
The Importance of Scale and the MAUP for Robust Ecosystem Service Evaluations and Landscape Decisions



Abstract
:1. Introduction
2. Background
3. Methods
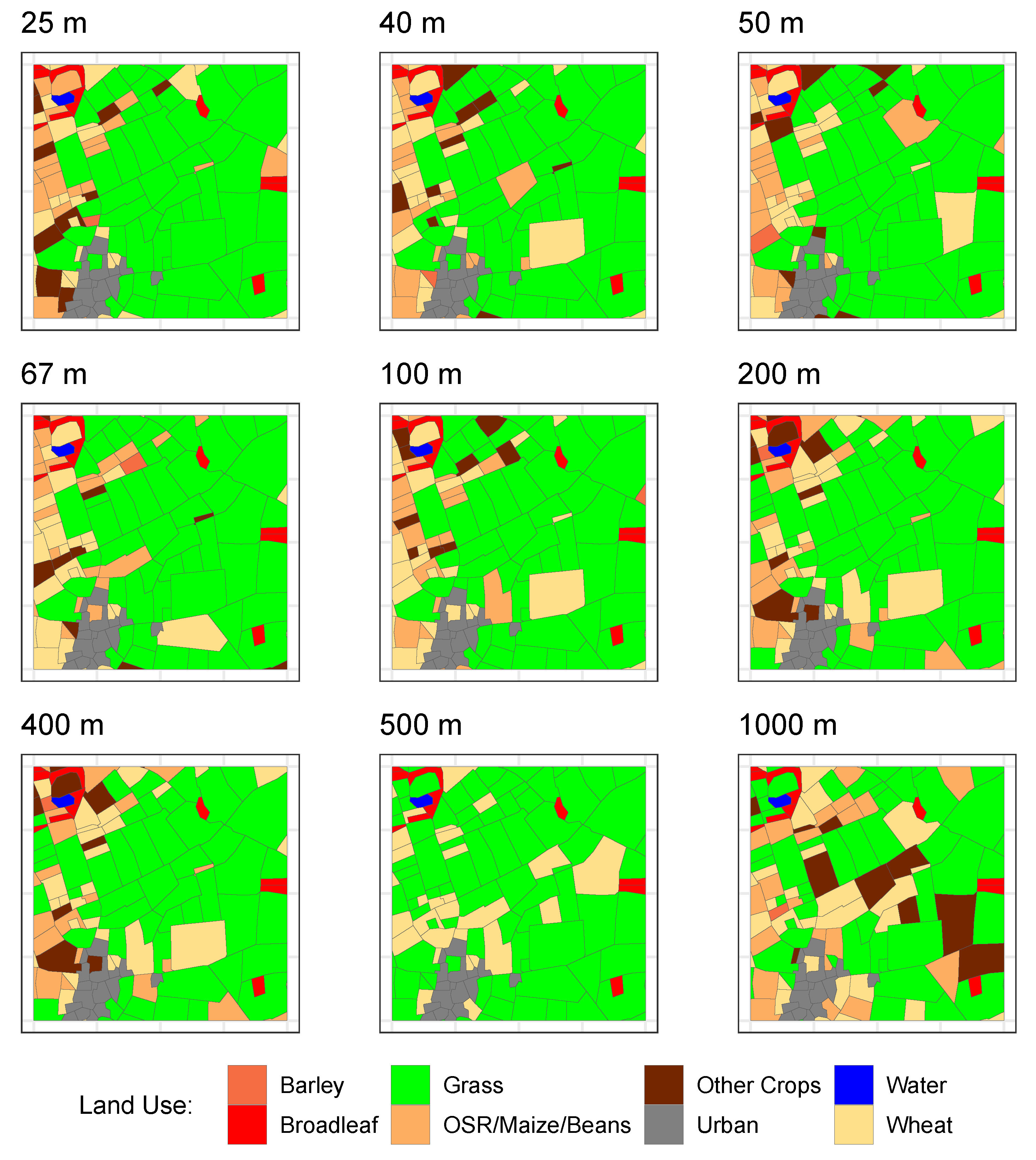
3.1. Data
3.2. Land Use Optimisation
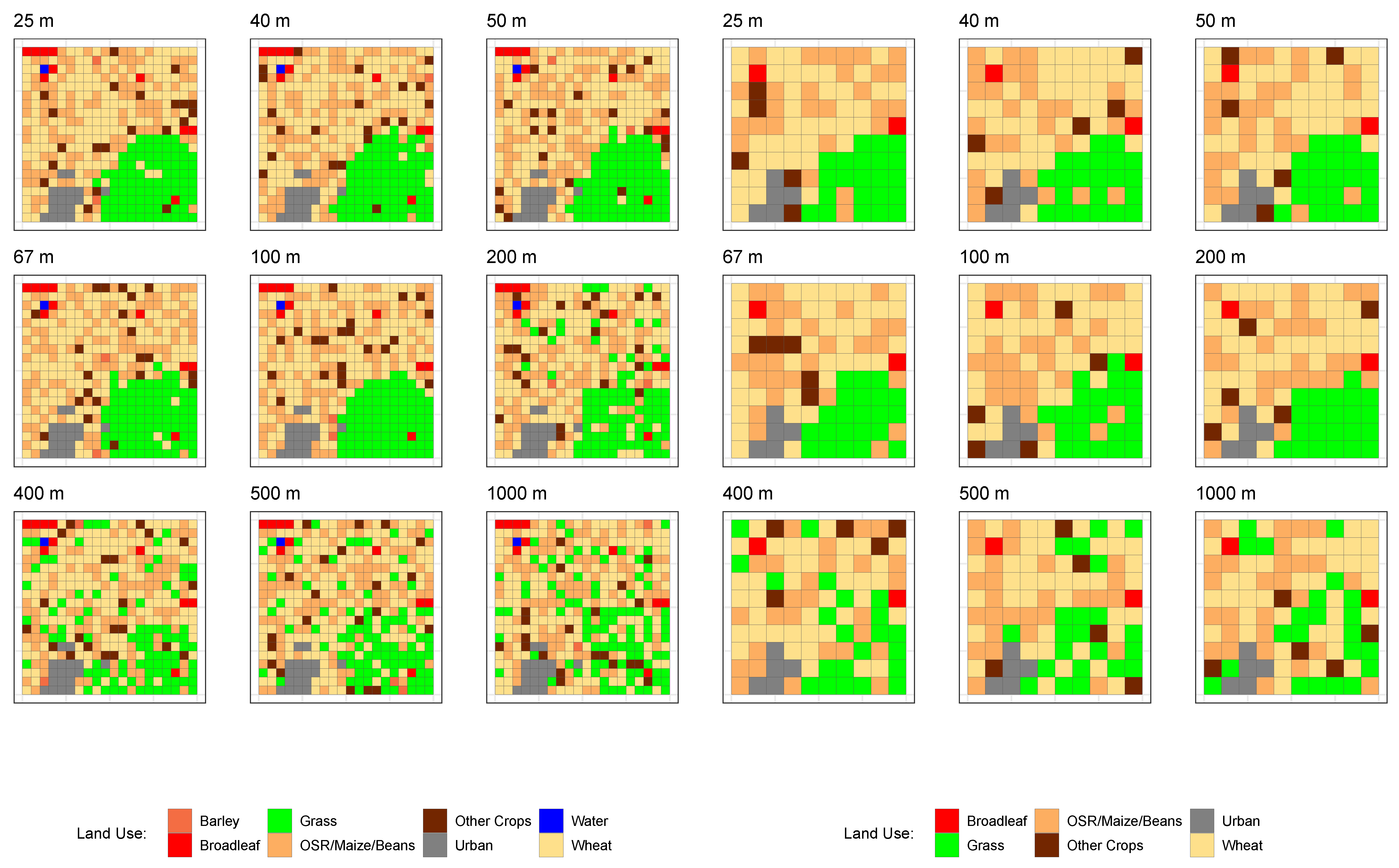
4. Results
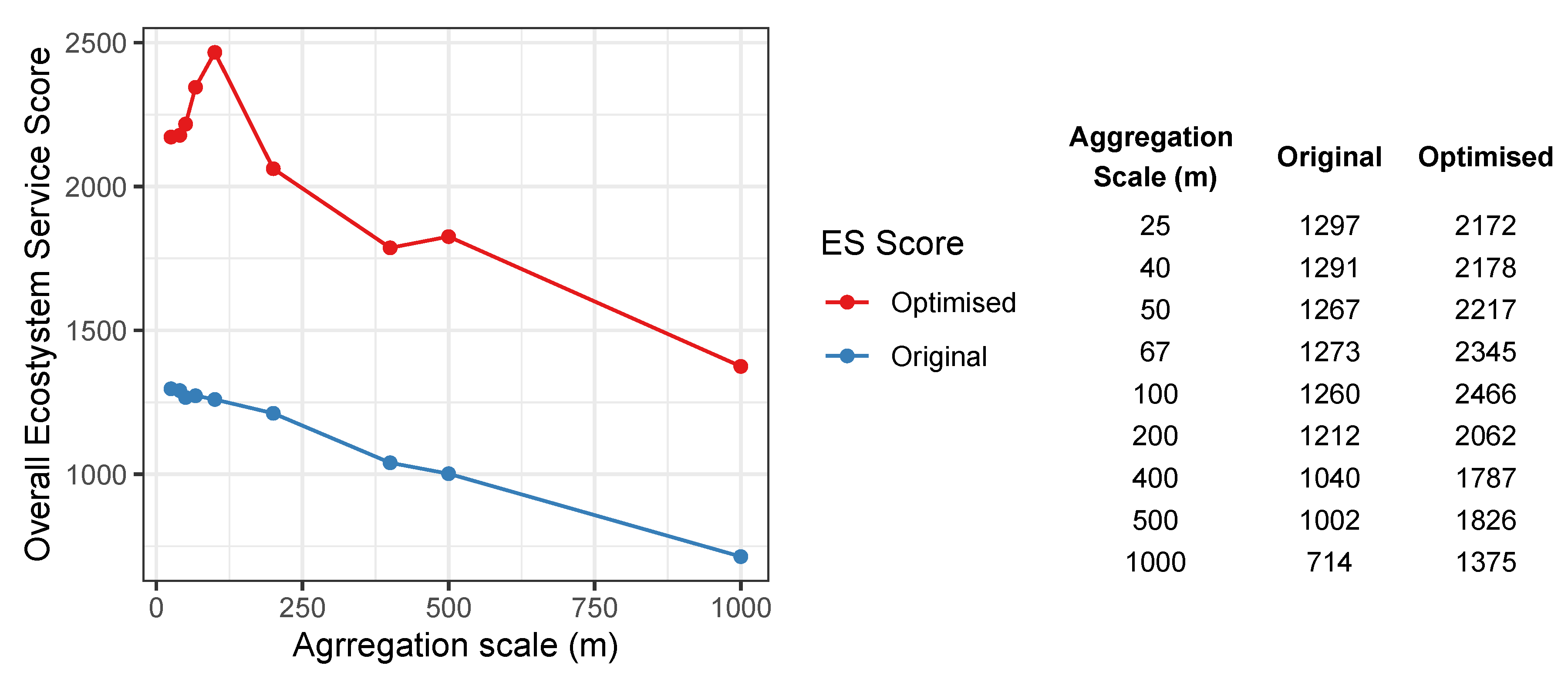
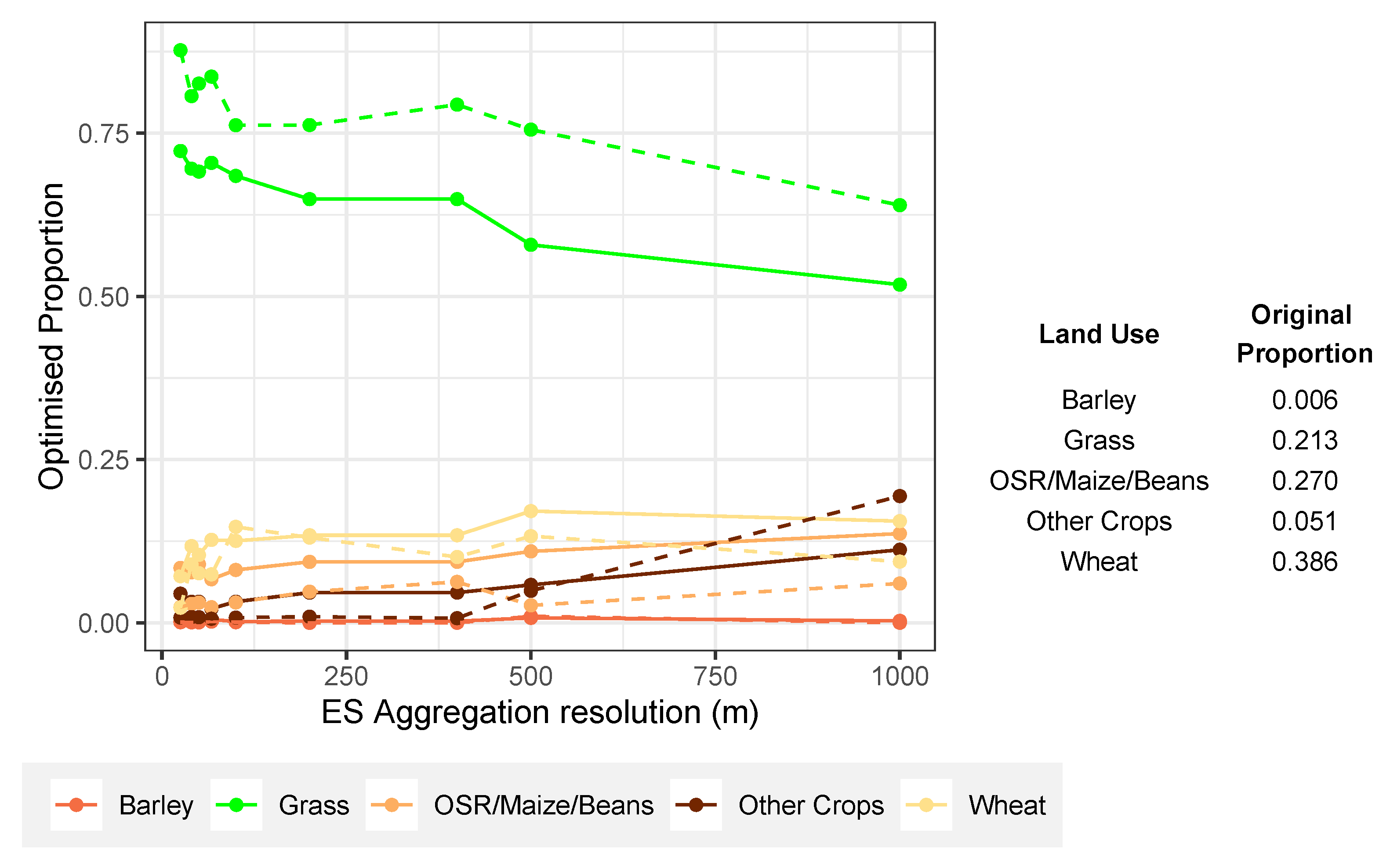
4.1. Vector (Field) Land Use Data with Gridded ES Surfaces
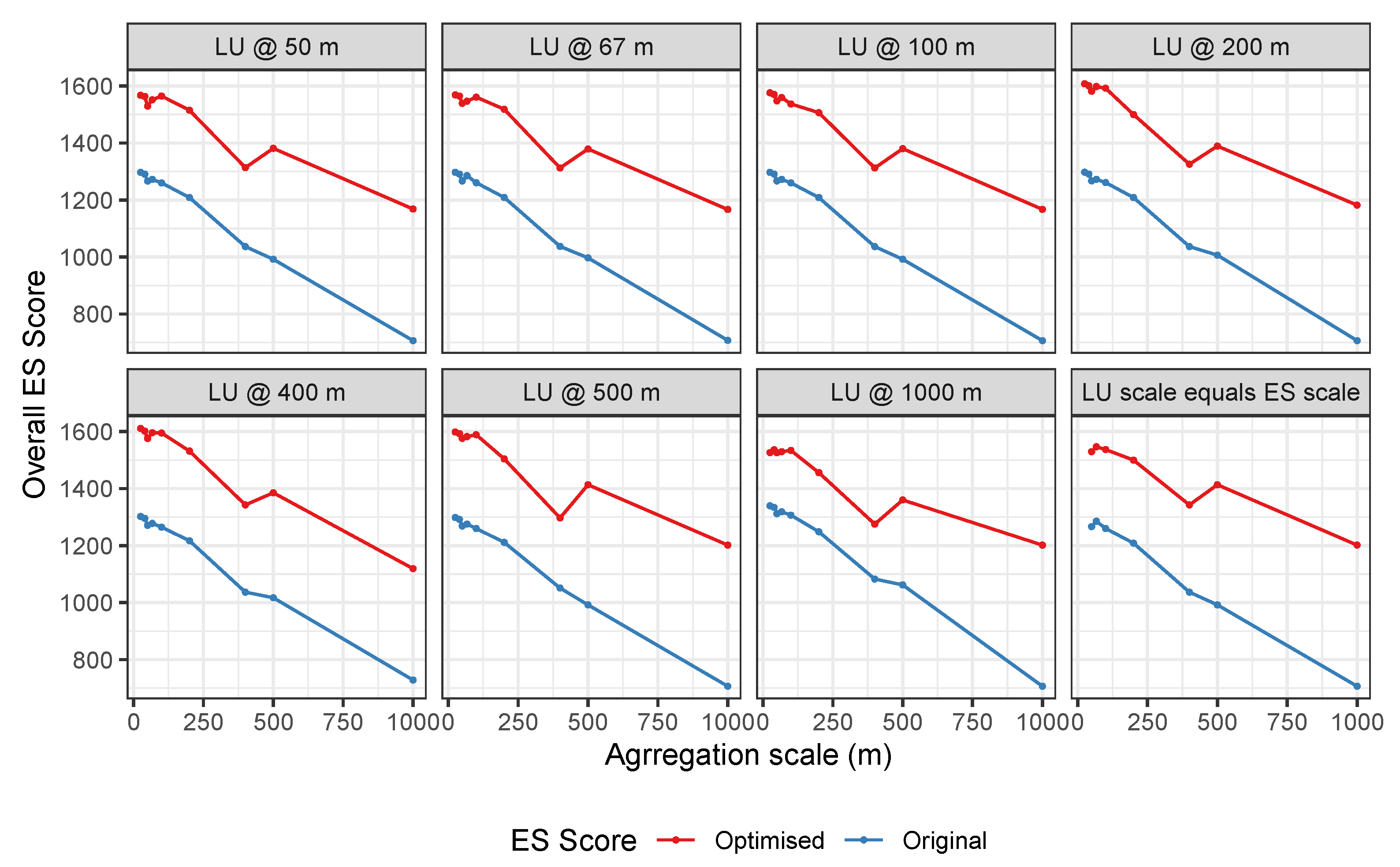
4.2. Aggregated Land Use Data with Gridded ES Surfaces
- The ES score trends for the different scales of land use aggregation are similar under each ES gradient aggregation scale;
- The ES scores generally decline with increased ES gradient aggregation scale, for both the original and optimised allocations;
- These overall decreasing trends in ES score for optimised land use allocation are disturbed under the ES grids of 100 m and 500 m (sharp increase);
- These patterns are replicated when optimisation is undertaken using land use data and ES gradients are aggregated to the same spatial scales.
5. Discussion
6. Conclusions
- MAUP should always be tested for. Any analysis of spatial data should routinely test for MAUP in order to understand the specific impacts of aggregations scales relative to the spatial support of the process being investigated. This is a common consideration in socio-economic analyses of spatial data [1] but has yet to be adopted in the ES domain and in work seeking to evaluate NC and to inform landscape decisions, land use planning and ES delivery.
- The scale of spatial data aggregations should be matched to the granularity of the processes being evaluated. This requires the identification of spatial scales at which the processes being investigated are considered to be stationary (stable) with respect to their variances, covariances and other moments in order to ensure that the results of any analyses, such as land use allocation in this study, are not affected by inherent scale mismatches. Here, these were observed under ES gradients aggregated to scales other than 100 and 500 m and can be determined by using local indicators of spatial association [34,35] or local spatial covariances [36].
- The impact of MAUP and aggregation scales should be evaluated alongside the scale of decision making. The support size and shape of the spatial units being used in spatial data analysis affect the patterns identified in the evaluations of ES and related concepts such as NC for a given spatial extent such as an agricultural field, a farm holding or river catchment.
- ES researchers and those in related disciplines (land use planning, landscape-scale decisions, etc.) should up-skill themselves in spatial analysis techniques. It is important that those undertaking research in these domains understand core paradigms associated with working with spatial data and understand techniques that are frequently used in spatial statistics. Scale blindness is commonly found in published ES research (as indicated above), where, for example, models constructed over one scale of spatial support are applied to data over another. Up-skilling is needed because powerful analytical tools that were previously the reserve of domain experts are now included in many off-the-shelf software environments and are easily applied in a naive manner. Such tools include those for spatial data aggregation (both up and down scaling), location allocation and spatial data integration. They will generate results without requiring the user to understand how to best parameterise them. Examples of similar misuse have been observed in the renewable energy literature with respect to land use [37].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brunsdon, C.; Comber, A. Opening practice: Supporting reproducibility and critical spatial data science. J. Geogr. Syst. 2021, 23, 477–496. [Google Scholar] [CrossRef]
- Spake, R.; Bellamy, C.; Gill, R.; Watts, K.; Wilson, T.; Ditchburn, B.; Eigenbrod, F. Forest damage by deer depends on cross-scale interactions between climate, deer density and landscape structure. J. Appl. Ecol. 2020, 57, 1376–1390. [Google Scholar] [CrossRef]
- Finch, T.; Day, B.H.; Massimino, D.; Redhead, J.W.; Field, R.H.; Balmford, A.; Green, R.E.; Peach, W.J. Evaluating spatially explicit sharing-sparing scenarios for multiple environmental outcomes. J. Appl. Ecol. 2021, 58, 655–666. [Google Scholar] [CrossRef]
- Openshaw, S. The Modifiable Areal Unit Problem, CATMOG 38; Geo Abstracts: Norwich, UK, 1984. [Google Scholar]
- Openshaw, S. Ecological fallacies and the analysis of areal census data. Environ. Plan. A 1984, 16, 17–31. [Google Scholar] [CrossRef] [Green Version]
- Dungan, J.L.; Perry, J.; Dale, M.; Legendre, P.; Citron-Pousty, S.; Fortin, M.J.; Jakomulska, A.; Miriti, M.; Rosenberg, M. A balanced view of scale in spatial statistical analysis. Ecography 2002, 25, 626–640. [Google Scholar] [CrossRef] [Green Version]
- Grêt-Regamey, A.; Weibel, B.; Bagstad, K.J.; Ferrari, M.; Geneletti, D.; Klug, H.; Schirpke, U.; Tappeiner, U. On the effects of scale for ecosystem services mapping. PLoS ONE 2014, 9, e112601. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Graham, A. Issues of scale and uncertainty in the global remote sensing of disease. Adv. Parasitol. 2006, 62, 79–118. [Google Scholar]
- Comber, A.J.; Harris, P.; Lü, Y.; Wu, L.; Atkinson, P.M. The Forgotten Semantics of Regression Modeling in Geography. Geogr. Anal. 2021, 53, 113–134. [Google Scholar] [CrossRef] [Green Version]
- Jones, K.; Manley, D.; Johnston, R.; Owen, D. Modelling residential segregation as unevenness and clustering: A multilevel modelling approach incorporating spatial dependence and tackling the MAUP. Environ. Plan. Urban Anal. City Sci. 2018, 45, 1122–1141. [Google Scholar] [CrossRef] [Green Version]
- Arbia, G.; Espa, G. Effects of the MAUP on image classification. Geogr. Syst. 1996, 3, 123–141. [Google Scholar]
- Gotway, C.A.; Young, L.J. Combining incompatible spatial data. J. Am. Stat. Assoc. 2002, 97, 632–648. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Atkinson, P.; Goodchild, M.F. Scale in Spatial Information and Analysis; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Murakami, D.; Tsutsumi, M. Area-to-point parameter estimation with geographically weighted regression. J. Geogr. Syst. 2015, 17, 207–225. [Google Scholar] [CrossRef] [Green Version]
- Fotheringham, A.S.; Wong, D.W. The modifiable areal unit problem in multivariate statistical analysis. Environ. Plan. A 1991, 23, 1025–1044. [Google Scholar] [CrossRef]
- Navas, A.L.A.; Osei, F.; Magalhães, R.J.S.; Leonardo, L.R.; Stein, A. Modelling the impact of MAUP on environmental drivers for Schistosoma japonicum prevalence. Parasites Vectors 2020, 13, 1–18. [Google Scholar]
- Zen, M.; Candiago, S.; Schirpke, U.; Vigl, L.E.; Giupponi, C. Upscaling ecosystem service maps to administrative levels: Beyond scale mismatches. Sci. Total Environ. 2019, 660, 1565–1575. [Google Scholar] [CrossRef]
- Frazier, A.E.; Kedron, P. Landscape metrics: Past progress and future directions. Curr. Landsc. Ecol. Rep. 2017, 2, 63–72. [Google Scholar] [CrossRef] [Green Version]
- Hellsten, S. A Spatio-Temporal Ammonia Emissions Inventory for the UK. Ph.D. Thesis, University of Edinburgh, Edinburgh, UK, 2006. [Google Scholar]
- Harper, A.B.; Powell, T.; Cox, P.M.; House, J.; Huntingford, C.; Lenton, T.M.; Sitch, S.; Burke, E.; Chadburn, S.E.; Collins, W.J.; et al. Land-use emissions play a critical role in land-based mitigation for Paris climate targets. Nat. Commun. 2018, 9, 2938. [Google Scholar] [CrossRef] [Green Version]
- Rowland, C.; Morton, D.; Carrasco Tornero, L.; McShane, G.; O’Neil, A.; Wood, C. Land Cover Map 2015 (Vector, GB); NERC Environmental Information Data Centre: Gwynedd, UK, 2017. [Google Scholar] [CrossRef]
- Rowland, C.; Morton, D.; Carrasco Tornero, L.; McShane, G.; O’Neil, A.; Wood, C. Land Cover Map 2015 (25 m Raster, GB); NERC Environmental Information Data Centre: Gwynedd, UK, 2017. [Google Scholar] [CrossRef]
- Rowland, C.; Morton, D.; Carrasco Tornero, L.; McShane, G.; O’Neil, A.; Wood, C. Land Cover Map 2015 (1 km Dominant Target Class, GB); NERC Environmental Information Data Centre: Gwynedd, UK, 2017. [Google Scholar] [CrossRef]
- Smith, A.; Dunford, R. Land-Cover Scores for Ecosystem Service Assessment. 2018. Available online: https://www.eci.ox.ac.uk/research/ecosystems/bio-clim-adaptation/downloads/bicester-2018-Land-cover-scoring-method%20.pdf (accessed on 26 April 2019).
- Falkenauer, E. Genetic Algorithms and Grouping Problems; John Wiley & Sons Inc.: Hoboken, NJ, USA, 1998. [Google Scholar]
- Comber, A.J.; Sasaki, S.; Suzuki, H.; Brunsdon, C. A modified grouping genetic algorithm to select ambulance site locations. Int. J. Geogr. Inf. Sci. 2011, 25, 807–823. [Google Scholar] [CrossRef] [Green Version]
- Sasaki, S.; Comber, A.J.; Suzuki, H.; Brunsdon, C. Using genetic algorithms to optimise current and future health planning-the example of ambulance locations. Int. J. Health Geogr. 2010, 9, 4. [Google Scholar] [CrossRef] [Green Version]
- Brown, E.C.; Sumichrast, R.T. Evaluating performance advantages of grouping genetic algorithms. Eng. Appl. Artif. Intell. 2005, 18, 1–12. [Google Scholar] [CrossRef]
- Willighagen, E. R Based Genetic Algorithm, R Package Version 2005; p. 1. Available online: https://cran.r-project.org/web/packages/genalg/index.html (accessed on 26 April 2019).
- Fisher, P. The pixel: A snare and a delusion. Int. J. Remote Sens. 1997, 18, 679–685. [Google Scholar] [CrossRef]
- Raudsepp-Hearne, C.; Peterson, G.D.; Bennett, E.M. Ecosystem service bundles for analyzing tradeoffs in diverse landscapes. Proc. Natl. Acad. Sci. USA 2010, 107, 5242–5247. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mouchet, M.A.; Lamarque, P.; Martín-López, B.; Crouzat, E.; Gos, P.; Byczek, C.; Lavorel, S. An interdisciplinary methodological guide for quantifying associations between ecosystem services. Glob. Environ. Chang. 2014, 28, 298–308. [Google Scholar] [CrossRef]
- Spake, R.; Lasseur, R.; Crouzat, E.; Bullock, J.M.; Lavorel, S.; Parks, K.E.; Schaafsma, M.; Bennett, E.M.; Maes, J.; Mulligan, M.; et al. Unpacking ecosystem service bundles: Towards predictive mapping of synergies and trade-offs between ecosystem services. Glob. Environ. Chang. 2017, 47, 37–50. [Google Scholar] [CrossRef] [Green Version]
- Anselin, L. Local indicators of spatial association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Hui, C. A Bayesian solution to the modifiable areal unit problem. In Foundations of Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2, pp. 175–196. [Google Scholar]
- Harris, P.; Charlton, M.; Fotheringham, A.S. Moving window kriging with geographically weighted variograms. Stoch. Environ. Res. Risk Assess. 2010, 24, 1193–1209. [Google Scholar] [CrossRef] [Green Version]
- Comber, A.; Dickie, J.; Jarvis, C.; Phillips, M.; Tansey, K. Locating bioenergy facilities using a modified GIS-based location–allocation-algorithm: Considering the spatial distribution of resource supply. Appl. Energy 2015, 154, 309–316. [Google Scholar] [CrossRef] [Green Version]
- Cressie, N.A. Change of support and the modifiable areal unit problem. Geogr. Syst. 1996, 3, 159–180. [Google Scholar]
- Young, L.J.; Gotway, C.A. Linking spatial data from different sources: The effects of change of support. Stoch. Environ. Res. Risk Assess. 2007, 21, 589–600. [Google Scholar] [CrossRef]
- Dark, S.J.; Bram, D. The modifiable areal unit problem (MAUP) in physical geography. Prog. Phys. Geogr. 2007, 31, 471–479. [Google Scholar] [CrossRef] [Green Version]
- Parenteau, M.P.; Sawada, M.C. The modifiable areal unit problem (MAUP) in the relationship between exposure to NO2 and respiratory health. Int. J. Health Geogr. 2011, 10, 58. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tuson, M.; Yap, M.; Kok, M.; Murray, K.; Turlach, B.; Whyatt, D. Incorporating geography into a new generalized theoretical and statistical framework addressing the modifiable areal unit problem. Int. J. Health Geogr. 2019, 18, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kyriakidis, P.C. A geostatistical framework for area-to-point spatial interpolation. Geogr. Anal. 2004, 36, 259–289. [Google Scholar] [CrossRef]
- Duque, J.C.; Laniado, H.; Polo, A. S-maup: Statistical test to measure the sensitivity to the modifiable areal unit problem. PLoS ONE 2018, 13, e0207377. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Classes | New Label |
|---|---|
| Spring barley, Winter barley | Barley |
| Broadleaf woodland | Broadleaf |
| Coniferous woodland | Coniferous |
| Grass, Improved grassland | Grass |
| Neutral grassland | Natural Grass |
| Field beans, Maize, Oilseed rape | OSR/Maize/Beans |
| Arable and horticulture, pother crops, Potatoes | Other Crops |
| Suburban, Urban | Urban |
| Freshwater | Water |
| Spring Wheat, Winter wheat (includes winter oats) | Wheat |
| Land Use | ES Score |
|---|---|
| Barley | 1 |
| Broadleaf | 5 |
| Grass | 2 |
| Natural Grass | 3 |
| OSR/Maize/Beans | 1 |
| Other Crops | 1 |
| Urban | 1 |
| Water | 3 |
| Wheat | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Comber, A.; Harris, P. The Importance of Scale and the MAUP for Robust Ecosystem Service Evaluations and Landscape Decisions. Land 2022, 11, 399. https://doi.org/10.3390/land11030399
Comber A, Harris P. The Importance of Scale and the MAUP for Robust Ecosystem Service Evaluations and Landscape Decisions. Land. 2022; 11(3):399. https://doi.org/10.3390/land11030399
Chicago/Turabian StyleComber, Alexis, and Paul Harris. 2022. "The Importance of Scale and the MAUP for Robust Ecosystem Service Evaluations and Landscape Decisions" Land 11, no. 3: 399. https://doi.org/10.3390/land11030399
APA StyleComber, A., & Harris, P. (2022). The Importance of Scale and the MAUP for Robust Ecosystem Service Evaluations and Landscape Decisions. Land, 11(3), 399. https://doi.org/10.3390/land11030399