
The Application of Convolutional Neural Networks (CNNs) to Recognize Defects in 3D-Printed Parts


Abstract
:1. Introduction
2. Materials and Methods
2.1. The Structure of Different Models
2.2. Image Data Preparations
2.3. Training Process for Different Models
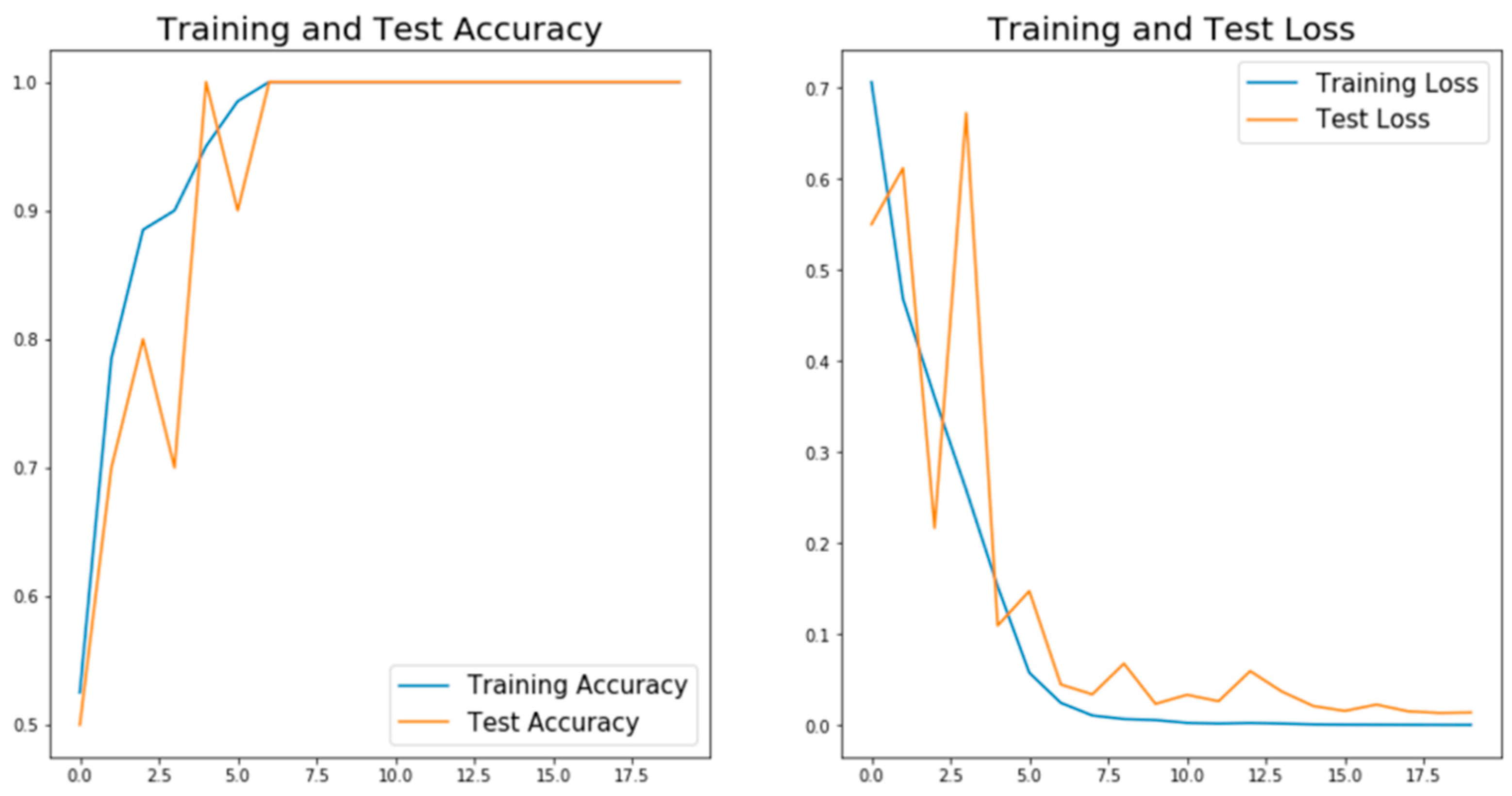
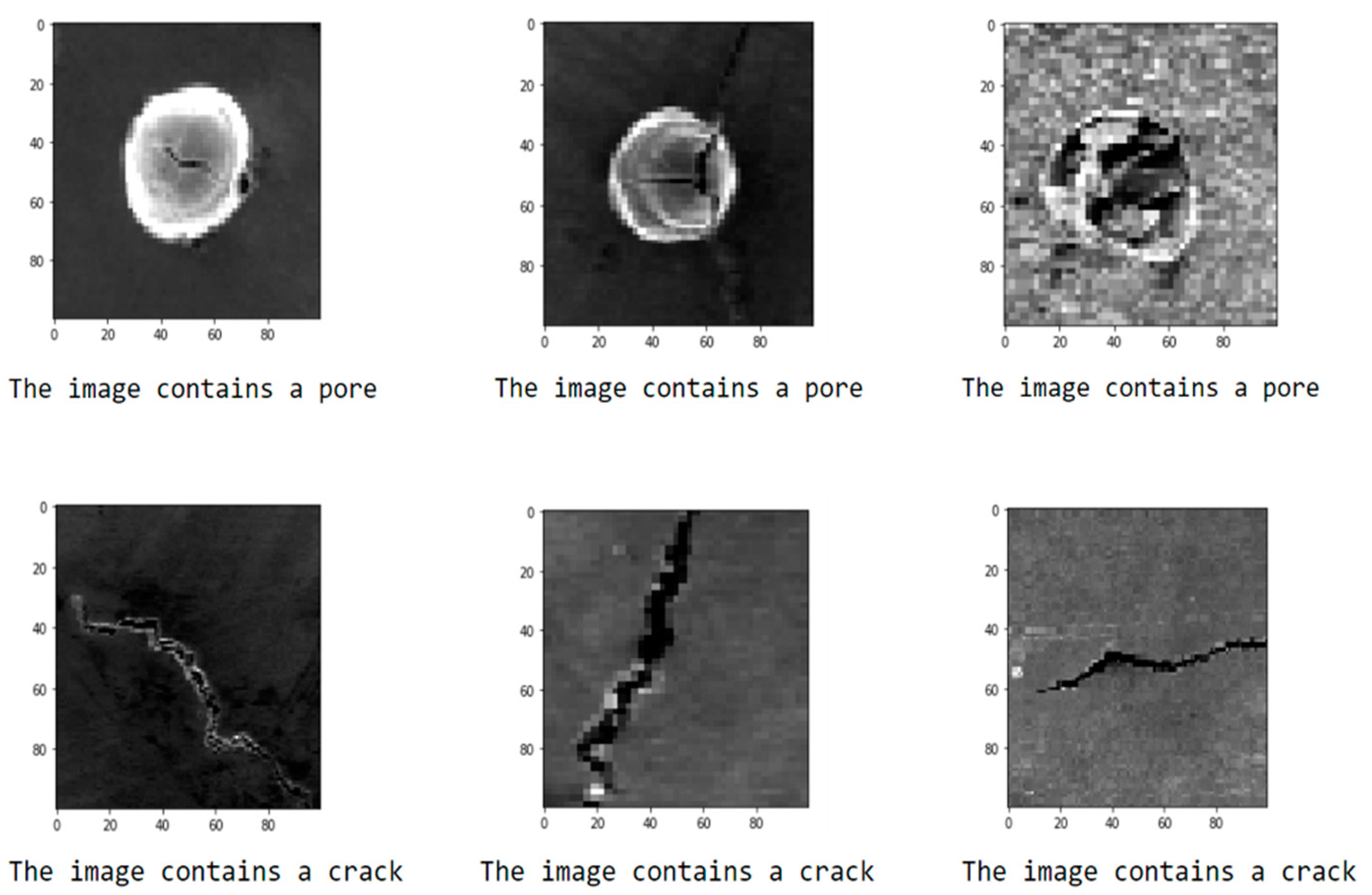
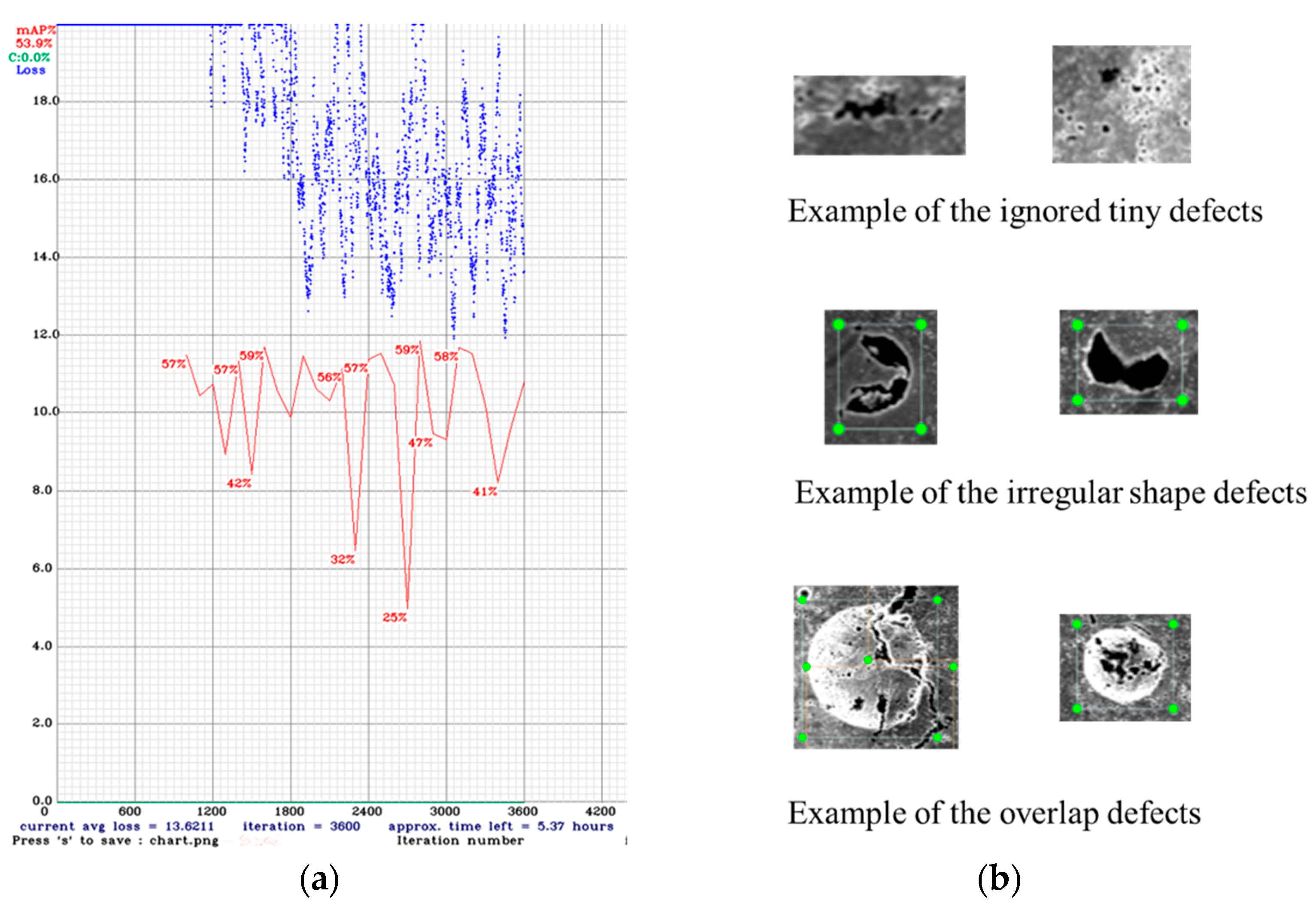
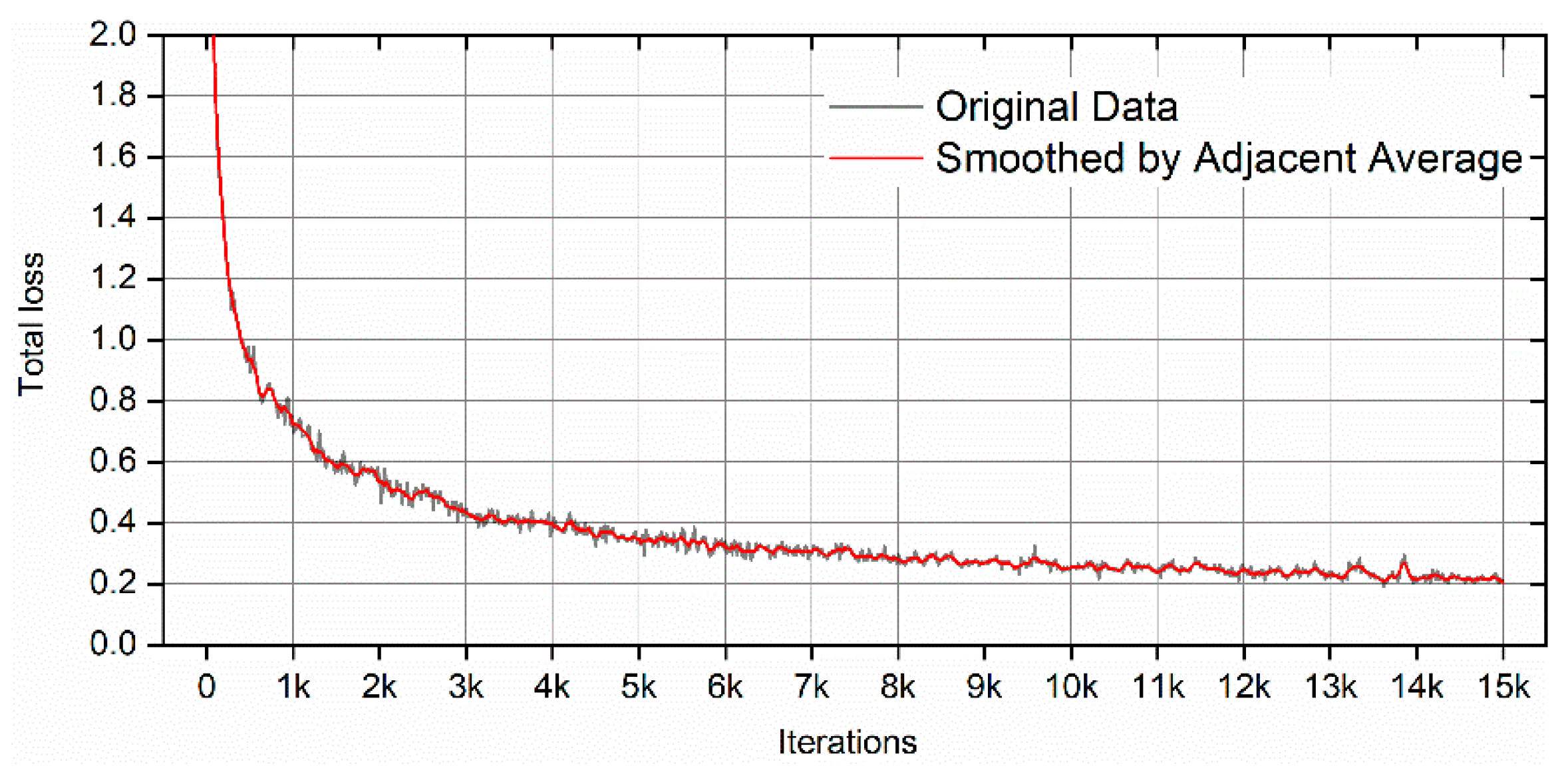
3. Results and Discussion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, F.; Deng, P.; Wan, J.; Zhang, D.; Vasilakos, A.V.; Rong, X. Data mining for the internet of things: Literature review and challenges. Int. J. Distrib. Sens. Netw. 2015, 11. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Jiang, Q.; Zhou, B.; Chen, D. Convolutional neural networks for computer-aided detection or diagnosis in medical image analysis: An overview. Math. Biosci. Eng. 2019, 16, 6536–6561. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- In, H.P.; Kim, Y.-G.; Lee, T.; Moon, C.-J.; Jung, Y.; Kim, I. A security risk analysis model for information systems. LNAI 2004, 3398, 505–513. [Google Scholar]
- Wei, J.; Chu, X.; Sun, X.; Xu, K.; Deng, H.; Chen, J.; Wei, Z.; Lei, M. Machine learning in materials science. InfoMat 2019, 1, 338–358. [Google Scholar] [CrossRef]
- Schütt, K.T.; Arbabzadah, F.; Chmiela, S.; Müller, K.R.; Tkatchenko, A. Quantum-chemical insights from deep tensor neural networks. Nat. Commun. 2017, 8, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schütt, K.T.; Sauceda, H.E.; Kindermans, P.-J.; Tkatchenko, A.; Müller, K.-R. SchNet—A deep learning architecture for molecules and materials. J. Chem. Phys. 2017. [Google Scholar] [CrossRef] [PubMed]
- Cecen, A.; Dai, H.; Yabansu, Y.C.; Kalidindi, S.R.; Song, L. Material structure-property linkages using three-dimensional convolutional neural networks. Acta Mater. 2018, 146, 76–84. [Google Scholar] [CrossRef]
- Jha, D.; Ward, L.; Paul, A.; Liao, W.; Keng Choudhary, A.; Wolverton, C.; Agrawal, A. ElemNet: Deep learning the chemistry of materials from only elemental composition. Sci. Rep. 2018, 8, 1–13. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow, 1st ed.; O’reilly: Sebastopol, CA, USA, 2017. [Google Scholar]
- Francis, J.; Bian, L. Deep learning for distortion prediction in laser-based additive manufacturing using big data. Manuf. Lett. 2019, 20, 10–14. [Google Scholar] [CrossRef]
- Saha, S. A Comprehensive Guide to Convolutional Neural Networks. 2018. Available online: https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53 (accessed on 30 March 2021).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767, ISSN: 23318422, 2018. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2: A PyTorch-Based Modular Object Detection Library. 2019. Available online: https://ai.facebook.com/blog/-detectron2-a-pytorch-based-modular-object-detection-library-/ (accessed on 28 January 2021).
- Wu, Y.; Kirillov, A.; Massa, F.; Yen, W.; Lo, R.G. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 14 January 2021).
- Ross, G.; Ilija, R.; Georgia, G.; Piotr Doll, K.H. Detectron. 2018. Available online: https://github.com/facebookresearch/Detectron (accessed on 14 January 2021).
- Khosravani, M.R.; Reinicke, T. On the use of X-ray computed tomography in assessment of 3D-printed components. J. Nondestruct. Eval. 2020, 39, 1–17. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.-H.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNET: A new backbone that can enhence learning capability of C.N.N. arXiv 2019, arXiv:1911.11929v1. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. arXiv 2015, arXiv:1406.4729v4. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. arXiv 2018, arXiv:1803.01534v4. [Google Scholar]
- Rugery, P. Explanation of YOLO V4 a One Stage Detector. Available online: https://becominghuman.ai/explaining-yolov4-a-one-stage-detector-cdac0826cbd7 (accessed on 28 January 2021).
- Solawetz, J. Breaking down YOLOv4. 2020. Available online: https://blog.roboflow.com/a-thorough-breakdown-of-yolov4/ (accessed on 28 January 2021).
- Honda, H. Digging into Detectron 2—Part 1-5. Available online: https://medium.com/@hirotoschwert/digging-into-detectron-2-part-5-6e220d762f9 (accessed on 29 January 2021).
- Pham, V.; Pham, C.; Dang, T. Road Damage Detection and Classification with Detectron2 and Faster R-CNN. arXiv 2020, arXiv:2010.15021. [Google Scholar]
- Lin, T. LabelImg. 2017. Available online: https://github.com/tzutalin/labelImg (accessed on 13 January 2021).
- Wada, K. Labelme: Image Polygonal Annotation with Python. 2016. Available online: https://github.com/wkentaro/labelme (accessed on 13 January 2021).
- Available online: https://colab.research.google.com/notebooks/intro.ipynb#scrollTo=5fCEDCU_qrC0 (accessed on 26 January 2021).
- Bochkovskiy, A. Darknet. Github. 2020. Available online: https://github.com/AlexeyAB/darknet (accessed on 26 January 2021).
- YOLOv4 Training Tutorial. Available online: https://colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing (accessed on 26 January 2021).
- Francesc Munoz-Martin, J.; Ying, X. An overview of overfitting and its solutions. J. Phys. Conf. Ser. 2019, 1168. [Google Scholar] [CrossRef]
- Tai, S.-K.; Dewi, C.; Chen, R.-C.; Liu, Y.-T.; Jiang, X.; Yu, H. Deep learning for traffic sign recognition based on spatial pyramid pooling with scale analysis. Appl. Sci. 2020, 10, 6997. [Google Scholar] [CrossRef]
- Lawal, M.O. Tomato Detection Based on Modified YOLOv3 Framework. Sci. Rep. 2021, 11, 1447. [Google Scholar] [CrossRef]
- Jing, J.; Zhuo, D.; Zhang, H.; Liang, Y.; Zheng, M. Fabric defect detection using the improved YOLOv3 model. J. Eng. Fiber. Fabr. 2020, 15, 155892502090826. [Google Scholar] [CrossRef] [Green Version]
- Evaluating Performance of an Object Detection Model|by Renu Khandelwal|Towards Data Science. Available online: https://towardsdatascience.com/evaluating-performance-of-an-object-detection-model-137a349c517b (accessed on 28 February 2021).
- Detectron2/MODEL_ZOO.Md at Master Facebookresearch/Detectron2. Available online: https://github.com/facebookresearch/detectron2/blob/master/ (accessed on 27 February 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model.Summary() | ||
|---|---|---|
| Model: “Sequential_3” | ||
| Layer (type) | Output Shape | Param # |
| conv2d (Conv2D) | (None, 100, 100, 16) | 160 |
| max_pooling2d (MaxPooling2D) | (None, 50, 50, 16) | 0 |
| conv2d_1 (Conv2D) | (None, 50, 50, 32) | 4640 |
| max_pooling2d_1 (MaxPooling2D) | (None, 25, 25, 32) | 0 |
| conv2d_2 (Conv2D) | (None, 25, 25, 64) | 18,496 |
| max_pooling2d_2 (MaxPooling2D) | (None, 12, 12, 64) | 0 |
| flatten (Flatten) | (None, 9216) | 0 |
| dense(Dense) | (None, 512) | 4,719,104 |
| dense_1 (Dense) | (None, 1) | 513 |
| Total params: 4,742,913 | ||
| Trainable params: 4,742,913 | ||
| Non-trainable params: 0 | ||
| No. | LR | Scales | AP | Recall | TP | FP | FN | Average IoU |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.001 | 0.1, 0.1 | 77% | 0.35 | 150 | 46 | 274 | 54.16% |
| 2 | 0.2, 0.2 | 79% | 0.49 | 208 | 56 | 216 | 54.44% | |
| 3 | 0.3, 0.3 | 75% | 0.49 | 207 | 69 | 217 | 52.19% | |
| 4 | 0.0005 | 0.1, 0.1 | 79% | 0.47 | 199 | 52 | 225 | 56.34% |
| 5 | 0.2, 0.2 | 73% | 0.48 | 205 | 77 | 219 | 49.48% | |
| 6 | 0.3, 0.3 | 80% | 0.5 | 210 | 51 | 214 | 57.19% |
| No. | Model | Iterations | mAP | AP50 | AP75 | AR10 | AR100 | AR1000 |
|---|---|---|---|---|---|---|---|---|
| 1 | X101-FPN 3x | 5000 | 0.174 | 0.383 | 0.141 | 0.055 | 0.214 | 0.214 |
| 10,000 | 0.172 | 0.393 | 0.122 | 0.054 | 0.211 | 0.211 | ||
| 2 | R50-FPN 3x | 5000 | 0.23 | 0.505 | 0.164 | 0.058 | 0.26 | 0.283 |
| 10,000 | 0.231 | 0.524 | 0.17 | 0.054 | 0.272 | 0.288 | ||
| 3 | R101-DC5 3x | 5000 | 0.237 | 0.59 | 0.133 | 0.045 | 0.27 | 0.324 |
| 10,000 | 0.237 | 0.569 | 0.155 | 0.042 | 0.271 | 0.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, H.; Huang, C.; Guo, S. The Application of Convolutional Neural Networks (CNNs) to Recognize Defects in 3D-Printed Parts. Materials 2021, 14, 2575. https://doi.org/10.3390/ma14102575
Wen H, Huang C, Guo S. The Application of Convolutional Neural Networks (CNNs) to Recognize Defects in 3D-Printed Parts. Materials. 2021; 14(10):2575. https://doi.org/10.3390/ma14102575
Chicago/Turabian StyleWen, Hao, Chang Huang, and Shengmin Guo. 2021. "The Application of Convolutional Neural Networks (CNNs) to Recognize Defects in 3D-Printed Parts" Materials 14, no. 10: 2575. https://doi.org/10.3390/ma14102575
APA StyleWen, H., Huang, C., & Guo, S. (2021). The Application of Convolutional Neural Networks (CNNs) to Recognize Defects in 3D-Printed Parts. Materials, 14(10), 2575. https://doi.org/10.3390/ma14102575