
Object-Based Crop Species Classification Based on the Combination of Airborne Hyperspectral Images and LiDAR Data


Abstract
:
1. Introduction
2. Study Area and Data
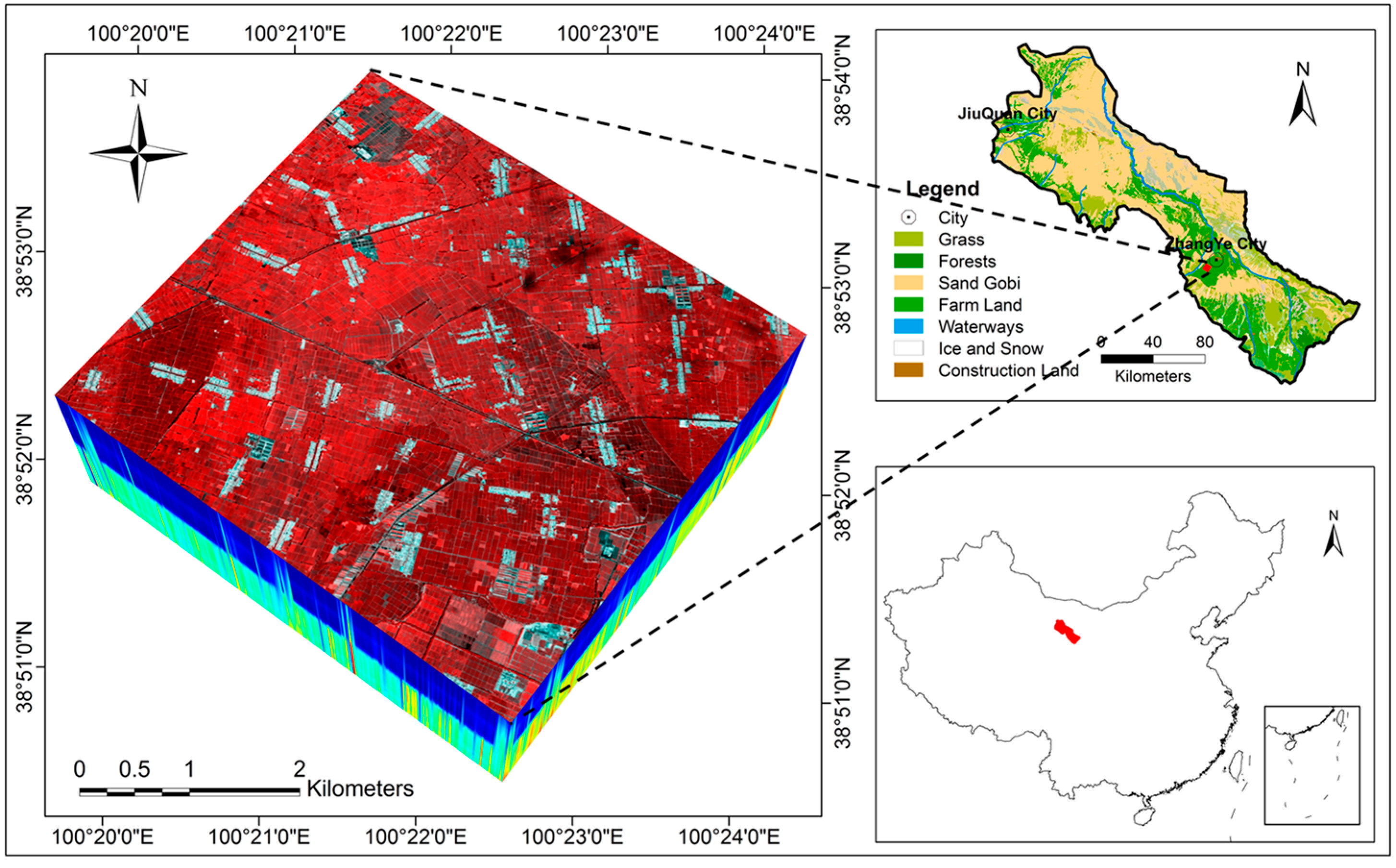
2.1. Study Area

2.2. Data
2.2.1. Airborne Remote Sensing Data
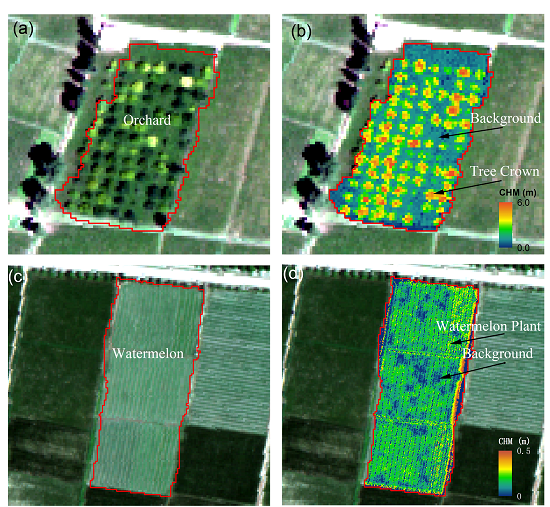
2.2.2. Field Data Collection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Assignment | Number of Ground Investigated Points (912 in Total) | Number of Visually Interpreted Points (270 in Total) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Maize | Orchard | Shelter Forest | Leek | Lettuce | Cauliflower | Nursery | Potato | Watermelon | Pepper | Buildings | Road | Shadow | |
| Parcels | 51 | 43 | 42 | 31 | 26 | 41 | 35 | 40 | 41 | 43 | 35 | 26 | 46 |
| Classification Training | 68 | 64 | 40 | 70 | 50 | 78 | 44 | 80 | 60 | 54 | 58 | 48 | 74 |
| Accuracy Assessment | 34 | 32 | 20 | 35 | 25 | 39 | 22 | 40 | 30 | 27 | 29 | 24 | 37 |
| Total | 102 | 96 | 60 | 105 | 75 | 117 | 66 | 120 | 90 | 81 | 87 | 72 | 111 |

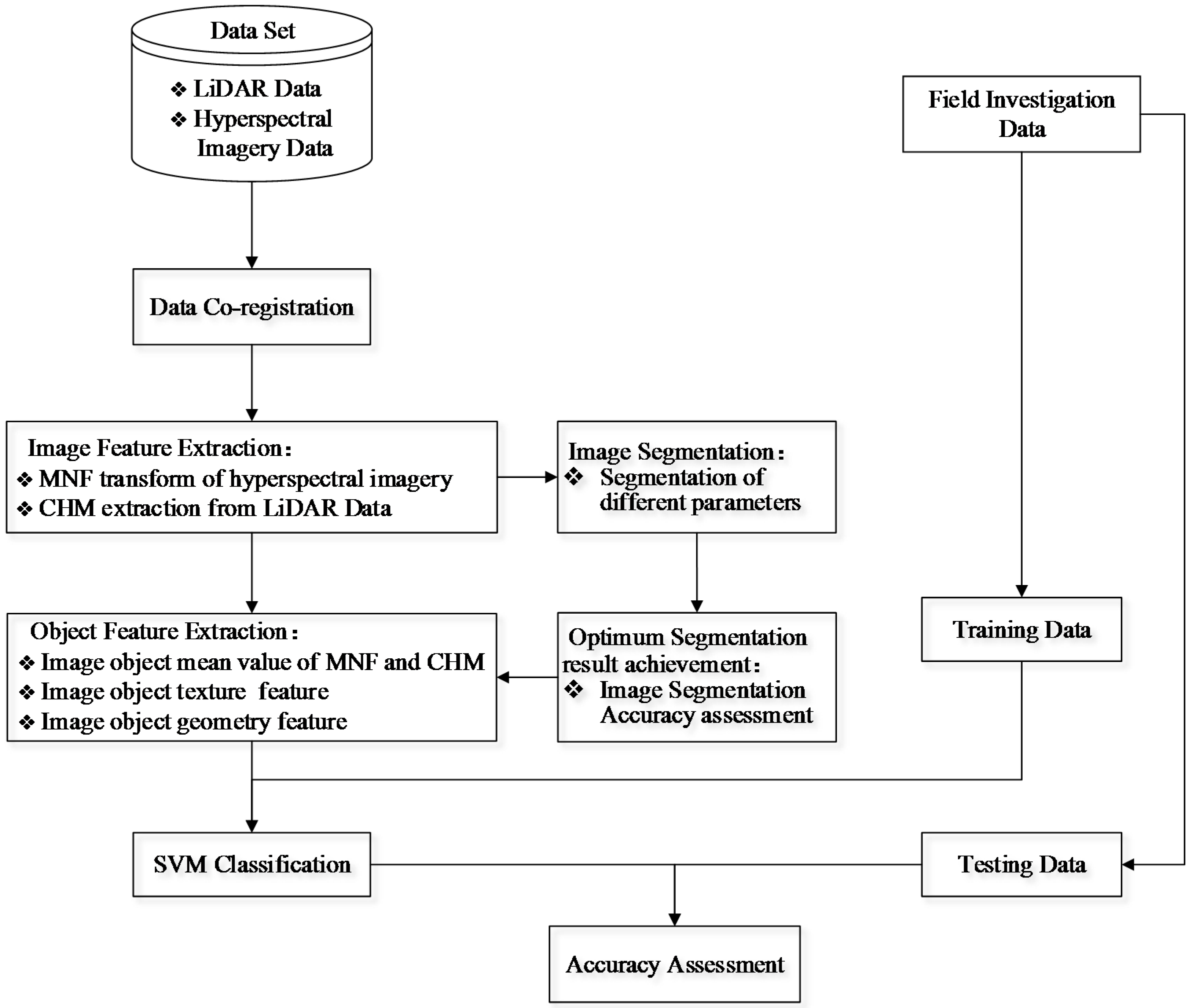
3. Methodology

3.1. Image Feature Extraction

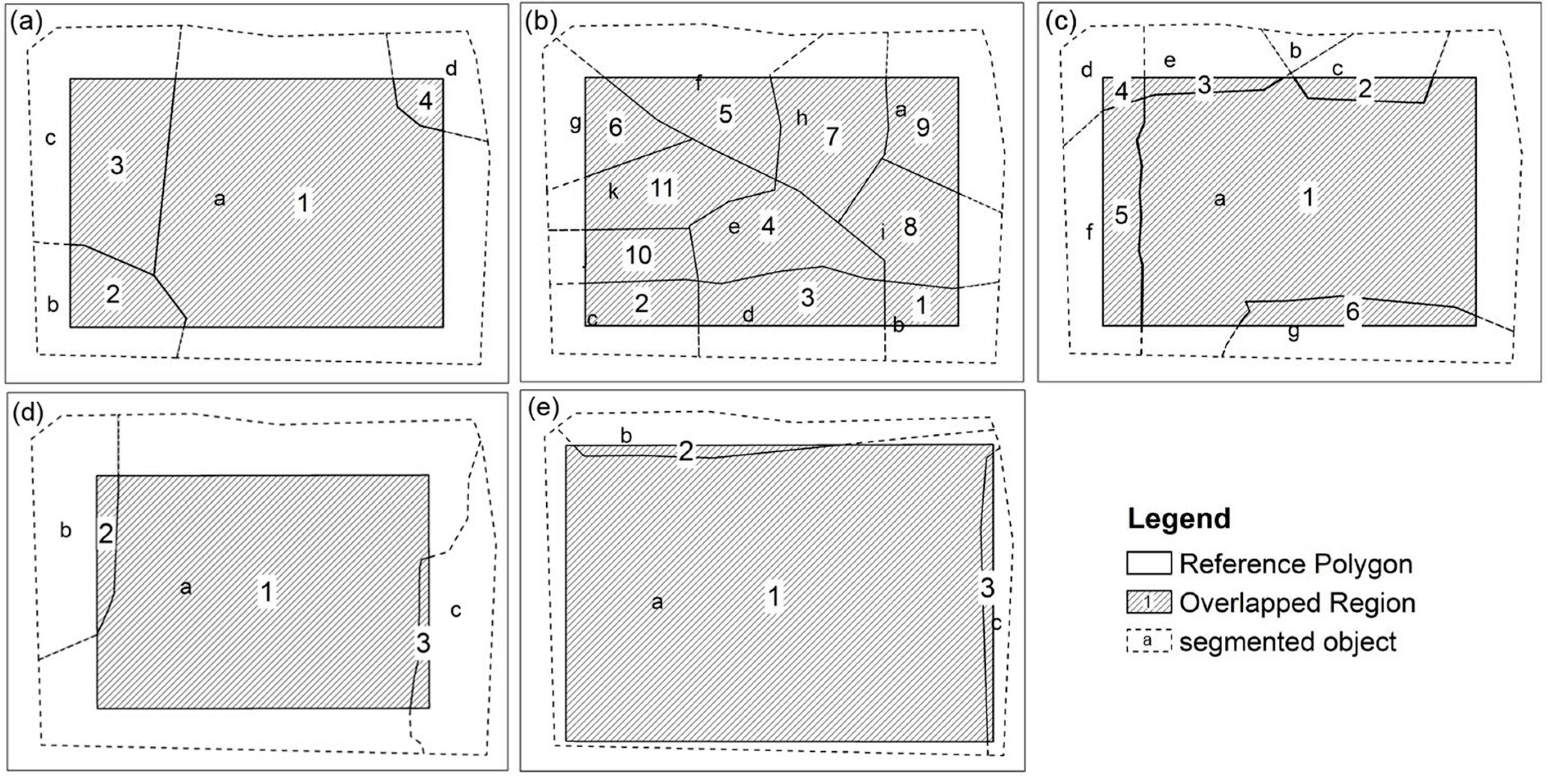
3.2. Image Segmentation and Segmentation Accuracy Assessment
- (1)
- As shown in Figure 5a–c, there are multiple segmented objects that have overlapped regions with the same reference polygon. We define a reference polygon as Over-Segmented (OS) if one of the following three conditions holds: (a) among the overlapped regions, there are more than one of the overlapped regions that are greater than 10% of the reference polygon’s area; (b) each of the overlapped regions is less than (or equal to) 10% of the reference polygon’s area, but the total area of the overlapped regions is more than 90% of the reference polygon’s area, as shown in Figure 5b; (c) among the overlapped regions, there is only one overlapped region that is greater than 10% of the reference polygon’s area, but less than 90% of the reference polygon’s area, as shown in Figure 5c.
- (2)
- As shown in Figure 5d, for each of the reference polygons, there could be one (or more) segmented object(s) that have overlapped region(s) with the same reference polygon. We define the reference polygon as Under-Segmented (US) if the following condition holds: for the overlapped region(s), if there is an overlapped region that is greater than 90% of the reference polygon’s area, but smaller than 90% of the segmented object’s area;
- (3)
- As shown in Figure 5e, for each of the reference polygons, there could be one (or more) segmented object(s) that have overlapped region(s) with the same reference polygon. We define the reference polygon as Accurate-Segmented (AS) if the following condition holds: for the overlapped region(s), if there is an overlapped region that is both greater than 90% but less than 110% of the reference polygon’s area and greater than 90% of the segmented object’s area.

3.3. Object Feature Extraction
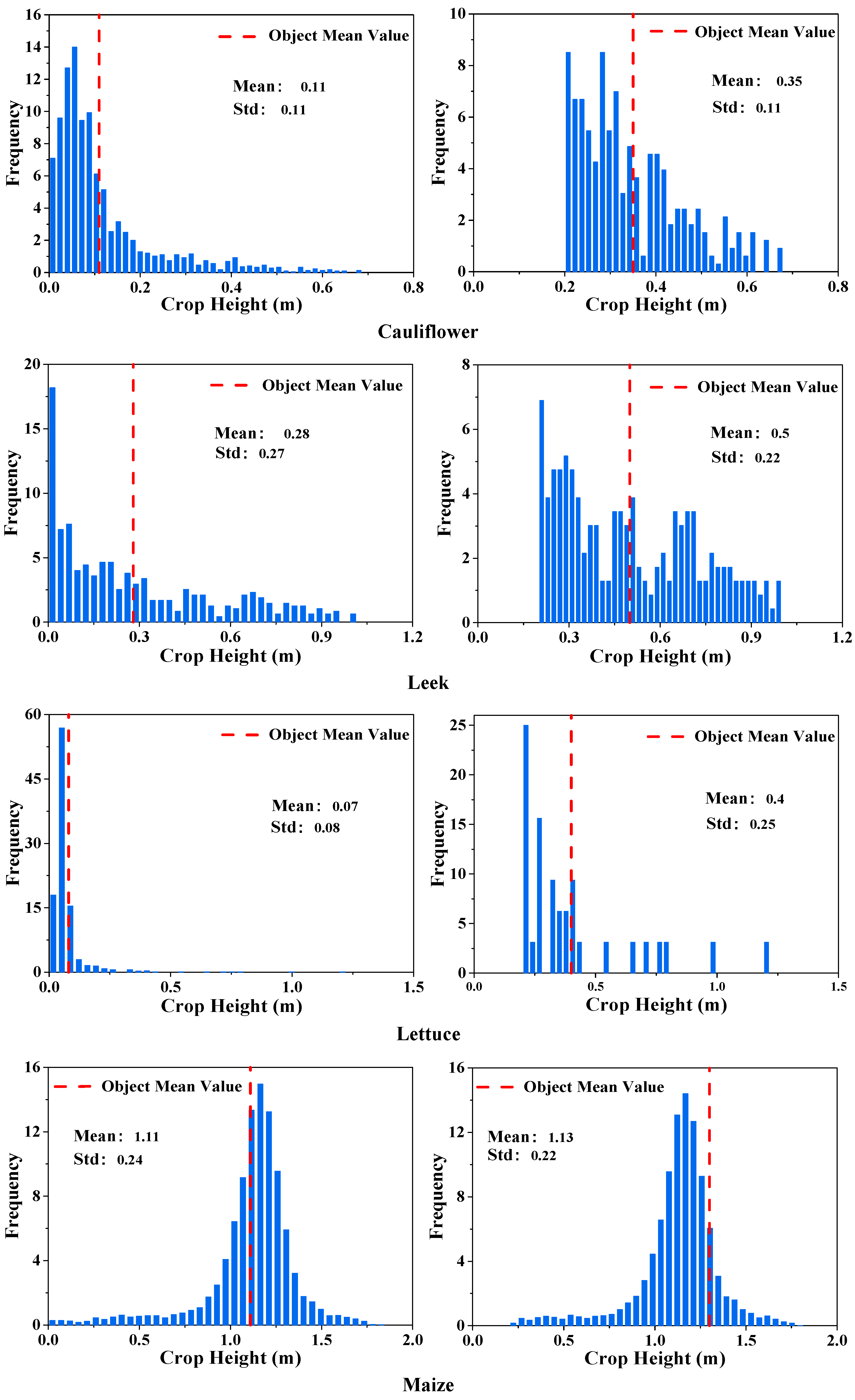
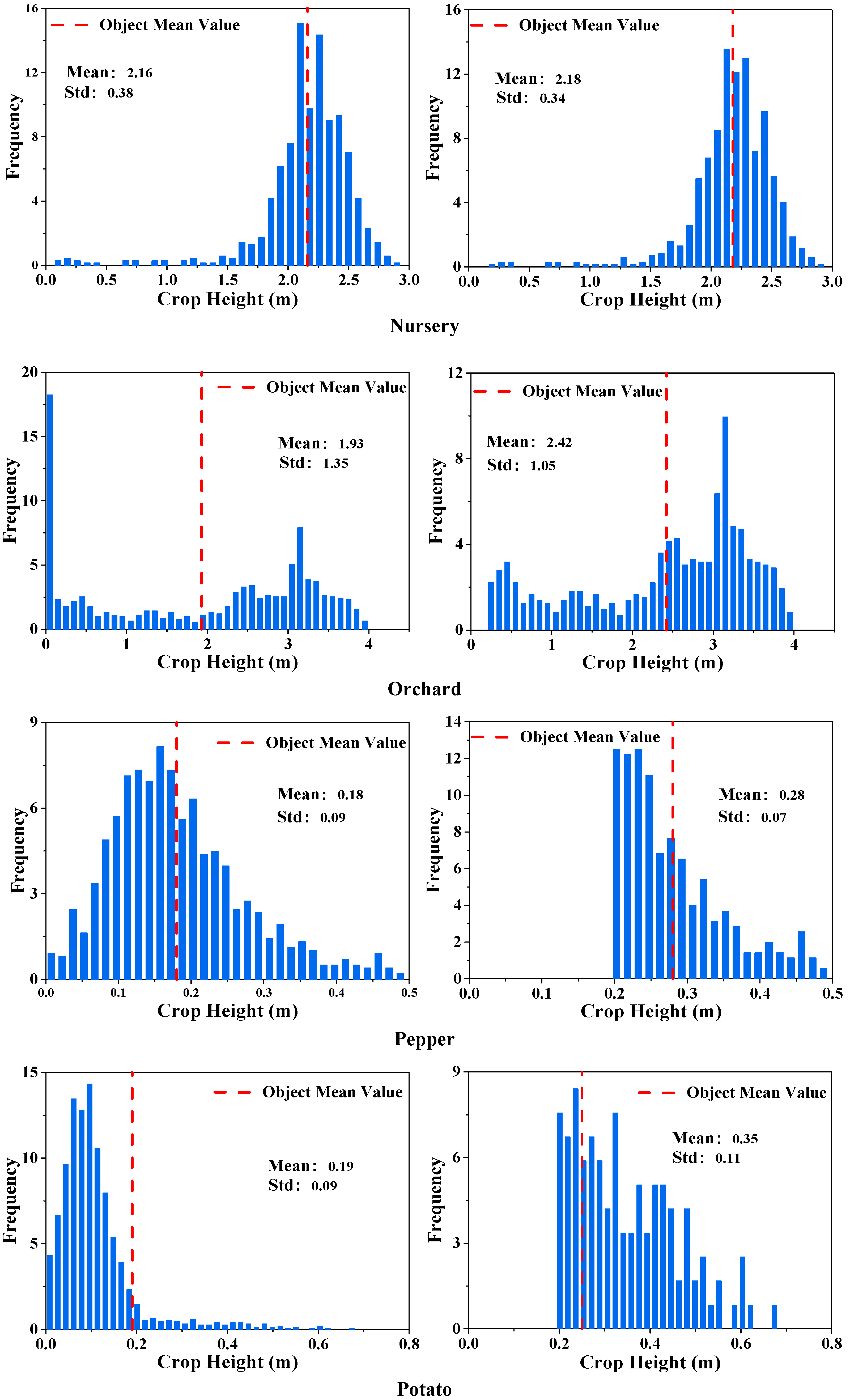
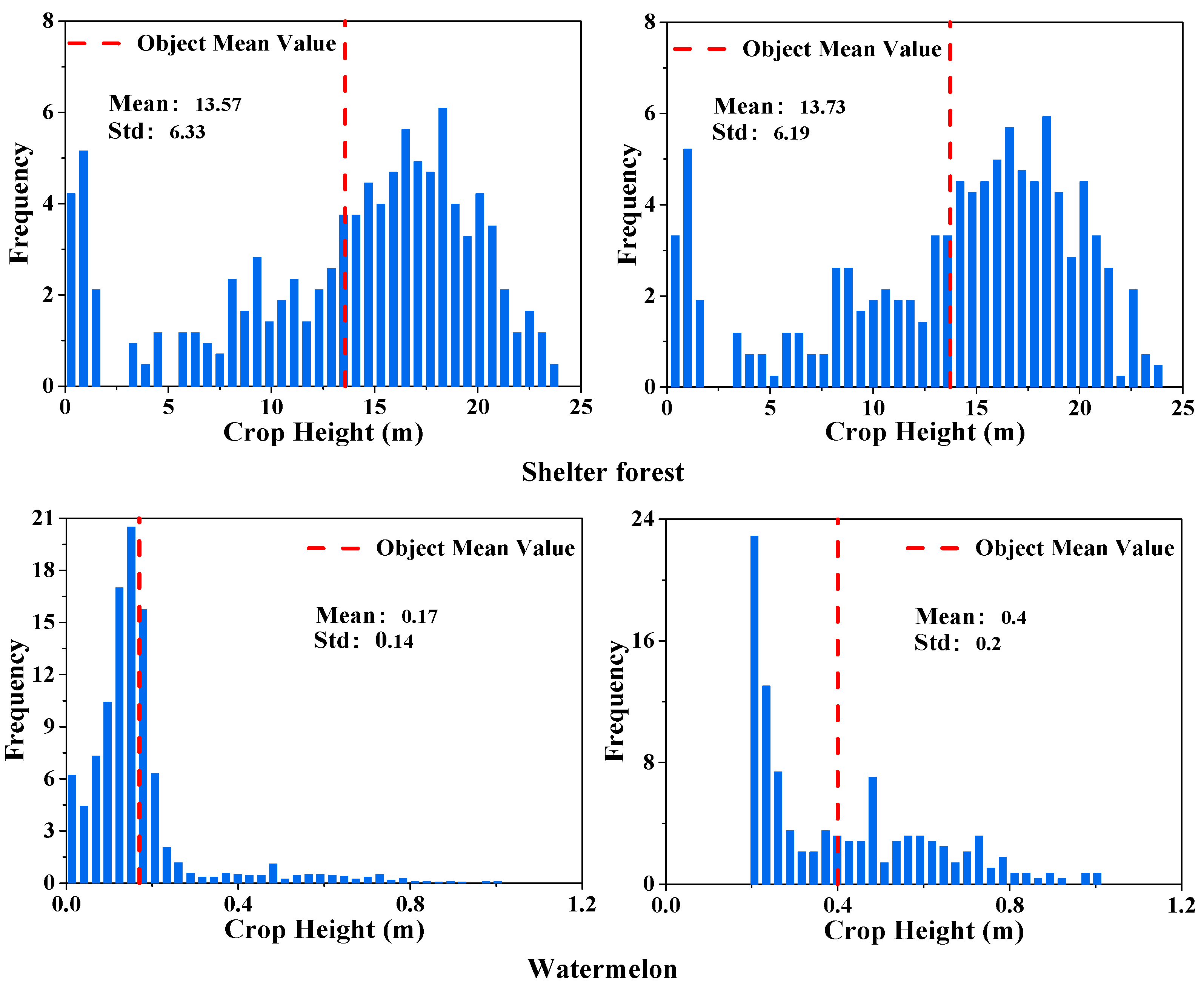
3.3.1. Image Object Crop Height Feature Extraction





3.3.2. Extraction of the Image Object Texture Features
3.3.3. Geometric Feature Extraction of Image Objects
| Statistic Feature | Expression | Description |
|---|---|---|
| Standard deviation | Measures the dispersion of the values around the mean, similar to contrast or dissimilarity. | |
| GLCM angular second moment | High when the GLCM is locally homogeneous. | |
| GLCM contrast | A measure of the amount of local variation in the image. | |
| GLCM dissimilarity | Similar to contrast, but increases linearly. High if the local region has a high contrast. | |
| GLCM entropy | The value for entropy is high if the elements of GLCM are distributed equally. It is low if the elements are close to either 0 or 1. |

3.4. Classification
3.5. Classification Accuracy Assessment
4. Results and Discussion
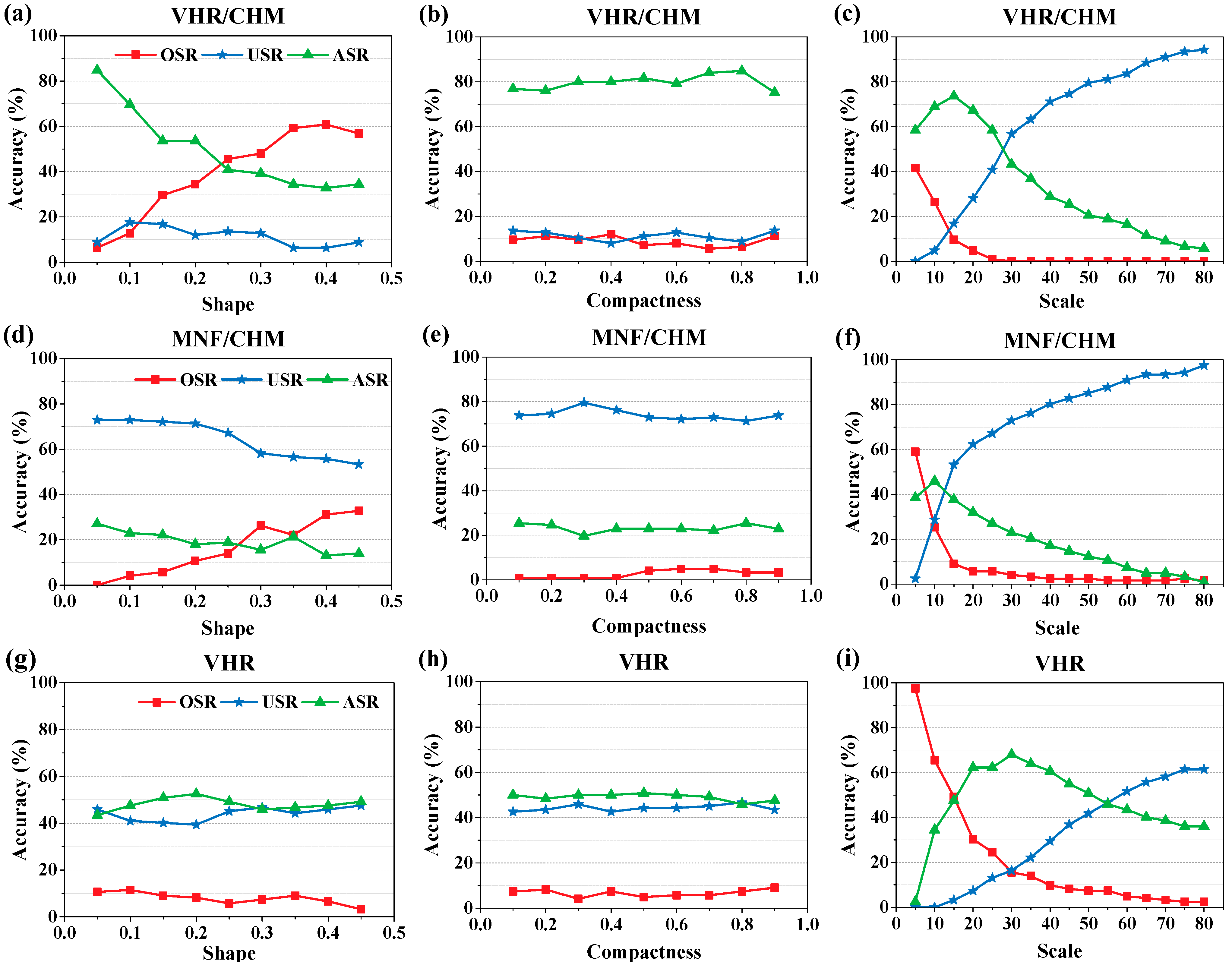
4.1. Segmentations of Different Image Feature Integrations
| Segmentation Scheme | Range | Increment | ||||
|---|---|---|---|---|---|---|
| Scale | Shape | Compactness | Scale | Shape | Compactness | |
| VHR-based segmentation | 5–80 | 0.05–0.45 | 0.1–0.9 | 5 | 0.05 | 0.1 |
| VHR/CHM-based segmentation | 5–80 | 0.05–0.45 | 0.1–0.9 | 5 | 0.05 | 0.1 |
| MNF/CHM-based segmentation | 5–80 | 0.05–0.45 | 0.1–0.9 | 5 | 0.05 | 0.1 |

| Segmentation Scheme | Optimum Segmentation Parameters | Segmentation Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Scale | Shape | Compactness | OSR | USR | ASR | |
| VHR-based segmentation | 30 | 0.2 | 0.7 | 3.20 | 24 | 72.80 |
| VHR/CHM-based segmentation | 15 | 0.05 | 0.8 | 6.40 | 8.80 | 84.80 |
| MNF/CHM-based segmentation | 10 | 0.05 | 0.3 | 17.60 | 20.80 | 61.60 |


4.2. Classification Accuracies of Different Data Integrations

| Feature Integration | Feature Description |
|---|---|
| VHR | With a high spatial resolution of 1 m, four bands were derived from hyperspectral data (bands centered at 454.4 nm, 540.4 nm, 697.7 nm, and 826.3 nm) |
| VHR/CHM | CHM was derived from LiDAR data. |
| MNF | MNF features were the first 10 components of MNF transformed hyperspectral data. |
| MNF/CHM | MNF features combined with CHM data. |
| MNF/CHM/GLCM/Geometric | GLCM features including object-level standard deviation, angular second moment, contrast, dissimilarity, and entropy; geometric features including image object shape index, length/width ratio, and rectangular fit indices. |

| Crop Species | Crop Height (cm) | Classification Accuracy Increment from VHR to VHR/CHM | Classification Accuracy Increment from MNF to MNF/CHM | ||
|---|---|---|---|---|---|
| Producer’s Accuracy (%) | User’s Accuracy (%) | Producer’s Accuracy (%) | User’s Accuracy (%) | ||
| Orchard | 369 | 34.79 | 19.37 | 24.54 | 20.65 |
| Shelter Forest | 1685 | 15.55 | 15.55 | 27.78 | 14.91 |
| Nursery | 356 | 0 | −20 | −3.47 | −20 |
| Maize | 212 | 7.48 | 8.95 | 5.76 | 11.17 |
| Leek | 34 | −10 | 1.32 | 2.55 | −3.02 |
| Cauliflower | 52 | 0 | −3.7 | 0.05 | −3.7 |
| Pepper | 56 | 11.76 | 7.69 | 7.22 | 16.08 |
| Lettuce | 37 | 0 | 0 | −5.75 | 0 |
| Potato | 54 | 0 | 7.14 | −5.96 | 7.51 |
| Watermelon | 30 | 0 | 0 | 0 | 9.42 |
| Buildings | 412 | 5.83 | 0 | 0 | 20 |
| Road | 0 | 11.11 | 5.56 | 51.99 | −10.26 |
| Shadow | 0 | 0 | 0 | −28.17 | 2.53 |
| Crop Species | VHR | VHR/CHM | MNF | MNF/CHM | MNF/CHM/GLCM/Geo | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PA | UA | PA | UA | PA | UA | PA | UA | PA | UA | |
| Cauliflower | 96.3 | 100 | 96.3 | 96.3 | 96.3 | 96.3 | 96.3 | 96.3 | 94.44 | 94.44 |
| Leek | 86.67 | 83.87 | 76.67 | 85.19 | 76.67 | 92 | 80 | 77.42 | 80 | 80 |
| Lettuce | 100 | 100 | 100 | 100 | 100 | 100 | 87.5 | 100 | 90 | 100 |
| Maize | 92.52 | 59.64 | 100 | 68.59 | 100 | 69.93 | 100 | 82.31 | 100 | 84.52 |
| Nursery | 66.67 | 100 | 66.67 | 80 | 83.33 | 71.43 | 66.67 | 80 | 60 | 75 |
| Orchard | 41.3 | 70.37 | 76.09 | 89.74 | 80.43 | 92.5 | 73.91 | 87.18 | 71.88 | 88.46 |
| Pepper | 70.59 | 92.31 | 82.35 | 100 | 70.59 | 85.71 | 82.35 | 100 | 81.82 | 100 |
| Potato | 76.47 | 92.86 | 76.47 | 100 | 82.35 | 100 | 70.59 | 100 | 72.73 | 100 |
| Shelter forest | 75.56 | 75.56 | 91.11 | 91.11 | 91.11 | 93.18 | 88.89 | 90.91 | 86.67 | 96.3 |
| Watermelon | 100 | 93.33 | 100 | 93.33 | 100 | 93.33 | 100 | 100 | 100 | 100 |
| Buildings | 100 | 87.5 | 100 | 93.33 | 100 | 82.35 | 100 | 100 | 100 | 100 |
| Road | 22.22 | 88.89 | 27.78 | 100 | 22.22 | 88.89 | 97.22 | 89.74 | 95.83 | 88.46 |
| Shadow | 55.56 | 90.91 | 55.56 | 90.91 | 61.11 | 91.67 | 50 | 90 | 100 | 92.3 |
| OA | 75.06 | 83.21 | 83.46 | 88.3 | 90.33 | |||||
| Kappa | 0.7 | 0.8 | 0.81 | 0.86 | 0.89 | |||||

5. Conclusions
- (i)
- The framework we presented in this study for mapping crop species by combining hyperspectral and LiDAR data in an object-based image analysis (OBIA) paradigm is effective. This approach produced a good crop species classification result, with an overall accuracy of 90.33% and a kappa coefficient of 0.89 in our study area, where there was a spatially fragmented agricultural landscape and a complicated planting structure.
- (ii)
- The image segmentation accuracy depends heavily on the hyperspectral data dimension-reduction method. In this case, the VHR data that was selected from the hyperspectral bands has higher segmentation accuracy than the MNF. Incorporating the CHM information extracted from high point density LiDAR data could significantly improve the segmentation accuracy of the VHR data.
- (iii)
- The height information derived from LiDAR data provided a substantial increase in the crop species classification accuracy. The MNF/CHM combination produced higher accuracy of crop species classification than VHR/CHM.
- (iv)
- Incorporating the textural and geometric features (i.e., the shape index, length-width ratio, and rectangular fit) of objects could significantly increase the crop species classification accuracy, which indicates that, due to its ability to provide diverse textural and geometric features, object-based image classification is effective for crop species mapping in regions with spatially fragmented landscape and complicated planting structure.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tapia-Silva, F.-O.; Itzerott, S.; Foerster, S.; Kuhlmann, B.; Kreibich, H. Estimation of flood losses to agricultural crops using remote sensing. Phys. Chem. Earth Parts A/B/C 2011, 36, 253–265. [Google Scholar] [CrossRef]
- Jia, K.; Li, Q.; Tian, Y.; Wu, B.; Zhang, F.; Meng, J. Crop classification using multi-configuration SAR data in the North China Plain. Int. J. Remote Sens. 2012, 33, 170–183. [Google Scholar] [CrossRef]
- Atzberger, C. Advances in remote sensing of agriculture: Context description, existing operational monitoring systems and major information needs. Remote Sens. 2013, 5, 949–981. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Z. Combining object-based texture measures with a neural network for vegetation mapping in the Everglades from hyperspectral imagery. Remote Sens. Environ. 2012, 124, 310–320. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Wilson, J.; Zhang, C.; Kovacs, J. Separating crop species in northeastern Ontario using hyperspectral data. Remote Sens. 2014, 6, 925–945. [Google Scholar] [CrossRef]
- Nidamanuri, R.R.; Zbell, B. Use of field reflectance data for crop mapping using airborne hyperspectral image. ISPRS J. Photogramm. Remote Sens. 2011, 66, 683–691. [Google Scholar] [CrossRef]
- Ewijk., K.Y.V.; Randin., C.F.; Treitz., P.M.; Scott., N.A. Predicting fine-scale tree species abundance patterns using biotic variables derived from LiDAR and high spatial resolution imagery. Remote Sens. Environ. 2014, 150, 120–131. [Google Scholar] [CrossRef]
- Maselli, F.; Chiesi, M.; Mura, M.; Marchetti, M.; Corona, P.; Chirici, G. Combination of optical and LiDAR satellite imagery with forest inventory data to improve wall-to-wall assessment of growing stock in Italy. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 377–386. [Google Scholar] [CrossRef]
- Alonzo, M.; Bookhagen, B.; Roberts, D.A. Urban tree species mapping using hyperspectral and LiDAR data fusion. Remote Sens. Environ. 2014, 148, 70–83. [Google Scholar] [CrossRef]
- Cho, M.A.; Mathieu, R.; Asner, G.P.; Naidoo, L.; Aardt, V.J.; Ramoelo, A.; Debba, P.; Wessels, K.; Main, R.; Smit, I.P.J.; et al. Mapping tree species composition in South African savannas using an integrated airborne spectral and LiDAR system. Remote Sens. Environ. 2012, 125, 214–226. [Google Scholar] [CrossRef]
- Ghosh, A.; Fassnacht, F.E.; Joshi, P.K.; Koch, B. A framework for mapping tree species combining hyperspectral and LiDAR data: Role of selected classifiers and sensor across three spatial scales. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 49–63. [Google Scholar] [CrossRef]
- Naidoo, L.; Cho, M.A.; Mathieu, R.; Asner, G. Classification of savanna tree species, in the Greater Kruger National Park region, by integrating hyperspectral and LiDAR data in a Random Forest data mining environment. ISPRS J. Photogramm. Remote Sens. 2012, 69, 167–179. [Google Scholar] [CrossRef]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D. Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogramm. Eng. Remote Sens. 2006, 72, 199–811. [Google Scholar]
- Wardlow, B.; Egbert, S.; Kastens, J. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the U.S. Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Ke, Y.; Quackenbush, L.J.; Im, J. Synergistic use of QuickBird multispectral imagery and LiDAR data for object-based forest species classification. Remote Sens. Environ. 2010, 114, 1141–1154. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J.; Castilla, G.; St-Onge, B.; Powers, R. A multiscale geographic object-based image analysis to estimate LiDAR-measured forest canopy height using Quickbird imagery. Int. J. Geogr. Inf. Sci. 2011, 25, 877–893. [Google Scholar] [CrossRef]
- Johansen, K.; Sohlbach, M.; Sullivan, B.; Stringer, S.; Peasley, D.; Phinn, S. Mapping banana plants from high spatial resolution orthophotos to facilitate plant health assessment. Remote Sens. 2014, 6, 8261–8286. [Google Scholar] [CrossRef]
- Castillejo-González, I.L.; López-Granados, F.; García-Ferrer, A.; Peña-Barragán, J.M.; Jurado-Expósito, M.; de la Orden, M.S.; González-Audicana, M. Object- and pixel-based analysis for mapping crops and their agro-environmental associated measures using QuickBird imagery. Comput. Electron. Agric. 2009, 68, 207–215. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Tansey, K.; Chambers, I.; Anstee, A.; Denniss, A.; Lamb, A. Object-oriented classification of very high resolution airborne imagery for the extraction of hedgerows and field margin cover in agricultural areas. Appl. Geogr. 2009, 29, 145–157. [Google Scholar] [CrossRef]
- Peña, J.M.; Gutiérrez, P.A.; Hervás-Martínez, C.; Six, J.; Plant, R.E.; López-Granados, F. Object-based image classification of summer crops with machine learning methods. Remote Sens. 2014, 6, 5019–5041. [Google Scholar] [CrossRef]
- Conrad, C.; Fritsch, S.; Zeidler, J.; Rücker, G.; Dech, S. Per-field irrigated crop classification in arid central asia using SPOT and ASTER data. Remote Sens. 2010, 2, 1035–1056. [Google Scholar] [CrossRef]
- Johnson, B.; Xie, Z. Unsupervised image segmentation evaluation and refinement using a multi-scale approach. ISPRS J. Photogramm. Remote Sens. 2011, 66, 473–483. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. On combining multiple features for hyperspectral remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 879–893. [Google Scholar] [CrossRef]
- Zhang, L.; Huang, X. Object-oriented subspace analysis for airborne hyperspectral remote sensing imagery. Neurocomputing 2010, 73, 927–936. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Chanussot, J.; Benediktsson, J.A. Segmentation and classification of hyperspectral images using watershed transformation. Pattern Recognit. 2010, 43, 2367–2379. [Google Scholar] [CrossRef]
- Sasaki, T.; Imanishi, J.; Ioki, K.; Morimoto, Y.; Kitada, K. Object-based classification of land cover and tree species by integrating airborne LiDAR and high spatial resolution imagery data. Landsc. Ecol. Eng. 2011, 8, 157–171. [Google Scholar] [CrossRef]
- Antonarakis, A.S.; Richards, K.S.; Brasington, J. Object-based land cover classification using airborne LiDAR. Remote Sens. Environ. 2008, 112, 2988–2998. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Fusion of hyperspectral and LiDAR remote sensing data for classification of complex forest areas. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1416–1427. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Tree species classification in the southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data. Remote Sens. Environ. 2012, 123, 258–270. [Google Scholar] [CrossRef]
- Li, X.; Cheng, G.; Liu, S.; Xiao, Q.; Ma, M.; Jin, R.; Che, T.; Liu, Q.; Wang, W.; Qi, Y. Heihe watershed allied telemetry experimental research (HiWATER): Scientific objectives and experimental design. Bull. Am. Meteorol. Soc. 2013, 94, 1145–1160. [Google Scholar] [CrossRef]
- Bannari, A.; Pacheco, A.; Staenz, K.; McNairn, H.; Omari, K. Estimating and mapping crop residues cover on agricultural lands using hyperspectral and IKONOS data. Remote Sens. Environ. 2006, 104, 447–459. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Adjorlolo, C.; Mutanga, O.; Cho, M.A.; Ismail, R. Spectral resampling based on user-defined inter-band correlation filter: C3 and C4 grass species classification. Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 535–544. [Google Scholar] [CrossRef]
- Gomez-Chova, L.; Calpe, J.; Soria, E.; Camps-Valls, G.; Martin, J.D.; Moreno, J. Cart-based feature selection of hyperspectral images for crop cover classification. In Proceedings of the 2003 International Conference on Image Processing, ICIP 2003, Barcelona, Catalonia, Spain, 14–17 September 2003; Volume 3, pp. 589–592.
- Green, A.A.; Berman, M.; Switzer, P.; Craig, M.D. A transformation for ordering multispectral data in terms of image quality with implications for noise removal. IEEE Trans. Geosci. Remote Sens. 1988, 26, 65–74. [Google Scholar] [CrossRef]
- Zhang, B.; Sun, X.; Gao, L.R.; Yang, L.N. Endmember extraction of hyperspectral remote sensing images based on the Ant Colony Optimization (ACO) algorithm. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2635–2646. [Google Scholar] [CrossRef]
- Dare, P.M. Shadow analysis in high-resolution satellite imagery of urban areas. Photogramm. Eng. Remote Sens. 2005, 71, 169–177. [Google Scholar] [CrossRef]
- Zhou, W.; Huang, G.; Troy, A.; Cadenasso, M. Object-based land cover classification of shaded areas in high spatial resolution imagery of urban areas: A comparison study. Remote Sens. Environ. 2009, 113, 1769–1777. [Google Scholar] [CrossRef]
- Gamon, J.; Penuelas, J.; Field, C. A narrow-waveband spectral index that tracks diurnal changes in photosynthetic efficiency. Remote Sens. Environ. 1992, 41, 35–44. [Google Scholar] [CrossRef]
- Cheng, J.; Bo, Y.; Zhu, Y.; Ji, X. A novel method for assessing the segmentation quality of high-spatial resolution remote-sensing images. Int. J. Remote Sens. 2014, 35, 3816–3839. [Google Scholar] [CrossRef]
- Baatz, M.; Schäpe, A. Multiresolution segmentation: An optimization approach for high quality multi-scale image segmentation. Angew. Geogr. Inf. 2000, XII, 12–23. [Google Scholar]
- Liu, D.; Xia, F. Assessing object-based classification: Advantages and limitations. Remote Sens. Lett. 2010, 1, 187–194. [Google Scholar] [CrossRef]
- Drǎguţ, L.; Tiede, D.; Levick, S.R. ESP: A tool to estimate scale parameter for multiresolution image segmentation of remotely sensed data. Int. J. Geogr. Inf. Sci. 2010, 24, 859–871. [Google Scholar] [CrossRef]
- Kim, M.; Madden, M.; Warner, T. Estimation of optimal image object size for the segmentation of forest stands with multispectral IKONOS imagery. In Object-Based Image Analysis; Springer: Berlin, Germany, 2008; pp. 291–307. [Google Scholar]
- Chen, J.; Deng, M.; Mei, X.; Chen, T.; Shao, Q.; Hong, L. Optimal segmentation of a high-resolution remote-sensing image guided by area and boundary. Int. J. Remote Sens. 2014, 35, 6914–6939. [Google Scholar] [CrossRef]
- Polak, M.; Zhang, H.; Pi, M. An evaluation metric for image segmentation of multiple objects. Image Vis. Comput. 2009, 27, 1223–1227. [Google Scholar] [CrossRef]
- Liu, Y.; Bian, L.; Meng, Y.; Wang, H.; Zhang, S.; Yang, Y.; Shao, X.; Wang, B. Discrepancy measures for selecting optimal combination of parameter values in object-based image analysis. ISPRS J. Photogramm. Remote Sens. 2012, 68, 144–156. [Google Scholar] [CrossRef]
- Yue, A.; Zhang, C.; Yang, J.; Su, W.; Yun, W.; Zhu, D. Texture extraction for object-oriented classification of high spatial resolution remotely sensed images using a semivariogram. Int. J. Remote Sens. 2013, 34, 3736–3759. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, D. Study of land cover classification based on knowledge rules using high-resolution remote sensing images. Expert Syst. Appl. 2011, 38, 3647–3652. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 2, 610–621. [Google Scholar] [CrossRef]
- Definiens, A.G. Definiens eCognition Developer 8 Reference Book; Definiens AG: München, Germany, 2009. [Google Scholar]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Bandos, T.V.; Bruzzone, L.; Camps-Valls, G. Classification of hyperspectral images with regularized linear discriminant analysis. IEEE Trans. Geosci. Remote Sens. 2009, 47, 862–873. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: New York, NY, USA, 2008. [Google Scholar]
- Bishop, Y.M.; Fienberg, S.E.; Holland, P.W. Discrete Multivariate Analysis: Theory and Practice; Springer: New York, NY, USA, 2007. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Bo, Y. Object-Based Crop Species Classification Based on the Combination of Airborne Hyperspectral Images and LiDAR Data. Remote Sens. 2015, 7, 922-950. https://doi.org/10.3390/rs70100922
Liu X, Bo Y. Object-Based Crop Species Classification Based on the Combination of Airborne Hyperspectral Images and LiDAR Data. Remote Sensing. 2015; 7(1):922-950. https://doi.org/10.3390/rs70100922
Chicago/Turabian StyleLiu, Xiaolong, and Yanchen Bo. 2015. "Object-Based Crop Species Classification Based on the Combination of Airborne Hyperspectral Images and LiDAR Data" Remote Sensing 7, no. 1: 922-950. https://doi.org/10.3390/rs70100922
APA StyleLiu, X., & Bo, Y. (2015). Object-Based Crop Species Classification Based on the Combination of Airborne Hyperspectral Images and LiDAR Data. Remote Sensing, 7(1), 922-950. https://doi.org/10.3390/rs70100922