

MEAHNE: miRNA–Disease Association Prediction Based on Semantic Information in a Heterogeneous Network

Abstract
:1. Introduction
2. Materials and Method
2.1. Data Collection and Construction of Heterogeneous Networks
2.2. Methods
2.2.1. Related Definitions
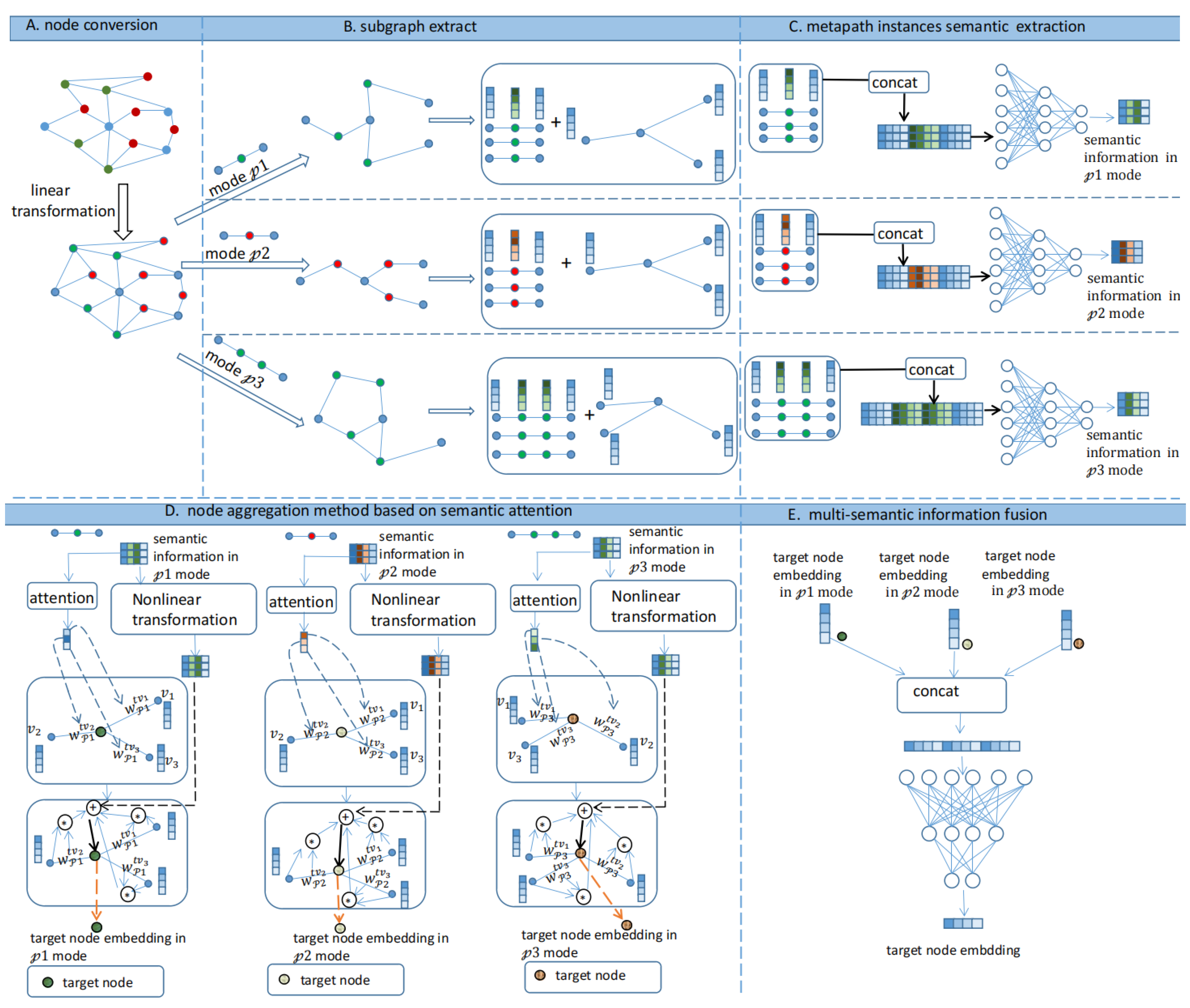
2.2.2. Specific Steps
- A.
- Node conversion
- B.
- Subgraph extraction
- C.
- Metapath instances semantic extraction
- D.
- Node aggregation method based on semantic attention
- E.
- Multisemantic information fusion
- F.
- Link prediction
3. Results and Discussion
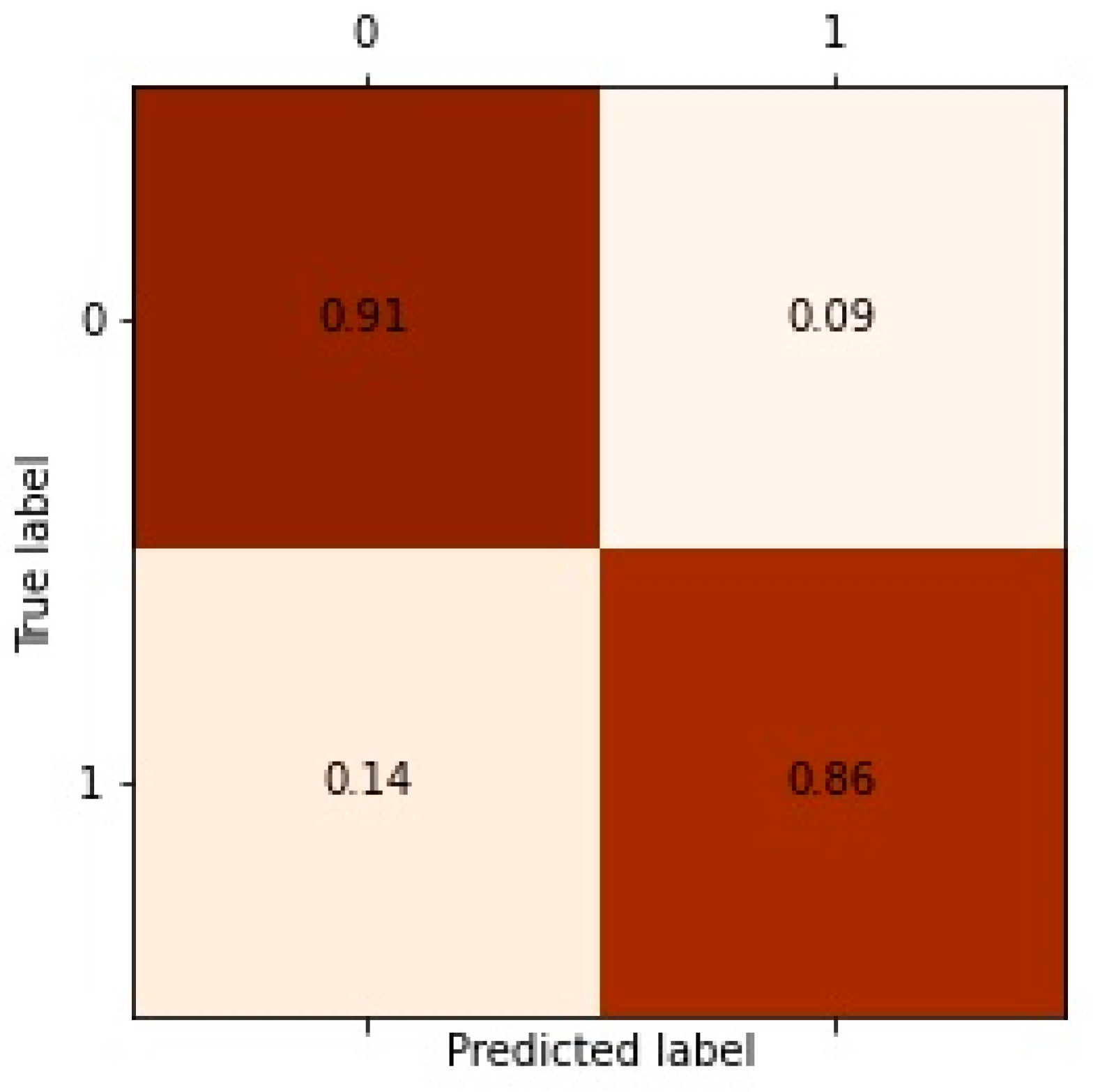
3.1. Experimental Data and Performance Evaluation
3.2. Factors Influencing Model Performance
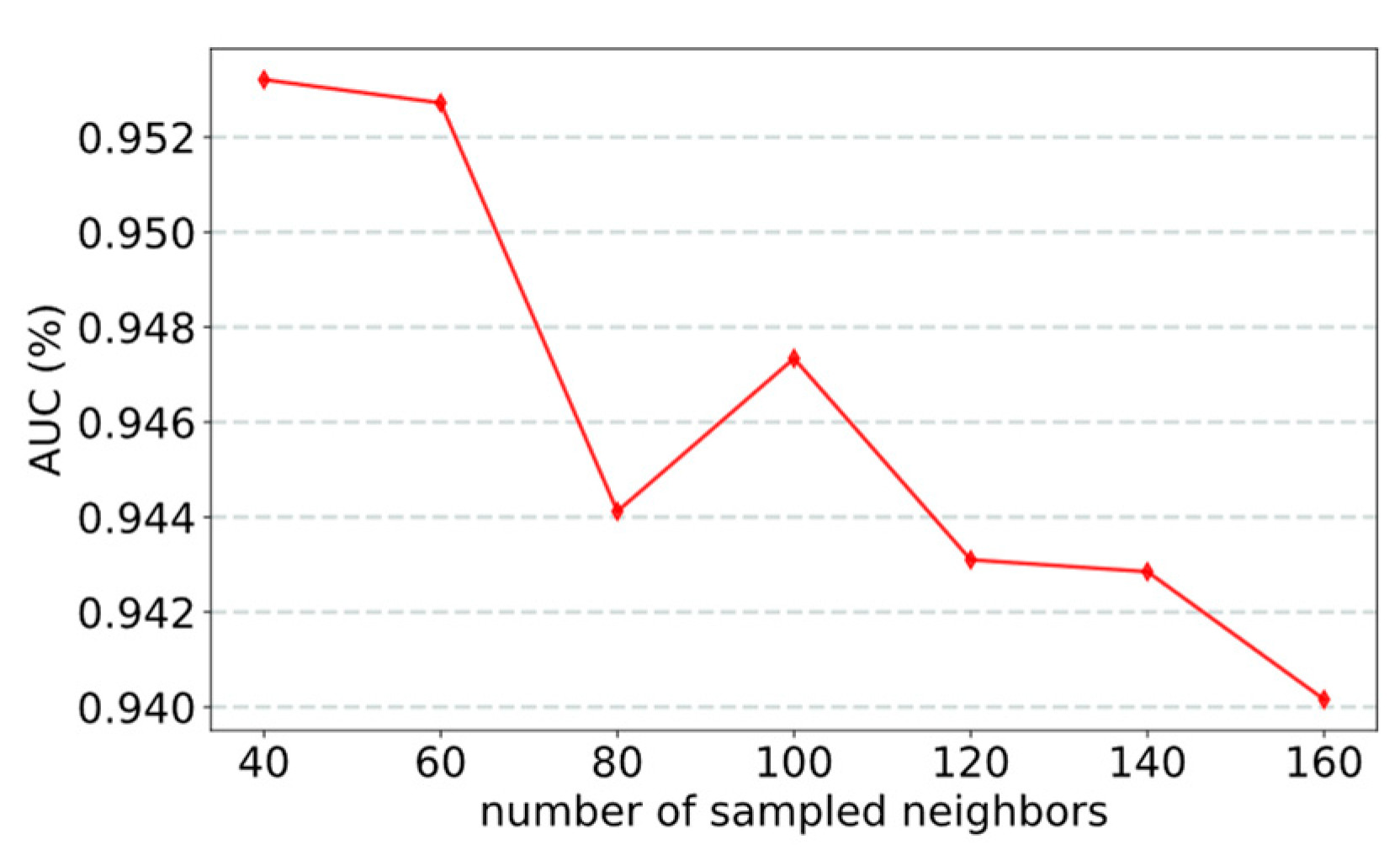
3.2.1. Effect of the Number of Sampled Neighbors
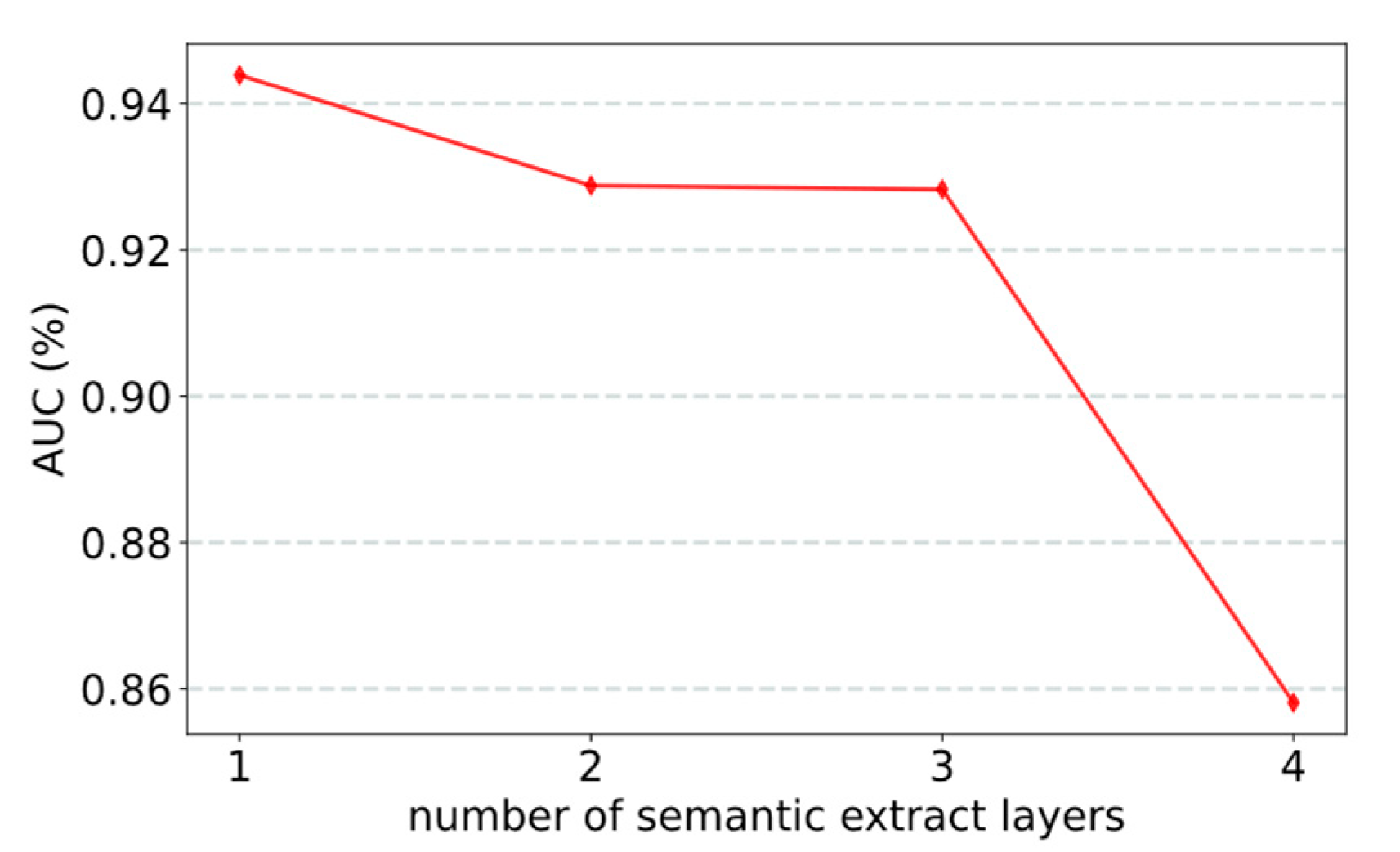
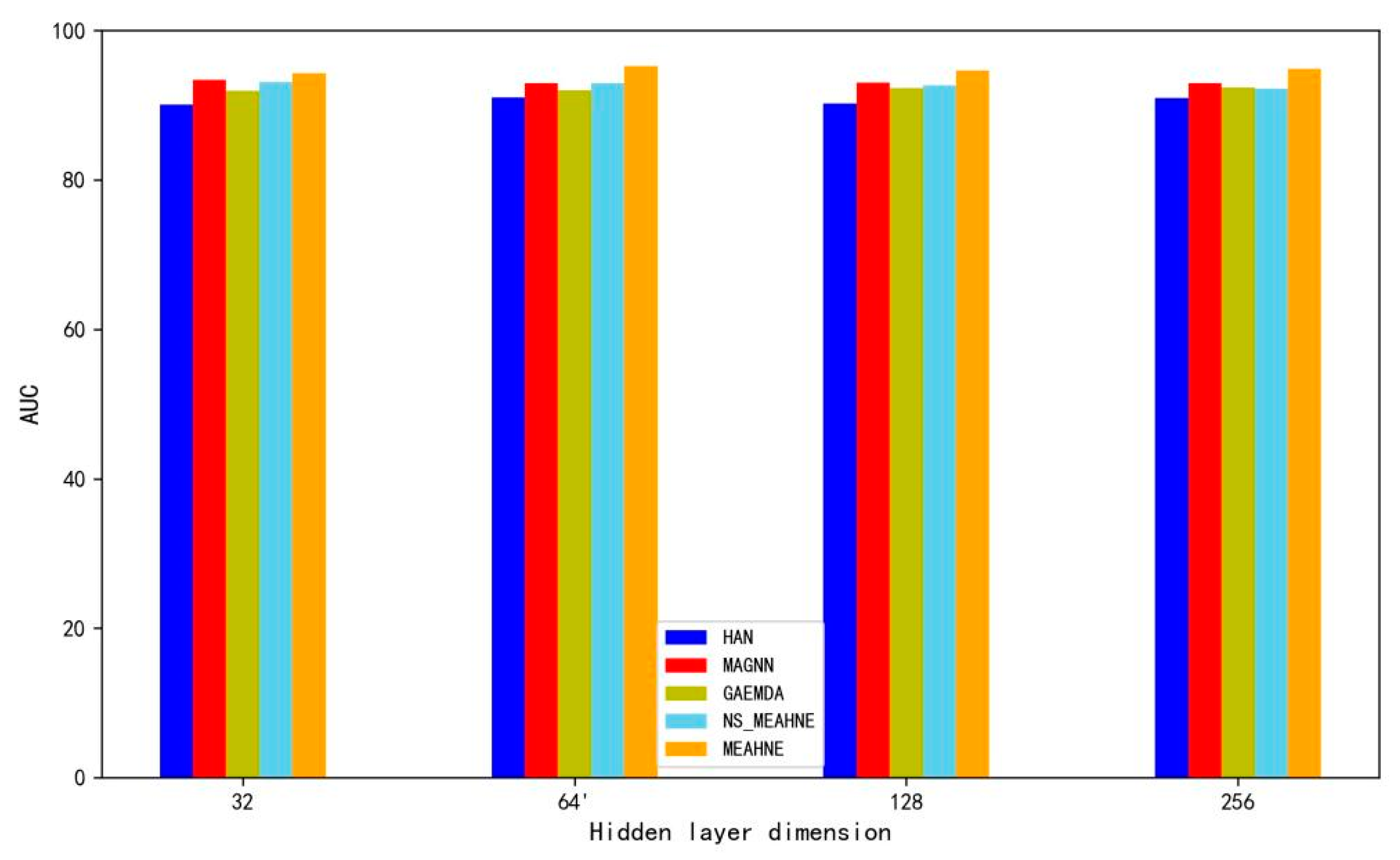
3.2.2. Effect of Number of Semantic Extract Layers
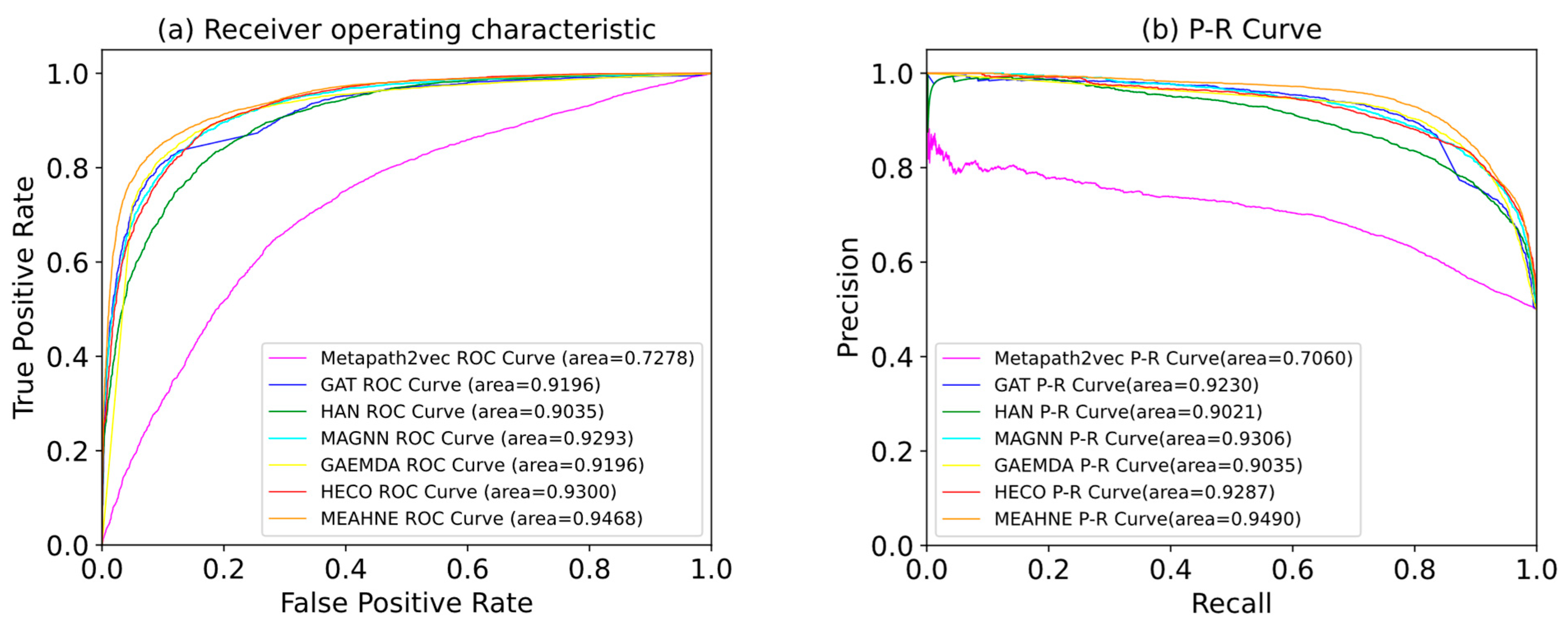
3.2.3. Comparison with Other Models
3.3. Case Study
3.4. Ablation Experiment
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Lee, R.C.; Ambros, V. An Extensive Class of Small RNAs in Caenorhabditis Elegans. Science 2001, 294, 862–864. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ambros, V. The Functions of Animal MicroRNAs. Nature 2004, 431, 350–355. [Google Scholar] [CrossRef] [PubMed]
- Lee, R.C.; Feinbaum, R.L.; Ambros, V. The C. Elegans Heterochronic Gene Lin-4 Encodes Small RNAs with Antisense Complementarity to Lin-14. Cell 1993, 75, 843–854. [Google Scholar] [CrossRef]
- Guo, C.; Sah, J.F.; Beard, L.; Willson, J.K.V.; Markowitz, S.D.; Guda, K. The Noncoding RNA, miR-126, Suppresses the Growth of Neoplastic Cells by Targeting Phosphatidylinositol 3-Kinase Signaling and Is Frequently Lost in Colon Cancers. Genes. Chromosomes Cancer 2008, 47, 939–946. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Calin, G.A.; Croce, C.M. MicroRNA Signatures in Human Cancers. Nat. Rev. Cancer 2006, 6, 857–866. [Google Scholar] [CrossRef] [PubMed]
- Cahill, S.; Smyth, P.; Denning, K.; Flavin, R.; Li, J.; Potratz, A.; Guenther, S.M.; Henfrey, R.; O’Leary, J.J.; Sheils, O. Effect of BRAFV600E Mutation on Transcription and Post-Transcriptional Regulation in a Papillary Thyroid Carcinoma Model. Mol. Cancer 2007, 6, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, L.; Hannon, G.J. MicroRNAs: Small RNAs with a Big Role in Gene Regulation. Nat. Rev. Genet. 2004, 5, 522–531. [Google Scholar] [CrossRef]
- Goh, J.N.; Loo, S.Y.; Datta, A.; Siveen, K.S.; Yap, W.N.; Cai, W.; Shin, E.M.; Wang, C.; Kim, J.E.; Chan, M.; et al. MicroRNAs in Breast Cancer: Regulatory Roles Governing the Hallmarks of Cancer. Biol. Rev. Camb. Philos. Soc. 2016, 91, 409–428. [Google Scholar] [CrossRef]
- Jiang, Y.; Liu, B.; Yu, L.; Yan, C.; Bian, H. Predict miRNA-Disease Association with Collaborative Filtering. Neuroinformatics 2018, 16, 363–372. [Google Scholar] [CrossRef]
- Chen, X.; Yan, C.C.; Zhang, X.; You, Z.-H.; Deng, L.; Liu, Y.; Zhang, Y.; Dai, Q. WBSMDA: Within and between Score for miRNA-Disease Association Prediction. Sci. Rep. 2016, 6, 21106. [Google Scholar] [CrossRef]
- Chen, X.; Liu, M.-X.; Yan, G.-Y. RWRMDA: Predicting Novel Human MicroRNA-Disease Associations. Mol. Biosyst. 2012, 8, 2792–2798. [Google Scholar] [CrossRef] [PubMed]
- You, Z.-H.; Huang, Z.-A.; Zhu, Z.; Yan, G.-Y.; Li, Z.-W.; Wen, Z.; Chen, X. PBMDA: A Novel and Effective Path-Based Computational Model for miRNA-Disease Association Prediction. PLoS Comput. Biol. 2017, 13, e1005455. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmadi, M.; Sharifi, A.; Jafarian Fard, M.; Soleimani, N. Detection of Brain Lesion Location in MRI Images Using Convolutional Neural Network and Robust PCA. Int. J. Neurosci. 2021, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Davoudi, A.; Ahmadi, M.; Sharifi, A.; Hassantabar, R.; Najafi, N.; Tayebi, A.; Kasgari, H.A.; Ahmadi, F.; Rabiee, M. Studying the Effect of Taking Statins before Infection in the Severity Reduction of COVID-19 with Machine Learning. BioMed Res. Int. 2021, 2021, 9995073. [Google Scholar] [CrossRef]
- Experimental and Numerical Diagnosis of Fatigue Foot Using Convolutional Neural Network. Available online: https://pubmed.ncbi.nlm.nih.gov/34121524/ (accessed on 7 October 2022).
- Wu, T.-R.; Yin, M.-M.; Jiao, C.-N.; Gao, Y.-L.; Kong, X.-Z.; Liu, J.-X. MCCMF: Collaborative Matrix Factorization Based on Matrix Completion for Predicting miRNA-Disease Associations. BMC Bioinform. 2020, 21, 454. [Google Scholar] [CrossRef]
- Chen, X.; Wang, L.; Qu, J.; Guan, N.-N.; Li, J.-Q. Predicting miRNA-Disease Association Based on Inductive Matrix Completion. Bioinformatics 2018, 34, 4256–4265. [Google Scholar] [CrossRef]
- Xu, J.; Li, C.-X.; Lv, J.-Y.; Li, Y.-S.; Xiao, Y.; Shao, T.-T.; Huo, X.; Li, X.; Zou, Y.; Han, Q.-L.; et al. Prioritizing Candidate Disease miRNAs by Topological Features in the miRNA Target-Dysregulated Network: Case Study of Prostate Cancer. Mol. Cancer Ther. 2011, 10, 1857–1866. [Google Scholar] [CrossRef] [Green Version]
- Xuan, P.; Han, K.; Guo, M.; Guo, Y.; Li, J.; Ding, J.; Liu, Y.; Dai, Q.; Li, J.; Teng, Z.; et al. Prediction of MicroRNAs Associated with Human Diseases Based on Weighted k Most Similar Neighbors. PLoS ONE 2013, 8, e70204. [Google Scholar] [CrossRef]
- Pasquier, C.; Gardès, J. Prediction of miRNA-Disease Associations with a Vector Space Model. Sci. Rep. 2016, 6, 27036. [Google Scholar] [CrossRef]
- Luo, J.; Xiao, Q.; Liang, C.; Ding, P. Predicting MicroRNA-Disease Associations Using Kronecker Regularized Least Squares Based on Heterogeneous Omics Data. IEEE Access 2017, 5, 2503–2513. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Velikovi, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Zhang, J.; Shi, X.; Xie, J.; Ma, H.; King, I.; Yeung, D.-Y. GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs. arXiv 2018. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. arXiv 2018. [Google Scholar] [CrossRef]
- Simonovsky, M.; Komodakis, N. GraphVAE: Towards Generation of Small Graphs Using Variational Autoencoders. arXiv 2018. [Google Scholar] [CrossRef]
- Li, J.; Zhang, S.; Liu, T.; Ning, C.; Zhang, Z.; Zhou, W. Neural Inductive Matrix Completion with Graph Convolutional Networks for miRNA-Disease Association Prediction. Bioinformatics 2020, 36, 2538–2546. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Li, J.; Nie, R.; You, Z.-H.; Bao, W. A Graph Auto-Encoder Model for miRNA-Disease Associations Prediction. Brief. Bioinform. 2021, 22, bbaa240. [Google Scholar] [CrossRef]
- Dong, Y.; Chawla, N.V.; Swami, A. Metapath2vec: Scalable Representation Learning for Heterogeneous Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17August 2017; pp. 135–144. [Google Scholar] [CrossRef]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Cui, P.; Yu, P.; Ye, Y. Heterogeneous Graph Attention Network. arXiv 2021. [Google Scholar] [CrossRef]
- Qu, Y.; Bai, T.; Zhang, W.; Nie, J.; Tang, J. An End-to-End Neighborhood-Based Interaction Model for Knowledge-Enhanced Recommendation. arXiv 2019. [Google Scholar] [CrossRef]
- Fu, X.; Zhang, J.; Meng, Z.; King, I. MAGNN: Metapath Aggregated Graph Neural Network for Heterogeneous Graph Embedding. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2331–2341. [Google Scholar] [CrossRef]
- Huang, Z.; Shi, J.; Gao, Y.; Cui, C.; Zhang, S.; Li, J.; Zhou, Y.; Cui, Q. HMDD v3.0: A Database for Experimentally Supported Human MicroRNA-Disease Associations. Nucleic Acids Res. 2019, 47, D1013–D1017. [Google Scholar] [CrossRef] [Green Version]
- Yao, D.; Zhang, L.; Zheng, M.; Sun, X.; Lu, Y.; Liu, P. Circ2Disease: A Manually Curated Database of Experimentally Validated CircRNAs in Human Disease. Sci. Rep. 2018, 8, 11018. [Google Scholar] [CrossRef] [Green Version]
- Piñero, J.; Bravo, À.; Queralt-Rosinach, N.; Gutiérrez-Sacristán, A.; Deu-Pons, J.; Centeno, E.; García-García, J.; Sanz, F.; Furlong, L.I. DisGeNET: A Comprehensive Platform Integrating Information on Human Disease-Associated Genes and Variants. Nucleic Acids Res. 2017, 45, D833–D839. [Google Scholar] [CrossRef]
- Yang, K.; Wang, R.; Liu, G.; Shu, Z.; Wang, N.; Zhang, R.; Yu, J.; Chen, J.; Li, X.; Zhou, X. HerGePred: Heterogeneous Network Embedding Representation for Disease Gene Prediction. IEEE J. Biomed. Health Inform. 2019, 23, 1805–1815. [Google Scholar] [CrossRef]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-Supervised Heterogeneous Graph Neural Network with Co-Contrastive Learning. arXiv 2021. [Google Scholar] [CrossRef]
- Yang, Z.; Wu, L.; Wang, A.; Tang, W.; Zhao, Y.; Zhao, H.; Teschendorff, A.E. DbDEMC 2.0: Updated Database of Differentially Expressed miRNAs in Human Cancers. Nucleic Acids Res. 2017, 45, D812–D818. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node | Number | Source Dataset |
|---|---|---|
| miRNA | 1296 | HMDD3.2/Circ2disease |
| Disease | 11,783 | DisGeNET/HMDD3.2 |
| Gene | 10,116 | Circ2disease/DisGeNET |
| Relationship | Number | Source |
|---|---|---|
| miRNA–disease | 17,972 | HMDD3.2 [33] |
| miRNA–gene | 4676 | Circ2disease [34] |
| Disease–gene | 84,038 | DisGeNET [35] |
| Gene–gene | 105,171 | HerGePred [36] |
| Model | AUC | AP | P@500 | P@1000 | P@1500 |
|---|---|---|---|---|---|
| Metapath2vec [29] | 72.78 | 70.60 | 99.60 | 95.44 | 80.12 |
| GAT [23] | 91.96 | 92.30 | 96.53 | 94.25 | 90.31 |
| HAN [30] | 92.35 | 92.21 | 99.56 | 99.13 | 96.09 |
| GAEMDA [28] | 91.96 | 90.35 | 99.50 | 98.21 | 94.89 |
| MAGNN [32] | 92.93 | 93.06 | 99.32 | 98.10 | 94.28 |
| HECO [37] | 93.00 | 92.87 | 99.14 | 98.35 | 93.46 |
| MEAHNE | 95.20 | 95.82 | 99.65 | 98.85 | 96.45 |
| miRNA | Breast Cancer | miRNA | Breast Cancer |
|---|---|---|---|
| hsa-mir-143 | * | hsa-mir-181b-2 | * |
| hsa-mir-296 | * | hsa-mir-29b-1 | * |
| hsa-mir-192 | * | hsa-mir-1-1 | |
| hsa-mir-133a-1 | hsa-mir-196a | * | |
| hsa-mir-382 | * | hsa-mir-148b | * |
| hsa-mir-34c | * | hsa-mir-26a-2 | * |
| hsa-mir-224 | * | hsa-mir-18 | * |
| hsa-mir-497 | * | hsa-mir-144 | * |
| hsa-mir-149 | * | hsa-mir-30d | * |
| hsa-mir-383 | * | hsa-mir-218-1 | * |
| miRNA | NPC | miRNA | NPC |
|---|---|---|---|
| hsa-mir-126 | * | hsa-mir-182 | |
| hsa-mir-210 | hsa-mir-196a | ||
| hsa-mir-17 | * | hsa-mir-34 | |
| hsa-mir-503 | * | hsa-mir-99a | * |
| hsa-mir-20a | * | hsa-mir-29b-1 | * |
| hsa-mir-18a | * | hsa-mir-192 | |
| hsa-mir-424 | * | hsa-mir-215 | |
| hsa-mir-221 | * | hsa-mir-335 | * |
| hsa-mir-375 | * | hsa-mir-342 | * |
| hsa-mir-150 | * | hsa-mir-100 | * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.; Cen, K.; Zhang, Y.; Liu, B.; Wang, Y.; Li, J. MEAHNE: miRNA–Disease Association Prediction Based on Semantic Information in a Heterogeneous Network. Life 2022, 12, 1578. https://doi.org/10.3390/life12101578
Huang C, Cen K, Zhang Y, Liu B, Wang Y, Li J. MEAHNE: miRNA–Disease Association Prediction Based on Semantic Information in a Heterogeneous Network. Life. 2022; 12(10):1578. https://doi.org/10.3390/life12101578
Chicago/Turabian StyleHuang, Chen, Keliang Cen, Yang Zhang, Bo Liu, Yadong Wang, and Junyi Li. 2022. "MEAHNE: miRNA–Disease Association Prediction Based on Semantic Information in a Heterogeneous Network" Life 12, no. 10: 1578. https://doi.org/10.3390/life12101578
APA StyleHuang, C., Cen, K., Zhang, Y., Liu, B., Wang, Y., & Li, J. (2022). MEAHNE: miRNA–Disease Association Prediction Based on Semantic Information in a Heterogeneous Network. Life, 12(10), 1578. https://doi.org/10.3390/life12101578