Computational Simulation and Prediction on Electrical Conductivity of Oxide-Based Melts by Big Data Mining


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection and Preprocessing
2.2. Prediction Methods
- Logistic regression (LR) as a generalization of linear regression can be used for predicting binary or multiple-class target variables. Rather than perfecting a point estimate of the event itself, it calculates the probability of a categorical variable (e.g., good/medium/bad) based on a number of input variables [28].
- Decision Tree (DT) is a powerful classification algorithm based on partitioning. In each step, it partitions the data based on one variable until all data in each node have the same category label or all variables have been used. Different partitioning criterions (such as information entropy, information gain ratio, and Gini index) represent different algorithms, such as ID3 [29], C4.5 [30] and Classification and Regression Trees (CART) [31]. In this study we employed CART Decision Tree for modeling.
- Naïve Bayes (NB) applies Bayes’ theorem to calculate a conditional probability distribution over the output of a function to achieve classification. Obviously, this algorithm has an assumption of independence among the predicting variables [32].
- Support Vector machine (SVM) aims to find a hyperplane to optimally separate different categories of data. It assumes that the larger the margin between these parallel hyperplanes, the better the generalization error of the classifier will be [33]. Therefore, finding the maximum-margin hyperplanes from both categories is an optimization problem. In this study, linear kernel function was adopted.
- Artificial Neural Network (ANN) tries to mimic the brain structure to model extremely complex non-linear relationships [34]. It has one input layer, multiple hidden layers, and one output layer. Neurons in the upper layer are connected to neurons in the next layer with different weights. In this study, we used two hidden layers.
- K-Nearest Neighbor (KNN) is different from the algorithms described above as it does not require training of the parameters. Based on a majority vote of its K neighbors, KNN classifies a sample [35]. Therefore, calculating the distance between the samples to select its K nearest neighbors is crucial. In this study, we used the default K value (K = 5) to calculate five nearest neighbors to classify the sample.
- Gradient Boosting Decision Tree (GBDT) belongs to a family of ensemble models. The general idea of boosting trees is to generate a number of simple trees, where each tree is built based on the prediction residuals of the preceding tree [36]. Due to learning from the previous tree, the misclassification can be minimized. On the basis of the traditional boosting tree, the GBDT algorithm employs a gradient descent algorithm to speed up the convergence.
- For the high category: TP2 (True Positive) means a slag whose conductivity value is no less than 10 (Ω·cm)−1 and the model also correctly predicts the slag as high; FP2_j (j = 1 or N) means a slag conductivity is less than 10 (Ω·cm)−1, but the model predicts the slag’s conductivity as high.
- For the medium category: TP1 (True Positive) means a slag whose conductivity value is between 1 (Ω·cm)−1 and 10 (Ω·cm)−1, and the model also correctly predicts the slag as medium; FP1_j (j = 2 or N) means a slag’s conductivity does not belong to the medium category, but the model misclassifies it as medium.
- For the low category: TN (True Negative) denotes a slag whose conductivity value is actually less than 1 (Ω·cm)−1 and the model also correctly predicts the slag as low; FNi (i = 1 or 2) denotes a slag with conductivity greater than 1 (Ω·cm)−1, but the model incorrectly predicts the slag’s conductivity as low.
2.3. Model Robustness
2.4. The Identification of Significant Factors
3. Results
3.1. Selecting the Best Model for Predicting Conductivity
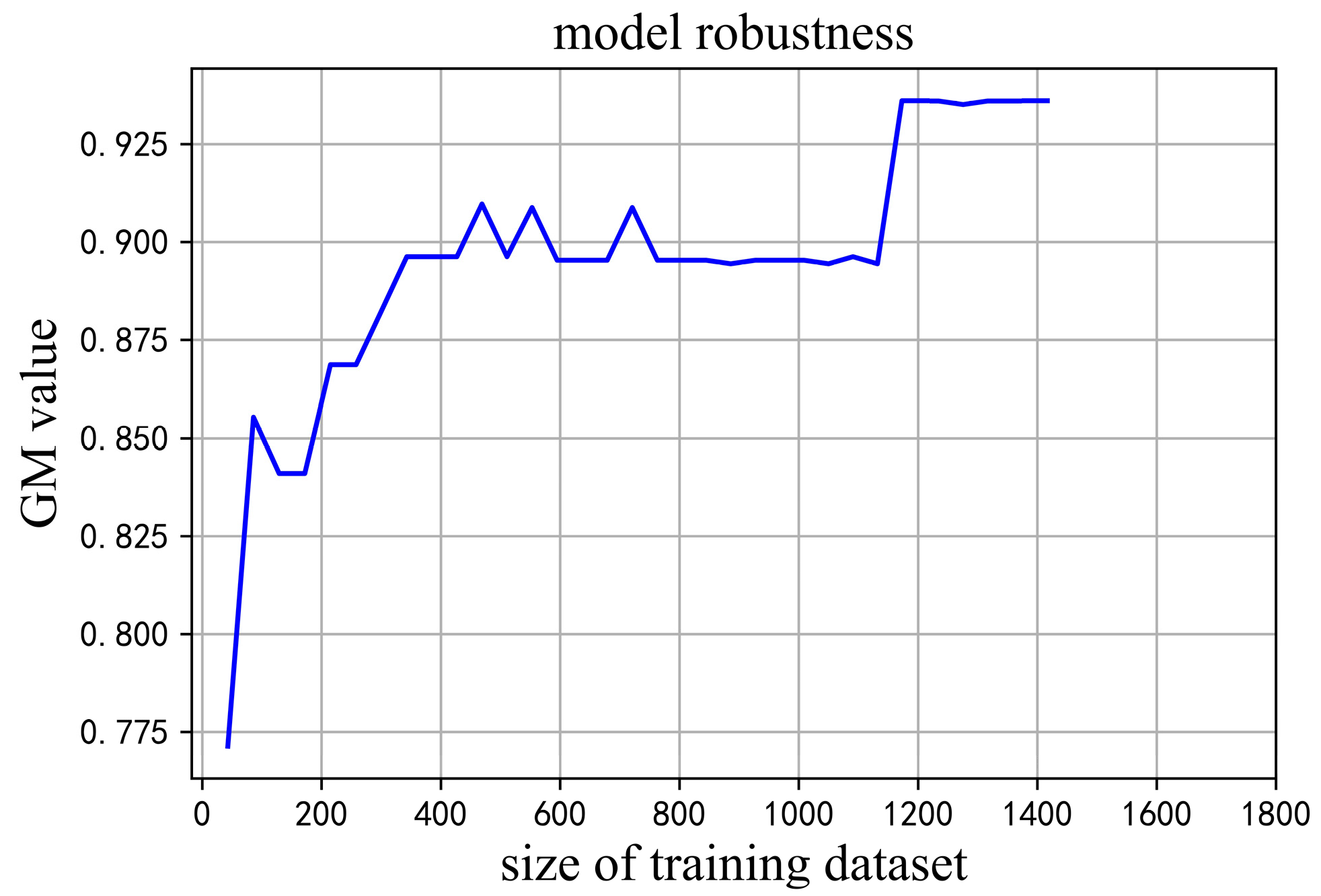
3.2. Investigating the Robustness of the Best Prediction Model
3.3. Finding the Most Significant Factors
- *Rule 1-1: SiO2 ≤ 31.9% (0/1/2:0.33/0.5/0.17)
- Rule 1-2: SiO2 > 31.9% (0/1/2:0.9/0.1/0)
- Rule 2-1: 1-1 + TiO2 ≤ 74.16% (0/1/2:0.37/0.55/0.08)
- *Rule 2-2: 1-1 + TiO2 > 74.16% (0/1/2:0/0/1)
- Rule 2-3: 1-2 + TiO2 ≤ 24.57% (0/1/2:0.99/0.01/0)
- *Rule 2-4: 1-2 + TiO2 > 24.57% (0/1/2:0.21/0.79/0)
- *Rule 3-1: 1-1 + 2-1 + CaO ≤ 27.7% (0/1/2:0.18/0.7/0.12)
- Rule 3-2: 1-1 + 2-1 + CaO > 27.7% (0/1/2:0.71/0.29/0)
- Rule 3-3: 1-2 + 2-3 + CaO ≤ 26.8% (0/1/2:0.91/0.09/0)
- Rule 3-4: 1-2 + 2-3 + CaO > 26.8% (0/1/2:1/0/0)
- Rule 3-5: 1-2 + 2-4 + Temperature ≤ 1000 °C (0/1/2:1/0/0)
- *Rule 3-6: 1-2 + 2-4 + Temperature > 1000 °C (0/1/2:0.11/0.89/0)
- *Rule 4-1: 1-1 + 2-1 + 3-1 + FeO ≤ 74.7% (0/1/2:0.2/0.75/0.05)
- *Rule 4-2: 1-1 + 2-1 + 3-1 + FeO > 74.7% (0/1/2:0/0.17/0.83)
- *Rule 4-3: 1-1 + 2-1 + 3-2 + Temperature ≤ 1337.5 °C (0/1/2:0.71/0.29/0)
- *Rule 4-4: 1-1 + 2-1 + 3-2 + Temperature > 1337.5 °C (0/1/2:0.08/0.87/0.05)
- Rule 4-5: 1-2 + 2-3 + 3-3 + Na2O ≤ 27.5% (0/1/2:0.94/0.06/0)
- *Rule 4-6: 1-2 + 2-3 + 3-3 + Na2O > 27.5% (0/1/2:0/1/0)
- *Rule 4-7: 1-2 + 2-4 + 3-6 + Temperature ≤ 1177.5 °C (0/1/2:0.02/0.98/0)
- Rule 4-8: 1-2 + 2-4 + 3-6 + Temperature > 1177.5 °C (0/1/2:0.86/0.14/0)
4. Discussion
4.1. The Importance of High Sensitivity and Gm Values
4.2. The Size Range for Training a Reliable Prediction Model for Conductivity
4.3. The Significant Factors for Predicting Conductivity
- The content of CaO is less than 50%;
- The temperature range is mainly concentrated at 1300–1500 °C;
- The original composition of the slag system is mainly composed of Al2O3 and SiO2 in addition to CaO.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ogino, K.; Hashimoto, H.; Hara, S. Measurement of the electrical conductivity of ESR containing fluoride by four electrodes method with alternating current. Tetsu-To-Hagane 1978, 64, 225–231. [Google Scholar] [CrossRef]
- Liu, J.H.; Zhang, G.H.; Wu, Y.D.; Chou, K.C. Electrical Conductivity and Electronic/Ionic Properties of TiOx-CaO-SiO2 Slags at Various Oxygen Potentials and Temperatures. Metall. Mater. Trans. B 2015, 47, 798–803. [Google Scholar] [CrossRef]
- Liu, J.H.; Zhang, G.H.; Wang, Z. Experimental study on electrical conductivity of MnO-CaO-SiO2 slags at 1723 K to 1823 K (1450 °C to 1550 °C) and various oxygen potentials. Metall. Mater. Trans. B. 2017, 1–5. [Google Scholar] [CrossRef]
- Sun, C.Y.; Guo, X.M. Electrical conductivity of MO(MO=FeO, NiO)-containing Cao-MgO-SiO2-Al2O3 slag with low basicity. Trans. Nonferrous Metall. Soc. 2011, 21, 1654. [Google Scholar] [CrossRef]
- Provost, F.; Fawcett, T. Data Science and its Relationship to Big Data and Data-Driven Decision Making. Big Data 2013, 1, 51–59. [Google Scholar] [CrossRef]
- Joseph, R.C.; Johnson, N.A. Big Data and Transformational Government. IT Prof. 2013, 15, 43–48. [Google Scholar] [CrossRef]
- Wang, G.; Gunasekaran, A.; Ngai, E.W.T.; Papadopoulos, T. Big data analytics in logistics and supply chain management: Certain investigations for research and applications. Int. J. Prod. Econ. 2016, 176, 98–110. [Google Scholar] [CrossRef] [Green Version]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: Promise and potential. Health Inf. Sci. Syst. 2014, 2, 3–12. [Google Scholar] [CrossRef]
- Schildkamp, K.; Lai, M.K.; Earl, L. Data-based Decision Making in Education. Stud. Educ. Leadersh. 2013, 17, 205–224. [Google Scholar] [CrossRef]
- O’Donovan, P.; Leahy, K.; Bruton, K.; O’Sullivan, D.T.J. An industrial big data pipeline for data-driven analytics maintenance applications in large-scale smart manufacturing facilities. J. Big Data 2015, 2, 1–26. [Google Scholar] [CrossRef]
- Chen, M.S.; Han, J.; Yu, P.S. Data mining: An overview from a database perspective. IEEE Trans. Knowl. Data Eng. 1996, 8, 866–883. [Google Scholar] [CrossRef]
- Jiao, Q.; Themelis, N.J. Correlations of electrical conductivity to slag composition and temperature. Metall. Trans. B 1988, 19, 133–140. [Google Scholar] [CrossRef]
- Zhang, G.H.; Chou, K.C. A new model for evaluating the electrical conductivity of nonferrous slag. Int. J. Min. Met. Mater. 2009, 16, 500–504. [Google Scholar] [CrossRef]
- Eisenhüttenleute, V.D. Slag Atlas, 2nd ed.; Verlag Stahleisen Gmbh: Düsseldorf, Germany, 1995; pp. 557–588. [Google Scholar]
- Dou, Z.H.; ZHANG, T.A.; Yao, J.M.; Jiang, X.L.; Niu, L.P.; He, J.C. Research on Properties of Al2O3−CaO Slag. Chin. J. Process Eng. 2009, 9, 246–249. [Google Scholar] [CrossRef]
- Wu, X.R.; Ma, B.; Lv, H.H.; Li, L.S. Research on Electrical Conductivity of Stainless Steel Slag Containing Cr2O3. J. Anhui Univ. Technol. 2016, 33, 5–9. [Google Scholar] [CrossRef]
- Dai, X.; Zhang, C.F. Electrical Conductivity Measurement of FeO-MgO-CaO-SiO2 Slag. Nonferrous Met. 2005, 4, 2–4. [Google Scholar] [CrossRef]
- Lv, R.X.; Hu, X.J.; Wang, L.J.; Zhou, G.Z. Measure on conductivity of CaO-SiO2-A12O3-MgO-FeOx SLAGS. Forum Metall. Eng. Sci. 2003, 252–255. [Google Scholar] [CrossRef]
- Zhang, G.H.; Zhen, W.W.; Jiao, S.Q.; Chou, K.C. Influences of Na2O and K2O Additions on Electrical Conductivity of CaO-SiO2-(Al2O3) Melts. ISIJ Int. 2017, 57. [Google Scholar] [CrossRef]
- Zhang, G.H.; Xue, Q.G.; Li, L.F.; Li, F.S.; Chou, K.C. Studies on the electrical conductivities and diffusion coefficients of ions in CaO-Al2O3-SiO2 melt. J. Univ. Sci. Technol. Beijing 2012, 34, 1250–1255. [Google Scholar] [CrossRef]
- Zhang, G.H.; Zheng, W.W.; Chou, K.C. Influences of Na2O and K2O Additions on Electrical Conductivity of CaO-MgO-Al2O3-SiO2 Melts. Metall. Mater. Trans. B 2017, 48, 1134–1138. [Google Scholar] [CrossRef]
- Liu, Y.X.; Liu, J.H.; Zhang, G.H.; Zhang, J.L.; CHOU, K.C. Experimental Study on Electrical Conductivity of FexO-CaO-SiO2-Al2O3 System at Various Oxygen Potentials. High Temp. Mater. Process. 2018, 37, 121–125. [Google Scholar] [CrossRef]
- Ju, J.T.; Lv, Z.L.; Jiao, Z.Y.; Zhao, J.X. Experimental Study on Electrical Conductivity of CaF2-SiO2-Al2O3-CaO-MgO Slags System. J. Iron Steel Res. 2012, 24, 27–31. [Google Scholar] [CrossRef]
- Dou, Z.H.; ZHANG, T.A.; Yao, J.M.; Niu, L.P.; Jiang, X.L.; He, J.C. Research on Properties of CaF2-CaO-Al2O3-MgO-SiO2 Refining Slag. Chin. J. Process Eng. 2009, 9, 132–136. [Google Scholar] [CrossRef]
- Chen, J.X. Data Sheet for Steel-Making; Metallurgical Industry Press: Beijing, China, 2010; pp. 299–303. [Google Scholar]
- Wang, S.L.; Li, G.Q.; Sui, Z.T. Variation of conductivity and crystallization of perovskite (CaTiO3) during the cooling process of ti-bearing blast furnace slag. Acta Met. Lurgica Sin. 1999, 35, 499–502. [Google Scholar] [CrossRef]
- Li, S.P. Study on Electrical Conductivity and Structure of High Titania Slag; Chongqing University: Chongqing, China, 2017. [Google Scholar]
- Khutner, M.; Nachtsheim, C.J.; Neter, J.; Li, W. Applied Linear Statistical Models; McGraw-Hill/Irwin: Chicago, IL, USA, 2004. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: San Mateo, CA, USA, 1993. [Google Scholar]
- Loh, W.Y. Classification and regression trees. Wires Data Min. Knowl. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian Network Classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Basheer, I. Artificial Neural Networks: Fundamentals, Computing, Design, and Application. J. Microbiol. Meth. 2000, 43, 3–31. [Google Scholar] [CrossRef]
- Hwang, W.J.; Wen, K.W. Fast KNN classification algorithm based on partial distance search. Electron. Lett. 1998, 34, 2062–2063. [Google Scholar] [CrossRef]
- Son, J.; Jung, I.; Park, K.; Han, B. Tracking-by-Segmentation with Online Gradient Boosting Decision Tree. In Proceedings of the IEEE International Conference on Computer Vision (CVPR2016), Las Vegas, NV, USA, 26 June–1 July 2006; pp. 3056–3064. [Google Scholar] [CrossRef]
- Ting, K.M. Confusion Matrix. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2017; p. 206. [Google Scholar] [CrossRef]
- Aalst, W.M.P.; Rubin, V.; Verbeek, H.M.W.; Dongen, B.F.; Kindler, E.; Gunther, C.W. Process mining: A two-step approach to balance between underfitting and overfitting. Softw. Syst. Model. 2010, 9, 87–111. [Google Scholar] [CrossRef]
- Surrogate Model. Available online: https://en.wikipedia.org/wiki/Surrogate_model (accessed on 8 November 2018).
- Patterson, G.; Zhang, M. Fitness Functions in Genetic Programming for Classification with Unbalanced Data. Adv. Artif. Intell. Lect. Notes Comput. Sci. 2007, 4830, 769–775. [Google Scholar] [CrossRef]
- MárquezVera, C.; Cano, A.; Romero, C.; Fardoun, H.M. Early dropout prediction using data mining: A case study with high school students. Expert Syst. J. Knowl. Eng. 2016, 33, 107–124. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 9–11 June 2000; pp. 1–15. [Google Scholar] [CrossRef]
- Zorarpacı, E.; Özel, S.A. A hybrid approach of differential evolution and artificial bee colony for feature selection. Expert. Syst. Appl. 2016, 62, 91–103. [Google Scholar] [CrossRef]
- Tranell, G.; Ostrovski, O.; Jahanshahi, S. The equilibrium partitioning of titanium between Ti3+ and Ti4+ valency states in CaO-SiO2-TiOx slags. Metall. Mater. Trans. A 2002, 33, 61–67. [Google Scholar] [CrossRef]
- Barati, M.; Coley, K.S. Electrical and electronic conductivity of CaO-SiO2-FeOx slags at various oxygen potentials: Part ii. mechanism and a model of electronic conduction. Metall. Mater. Trans. B 2006, 37, 51–60. [Google Scholar] [CrossRef]
- Bale, C.W.; Chartrand, P.; Degterov, S.A.; Eriksson, G.; Hack, K.; Mahfoud, R.B.; Melançon, J.; Pelton, A.D.; Petersen, S. FactSage thermochemical software and databases, 2010–2016. Calphad 2016, 54, 35–53. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Attribute | Description | Extent |
|---|---|---|---|
| FeO | Numeric | FeO mass fraction in slag | 0–100% |
| Al2O3 | Numeric | Al2O3 mass fraction in slag | 0–100% |
| CaF2 | Numeric | CaF2 mass fraction in slag | 0–100% |
| Fe2O3 | Numeric | Fe2O3 mass fraction in slag | 0–100% |
| SiO2 | Numeric | SiO2 mass fraction in slag | 0–100% |
| CaO | Numeric | CaO mass fraction in slag | 0–100% |
| MgO | Numeric | MgO mass fraction in slag | 0–100% |
| SrO2 | Numeric | SrO2 mass fraction in slag | 0–44% |
| TiO2 | Numeric | TiO2 mass fraction in slag | 0–90% |
| K2O | Numeric | K2O mass fraction in slag | 0–45% |
| MnO | Numeric | MnO mass fraction in slag | 0–74% |
| Na2O | Numeric | Na2O mass fraction in slag | 0–50% |
| ZrO2 | Numeric | ZrO2 mass fraction in slag | 0–24% |
| Cr2O3 | Numeric | Cr2O3 mass fraction in slag | 0–10% |
| Temperature | Numeric | Temperature of slag | 300–2800 °C |
| Conductivity | Categorical | Slag’s conductivity value | 0.00037–335.3 (Ω·cm)−1 |
| Total Samples | Predicted Category | |||
|---|---|---|---|---|
| High (P2) | Medium (P1) | Low (N) | ||
| Actual category | High (P2) | TP2 | FP1_2 | FN2 |
| Medium (P1) | FP2_1 | TP1 | FN1 | |
| Low (N) | FP2_N | FP1_N | TN | |
| Methods | LR | DT | NB | SVM | ANN | KNN | GBDT |
|---|---|---|---|---|---|---|---|
| Accuracy | 0.80 | 0.88 | 0.28 | 0.84 | 0.88 | 0.86 | 0.90 |
| Sensitivity1 | 0.61 | 0.82 | 0.43 | 0.77 | 0.90 | 0.84 | 0.88 |
| Sensitivity2 | 0.85 | 0.85 | 0.93 | 0.86 | 0.84 | 0.84 | 0.89 |
| Specificity | 0.89 | 0.91 | 0.14 | 0.87 | 0.88 | 0.88 | 0.91 |
| GM | 0.66 | 0.79 | 0.21 | 0.74 | 0.80 | 0.78 | 0.84 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, A.; Huo, Y.; Yang, J.; Li, G. Computational Simulation and Prediction on Electrical Conductivity of Oxide-Based Melts by Big Data Mining. Materials 2019, 12, 1059. https://doi.org/10.3390/ma12071059
Huang A, Huo Y, Yang J, Li G. Computational Simulation and Prediction on Electrical Conductivity of Oxide-Based Melts by Big Data Mining. Materials. 2019; 12(7):1059. https://doi.org/10.3390/ma12071059
Chicago/Turabian StyleHuang, Ao, Yanzhu Huo, Juan Yang, and Guangqiang Li. 2019. "Computational Simulation and Prediction on Electrical Conductivity of Oxide-Based Melts by Big Data Mining" Materials 12, no. 7: 1059. https://doi.org/10.3390/ma12071059
APA StyleHuang, A., Huo, Y., Yang, J., & Li, G. (2019). Computational Simulation and Prediction on Electrical Conductivity of Oxide-Based Melts by Big Data Mining. Materials, 12(7), 1059. https://doi.org/10.3390/ma12071059