
Reframing Demand Forecasting: A Two-Fold Approach for Lumpy and Intermittent Demand



Abstract
:1. Introduction
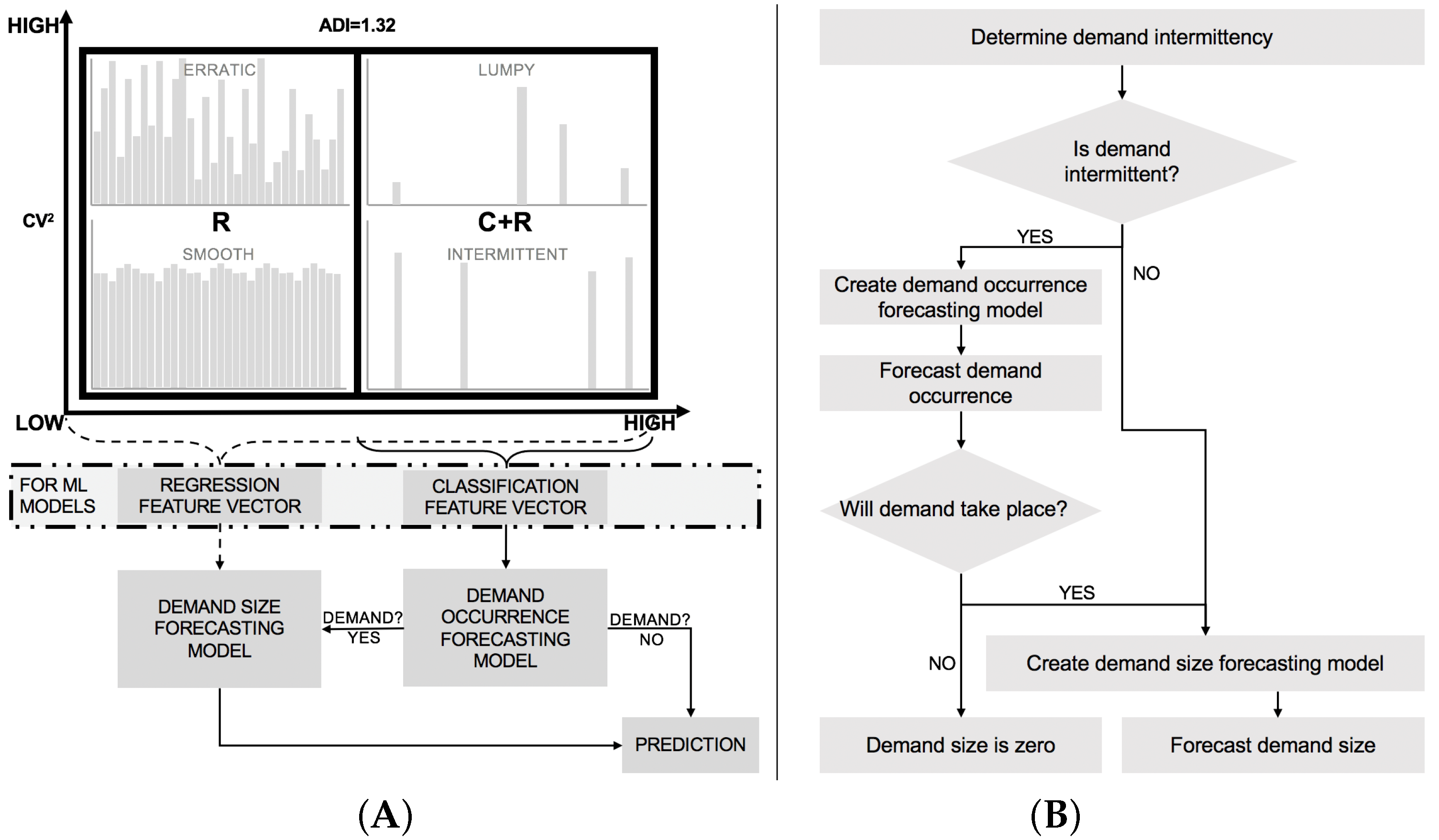
- Decoupling the demand forecasting problem into two separate problems: classification (demand occurrence) and regression (demand quantity estimation);
- Using four measurements to assess demand forecast performance: (i) the area under the receiver operating characteristic curve (AUC ROC) (Bradley [23]) to assess demand occurrence, (ii) two variations of the mean absolute scaled error (MASE) (Hyndman et al. [24]) to assess demand quantity forecasts, and (iii) stock-keeping-oriented prediction error cost (SPEC), proposed by Martin et al. [25] as an inventory metric;
- A new demand classification schema based on the existing literature and our research findings.
2. Related Work
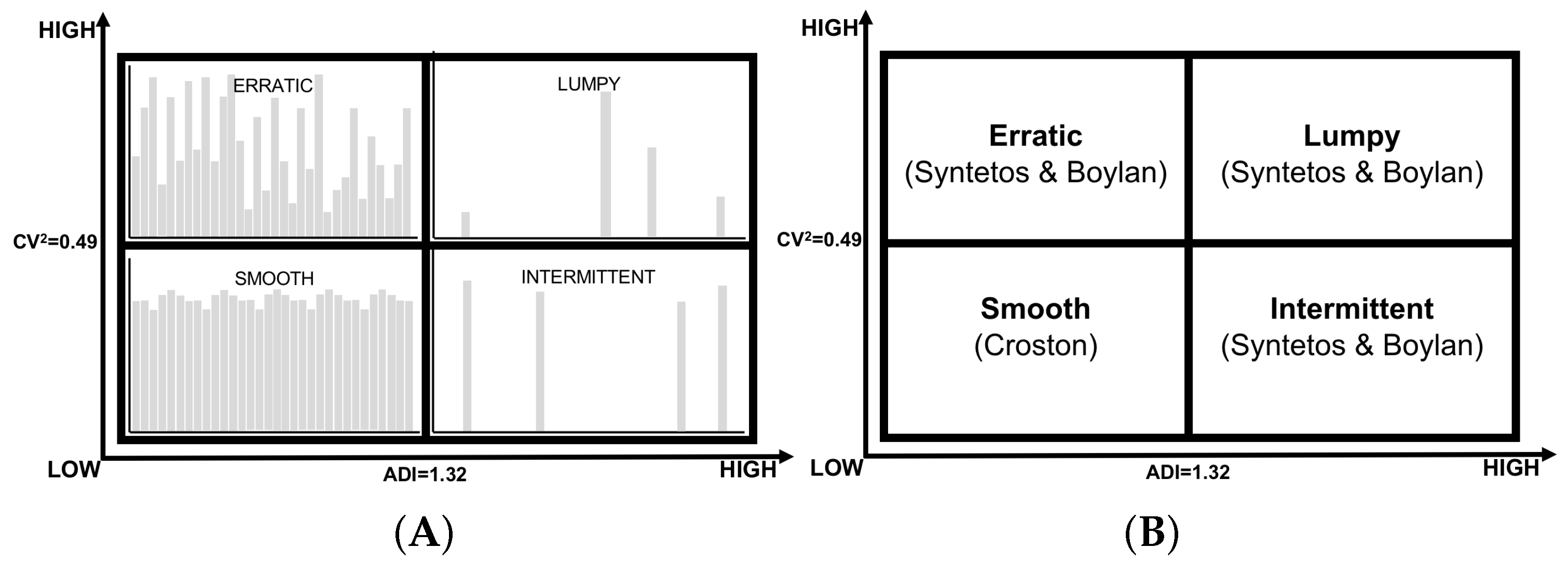
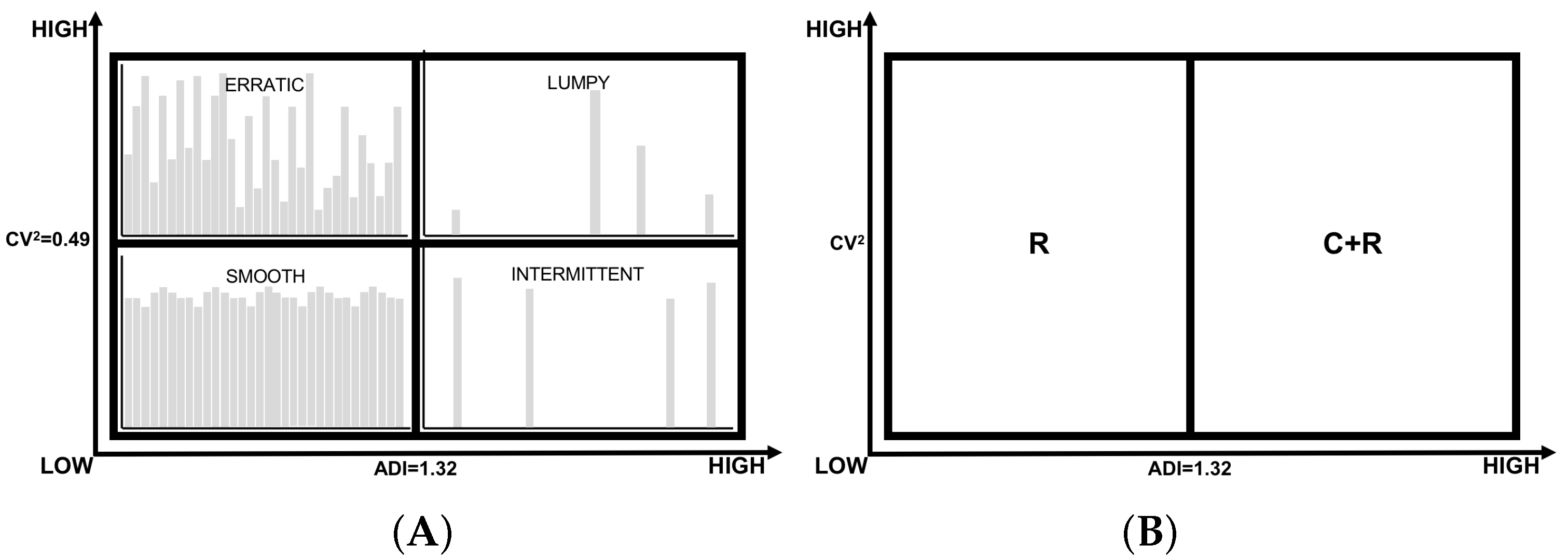
2.1. Demand Characterization
2.2. Forecasting Sparse Demand
2.3. Demand Forecasting Models
Forecasting Features
2.4. Metrics
3. Reframing Demand Forecasting
3.1. A Classification of Existing Demand Forecasting Models for Lumpy and Intermittent Demand
- Type I: uses a single model to predict the expected demand size for a given time step.
- Type II: uses aggregation to remove demand intermittency and benefit from regular time series models to forecast demand.
- Type III: uses separate models to estimate whether demand will take place at a given point in time and the expected demand size.
- Type IV: uses separate models to estimate the demand interval and demand size.
3.2. Demand Characterization and Forecasting Models
3.3. Metrics
4. Methodology
4.1. Business Understanding
4.2. Data Understanding
4.3. Data Preparation, Feature Creation, and Modeling
- MC+RAND: a hybrid model proposed by Willemain et al. [29]. Demand occurrence is estimated as a Markov process, while demand sizes are randomly sampled from previous occurrences.
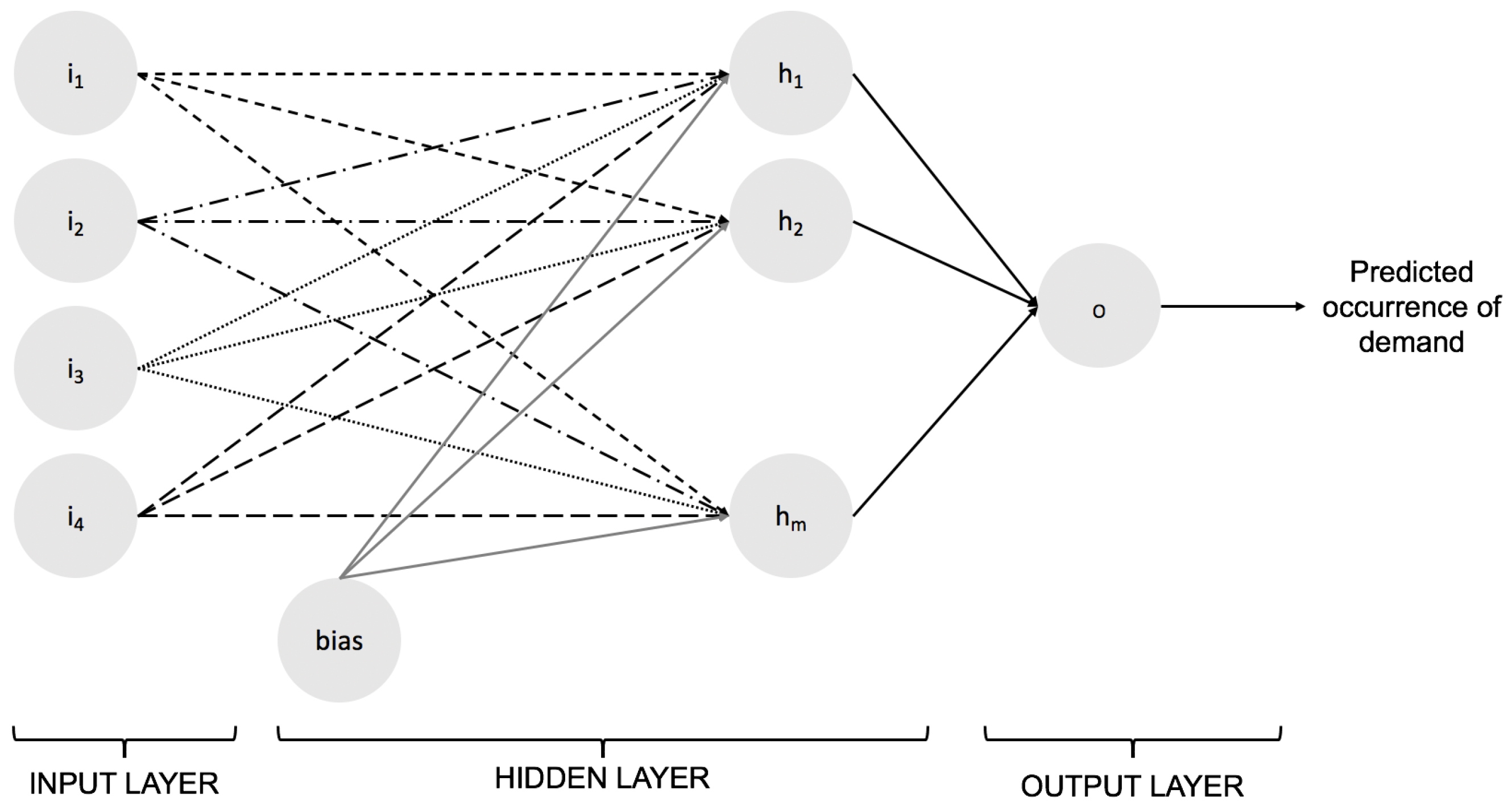
- NN+SES: a hybrid model proposed by Nasiri Pour et al. [28]. Considers a NN model (see Figure 2) to forecast demand occurrence; demand size is computed by exponential smoothing over non-zero demand quantities in past periods. We used the following parameters for the NN: a maximum of 300 iterations, a constant learning rate of 0.01, and a hyperbolic tangent activation. Given that no description was given on whether scaling was applied to the dataset prior to training the network, we explored two models: without feature scaling (NNNS+SES) and with feature scaling (NNWS+SES).
- ADIDA forecasting method, proposed by Nikolopoulos et al. [30], which removes intermittence through aggregation and then disaggregates the forecast back to the original aggregation level.
- ELM: an ELM model as proposed by Lolli et al. [31]. We initialized the model with the following parameters: 15 hidden units, ReLU activation, a regularization factor of 0.1, and normal weight initialization. We trained two models: ELM(C1) (two models, trained per demand type) and ELM(C2) (global model, considering all the demand types).
- VZadj: a method proposed by Hasni et al. [32], considering only positive demands when the predicted lead-time demand was equal to the forecasting horizon considered.
5. Experiments and Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| A-MAPE | Alternative mean absolute percentage error |
| ADI | Average demand interval |
| ADIDA | Aggregate–disaggregate intermittent demand approach |
| AUC ROC | Area under the curve of the receiver operating characteristic |
| CV | Coefficient of variation |
| ELM | Extreme learning machine |
| FSN | Fast-slow-non moving |
| GMAE | Geometric mean absolute error |
| GMAMAE | Geometric mean (across series) of the arithmetic mean (across time) of the absolute errors |
| GMRAE | Geometric mean relative absolute error |
| MAD | Mean absolute deviation |
| MADn | Mean absolute deviation over non-zero occurrences |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| MAR | Mean absolute error |
| MASE | Mean absolute scaled error |
| MdAE | Median absolute error |
| MdRAE | Median relative absolute error |
| ME | Mean error |
| MFV | Most frequent value |
| mGMRAE | Mean-based geometric mean relative absolute error |
| MLP | Multilayer perceptron |
| mMAE | Mean-based mean absolute error |
| mMAPE | Mean-based mean absolute percentage error |
| mMdAE | Mean-based median absolute error |
| mMSE | Mean-based mean squared error |
| mPB | Mean-based percentage of times better |
| MSE | Mean squared error |
| MSEn | Mean squared error over non-zero occurrences |
| MSR | Mean squared rate |
| NN | Neural network |
| PB | Percentage of times better |
| PIS | Periods in stock |
| RGRMSE | Relative geometric root mean squared error |
| RMSE | Root mean squared error |
| RMSSE | Root mean squared scaled error |
| sAPIS | Scaled absolute periods in stock |
| SBA | Syntetos–Boylan approximation |
| SES | Simple exponential smoothing |
| SKU | Stock-keeping unit |
| sMAPE | Symmetric mean absolute percentage error |
| SPEC | Stock-keeping-oriented prediction error cost |
| TSB | Teunter, Syntetos, and Babai |
| VED | Vital–essential–desirable |
| WRMSSE | Weighted root mean squared scaled error |
References
- Kim, M.; Jeong, J.; Bae, S. Demand forecasting based on machine learning for mass customization in smart manufacturing. In Proceedings of the 2019 International Conference on Data Mining and Machine Learning, Hong Kong, China, 28–30 April 2019; pp. 6–11. [Google Scholar]
- Moon, S. Predicting the Performance of Forecasting Strategies for Naval Spare Parts Demand: A Machine Learning Approach. Manag. Sci. Financ. Eng. 2013, 19, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Williams, T. Stock control with sporadic and slow-moving demand. J. Oper. Res. Soc. 1984, 35, 939–948. [Google Scholar] [CrossRef]
- Johnston, F.; Boylan, J.E. Forecasting for items with intermittent demand. J. Oper. Res. Soc. 1996, 47, 113–121. [Google Scholar] [CrossRef]
- Syntetos, A.A.; Boylan, J.E.; Croston, J. On the categorization of demand patterns. J. Oper. Res. Soc. 2005, 56, 495–503. [Google Scholar] [CrossRef]
- Amin-Naseri, M.R.; Tabar, B.R. Neural network approach to lumpy demand forecasting for spare parts in process industries. In Proceedings of the 2008 International Conference on Computer and Communication Engineering, Kuala Lumpur, Malaysia, 13–15 May 2008; IEEE: New York, NY, USA, 2008; pp. 1378–1382. [Google Scholar]
- Mukhopadhyay, S.; Solis, A.O.; Gutierrez, R.S. The accuracy of non-traditional versus traditional methods of forecasting lumpy demand. J. Forecast. 2012, 31, 721–735. [Google Scholar] [CrossRef]
- Petropoulos, F.; Kourentzes, N. Forecast combinations for intermittent demand. J. Oper. Res. Soc. 2015, 66, 914–924. [Google Scholar] [CrossRef] [Green Version]
- Bartezzaghi, E.; Kalchschmidt, M. The Impact of Aggregation Level on Lumpy Demand Management. In Service Parts Management: Demand Forecasting and Inventory Control; Springer: London, UK, 2011; pp. 89–104. [Google Scholar] [CrossRef]
- Babai, M.Z.; Syntetos, A.; Teunter, R. Intermittent demand forecasting: An empirical study on accuracy and the risk of obsolescence. Int. J. Prod. Econ. 2014, 157, 212–219. [Google Scholar] [CrossRef]
- Johnston, F.; Boylan, J.E.; Shale, E.A. An examination of the size of orders from customers, their characterisation and the implications for inventory control of slow moving items. J. Oper. Res. Soc. 2003, 54, 833–837. [Google Scholar] [CrossRef]
- Davies, R. Briefing Industry 4.0 Digitalisation for productivity and growth. In EPRS| European Parliamentary Research Service; European Parliament: Strasbourg, France, 2015. [Google Scholar]
- Glaser, B.S. Made in China 2025 and the Future of American Industry; Center for Strategic International Studies: Washington, DC, USA, 2019. [Google Scholar]
- Yang, F.; Gu, S. Industry 4.0, a revolution that requires technology and national strategies. Complex Intell. Syst. 2021, 7, 1311–1325. [Google Scholar] [CrossRef]
- Syntetos, A.A.; Babai, Z.; Boylan, J.E.; Kolassa, S.; Nikolopoulos, K. Supply chain forecasting: Theory, practice, their gap and the future. Eur. J. Oper. Res. 2016, 252, 1–26. [Google Scholar] [CrossRef]
- Croston, J.D. Forecasting and stock control for intermittent demands. J. Oper. Res. Soc. 1972, 23, 289–303. [Google Scholar] [CrossRef]
- Brühl, B.; Hülsmann, M.; Borscheid, D.; Friedrich, C.M.; Reith, D. A sales forecast model for the german automobile market based on time series analysis and data mining methods. In Proceedings of the Industrial Conference on Data Mining, Leipzig, Germany, 20–22 July 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 146–160. [Google Scholar]
- Wang, F.K.; Chang, K.K.; Tzeng, C.W. Using adaptive network-based fuzzy inference system to forecast automobile sales. Expert Syst. Appl. 2011, 38, 10587–10593. [Google Scholar] [CrossRef]
- Sharma, R.; Sinha, A.K. Sales forecast of an automobile industry. Int. J. Comput. Appl. 2012, 53, 25–28. [Google Scholar] [CrossRef]
- Gao, J.; Xie, Y.; Cui, X.; Yu, H.; Gu, F. Chinese automobile sales forecasting using economic indicators and typical domestic brand automobile sales data: A method based on econometric model. Adv. Mech. Eng. 2018, 10, 1687814017749325. [Google Scholar] [CrossRef] [Green Version]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Bandara, K.; Bergmeir, C.; Smyl, S. Forecasting across time series databases using recurrent neural networks on groups of similar series: A clustering approach. Expert Syst. Appl. 2020, 140, 112896. [Google Scholar] [CrossRef] [Green Version]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J. Another look at forecast-accuracy metrics for intermittent demand. Foresight Int. J. Appl. Forecast. 2006, 4, 43–46. [Google Scholar]
- Martin, D.; Spitzer, P.; Kühl, N. A New Metric for Lumpy and Intermittent Demand Forecasts: Stock-keeping-oriented Prediction Error Costs. arXiv 2020, arXiv:2004.10537. [Google Scholar]
- Syntetos, A.A.; Boylan, J.E. The accuracy of intermittent demand estimates. Int. J. Forecast. 2005, 21, 303–314. [Google Scholar] [CrossRef]
- Teunter, R.; Sani, B. On the bias of Croston’s forecasting method. Eur. J. Oper. Res. 2009, 194, 177–183. [Google Scholar] [CrossRef] [Green Version]
- Nasiri Pour, A.; Rostami-Tabar, B.; Rahimzadeh, A. A Hybrid Neural Network and Traditional Approach for Forecasting Lumpy Demand; World Academy of Science, Engineering and Technology: Paris, France, 2008; Volume 2. [Google Scholar]
- Willemain, T.R.; Smart, C.N.; Schwarz, H.F. A new approach to forecasting intermittent demand for service parts inventories. Int. J. Forecast. 2004, 20, 375–387. [Google Scholar] [CrossRef]
- Nikolopoulos, K.; Syntetos, A.A.; Boylan, J.E.; Petropoulos, F.; Assimakopoulos, V. An aggregate–disaggregate intermittent demand approach (ADIDA) to forecasting: An empirical proposition and analysis. J. Oper. Res. Soc. 2011, 62, 544–554. [Google Scholar] [CrossRef] [Green Version]
- Lolli, F.; Gamberini, R.; Regattieri, A.; Balugani, E.; Gatos, T.; Gucci, S. Single-hidden layer neural networks for forecasting intermittent demand. Int. J. Prod. Econ. 2017, 183, 116–128. [Google Scholar] [CrossRef]
- Hasni, M.; Aguir, M.; Babai, M.Z.; Jemai, Z. On the performance of adjusted bootstrapping methods for intermittent demand forecasting. Int. J. Prod. Econ. 2019, 216, 145–153. [Google Scholar] [CrossRef]
- Flores, B.E.; Whybark, D.C. Multiple criteria ABC analysis. Int. J. Oper. Prod. Manag. 1986, 6, 38–46. [Google Scholar] [CrossRef]
- Mitra, S.; Reddy, M.S.; Prince, K. Inventory control using FSN analysis–a case study on a manufacturing industry. Int. J. Innov. Sci. Eng. Technol. 2015, 2, 322–325. [Google Scholar]
- Scholz-Reiter, B.; Heger, J.; Meinecke, C.; Bergmann, J. Integration of demand forecasts in ABC-XYZ analysis: Practical investigation at an industrial company. Int. J. Product. Perform. Manag. 2012, 61, 445–451. [Google Scholar] [CrossRef] [Green Version]
- Botter, R.; Fortuin, L. Stocking strategy for service parts–a case study. Int. J. Oper. Prod. Manag. 2000, 20, 656–674. [Google Scholar] [CrossRef] [Green Version]
- Nallusamy, S. Performance Measurement on Inventory Management and Logistics Through Various Forecasting Techniques. Int. J. Perform. Eng. 2021, 17, 216–228. [Google Scholar]
- Eaves, A.H.; Kingsman, B.G. Forecasting for the ordering and stock-holding of spare parts. J. Oper. Res. Soc. 2004, 55, 431–437. [Google Scholar] [CrossRef]
- Syntetos, A.A.; Boylan, J.E. On the bias of intermittent demand estimates. Int. J. Prod. Econ. 2001, 71, 457–466. [Google Scholar] [CrossRef]
- Syntetos, A.; Boylan, J. Correcting the bias in forecasts of intermittent demand. In Proceedings of the 19th International Symposium on Forecasting, Washington, DC, USA, 27–30 June 1999. [Google Scholar]
- Arzi, Y.; Bukchin, J.; Masin, M. An efficiency frontier approach for the design of cellular manufacturing systems in a lumpy demand environment. Eur. J. Oper. Res. 2001, 134, 346–364. [Google Scholar] [CrossRef]
- Wallström, P.; Segerstedt, A. Evaluation of forecasting error measurements and techniques for intermittent demand. Int. J. Prod. Econ. 2010, 128, 625–636. [Google Scholar] [CrossRef]
- Shenstone, L.; Hyndman, R.J. Stochastic models underlying Croston’s method for intermittent demand forecasting. J. Forecast. 2005, 24, 389–402. [Google Scholar] [CrossRef] [Green Version]
- Levén, E.; Segerstedt, A. Inventory control with a modified Croston procedure and Erlang distribution. Int. J. Prod. Econ. 2004, 90, 361–367. [Google Scholar] [CrossRef]
- Teunter, R.H.; Syntetos, A.A.; Babai, M.Z. Intermittent demand: Linking forecasting to inventory obsolescence. Eur. J. Oper. Res. 2011, 214, 606–615. [Google Scholar] [CrossRef]
- Vasumathi, B.; Saradha, A. Enhancement of intermittent demands in forecasting for spare parts industry. Indian J. Sci. Technol. 2015, 8, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Prestwich, S.D.; Tarim, S.A.; Rossi, R.; Hnich, B. Forecasting intermittent demand by hyperbolic-exponential smoothing. Int. J. Forecast. 2014, 30, 928–933. [Google Scholar] [CrossRef] [Green Version]
- Türkmen, A.C.; Januschowski, T.; Wang, Y.; Cemgil, A.T. Forecasting intermittent and sparse time series: A unified probabilistic framework via deep renewal processes. PLoS ONE 2021, 16, e0259764. [Google Scholar] [CrossRef]
- Chua, W.K.W.; Yuan, X.M.; Ng, W.K.; Cai, T.X. Short term forecasting for lumpy and non-lumpy intermittent demands. In Proceedings of the 2008 6th IEEE International Conference on Industrial Informatics, Daejeon, Korea, 13–16 July 2008; IEEE: New York, NY, USA, 2008; pp. 1347–1352. [Google Scholar]
- Wright, D.J. Forecasting data published at irregular time intervals using an extension of Holt’s method. Manag. Sci. 1986, 32, 499–510. [Google Scholar] [CrossRef]
- Altay, N.; Rudisill, F.; Litteral, L.A. Adapting Wright’s modification of Holt’s method to forecasting intermittent demand. Int. J. Prod. Econ. 2008, 111, 389–408. [Google Scholar] [CrossRef] [Green Version]
- Sani, B.; Kingsman, B.G. Selecting the best periodic inventory control and demand forecasting methods for low demand items. J. Oper. Res. Soc. 1997, 48, 700–713. [Google Scholar] [CrossRef]
- Ghobbar, A.A.; Friend, C.H. Evaluation of forecasting methods for intermittent parts demand in the field of aviation: A predictive model. Comput. Oper. Res. 2003, 30, 2097–2114. [Google Scholar] [CrossRef]
- Chatfield, D.C.; Hayya, J.C. All-zero forecasts for lumpy demand: A factorial study. Int. J. Prod. Res. 2007, 45, 935–950. [Google Scholar] [CrossRef]
- Gutierrez, R.S.; Solis, A.O.; Mukhopadhyay, S. Lumpy demand forecasting using neural networks. Int. J. Prod. Econ. 2008, 111, 409–420. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Hotta, L.; Neto, J.C. The effect of aggregation on prediction in autoregressive integrated moving-average models. J. Time Ser. Anal. 1993, 14, 261–269. [Google Scholar] [CrossRef]
- Souza, L.R.; Smith, J. Effects of temporal aggregation on estimates and forecasts of fractionally integrated processes: A Monte-Carlo study. Int. J. Forecast. 2004, 20, 487–502. [Google Scholar] [CrossRef]
- Athanasopoulos, G.; Hyndman, R.J.; Song, H.; Wu, D.C. The tourism forecasting competition. Int. J. Forecast. 2011, 27, 822–844. [Google Scholar] [CrossRef]
- Rostami-Tabar, B.; Babai, M.Z.; Syntetos, A.; Ducq, Y. Demand forecasting by temporal aggregation. Nav. Res. Logist. (NRL) 2013, 60, 479–498. [Google Scholar] [CrossRef]
- Rostami-Tabar, B.; Babai, M.Z.; Ali, M.; Boylan, J.E. The impact of temporal aggregation on supply chains with ARMA (1, 1) demand processes. Eur. J. Oper. Res. 2019, 273, 920–932. [Google Scholar] [CrossRef]
- Kourentzes, N.; Petropoulos, F. Forecasting with multivariate temporal aggregation: The case of promotional modelling. Int. J. Prod. Econ. 2016, 181, 145–153. [Google Scholar] [CrossRef] [Green Version]
- Hua, Z.; Zhang, B.; Yang, J.; Tan, D. A new approach of forecasting intermittent demand for spare parts inventories in the process industries. J. Oper. Res. Soc. 2007, 58, 52–61. [Google Scholar] [CrossRef]
- Petropoulos, F.; Kourentzes, N.; Nikolopoulos, K. Another look at estimators for intermittent demand. Int. J. Prod. Econ. 2016, 181, 154–161. [Google Scholar] [CrossRef] [Green Version]
- Bartezzaghi, E.; Verganti, R.; Zotteri, G. A simulation framework for forecasting uncertain lumpy demand. Int. J. Prod. Econ. 1999, 59, 499–510. [Google Scholar] [CrossRef]
- Verganti, R. Order overplanning with uncertain lumpy demand: A simplified theory. Int. J. Prod. Res. 1997, 35, 3229–3248. [Google Scholar] [CrossRef]
- Bartezzaghi, E.; Verganti, R.; Zotteri, G. Measuring the impact of asymmetric demand distributions on inventories. Int. J. Prod. Econ. 1999, 60, 395–404. [Google Scholar] [CrossRef]
- Zotteri, G. The impact of distributions of uncertain lumpy demand on inventories. Prod. Plan. Control 2000, 11, 32–43. [Google Scholar] [CrossRef]
- Willemain, T.R.; Smart, C.N.; Shockor, J.H.; DeSautels, P.A. Forecasting intermittent demand in manufacturing: A comparative evaluation of Croston’s method. Int. J. Forecast. 1994, 10, 529–538. [Google Scholar] [CrossRef]
- Syntetos, A. Forecasting of Intermittent Demand. Ph.D. Thesis, Brunel University Uxbridge, London, UK, 2001. [Google Scholar]
- Anderson, C.J. Forecasting Demand for Optimal Inventory with Long Lead Times: An Automotive Aftermarket Case Study. Ph.D. Thesis, University of Missouri-Saint Louis, Saint Louis, MO, USA, 2021. [Google Scholar]
- Teunter, R.H.; Duncan, L. Forecasting intermittent demand: A comparative study. J. Oper. Res. Soc. 2009, 60, 321–329. [Google Scholar] [CrossRef]
- Hemeimat, R.; Al-Qatawneh, L.; Arafeh, M.; Masoud, S. Forecasting spare parts demand using statistical analysis. Am. J. Oper. Res. 2016, 6, 113. [Google Scholar] [CrossRef] [Green Version]
- Kourentzes, N. On intermittent demand model optimisation and selection. Int. J. Prod. Econ. 2014, 156, 180–190. [Google Scholar] [CrossRef] [Green Version]
- Prestwich, S.; Rossi, R.; Armagan Tarim, S.; Hnich, B. Mean-based error measures for intermittent demand forecasting. Int. J. Prod. Res. 2014, 52, 6782–6791. [Google Scholar] [CrossRef] [Green Version]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M5 Accuracy Competition: Results, Findings and Conclusions. 2020. Available online: https://www.researchgate.net/publication/344487258_The_M5_Accuracy_competition_Results_findings_and_conclusions (accessed on 25 May 2022).
- Syntetos, A.A.; Boylan, J.E. On the variance in intermittent demand estimates. Int. J. Prod. Econ. 2010, 128, 546–555. [Google Scholar] [CrossRef]
- Regattieri, A.; Gamberi, M.; Gamberini, R.; Manzini, R. Managing lumpy demand for aircraft spare parts. J. Air Transp. Manag. 2005, 11, 426–431. [Google Scholar] [CrossRef]
- Quintana, R.; Leung, M. Adaptive exponential smoothing versus conventional approaches for lumpy demand forecasting: Case of production planning for a manufacturing line. Int. J. Prod. Res. 2007, 45, 4937–4957. [Google Scholar] [CrossRef]
- Amirkolaii, K.N.; Baboli, A.; Shahzad, M.; Tonadre, R. Demand forecasting for irregular demands in business aircraft spare parts supply chains by using artificial intelligence (AI). IFAC-PapersOnLine 2017, 50, 15221–15226. [Google Scholar] [CrossRef]
- Gomez, G.C.G. Lumpy Demand Characterization and Forecasting Performance Using Self-Adaptive Forecasting Models and Kalman Filter; The University of Texas at El Paso: Texas, TX, USA, 2008. [Google Scholar]
- Kiefer, D.; Grimm, F.; Bauer, M.; Van Dinther, C. Demand forecasting intermittent and lumpy time series: Comparing statistical, machine learning and deep learning methods. In Proceedings of the 54th Hawaii International Conference on System Sciences, Virtual, 4–9 January 2021; p. 1425. [Google Scholar]
- Nikolopoulos, K. We need to talk about intermittent demand forecasting. Eur. J. Oper. Res. 2021, 291, 549–559. [Google Scholar] [CrossRef] [Green Version]
- Laptev, N.; Yosinski, J.; Li, L.E.; Smyl, S. Time-series extreme event forecasting with neural networks at uber. In Proceedings of the International Conference on Machine Learning, Ho Chi Minh, Vietnam, 13–16 January 2017; Volume 34, pp. 1–5. [Google Scholar]
- Rožanec, J.M.; Kažič, B.; Škrjanc, M.; Fortuna, B.; Mladenić, D. Automotive OEM demand forecasting: A comparative study of forecasting algorithms and strategies. Appl. Sci. 2021, 11, 6787. [Google Scholar] [CrossRef]
- Lowas III, A.F.; Ciarallo, F.W. Reliability and operations: Keys to lumpy aircraft spare parts demands. J. Air Transp. Manag. 2016, 50, 30–40. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 6638–6648. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B (Methodol.) 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Song, H.; Perello-Nieto, M.; Santos-Rodriguez, R.; Kull, M.; Flach, P. Classifier Calibration: How to assess and improve predicted class probabilities: A survey. arXiv 2021, arXiv:2112.10327. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | [54] | [79] | [55] | [6] | [80] | [28] | [66] | [81] | [53] | [82] | [16] | [39] | [83] | [42] | [71] | [73] | [74] | [75] | [76] | [77] | [24] | [25] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A-MAPE | X | X | X | |||||||||||||||||||
| GMAE | X | |||||||||||||||||||||
| GMAMAE | X | |||||||||||||||||||||
| GMRAE | X | |||||||||||||||||||||
| MAD | X | X | X | X | X | X | ||||||||||||||||
| MAE | X | X | X | |||||||||||||||||||
| MAPE | X | X | X | X | X | X | X | |||||||||||||||
| MAR | X | |||||||||||||||||||||
| MASE | X | X | X | X | ||||||||||||||||||
| MdAE | X | |||||||||||||||||||||
| MdRAE | X | X | ||||||||||||||||||||
| ME | X | |||||||||||||||||||||
| mGMRAE | X | |||||||||||||||||||||
| mMAE | X | |||||||||||||||||||||
| mMAPE | X | |||||||||||||||||||||
| mMdAE | X | |||||||||||||||||||||
| mMSE | X | |||||||||||||||||||||
| mPB | X | |||||||||||||||||||||
| MSE | X | X | X | X | X | X | X | |||||||||||||||
| MSR | X | |||||||||||||||||||||
| MSEn | X | |||||||||||||||||||||
| MADn | X | |||||||||||||||||||||
| PB | X | X | X | X | ||||||||||||||||||
| PIS | X | X | ||||||||||||||||||||
| RGRMSE | X | X | X | |||||||||||||||||||
| RMSSE | X | |||||||||||||||||||||
| RMSE | X | X | X | |||||||||||||||||||
| sAPIS | X | |||||||||||||||||||||
| sMAPE | X | X | X | X | ||||||||||||||||||
| SPEC | X | X | ||||||||||||||||||||
| Theil’s U statistic | X | |||||||||||||||||||||
| WRMSSE | X |
| Model Type | Related Work |
|---|---|
| I | [16,26,31,44,45,46,49,50,51,52,53,54,55] |
| II | [8,30,58,59,60,61,63] |
| III | [28,29,64] |
| IV | [32,65] |
| Metric | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|
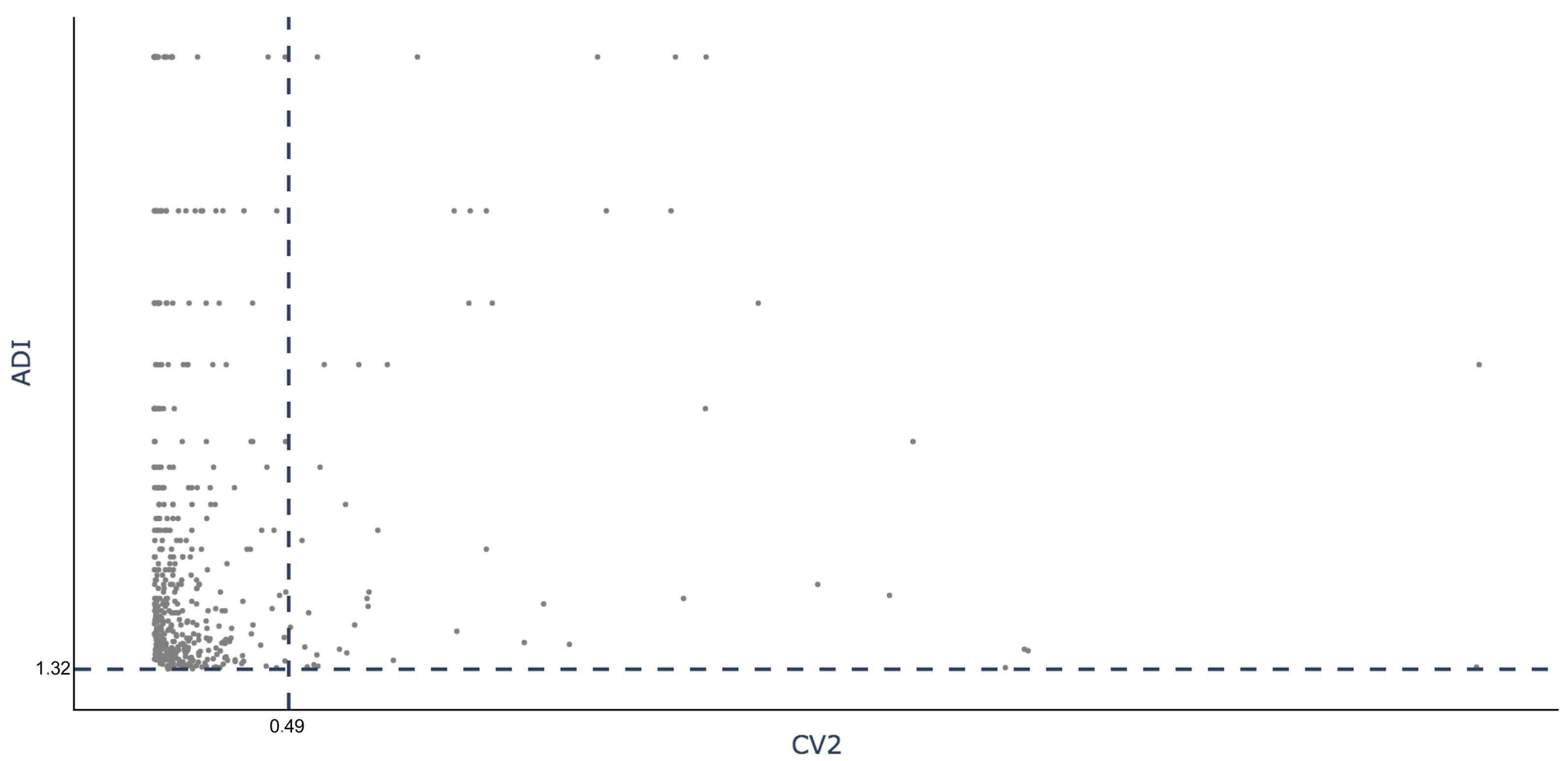
| ADI | 86.00 | 87.26 | 1.97 | 11.86 | 37.29 | 156.60 | 261.00 |
| CV2 | 1.44 | 1.04 | 0.50 | 0.70 | 1.10 | 1.90 | 4.83 |
| Metric | Mean | Std | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|
| ADI | 56.72 | 70.58 | 1.41 | 9.79 | 25.26 | 71.18 | 261.00 |
| CV2 | 0.09 | 0.11 | 0.00 | 0.02 | 0.05 | 0.13 | 0.48 |
| Model Task | Model Type | ID | Models | Data |
|---|---|---|---|---|
| Classification | Global, per demand type (lumpy or intermittent) | C1 | CatBoost | Demand occurrence features |
| Global, over all instances (lumpy and intermittent) | C2 | CatBoost | Demand occurrence features | |
| Regression | Local, one per each time series | R1 | Naive SES MA(3) MFV RAND | Past non-zero demand sizes |
| Global, per demand type (lumpy or intermittent) | R2 | LightGBM | Demand size features | |
| Global, over all instances (lumpy and intermittent) | R3 | LightGBM | Demand size features |
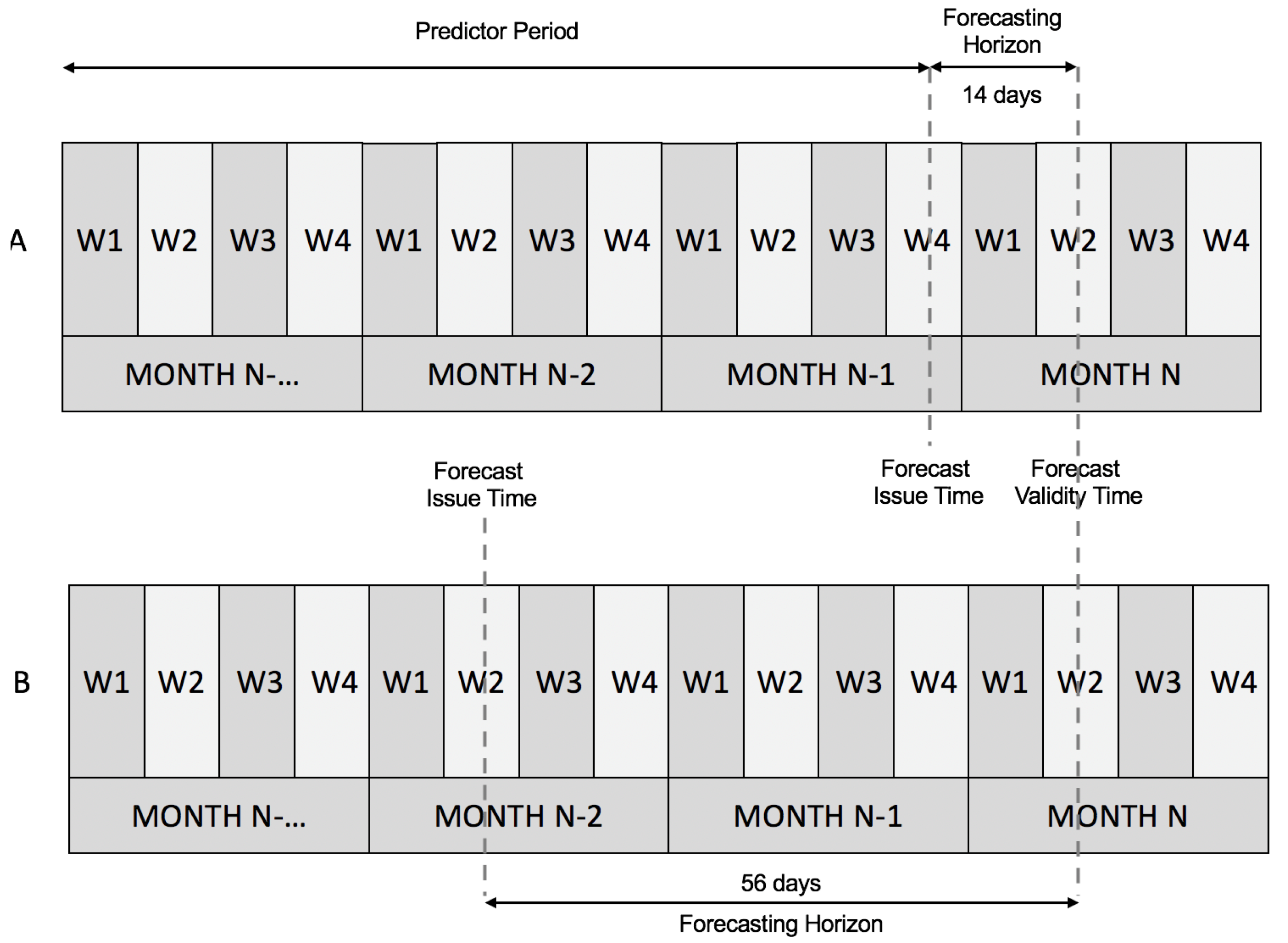
| Model | Regression | Forecasting Horizon: 14 Days | Forecasting Horizon: 56 Days | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AUC ROC ↑ | MASEI ↓ | MASEII ↓ | SPECmedian ↓ | AUC ROC ↑ | MASEI ↓ | MASEII ↓ | SPECmedian ↓ | ||
| C1R1 | Naive | 0.9408 | 0.5764 | 1.1084 | 121.9809 | 0.9409 | 0.4861 | 1.1084 | 121.9809 |
| MA(3) | 0.9408 | 0.5482 | 1.0544 | 281.2004 | 0.9409 | 0.4624 | 1.0544 | 281.2004 | |
| SES | 0.9408 | 0.5229 | 1.0058 | 1210.7634 | 0.9409 | 0.4410 | 1.0058 | 1210.7634 | |
| MFV | 0.9408 | 0.5437 | 1.0457 | 141.4351 | 0.9409 | 0.4585 | 1.0457 | 141.4351 | |
| RAND | 0.9408 | 0.7552 | 1.4524 | 2011.5744 | 0.9409 | 0.6353 | 1.4485 | 2675.2844 | |
| C1R2 | ML | 0.9408 | 0.5813 | 1.1183 | 46,422.3206 | 0.9409 | 0.4917 | 1.1215 | 46,162.9523 |
| C1R3 | ML | 0.9408 | 0.5758 | 1.1250 | 48,807.4847 | 0.9409 | 0.4613 | 1.1274 | 48,279.0973 |
| C2R1 | Naive | 0.9700 | 0.5271 | 1.0460 | 110.3435 | 0.9700 | 0.4445 | 1.0460 | 110.3435 |
| MA(3) | 0.9700 | 0.4906 | 0.9736 | 245.1851 | 0.9700 | 0.4137 | 0.9736 | 245.1851 | |
| SES | 0.9700 | 0.4611 | 0.9152 | 1343.2328 | 0.9700 | 0.3888 | 0.9152 | 1343.2328 | |
| MFV | 0.9700 | 0.4760 | 0.9448 | 94.8092 | 0.9700 | 0.4014 | 0.9448 | 94.8092 | |
| RAND | 0.9700 | 0.7267 | 1.4422 | 2034.5172 | 0.9700 | 0.5975 | 1.4059 | 2938.0534 | |
| C2R2 | ML | 0.9700 | 0.5194 | 1.0310 | 44,255.2309 | 0.9700 | 0.4398 | 1.0352 | 44,101.6088 |
| C2R3 | ML | 0.9700 | 0.5295 | 1.0510 | 39,918.1584 | 0.9700 | 0.4479 | 1.0542 | 40219.3378 |
| Model | Forecasting Horizon: 14 days | Forecasting Horizon: 56 days | ||||||
|---|---|---|---|---|---|---|---|---|
| AUC ROC ↑ | MASEI ↓ | MASEII ↓ | SPECmedian ↓ | AUC ROC↑ | MASEI ↓ | MASEII ↓ | SPECmedian ↓ | |
| Croston [16] | 0.5000 | 1.5997 | 96.2732 | 182,590,225.2842 | 0.5000 | 1.4769 | 1.4769 | 173,846,999.3033 |
| SBA [26] | 0.5000 | 1.5196 | 91.4593 | 173,457,612.1803 | 0.5000 | 1.4047 | 88.2762 | 165,151,599.2596 |
| TSB [27] | 0.5337 | 1.0340 | 42.8525 | 82,848,841.2377 | 0.5448 | 0.7491 | 11.9425 | 2,0024,649.5191 |
| MC+RAND [29] | 0.5000 | 0.8616 | 1.3786 | 199.3702 | 0.5000 | 0.8619 | 1.3786 | 199.3702 |
| NNWS+SES [28] | 0.5000 | 0.3872 | 0.8588 | 18,804,861.1954 | 0.5000 | 0.3825 | 0.8588 | 18,240,504.9768 |
| NNNS+SES [28] | 0.5000 | 0.3834 | 0.8588 | 18,804,861.1954 | 0.5000 | 0.3825 | 0.8588 | 18,240,504.9768 |
| ELM(C1) [31] | 0.6931 | 1.1020 | 0.0004 | 1593.4317 | 0.7024 | 0.3087 | 0.0004 | 1566.1803 |
| ELM(C2) [31] | 0.6955 | 0.1034 | 0.0004 | 1605.4686 | 0.6967 | 0.0317 | 0.0004 | 1581.5055 |
| VZadj [32] | 0.5000 | 0.9998 | 1.9864 | 23,883.8074 | 0.5000 | 0.9922 | 1.9864 | 23,883.8074 |
| C2R1-Naive | 0.9700 | 0.5271 | 1.0460 | 110.3435 | 0.9700 | 0.4445 | 1.0460 | 110.3435 |
| C2R1-SES | 0.9700 | 0.4611 | 0.9152 | 1343.2328 | 0.9700 | 0.3888 | 0.9152 | 1343.2328 |
| C2R1-MFV | 0.9700 | 0.4760 | 0.9448 | 94.8092 | 0.9700 | 0.4014 | 0.9448 | 94.8092 |
| Model | Forecasting Horizon: 14 Days | Forecasting Horizon: 56 Days | ||
|---|---|---|---|---|
| AUC ROClumpy ↑ | AUC ROCintermittent ↑ | AUC ROClumpy ↑ | AUC ROCintermittent ↑ | |
| C1 | 0.7368 | 0.9666 | 0.7379 | 0.9666 |
| C2 | 0.9097 | 0.9776 | 0.9097 | 0.9776 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rožanec, J.M.; Fortuna, B.; Mladenić, D. Reframing Demand Forecasting: A Two-Fold Approach for Lumpy and Intermittent Demand. Sustainability 2022, 14, 9295. https://doi.org/10.3390/su14159295
Rožanec JM, Fortuna B, Mladenić D. Reframing Demand Forecasting: A Two-Fold Approach for Lumpy and Intermittent Demand. Sustainability. 2022; 14(15):9295. https://doi.org/10.3390/su14159295
Chicago/Turabian StyleRožanec, Jože Martin, Blaž Fortuna, and Dunja Mladenić. 2022. "Reframing Demand Forecasting: A Two-Fold Approach for Lumpy and Intermittent Demand" Sustainability 14, no. 15: 9295. https://doi.org/10.3390/su14159295
APA StyleRožanec, J. M., Fortuna, B., & Mladenić, D. (2022). Reframing Demand Forecasting: A Two-Fold Approach for Lumpy and Intermittent Demand. Sustainability, 14(15), 9295. https://doi.org/10.3390/su14159295