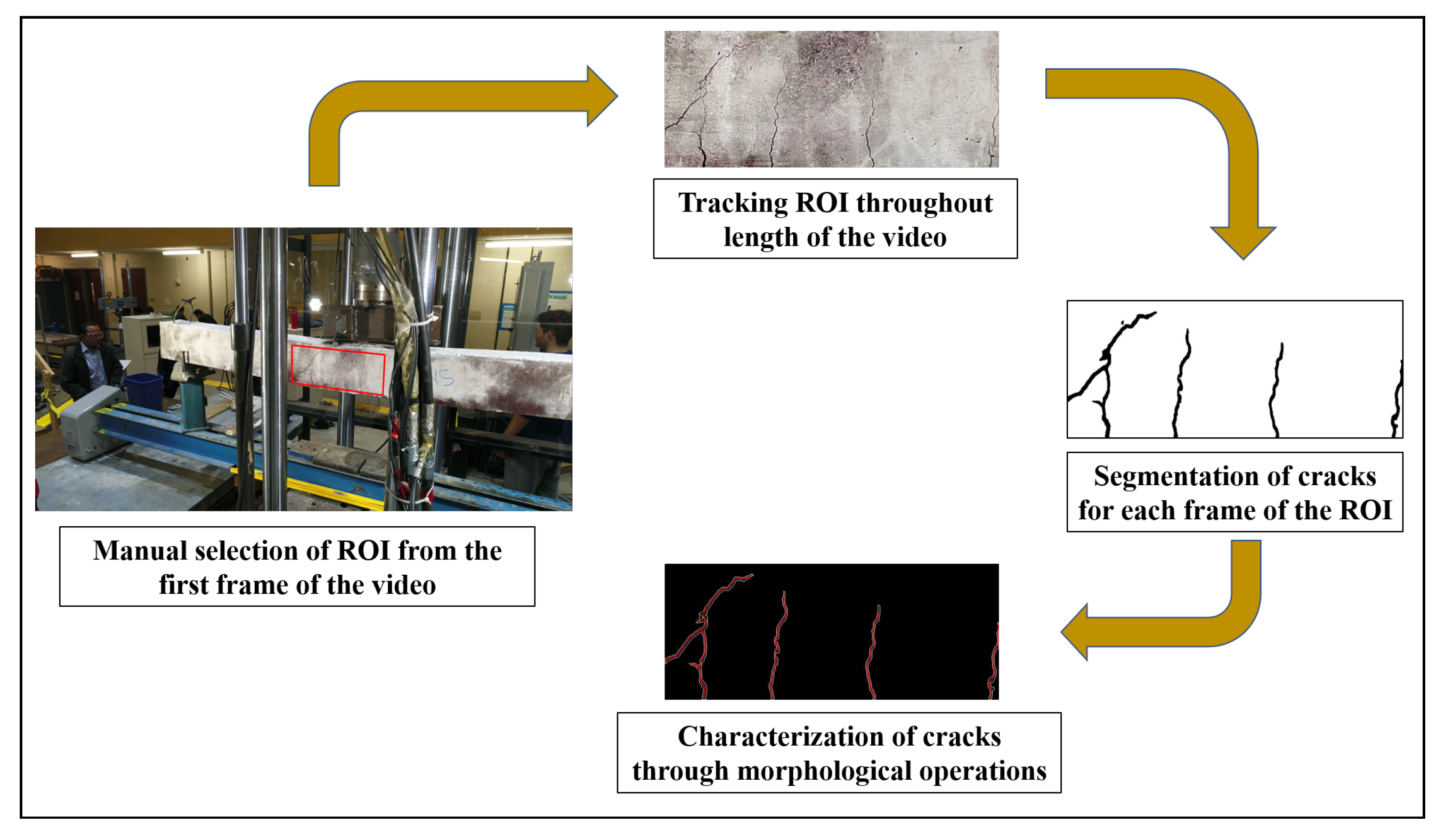
The suggested steps detect the presence of damage, localizes it with respect to the overall structure, further quantifies the damage based on its dimensions and location. This paper address steps 3 and 4 of the suggested framework instead of proposing a solution for the whole presented framework. The paper proposes a methodology to automatically detect and geometrically quantify cracks on the concrete surface from its video captured using UAV. The first two steps of the framework are beyond the scope of this study and are the subject of a future study. Hence, the concrete surface is tracked over subsequent frames of the video to automatically select the region of interest (ROI). The ROI is selected from the first frame of the video and the region is tracked over multiple frames of the UAV video even when the UAV is translated. The outline of the proposed framework is illustrated in
Figure 1 which uses video recorded using UAV for automatic bridge inspection to detect cracks, as well as quantify its geometric features. The paper proposes a Convolution Neural Network (CNN)-based segmentation algorithm to classify pixels belonging to cracks from images of concrete surface which only uses 205 images, along with its pixel-level annotated ground truth binary image, for its training and validation. The algorithm takes as input the image of the concrete surface and yields a binary image as output with pixels belonging to cracks, if present, having values of ones, and pixels containing uncracked concrete surface having zero values. The obtained binary image of the crack is required to obtain the geometric characteristics of the cracks, like length, area, width, and orientation of individual cracks, using image processing techniques. The obtained geometrical features are in pixel units which are converted to physical units using a scaling factor obtained using the known physical dimension of the structural element. The method extends beyond mere detection of cracks as it quantifies the amount of damage depending on its geometric properties. The proposed method is successfully able to detect and quantify cracks on the beam used for experimental validation from its recorded video.
The key contribution of the paper consists of experimentally validating the proposed method of detecting and quantifying cracks on the concrete surface from video obtained using UAV. The proposed methodology consists of training U-Net deep network architecture with a small number of the dataset obtained from two different sources. Then, the segmented image of the crack is processed to obtain spatially dense geometric measurements of cracks consisting of length, width, area and dominant orientation of individual cracks. The initiation, propagation, and evolution of individual cracks of the pseudo-statically loaded 8-foot-long beam for experimental validation are quantified at the pixel level, as well as in time. The obtained information is further used to infer the nature of crack formation. The method validates the formation of initial flexure cracks and then its evolution to shear cracks. To the best knowledge of the authors, this is the first instance of presenting the efficacy of crack detection, quantification, and inference of its propagation and evolution, using UAV videos. First, an image segmentation deep neural network is trained with a very small number of concrete surface images (346 pixel-annotated images). The binary crack image is processed to compute its geometrical properties, like length, width, area, and dominant orientation of the cracks, which helps in recognizing the nature of the crack, i.e., whether the crack is flexure or shear crack. Further, experimental validation of the proposed method includes the application of the trained image segmentation algorithm to detect the presence of cracks on a concrete beam using video recordings from UAV, as well as using a ground-based camera. The images used for training the segmentation network does not contain the images of the beam experiment. Hence, the result of the experiment validates the robustness of the trained model in detecting cracks at a pixel scale of different images of the concrete surface obtained using different sources and under a different condition that is not part of training data.
Section 2 describes the deep learning algorithm used for the segmentation of cracks from images of concrete surface. The deep neural network is trained using images of the concrete surface, along with its pixel-level annotated ground truth, the details of which are provided in
Section 3. Hyperparameters of the network are tuned using images from the validation set, which are kept separate from the training set as discussed in
Section 4. The quantification of the geometric properties of a crack is proposed in
Section 5 using morphological operations on binary images of crack objects. The details of the experimental validation of the suggested method are provided in
Section 6.
2. Deep Segmentation Network
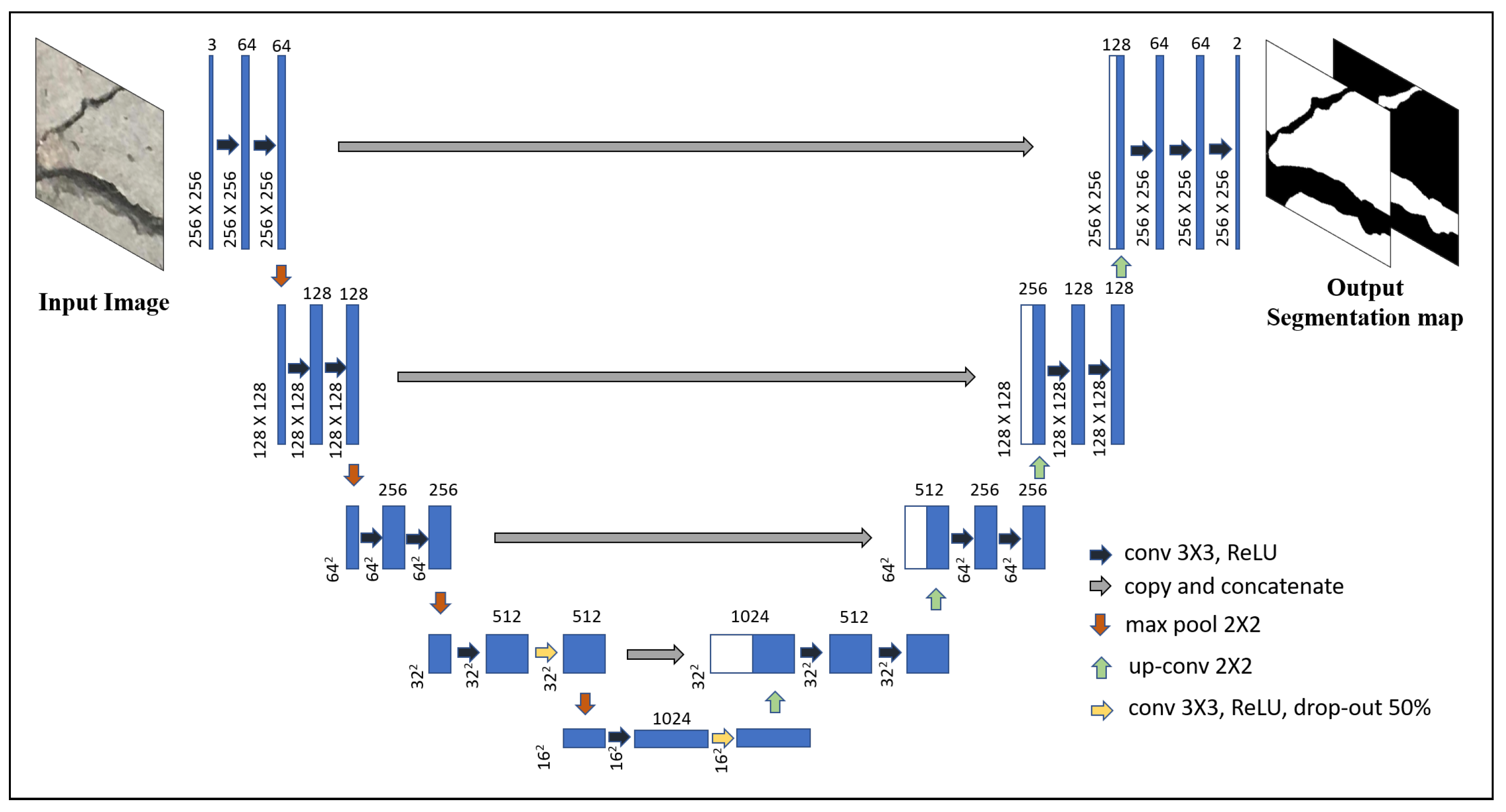
The Deep Learning architecture used in this paper, U-Net [
21], has proved effective in segmenting biomedical images where the amount of pixel annotated images are limited. It is a difficult and time-consuming process to gather images of concrete cracks, as well as manually construct ground truth of each image. But, the number of images used during training is further expanded by augmenting the dataset with random rotations and flipping both horizontally and vertically each original image as suggested in Reference [
21]. The details of the network architecture are shown in
Figure 2. The unique part of this CNN architecture consists of a contracting path followed by an expansive path. The adopted architecture is almost similar to the one suggested by Ronneberger et al. [
21] with small modifications. The input to the original U-net architecture consists of a grayscale image, or
for input image shape of
where
W,
H, and
D are the width, height, and depth of the image. But, in the modified architecture, the RGB image is used as input where
. In addition,
for input image in the modified architecture instead of
in the original one. The contracting part starts off with two
zero padded convolutions such that the output spatial dimension remains the same as the input but a number of feature map is extended to 64. Each convolution is followed by a rectified linear unit (ReLU) non-linear activation function. The feature maps are downsampled by carrying out
max pooling operation with stride 2. The steps are further repeated and each time after downsampling spatial dimension by max pooling, the number of feature maps is doubled in the subsequent convolution step. At the last two steps of the contraction side, drop out layer is added. In the expansive path, at each step, the spatial dimension is doubled by upsampling followed by
convolution (up-convolution), then the feature maps are doubled by concatenating corresponding feature maps from the contracting path, further carrying out
convolutions two times with ReLU activation. The final layer consists of
convolution layer with sigmoid activation to reduce the number of feature maps from 64 to a number of classes for pixel level classification. The zero padded convolutions ensure the output segmentation map is of the same size as that of the input image.
Both the input images and their pixel-level annotated ground truth are needed to optimize binary cross-entropy loss function which is computed by pixel-level softmax over the final feature map computed as.
where
is the activation in the
kth feature map at the pixel position
x and
K is the total number of classes. The cross entropy loss function is computed using the ground truth of the image as
where
, and
is the ground truth of
kth class at pixel
x.
is minimized using Adam optimization with adaptive learning rate. The weights of the convolution layers are initialized using He normal [
24].
5. Crack Characterization
The output of the algorithm so far provides a binary image to highlight crack present in the concrete surface. However, accessing the amount of damage, along with the subsequent decision of retrofitting, depends on the location of the crack, as well as its geometric properties, like its length, width, orientation, number of cracks, etc. This paper focuses on quantifying the geometrical properties of concrete surface cracks, by the use of morphological operations from image processing [
6,
22,
23].
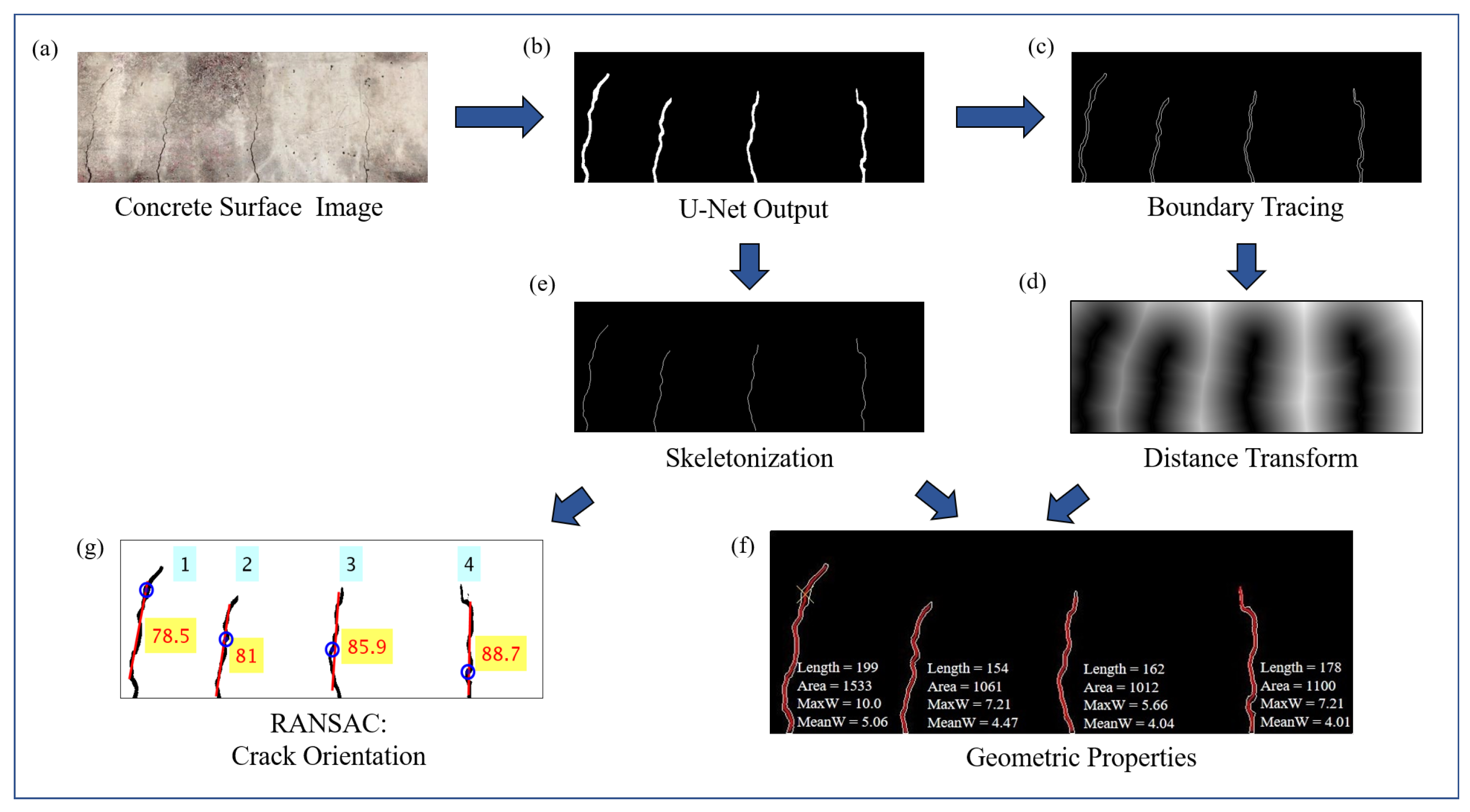
Figure 5 shows the flowchart of algorithms used to obtain pixel level information about crack geometry from the concrete surface image. The image in
Figure 5a is of the concrete surface with cracks, and
Figure 5b shows the output of trained U-net after applying Otsu’s thresholding method. The first step in the morphological operation involves finding out the pixel area of individual cracks in the binary image. A single crack in the binary image is object formed by continuous pixels, and if there is a gap of even a single pixel between the binary objects, then its a different crack. In order to filter out small blobs which may appear in the predicted binary image due to surface textures, a threshold for pixel area of individual cracks is set below which all the small objects are removed. This image is further processed to obtain single pixel thick outline of individual binary objects (cracks) as shown in
Figure 5c using boundary tracing morphological operation, as well as single pixel thick skeleton of the objects, as shown in
Figure 5e, which represents the center line of the cracks. Euclidean distance transform of the outline image shown in
Figure 5c is constructed as shown in
Figure 5d. Distance transform of a binary image provides another image in which pixel values represent the distance in pixels to the nearest non zero pixels. Hence, any particular pixel of the image in
Figure 5d represents its shortest distance to outline of cracks as represented in
Figure 5c. Its values corresponding to the center-line pixels shown in
Figure 5e provide the half width of cracks along the length of the individual cracks. Combining information from both
Figure 5e and
Figure 5d, the length and width in units of the pixel of the cracks, along its length, is obtained. The pixel area of individual cracks are obtained from
Figure 5b. The geometric properties of the cracks are obtained in units of pixels which can be transformed into physical units using the depth information of the camera from the concrete surface.
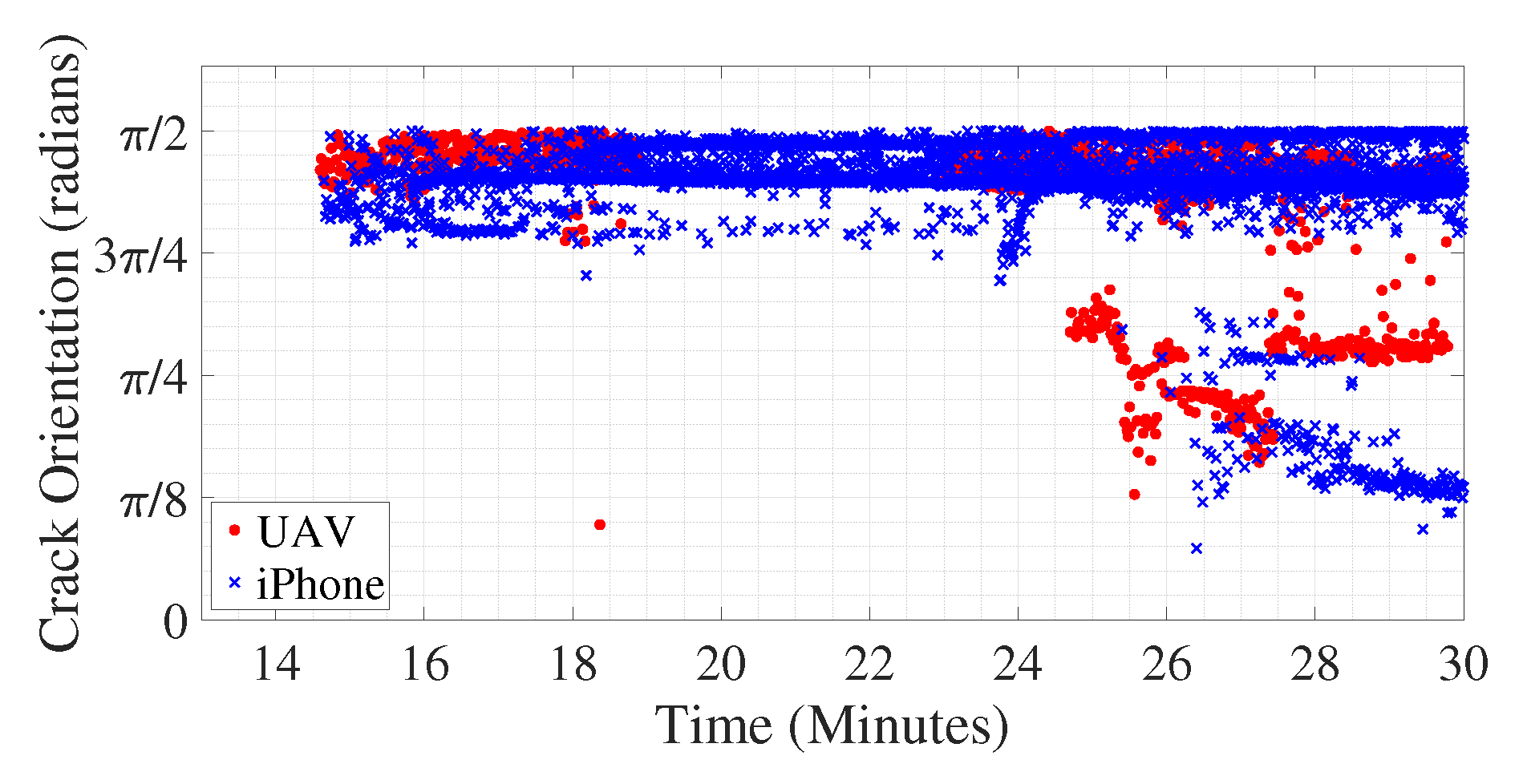
In order to separately detect the qualitative orientations of individual cracks (even for more than one dominant orientation for a single crack), Random sample consensus (RANSAC) [
31] algorithm is used on the skeleton pixels of individual cracks as shown in
Figure 5e. It is an iterative algorithm that looks for the best fitted straight line which passes through randomly chosen two points in every iteration. Perpendicular distance of all the points from the selected line is computed and compared against threshold distance in order to classify each pixel as inliers or outliers. The steps are iterated for a certain number of sample size and the model corresponding to the best inlier ratio is selected in the end. In this paper, the RANSAC algorithm is used in succession to find dominant crack orientations which can even be more than one for certain cracks as mentioned before. After applying RANSAC for the first time on a particular crack, the slope of the best-fitted model gives the most dominant crack orientation. If the outlier ratio is more than 0.2 (selected based on heuristics), the RANSAC algorithm is applied again on the remaining outlying points successively till the overall outlier ratio is less than 0.2, each time the slope of the best fitted straight line model on the residual pixels gives the next dominant orientation. The result of the algorithm provides crack orientation as shown in
Figure 5g.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}