


Partial-to-Partial Point Cloud Registration by Rotation Invariant Features and Spatial Geometric Consistency

Abstract
:1. Introduction
2. Related Work
2.1. Traditional Point Cloud Registration Methods
2.2. Correspondences-Free Methods
2.3. Correspondences-Learning Methods
2.4. Rotation-Invariant Descriptors
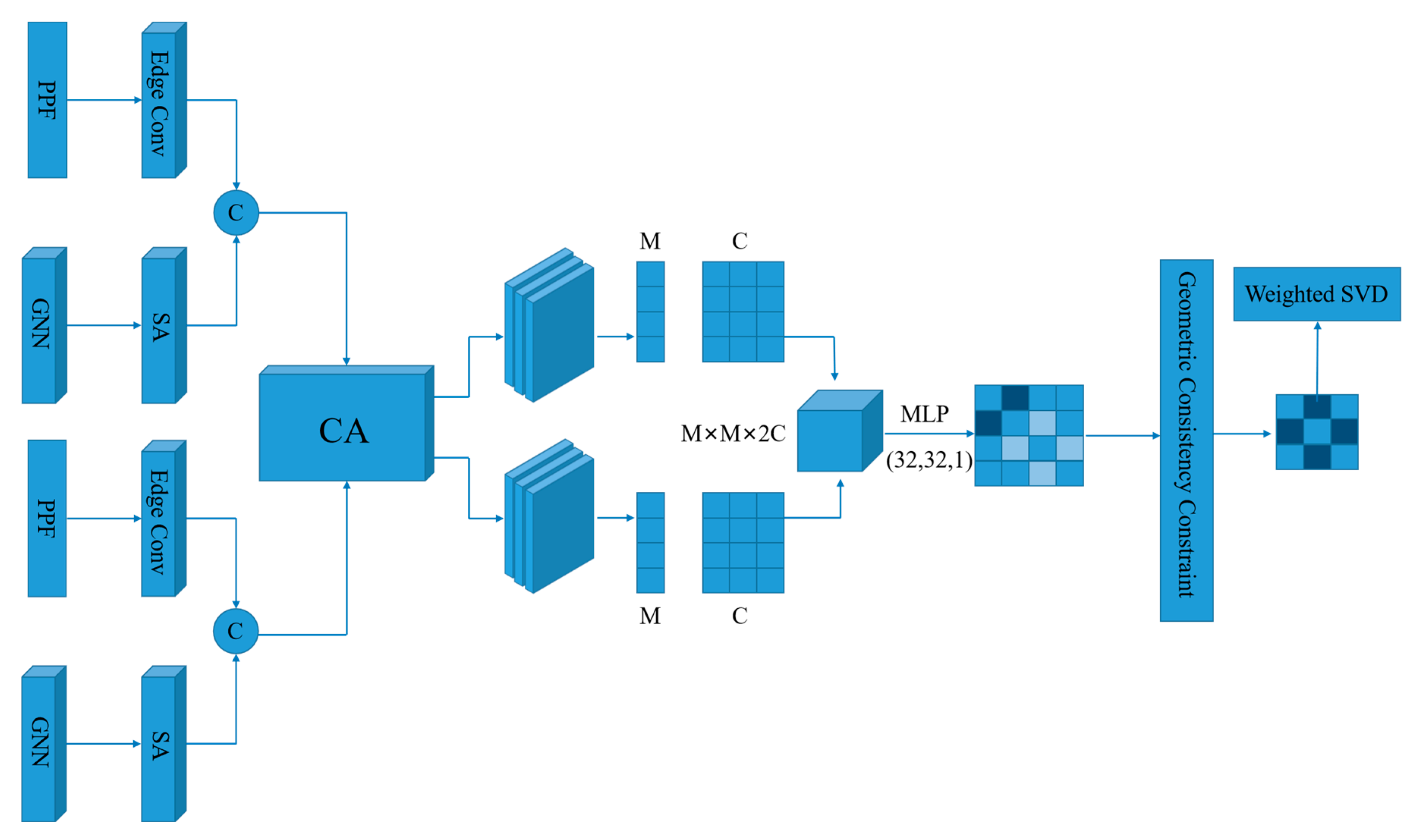
3. Method
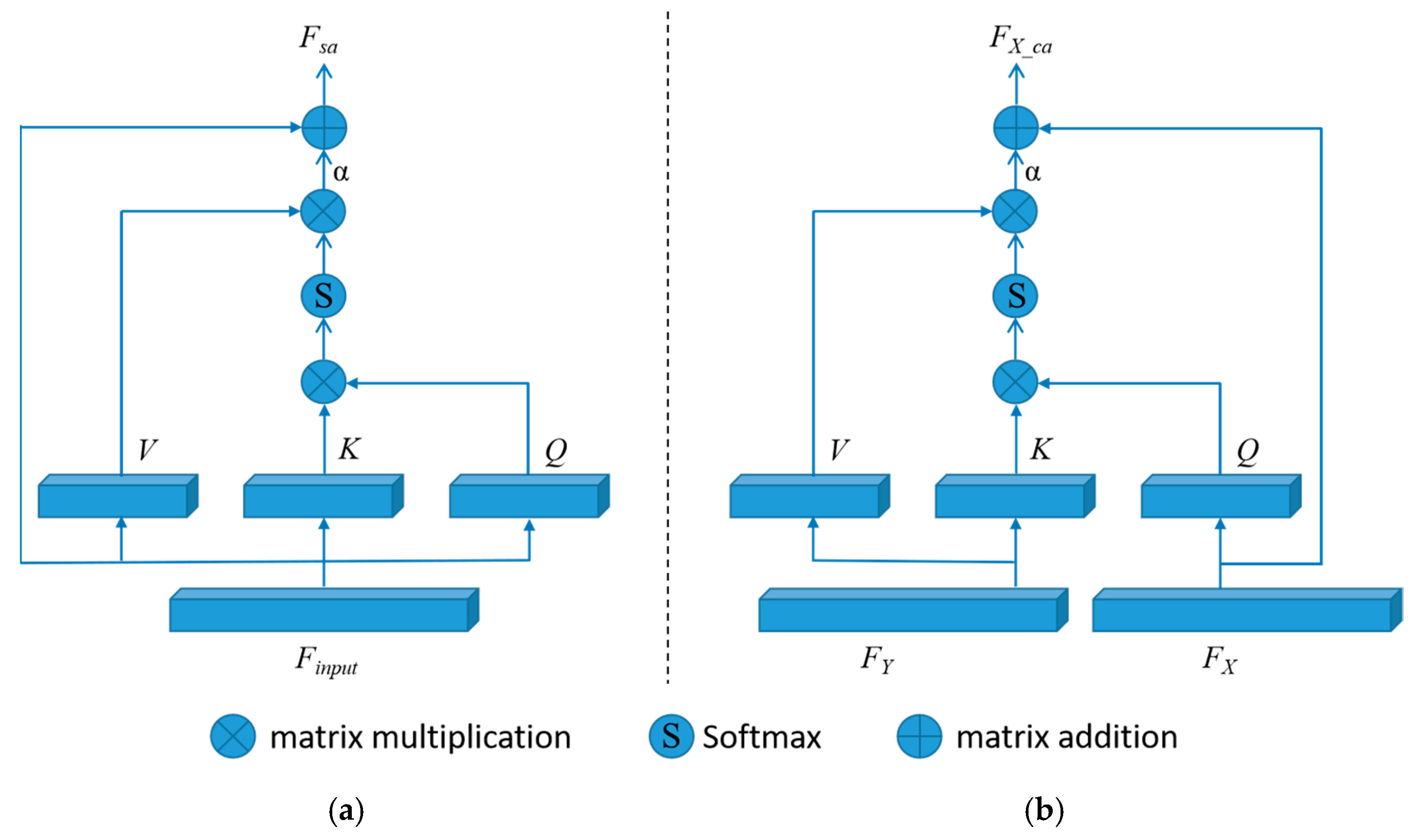
3.1. Feature Extraction Network
3.2. Key Points and Soft Matching
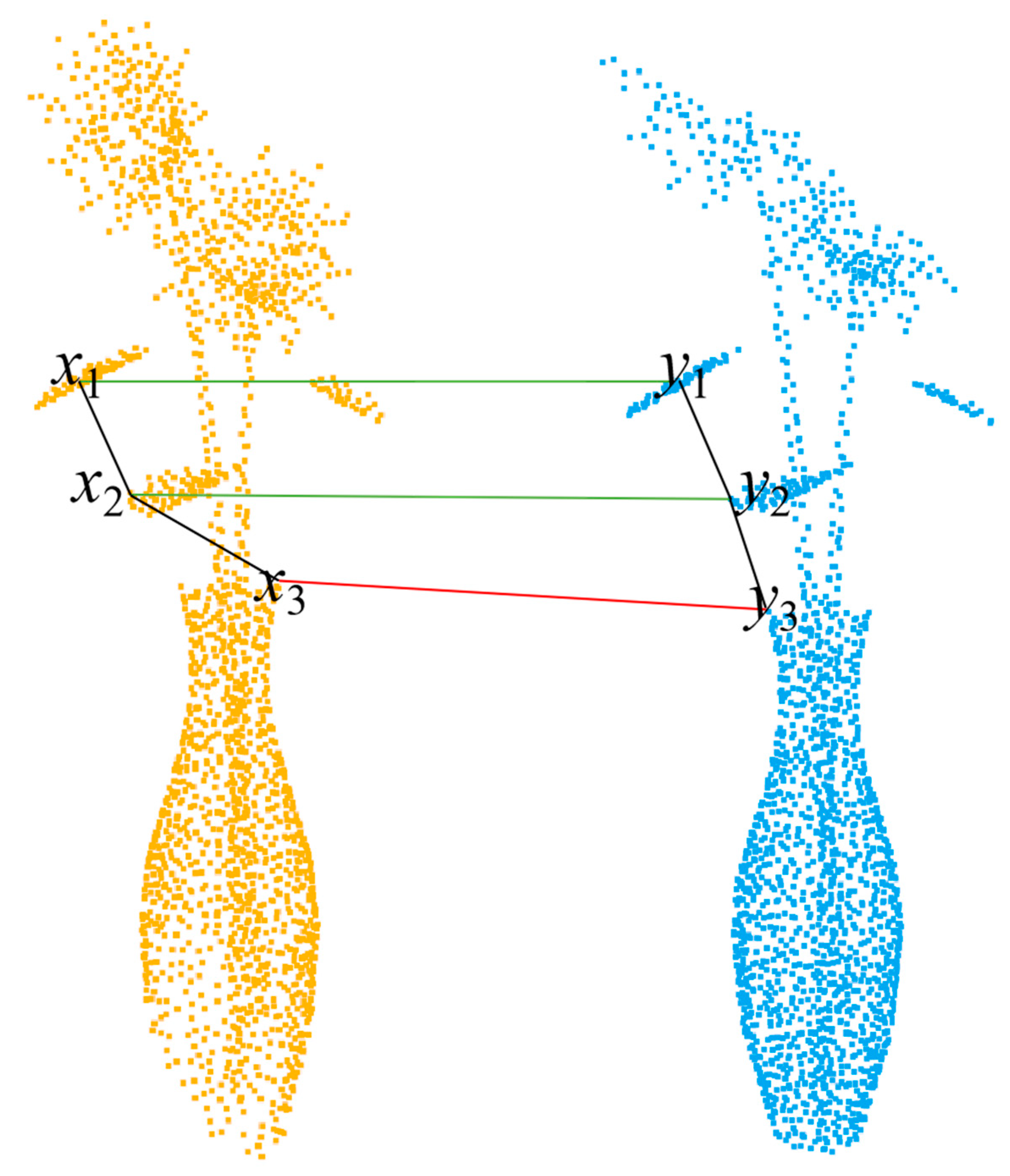
3.3. Spatial Geometric Consistency Constraint Module
3.4. Loss Functions
4. Results
4.1. ModelNet40
4.1.1. Unseen Shapes
4.1.2. Gaussian Noise
4.1.3. Partial Visibility
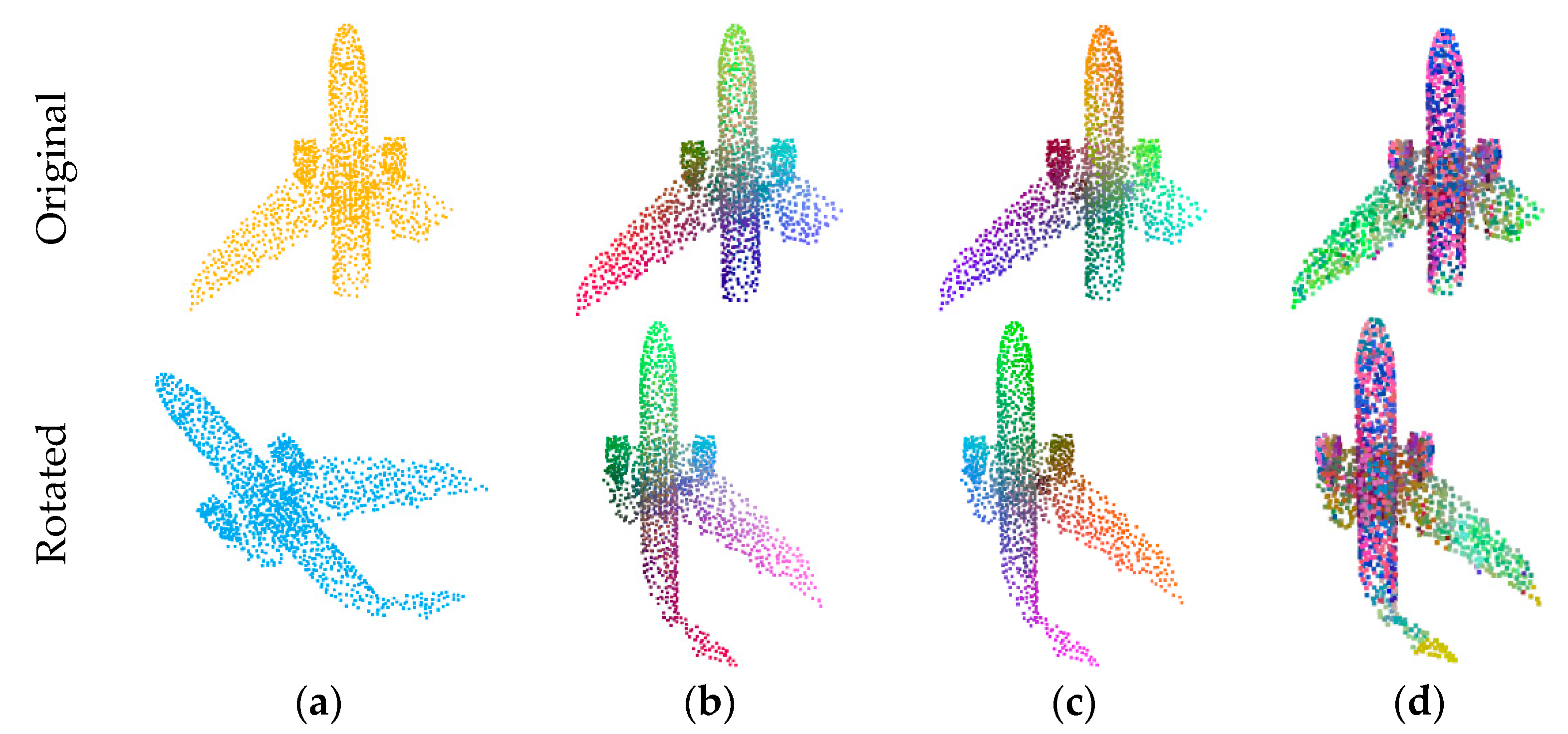
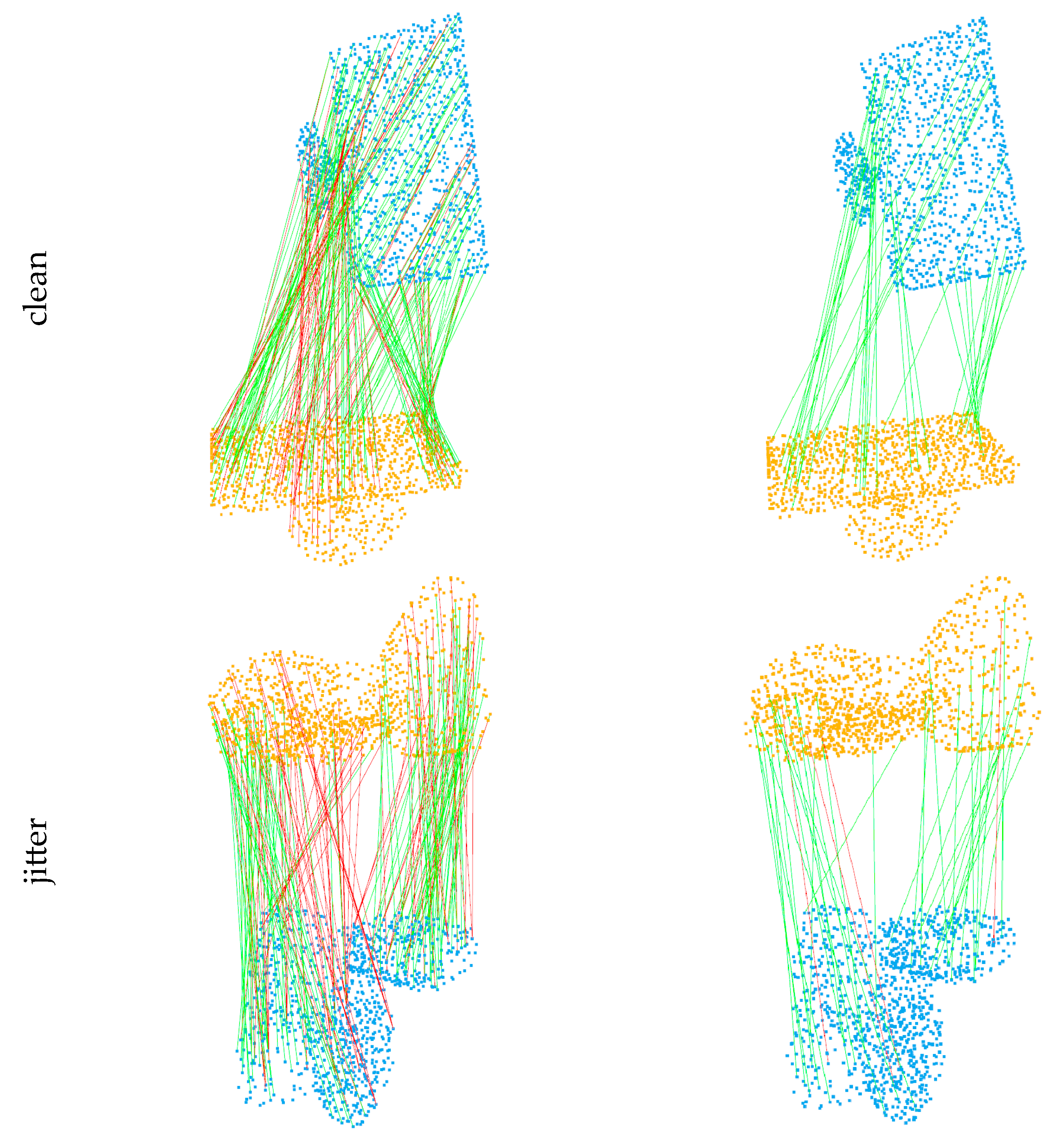
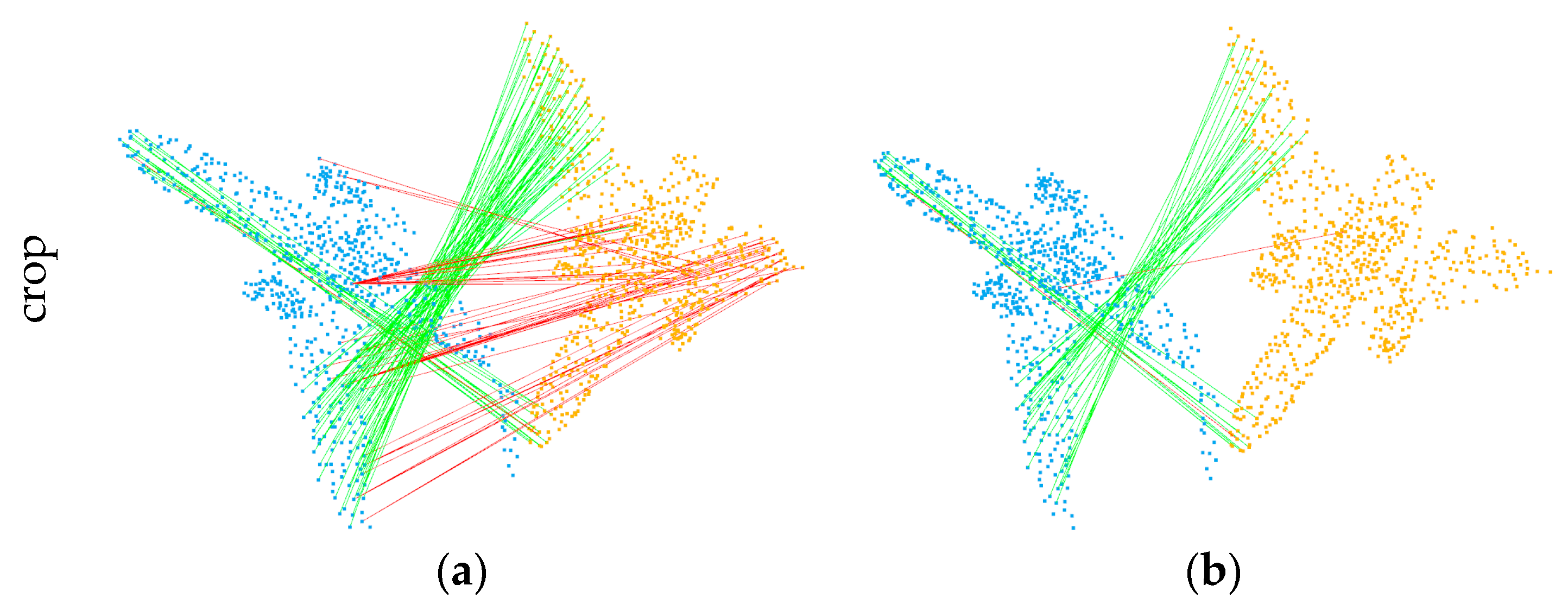
4.2. Key points and Correspondences
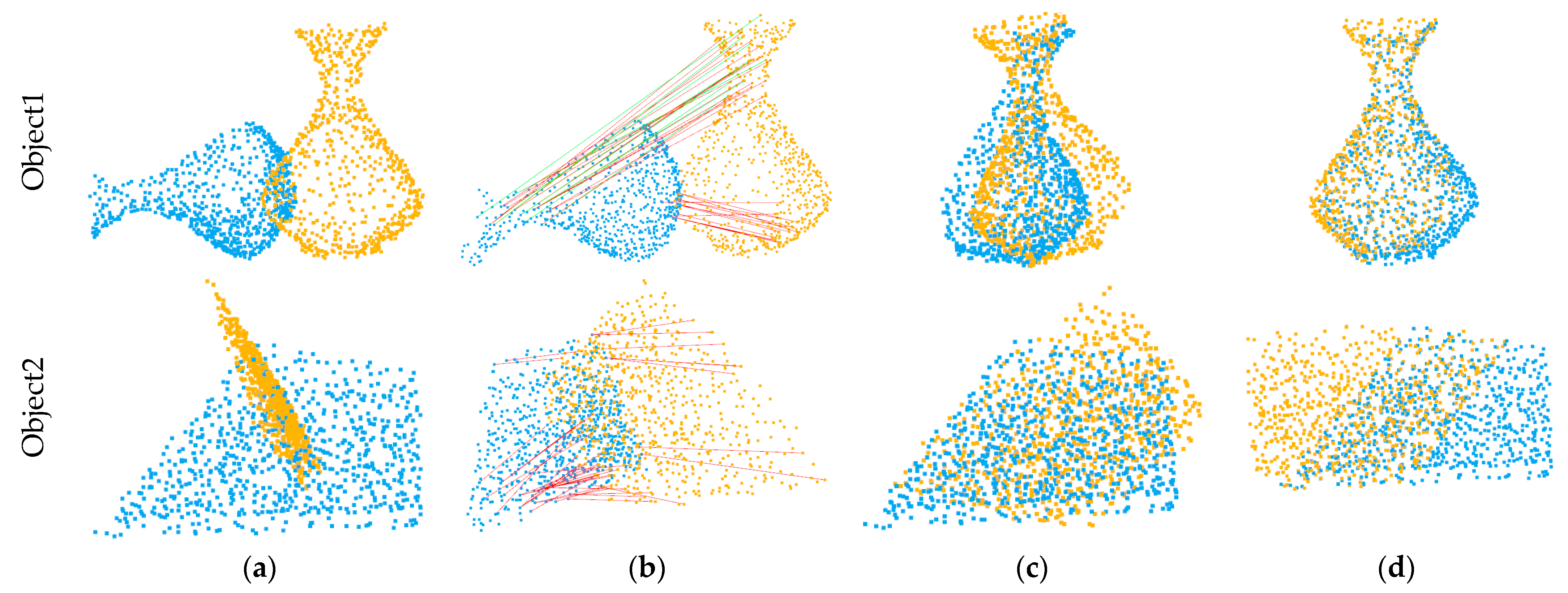
4.3. Real Data
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ICP | Iterative Closest Point |
| FGR | Fast Global Registration |
| DCP | Deep Closest Point |
| PPF | Point Pair Features |
| RANSAC | Singular Value Decomposition |
| FPFH | Fast Point Feature Histogram |
| SHOT | Signature of Histogram of Orientation |
| MLP | Multi-Layer Perceptron |
| DGCNN | Dynamic Graph CNN |
| GNN | Graph Neural Networks |
| K-NN | K-Nearest Neighbor |
| RMSE | Root Mean Square Error |
| MAE | Mean Absolute Error |
| SGC | Space Geometric Consistency |
| SA | Self-attention |
| CA | Cross-attention |
References
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. Kinectfusion: Real-time 3d reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on Utilizer Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 559–568. [Google Scholar]
- Eldefrawy, M.; King, S.A.; Starek, M. Partial Scene Reconstruction for Close Range Photogrammetry Using Deep Learning Pipeline for Region Masking. Remote Sens. 2022, 14, 3199. [Google Scholar] [CrossRef]
- Zhang, Z.; Dai, Y.; Sun, J. Deep learning based point cloud registration: An overview. Virtual Real. Intell. Hardw. 2020, 2, 222–246. [Google Scholar] [CrossRef]
- Chen, K.; Lopez, B.T.; Agha-Mohammadi, A.-A.; Mehta, A. Direct lidar odometry: Fast localization with dense point clouds. IEEE Robot. Autom. Lett. 2022, 7, 2000–2007. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, Y.; Yang, S.; Lu, H. Global-PBNet: A novel point cloud registration for autonomous driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22312–22319. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor Fusion IV: Control Paradigms and Data Structures, Boston, MA, USA, 12–15 November 1991; SPIE: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A globally optimal solution to 3D ICP point-set registration. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2241–2254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, Q.Y.; Park, J.; Koltun, V. Fast global registration. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 766–782. [Google Scholar]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. Pointnetlk: Robust & efficient point cloud registration using pointnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7163–7172. [Google Scholar]
- Sarode, V.; Li, X.; Goforth, H.; Aoki, Y.; Srivatsan, R.A.; Lucey, S.; Choset, H. Pcrnet: Point cloud registration network using pointnet encoding. arXiv 2019, arXiv:1908.07906. [Google Scholar]
- Xu, H.; Liu, S.; Wang, G.; Liu, G.; Zeng, B. Omnet: Learning overlapping mask for partial-to-partial point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3132–3141. [Google Scholar]
- Wang, Y.; Solomon, J.M. Deep closest point: Learning representations for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3523–3532. [Google Scholar]
- Wang, Y.; Solomon, J.M. Prnet: Self-supervised learning for partial-to-partial registration. arXiv 2019, arXiv:1910.12240. [Google Scholar]
- Yew, Z.J.; Lee, G.H. Rpm-net: Robust point matching using learned features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11824–11833. [Google Scholar]
- Li, J.; Zhang, C.; Xu, Z.; Zhou, H.; Zhang, C. Iterative distance-aware similarity matrix convolution with mutual-supervised point elimination for efficient point cloud registration. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 378–394. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: San Francisco, CA, USA, 2010; pp. 998–1005. [Google Scholar]
- Low, K.L. Linear Least-Squares Optimization for Point-to-Plane ICP Surface Registration; University of North Carolina: Chapel Hill, NC, USA, 2004; Volume 4, pp. 1–3. [Google Scholar]
- Bouaziz, S.; Tagliasacchi, A.; Pauly, M. Sparse iterative closest point. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2013; Volume 32, pp. 113–123. [Google Scholar]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the Third International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Medioni, G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; IEEE: Kobe, Japan, 2009; pp. 3212–3217. [Google Scholar]
- Tombari, F.; Salti, S.; Di Stefano, L. Unique signatures of histograms for local surface description. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Springer: Berlin, Heidelberg, 2010; pp. 356–369. [Google Scholar]
- Aiger, D.; Mitra, N.J.; Cohen-Or, D. 4-points congruent sets for robust pairwise surface registration. ACM Trans. Graph. 2008, 27, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the IJCAI’81: 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (Tog) 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Sinkhorn, R. A relationship between arbitrary positive matrices and doubly stochastic matrices. Ann. Math. Stat. 1964, 35, 876–879. [Google Scholar] [CrossRef]
- Deng, H.; Birdal, T.; Ilic, S. Ppfnet: Global context aware local features for robust 3d point matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 195–205. [Google Scholar]
- Deng, H.; Birdal, T.; Ilic, S. Ppf-foldnet: Unsupervised learning of rotation invariant 3d local descriptors. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 602–618. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 206–215. [Google Scholar]
- Ginzburg, D.; Raviv, D. Deep Weighted Consensus Dense Correspondence Confidence Maps for 3d Shape Registration. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Bordeaux, France, 2022; pp. 71–75. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Huang, S.; Gojcic, Z.; Usvyatsov, M.; Wieser, A.; Schindler, K. Predator: Registration of 3d point clouds with low overlap. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4267–4276. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A modern library for 3D data processing. arXiv 2018, arXiv:1801.09847. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Curless, B.; Levoy, M. A volumetric method for building complex models from range images. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2017; p. 30. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Choy, C.; Park, J.; Koltun, V. Fully convolutional geometric features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8958–8966. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|
| ICP | 11.297 | 3.236 | 0.0788 | 0.0249 |
| FGR | 3.701 | 0.327 | 0.0171 | 0.0017 |
| RANSAC | 2.476 | 0.044 | 0.0072 | 0.0002 |
| DCP | 1.324 | 0.929 | 0.0096 | 0.0061 |
| IDAM | 0.086 | 0.044 | 0.0016 | 0.0004 |
| RPMNet | 0.241 | 0.026 | 0.0013 | 0.0002 |
| PointNetLK | 4.852 | 0.998 | 0.0340 | 0.0061 |
| Predator | 0.541 | 0.266 | 0.0064 | 0.0034 |
| Ours | <10−4 | <10−4 | <10−4 | <10−4 |
| Model | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|
| ICP | 63.794 | 39.558 | 0.3113 | 0.1842 |
| FGR | 11.277 | 2.342 | 0.0560 | 0.0109 |
| RANSAC | 20.736 | 3.241 | 0.0808 | 0.0109 |
| DCP | 14.937 | 9.555 | 0.0962 | 0.0647 |
| IDAM | 0.124 | 0.053 | 0.0008 | 0.0003 |
| RPMNet | 3.387 | 0.543 | 0.0218 | 0.0030 |
| PointNetLK | 47.597 | 30.857 | 0.2785 | 0.1699 |
| Predator | 5.721 | 0.800 | 0.0145 | 0.0037 |
| Ours | <10−4 | <10−4 | <10−4 | <10−4 |
| Model | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|
| ICP | 10.699 | 3.339 | 0.0749 | 0.0249 |
| FGR | 39.420 | 18.544 | 0.1935 | 0.1050 |
| RANSAC | 21.598 | 5.655 | 0.0997 | 0.0323 |
| DCP | 5.490 | 3.458 | 0.0382 | 0.0231 |
| IDAM | 3.250 | 1.616 | 0.0308 | 0.0158 |
| RPMNet | 1.000 | 0.343 | 0.0064 | 0.0032 |
| PointNetLK | 4.963 | 2.055 | 0.0352 | 0.0161 |
| Predator | 1.650 | 0.761 | 0.0121 | 0.0066 |
| Ours | 1.189 | 0.513 | 0.0128 | 0.0052 |
| Model | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|
| ICP | 63.834 | 39.828 | 0.3115 | 0.1851 |
| FGR | 70.652 | 44.373 | 0.3087 | 0.1959 |
| RANSAC | 51.107 | 22.179 | 0.1988 | 0.0854 |
| DCP | 15.700 | 9.473 | 0.0964 | 0.0626 |
| IDAM | 13.871 | 5.633 | 0.0807 | 0.0359 |
| RPMNet | 6.669 | 1.933 | 0.0310 | 0.0114 |
| PointNetLK | 61.323 | 43.914 | 0.3228 | 0.2153 |
| Predator | 9.835 | 2.554 | 0.0319 | 0.0090 |
| Ours | 1.339 | 0.823 | 0.0147 | 0.0077 |
| Model | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|
| ICP | 22.783 | 12.792 | 0.2027 | 0.1278 |
| FGR | 60.227 | 37.594 | 0.3130 | 0.2157 |
| RANSAC | 57.666 | 27.130 | 0.2552 | 0.1268 |
| DCP | 8.681 | 6.595 | 0.0879 | 0.0641 |
| IDAM | 6.093 | 3.892 | 0.0548 | 0.0341 |
| RPMNet | 2.350 | 0.893 | 0.0214 | 0.0083 |
| PointNetLK | 20.481 | 14.064 | 0.2111 | 0.1404 |
| Predator | 2.033 | 0.931 | 0.0233 | 0.0089 |
| Ours | 1.313 | 0.667 | 0.0211 | 0.0075 |
| Model | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|
| ICP | 64.598 | 50.813 | 0.3567 | 0.2479 |
| FGR | 75.859 | 55.222 | 0.3931 | 0.2858 |
| RANSAC | 77.101 | 45.179 | 0.3289 | 0.1893 |
| DCP | 21.719 | 15.889 | 0.1882 | 0.1383 |
| IDAM | 16.242 | 8.789 | 0.1080 | 0.0586 |
| RPMNet | 9.773 | 3.413 | 0.0526 | 0.0227 |
| PointNetLK | 56.729 | 48.011 | 0.3802 | 0.2956 |
| Predator | 12.826 | 3.784 | 0.0551 | 0.0158 |
| Ours | 6.439 | 1.360 | 0.0414 | 0.0111 |
| Model | Clean | Jitter | Crop |
|---|---|---|---|
| Input | 80.23% | 54.34% | 36.82% |
| RANSAC | 84.88% | 61.34% | 46.17% |
| SGC | 98.26% | 77.31% | 60.40% |
| Object | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|
| Object1 | 16.950 | 13.826 | 0.1583 | 0.1243 |
| Object2 | 26.790 | 19.357 | 0.1389 | 0.1372 |
| SA | CA | PPF | SGC | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|---|---|---|
| ✓ | 5.884 | 3.829 | 0.0548 | 0.0334 | |||
| ✓ | ✓ | 4.161 | 2.682 | 0.0405 | 0.0231 | ||
| ✓ | ✓ | ✓ | 3.771 | 2.446 | 0.0339 | 0.0191 | |
| ✓ | ✓ | ✓ | ✓ | 1.313 | 0.667 | 0.0211 | 0.0075 |
| SA | CA | PPF | SGC | RMSE(R)(deg) | MAE(R)(deg) | RMSE(t)(m) | MAE(t)(m) |
|---|---|---|---|---|---|---|---|
| ✓ | 19.428 | 6.443 | 0.0894 | 0.0457 | |||
| ✓ | ✓ | 12.07 | 5.955 | 0.0850 | 0.0434 | ||
| ✓ | ✓ | ✓ | 8.336 | 4.215 | 0.0562 | 0.0284 | |
| ✓ | ✓ | ✓ | ✓ | 6.439 | 1.360 | 0.0414 | 0.0111 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhang, W.; Li, J. Partial-to-Partial Point Cloud Registration by Rotation Invariant Features and Spatial Geometric Consistency. Remote Sens. 2023, 15, 3054. https://doi.org/10.3390/rs15123054
Zhang Y, Zhang W, Li J. Partial-to-Partial Point Cloud Registration by Rotation Invariant Features and Spatial Geometric Consistency. Remote Sensing. 2023; 15(12):3054. https://doi.org/10.3390/rs15123054
Chicago/Turabian StyleZhang, Yu, Wenhao Zhang, and Jinlong Li. 2023. "Partial-to-Partial Point Cloud Registration by Rotation Invariant Features and Spatial Geometric Consistency" Remote Sensing 15, no. 12: 3054. https://doi.org/10.3390/rs15123054
APA StyleZhang, Y., Zhang, W., & Li, J. (2023). Partial-to-Partial Point Cloud Registration by Rotation Invariant Features and Spatial Geometric Consistency. Remote Sensing, 15(12), 3054. https://doi.org/10.3390/rs15123054