Coupled Higher-Order Tensor Factorization for Hyperspectral and LiDAR Data Fusion and Classification


Abstract
:1. Introduction
- Mathematical morphology generates multisource spatial features from remotely sensed images, and fuses those features in feature level for image classification by using an independent classifier. For example, attribute profiles (APs) [4,5,6,7,8,9], morphological profiles (MPs) [10,11,12], extinction profiles (EPs) [7,13,14,15,16] were computed on both optical and LiDAR data to extract the multisource features, leading to a fusion of spectral, spatial and elevation information.
- Markov modeling formalizes spatial information and data fusion through global minimum energy concepts, which has been used for remotely sensed data fusion. For example, the work in [17] proposed an edge-constrained Markov random field method for accurate land cover classification over urban areas using hyperspectral and LiDAR data.
- Sparse representation conducts data fusion by minimizing the signal-to-reconstruction error with a predefined dictionary and a sparse-inducing constraint. For example, in [18], a method of fusing hyperspectral and LiDAR data for landscape visual quality assessment was presented, where the relationship between physical features and human landscape preferences was learned using least absolute shrinkage and selection operator regression. Further, joint sparse representation [19] and sparse low-rank [20] techniques were exploited for the fusion and classification of hyperspectral and LiDAR data.
- Ensemble learning conducts data fusion in decision level by combining results from many weak learners based on multisource features. For example, multiple fuzzy classifier system was studied for hyperspectral and LiDAR data fusion [21,22]. In addition, the work in [12] used a random forest classifier to produce multiple classification results based on multiple features, and majority voting was then used to fuse the results.
- Manifold learning serves as a framework for low-dimensional feature extraction through graph embedding, where data fusion coupled with dimensionality reduction can be conducted by fusing the Laplacian matrices computed for multisource data. For example, generalized graph-based method [10], kernel local Fisher discriminant analysis [25], discriminative graph-based method [11], and orthogonal total variation component analysis [14] were used to extract low-dimensional features for hyperspectral and LiDAR data fusion.
- Hash learning is used to extract compact binary features which are then used for HSI classification [28].
- We propose a novel coupled high-order tensor factorization model for hyperspectral and LiDAR data fusion and classification, which is unique compared with regard to previously proposed approaches in this area. Note that, this is the first time of exploiting tensor factorization for hyperspectral and LiDAR data fusion.
- We propose to represent HSI, HSI-derived EMAPs, and LiDAR-derived APs as third-order tensors, and the shared and unshared factors are produced by using coupled tensor factorization.
- Last but not least, only training samples are fed into the model for factorizing, and feature projection is achieved by using model-n tensor-matrix product based on shared factors and the test samples.
2. Materials and Methods
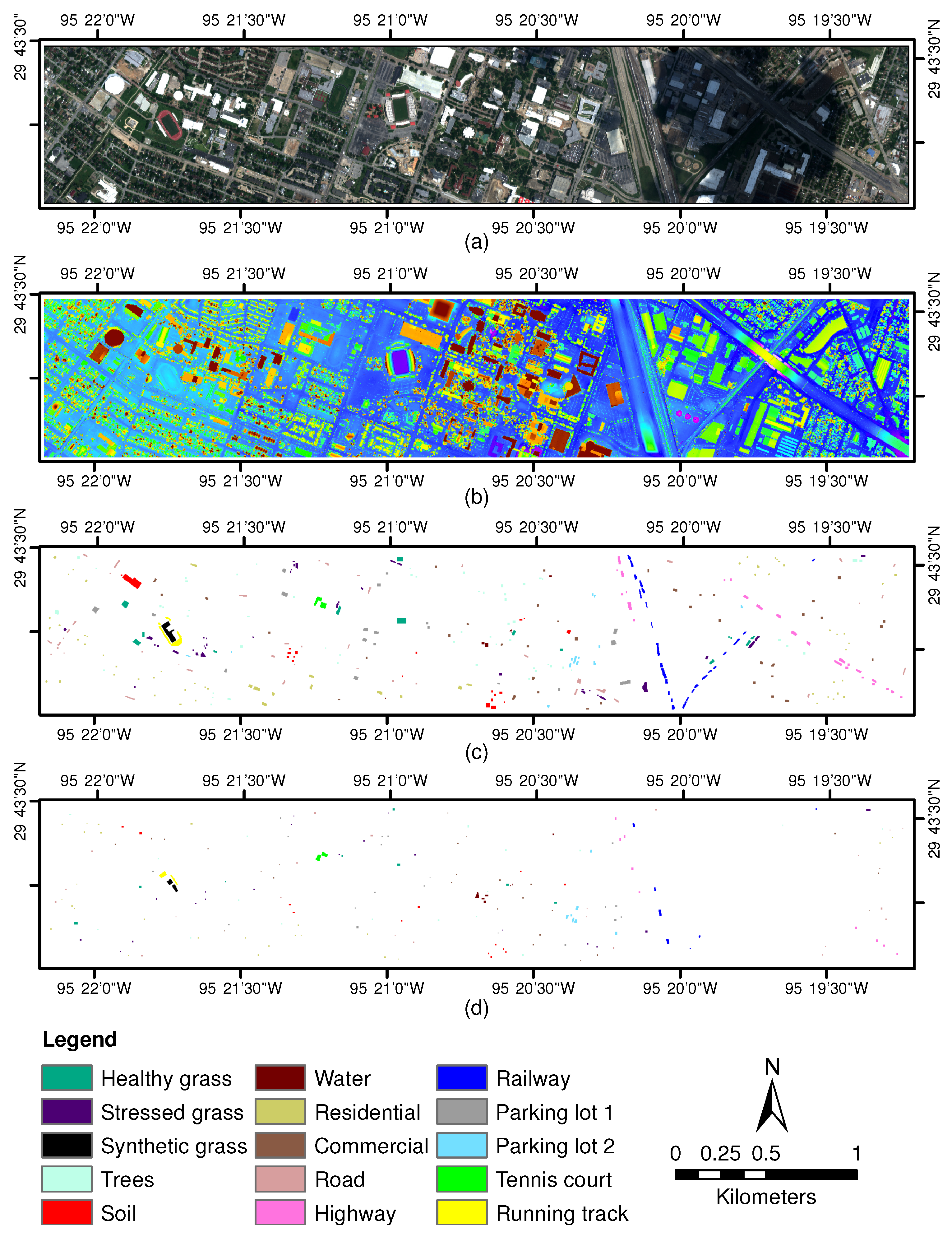
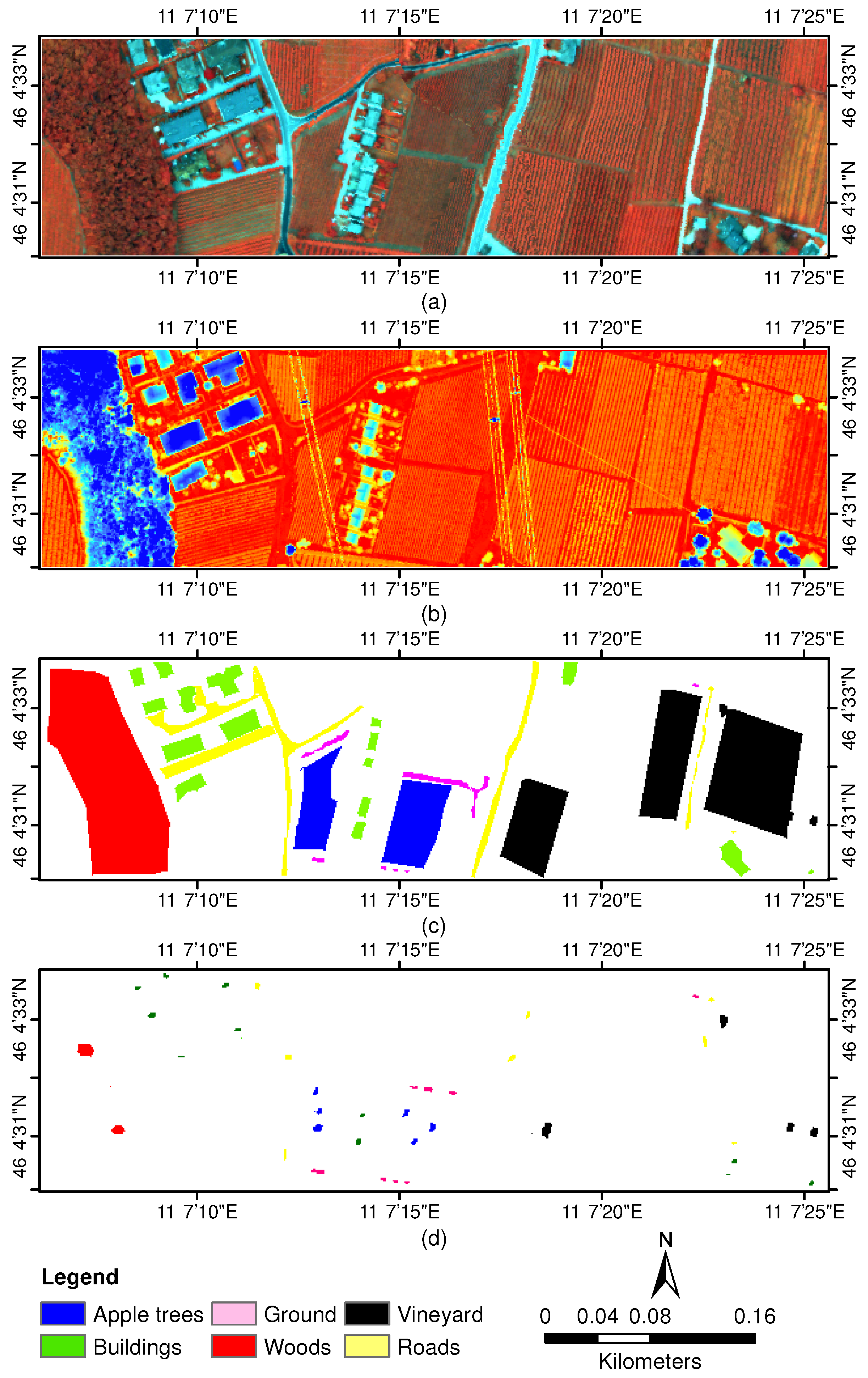
2.1. Validation Test Sites
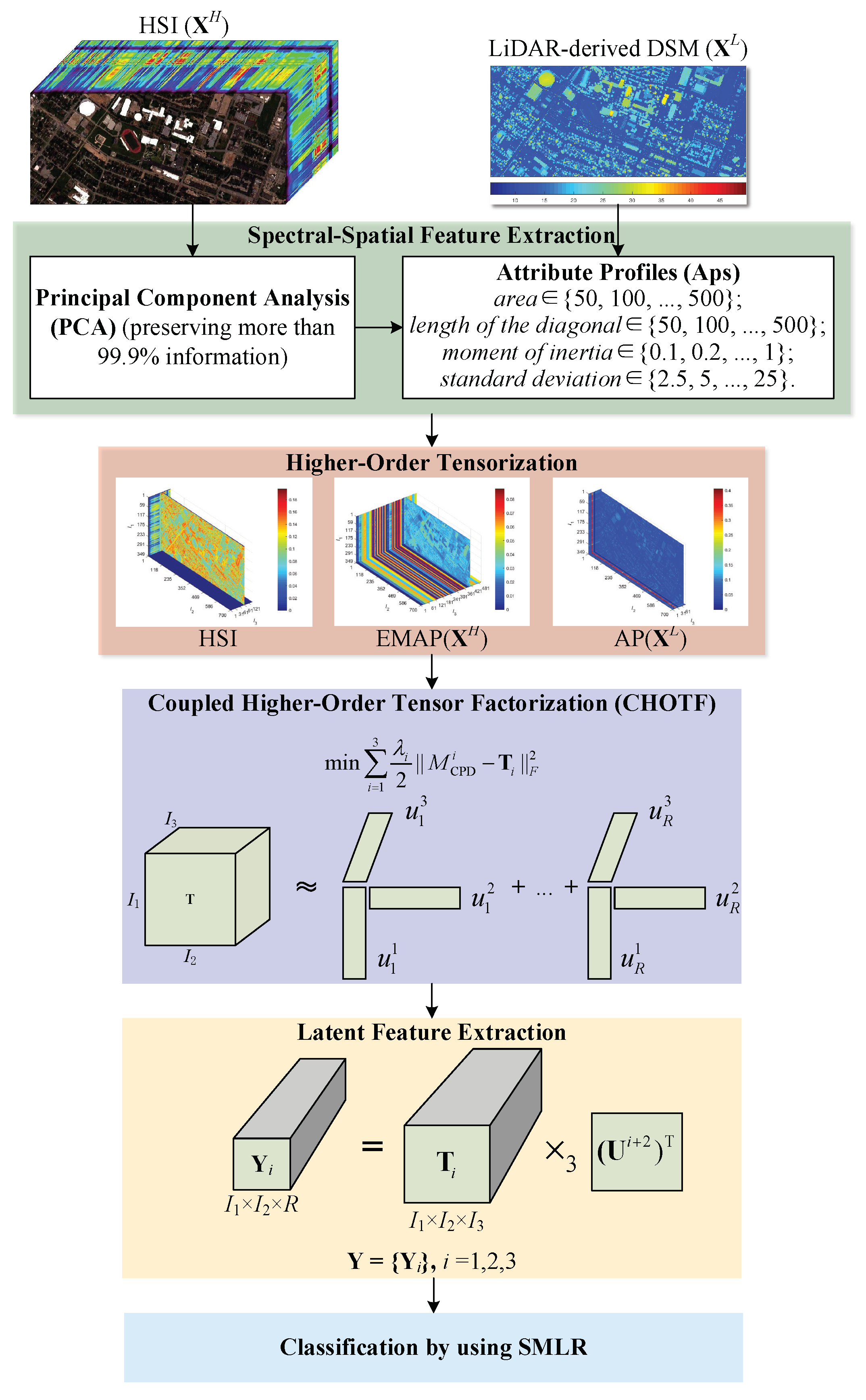
2.2. Proposed Methodology
2.2.1. Spectral-Spatial Features Extraction via APs
2.2.2. Higher-Order Tensor Representation
2.2.3. Coupled Higher-Order Tensor Factorization
2.2.4. Latent Feature Extraction
2.2.5. Classification By Using SMLR
| Algorithm 1 Coupled higher-order tensor factorization for hyperspectral and LiDAR data fusion and classification. |
|
3. Results
3.1. Experimental Settings
- For building EMAP(X) and AP(X), the four types of attributes are set as area∈{50, 100, ..., 500}; length of the diagonal∈{50, 100, ..., 500}; moment of inertia∈{0.1, 0.2, ..., 1}; standard deviation∈{2.5, 5, ..., 25}. Especially, when using Principal Component Analysis (PCA) to build EMAP(X), the features extracted by PCA preserving more than 99.9% information according to the cumulative variance, i.e., 6 PCs for University of Houston data sets, and 8 PCs for Trento data sets.
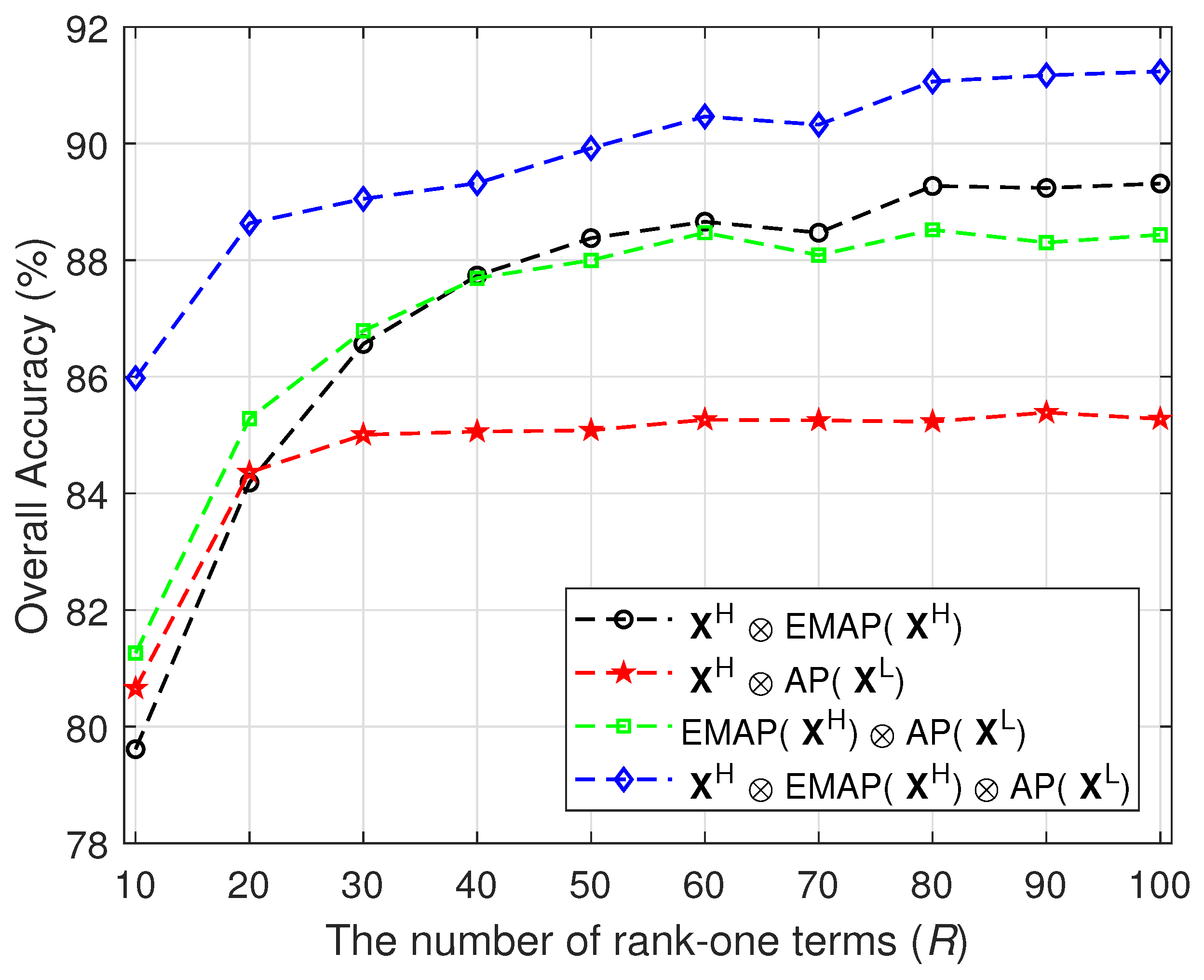
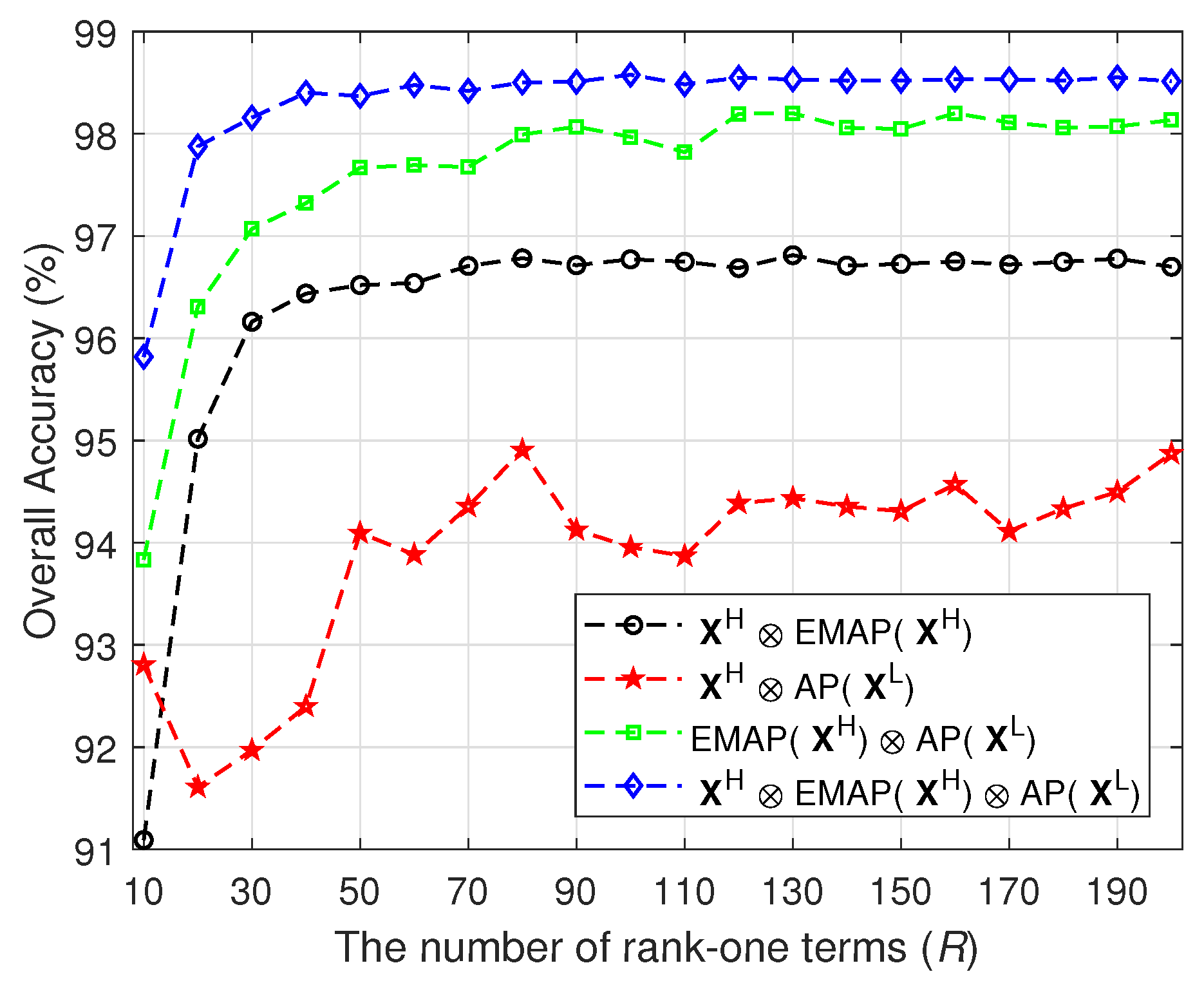
- For the proposed method, we experimentally set , and . Although this parameter setting may not be optimal, it has produced good results in our experiments. As for the rank-one term R, we carefully optimized it in the experiments for different data sets.
- The individual features considered in this work include: the original HSI (X), the EMAP built on X [EMAP(X)], and the AP built on X [AP(X)]. We denote by “A⊗B” the proposed CHOTF-based fusion based on different features A and B.
- In the comparison with different dimensionality reduction (DR) methods, we include PCA, Linear Graph Embedding (LGE), Locality Preserving Projections (LPP), Linear Discriminant Analysis (LDA), and Marginal Fisher Analysis (MFA). Different DR methods are applied on each individual features, and each extracted features preserving more than 99.9% information, then the extracted features are stacked together for classification.
- In the comparison with independent third-order tensor factorization methods, we include canonical polyadic decomposition (CPD) [52], decomposition in multilinear rank-() terms (LL1) [61], multilinear singular value decomposition (MLSVD) [62], low multilinear rank approximation (LMLRA) [52], and block term decomposition (BTD) [52]. Note that we fixed the variables instead of random initialization for different tensor-based methods.
- In the comparison with other hyperspectral and LiDAR data fusion methods, we include generalized graph-based fusion (GGF) [10], EPs based on CNN (EP+CNN) [13], deep fusion [7], two-branch CNN [29], three-stream CNN [15], hyperspectral multisensor composite kernels (HyMCKs) [16], higher order discriminant analysis (HODA) [63], local tensor discriminant analysis (LTDA) [34]. Note that, we fed our extracted APs into GGF, HODA, and LTDA for feature extraction, whereas for other methods, we directly reported their accuracies. This comparison is fair since the same training and test samples were used in those considered methods.
- In the comparison with different classifiers, we include random forest (RF) [64], support vector machine (SVM) implemented by LIBSVM [65], subspace projection based multinomial logistic regression (MLR) algorithm (MLRsub) [66], MLR optimized via a variable splitting and augmented Lagrangian algorithm and on a multilevel logistic prior (LORSAL-MLL) [54], and generalized composite kernel framework using multinomial logistic regression (MLR-GCK) [67]. In our paper, we adopt a SMLR classifier to produce the final classification map. SMLR model is optimized by using LORSAL, where the regularization parameter is set to and the number of iterations is set to 100.
- The classification results are quantitatively evaluated by measuring the overall accuracy (OA), the average accuracy (AA), the individual class accuracy, and the Kappa statistic (). Note that we were neither intend to select the training samples from ground-truth nor try to split the ground-truth into training and test sets. Whereas, we directly used the training set to train our classifier which was then directly applied to the test set for validation.
- Finally, it should be noted that all the implementations were carried out using Matlab R2017b in a desktop PC equipped with an Intel Xeon E3 CPU (at 3.4 GHz) and 32 GB of RAM.
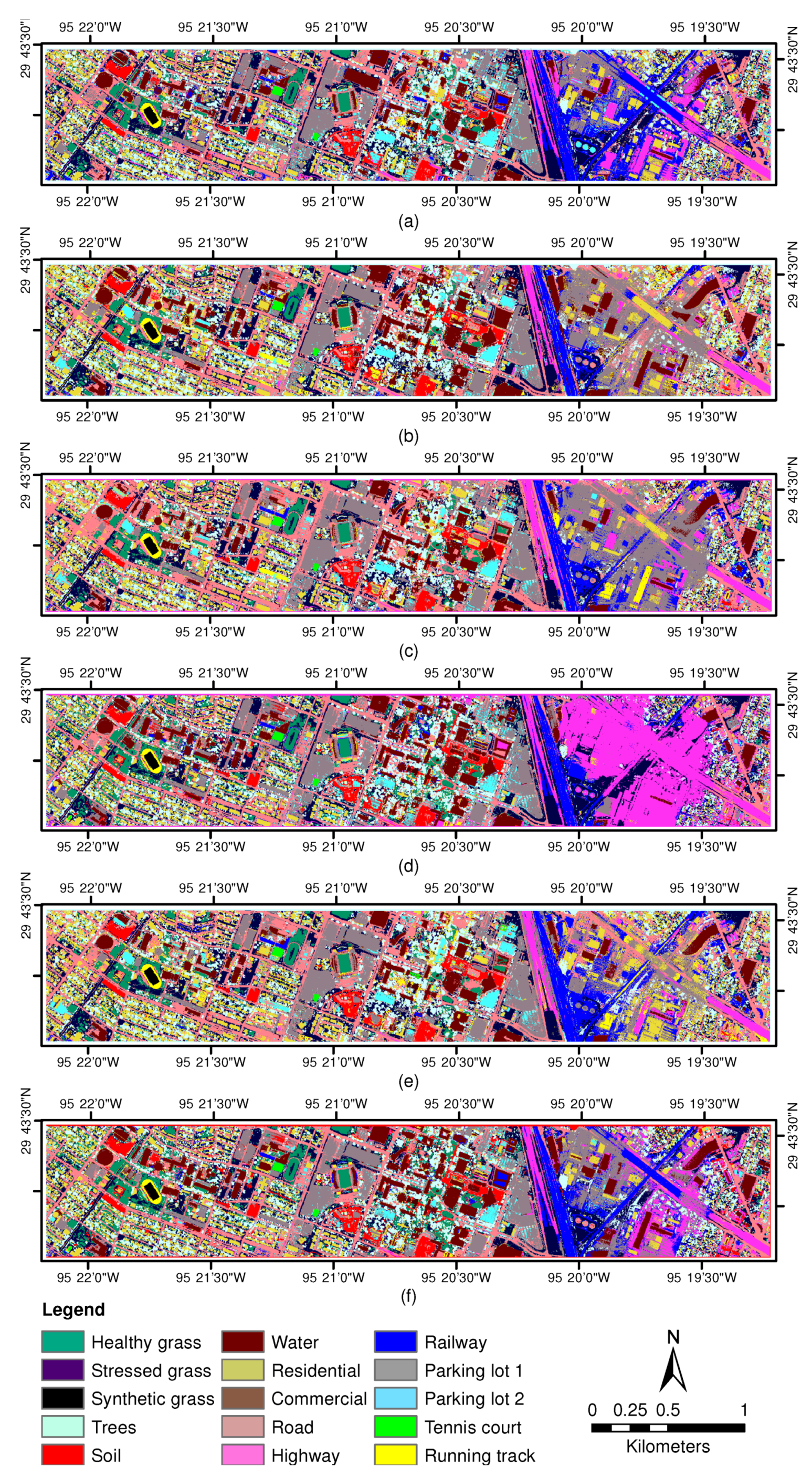
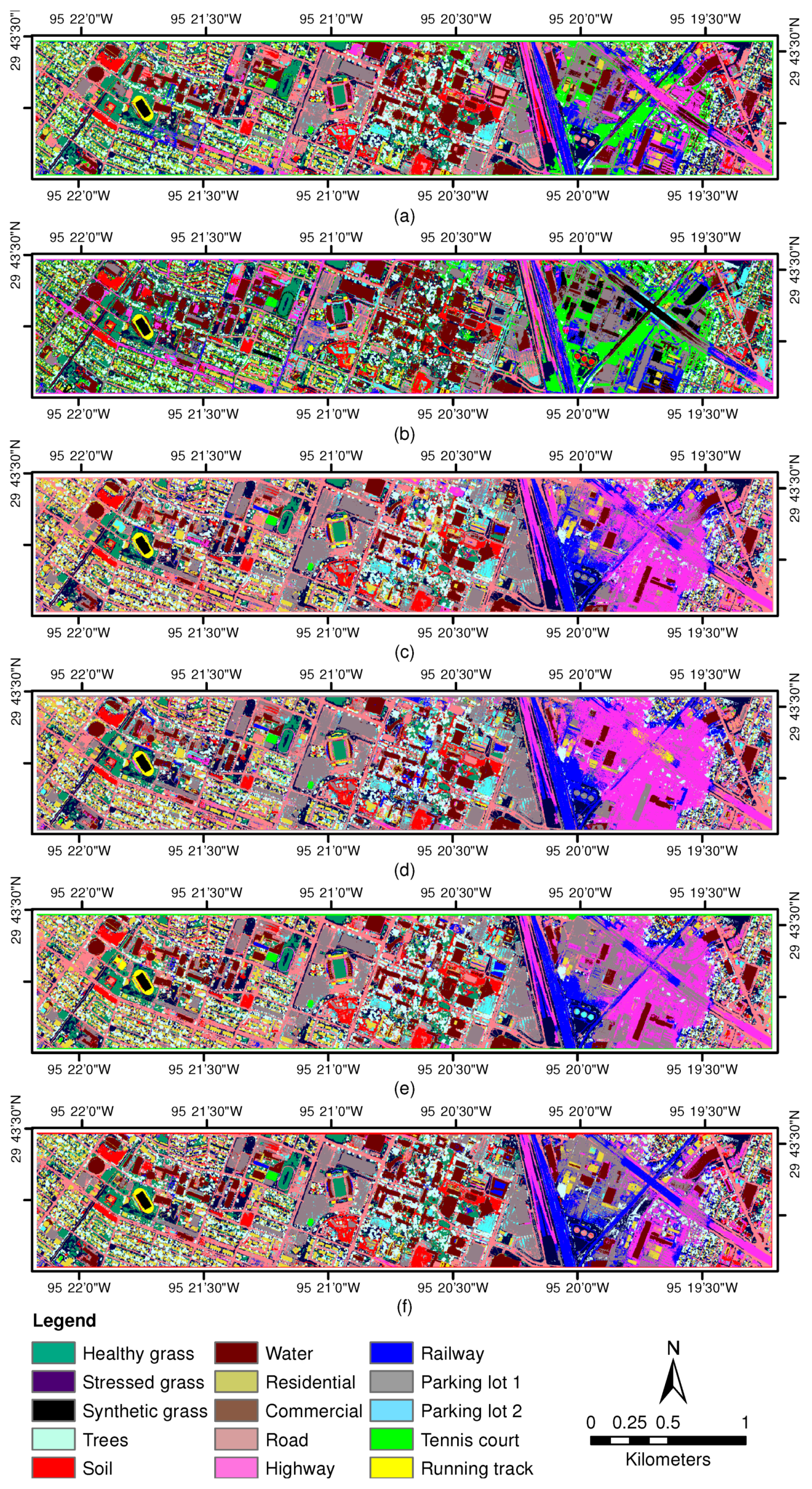
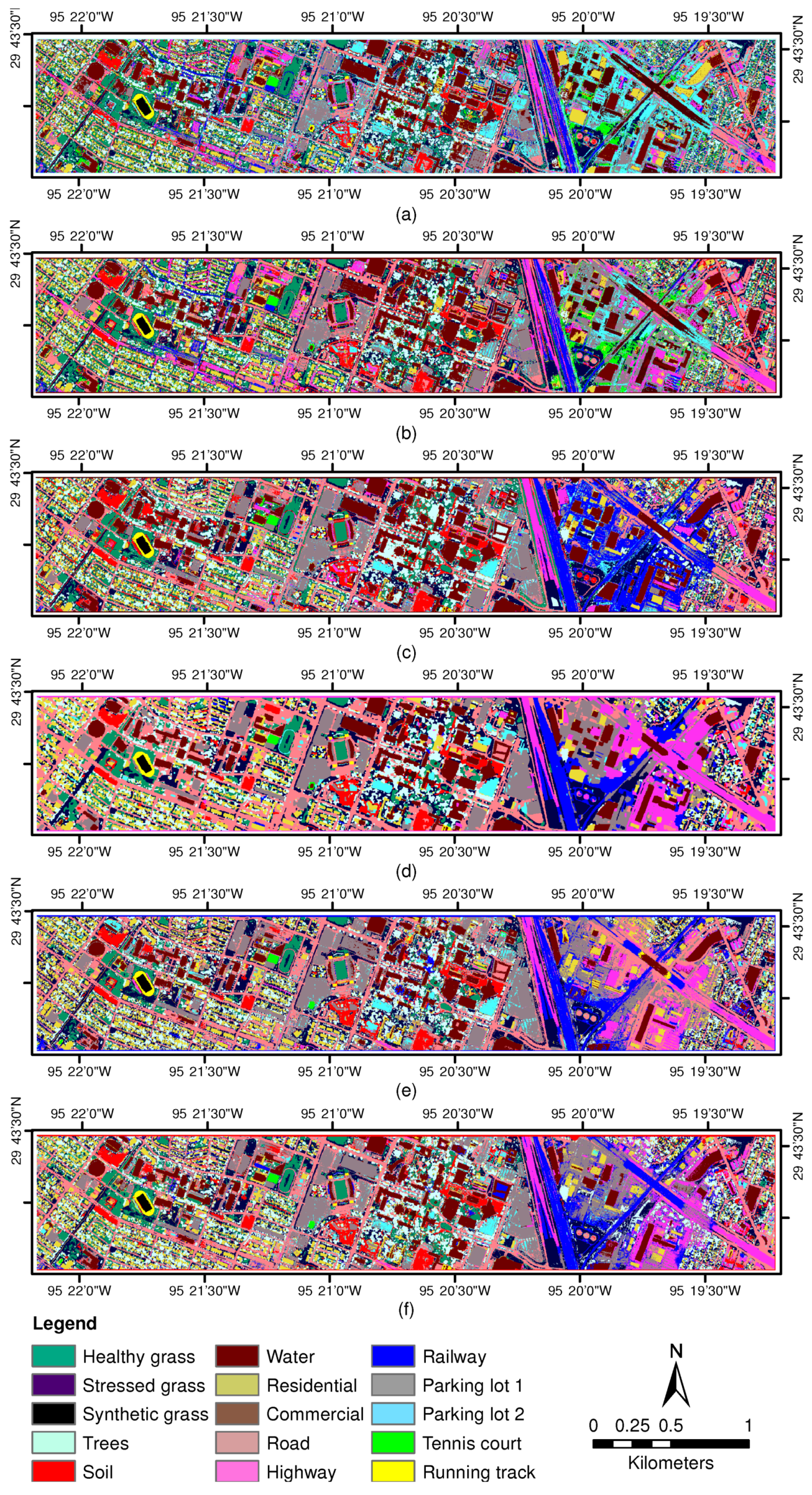
3.2. Experiments With University of Houston Data Sets
3.2.1. Experiment 1—Parameter Sensitiveness Analysis
3.2.2. Experiment 2—Comparison with DR-Based Methods
3.2.3. Experiment 3—Comparison with Independent Third-Order Tensor Factorization
3.2.4. Experiment 4—Comparison with Different Classifiers Based on CHOTF-Derived Features
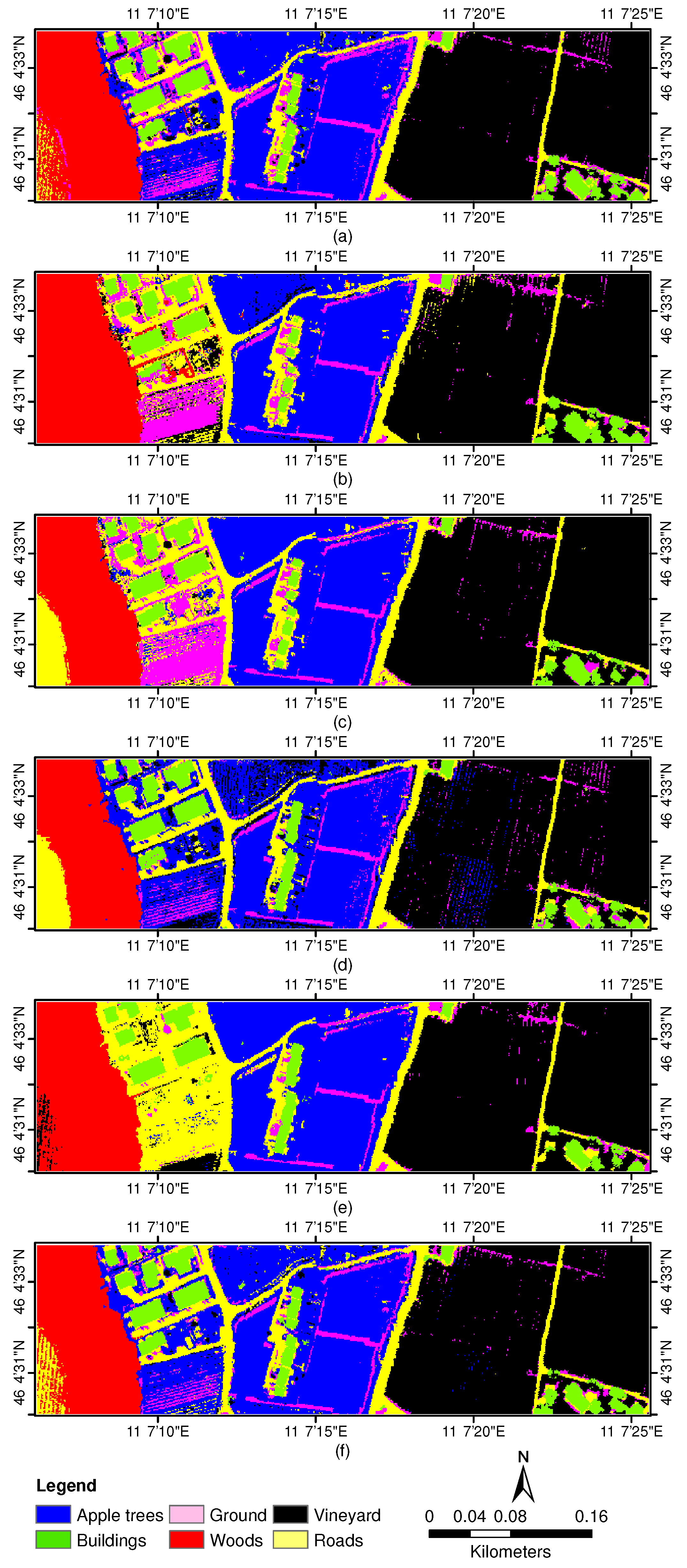
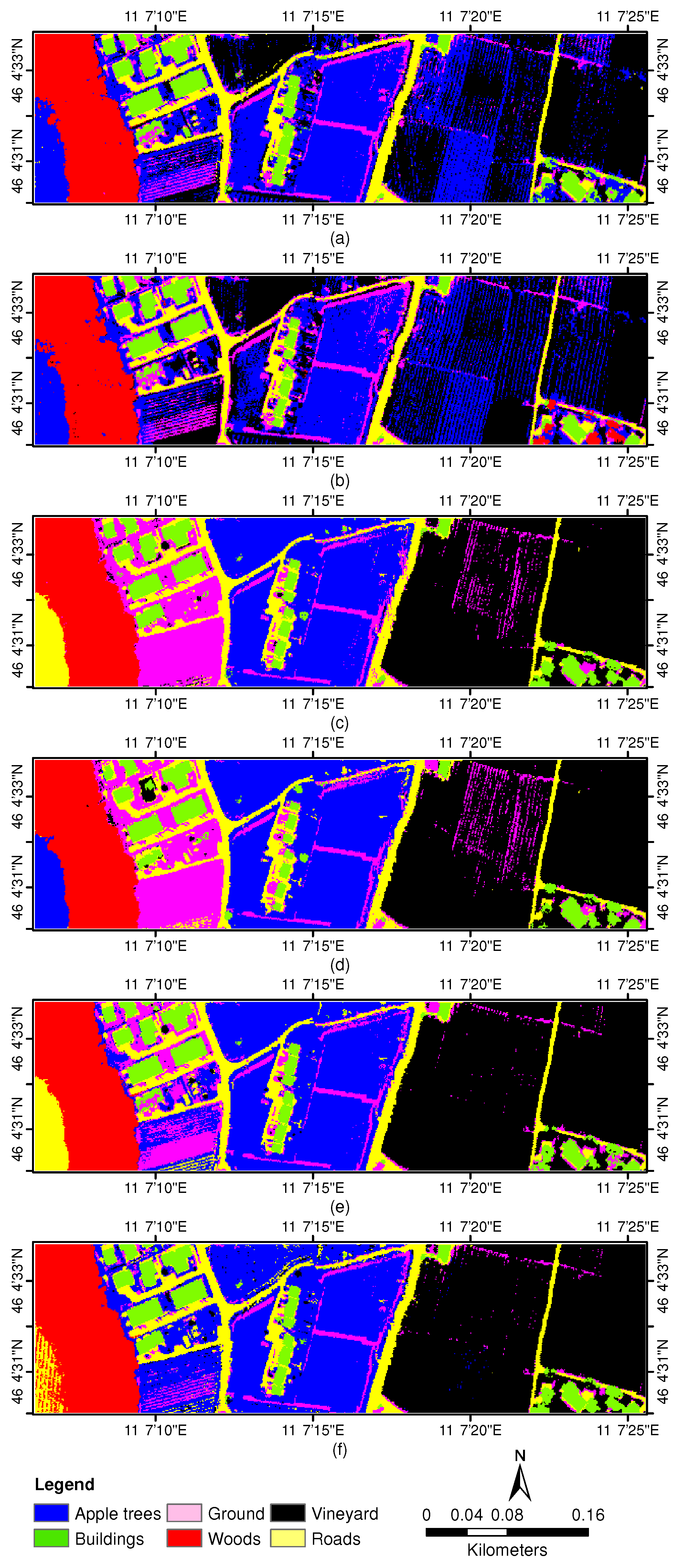
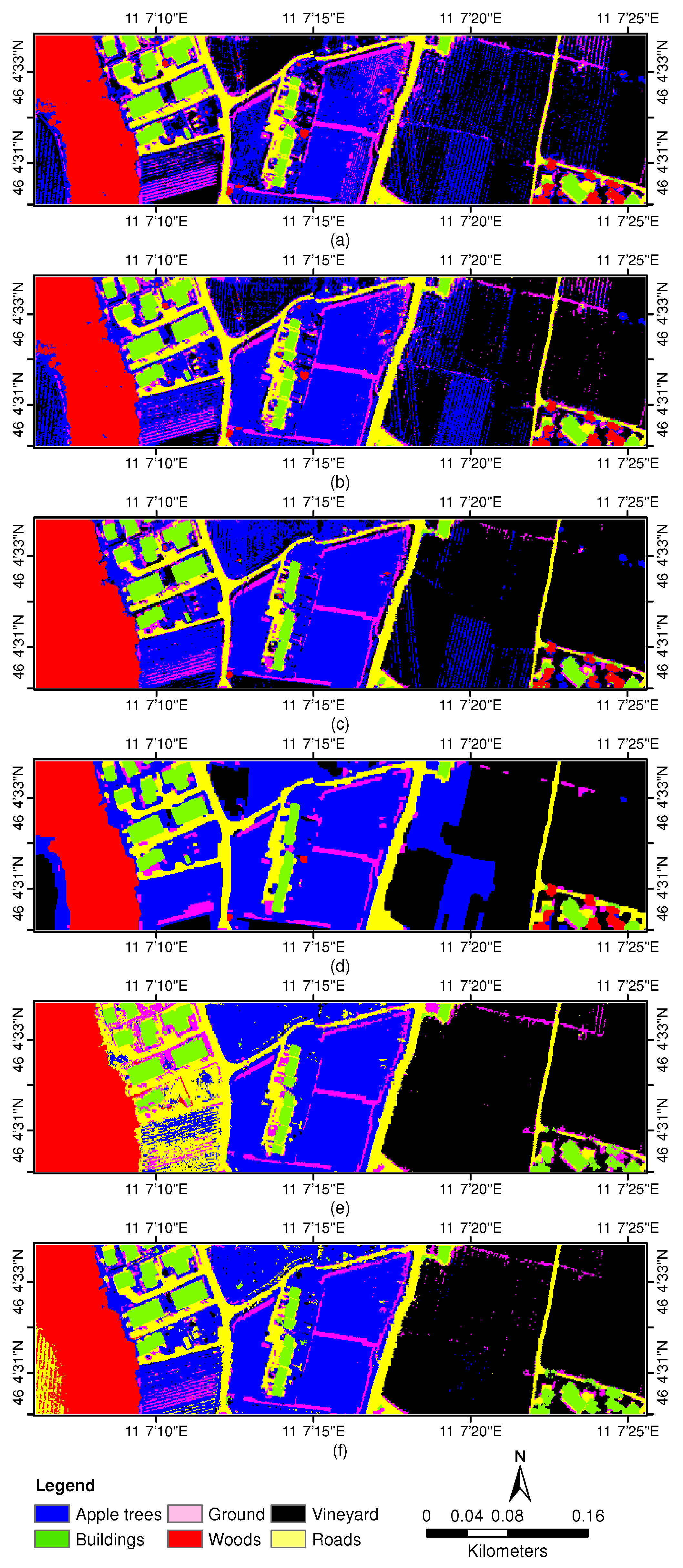
3.3. Experiments With Trento Data Sets
3.3.1. Experiment 1—Parameter Sensitiveness Analysis
3.3.2. Experiment 2—Comparison with DR-Based Methods
3.3.3. Experiment 3—Comparison with Independent Third-Order Tensor Factorization
3.3.4. Experiment 4—Comparison with Different Classifiers Based on CHOTF-Derived Features
4. Discussion
4.1. For the University of Houston Data Sets
4.2. For the Trento Data Sets
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mura, M.D.; Prasad, S.; Pacifici, F.; Gamba, P.; Chanussot, J.; Benediktsson, J.A. Challenges and opportunities of multimodality and data fusion in remote sensing. Proc. IEEE 2015, 103, 1585–1601. [Google Scholar] [CrossRef]
- Gomez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; van Kasteren, T.; Liao, W.Z.; Bellens, R.; Pizurica, A.; Gautama, S.; et al. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2405–2418. [Google Scholar] [CrossRef]
- Pedergnana, M.; Marpu, P.R.; Mura, M.D.; Benediktsson, J.A.; Bruzzone, L. Classification of remote sensing optical and LiDAR data using extended attribute profiles. IEEE J. Sel. Top. Signal Process. 2012, 6, 856–865. [Google Scholar] [CrossRef]
- Khodadadzadeh, M.; Li, J.; Prasad, S.; Plaza, A. Fusion of hyperspectral and LiDAR remote sensing data using multiple feature learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2971–2983. [Google Scholar] [CrossRef]
- Luo, R.B.; Liao, W.Z.; Zhang, H.Y.; Zhang, L.P.; Scheunders, P.; Pi, Y.G.; Philips, W. Fusion of hyperspectral and LiDAR data for classification of cloud-shadow mixed remote sensed scene. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3768–3781. [Google Scholar] [CrossRef]
- Chen, Y.S.; Li, C.Y.; Ghamisi, P.; Jia, X.P.; Gu, Y.F. Deep fusion of remote sensing data for accurate classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1253–1257. [Google Scholar] [CrossRef]
- Wang, A.L.; He, X.; Ghamisi, P.; Chen, Y.S. LiDAR Data classification using morphological profiles and convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 774–778. [Google Scholar] [CrossRef]
- Jahan, F.; Zhou, J.; Awrangjeb, M.; Gao, Y.S. Fusion of hyperspectral and LiDAR data using discriminant correlation analysis for land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3905–3917. [Google Scholar] [CrossRef]
- Liao, W.Z.; Pizurica, A.; Bellens, R.; Gautama, S.; Philips, W. Generalized graph-based fusion of hyperspectral and LiDAR data using morphological features. IEEE Geosci. Remote Sens. Lett. 2015, 12, 552–556. [Google Scholar] [CrossRef]
- Gu, Y.F.; Wang, Q.W. Discriminative graph-based fusion of HSI and LiDAR data for urban area classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 906–910. [Google Scholar] [CrossRef]
- Xia, J.S.; Yokoya, N.; Iwasaki, A. Fusion of hyperspectral and LiDAR data with a novel ensemble classifier. IEEE Geosci. Remote Sens. Lett. 2018, 15, 957–961. [Google Scholar] [CrossRef]
- Ghamisi, P.; Hofle, B.; Zhu, X.X. Hyperspectral and LiDAR data fusion using extinction profiles and deep convolutional neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3011–3024. [Google Scholar] [CrossRef]
- Rasti, B.; Ghamisi, P.; Gloaguen, R. Hyperspectral and LiDAR fusion using extinction profiles and total variation component analysis. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3997–4007. [Google Scholar] [CrossRef]
- Li, H.; Ghamisi, P.; Soergel, U.; Zhu, X.X. Hyperspectral and LiDAR fusion using deep three-stream convolutional neural networks. Remote Sens. 2018, 10, 1649. [Google Scholar] [CrossRef]
- Ghamisi, P.; Rash, B.; Benediktsson, J.A. Multisensor composite kernels based on extreme learning machines. IEEE Geosci. Remote Sens. Lett. 2019, 16, 196–200. [Google Scholar] [CrossRef]
- Ni, L.; Gao, L.R.; Li, S.S.; Li, J.; Zhang, B. Edge-constrained Markov random field classification by integrating hyperspectral image with LiDAR data over urban areas. J. Appl. Remote Sens. 2014, 8, 085089. [Google Scholar] [CrossRef]
- Yokoya, N.; Nakazawa, S.; Matsuki, T.; Iwasaki, A. Fusion of hyperspectral and LiDAR data for landscape visual quality assessment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2419–2425. [Google Scholar] [CrossRef]
- Zhang, Y.; Prasad, S. Multisource geospatial data fusion via local joint sparse representation. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3265–3276. [Google Scholar] [CrossRef]
- Rasti, B.; Ghamisi, P.; Plaza, J.; Plaza, A. Fusion of hyperspectral and LiDAR data using sparse and low-rank component analysis. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6354–6365. [Google Scholar] [CrossRef]
- Bigdeli, B.; Samadzadegan, F.; Reinartz, P. Feature grouping-based multiple fuzzy classifier system for fusion of hyperspectral and LiDAR data. J. Appl. Remote Sens. 2014, 8, 083509. [Google Scholar] [CrossRef]
- Bigdeli, B.; Samadzadegan, F.; Reinartz, P. Fusion of hyperspectral and LiDAR data using decision template-based fuzzy multiple classifier system. Int. J. Appl. Earth Obse. Geoinf. 2015, 38, 309–320. [Google Scholar] [CrossRef]
- Gu, Y.F.; Wang, Q.W.; Jia, X.P.; Benediktsson, J.A. A novel MKL model of integrating LiDAR data and MSI for urban area classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5312–5326. [Google Scholar]
- Zhang, Y.; Yang, H.L.; Prasad, S.; Pasolli, E.; Jung, J.; Crawford, M. Ensemble multiple kernel active learning for classification of multisource remote sensing data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 845–858. [Google Scholar] [CrossRef]
- Zhang, Y.; Prasad, S. Locality preserving composite kernel feature extraction for multi-source geospatial image analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1385–1392. [Google Scholar] [CrossRef]
- Liu, X.L.; Bo, Y.C. Object-based crop species classification based on the combination of airborne hyperspectral images and LiDAR data. Remote Sens. 2015, 7, 922–950. [Google Scholar] [CrossRef]
- Man, Q.; Dong, P.; Guo, H. Pixel- and feature-level fusion of hyperspectral and LiDAR data for urban land-use classification. Int. J. Remote Sens. 2015, 36, 1618–1644. [Google Scholar] [CrossRef]
- Zhong, Z.S.; Fan, B.; Ding, K.; Li, H.C.; Xiang, S.M.; Pan, C.H. Efficient multiple feature fusion with hashing for hyperspectral imagery classification: A comparative study. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4461–4478. [Google Scholar] [CrossRef]
- Xu, X.D.; Li, W.; Ran, Q.; Du, Q.; Gao, L.R.; Zhang, B. Multisource remote sensing data classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 937–949. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q.; Gao, L.; Zhang, B. Feature extraction for classification of hyperspectral and LiDAR data using patch-to-patch CNN. IEEE Trans. Cybern. 2019, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Makantasis, K.; Doulamis, A.D.; Doulamis, N.D.; Nikitakis, A. Tensor-based classification models for hyperspectral data analysis. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6884–6898. [Google Scholar] [CrossRef]
- Vervliet, N.; Debals, O.; Sorber, L.; De Lathauwer, L. Breaking the curse of dimensionality using decompositions of incomplete tensors. IEEE Signal Process. Mag. 2014, 31, 71–79. [Google Scholar] [CrossRef]
- Li, Q.; Schonfeld, D. Multilinear discriminant analysis for higher-order tensor data classification. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2524–2537. [Google Scholar] [PubMed]
- Zhong, Z.S.; Fan, B.; Duan, J.Y.; Wang, L.F.; Ding, K.; Xiang, S.M.; Pan, C.H. Discriminant tensor spectral-spatial feature extraction for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1028–1032. [Google Scholar] [CrossRef]
- He, Z.; Li, J.; Liu, L.; Liu, K.; Zhuo, L. Fast three-dimensional empirical mode decomposition of hyperspectral images for class-oriented multitask learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6625–6643. [Google Scholar] [CrossRef]
- Yang, L.X.; Wang, M.; Yang, S.Y.; Zhao, H.; Jiao, L.C.; Feng, X.C. Hybrid probabilistic sparse coding with spatial neighbor tensor for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2491–2502. [Google Scholar] [CrossRef]
- Fan, H.Y.; Li, C.; Guo, Y.L.; Kuang, G.Y.; Ma, J.Y. Spatial-spectral total variation regularized low-rank tensor decomposition for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6196–6213. [Google Scholar] [CrossRef]
- An, J.L.; Zhang, X.R.; Zhou, H.Y.; Jiao, L.C. Tensor-based low-rank graph with multimanifold regularization for dimensionality reduction of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4731–4746. [Google Scholar] [CrossRef]
- Li, S.T.; Dian, R.W.; Fang, L.Y.; Bioucas-Dias, J.M. Fusing hyperspectral and multispectral images via coupled sparse tensor factorization. IEEE Trans. Image Process. 2018, 27, 4118–4130. [Google Scholar] [CrossRef]
- Zhang, X.; Wen, G.J.; Dai, W. A tensor decomposition-based anomaly detection algorithm for hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5801–5820. [Google Scholar] [CrossRef]
- Liu, Y.J.; Gao, G.M.; Gu, Y.F. Tensor matched subspace detector for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1967–1974. [Google Scholar] [CrossRef]
- Qian, Y.T.; Xiong, F.C.; Zeng, S.; Zhou, J.; Tang, Y.Y. Matrix-vector nonnegative tensor factorization for blind unmixing of hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1776–1792. [Google Scholar] [CrossRef]
- Cichocki, A.; Mandic, D.P.; Phan, A.H.; Caiafa, C.F.; Zhou, G.X.; Zhao, Q.B.; De Lathauwer, L. Tensor decompositions for signal processing applications. IEEE Signal Process. Mag. 2015, 32, 145–163. [Google Scholar] [CrossRef]
- Acar, E.; Papalexakis, E.E.; Gurdeniz, G.; Rasmussen, M.A.; Lawaetz, A.J.; Nilsson, M.; Bro, R. Structure-revealing data fusion. BMC Bioinform. 2014, 15, 239. [Google Scholar] [CrossRef]
- Lahat, D.; Adali, T.; Jutten, C. Multimodal data fusion: An overview of methods, challenges, and prospects. Proc. IEEE 2015, 103, 1449–1477. [Google Scholar] [CrossRef]
- Acar, E.; Rasmussen, M.A.; Savorani, F.; Næs, T.; Bro, R. Understanding data fusion within the framework of coupled matrix and tensor factorizations. Chemom. Intell. Lab. Syst. 2013, 129, 53–63. [Google Scholar] [CrossRef]
- Sorber, L.; Van Barel, M.; De Lathauwer, L. Structured data fusion. IEEE J. Sel. Top. Signal Process. 2015, 9, 586–600. [Google Scholar] [CrossRef]
- Pesaresi, M.; Benediktsson, J.A. A new approach for the morphological segmentation of high-resolution satellite imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 309–320. [Google Scholar] [CrossRef] [Green Version]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Benediktsson, J.A.; Waske, B.; Bruzzone, L. Morphological attribute profiles for the analysis of very high resolution images. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3747–3762. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Benediktsson, J.A.; Waske, B.; Bruzzone, L. Extended profiles with morphological attribute filters for the analysis of hyperspectral data. Int. J. Remote Sens. 2010, 31, 5975–5991. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Krishnapuram, B.; Carin, L.; Figueiredo, M.A.T.; Hartemink, A.J. Sparse multinomial logistic regression: Fast algorithms and generalization bounds. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 957–968. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Hyperspectral image segmentation using a new Bayesian approach with active learning. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3947–3960. [Google Scholar] [CrossRef]
- Xue, Z.H.; Li, J.; Cheng, L.; Du, P.J. Spectral-spatial classification of hyperspectral data via morphological component analysis-based image separation. IEEE Trans. Geosci. Remote Sens. 2015, 53, 70–84. [Google Scholar]
- Du, P.J.; Xue, Z.H.; Li, J.; Plaza, A. Learning discriminative sparse representations for hyperspectral image classification. IEEE J. Sel. Top. Signal Process. 2015, 9, 1089–1104. [Google Scholar] [CrossRef]
- Xue, Z.H.; Du, P.J.; Li, J.; Su, H.J. Simultaneous sparse graph embedding for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6114–6133. [Google Scholar] [CrossRef]
- Xue, Z.H.; Du, P.J.; Li, J.; Su, H.J. Sparse graph regularization for hyperspectral remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2351–2366. [Google Scholar] [CrossRef]
- Xue, Z.H.; Du, P.J.; Li, J.; Su, H.J. Sparse graph regularization for robust crop mapping using hyperspectral remotely sensed imagery with very few in situ data. ISPRS J. Photogramm. Remote Sens. 2017, 124, 1–15. [Google Scholar] [CrossRef]
- Zhou, S.G.; Xue, Z.H.; Du, P.J. Semisupervised stacked autoencoder with cotraining for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1–14. [Google Scholar] [CrossRef]
- Sorber, L.; Van Barel, M.; De Lathauwer, L. Optimization-based algorithms for tensor decompositions: Canonical polyadic decomposition, decomposition in rank-(Lr,Lr,1) terms, and a new generalization. SIAM J. Optim. 2013, 23, 695–720. [Google Scholar] [CrossRef]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Phan, A.H.; Cichocki, A. Tensor decompositions for feature extraction and classification of high dimensional datasets. Nonlinear Theory Appl. IEICE 2010, 1, 37–68. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral-spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Li, J.; Marpu, P.R.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A. Generalized composite kernel framework for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4816–4829. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | #Samples | |
|---|---|---|
| Train | Test | |
| Healthy grass | 198 | 1053 |
| Stressed grass | 190 | 1064 |
| Synthetic grass | 192 | 505 |
| Trees | 188 | 1056 |
| Soil | 186 | 1056 |
| Water | 182 | 143 |
| Residential | 196 | 1072 |
| Commercial | 191 | 1053 |
| Road | 193 | 1059 |
| Highway | 191 | 1036 |
| Railway | 181 | 1054 |
| Parking lot 1 | 192 | 1041 |
| Parking lot 2 | 184 | 285 |
| Tennis court | 181 | 247 |
| Running track | 187 | 473 |
| Total | 2832 | 12197 |
| Class | #Samples | |
|---|---|---|
| Train | Test | |
| Apple trees | 129 | 4034 |
| Buildings | 125 | 2903 |
| Ground | 105 | 479 |
| Woods | 154 | 9123 |
| Vineyard | 184 | 10501 |
| Roads | 122 | 3174 |
| Total | 819 | 30214 |
| Class | PCA | LGE | LPP | LDA | MFA | CHOTF |
|---|---|---|---|---|---|---|
| Healthy grass | 83.10 | 82.81 | 83.10 | 83.00 | 83.10 | 83.00 |
| Stressed grass | 97.18 | 84.40 | 85.06 | 98.68 | 84.87 | 95.68 |
| Synthetic grass | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Trees | 93.37 | 95.45 | 84.09 | 90.06 | 88.54 | 95.83 |
| Soil | 99.91 | 100.00 | 100.00 | 99.91 | 100.00 | 99.91 |
| Water | 100.00 | 99.30 | 99.30 | 95.10 | 98.60 | 95.10 |
| Residential | 95.62 | 88.06 | 82.93 | 83.40 | 87.87 | 89.93 |
| Commercial | 55.94 | 75.69 | 57.64 | 54.13 | 60.21 | 82.43 |
| Road | 95.47 | 94.05 | 93.96 | 94.33 | 97.26 | 94.43 |
| Highway | 57.24 | 59.07 | 67.76 | 90.54 | 68.15 | 68.24 |
| Railway | 99.05 | 93.93 | 98.96 | 85.96 | 99.72 | 99.15 |
| Parking lot 1 | 93.28 | 97.89 | 85.49 | 91.45 | 85.98 | 96.06 |
| Parking lot 2 | 80.00 | 83.16 | 78.25 | 78.60 | 74.74 | 80.70 |
| Tennis court | 100.00 | 100.00 | 100.00 | 99.60 | 100.00 | 99.60 |
| Running track | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 98.94 |
| Average accuracy | 90.01 | 90.25 | 87.77 | 89.65 | 88.60 | 91.93 |
| Overall accuracy | 88.37 | 88.51 | 85.59 | 88.32 | 86.96 | 91.24 |
| statistic | 0.874 | 0.875 | 0.844 | 0.873 | 0.858 | 0.905 |
| Class | CPD | LL1 | MLSVD | LMLRA | BTD | CHOTF |
|---|---|---|---|---|---|---|
| Healthy grass | 83.00 | 83.00 | 82.91 | 83.00 | 82.91 | 83.00 |
| Stressed grass | 81.67 | 80.36 | 84.30 | 84.12 | 83.93 | 95.68 |
| Synthetic grass | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Trees | 90.63 | 97.54 | 91.38 | 93.37 | 92.42 | 95.83 |
| Soil | 100.00 | 97.06 | 99.81 | 99.91 | 99.91 | 99.91 |
| Water | 97.20 | 95.80 | 99.30 | 95.80 | 95.10 | 95.10 |
| Residential | 92.91 | 81.62 | 85.91 | 84.79 | 87.59 | 89.93 |
| Commercial | 77.68 | 38.18 | 65.91 | 59.16 | 69.42 | 82.43 |
| Road | 81.02 | 49.48 | 95.18 | 94.43 | 93.58 | 94.43 |
| Highway | 67.86 | 31.27 | 73.65 | 69.69 | 70.46 | 68.24 |
| Railway | 93.26 | 81.02 | 92.69 | 87.38 | 93.74 | 99.15 |
| Parking lot 1 | 71.28 | 40.73 | 94.91 | 90.49 | 87.80 | 96.06 |
| Parking lot 2 | 68.77 | 37.89 | 77.54 | 80.00 | 79.30 | 80.70 |
| Tennis court | 100.00 | 100.00 | 100.00 | 99.60 | 100.00 | 99.60 |
| Running track | 98.94 | 97.04 | 99.58 | 99.79 | 98.94 | 98.94 |
| Average accuracy | 86.95 | 74.07 | 89.54 | 88.10 | 89.01 | 91.93 |
| Overall accuracy | 85.36 | 70.86 | 87.94 | 86.21 | 87.50 | 91.24 |
| statistic | 0.842 | 0.685 | 0.869 | 0.850 | 0.864 | 0.905 |
| Class | RF | SVM | MLRsub | LORSAL-MLL | MLR-GCK | SMLR |
|---|---|---|---|---|---|---|
| Healthy grass | 82.62 | 82.62 | 83.00 | 83.10 | 82.91 | 83.00 |
| Stressed grass | 81.48 | 82.71 | 92.86 | 86.18 | 84.96 | 95.68 |
| Synthetic grass | 99.60 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Trees | 93.75 | 95.36 | 98.96 | 94.51 | 88.45 | 95.83 |
| Soil | 96.88 | 98.48 | 100.00 | 100.00 | 99.91 | 99.91 |
| Water | 99.30 | 99.30 | 94.41 | 100.00 | 99.30 | 95.10 |
| Residential | 74.16 | 78.17 | 79.66 | 76.68 | 93.47 | 89.93 |
| Commercial | 68.09 | 69.33 | 90.22 | 82.15 | 68.85 | 82.43 |
| Road | 81.21 | 81.78 | 93.96 | 96.69 | 97.07 | 94.43 |
| Highway | 36.78 | 58.69 | 48.46 | 80.89 | 67.66 | 68.24 |
| Railway | 81.59 | 83.78 | 99.91 | 95.54 | 99.05 | 99.15 |
| Parking lot 1 | 64.36 | 81.08 | 98.75 | 98.66 | 99.42 | 96.06 |
| Parking lot 2 | 66.67 | 65.26 | 74.04 | 74.04 | 80.35 | 80.70 |
| Tennis court | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 99.60 |
| Running track | 97.46 | 98.94 | 100.00 | 100.00 | 99.79 | 98.94 |
| Average accuracy | 81.60 | 85.03 | 90.28 | 91.23 | 90.75 | 91.93 |
| Overall accuracy | 78.51 | 82.92 | 89.50 | 90.25 | 89.33 | 91.24 |
| statistic | 0.768 | 0.815 | 0.886 | 0.894 | 0.884 | 0.905 |
| Class | PCA | LGE | LPP | LDA | MFA | CHOTF |
|---|---|---|---|---|---|---|
| Apple trees | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Buildings | 98.00 | 93.39 | 97.31 | 98.79 | 82.78 | 98.62 |
| Ground | 96.45 | 94.36 | 93.53 | 95.82 | 73.70 | 95.62 |
| Woods | 99.95 | 99.99 | 99.97 | 99.70 | 99.97 | 99.91 |
| Vineyard | 99.80 | 99.80 | 99.63 | 98.40 | 99.70 | 99.75 |
| Roads | 89.48 | 94.27 | 92.66 | 91.34 | 96.22 | 91.15 |
| Average accuracy | 97.28 | 96.97 | 97.18 | 97.34 | 92.06 | 97.51 |
| Overall accuracy | 98.56 | 98.60 | 98.73 | 98.26 | 97.42 | 98.76 |
| statistic | 0.981 | 0.981 | 0.983 | 0.977 | 0.965 | 0.983 |
| Class | CPD | LL1 | MLSVD | LMLRA | BTD | CHOTF |
|---|---|---|---|---|---|---|
| Apple trees | 99.43 | 85.32 | 100.00 | 100.00 | 100.00 | 100.00 |
| Buildings | 95.83 | 93.63 | 97.97 | 89.29 | 94.94 | 98.62 |
| Ground | 96.45 | 97.49 | 95.82 | 95.62 | 95.82 | 95.62 |
| Woods | 99.19 | 98.41 | 99.90 | 99.84 | 99.93 | 99.91 |
| Vineyard | 91.07 | 77.28 | 96.21 | 94.61 | 99.78 | 99.75 |
| Roads | 89.22 | 87.52 | 88.15 | 90.04 | 89.48 | 91.15 |
| Average accuracy | 95.20 | 89.94 | 96.34 | 94.90 | 96.66 | 97.51 |
| Overall accuracy | 94.99 | 87.70 | 97.15 | 95.93 | 98.25 | 98.76 |
| statistic | 0.934 | 0.839 | 0.962 | 0.946 | 0.977 | 0.983 |
| Class | RF | SVM | MLRsub | LORSAL-MLL | MLR-GCK | SMLR |
|---|---|---|---|---|---|---|
| Apple trees | 89.86 | 99.85 | 100.00 | 100.00 | 100.00 | 100.00 |
| Buildings | 97.28 | 97.52 | 98.83 | 98.28 | 97.73 | 98.62 |
| Ground | 95.20 | 96.24 | 94.99 | 96.24 | 95.20 | 95.62 |
| Woods | 99.32 | 99.18 | 99.65 | 99.87 | 99.98 | 99.91 |
| Vineyard | 85.02 | 95.67 | 98.00 | 100.00 | 99.96 | 99.75 |
| Roads | 91.34 | 89.51 | 88.59 | 92.75 | 91.75 | 91.15 |
| Average accuracy | 93.00 | 96.33 | 96.68 | 97.86 | 97.44 | 97.51 |
| Overall accuracy | 91.99 | 96.83 | 97.81 | 98.97 | 98.82 | 98.76 |
| statistic | 0.894 | 0.958 | 0.971 | 0.986 | 0.984 | 0.983 |
| Methods | Average Accuracy | Overall Accuracy | Statistic | Elapsed Time |
|---|---|---|---|---|
| GGF [10] | 83.03 | 80.48 | 0.788 | 34 s |
| EP+CNN [13] | 90.39 | 89.71 | 0.888 | ∼700 s |
| Deep Fusion [7] | 85.31 | 90.60 | 0.898 | |
| two-branch CNN [29] | 90.11 | 87.98 | 0.870 | |
| three-stream CNN [15] | 84.36 | 90.22 | 0.894 | |
| HyMCKs [16] | 91.14 | 90.33 | 0.895 | - |
| HODA [63] | 88.79 | 87.05 | 0.860 | 18 s |
| LTDA [34] | 88.83 | 87.12 | 0.860 | 60 s |
| CHOTF (ours) | 91.93 | 91.24 | 0.905 | 254 s |
| Methods | Average Accuracy | Overall Accuracy | Statistic | Elapsed Time |
|---|---|---|---|---|
| GGF [10] | 78.23 | 77.98 | 0.717 | 15 s |
| EP+CNN [13] | 98.40 | 98.85 | 0.985 | ∼500 s |
| Deep Fusion [7] | 77.17 | 97.83 | 0.971 | |
| two-branch CNN [29] | 96.19 | 97.92 | 0.968 | |
| three-stream CNN [15] | 79.47 | 97.91 | 0.973 | |
| HyMCKs [16] | 98.18 | 98.97 | 0.986 | - |
| HODA [63] | 97.19 | 98.76 | 0.972 | 3 s |
| LTDA [34] | 90.29 | 92.73 | 0.903 | 15 s |
| CHOTF (ours) | 97.51 | 98.76 | 0.983 | 144 s |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, Z.; Yang, S.; Zhang, H.; Du, P. Coupled Higher-Order Tensor Factorization for Hyperspectral and LiDAR Data Fusion and Classification. Remote Sens. 2019, 11, 1959. https://doi.org/10.3390/rs11171959
Xue Z, Yang S, Zhang H, Du P. Coupled Higher-Order Tensor Factorization for Hyperspectral and LiDAR Data Fusion and Classification. Remote Sensing. 2019; 11(17):1959. https://doi.org/10.3390/rs11171959
Chicago/Turabian StyleXue, Zhaohui, Sirui Yang, Hongyan Zhang, and Peijun Du. 2019. "Coupled Higher-Order Tensor Factorization for Hyperspectral and LiDAR Data Fusion and Classification" Remote Sensing 11, no. 17: 1959. https://doi.org/10.3390/rs11171959
APA StyleXue, Z., Yang, S., Zhang, H., & Du, P. (2019). Coupled Higher-Order Tensor Factorization for Hyperspectral and LiDAR Data Fusion and Classification. Remote Sensing, 11(17), 1959. https://doi.org/10.3390/rs11171959