1. Introduction
Water and energy are basic natural and strategic resources, and they form the material basis for the survival of human society and provide an important guarantee for the sustainable development of the national economy. At present, the water-energy nexus is the focus of research by domestic and foreign scholars [
1,
2,
3,
4,
5,
6]. With intensified global climate change, population growth, and rapid economic and social development, the comprehensive forecast of water and energy demand in urban areas is of great significance for policy planning. In the study of water demand forecasting, Cengiz Koç forecasted the water demand of the Bodrum Peninsula for the next 3 to 40 years of the tourism season based on the local population statistics [
7]. The study only analyzed the impacts of population size and structure of water demand, and it did not take into account the constraints of other economic factors on water use. Rathnayaka established Australian urban households as water terminals, divided residential end-use water into different types, established the urban residential end-use water demand model, and verified it on a time scale by the quarter and year [
8]. The model only predicted the urban domestic water use without considering industrial, agricultural, and other departments of the water forecast.
In the energy demand forecast study, two fundamental approaches called the top-down and the bottom-up approach have been identified to model the residential sector’s energy consumption [
9]. Ghiassi studied the bottom-up approach for urban energy computing supported by multivariate cluster analysis and introduced a two-step approach involving a reductive phase and a re-diversification process [
10]. These methods were applied to forecast the energy demand without studying the relationship between water and energy instead of taking the relevant constraints of water resources into account.
Over the last decade, artificial intelligence (AI) techniques have been increasingly used in different fields for fitting and forecasting. In many quantitative structure-property studies, the multiple linear regression (MLR) method is commonly used; however, this method also presents certain limitations when working with a complex system. The flexibility of an artificial neural network (ANN) model can be used to resolve relatively complex non-linear issues. Tiantian Yang et al. used Random Forest, ANN, and Support Vector Regression methods to predict one-month-ahead reservoir inflows for two headwater reservoirs in the United States of America (USA) and China, respectively [
11]. Yusuf Kurtgoz et al. estimated the thermal efficiency, brake specific fuel consumption, and volumetric efficiency values of a biogas engine operated via spark ignition at different methane ratios and engine load values with the help of the ANN model, and their study showed that ANN models generate good results for spark ignition biogas engines that present strong correlations and low error rates [
12]. An improved solar forecasting algorithm based on the ANN model with fuzzy logic pre-processing was proposed, and more accurate solar irradiance forecasting results were found for Singapore [
13].
Based on the nexus between water and energy, this paper overcomes the limitations of the traditional forecasting methods and improves the feedforward ANN to establish a novel model for the comprehensive forecast of urban water resources and energy demand. Also, MLR is used as a basic regression method to draw comparisons. Taking Wuxi City as an example, this paper validates the accuracy and effectiveness of the model’s prediction, reveals the quantitative connection between the two objects, and provides more intuitive and scientific data support for the nexus between water and energy.
2. Data
A water resources and energy demand integrated forecasting system is a non-linear complex system. Various factors affect the water and energy demands in urban areas and can be divided into socio-economic and natural factors [
14]. Selecting the comprehensive evaluation indicators of urban water resources and energy demand should follow the principle of testability, reliability, and adequacy [
15]. According to the above principles, the study uses sequential statistics from 1991 to 2016 as the basic data to access the water and energy supply and demand for Wuxi City, and the following 14 indicators based on different aspects have been selected from the
Wuxi Statistical Yearbook (1991–2016) and the
Water Resources Bulletin.
- (1)
Economic and social development factors
Economic output is a major factor that affects the demand for water and energy. With continued urbanization and the implementation of the universal two-child policy, China’s urban population has grown rapidly, which has led to a corresponding increase in the demand for water and energy. This paper chose the total population (X1), urban population (X2), and the primary, secondary, and tertiary industry gross domestic product (GDP) (X3) (X4) (X5) as factors to measure the economic development.
- (2)
Natural factors
According to water resources assessment requirements, research on the inter-annual variation of regional precipitation can provide the evidence for water resources supply and demand. In this paper, annual precipitation (X6) was used as the natural factor that influences the water demand in urban areas.
- (3)
Use and treatment of urban water resources
Urban residents’ activities can consume and pollute many water resources. It is related to the reuse of water resources via the sewage treatment and recycling. Water consumption is usually classified into production, living, and ecological water. Given that the latter takes up quite a small proportion of water, its consumption can be disregarded. Here, agricultural (X7) and industrial water consumption (X8) are selected as water for production, while tap water supply (X9) proxied for living water consumption. Additionally, the total discharge of industrial wastewater (X10) and the daily sewage treatment capacity (X11) were used.
- (4)
Use of major energy sources
In China, the whole of society’s energy consumption mainly relies on coal, oil, and other primary energy, which results in low efficiency and utilization and high energy consumption. Meanwhile, the total electricity consumption accounts for most of the energy consumption. The research selected total and domestic electricity consumption (X12) (X13), respectively, and the consumption of coal in industrial enterprises above a designed size (X14).
The above fourteen indices based on different aspects that influence water and energy demand were used as the indices to establish the network input.
3. Methodology
3.1. Artificial Neural Network Model
The Artificial Neural Network (ANN) is a robust, non-linear regression approach that has been extensively applied for many classification and regression problems in various fields. The learning process of the feedforward ANN with the back propagation (BP) algorithm is divided into two stages. The first stage inputs the known learning samples and calculates the output of the neurons from the first layer of the network to the following layers using the network structure and the previous iteration of the weight and threshold. The second stage modifies the weights and thresholds by calculating the effect of each weight and threshold on the total error from the last layer to the previous layers. The two processes are repeated alternately until the convergence is achieved.
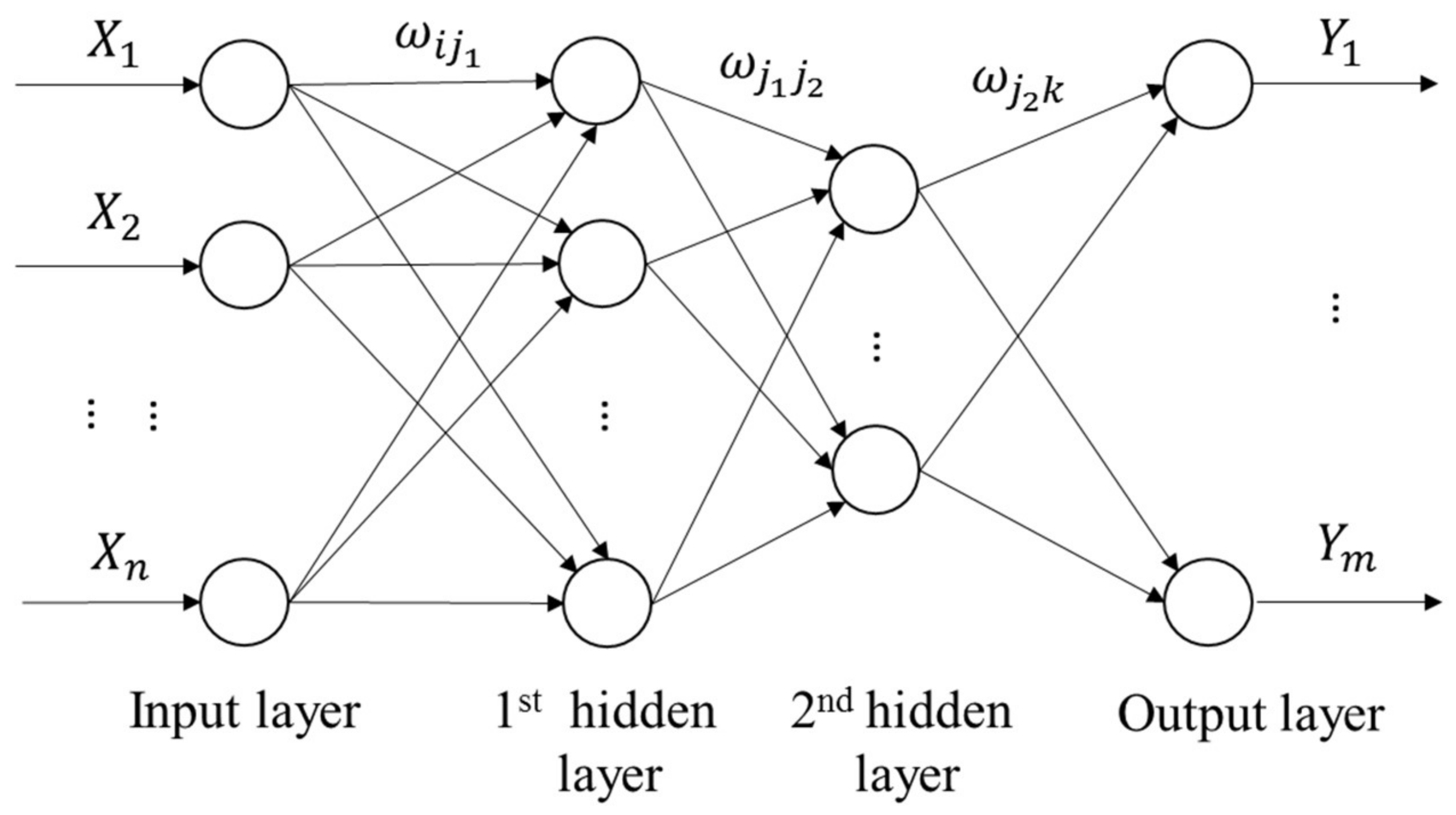
The back propagation neural network algorithm with double-hidden layers (shown in
Figure 1) is employed as follows:
Step 1: Network initialization. Confirm the number of network input layer nodes n, the number of nodes in the first hidden layer l, the number of nodes in the second hidden layer p, and the number of nodes in the output layer m according to the input and output sequence (X, Y) of the system. Initialize the connection weights between the input layer, the hidden layer, and the output layer which are marked as , , and , respectively. Initialize the thresholds of the hidden layers , , the threshold of the output layer , and preset the learning rate and the neuron excitation function.
Step 2: Calculate the hidden layer’s output. The signal that the first hidden layer transmits to the second hidden layer is as follows:
The signal that the second hidden layer transmits to the output layer is as follows:
The selection functions of
and
are written as follows:
Step 3: Calculate the output layer’s output. The output of the BP Neural Network with double hidden layers is written as follows:
Step 4: Calculate the errors. The network prediction error
is calculated based on the network predicted output
Y and the expected output
T. The nodal error of the output layer is:
where
n is the number of output layer nodes and
m is the number of input layer nodes.
Step 5: Update the weights. The connection weights
,
, and
are updated based on the network prediction error
. The correction of the weights is conducted along the opposite direction of the gradient of the error performance function [
16].
Step 6: Update the thresholds. Update thresholds of the network node
,
and
according to the network prediction error
.
Step 7: Determine whether the algorithm iteration ends until the global error
meets the conditions in which
and
, where
is the preset error accuracy,
n is the number of input nodes, and
m is the number of output nodes, or reaches the maximum number of learning times. Then, the iteration ends. Otherwise, return to Step 2.
3.2. Model Establishment and Implementation
In this paper, the BP network functions of the MATLAB R2014b Software [
17] are used to realize the establishment of the network model with double hidden layers. The BP network functions are
newff (),
train (), and
sim ().
newff () is used to design a BP network,
train () is applied to train a feedforward ANN, and
sim () is used to predict the functional output of a trained network. The network design is written as follows:
where
P and
T are the input and output matrices of the training set, respectively.
S1 and
S2 are the number of the first and second hidden layer nodes, respectively.
TF1 and
TF2 are the transfer functions of the two layers’ nodes,
BTF is the training function of the network,
BLF represents the learning function, and
PF represents the performance analysis function.
net is the value returned back to the completed BP network model.
train () is used to train the network model, such as the following
When the network model training is complete, use the function
sim () for data simulation, such as the following
where
X0 is the input matrix of the test set and
Y is the simulation result of the neural network. Select the mean square error of the network predicted and the expected value as a measure
where
m is the number of output layer nodes;
n is the number of input layer nodes.
is the actual output value of the
j-th output of the
i-th input sample; and
is the expected output value of the
j-th output of the
i-th input sample.
Furthermore, the multiple linear regression model (MLR) is used as a basic method to draw comparisons to the proposed ANN. We set the fourteen indices as the independent variables while the water resources demand and energy demand were defined as the dependent variables Y1 and Y2, respectively.
3.3. Multiple Linear Regression Model
Most statistical calculations are performed using linear regression models, which have been frequently applied in different fields [
18,
19,
20]. Almost every discipline utilizes regression analyses as a basis for comparing improved models [
21,
22,
23].
Usually, the expression formula of MLR is set as
where
Y and
X denote the dependent and independent variables with the number
p,
stands for the regression coefficient, and
is the random error.
The bias measure of the MLR is the correlation coefficient (
R2) for a calibration set with
n samples, which is calculated as follows:
where
and
denote the reference and mean value for the
i-th sample, respectively, and
denotes the corresponding estimated value derived from the MLR model [
24]. The
R2 value represents the contribution of the explanatory variable to a change in the predictor variable ranging from 0 to 1. When the value closes to 1, it means the corresponding MLR model has achieved a high level of reliability [
25].
4. Study Area and Experiment Design
4.1. Overview of Wuxi City, China
Wuxi is located in the south of Jiangsu Province, in the center of China’s economically developed Yangtze River Delta, and it is south of China’s third largest freshwater body, Taihu Lake. It is an important economic center, city and regional transportation hub, and represents a famous tourist destination in China. The city has a total area of 4627 km2, of which the water accounts for 1290 km2, or 27.9% of the total area. With the energy resources being relatively poor, the contradiction between energy supply and demand is increasingly acute. Coal, oil, and natural gas and other forms of primary energy are mainly supplied via nonlocal transfers, while only solar energy on behalf of renewable energy has large-scale use conditions.
4.2. Urban Water-Energy Demand Training and Forecast
We chose the data of water resources and energy in Wuxi from 1991 to 2016 as samples (See
Appendix A). Typically, in the feedforward ANN, the data have to be divided into 2–3 chunks, with a segment of data reserved outside of the training phase and validation phase of the model. Then, we test the performance of the trained model on the reserved dataset as an independent test set to verify the results (overfitting, accuracy, etc.).
The fourteen impact factors from
Section 2 are used here as the input indices of the network. We chose their values from 1991 to 2010 and the total water and energy consumption in the corresponding years as the training sets, while we selected the same fourteen variables from 2011 to 2016 as the test sets, aiming to verify the validity of the model. The sample data were drawn from the
Wuxi Statistical Yearbook.
The training sets are divided into two subsets. One is used as a training subset to fit the parameters of the network (i.e., the gradient, weights, and bias values), which accounts for 80% of the total dataset. The other subset is known as the validation subset and is used to check for network errors during training. The latter subset accounts for 20% of the total data. The errors will be reduced in the first training stage. However, as the network begins to overfit, the errors will increase and the training needs to be stopped immediately. As a result, the network structure and parameters of the network can be obtained when the minimum validation error is achieved.
The first hidden layer includes ten process neuron nodes that are used to complete the spatial weighted aggregation and excitation output of the input signal. The second hidden layer is also made up of ten process neuron nodes and aims to improve the non-linear mapping capacities of the network. The transfer functions between the former two layers are both the logarithmic S-type transfer function
logsig. Furthermore, the transfer function of the output layer is the linear function
purelin. Set the network training learning rate as
, the momentum factor as
, and the mean square error of convergence as
. The number of network training iterations is set to 10,000 times, while the interval numbers of steps of the training results is set to 200 times. The utilized network training algorithm is the Levenberg–Marquardt algorithm [
26], which is the fastest algorithm to train the BP neural network and allows it overcome the shortcomings of the neural network (slow convergence speed and easiness to fall into the local minima value). After several training sessions, the network has met network error requirements to achieve convergence.
5. Results and Discussion
5.1. Results of ANN
After forming the neural network, the former 20 groups of data from the years 1991 to 2010 were set as the training set, while the rest of the data from the years 2011 to 2016 were used as the testing set. Furthermore, we used the Rolling Forecast method [
27], which incorporates the previous 20 sets of data into the network, predicts the 21st group of data, and calculates the relative error. When the error meets the accuracy requirement, the results will continue to be input in the network. Then, the 22nd group will be forecasted, and the process will continuously repeat.
- (1)
Results for the training and testing periods
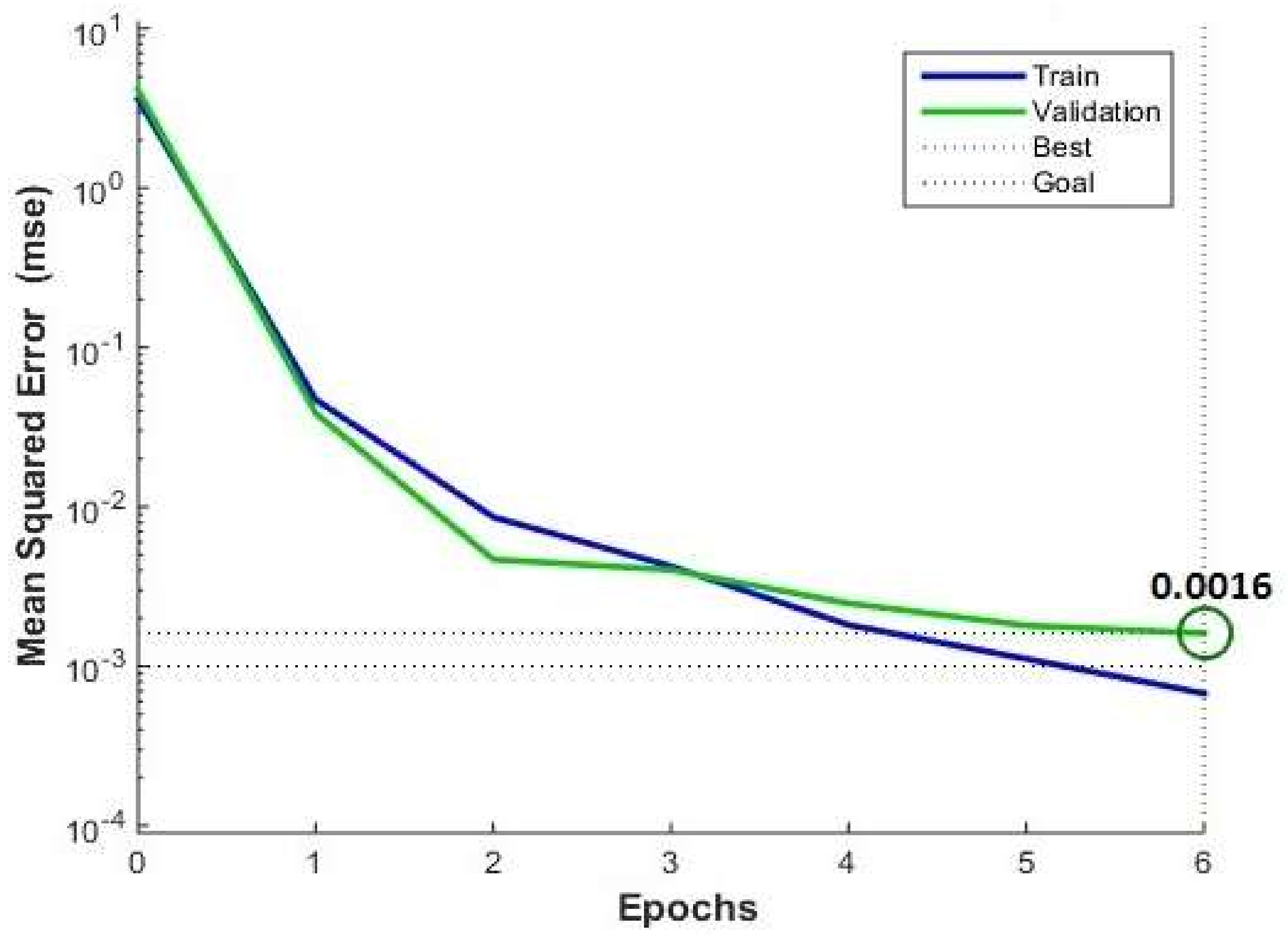
The mean relative errors (MRE) of the water and energy demand forecast from 1991 to 2016 are 1.58% and 2.71%, respectively. The neural network training performance can be seen in
Figure 2. In the BP algorithm, an epoch of the net training means the finish of two stages, the forward propagation of signals, and the back propagation of errors, with the weight and threshold modified. From
Figure 2, the validation shows the best performance in the 6th epoch and shows that the mean square error has reached the accuracy requirements (
mse = 0.001). This finding indicates that the network training speed is quickly trained by the Levenberg–Marquardt algorithm. Additionally, the training and validation line fits well, which means that the model offers strong generalization capacities and can be applied to forecast new data.
- (2)
Rolling forecast results
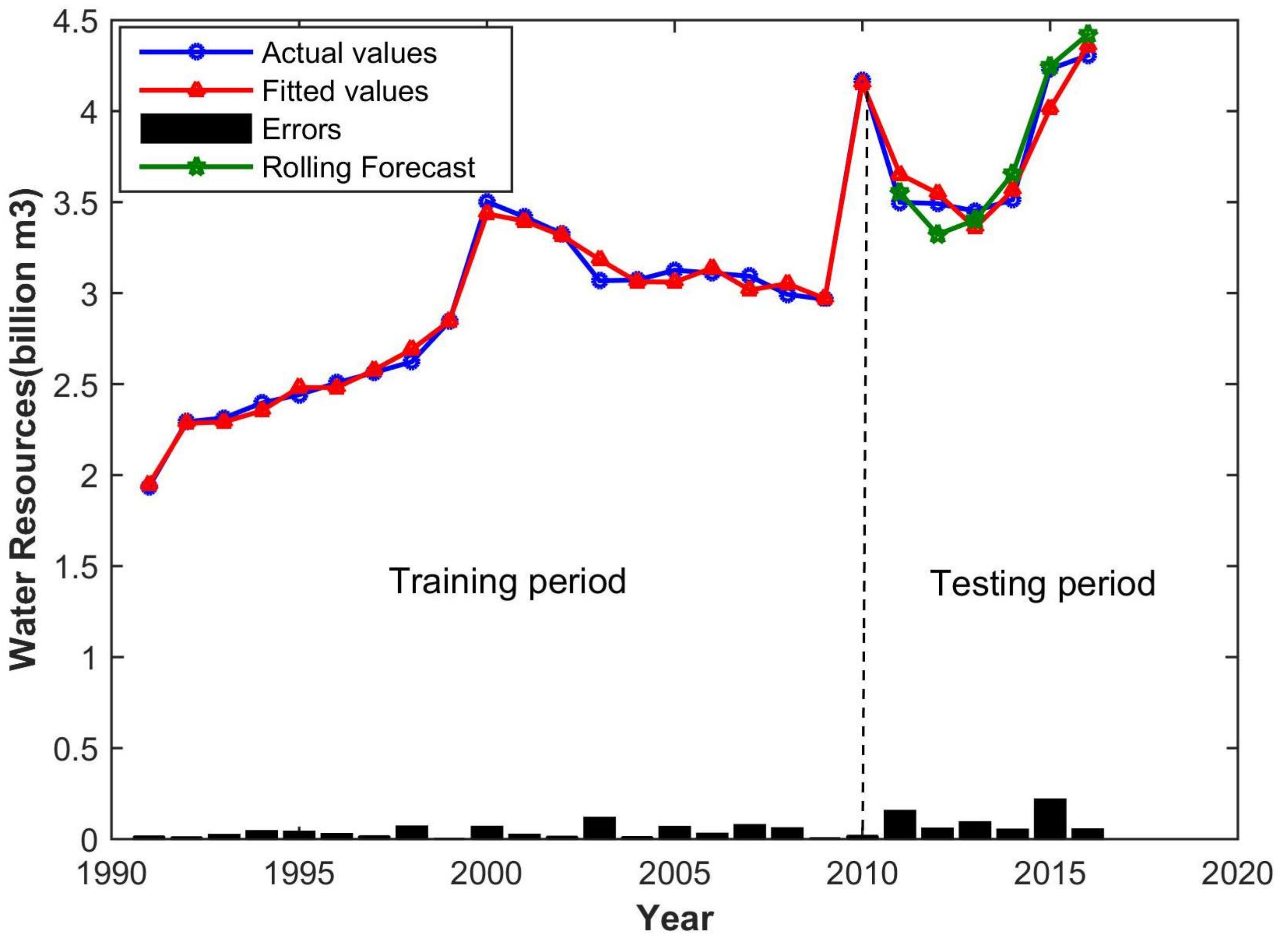
The MRE of water demand and energy demand are 2.49% and 3.95%, respectively, which indicates that the network is highly stable and adaptable and can be used to predict future demand trends.
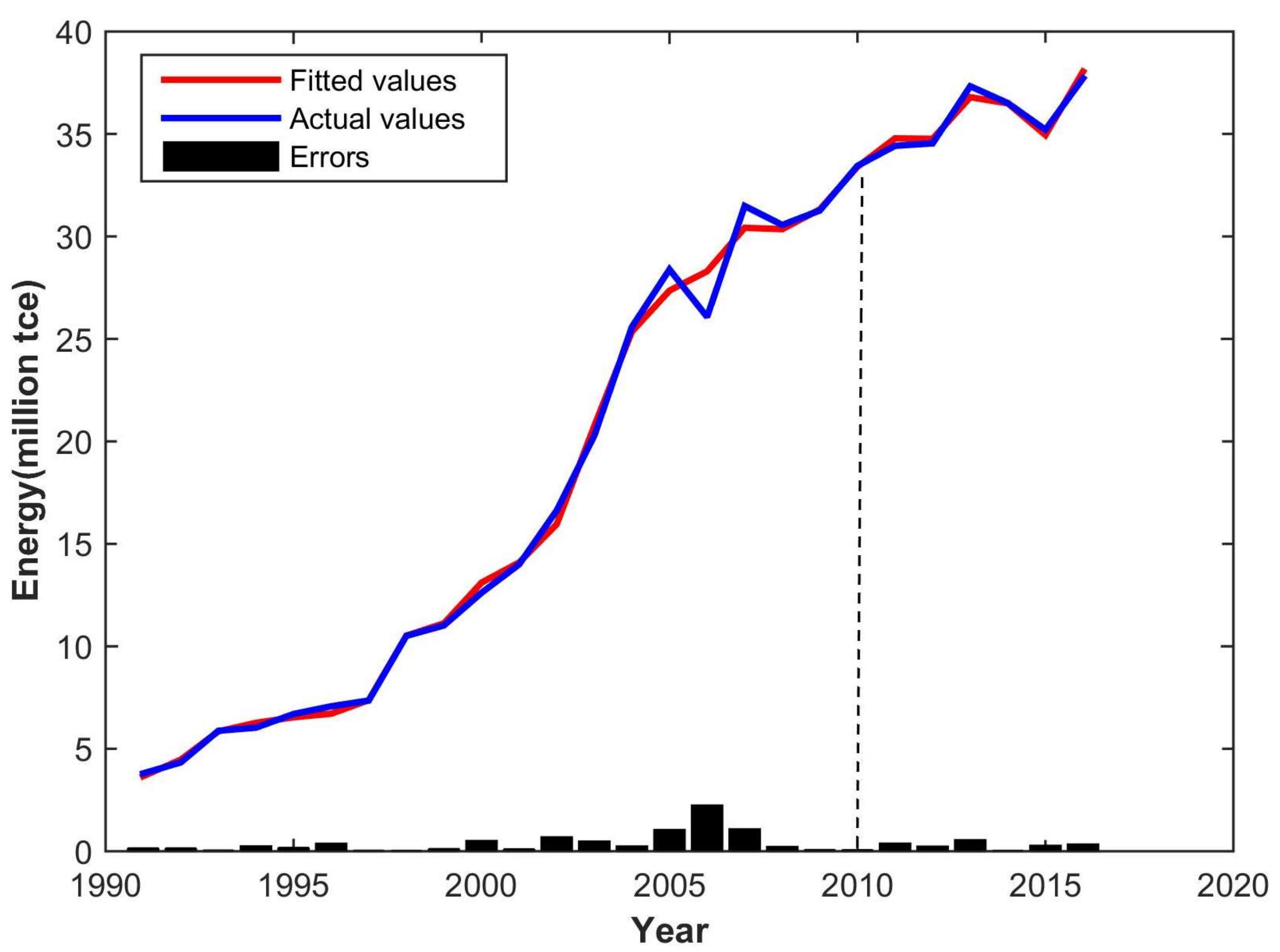
Graphs of the actual value and forecast result of water and energy demand for Wuxi are shown in
Figure 3 and
Figure 4.
- (3)
Planning level year forecast
Most of the input data for 2020 and 2030 were collected from the Wuxi’s statistical department. The primary, secondary, and tertiary industry GDP were forecast according to the average annual growth rate for the past five years.
According to a plan to further develop the Yangtze River Delta’s urban agglomerations [
28], we obtained the total population index. The urban population was calculated with the urbanization rate up to 77% and 78% in year 2020 and 2030. We chose the average annual precipitation as the value in 2030 and the average for the last five years for 2020.
Tap water supply index was achieved by using the water quota of residents in the south of Jiangsu [
29]. According to the plan for the construction of sewage treatment plants in Wuxi, the daily sewage treatment capacity was forecasted.
Based on the National Strategic Action Plan for Energy Development (2014–2020 Years), consumption of coal in industrial enterprises above designed size was predicted.
Other indices were forecast using the basic time series method which can be stimulated by Oracle Crystal Ball Software [
30]. Due to the persistent effort in saving water in the past five years, the water consumption per ten thousand yuan for primary industry and secondary industry are both decreasing slowly, information about which can be obtained from
Water Resources Bulletin of Wuxi. We forecasted the two indices with their average annual rate of decline (from 2011 to 2016) and then calculated the agricultural and industrial water consumption in 2020 and 2030.
Total discharging of industrial wastewater was done using the second exponential smoothing method [
31]. An Autoregressive Integrated Moving Average Model [
32] was used to derive total and domestic electricity consumption for the whole of society. We used the model to forecast the water and energy demand for 2020 and 2030 based on the data shown in
Table 1 as input values. The corresponding results are shown in
Table 2.
According to the
13th Five-Year Plan for Water Resources Development in Jiangsu Province [
33], the province’s total water use is controlled at 52.4 billion m
3 for 2020. The water demand forecast in Wuxi is forecasted to reach 4.843 billion m
3 in 2020 according to
the Plan for Water Resources Management in Wuxi under the Three Red Lines [
34]. Compared with the planning objectives, the forecasted data calculated by the neural network model is reasonable. However, according to
the 13th Five-Year Plan for Energy Development of Wuxi [
35], the city has focused strictly on controlling the energy consumption intensity and the total consumption of coal. It has been vigorously applying new energy to promote a clean energy structure. As a result, the total energy demand in the future increases slowly, and even has the possibility of negative growth. Therefore, the comprehensive forecast for the network model is relatively accurate and worthy of reference.
5.2. Results of MLR
The MREs of the water and energy demand fittings are 3.88% and 2.04%, respectively.
The regression coefficients of the MLR models used to fit water resources and energy demand are shown in
Table 3.
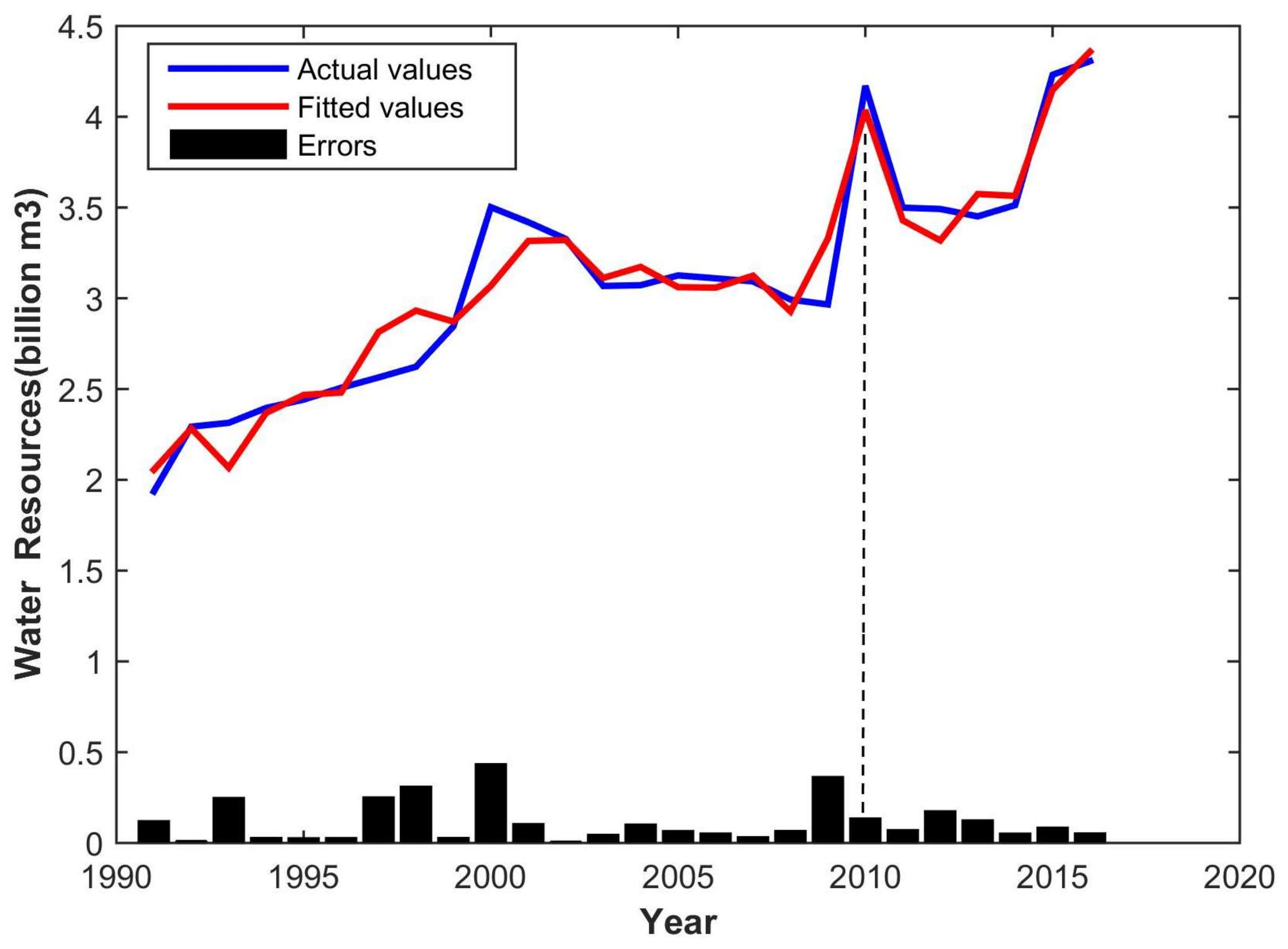
Figure 5 shows that the fitting of water resources is quite accurate on the whole, while energy fitting turns out better without considering the small errors of the middle section (
Figure 6).
According to MATLAB R2014b software results, the R2 values of the water and energy demand model are 0.9279 and 0.9976, respectively, indicating that both present strong fitness.
We used the model to forecast the water and energy demand for 2020 and 2030 using the data shown in
Table 1 as input values. The corresponding results are shown in
Table 4. A comparison of the ANN and MLR model is shown in
Table 5.
The MLR model appears to generate higher values of water and energy demand for the planning level year than that of the planning data written in documents. Overall, these results may serve as a point of comparison and offer support for the proposed ANN model.
From
Table 5, we can see that the ANN model shows a better performance in fitting data of both water and energy, with a lower average MRE of 2.14% while that of MLR is 3.96%.
6. Conclusions
This paper overcomes the limitations of current traditional forecasting methods for water resources or energy demand based on the water-energy nexus via the establishment of a comprehensive forecasting model for water resources and energy demand in urban areas based on the feedforward neural network. Fourteen indices were chosen from several factors that affect the urban water and energy demand as input parameters to establish the network. The traditional BP neural network with the single hidden layer was improved by using the water resources and energy demand as the outputs. A network model with two hidden layers with local approximations and strong non-linear mapping capacities was constructed. The network can thus forecast water and energy demand.
The network model was applied to Wuxi. The average relative error values for water and energy demand forecasts were 1.58% and 2.71% for the testing period, respectively, and 2.49% and 3.95% for the rolling forecast, respectively. These results indicate that the model has strong reliability and stability.
The average MRE for water and energy demand from the ANN model was 2.14% while that of the MLR is 3.96%. Both models exhibit excellent performance. Compared with the MLR model, the proposed method indicates that the ANN can be more efficiently used to measure water and energy demand. Moreover, the results reveal the consistency and accuracy of the ANN model.
The ANN model has also been used to forecast planning years in Wuxi. The forecast results are consistent with the local planning data, which means that the model has achieved satisfactory levels of accuracy and meets the actual forecasting requirements. Thus, this model can serve as a reference of the analysis of the supply and demand balance between urban water resources and energy levels and provide a foundation for the development of water and energy planning strategies. Further studies can be conducted on the following issues:
- (a)
The results obtained from the present study can be compared to the results obtained from different ANN training algorithms.
- (b)
Because the ANN tends to overfit the data, other AI models such as the Support Vector Machine (SVM) and General Regression Neural Network (GRNN) can be used to draw comparisons with the ANN [
36].
- (c)
Additional data and information on the water and energy demand for Wuxi must be generated through joint efforts between government officials and researchers.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





