
Federated Learning in Edge Computing: A Systematic Survey


Abstract
:1. Introduction
- Communication cost: Sending large amounts of data from EC nodes or edge devices to a remote server requires further network traffic encoding and transmission time. In other words, insufficient bandwidth negatively affects the efficiency of data transmission. In addition, cloud servers are often far from end-users, where data need to travel across multiple edge nodes. Therefore, a network with thousands of edge devices lacks the ability to meet the real-time, low-latency, and high Quality of Service (QoS) requirements due to the long-distance data transmission [9]. Therefore, the traditional cloud-based architecture is not suitable to accomplish the requirements mentioned above;
- Reliability: Clients send their datasets via different communication network connections to the remotely located cloud server in conventional centralized model-training architectures. Therefore, the wireless communications and core network connections between clients and servers affect DL model training and inferences to a large extent. Hence, the connection has to be reasonably reliable even when there is an interruption in the network. Nevertheless, a centralized architecture faces system performance degradation and possible failure because of the unreliable wireless connection between the client and server, which can significantly affect the model;
- Data privacy and security concerns: Due to concerns about privacy and unauthorized access to their data, users are often hesitant to share their information [10]. As a result, the specific implementation of a set of controls, applications, and techniques that identify the relative importance of various datasets, their sensitivity, compliance requirements, and the application of appropriate safeguards to secure these resources is required. Traditional centralized training, however, is vulnerable to sensitive data privacy breaches, intruders, hackers, and sniffers since clients have to share their raw data with third parties, such as cloud or edge servers, to train a model;
- Administrative policies: Data owners are becoming more concerned about their privacy. Following public fears about privacy in the age of Big Data, legislators have responded by enacting data privacy legislation. For example, the General Data Protection Regulation (GDPR in the European Union) [11], California Consumer Privacy Act (CCPA) [12] in the USA, and the Personal Data Protection Act (PDPA) in Singapore [13] intend to restrict the collection of data to only those that are needed for processing and consented to by consumers. Privacy legalization cannot be achieved by the traditional centralized model-training architecture since clients must send raw data to the server for model training.
2. Fundamentals of Edge Computing and Federated Learning
2.1. Edge Computing
2.2. Deep Learning
2.3. Enabling Deep Learning at the Edge
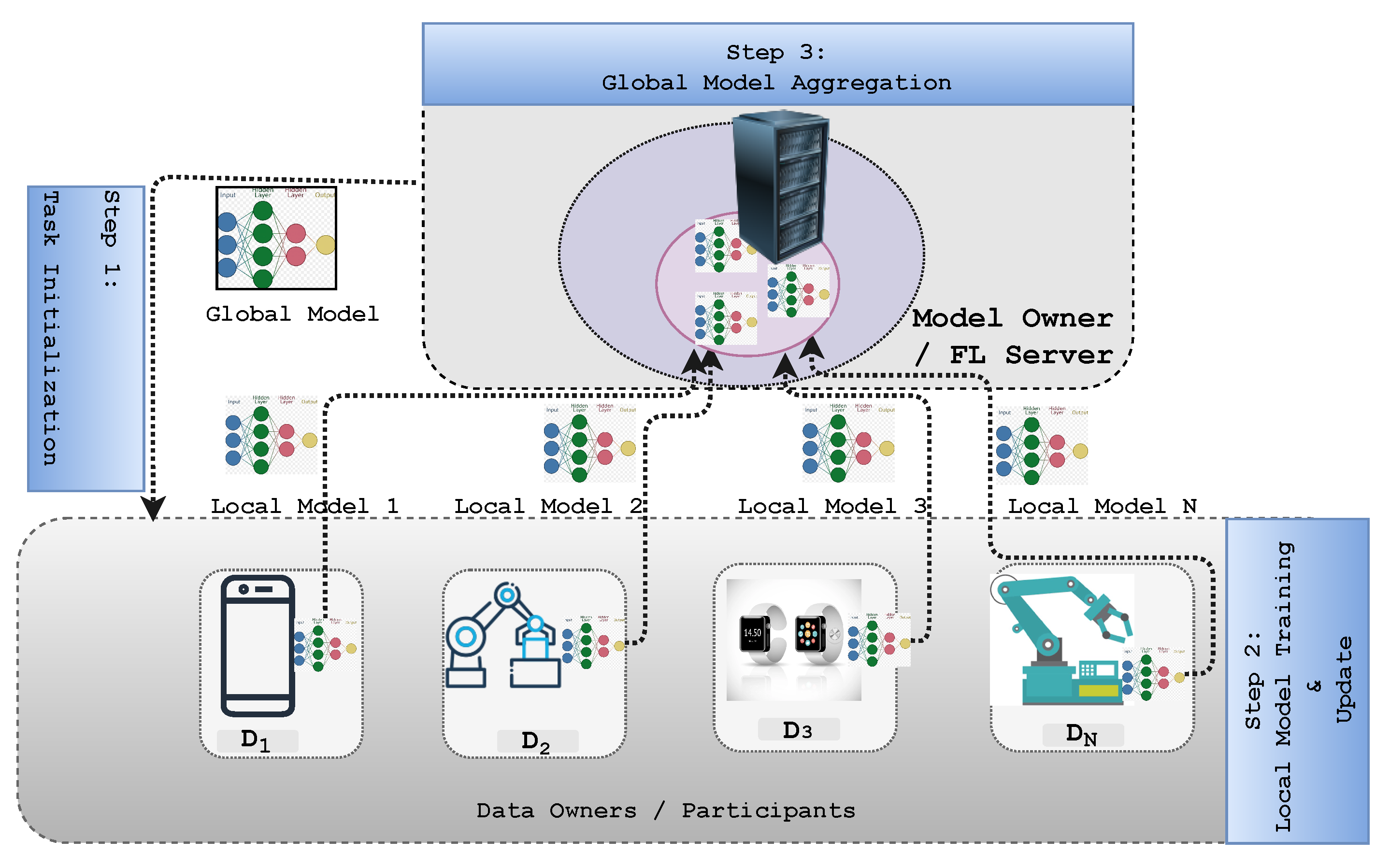
2.4. Federated Learning
- Task initialization: In a specific interval, the server selects a certain number of devices from the thousands available. It determines the target application and data requirements once the training task is specified. In addition, the server sets the hyperparameters related to the model and training process, such as the learning rate. Specifically, it initializes the weights on the server by leveraging weight initialization methods such as random, He, or Xavier initialization [3]. The parameter server disseminates the global model and the FL task to the selected participants after specifying the devices;
- Local model training: The participants receive the global model , where t denotes the current iteration index, and each participant updates the local model parameters based on their local data and device. The objective of client i is therefore to obtain an optimal parameter at the t time iteration at the minimum value of the loss function [50]:Finally, each local model’s updated parameters are sent again back to the FL parameter server;
- Global model aggregation: The centralized server receives the local parameters from each participant and aggregates the local models from the participants, then sends the updated global model parameters back to all the participating clients to minimize the global loss function, , i.e.,
3. Literature Review
3.1. Related Works on Federated Learning in Edge Computing
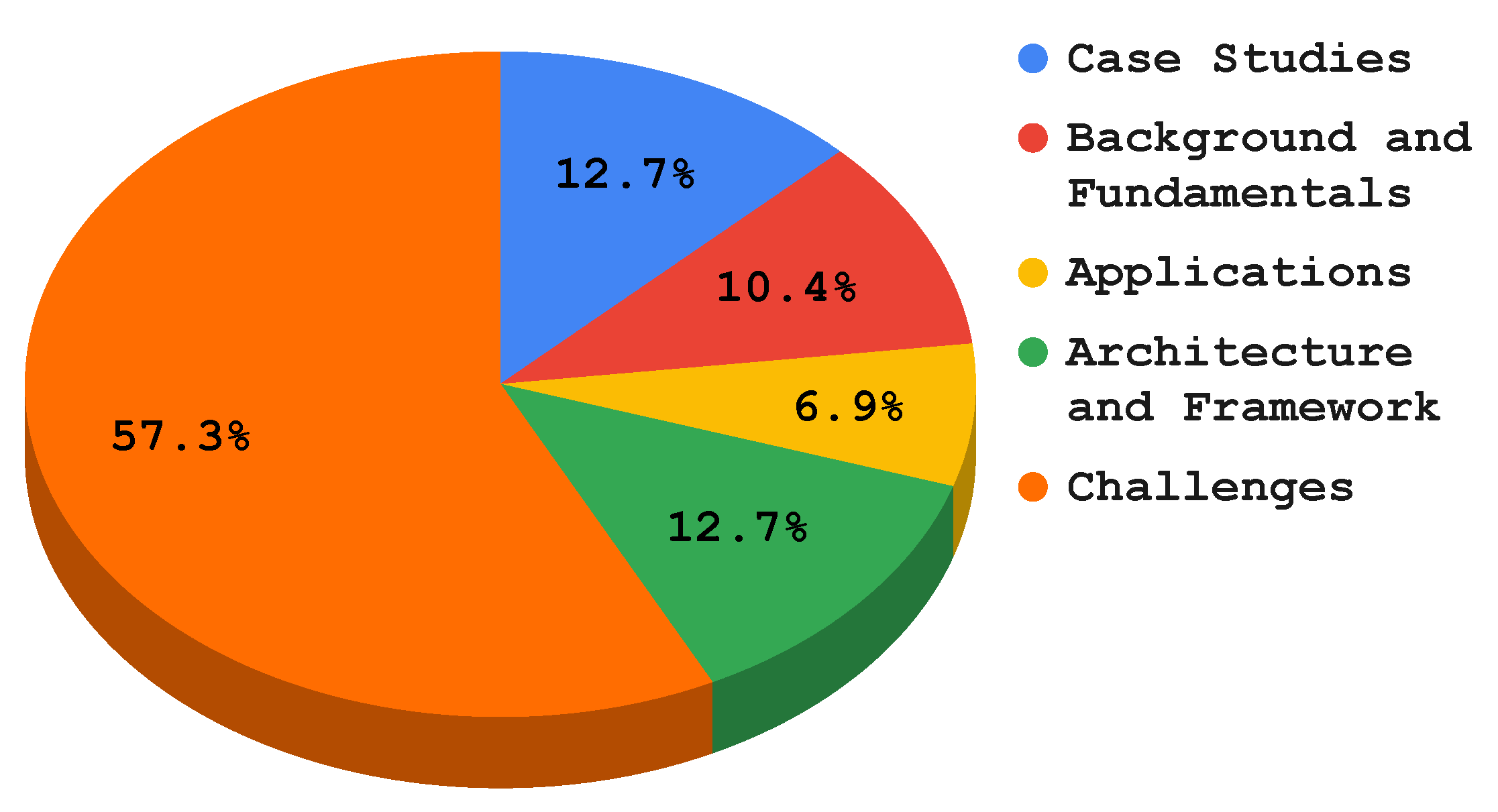
3.2. Contributions
- Classifying and describing the techniques and approaches to understand FL in the EC paradigm. Furthermore, this survey will help readers understand the current literature’s tendency and emphasis in the field of EC and FL;
- Categorizing and analyzing the challenges and constraints in EC to FL implementation settings;
- Identifying and evaluating state-of-the-art technical solutions to mitigate the challenges in FL implementation in the EC context;
- Providing case studies that leverage the enabling technologies of the FL and EC paradigm, such as healthcare and autonomous vehicles;
- Enhancing the understanding of FL implementation in the EC paradigm by providing insights into existing mechanisms and future research directions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Summary | SLR | EC | FL | CS | HWR | FRD |
|---|---|---|---|---|---|---|---|
| [7] | Survey on architecture and computation offloading in MEC | X | √ | X | √ | X | √ |
| [25] | Survey on convergence of the intelligent edge and edge intelligence | X | √ | X | √ | √ | √ |
| [62] | Communication and networking issues being addressed by DRL | √ | √ | X | X | X | √ |
| [33] | Survey on fog computing and related edge computing paradigms | X | √ | X | X | X | √ |
| [6] | Survey on the integrated management of mobile computing and wireless communication resources in MEC | X | √ | X | √ | X | √ |
| [63] | Edge intelligence architectures and frameworks’ survey | X | √ | X | X | X | √ |
| [64] | Survey on edge intelligence specifically for 6G networks | X | √ | X | √ | X | √ |
| [65] | Management of IoT systems, e.g., network security and management by leveraging ML | X | √ | X | √ | X | X |
| [66] | Survey on computation offloading approaches in mobile edge computing | √ | √ | X | √ | X | √ |
| [67] | Survey on techniques for computation offloading | X | √ | X | X | X | X |
| [68] | Survey on architectures and applications of MEC | X | √ | X | √ | X | √ |
| [69] | Survey on computation offloading modeling for edge computing | X | √ | X | X | X | √ |
| [70] | A MEC survey on computing, caching, and communications | X | √ | X | √ | X | √ |
| [71] | Comparative study of caching phases and caching schemes | X | √ | X | X | X | √ |
| [72] | Survey on MEC for the 5G network architecture | X | √ | X | X | X | X |
| [80] | Survey on the data privacy and security of FL | X | X | √ | X | X | √ |
| [81] | Survey on FL applications in industrial engineering and computer science | X | X | √ | √ | X | √ |
| [61] | Survey on FL research from five perspectives: data partition, privacy techniques, relevant ML models, communication architecture, and heterogeneity solutions | X | X | √ | X | X | √ |
| [82] | Proposed an FL building block taxonomy with six different aspects: data distribution, ML model, privacy mechanism, communication architecture, the scale of the federation, and the motivation for FL | √ | X | √ | √ | X | √ |
| [19] | Tutorial on FL challenges | X | X | √ | X | X | √ |
| [18] | Overview of current research trends and relevant challenges | X | X | √ | X | X | √ |
| [83] | Discussed the opportunities and challenges in FL | X | X | √ | √ | X | X |
| [84] | described the existing FL and proposed an architecture of FL systems | X | X | √ | X | X | √ |
| [17] | Described the different FL settings in more detail, emphasizing their architecture and categorization | X | X | √ | X | X | X |
| [85] | Discussion on the applicability of FL in smart city sensing | X | X | √ | √ | X | √ |
| [86] | Survey on the security threats and vulnerability challenges in FL systems | X | X | √ | X | X | √ |
| [87] | Summarized the most used defense strategies in FL | X | X | √ | X | X | X |
| [88] | Developed protocols and platforms to help industries in need of FL build privacy-preserving solutions | X | X | √ | √ | X | X |
| [89] | Performed a systematic literature review on FL from the software engineering perspective | √ | X | √ | X | X | √ |
| [90] | Highlighted FL’s applications in wireless communications | X | X | √ | X | X | √ |
| [50] | Discussed the basics and problems of FL for edge networks | X | √ | √ | √ | X | √ |
| [91] | Analysis of FL from the 6G communications perspective | X | X | √ | X | X | √ |
| [92] | Survey on FL-powered IoT applications to run on IoT networks | X | √ | √ | X | X | √ |
| [93] | Survey on the FL-enabled IIoT | X | √ | √ | √ | X | √ |
| [94] | Survey on FL implementation in wireless communications | X | X | √ | X | X | √ |
| [95] | Analysis of FL’s potential for enabling a wide range of IoT services | X | √ | √ | √ | X | √ |
| [96] | FDL application for UAV-enabled wireless networks | X | √ | √ | √ | X | √ |
| [97] | Survey on the implementation of FL and challenges | X | √ | √ | X | X | √ |
| [98] | Review of FL for vehicular IoT | X | √ | √ | √ | X | √ |
| [99] | Survey on FL for the future of digital health | X | √ | √ | √ | X | √ |
| [100] | Survey on applications of FL to autonomous robots | X | √ | √ | √ | X | √ |
| [101] | Review of FL technologies within the biomedical space and the challenges | X | √ | √ | √ | X | √ |
| [102] | A tutorial on FL in the domain of communication and networking | X | √ | √ | X | √ | √ |
| [65] | Analysis and design of heterogeneous federated learning | X | X | √ | X | X | √ |
| Our Paper | A systematic review on FL implementation in the EC paradigm | √ | √ | √ | √ | √ | √ |
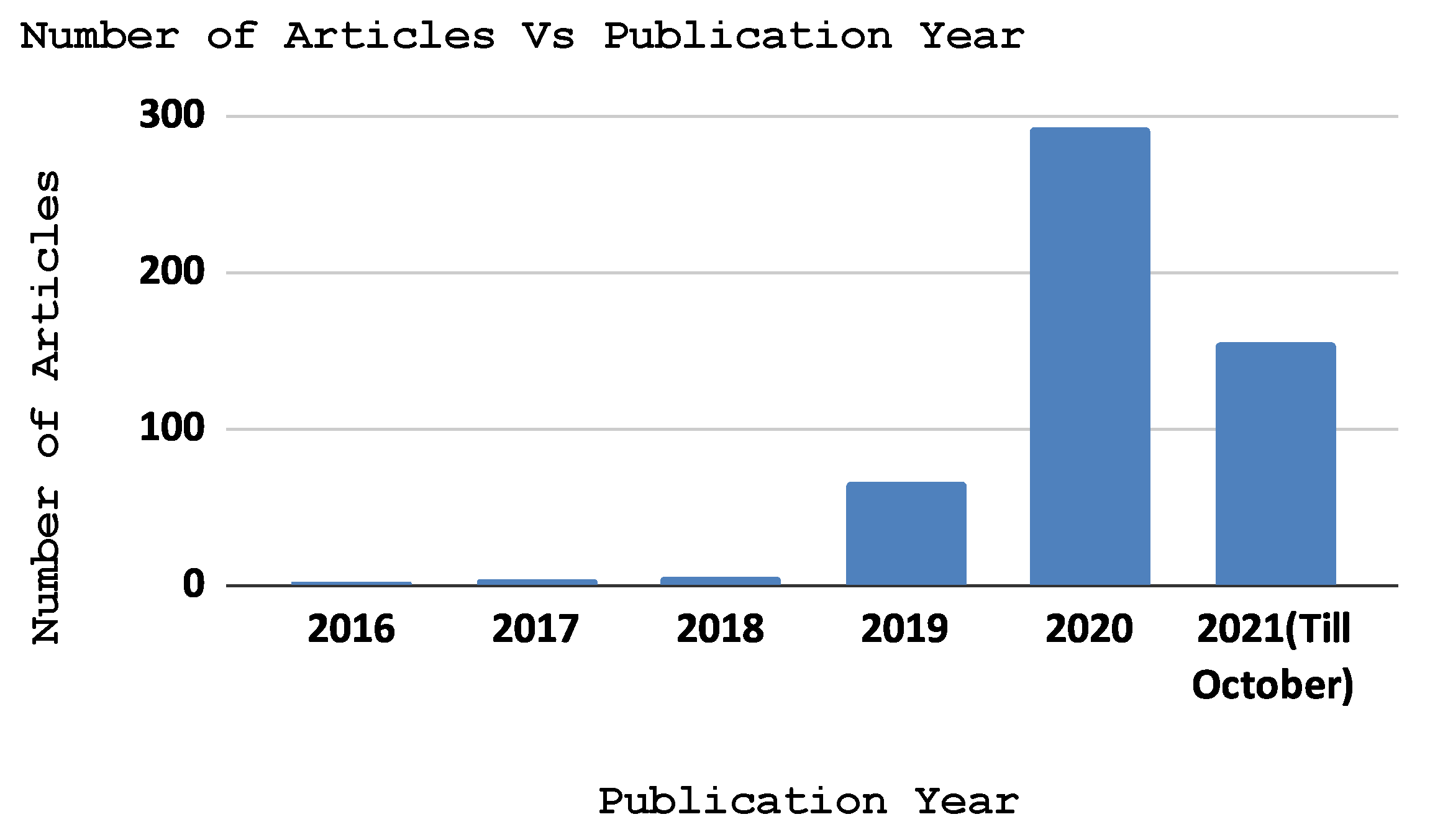
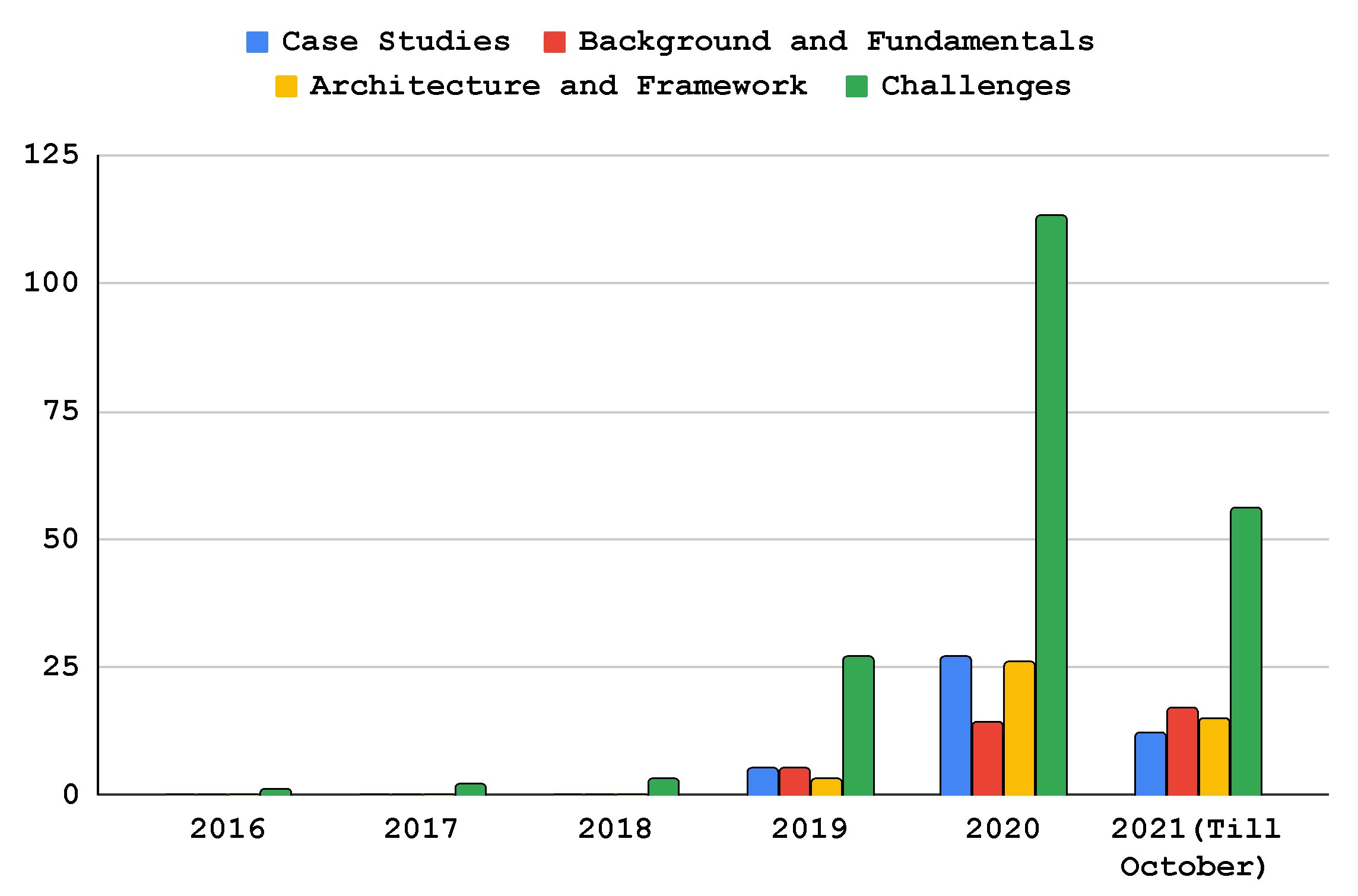
4. Research Methodology
4.1. Research Question Formulation (Stage I)
4.2. Source Selection and Strategy (Stage II)
4.3. Inclusion and Exclusion Methods (Stage III)
4.4. Analysis and Synthesis (Stage IV)
4.5. Reporting and Utilization of the Findings (Stage V)
5. Review and Analysis of Federated Learning Implementation in Edge Computing
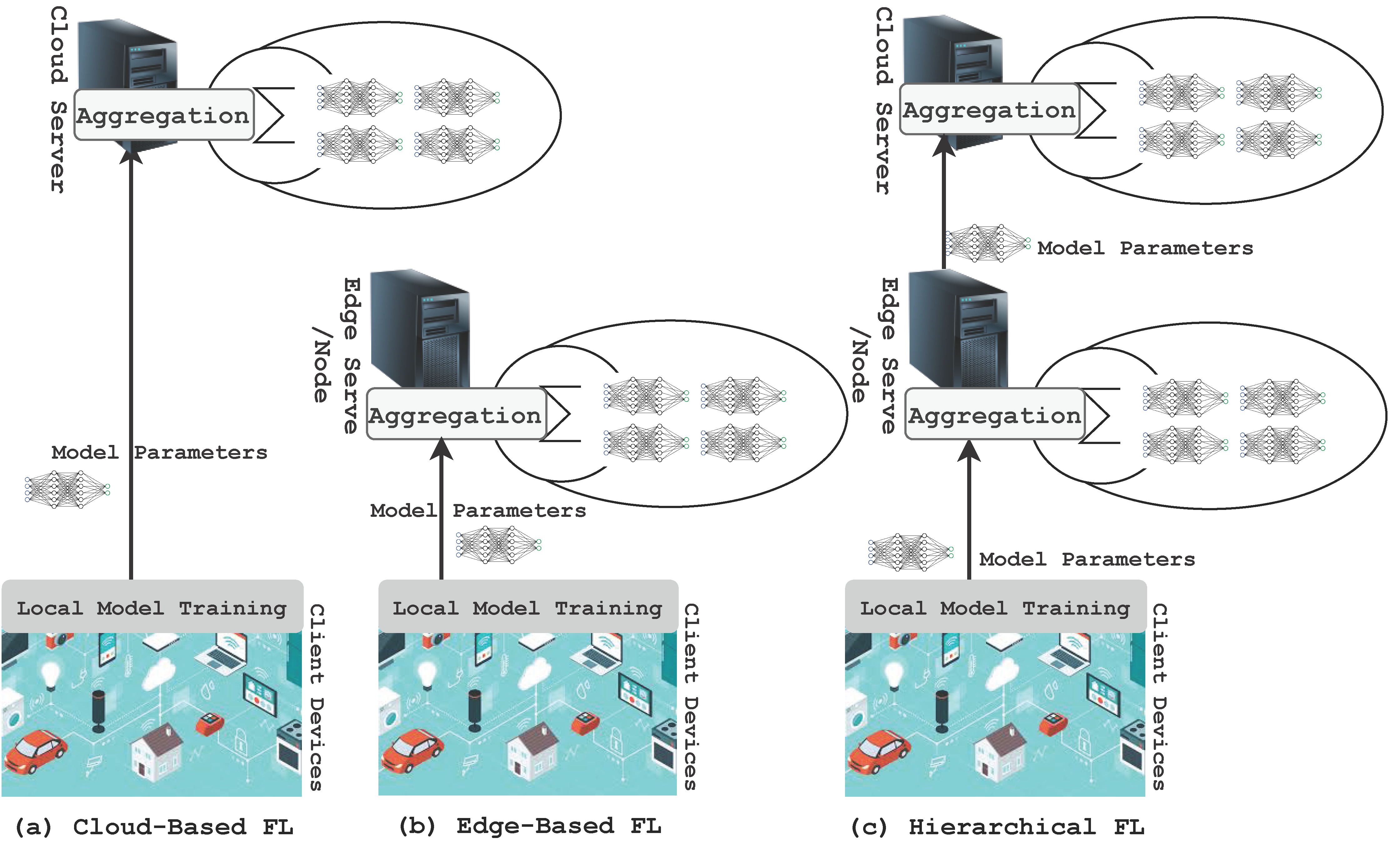
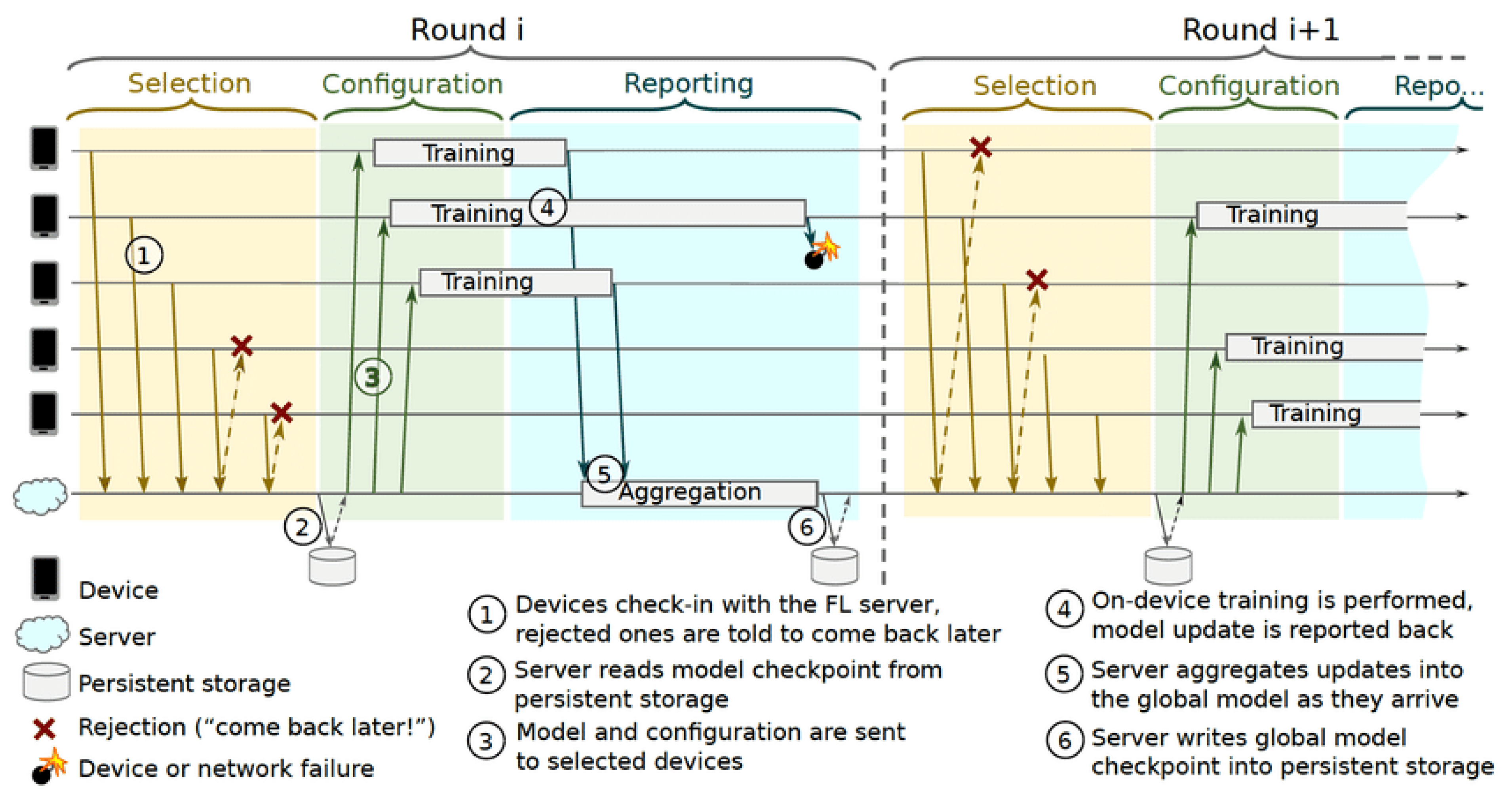
5.1. Federated Learning in Edge Computing: Protocols, Architectures, and Frameworks
- Selection: Devices that meet the eligibility criteria check in to the server on a regular basis through bidirectional communication streams. The availability of clients is kept track of through the stream: whether or not anything is alive and to organize multi-step communication. Furthermore, an FL parameter server selects a subset of active clients for participation in a training round, and they perform a specified FL task based on a defined client selection algorithm such as FedCS [20]. Subsection C discusses the client selection methods and challenges;
- Reporting: The parameter FL server waits for updates from the participating clients. As updates arrive, the server aggregates them using predefined algorithms such as FedAvg [15] and instructs the reporting devices when to reconnect. When a sufficient number of clients are connected over time, the federated training is accomplished under the control of the server, and the server’s global model will be updated; otherwise, the round will be abandoned. The model update is frequently sent to the server via encrypted communication. To eliminate objective inconsistency, the authors of [105] proposed FedNova as a normalized averaging method.
5.1.1. Architecture of Participating Device
5.1.2. Architecture of the Federated Learning Server
- Coordinators: Trains are synchronized globally and flow in lockstep by these top-level players (one for each population). Based on the number of tasks scheduled for FL, the coordinator receives information about the number of devices connected to each selector;
- Selectors: This accepts and forwards device connections. When the coordinator starts the master aggregator and a set of aggregators, the selectors are instructed to send a subset of their connected devices to the aggregators. This technique allows the coordinator to efficiently assign devices to FL tasks regardless of the number of available devices;
- Master aggregators are spawned to complete the work according to the number of devices and the update size. To balance the number of devices and the update size, they scale as needed.
5.1.3. Open-Source Federated Learning Frameworks
- TensorFlow Federated (TFF): TFF [108] is an open-source framework for decentralized ML and other computations. TFF was created to enable open research and experimentation with FL by Google. TFF’s building blocks can also be used to implement nonlearning computations such as federated analytics. TFF’s interfaces are divided into two layers: (i) FL API and (ii) Federated Core (FC) API. The FL API offers a set of high-level interfaces that allow developers to apply the included implementations of federated training and evaluation to their existing TensorFlow models. Furthermore, the FC API is a set of lower-level interfaces for expressing novel federated algorithms in a strongly typed functional programming environment by combining TensorFlow with distributed communication operators. This layer also serves as the foundation upon which FL is built;
- Federated AI Technology Enabler (FATE): The FATE [109] project was started by Webank’s [110] AI Department to provide a secure computing framework to support the federated AI ecosystem. It uses homomorphic encryption and multi-party computation to implement secure computation protocols (MPCs). It supports the FL architecture, as well as the secure computation of various ML algorithms such as logistic regression, tree-based algorithms, deep learning, and transfer learning;
- Paddle Federated Learning framework (PaddleFL): PaddleFL [111] is a PaddlePaddle-based open-source FL framework. Several FL strategies will be provided in PaddleFL, including multi-task learning [112], transfer learning [113], and active learning [114], with applications in computer vision, natural language processing, recommendations, and so on. PaddleFL developers claim that based on Paddle’s large-scale distributed training and elastic scheduling of training jobs on Kubernetes, PaddlePaddle can be easily deployed on full-stack open-sourced software;
- PySyft framework: PySyft is an MIT-licensed open-source Python project for secure and private deep learning. Furthermore, it is a PyTorch-based framework for performing encrypted, privacy-preserving DL and the implementation of related techniques such as Secure Multiparty Computation (SMPC) and Data Privacy (DP) in untrusted environments while protecting data. PySyft is designed to retain the native Torch interface, which means that the methods for performing all tensor operations remain unchanged from PyTorch. When a SyftTensor is created, a LocalTensor is created automatically to apply the input command to the native PyTorch tensor. Participants are created as virtual workers to simulate FL. As a simulation of a practical FL setting, data in the form of tensors can be split and distributed to virtual workers. The data owner and storage location are then specified using a PointerTensor. Model updates can also be retrieved from the virtual workers for global aggregation;
- Federated Learning and Differential Privacy framework (FL& DP): A simple FL and DP framework has been released under the Apache 2.0 license. FL is an open-source framework [115]. Granada’s Andalusian Research Institute for Data Science and Computational Intelligence developed the framework of Sherpa.AI. This framework uses TensorFlow Version 2.2 and the SciKit-Learn library to train linear models and clusters;
- LEAF: LEAF [116] is an FL benchmarking system that has applications in FL, multi-task learning, meta-learning, and on-device learning. It consists of three parts: (1) a collection of open-source datasets, (2) a set of statistical and system metrics, and (3) a set of reference implementations. Because of LEAF’s modular design, these three components can readily be integrated into a variety of experimental workflows [117]. The “Datasets” module preprocesses and transforms the data into a common format that can be used in any ML pipeline. The “Reference Implementations” module in LEAF is a growing repository of common federated techniques, with each implementation generating a log of various statistical and system characteristics. Through LEAF’s “Metrics” module, any log created in a proper format can be used to aggregate and analyze these metrics in a variety of ways.
5.1.4. Proprietary Federated Learning Frameworks
- IBM Federated Learning Framework: A Python framework for FL in an enterprise environment is IBM Federated Learning. IBM distributes the framework under a license that restricts its use [119]. One of the most salient features of the framework is the large number of ML algorithms it contains. Besides NN, linear classification, and decision trees (ID3 algorithm), it also supports K-means, naive Bayes, and reinforcement learning algorithms. IBM FL integrates libraries such as Keras, PyTorch, TensorFlow, SciKit-learn, and RLlib;
- NVIDIA Federated Learning Framework [120]: It is not possible to open source the entire framework of the NVIDIA Clara Train SDK because of the restrictive license under which it has been released. For NVIDIA Clara Train SDK, FL requires CUDA 6.0 or later. It supports TensorFlow [121], TResNet [122], and AutoML, making the development of models easy and intuitive. To track the progress of model training, the software uses a centralized workflow between the server and the clients. The original model is then sent to each client.
5.2. Hardware Requirements for Implementing Federated Learning in an Edge Computing Environment
- GPU-based accelerators: A GPU is an efficient computing tool because it is able to perform highly efficient matrix-based operations coupled with a variety of hardware choices [123]. The GPU accelerator, on the other hand, uses much power, making it difficult to use on cloud servers or battery-powered devices. In addition to its GPU-based architecture, the NVIDIA Tensor Core architecture runs large amounts of computations in parallel to increase throughput and efficiency. NVIDIA DGX1 and DGX2 [124] are two popular GPU-based accelerators that offer accelerated deep learning performance. There are also Intel Nervana Neural Network Processors [122], two different GPU accelerators that can be used for deep learning training (NNP-L 1000) and the deep learning inference (NNP-I 1000). Mobile phones, wearable devices, and surveillance cameras enable rapid deployment of DL applications, making them even more valuable near the venue. There are ways to perform DL computation on edge devices without moving them to the cloud, but they have limited computing power, storage, and power consumption. Several academics are developing a GPU accelerator for edge computing to solve the bottlenecks. Reference [125], for example, described ARM Cortex-M microcontrollers and developed CMSIS-NN, a set of efficient NN kernels. CMSIS-NN reduces the memory footprint of NNs on ARM Cortex-M processor cores, allowing the DL model to be implemented in IoT devices while maintaining standard performance and energy efficiency;
- FPGAs-based accelerator: Although GPU solutions are frequently used in cloud computing for DL modeling, training, and inference, similar solutions may not be available at the edge due to power and cost constraints. Furthermore, edge nodes should be able to handle numerous DL compute requests at once, making the use of lightweight CPUs and GPUs impracticable. As a result, edge hardware based on FPGAs is being investigated for edge DL. As a tradeoff for low speed, FPGAs are more energy efficient than GPUs when computing machine-learning algorithms. FPGAs are increasingly vying with GPUs for the implementation of AI solutions as the market evolves. It is estimated that FPGAs are 10-times more power efficient than GPUs, according to Microsoft Research’s Catapult Project [126]. In terms of FPGA-based accelerators, Microsoft’s Project Brainwave is outstanding. It is a high-performing distributed system with soft DNN engines rendered with Intel’s Stratix FPGAs that use real-time, low-latency artificial intelligence [127]. However, it requires a significant amount of storage, external memory and bandwidth, and computational resources on the order of billions of operations per second. Therefore, as FL demands a sufficient storage size for local datasets, further research is required for FL implementation requirements in FPGA-enabled edge devices;
- ASIC-based accelerator: FPGAs have higher DL inefficiency and require more complex programmable logic, while ASIC architectures for DL have higher power efficiency, but lower reconfigurability. Either way, ASICs are more suitable for DL applications due to their high DL efficiency and programmability. ASICs still provide a much higher overall efficiency than FPGAs for simple algorithms even though FPGAs can reduce the power consumption in computing by optimizing ML algorithms to the hardware design. ASICs introduce complex logic, while FPGAs introduce programmability, increasing the hardware design costs. Moreover, FPGAs have a limited frequency of 300 MHz, four- to five-times less than typical ASICs [123]. Furthermore, due to their reduced network overhead and off-chip memory access characteristics, ASICs are increasingly being used in EC by academia and industry. They also support DL training with a low power and processing time [128]. EdgeTPU [129] is a Google-developed open, end-to-end infrastructure for implementing AI solutions that is a prime example of an ASIC-based accelerator installed in an EC. ASIC-based accelerators are hence promising hardware components for implementing FL in EC devices. Although it has already been tried for several DL applications in EC, such as object identification and recognition [130] and emotion recognition [131], more research is needed to understand the impact of ASIC-based accelerators for FL implementation in EC. However, ASIC-based accelerators have a long development cycle and are not flexible to cope with varying DL network designs.
5.3. Federated Learning Applications in an Edge Computing Environment
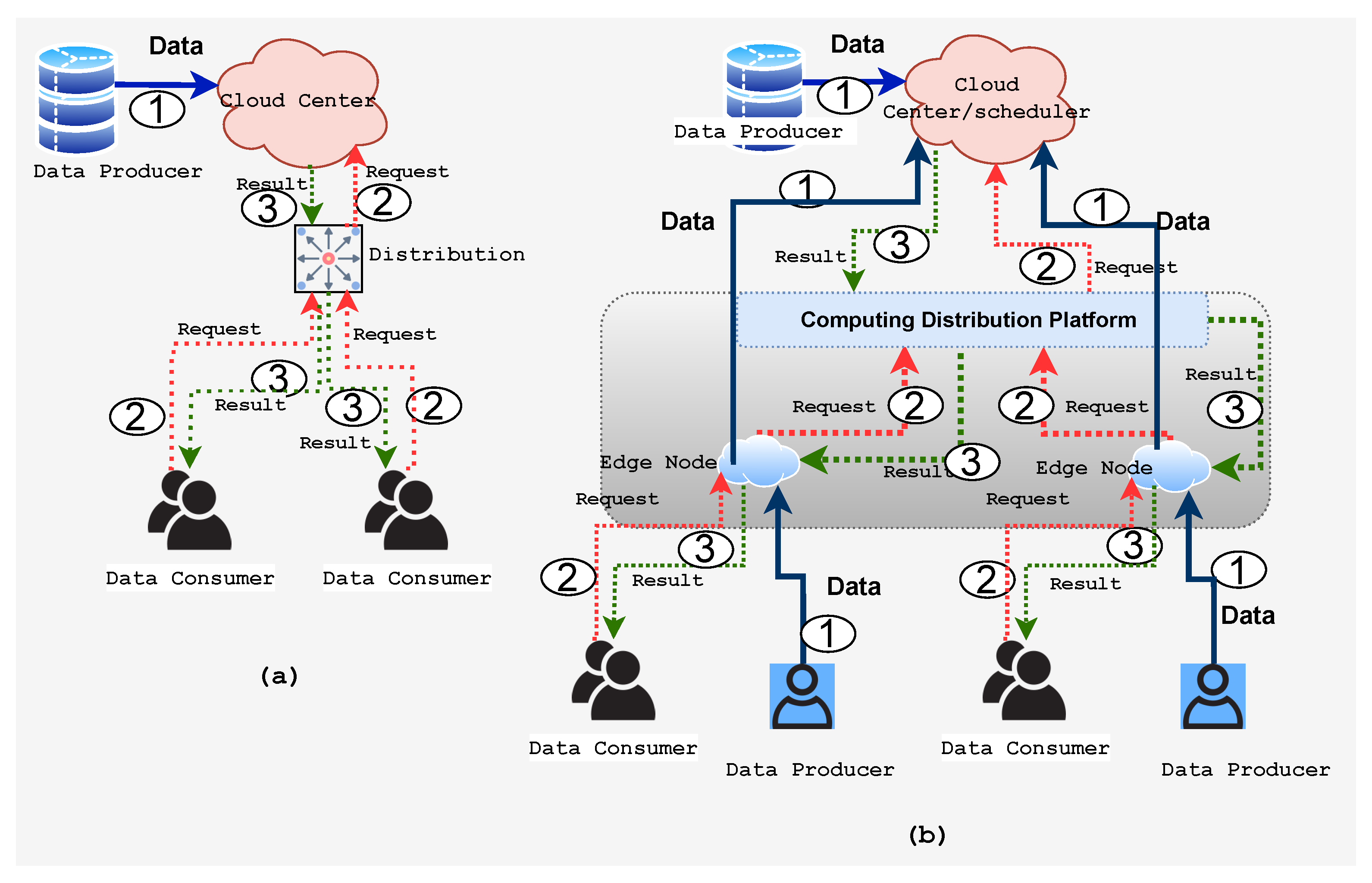
5.3.1. Computation Offloading and Content Caching
- In the case of EC implementations that involve massive clients, Big Data training is uploaded to a central cloud server for model training through an uplink channel (i.e., wireless link). This introduces additional burdens and congestion on the uplink channel;
- The uploaded training dataset to the server may be sensitive to privacy, such as patient history data, which results in potential privacy violations;
- Consider that we need to train the DL model at the end device such as mobile phones, tablets, wearable things, and implanted sensors to prevent privacy. However, the model training demands intensive computational capacity and energy to find the optimal solution as in the SGD convergence algorithm. It uses a large amount of data factors and parameters over a large scale. Thus, DL training at the resource-constrained edge introduces extra energy consumption and long processing times;
- The conventional centralized training of a DL model fails to handle non-IID and unbalanced data distributions. However, the data distribution in the EC environment depends on several conditions such as the location and amount of data. In addition, the performance of DL usually deteriorates with weak consideration of both data and network state heterogeneity.
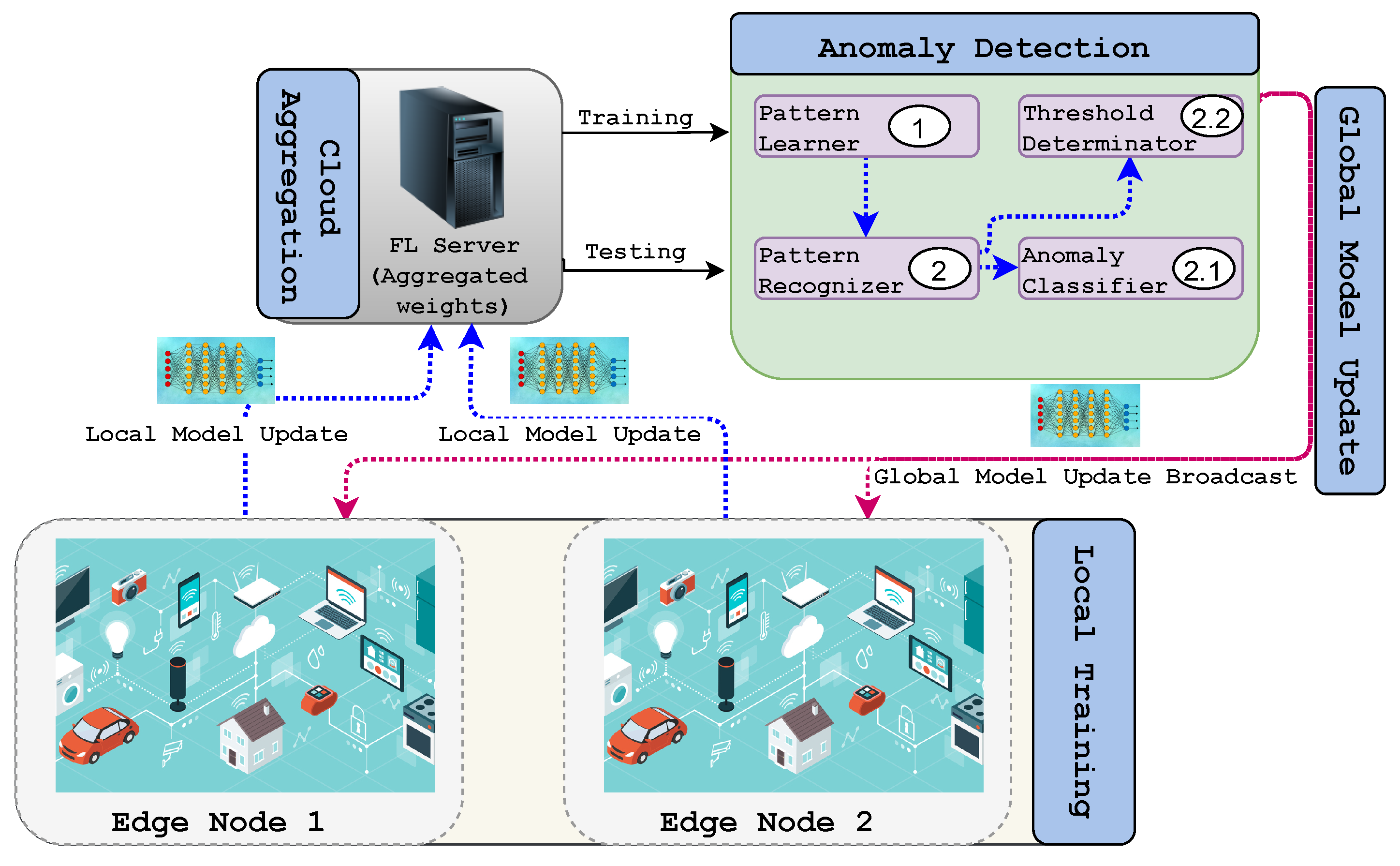
5.3.2. Malware and Anomaly Detection
5.3.3. Task Scheduling and Resource Allocation
5.4. Implementing Federated Learning in an Edge Computing Environment: Challenges and Solutions
5.4.1. Communication and Computation Efficiency
5.4.2. Heterogeneity Management
5.4.3. Privacy and Security Preservation
- Security: Since FL has numerous clients for collaborative training and exposure to model parameters, it is vulnerable to various attacks and risks. Therefore, we can analyze the security challenges by identifying the threats/attacks and the corresponding defense/solutions:
- (a)
- Attacks: Generally, two main classifications of attacks are identified to manipulate the collaborative learning process in the edge FL: Byzantine and poisoning attacks. Byzantine attack is the attack performed by a fully trusted node that has turned rogue and already has passed all authentication and verification processes, for example when selected participants turn into rogues in the FL learning process. If some nodes are compromised, attacked, or fail, the entire FL system fails [192,193].A poisoning attack is similar to an injection attack in the FL training process. The two types of poisoning attacks are data poisoning and model poisoning. By targeting ML algorithms’ vulnerability and introducing malicious data during training, data poisoning attacks aim to maximize the classification error [194]. Through FL, the client interacts with the server; the client sends the training data and parameters, but the client can also manipulate the training to poison the model. Data poisoning in FL refers to sending false model parameters using dirty samples to train the global model. Malicious clients can also inject malicious data into a local model’s processing in a method known as data injection. Because of this, a malicious agent is able to manipulate the local models of multiple clients and influence the global model. Malicious agents use fake data in data poisoning, but they target global models directly in model poisoning. Research has shown that data poisoning attacks are less effective than model poisoning attacks [194]. When multiple clients use a large-scale FL product, there is a greater likelihood of model poisoning happening. It is generally possible to poison the global model by modifying the updated model and then sending it to the central server for aggregation;
- (b)
- Defense: A client may intentionally or unintentionally deviate from the prescribed course of FL training, resulting in abnormal behaviors. Timely detection and aversion of these abnormal client’s behavior is therefore critical to minimize their negative impact [195]. Many solutions have been proposed, mainly related to the safe FL training process. The authors of [196] proposed a detection method for Byzantine attackers using a pre-trained anomaly detection model, a pre-trained autoencoder model running at the server level to detect anomalous model weight updates and identify their originators. Based on their results, they found that detection-based approaches outperform conventional defense-based methods significantly. However, Byzantine-tolerant aggregation methods are inefficient due to the non-identically and independently distributed training data. Moreover, Wei Wan et al. [197] proposed a density-based detection technique to protect against high-rate attacks by modeling the problem as anomaly detection to effectively detect anomalous updates. Due to this, the global model became less adversarial. However, this approach is computationally intensive even though it improves the accuracy of the global model, which will be affected by the convergence of the aggregated model. In fact, model poisoning attacks with limited training data can be highly successful, as demonstrated by [198]. In order to prevent such attacks, several recommendations were proposed. When a participant shares a new version of the global model, the server evaluates whether the updated version can improve the global model. By default, the server marks the participant as a potential attacker, and after viewing updated models for a few rounds, it can decide whether or not the participant is malicious. The second solution allows participants to compare their updated models. Malicious participants can update models that are too different from those around them. Until it can determine whether or not this participant is malicious, the server will observe updates from this participant. Although impossible to prevent, model poisoning attacks can occur because it is impossible to assess the progress of each and every participant when training with millions of participants. Therefore, more effective solutions are needed.Furthermore, the authors of [199] described the use of a learning-rate-adjustment system against Sybil-based poisoning attacks that uses the similarity of gradient updates to regulate learning rates. A system using FoolsGold can withstand the Sybil data poisoning attack with minimal modifications to the conventional FL process and without using any auxiliary information. In other words, using a variety of participant distributions, poisoning targets, and attack strategies, the authors showed that FoolsGold mitigates such attacks. However, they did not propose any convergence-proof defense methods. Further, the authors of [200] presented a method of detecting and eliminating malicious model updates based on spectral anomaly detection techniques exploiting its low dimensions. Both Byzantine and targeted model poisoning attacks include the detection and removal of spectra anomalies occurring on the server side. The central server can detect and remove malicious updates using a powerful detection model, providing targeted defenses. Convergence and computational complexity, however, will need to be analyzed;
- Privacy: Although FL improves the privacy of participating clients, there may still be a breach of privacy when data are exchanged among servers. During the training process, orchestrating FL servers may extract personal data [80,201]. Privacy threats in FL generally fall into three categories: attacks by affiliation inference, inadvertent data leakage and reconstruction inference, and GANs-based inference attacks. An affiliation inference attack searches for private data in the training dataset, abusing the global model. In such cases, the information about the training dataset is derived by guessing and training the predictive model to predict the original training data. Furthermore, inadvertent data leakage and reconstruction inference is a method to extract information from the FL server by sending model updates from participating edge devices. Since GAN can effectively learn the distribution of training data, GAN-based attacks aim to reconstruct, for example, human-distinguishable images from the victim’s personal dataset [80].Differential Privacy (DP) and secure aggregation approaches are the two most common methods to mitigate privacy issues in FL [104]. Differential Privacy (DP) is a mathematical concept often used in statistical machine learning to overcome personal information leakage during data collection and processing. Thus, numerous works of literature proposed DP as the main privacy-preserving algorithm in FL implementation. The authors of [202] analyzed FL using the DP approach and designed a client selection method to improve privacy for subscribers. Yao Fu et al. [203] analyzed the practicality of DP in FL by tuning the number of iterations performed to optimize model accuracy. Secure model aggregation is a privacy-preserving algorithm that ensures that multiple clients participate in global model training while protecting their data shared with others. Therefore, secure model aggregation is a critical component of FL model training. It can be implemented in different approaches such as homomorphic Encryption [204], secure multiparty computation [205], and blockchain [206]. Recent research has been conducted on blockchain-enabled FL in edge networks. The authors of [207] proposed a data-protecting blockchain-based FL for IoT devices. As DP algorithms are lightweight compared to secure aggregation algorithms, they can be deployed easily in edge computing environments with limited resources. DP algorithms are generally used for less sensitive queries, making them vulnerable to privacy leaks, especially when adaptive queries are needed in applications or services. Although more computationally and storage intensive, secure aggregation algorithms are more secure than DP-based aggregation.
5.4.4. Client Selection and Resource Allocation
5.4.5. Service Pricing
6. Federated Learning in Edge Computing: Case Studies
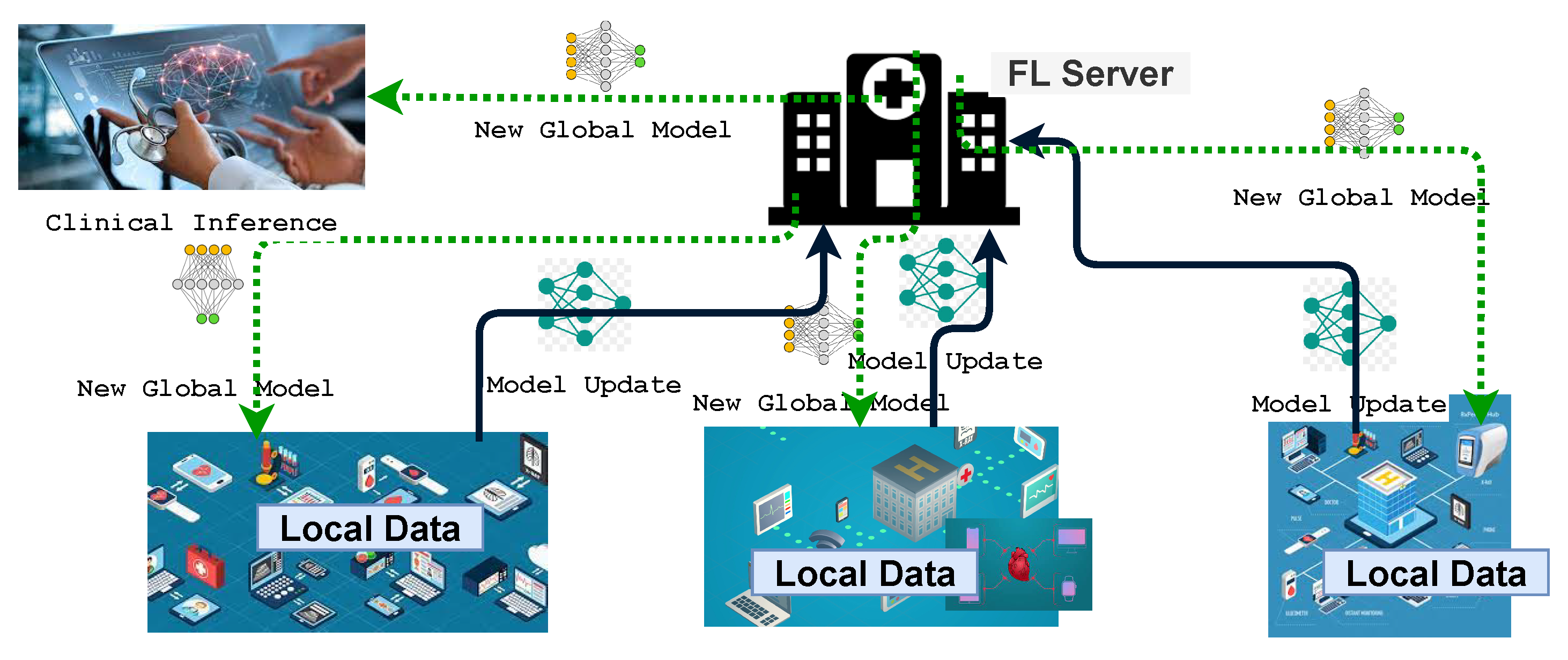
6.1. Smart Healthcare
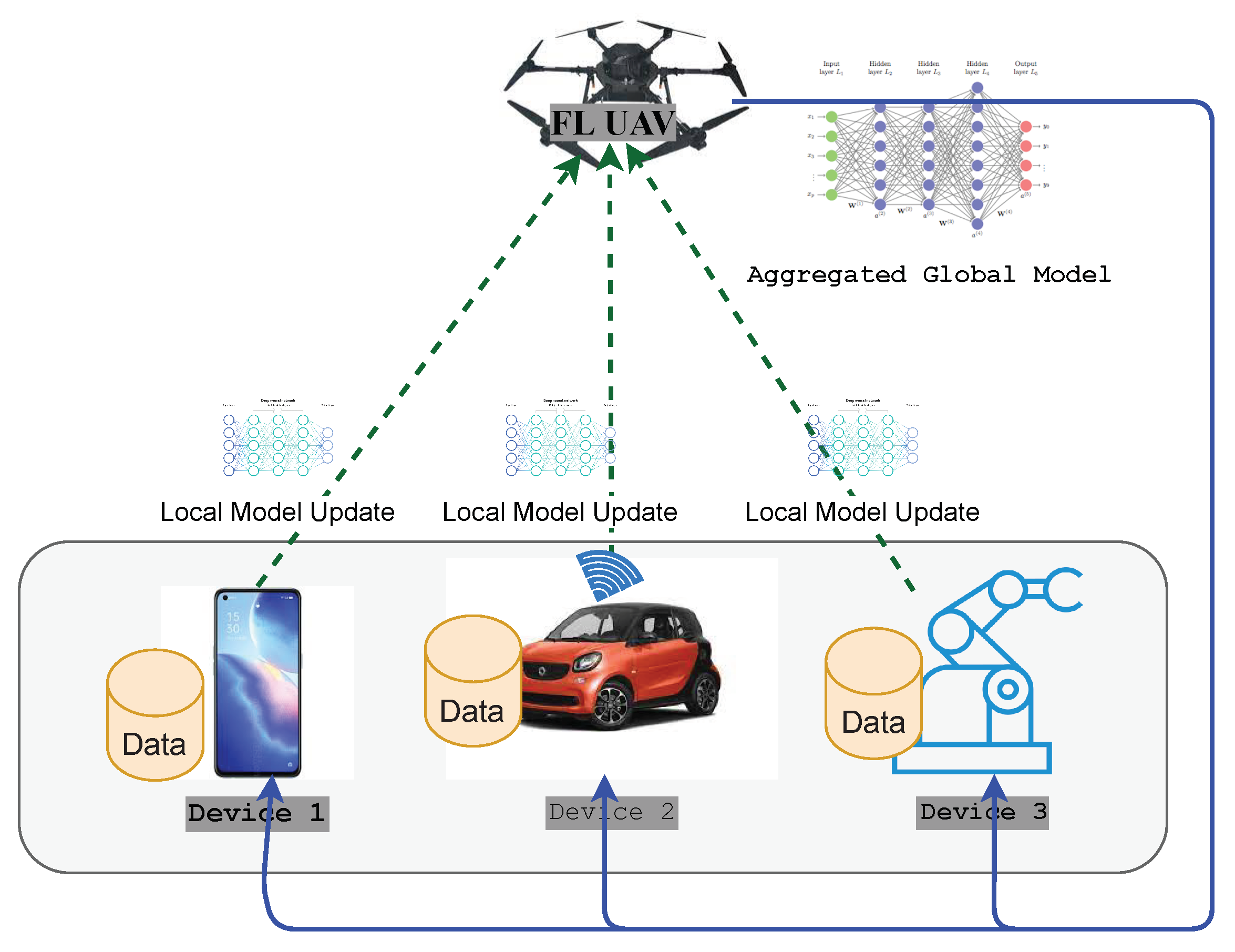
6.2. Unmanned Aerial Vehicles
7. Open Issues and Future Research Directions
- Multi-model support federated learning training process: In the FL training process, it is assumed that the participating clients update their corresponding model parameters according to a global model. However, clients may wish to train multiple models, even during their idle time. Therefore, decoupling global model aggregation from local training allows clients to use different learning algorithms. For instance, it may be necessary to develop multiple and various models using a federated approach for different purposes. How should the federated learning architecture look? What is the best way to manage this problem? Therefore, appropriate techniques need to be analyzed and implemented;
- Impact of wireless channel: Edge devices are often connected to edge or cloud servers over unreliable wireless channels. Moreover, we believe that channel characteristics affect the model accuracy. Therefore, studying the impact of the network requirements, especially wireless communication, on the accuracy of federated model training is considered a future research trend. Noise, path loss, shadowing, and fading are all impairments that should be considered in wireless communication systems. In the federated learning process, the communication between clients and parameter servers usually occurs over an impaired wireless channel. This raises some research questions, for example: How does channel fading affect learning? How can it be mitigated?
- Joint dynamic client selection and adaptive model aggregation: We described the effects of client selection and model aggregation algorithms on resource allocation independently. However, adaptive model aggregation and dynamic client selection for resource allocation considering the non-IID behavior of data, computational power, the data size, network capacity, and link reliability are among the future research works. Therefore, joint dynamic client selection and adaptive model aggregation should be investigated as future research trends. Consider, for instance, the algorithms and their complexities that are suitable for dynamically varying client requests and volatile resources on both the client-side and server-side. In such scenarios, how can we manage the federated learning training process?
- Adaptive privacy-preserving security solution: We already described the tradeoff between privacy-preserving techniques and communication/computational efficiency. It is critical to develop solutions that protect privacy while supporting a heterogeneity of client devices in terms of hardware and software. Therefore, an adaptive privacy-preserving security solution is a possible research direction;
- SDN/NFV-enabled federated learning implementation: Software-Defined Networking (SDN) and Network Function Virtualization (NFV) have captured people’s attention and are increasingly redefining the way networks are built and managed for a modern, connected, always-on world. We also believe that SDN/NFV would be a possible research topic;
- Service pricing in edge federated learning: As we described earlier, service pricing in federated learning in edge computing determines how clients interact economically with the cloud/edge server. However, service pricing in federated learning at the edge has not yet been analyzed and implemented and requires further research;
- New federated learning approach: The size of the federated learning model is too large to fit on a resource-constrained edge device. Moreover, the training of the federated learning model is too slow to converge and meet the delay requirements in certain delay-sensitive applications. A new federated learning approach is required to achieve the goals dynamically. Therefore, dynamic and adaptive federated learning must be analyzed and implemented for resource-constrained edge devices.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FL | Federated Learning |
| FCN | Fully Connected Neural Network |
| ML | Machine Learning |
| CNN | Convectional Neural Network |
| DNN | Deep Neural Network |
| EC | Edge Computing |
| DRL | Deep Reinforcement Learning |
| DP | Differential Privacy |
| LSTM | Long Short-Term Memory |
| DL | Deep Learning |
| FedAvg | Federated Averaging |
| QoS | Quality of Service |
| QoE | Quality of Experience |
| FedProx | Federated Proximal |
| KPI | Key Performance Indicator |
| IoT | Internet of Things |
| IoV | Internet of Vehicles |
| FedMA | Federated Matched Averaging |
| IIoT | Industrial Internet of Things |
| FedSGD | Federated Stochastic Gradient Descent |
| FDL | Federated Deep Learning |
| IID | Distributed Independent and Identically |
| UAV | Unmanned Areal Vehicle |
| GDPR | General Data Protection Regulation |
| CCPA | California Consumer Privacy Act |
| PDPA | Personal Data Protection Act |
| SLR | Systematic Literature Review |
References
- The Future of IoT Miniguide: The Burgeoning IoT Market Continues. Available online: https://www.cisco.com/c/en/us/solutions/internet-of-things/future-of-iot.html (accessed on 20 April 2020).
- Basir, R.; Qaisar, S.; Ali, M.; Aldwairi, M.; Ashraf, M.I.; Mahmood, A.; Gidlund, M. Fog Computing Enabling Industrial Internet of Things: State-of-the-Art and Research Challenges. Sensors 2019, 19, 4807. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pryss, R.; Reichert, M.; Herrmann, J.; Langguth, B.; Schlee, W. Mobile Crowd Sensing in Clinical and Psychological Trials—A Case Study. In Proceedings of the 2015 IEEE 28th International Symposium on Computer-Based Medical Systems, Sao Carlos, Brazil, 22–25 June 2015; pp. 23–24. [Google Scholar]
- Liu, L.; Chen, C.; Pei, Q.; Maharjan, S.; Zhang, Y. Vehicular Edge Computing and Networking: A Survey. Mob. Netw. Appl. 2021, 26, 1145–1168. [Google Scholar] [CrossRef]
- Haftay Gebreslasie, A.; Bernardos, C.J.; De La Oliva, A.; Cominardi, L.; Azcorra, A. Monitoring in fog computing: State-of-the-art and research challenges. Int. J. Ad Hoc Ubiquitous Comput. 2021, 36, 114–130. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef] [Green Version]
- Yann, L.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar]
- Corcoran, P.; Datta, S.K. Mobile-Edge Computing and the Internet of Things for Consumers: Extending cloud computing and services to the edge of the network. IEEE Consum. Electron. Mag. 2016, 5, 73–74. [Google Scholar] [CrossRef]
- Chiang, M.; Zhang, T. Fog and IoT: An Overview of Research Opportunities. IEEE Int. Things J. 2016, 3, 854–864. [Google Scholar] [CrossRef]
- Paul Voigt, A.V.D.B. The EU General Data Protection Regulation (GDPR), A Practical Guide; Springer International Publishing AG: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- California Consumer Privacy Act Home Page. Available online: https://oag.ca.gov/privacy/ccpa (accessed on 20 April 2021).
- Personal Data Protection Act 2012. Available online: https://sso.agc.gov.sg/Act/PDPA2012 (accessed on 20 April 2021).
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Roselander, J. Towards Federated Learning at scale: System design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Aguera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. PMLR 2017, 54, 1273–1282. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Int. Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Hou, X.; Lu, Y.; Dey, S. Wireless VR/AR with Edge/Cloud Computing. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–8. [Google Scholar]
- Hussain, R.; Zeadally, S. Autonomous Cars: Research Results, Issues, and Future Challenges. IEEE Commun. Surv. Tutor. 2019, 21, 1275–1313. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef] [Green Version]
- Aazam, M.; Huh, E.-N. Fog Computing Micro Datacenter Based Dynamic Resource Estimation and Pricing Model for IoT. In Proceedings of the 2015 IEEE 29th International Conference on Advanced Information Networking and Applications, Gwangju, Korea, 24–27 March 2015; pp. 687–694. [Google Scholar]
- Satyanarayanan, M.; Bahl, P.; Caceres, R.; Davies, N. The case for vm-based Cloudlets in mobile computing. IEEE Pervasive Comput. 2009, 8, 14–23. [Google Scholar] [CrossRef]
- Hu, W.; Gao, Y.; Ha, K.; Wang, J.; Amos, B.; Chen, Z.; Pillai, P.; Satyanarayanan, M. Quantifying the Impact of Edge Computing on Mobile Applications. In Proceedings of the 7th ACM SIGOPS Asia-Pacific Workshop on Systems, Hong Kong, China, 4–5 August 2016; pp. 1–8. [Google Scholar]
- Multi-access Edge Computing (MEC). Available online: https://www.etsi.org/technologies/multi-access-Edge-computing (accessed on 30 April 2021).
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 17 August 2012; pp. 13–16. [Google Scholar]
- Bonomi, F.; Milito, R.; Natarajan, P.; Zhu, J. Fog computing: A platform for internet of things and analytics. In Big Data and Internet of Things: A Roadmap for Smart Environments; Springer: Cham, Switzerland, 2014; pp. 169–186. [Google Scholar]
- Bilal, K.; Khalid, O.; Erbad, A.; Khan, S.U. Potentials, trends, and prospects in edge technologies: Fog, cloudlet, mobile edge, and micro data centers. Comput. Netw. 2018, 130, 94–120. [Google Scholar] [CrossRef] [Green Version]
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Mudassar, B.A.; Ko, J.H.; Mukhopadhyay, S. Edge-Cloud Collaborative Processing for Intelligent Internet of Things: A Case Study on Smart Surveillance. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar]
- Alibabacloud Homepage. Available online: https://www.alibabaCloud.com/blog/extending-the-boundaries-of-the-Cloud-with-Edge-computing_594214 (accessed on 27 August 2021).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS, Lake Tahoe, CA, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the 31st International Conference on Machine Learning. PMLR 2014, 32, 647–655. [Google Scholar]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Brief. Bioinform. 2018, 19, 1236–1246. [Google Scholar] [CrossRef] [PubMed]
- Justesen, N.; Bontrager, P.; Togelius, J.; Risi, S. Deep Learning for Video Game Playing. IEEE Trans. Games 2020, 12, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Kisacanin, B. Deep Learning for Autonomous Vehicles. In Proceedings of the 2017 IEEE 47th International Symposium on Multiple-Valued Logic (ISMVL), Novi Sad, Serbia, 22–24 May 2017; p. 142. [Google Scholar]
- Qing, R.; Frtunikj, J. Deep learning for self-driving cars: Chances and challenges. In Proceedings of the 1st International Workshop on Software Engineering for AI in Autonomous Systems, Gothenburg, Sweden, 28 May 2018; pp. 35–38. [Google Scholar]
- Li, D.; Liu, Y. Deep Learning in Natural Language Processing; Apress: New York, NU, USA, 2018. [Google Scholar]
- Sorin, V.; Barash, Y.; Konen, E.; Klang, E. Deep Learning for Natural Language Processing in Radiology—Fundamentals and a Systematic Review. J. Am. Coll. Radiol. 2020, 17, 639–648. [Google Scholar] [CrossRef]
- Kumar, S.K. On weight initialization in deep neural networks. arXiv 2017, arXiv:1704.08863. [Google Scholar]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Ian, G.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 18–22 June 1989; Volume 1, pp. 593–605. [Google Scholar]
- Geoffrey, H.; Srivastava, N.; Swersky, K. Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited 2012, 14, 2. [Google Scholar]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.-C.; Yang, Q.; Niyato, D.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Baur, C.; Albarqouni, S.; Navab, N. Semi-supervised Deep Learning for Fully Convolutional Networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2017; pp. 311–319. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Mokhtari, A.; Hassani, H.; Jadbabaie, A.; Pedarsani, R. Fedpaq: A communication-efficient federated learning method with periodic averaging and quantization. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics. PMLR 2020, 108, 2021–2031. [Google Scholar]
- Ericsson Homepage. Available online: https://www.ericsson.com/en/reports-and-papers/ericsson-technology-review/articles/critical-iot-connectivity (accessed on 27 August 2021).
- Ang, F.; Chen, L.; Zhao, N.; Chen, Y.; Wang, W.; Yu, F.R. Robust Federated Learning with Noisy Communication. IEEE Trans. Commun. 2020, 68, 3452–3464. [Google Scholar] [CrossRef] [Green Version]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl. Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.-C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef] [Green Version]
- Al-Ansi, A.; Al-Ansi, A.; Muthanna, A.; Elgendy, I.; Koucheryavy, A. Survey on Intelligence Edge Computing in 6G: Characteristics, Challenges, Potential Use Cases, and Market Drivers. Future Int. 2021, 13, 118. [Google Scholar] [CrossRef]
- Cui, L.; Yang, S.; Chen, F.; Ming, Z.; Lu, N.; Qin, J. A survey on application of machine learning for Internet of Things. Int. J. Mach. Learn. Cybern. 2018, 9, 1399–1417. [Google Scholar] [CrossRef]
- Shakarami, A.; Ghobaei-Arani, M.; Shahidinejad, A. A survey on the computation offloading approaches in mobile edge computing: A machine learning-based perspective. Comput. Netw. 2020, 182, 107496. [Google Scholar] [CrossRef]
- Kumar, K.; Liu, J.; Lu, Y.-H.; Bhargava, B. A Survey of Computation Offloading for Mobile Systems. Mob. Netw. Appl. 2013, 18, 129–140. [Google Scholar] [CrossRef]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A Survey. IEEE Int. Things J. 2018, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.; Zeadally, S.; Chen, Z.; Labiod, H.; Wang, L. A survey on computation offloading modeling for edge computing. J. Netw. Comput. Appl. 2020, 169, 102781. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Zhang, Y.; Wang, L.; Yang, J.; Wang, W. A Survey on Mobile Edge Networks: Convergence of Computing, Caching and Communications. IEEE Access 2017, 5, 6757–6779. [Google Scholar] [CrossRef]
- Yao, J.; Han, T.; Ansari, N. On mobile edge caching. IEEE Commun. Surv. Tutor. 2019, 21, 2525–2553. [Google Scholar] [CrossRef]
- Filali, A.; Abouaomar, A.; Cherkaoui, S.; Kobbane, A.; Guizani, M. Multi-Access Edge Computing: A Survey. IEEE Access 2020, 8, 197017–197046. [Google Scholar] [CrossRef]
- Salmeron, J.L.; Arévalo, I. A Privacy-Preserving, Distributed and Cooperative FCM-Based Learning Approach for Cancer Research. In Proceedings of the Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; pp. 477–487. [Google Scholar]
- Feki, I.; Ammar, S.; Kessentini, Y.; Muhammad, K. Federated learning for COVID-19 screening from Chest X-ray images. Appl. Soft Comput. 2021, 106, 107330. [Google Scholar] [CrossRef] [PubMed]
- Yan, B.; Wang, J.; Cheng, J.; Zhou, Y.; Zhang, Y.; Yang, Y.; Liu, L.; Zhao, H.; Wang, C.; Liu, B. Experiments of Federated Learning for COVID-19 Chest X-ray Images. In International Conference on Artificial Intelligence and Security; Springer: Cham, Switzerland, 2021; pp. 41–53. [Google Scholar]
- Ning, Z.; Zhang, K.; Wang, X.; Guo, L.; Hu, X.; Huang, J.; Kwok, R.Y. Intelligent edge computing in internet of vehicles: A joint computation offloading and caching solution. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2212–2225. [Google Scholar] [CrossRef]
- Ndikumana, A.; Tran, N.H.; Kim, D.H.; Kim, K.T.; Hong, C.S. Deep Learning Based Caching for Self-Driving Cars in Multi-Access Edge Computing. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2862–2877. [Google Scholar] [CrossRef]
- Liu, J.; Wang, S.; Wang, J.; Liu, C.; Yan, Y. A Task Oriented Computation Offloading Algorithm for Intelligent Vehicle Network with Mobile Edge Computing. IEEE Access 2019, 7, 180491–180502. [Google Scholar] [CrossRef]
- Zhang, K.; Cao, J.; Liu, H.; Maharjan, S.; Zhang, Y. Deep Reinforcement Learning for Social-Aware Edge Computing and Caching in Urban Informatics. IEEE Trans. Ind. Inform. 2019, 16, 5467–5477. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.-Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. IEEE Trans. Knowl. Data Eng. 2021, 1. [Google Scholar] [CrossRef]
- Mammen, P.M. Federated Learning: Opportunities and Challenges. arXiv 2021, arXiv:2101.05428. [Google Scholar]
- Liu, J.; Huang, J.; Zhou, Y.; Li, X.; Ji, S.; Xiong, H.; Dou, D. From Distributed Machine Learning to Federated Learning: A Survey. arXiv 2021, arXiv:2104.14362. [Google Scholar]
- Jiang, J.C.; Kantarci, B.; Oktug, S.; Soyata, T. Federated Learning in Smart City Sensing: Challenges and Opportunities. Sensors 2020, 20, 6230. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Yang, Q. Threats to federated learning: A survey. arXiv 2020, arXiv:2003.02133. [Google Scholar]
- Enthoven, D.; Al-Ars, Z. An Overview of Federated Deep Learning Privacy Attacks and Defensive Strategies. Stud. Comput. Intell. 2021, 965, 173–196. [Google Scholar]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- Lo, S.K.; Lu, Q.; Wang, C.; Paik, H.Y.; Zhu, L. A systematic literature review on federated machine learning: From a software engineering perspective. ACM Comput. Surv. 2021, 54, 1–39. [Google Scholar] [CrossRef]
- Niknam, S.; Dhillon, H.S.; Reed, J.H. Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges. IEEE Commun. Mag. 2020, 58, 46–51. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, X.; Xiong, Z.; Kang, J.; Wang, X.; Niyato, D. Federated learning for 6G communications: Challenges, methods, and future directions. China Commun. 2020, 17, 105–118. [Google Scholar] [CrossRef]
- Khan, L.U.; Saad, W.; Han, Z.; Hossain, E.; Hong, C.S. Federated Learning for Internet of Things: Recent Advances, Taxonomy, and Open Challenges. IEEE Commun. Surv. Tutor. 2021, 23, 1759–1799. [Google Scholar] [CrossRef]
- Pham, Q.V.; Dev, K.; Maddikunta, P.K.R.; Gadekallu, T.R.; Huynh-The, T. Fusion of Federated Learning and Industrial Internet of Things: A Survey. arXiv 2021, arXiv:2101.00798. [Google Scholar]
- Yang, Z.; Chen, M.; Wong, K.-K.; Poor, H.V.; Cui, S. Federated Learning for 6G: Applications, Challenges, and Opportunities. arXiv 2021, arXiv:2101.01338. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated Learning for Internet of Things: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Brik, B.; Ksentini, A.; Bouaziz, M. Federated Learning for UAVs-Enabled Wireless Networks: Use Cases, Challenges, and Open Problems. IEEE Access 2020, 8, 53841–53849. [Google Scholar] [CrossRef]
- Zhao, Z.; Feng, C.; Yang, H.H.; Luo, X. Federated-Learning-Enabled Intelligent Fog Radio Access Networks: Fundamental Theory, Key Techniques, and Future Trends. IEEE Wirel. Commun. 2020, 27, 22–28. [Google Scholar] [CrossRef]
- Du, Z.; Wu, C.; Yoshinaga, T.; Yau, K.-L.A.; Ji, Y.; Li, J. Federated Learning for Vehicular Internet of Things: Recent Advances and Open Issues. IEEE Open J. Comput. Soc. 2020, 1, 45–61. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletarì, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 1–7. [Google Scholar] [CrossRef]
- Xianjia, Y.; Queralta, J.P.; Heikkonen, J.; Westerlund, T. An Overview of Federated Learning at the Edge and Distributed LEdger Technologies for Robotic and Autonomous Systems. arXiv 2021, arXiv:2104.10141. [Google Scholar]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated Learning for Healthcare Informatics. J. Health Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef]
- Wahab, O.A.; Mourad, A.; Otrok, H.; Taleb, T. Federated Machine Learning: Survey, Multi-Level Classification, Desirable Criteria and Future Directions in Communication and Networking Systems. IEEE Commun. Surv. Tutor. 2021, 23, 1342–1397. [Google Scholar] [CrossRef]
- Denyer, D.; Tranfield, D. Producing a Systematic Review. In The Sage Handbook of Organizational Research Methods; Buchanan, D., Bryman, A., Eds.; Sage: London, UK, 2009; pp. 671–687. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical Secure Aggregation for Privacy-Preserving Machine Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1175–1191. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Gauri, J.; Poor, H.V. A Novel Framework for the Analysis and Design of Heterogeneous Federated Learning. IEEE Trans. Signal Process. 2021, 69, 5234–5249. [Google Scholar] [CrossRef]
- Lo, S.K.; Lu, Q.; Zhu, L.; Paik, H.Y.; Xu, X.; Wang, C. Architectural Patterns for the Design of Federated Learning Systems. arXiv 2021, arXiv:2101.02373. [Google Scholar]
- Jiao, Y.; Wang, P.; Niyato, D.; Lin, B.; Kim, D.I. Toward an Automated Auction Framework for Wireless Federated Learning Services Market. IEEE Trans. Mob. Comput. 2020, 20, 3034–3048. [Google Scholar] [CrossRef]
- Tensorflow Homepage. Available online: https://www.tensorflow.org/federated (accessed on 30 September 2021).
- Fedai Homepage. Available online: https://fate.fedai.org/ (accessed on 30 September 2021).
- Webank Homepage. Available online: https://www.webank.it/webankpub/wbresp/home.do (accessed on 30 September 2021).
- Paddlefl Homepage. Available online: https://paddlefl.readthedocs.io/en/stable/ (accessed on 21 September 2021).
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A. Federated multi-task learning. arXiv 2017, arXiv:1705.10467. [Google Scholar]
- Liu, Y.; Kang, Y.; Xing, C.; Chen, T.; Yang, Q. A Secure Federated Transfer Learning Framework. IEEE Intell. Syst. 2020, 35, 70–82. [Google Scholar] [CrossRef]
- Goetz, J.; Malik, K.; Bui, D.; Moon, S.; Liu, H.; Kumar, A. Active federated learning. arXiv 2019, arXiv:1909.12641. [Google Scholar]
- Sherpai Homepage. Available online: https://sherpa.ai/ (accessed on 21 September 2021).
- Leaf Homepage. Available online: https://leaf.cmu.edu/ (accessed on 21 September 2021).
- Caldas, S.; Duddu, S.M.K.; Wu, P.; Li, T.; Konečný, J.; McMahan, H.B.; Talwalkar, A. Leaf: A benchmark for federated settings. arXiv 2018, arXiv:1812.01097. [Google Scholar]
- Kholod, I.; Yanaki, E.; Fomichev, D.; Shalugin, E.; Novikova, E.; Filippov, E.; Nordlund, M. Open-Source Federated Learning Frameworks for IoT: A Comparative Review and Analysis. Sensors 2020, 21, 167. [Google Scholar] [CrossRef] [PubMed]
- IBM Homepage. Available online: https://ibmfl.mybluemix.net/ (accessed on 24 September 2021).
- NVIDIA Homepage. Available online: https://docs.NVIDIA.com/clara/ (accessed on 27 September 2021).
- Markidis, S.; Der Chien, S.W.; Laure, E.; Peng, I.B.; Vetter, J.S. NVIDIA Tensor Core Programmability, Performance & Precision. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Vancouver, BC, Canada, 21–25 May 2018; pp. 522–531. [Google Scholar]
- Ridnik, T.; Lawen, H.; Noy, A.; Ben, E.; Sharir, B.G.; Friedman, I. TResNet: High Performance GPU-Dedicated Architecture. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1399–1408. [Google Scholar]
- Du, L.; Du, Y. Hardware Accelerator Design for Machine Learning. In Machine Learning—Advanced Techniques and Emerging Applications; IntechOpen: London, UK, 2018. [Google Scholar]
- NVIDIA Homepage. Available online: https://www.NVIDIA.com/en-us/data-center/dgx-2/ (accessed on 1 October 2021).
- Du, L.; Du, Y.; Li, Y.; Su, J.; Kuan, Y.-C.; Liu, C.-C.; Chang, M.-C.F. A Reconfigurable Streaming Deep Convolutional Neural Network Accelerator for Internet of Things. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 198–208. [Google Scholar] [CrossRef] [Green Version]
- Putnam, A. The Configurable Cloud—Accelerating Hyperscale Datacenter Services with FPGA. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; p. 1587. [Google Scholar]
- Microsoft Homepage. Available online: https://www.microsoft.com/en-us/research/blog/microsoft-unveils-project-brainwave/ (accessed on 2 October 2021).
- Venkataramanaiah, S.K.; Yin, S.; Cao, Y.; Seo, J.-S. Deep Neural Network Training Accelerator Designs in ASIC and FPGA. In Proceedings of the 2020 International SoC Design Conference (ISOCC), Yeosu, Korea, 21–24 October 2020; pp. 21–22. [Google Scholar]
- Yazdanbakhsh, A.; Seshadri, K.; Akin, B.; Laudon, J.; Narayanaswami, R. An evaluation of Edge tpu accelerators for convolutional neural networks. arXiv 2021, arXiv:2102.10423. [Google Scholar]
- Bong, K.; Choi, S.; Kim, C.; Han, D.; Yoo, H.-J. A Low-Power Convolutional Neural Network Face Recognition Processor and a CIS Integrated with Always-on Face Detector. IEEE J. Solid-State Circuits 2017, 53, 115–123. [Google Scholar] [CrossRef]
- Desoli, G.; Chawla, N.; Boesch, T.; Singh, S.-P.; Guidetti, E.; De Ambroggi, F.; Majo, T.; ZambottI, P.; Ayodhyawasi, M.; Singh, H.; et al. 14.1 A 2.9TOPS/W deep convolutional neural network SoC in FD-SOI 28nm for intelligent embedded systems. In Proceedings of the 2017 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–9 February 2017; pp. 238–239. [Google Scholar]
- Mutalemwa, L.C.; Shin, S. A Classification of the Enabling Techniques for Low Latency and Reliable Communications in 5G and Beyond: AI-Enabled Edge Caching. IEEE Access 2020, 8, 205502–205533. [Google Scholar] [CrossRef]
- Perez-Torres, R.; Torres-Huitzil, C.; Truong, T.; Buckley, D.; Sreenan, C.J. Using Context-Awareness for Storage Services in Edge Computing. IT Prof. 2021, 23, 50–57. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Wang, C.; Zhao, Q.; Chen, X.; Chen, M. In-Edge AI: Intelligentizing Mobile Edge Computing, Caching and Communication by Federated Learning. IEEE Netw. 2019, 33, 156–165. [Google Scholar] [CrossRef] [Green Version]
- Chilukuri, S.; Pesch, D. Achieving Optimal Cache Utility in Constrained Wireless Networks through Federated Learning. In Proceedings of the 2020 IEEE 21st International Symposium on A World of Wireless, Mobile and Multimedia Networks (WoWMoM), Cork, Ireland, 31 August–3 September 2020; pp. 254–263. [Google Scholar]
- Cui, L.; Su, X.; Ming, Z.; Chen, Z.; Yang, S.; Zhou, Y.; Xiao, W. CREAT: Blockchain-assisted Compression Algorithm of Federated Learning for Content Caching in Edge Computing. IEEE Int. Things J. 2021, 1. [Google Scholar] [CrossRef]
- Yu, Z.; Hu, J.; Min, G.; Xu, H.; Mills, J. Proactive Content Caching for Internet-of-Vehicles based on Peer-to-Peer Federated Learning. In Proceedings of the 2020 IEEE 26th International Conference on Parallel and Distributed Systems (ICPADS), Hong Kong, China, 2–4 December 2020; pp. 601–608. [Google Scholar]
- Qi, K.; Yang, C. Popularity Prediction with Federated Learning for Proactive Caching at Wireless Edge. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Korea, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Ren, J.; Wang, H.; Hou, T.; Zheng, S.; Tang, C. Federated Learning-Based Computation Offloading Optimization in Edge Computing-Supported Internet of Things. IEEE Access 2019, 7, 69194–69201. [Google Scholar] [CrossRef]
- Shen, S.; Han, Y.; Wang, X.; Wang, Y. Computation Offloading with Multiple Agents in Edge-Computing–Supported IoT. ACM Trans. Sens. Netw. 2020, 16, 1–27. [Google Scholar] [CrossRef]
- Zhong, S.; Guo, S.; Yu, H.; Wang, Q. Cooperative service caching and computation offloading in multi-access edge computing. Comput. Netw. 2021, 189, 107916. [Google Scholar] [CrossRef]
- Liu, W.; Lin, H.; Wang, X.; Hu, J.; Kaddoum, G.; Piran, J.; Alamri, A. D2MIF: A Malicious Model Detection Mechanism for Federated Learning Empowered Artificial Intelligence of Things. IEEE Int. Things J. 2021, 1. [Google Scholar] [CrossRef]
- Zhou, Y.; Han, M.; Liu, L.; He, J.S.; Wang, Y. Deep learning approach for cyberattack detection. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Honolulu, HI, USA, 15–19 April 2018; pp. 262–267. [Google Scholar]
- Unb Homepage. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 2 October 2021).
- Cloudstor Homepage. Available online: https://Cloudstor.aarnet.edu.au/plus/index.php/s/2DhnLGDdEECo4ys (accessed on 2 October 2021).
- Sahu, A.K.; Sharma, S.; Tanveer, M.; Raja, R. Internet of Things attack detection using hybrid Deep Learning Model. Comput. Commun. 2021, 176, 146–154. [Google Scholar] [CrossRef]
- Sater, R.A.; Ben Hamza, A. A Federated Learning Approach to Anomaly Detection in Smart Buildings. ACM Trans. Int. Things 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, J.; Wu, D.; Teng, J.; Yu, S. Multi-Task Network Anomaly Detection using Federated Learning. In Proceedings of the Tenth International Symposium on Information and Communication Technology—SoICT 2019, Ha Long Bay, Hanoi, Vietnam, 4–6 December 2019; pp. 273–279. [Google Scholar]
- Abeshu, A.; Chilamkurti, N. Deep Learning: The Frontier for Distributed Attack Detection in Fog-to-Things Computing. IEEE Commun. Mag. 2018, 56, 169–175. [Google Scholar] [CrossRef]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated Learning-based Anomaly Detection for IoT Security Attacks. IEEE Int. Things J. 2021, 1. [Google Scholar] [CrossRef]
- Rey, V.; Sánchez, P.M.S.; Celdrán, A.H.; Bovet, G.; Jaggi, M. Federated learning for malware detection in iot devices. arXiv 2021, arXiv:2104.09994. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, J.; Yeo, C.K. Network Anomaly Detection Using Federated Deep Autoencoding Gaussian Mixture Model. In Proceedings of the Machine Learning for Networking; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–14. [Google Scholar]
- Preuveneers, D.; Rimmer, V.; Tsingenopoulos, I.; Spooren, J.; Joosen, W.; Ilie-Zudor, E. Chained Anomaly Detection Models for Federated Learning: An Intrusion Detection Case Study. Appl. Sci. 2018, 8, 2663. [Google Scholar] [CrossRef] [Green Version]
- Hsu, R.-H.; Wang, Y.-C.; Fan, C.-I.; Sun, B.; Ban, T.; Takahashi, T.; Wu, T.-W.; Kao, S.-W. A Privacy-Preserving Federated Learning System for Android Malware Detection Based on Edge Computing. In Proceedings of the 2020 15th Asia Joint Conference on Information Security (AsiaJCIS), Taipei, Taiwan, 20–21 August 2020; pp. 128–136. [Google Scholar]
- Sheng, S.; Chen, P.; Chen, Z.; Wu, L.; Yao, Y. Deep Reinforcement Learning-Based Task Scheduling in IoT Edge Computing. Sensors 2021, 21, 1666. [Google Scholar] [CrossRef] [PubMed]
- Meng, F.; Chen, P.; Wu, L.; Cheng, J. Power Allocation in Multi-User Cellular Networks: Deep Reinforcement Learning Approaches. IEEE Trans. Wirel. Commun. 2020, 19, 6255–6267. [Google Scholar] [CrossRef]
- Xiong, X.; Zheng, K.; Lei, L.; Hou, L. Resource Allocation Based on Deep Reinforcement Learning in IoT Edge Computing. IEEE J. Sel. Areas Commun. 2020, 38, 1133–1146. [Google Scholar] [CrossRef]
- Baek, J.; Kaddoum, G. Heterogeneous Task Offloading and Resource Allocations via Deep Recurrent Reinforcement Learning in Partial Observable Multifog Networks. IEEE Int. Things J. 2021, 8, 1041–1056. [Google Scholar] [CrossRef]
- Alwarafy, A.; Abdallah, M.; Ciftler, B.S.; Al-Fuqaha, A.; Hamdi, M. Deep Reinforcement Learning for Radio Resource Allocation and Management in Next Generation Heterogeneous Wireless Networks: A Survey. arXiv 2021, arXiv:2106.00574. [Google Scholar]
- Wang, S.; Chen, M.; Yin, C.; Saad, W.; Hong, C.S.; Cui, S.; Poor, H.V. Federated Learning for Task and Resource Allocation in Wireless High-Altitude Balloon Networks. IEEE Int. Things J. 2021, 8, 17460–17475. [Google Scholar] [CrossRef]
- Samarakoon, S.; Bennis, M.; Saad, W.; Debbah, M. Distributed federated learning for ultra-reliable low-latency vehicular communications. IEEE Trans. Commun. 2019, 68, 1146–1159. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Chauhan, R.; Ghanshala, K.K.; Joshi, R.C. Convolutional Neural Network (CNN) for Image Detection and Recognition. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018; pp. 122–129. [Google Scholar]
- Swenson, B.; Murray, R.; Kar, S.; Poor, H.V. Distributed Stochastic Gradient Descent: Nonconvexity, Nonsmoothness, and Convergence to Local Minima. arXiv 2020, arXiv:2003.02818. [Google Scholar]
- Stich, S.U. Local SGD converges fast and communicates little. arXiv 2018, arXiv:1805.09767. [Google Scholar]
- Deng, Y.; Mahdavi, M. Local Stochastic Gradient Descent Ascent: Convergence Analysis and Communication Efficiency. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics. PMLR 2021, 130, 1387–1395. [Google Scholar]
- Beznosikov, A.; Dvurechensky, P.; Koloskova, A.; Samokhin, V.; Stich, S.U.; Gasnikov, A. Decentralized Local Stochastic Extra-Gradient for Variational Inequalities. arXiv 2021, arXiv:2106.08315. [Google Scholar]
- Alistarh, D.; Grubic, D.; Li, J.; Tomioka, R.; Vojnovic, M. QSGD: Communication-efficient SGD via gradient quantization and encoding. Adv. Neural Inf. Process. Syst. 2017, 30, 1709–1720. [Google Scholar]
- Chen, M.; Shlezinger, N.; Poor, H.V.; Eldar, Y.C.; Cui, S. Communication-efficient federated learning. Proc. Natl. Acad. Sci. USA 2021, 118. [Google Scholar] [CrossRef]
- Wu, J.; Huang, W.; Huang, J.; Zhang, T. Error compensated quantized SGD and its applications to large-scale distributed optimization. In Proceedings of the 35th International Conference on Machine Learning. PMLR 2018, 80, 5325–5333. [Google Scholar]
- Gandikota, V.; Kane, D.; Maity, R.K.; Mazumdar, A. vqsgd: Vector quantized stochastic gradient descent. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics. PMLR 2021, 130, 2197–2205. [Google Scholar]
- Wangni, J.; Wang, J.; Liu, J.; Zhang, T. Gradient sparsification for communication-efficient distributed optimization. arXiv 2017, arXiv:1710.09854. [Google Scholar]
- Ozfatura, E.; Ozfatura, K.; Gunduz, D. Time-Correlated Sparsification for Communication-Efficient Federated Learning. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 12–20 July 2021; pp. 461–466. [Google Scholar]
- Sun, Y.; Zhou, S.; Niu, Z.; Gunduz, D. Dynamic Scheduling for Over-the-Air Federated Edge Learning with Energy Constraints. IEEE J. Sel. Areas Commun. 2021, 1. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. arXiv 2018, arXiv:1812.06127. [Google Scholar]
- Laguel, Y.; Pillutla, K.; Malick, J.; Harchaoui, Z. A Superquantile Approach to Federated Learning with Heterogeneous Devices. In Proceedings of the 2021 55th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 24–26 March 2021; pp. 1–6. [Google Scholar]
- Yang, C.; Wang, Q.; Xu, M.; Chen, Z.; Bian, K.; Liu, Y.; Liu, X. Characterizing Impacts of Heterogeneity in Federated Learning upon Large-Scale Smartphone Data. In Proceedings of the Web Conference 2021, Virtual Event, France, 25–29 April 2022; pp. 935–946. [Google Scholar]
- Abdelmoniem, A.M.; Canini, M. Towards Mitigating Device Heterogeneity in Federated Learning via Adaptive Model Quantization. In Proceedings of the 1st Workshop on Machine Learning and Systems, Online, 26 April 2021; pp. 96–103. [Google Scholar]
- Duan, M.; Liu, D.; Chen, X.; Liu, R.; Tan, Y.; Liang, L. Self-Balancing Federated Learning with Global Imbalanced Data in Mobile Systems. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 59–71. [Google Scholar] [CrossRef]
- Wang, L.; Xu, S.; Wang, X.; Zhu, Q. Addressing Class Imbalance in Federated Learning. arXiv 2020, arXiv:2008.06217. [Google Scholar]
- Sarkar, D.; Narang, A.; Rai, S. Fed-Focal Loss for imbalanced data classification in Federated Learning. arXiv 2020, arXiv:2011.06283. [Google Scholar]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Hsieh, K.; Phanishayee, A.; Mutlu, O.; Gibbons, P.B. The non-iid data quagmire of decentralized machine learning. In Proceedings of the 37th International Conference on Machine Learning. PMLR 2020, 119, 4387–4398. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-IID data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Jeong, E.; Oh, S.; Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-IID private data. arXiv 2018, arXiv:1811.11479. [Google Scholar]
- Huang, L.; Yin, Y.; Fu, Z.; Zhang, S.; Deng, H.; Liu, D. LoAdaBoost: Loss-based AdaBoost federated machine learning with reduced computational complexity on IID and non-IID intensive care data. PLoS ONE 2020, 15, e0230706. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Wang, X.; Zhu, H.; Wang, H.; Qian, H. Federated learning with class imbalance reduction. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Reisizadeh, A.; Farnia, F.; Pedarsani, R.; Jadbabaie, A. Robust federated learning: The case of affine distribution shifts. arXiv 2020, arXiv:2006.08907. [Google Scholar]
- Andreux, M.; du Terrail, J.O.; Beguier, C.; Tramel, E.W. Siloed Federated Learning for Multi-centric Histopathology Datasets. In Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 129–139. [Google Scholar]
- Li, X.; Jiang, M.; Zhang, X.; Kamp, M.; Dou, Q. Fedbn: Federated learning on non-IID features via local batch normalization. arXiv 2021, arXiv:2102.07623. [Google Scholar]
- Li, Z.; Yu, H.; Zhou, T.; Luo, L.; Fan, M.; Xu, Z.; Sun, G. Byzantine Resistant Secure Blockchained Federated Learning at the Edge. IEEE Netw. 2021, 35, 295–301. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Rieger, P.; Miettinen, M.; Sadeghi, A.-R. Poisoning Attacks on Federated Learning-based IoT Intrusion Detection System. In Proceedings of the Workshop on Decentralized IoT Systems and Security (DISS) 2020, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Zhou, X.; Xu, M.; Wu, Y.; Zheng, N. Deep Model Poisoning Attack on Federated Learning. Future Int. 2021, 13, 73. [Google Scholar] [CrossRef]
- Luo, X.; Zhu, X. Exploiting defenses against GAN-based feature inference attacks in federated learning. arXiv 2020, arXiv:2004.12571. [Google Scholar]
- Li, S.; Cheng, Y.; Liu, Y.; Wang, W.; Chen, T. Abnormal client behavior detection in federated learning. arXiv 2019, arXiv:1910.09933. [Google Scholar]
- Wan, W.; Lu, J.; Hu, S.; Zhang, L.Y.; Pei, X. Shielding Federated Learning: A New Attack Approach and Its Defense. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–7. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Analyzing federated learning through an adversarial lens. In Proceedings of the 36th International Conference on Machine Learning. PMLR 2019, 97, 634–643. [Google Scholar]
- Fung, C.; Yoon, C.J.; Beschastnikh, I. Mitigating sybils in federated learning poisoning. arXiv 2018, arXiv:1808.04866. [Google Scholar]
- Li, S.; Cheng, Y.; Wang, W.; Liu, Y.; Chen, T. Learning to detect malicious clients for robust federated learning. arXiv 2020, arXiv:2002.00211. [Google Scholar]
- Xia, Q.; Ye, W.; Tao, Z.; Wu, J.; Li, Q. A survey of federated learning for edge computing: Research problems and solutions. High-Confid. Comput. 2021, 1, 100008. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef] [Green Version]
- Fu, Y.; Zhou, Y.; Wu, D.; Yu, S.; Wen, Y.; Li, C. On the Practicality of Differential Privacy in Federated Learning by Tuning Iteration Times. arXiv 2021, arXiv:2101.04163. [Google Scholar]
- Homomorphicencryption Homepage. Available online: https://homomorphicencryption.org/introduction/ (accessed on 3 October 2021).
- Yehuda, L. Secure Multiparty Computation (MPC). IACR Cryptol. ePrint Arch. 2020, 2020, 300. [Google Scholar]
- Zheng, Z.; Xie, S.; Dai, H.N.; Chen, X.; Wang, H. Blockchain challenges and opportunities: A survey. Int. J. Web Grid Serv. 2018, 14, 352–375. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Jiang, L.; Tan, R.; Niyato, D.; Li, Z.; Liu, Y. Privacy-preserving blockchain-based federated learning for IoT devices. IEEE Int. Things J. 2020, 8, 1817–1829. [Google Scholar] [CrossRef]
- Cho, Y.J.; Wang, J.; Joshi, G. Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies. arXiv 2020, arXiv:2010.01243. [Google Scholar]
- Tang, M.; Ning, X.; Wang, Y.; Wang, Y.; Chen, Y. Fedgp: Correlation-based active client selection for heterogeneous federated learning. arXiv 2021, arXiv:2103.13822. [Google Scholar]
- Wu, H.; Wang, P. Node Selection Toward Faster Convergence for Federated Learning on non-IID Data. arXiv 2021, arXiv:2105.07066. [Google Scholar]
- Xu, B.; Xia, W.; Zhang, J.; Quek, T.Q.S.; Zhu, H. Online Client Scheduling for Fast Federated Learning. IEEE Wirel. Commun. Lett. 2021, 10, 1434–1438. [Google Scholar] [CrossRef]
- Song, T.; Tong, Y.; Wei, S. Profit Allocation for Federated Learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2577–2586. [Google Scholar]
- Kang, J.; Xiong, Z.; Niyato, D.; Yu, H.; Liang, Y.-C.; Kim, D.I. Incentive Design for Efficient Federated Learning in Mobile Networks: A Contract Theory Approach. In Proceedings of the 2019 IEEE VTS Asia Pacific Wireless Communications Symposium (APWCS), Singapore, 28–30 August 2019; pp. 1–5. [Google Scholar]
- Feng, S.; Niyato, D.; Wang, P.; Kim, D.I.; Liang, Y.-C. Joint Service Pricing and Cooperative Relay Communication for Federated Learning. In Proceedings of the 2019 International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Atlanta, GA, USA, 14–17 July 2019; pp. 815–820. [Google Scholar]
- Filho, G.P.R.; Villas, L.; Freitas, H.; Valejo, A.; Guidoni, D.L.; Ueyama, J. ResiDI: Towards a smarter smart home system for decision-making using wireless sensors and actuators. Comput. Netw. 2018, 135, 54–69. [Google Scholar] [CrossRef]
- Filho, G.P.R.; Meneguette, R.I.; Maiac, G.; Pessind, G.; Gonçalves, V.P.; Weiganga, L.; Ueyama, J.; Villas, L.A. A fog-enabled smart home solution for decision-making using smart objects. Future Gener. Comput. Syst. 2020, 103, 18–27. [Google Scholar] [CrossRef]
- Rocha Filho, G.P.; Mano, L.Y.; Valejo, A.D.B.; Villas, L.A.; Ueyama, J. A low-cost smart home automation to enhance decision-making based on fog computing and computational intelligence. IEEE Lat. Am. Trans. 2018, 16, 186–191. [Google Scholar] [CrossRef]
- Filho, G.; Ueyama, J.; Villas, L.; Pinto, A.; Gonçalves, V.; Pessin, G.; Pazzi, R.; Braun, T. NodePM: A Remote Monitoring Alert System for Energy Consumption Using Probabilistic Techniques. Sensors 2014, 14, 848–867. [Google Scholar] [CrossRef]
- Aivodji, U.M.; Gambs, S.; Martin, A. IOTFLA: A Secured and Privacy-Preserving Smart Home Architecture Implementing Federated Learning. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 19–23 May 2019; pp. 175–180. [Google Scholar]
- Li, W.; Milletarì, F.; Xu, D.; Rieke, N.; Hancox, J.; Zhu, W.; Baust, M.; Cheng, Y.; Ourselin, S.; Cardoso, M.J.; et al. Privacy-Preserving Federated Brain Tumour Segmentation. In Machine Learning in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2019; pp. 133–141. [Google Scholar]
- Lee, G.H.; Shin, S.-Y. Federated Learning on Clinical Benchmark Data: Performance Assessment. J. Med. Int. Res. 2020, 22, e20891. [Google Scholar] [CrossRef]
- Yang, H.; Zhao, J.; Xiong, Z.; Lam, K.Y.; Sun, S.; Xiao, L. Privacy-Preserving Federated Learning for UAV-Enabled Networks: Learning-Based Joint Scheduling and Resource Management. IEEE J. Sel. Areas Commun. 2021, 39, 3144–3159. [Google Scholar] [CrossRef]
- Zhang, H.; Hanzo, L. Federated Learning Assisted Multi-UAV Networks. IEEE Trans. Veh. Technol. 2020, 69, 14104–14109. [Google Scholar] [CrossRef]












| Activation Function | Equation | Range |
|---|---|---|
| Linear Function | ||
| Step Function | ||
| Sigmoid Function | ||
| Hyperbolic Tangent Function | ||
| ReLU | ||
| Leaky ReLU | ||
| Swish Function |
| Name | Owner | Pros | Cons |
|---|---|---|---|
| CPU/GPU | NVIDIA and Radeon | High memory, bandwidth, and throughput | Consumes a large amount of power |
| FPGA | Intel | High performance per watt of power consumption, reduced costs for large-scale operations, excellent choice for battery-powered devices and on cloud servers for large applications | It requires a significant amount of storage, external memory and bandwidth, and computational resources on the order of billions of operations per second |
| ASIC | Intel | Minimizes memory transfer, most energy efficient compared to FPGAs and GPUs, and best computational speed compared to FPGAs and GPUs | Long development cycle, Lack of flexibility to handle varying DL network designs |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abreha, H.G.; Hayajneh, M.; Serhani, M.A. Federated Learning in Edge Computing: A Systematic Survey. Sensors 2022, 22, 450. https://doi.org/10.3390/s22020450
Abreha HG, Hayajneh M, Serhani MA. Federated Learning in Edge Computing: A Systematic Survey. Sensors. 2022; 22(2):450. https://doi.org/10.3390/s22020450
Chicago/Turabian StyleAbreha, Haftay Gebreslasie, Mohammad Hayajneh, and Mohamed Adel Serhani. 2022. "Federated Learning in Edge Computing: A Systematic Survey" Sensors 22, no. 2: 450. https://doi.org/10.3390/s22020450
APA StyleAbreha, H. G., Hayajneh, M., & Serhani, M. A. (2022). Federated Learning in Edge Computing: A Systematic Survey. Sensors, 22(2), 450. https://doi.org/10.3390/s22020450