1. Introduction
With the rapid development of information technology, marine datasets are growing at an astonishing rate, driving the ocean into the era of big data. Marine data possesses characteristics such as large volume, diversity, and spatiotemporal properties, making it a typical application area for big data [
1]. Among marine data, ship trajectory dataset is an important component, formed by collecting and recording a series of navigation information generated by ships during their voyages. These data form sequences with temporal and spatial attributes, composed in the order of collection time.
The Automatic Identification System (AIS) [
2] is currently the most widely used global ship identification and tracking system in the field of maritime traffic. The AIS system encodes and broadcasts key information of ships (such as position, speed, heading, ship type, etc.) through transmitters and receivers on the ships. This information can be received and used by surrounding ships, shore-based stations, and satellites to monitor the real-time positions and navigation statuses of ships.
Through AIS, ships are able to perceive and recognize each other, taking timely evasive actions to reduce the risk of collisions at sea. AIS provides not only static information about the ships, such as length, width, and ship type, but also dynamic information including latitude, longitude, and acquisition time. These pieces of information can be used for predicting ship behavior [
3,
4,
5,
6] and trajectories [
7,
8], supporting maritime search and rescue systems [
9,
10], detecting fishing activities [
11,
12], as well as identifying anomalous behavior [
13,
14,
15,
16]. This greatly facilitates maritime operations and enhances maritime safety governance. Additionally, the ship type information in AIS plays a crucial role in shipping analysis, prevention of maritime terrorism, and combating maritime smuggling activities [
17].
In order to better understand and utilize ship trajectory data, the task of ship trajectory classification has emerged. This task aims to construct classification models by extracting feature information embedded in trajectory data to accurately determine the types of different ship trajectories. This ship trajectory-based classification task has extensive application value and prospects. It can be used in maritime traffic management to assist in monitoring and controlling ship operations. In the field of maritime safety, it helps identify suspicious ship activities and prevent illegal behaviors such as terrorism. Moreover, it can provide decision-making support for marine resource management, promoting the sustainable development of fisheries and shipping industries.
However, it is important to note that AIS data presents certain challenges and issues in practical applications. Due to the susceptibility of AIS data to manipulation by vessel owners, some illicit vessels may intentionally falsify ship type information to conceal illegal fishing activities, espionage operations, or other unlawful behaviors. According to statistics, illegal fishing activities result in the capture of approximately 11 to 26 million metric tons of fish annually, accounting for 15% of global fish consumption [
18]. Additionally, there are instances where certain countries may engage in malicious manipulation of AIS data, disguising reconnaissance vessels as neighboring fishing vessels, leading to security risks and geopolitical concerns.
Moreover, AIS data itself may contain recording or transmission errors, resulting in ship type information not matching the actual situation. Such data noise and errors pose challenges to ship trajectory-based classification tasks because incorrect ship type information increases the difficulty of detecting maritime illegal activities, posing a serious threat to maritime safety.
Trajectory classification methods based on deep learning typically assume that the ship types in the dataset are correctly labeled. However, this assumption is often difficult to meet in real-world scenarios. Deep learning models have powerful learning capabilities and can fit training sets with arbitrary label noise proportions [
19]. However, the presence of label noise severely compromises the generalization performance of the models. Compared to other types of noise, label noise is considered more harmful to the model’s performance [
20]. Learning from datasets with noisy labels has become an important task in modern deep learning applications.
To avoid the model learning incorrect samples, many recent studies have adopted sample selection methods to choose correctly labeled samples from the noisy training dataset. Arpit et al. [
21] found that deep learning models tend to first learn from easy samples during the training process and then learn from noisy label samples and difficult samples. Therefore, the small loss selection strategy treats samples with small training losses as clean samples [
22]. MentorNet [
23], based on the idea of knowledge distillation [
24], first uses a teacher model to select clean samples, which are then input into the student model for training, partially avoiding the influence of noisy label samples. Co-teaching [
25] proposes using two different models (with different structures or different initializations of the same structure) with different learning abilities to filter out different types of errors caused by noisy labels. Each model selects its own small-loss samples from the same mini-batch and exchanges them with the peer model to update parameters. Co-teaching+ [
26] further selects samples with inconsistent predictions from the small-loss samples, encouraging both models to learn the same correct patterns. JoCoR (joint training with co-regularization) [
27] uses contrastive loss to measure the consistency of predictions between the two peer models and combines it with the supervised loss of the two peer models to form a joint loss. It selects a certain proportion of small joint loss samples to train the two peer models simultaneously. Yao et al. [
28] believe that the proportions of noisy label samples in different mini-batches are different, and using a relatively fixed proportion to select training samples does not reflect the actual situation. They propose using the Jensen–Shannon divergence (ranging from 0 to 1) to measure the difference between predicted results and true labels, which represents the probability of belonging to clean samples. For samples identified as containing noisy labels, they construct two different views to further measure the difference in predictions between the two views and differentiate between in-distribution samples and out-of-distribution samples.
The method of learning from small-loss samples has overall good performance but can accumulate errors due to incorrect selections. In addition, determining the appropriate proportion of small-loss samples remains a challenge. Existing methods mostly directly use the true noise rate of the dataset as the proportion of small-loss samples. However, it is often difficult to obtain the true noise rate of the dataset in reality, making these methods challenging to directly apply to practical problems. To address this issue, we propose a noise rate adaptive learning mechanism without prior conditions, allowing the model to learn the data noise rate during training. We combine this mechanism with JoCoR and design a robust training paradigm called A-JoCoR.
The contributions of this study are summarized as follows: (1) propose a noise rate adaptive learning mechanism without prior conditions. (2) Combine the proposed noise rate adaptive learning mechanism with JoCoR to design the robust training paradigm A-JoCoR. (3) Using AIS data from the Danish Maritime Authority, which includes 80,000 trajectories with eight ship types, each containing 10,000 samples from January to May 2020 within their territorial waters, we demonstrate the effectiveness of the proposed method for ship trajectory classification problems with noisy labels.
The rest of this paper is organized as follows:
Section 2 introduces the methods used in this paper.
Section 3 demonstrates the effectiveness of the proposed algorithm through its application to AIS trajectories.
Section 4 discusses and analyzes the experimental results. Finally, the conclusions are discussed in
Section 5.
2. Methods
The classification of ship trajectories with noisy labels in this paper consists of three stages: (1) data preprocessing and construction of the trajectory dataset, (2) adding different levels of label noise to the original dataset through a label transformation matrix, and (3) learning the noisy trajectory dataset using the A-JoCoR robust training paradigm.
2.1. AIS Data Preprocessing
AIS data contains a vast amount of information generated by ships during their voyages, comprising a total of 27 fields, including 10 dynamic data fields such as collection timestamp, latitude, longitude, and speed, and 14 static data fields such as ship dimensions, draft, and ship type. Additionally, there are three calculated fields. The names and meanings of some fields are shown in
Table 1. Through a survey of existing ship trajectory classification works, this paper ultimately aims to retain seven fields from the AIS data: timestamp, MMSI, latitude, longitude, Speed Over Ground (SOG), Course Over Ground (COG), and ship type. The MMSI serves as a unique identifier for different ship trajectory data, facilitating the segmentation of data from different vessels. The ship type is used as a label for annotating ship trajectory data, and it plays a role in subsequent model training. The combination of timestamp, latitude, and longitude forms a ship trajectory data point containing temporal and spatial information, while the inclusion of SOG and COG enriches the features of the ship trajectory data. However, due to technical malfunctions and coverage limitations, the data may suffer from issues such as missing data and cannot be directly used for training deep learning models. Therefore, preprocessing of the AIS raw data is necessary before constructing the ship trajectory dataset (
Figure 1).
The data preprocessing process is as follows. Firstly, the trajectory points in the raw AIS data with the same MMSI are arranged in chronological order. This is performed to separate the navigation trajectories of different vessels. Secondly, trajectory points with missing values or values that clearly do not conform to real-world conditions are removed. This includes cases where the SOG is greater than 80 knots/hour, longitude is greater than 180 , and latitude is greater than 90 . Next, a threshold-based method is applied to remove drift points in the trajectories. In this study, a distance threshold of 1 km is set based on experience. If the distance between a trajectory point and the line connecting its preceding and succeeding points exceeds the threshold, the point is considered a drift point and is removed. Furthermore, the trajectories are segmented. A single vessel’s data within a specific time period may include multiple sailing trips. To determine if a vessel’s data within a time period contains multiple sailing trips, time and distance interval thresholds are set for adjacent trajectory points. If the time interval between two adjacent trajectory points exceeds 1 h or the distance interval exceeds 1 km, it is considered that the vessel has started a new trip, and the trajectory is segmented accordingly. After segmenting all trajectory data, the trajectories are further divided into segments of 500 trajectory points each. Trajectory segments with fewer than 500 points and excessively short trajectories are removed, resulting in fixed-length trajectory data of 500 points.
In addition, when analyzing the segmented vessel trajectories, it was observed that many vessels had a prolonged SOG value of 0. Upon observing the latitude and longitude of these trajectory points, it was found that these vessels remained stationary throughout the duration or for a significant period of time. For this category of stationary vessels, it is believed that their trajectories contain insufficient information and cannot be applied to subsequent research tasks. Therefore, their entire trajectories are removed.
After the preprocessing steps described above, this study extracted a total of 381,483 trajectory data points from AIS data within the territorial waters of Denmark from January to May 2020, as provided by the Danish Maritime Authority [
29]. These trajectory data points encompassed 15 types of vessel trajectories, as shown in
Table 2 with specific information.
It can be observed that the preprocessed ship trajectory data exhibits a severe class imbalance issue. The number of cruise ship trajectories is over two hundred times greater than the number of sailboat trajectories. To ensure a balanced distribution of samples in the constructed dataset, we selects eight types of vessel categories, including passenger ships, tugboats, fishing boats, pilot boats, cargo ships, dredgers, high-speed boats, and search and rescue vessels. Each category consists of 10,000 trajectories, resulting in a total of 80,000 trajectories comprising the ship trajectory dataset for further analysis and research.The training set, validation set, and test set are divided in a ratio of 6:2:2, with the samples of ship trajectories from each class evenly distributed across these datasets.
2.2. Noise Label Setting
To evaluate the performance of the proposed method on ship trajectory classification tasks with noisy labels, this study follows the approach outlined in references [
27,
30,
31] to introduce noisy labels into the dataset. Specifically, a label corruption matrix
Q is employed to intentionally introduce label noise into the constructed dataset.
where
denotes the probability of a clean sample with label
i being flipped to a noisy sample with label
j.
In this study, two structures of label corruption matrix
Q are utilized: (1) symmetric flipping [
32], and (2) asymmetric flipping [
30], which simulates the noise labels in fine-grained classification. An example of the label corruption matrix
Q is shown in
Figure 2. It is worth noting that asymmetric flipping only selects half of the labels for flipping, resulting in a total label corruption rate that is half of the label flipping ratio.
2.3. Robust Training Paradigm for Noise Rate Adaptive Learning
This paper proposes a noise rate adaptive learning mechanism without any prior assumptions. The mechanism enables the model to learn the noise rate of the dataset during the training process, allowing for the adaptive adjustment of the selection ratio of small-loss samples. The proposed mechanism combines this approach with the robust training paradigm JoCoR, resulting in the design of a robust training paradigm called A-JoCoR, which incorporates noise rate adaptive learning.
2.3.1. Mechanism of Noise Rate Adaptive Learning without Prior Assumptions
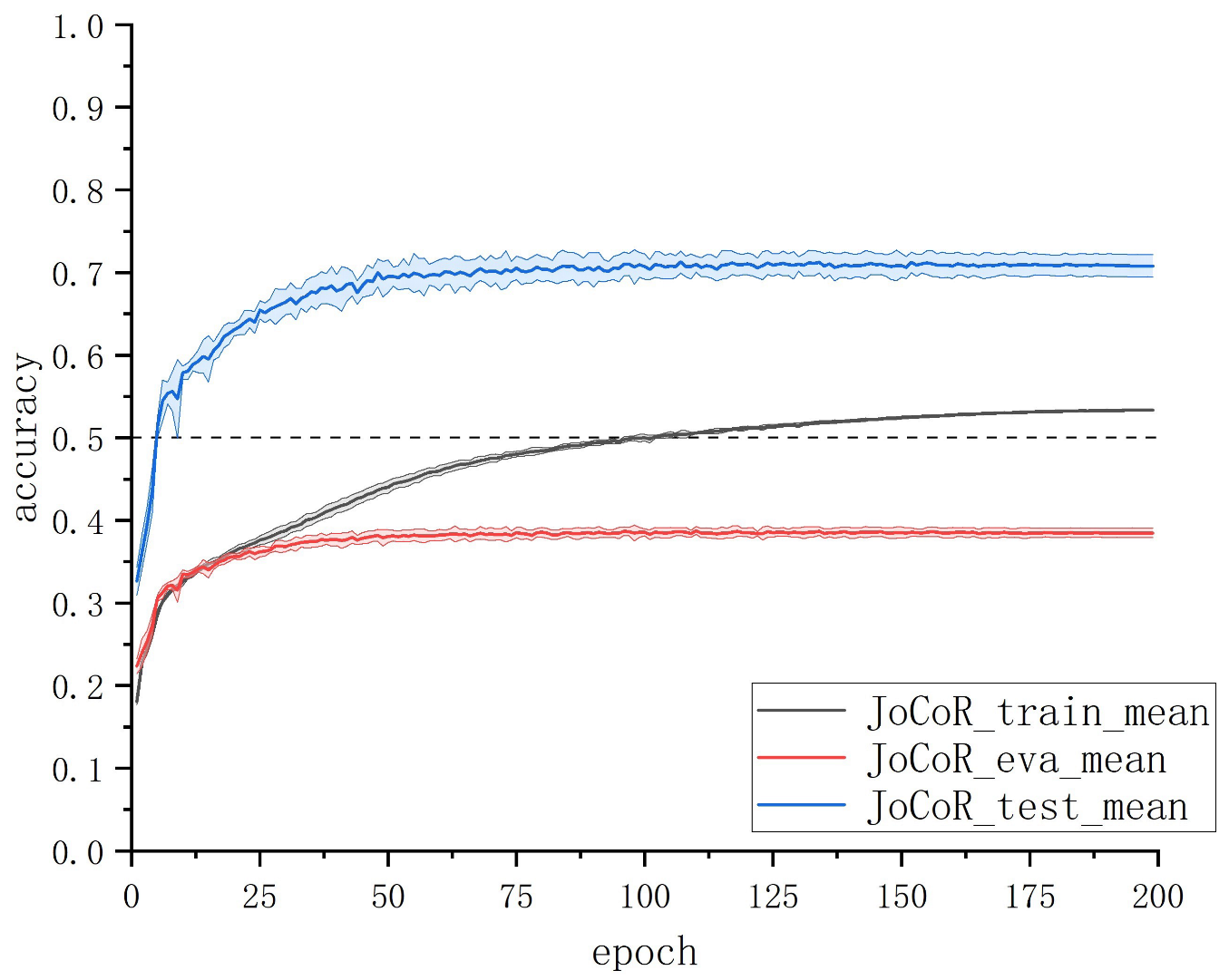
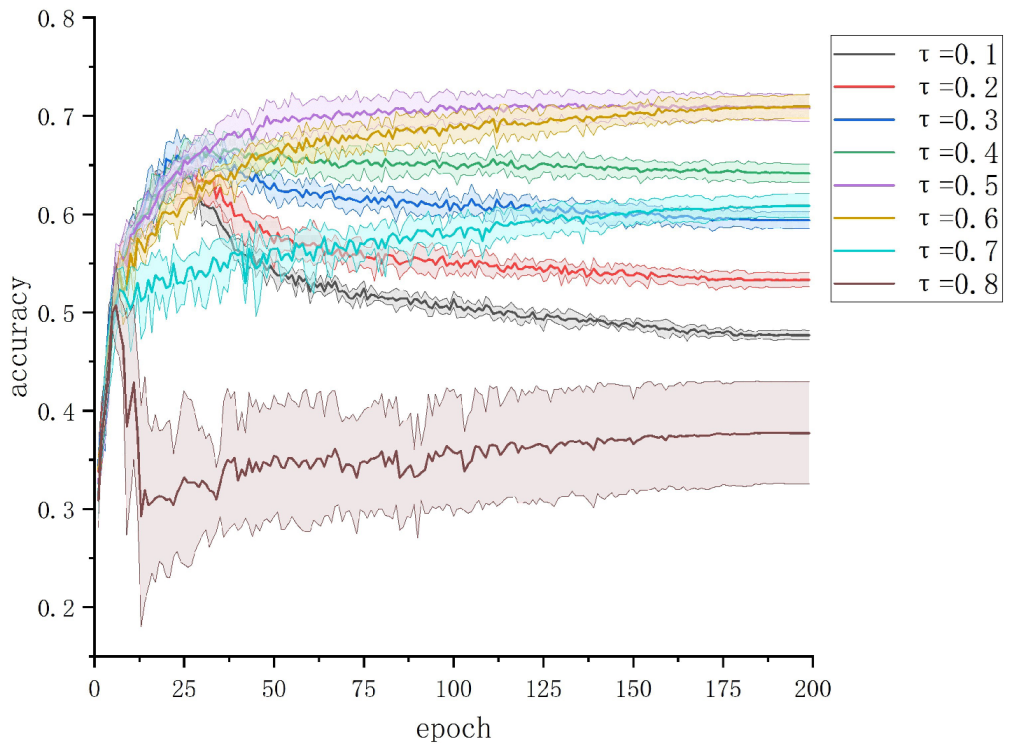
We explored the intrinsic relationship between various metrics of deep learning models during training and the actual data corruption rate. Through experimental analysis on the ship trajectory dataset with noisy labels using JoCoR, taking the results on a 50% symmetric noise dataset as an example (as shown in
Figure 3), we found that as the number of training epochs increases, the training accuracy of the model continues to rise until it surpasses the proportion of clean data in the training set. This is because the model gradually fits to the erroneous label data in the later stages of training. However, during this process, the validation accuracy of the model does not rise along with the training accuracy but rather starts to deviate and never exceeds the proportion of clean data. This discrepancy is likely due to inconsistent characteristics of the noise data between the training and validation sets. The features learned from the erroneous label data in the training set do not help improve the model’s classification performance on the validation set, as the relatively easy-to-discriminate clean samples continue to be correctly classified on the validation set.
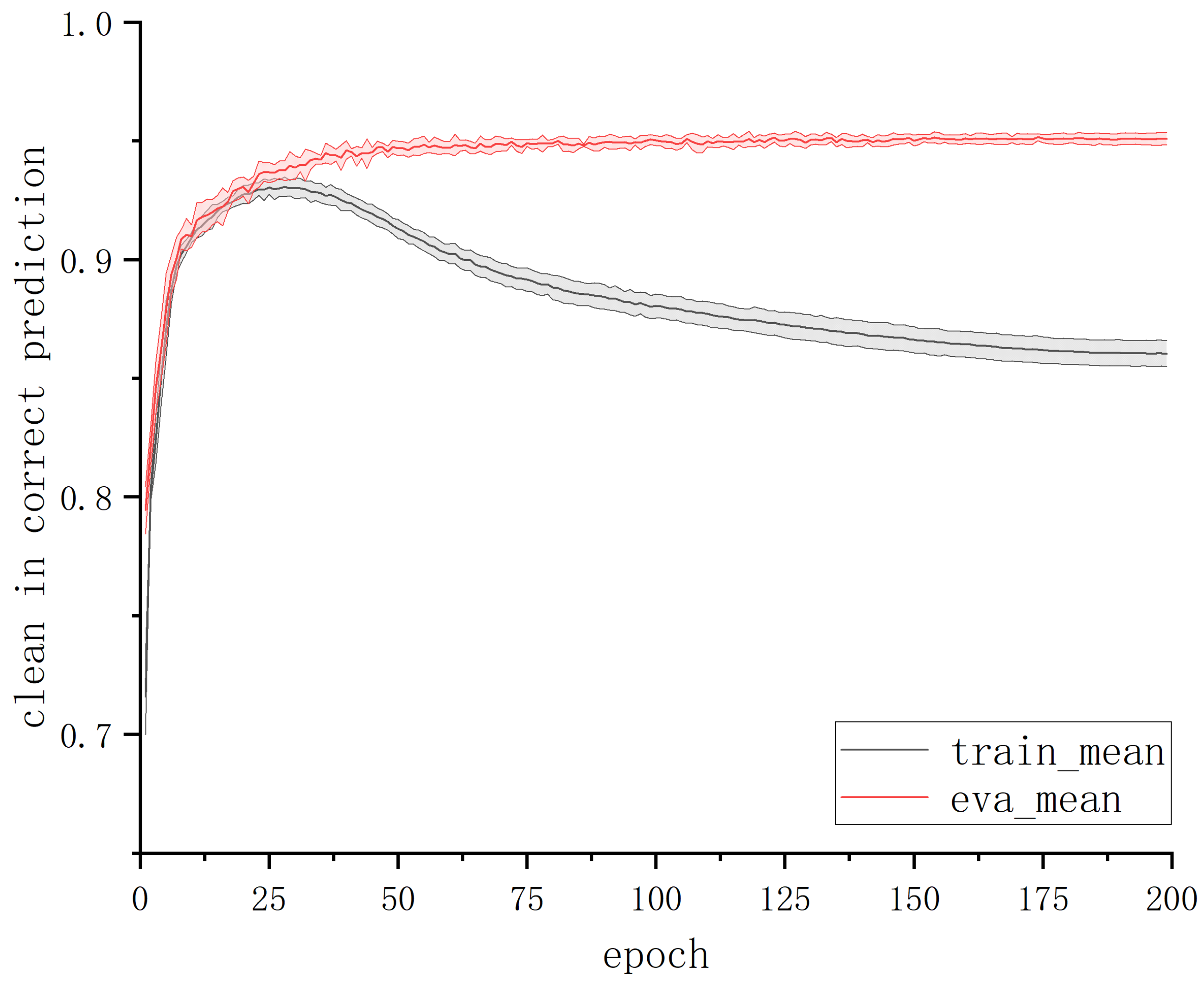
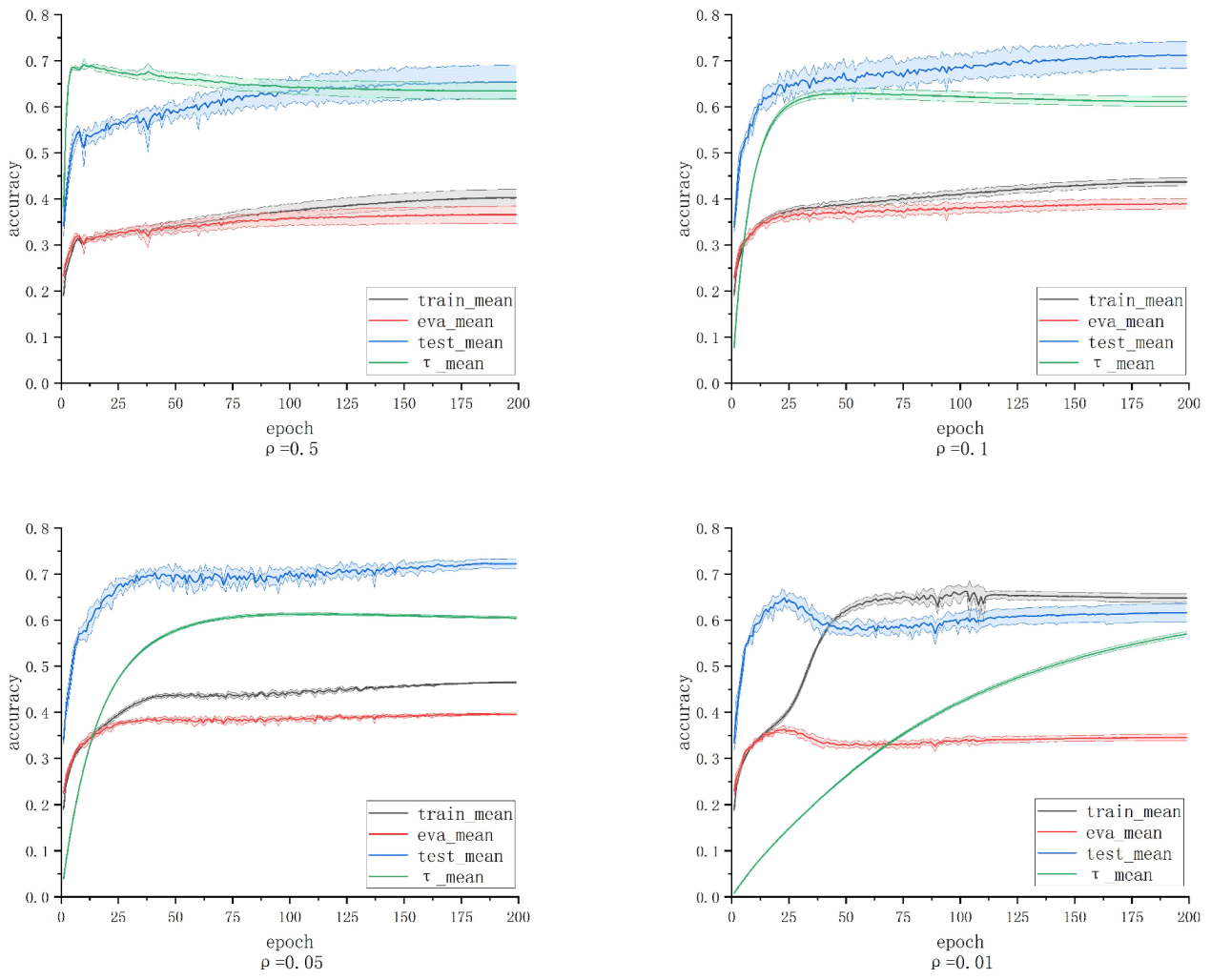
To validate this inference, we conducted statistics on the proportion of correctly predicted clean samples in the training set and validation set under each epoch during JoCoR’s training on a 50% symmetric noise dataset. The variation curve of this proportion with respect to epochs is shown in
Figure 4. The solid line in the graph represents the mean accuracy over five experiments, and the shaded area represents the STD band.
By comparing
Figure 3 and
Figure 4, it can be observed that when the training accuracy curve and the validation accuracy curve begin to diverge, the curve representing the proportion of correctly predicted clean samples also starts to separate. The proportion of correctly predicted clean samples in the training set gradually decreases with an increasing number of epochs, while the proportion in the validation set remains relatively unchanged. This alignment perfectly aligns with the changing trends of training accuracy and validation accuracy. This experimental phenomenon confirms the previous inference: the model’s learning of erroneous label data features on the training set does not immediately affect its classification results on the validation set. This also explains why the model’s validation accuracy does not surpass the proportion of clean data.
Based on this finding, we incorporate the model’s validation accuracy into the small-loss sample selection mechanism and propose a no prior condition adaptive learning mechanism for noise rate. The specific design is as follows:
where
t represents the training epoch,
denotes the estimated noise rate of the model in the
t-th round,
represents the validation accuracy of the model in the
t-th round,
denotes the sample abandonment rate in the
t-th round, and the adaptive learning rate
.
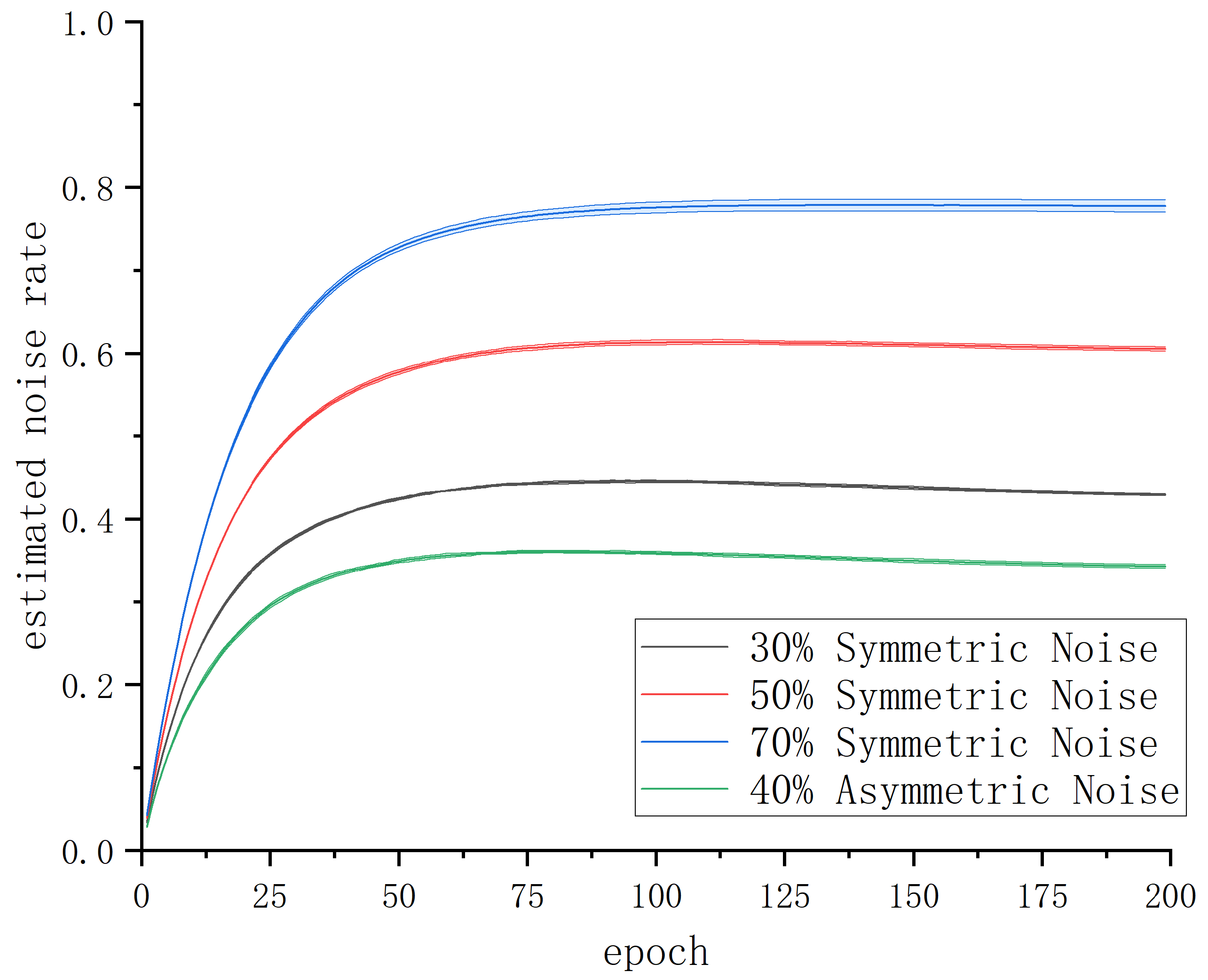
The noise rate adaptive learning mechanism proposed in this paper only requires setting the initial values of the sample abandonment rate and the adaptive learning rate . With these settings, it can dynamically estimate the noise rate based on the validation accuracy during the model training process. This eliminates the drawbacks of existing robust classification frameworks that rely on prior means to estimate the noise rate.
2.3.2. Robust Training Paradigm for Noise Rate Adaptive Learning
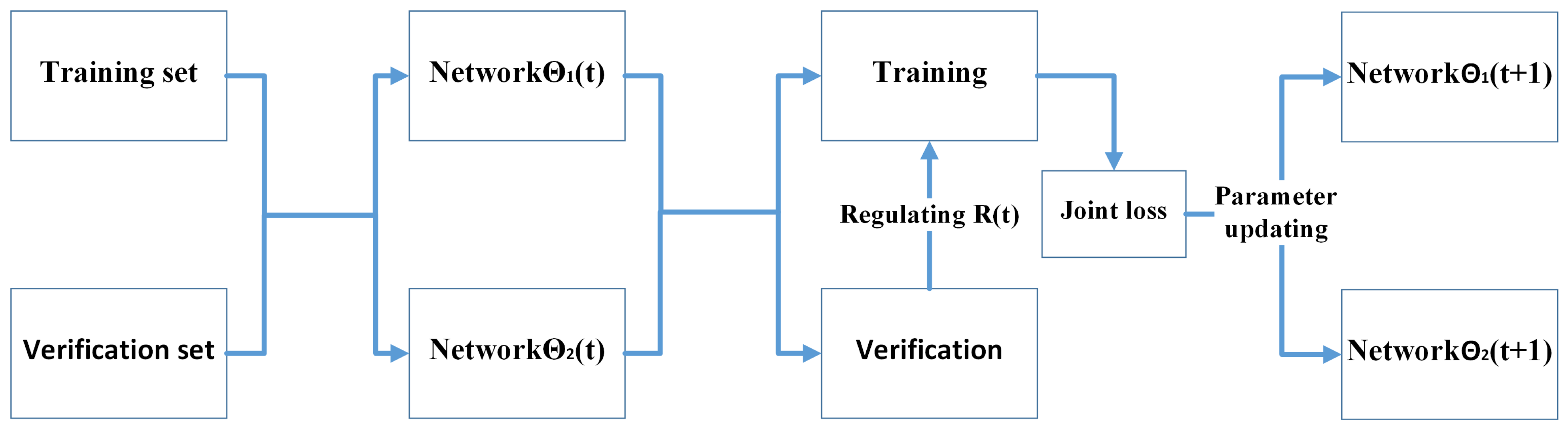
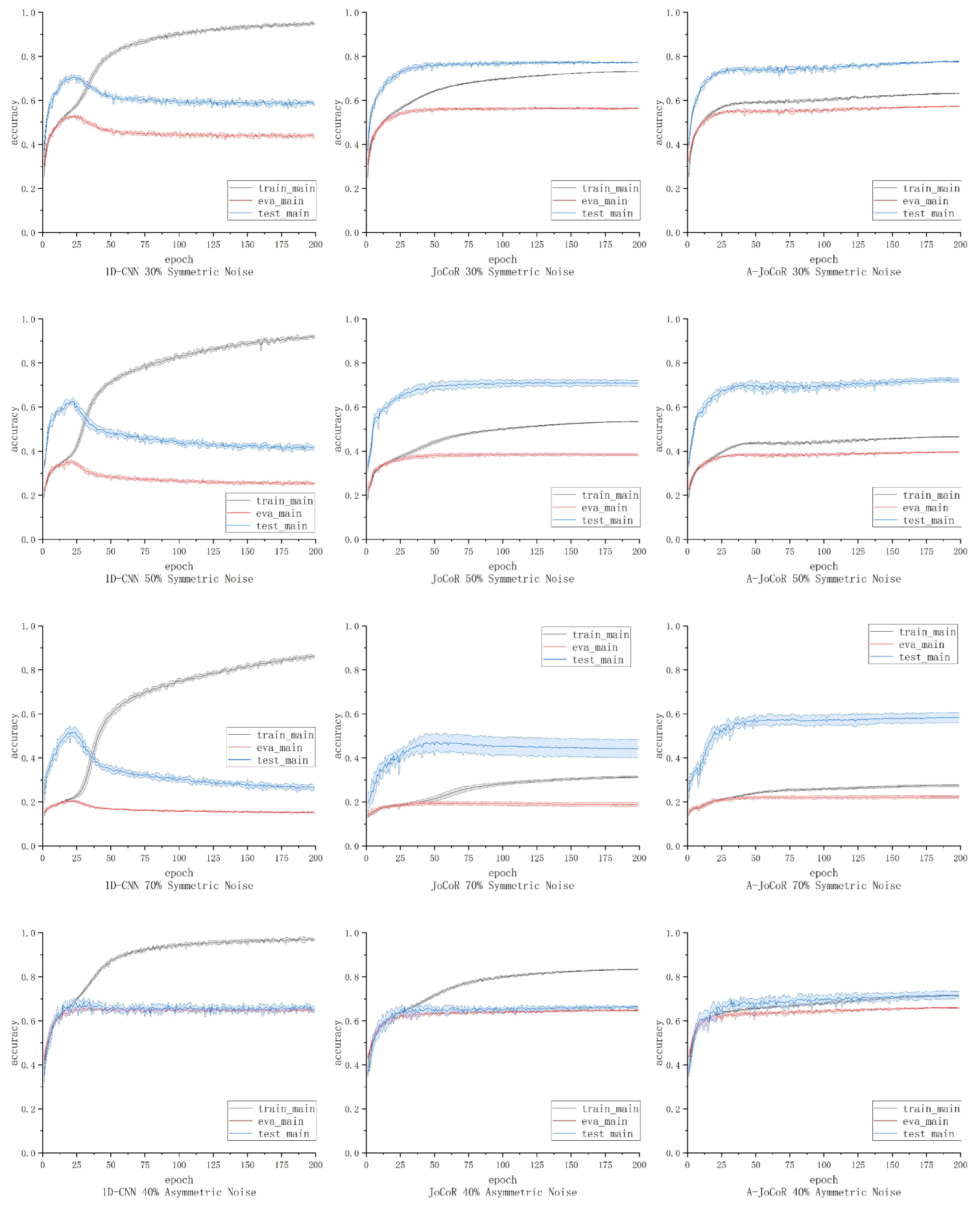
To evaluate the effectiveness of the proposed noise rate adaptive learning mechanism, it was combined with JoCoR to introduce a joint training framework called A-JoCoR. The overall framework structure is illustrated in
Figure 5.
A-JoCoR initially performs different parameter initializations for two equivalent models with the same structure. Then, during the training process, the noise rate adaptive learning mechanism estimates the true noise rate
and assigns the estimated noise rate
to the sample abandonment rate
. Each equivalent model retains a corresponding proportion of small-loss samples based on the
value of each epoch. They calculate their respective supervised loss and contrastive loss, forming a joint loss for simultaneous training. This process enhances their discriminative ability towards clean samples and gradually achieves consistent predictions. The detailed procedure is shown in Algorithm 1.
| Algorithm 1 A-JoCoR |
Input: Network f with , learning rate , training set D, epoch , iteration , initial sample abandonment rate , the estimated noise rate ; for do Shuffle training set D; for do Fetch mini-batch from D; ; ; Calculate the joint loss of and by Equation ( 3); Obtain small-loss sets by from ; Calculate the average loss of by ; Update ; end for Obtain ; Update ; Update ; Update ; end for Output: and |
In the context of multi-class classification involving M classes, we consider a dataset consisting of N samples, where represents the i-th instance and is its corresponding observed label. Following JoCoR, A-JoCoR involves two deep neural networks referred to as and . The prediction probabilities of instance are denoted as and for and , respectively. These probabilities are generated by the "softmax" layer outputs of and .
During the training stage of A-JoCoR, each network has the capability to make predictions independently. However, to enhance the collaboration between the networks, a pseudo-siamese paradigm is employed. In this paradigm, although the parameters of the two networks are distinct, they are updated simultaneously using a joint loss. The loss function
, applied to instance
, is constructed in the following manner:
In the loss function, the first part is conventional supervised learning loss of the two networks, the second part is the contrastive loss between predictions of the two networks for achieving co-regularization.
For multi-class classification, A-JoCoR use cross-entropy loss as the supervised part to minimize the distance between predictions and labels.
where
and
represent the cross-entropy losses of two networks.
Following JoCoR, A-JoCoR incorporates a co-regularization approach by utilizing a contrastive term. This ensures that the two networks guide each other during training. In order to assess the similarity between the predictions of the two networks, A-JoCoR employs the symmetric Kullback–Leibler (KL) divergence.
where
represents the Kullback–Leibler divergence calculation.
represents the KL divergence from distribution
to distribution
, while
represents the KL divergence from distribution
to distribution
. By summing these two divergences, the overall KL divergence is obtained.
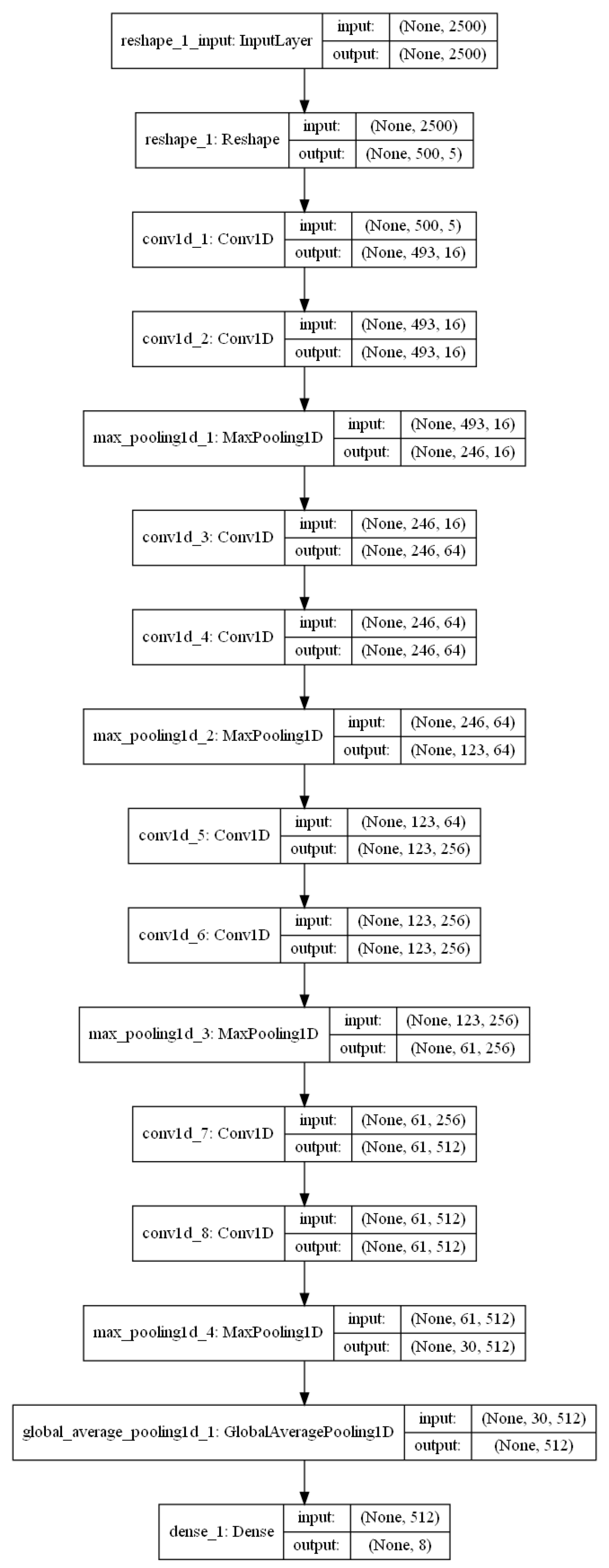
We employ 1D-CNN (1D convolutional neural network) as the network architecture for A-JoCoR, which can be divided into three parts: the input layer, the hidden layers, and the output layer. The input layer of the 1D-CNN transforms the input data into a feature vector
of length 500 with five features. The hidden layers of the 1D-CNN consist of eight 1D convolutional layers with ReLU as the activation function. A 1D max pooling layer follows every two convolutional layers. A basic building block can be formalized as follows:
where
k represents the index of the convolutional layer,
;
and
are the weight vector and bias vector for the
k-th convolutional layer;
represents a 1D max pooling operation;
represents the rectified linear unit activation function applied to the input; ⨂ denotes the convolution operator.
The output layer of the 1D-CNN is composed of a global average pooling layer and a fully connected layer with a softmax activation function, resulting in a probability distribution vector
for the eight ship types. The visualization of the 1D-CNN is shown in
Figure 6.
5. Conclusions
AIS data are susceptible to manipulation by vessel owners, and some illicit vessels may intentionally falsify ship type information to conceal illegal fishing activities, espionage operations, or other unlawful behaviors. Additionally, AIS data itself may suffer from data recording or transmission errors, leading to inconsistencies between reported ship type information and the actual situation. This label noise poses challenges for classification tasks based on ship trajectories and poses a serious threat to maritime security.
To address this issue, we proposed a noise rate adaptive learning mechanism without prior assumptions. We combined this mechanism with JoCoR to design a robust training paradigm called A-JoCoR. This paradigm allows the model to adaptively learn the noise rate of the dataset during training, enabling dynamic adjustment of the selection ratio of small-loss samples.
To evaluate the effectiveness of our proposed method on real ship trajectory datasets, we used AIS data published by the Danish Maritime Authority as the original data. Through preprocessing techniques, we constructed a ship trajectory dataset consisting of eight ship types, with 10,000 samples per class and a total of 80,000 trajectories. Extensive experimental results on this dataset demonstrated the effectiveness of our proposed method for ship trajectory classification with noisy labels. Furthermore, thorough ablation studies clearly show that using the noise rate adaptive learning mechanism leads to better clean sample selection effects.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}