
Industrial X-ray Image Analysis with Deep Neural Networks Robust to Unexpected Input Data


Abstract
:1. Introduction
2. Background
3. Materials and Methods
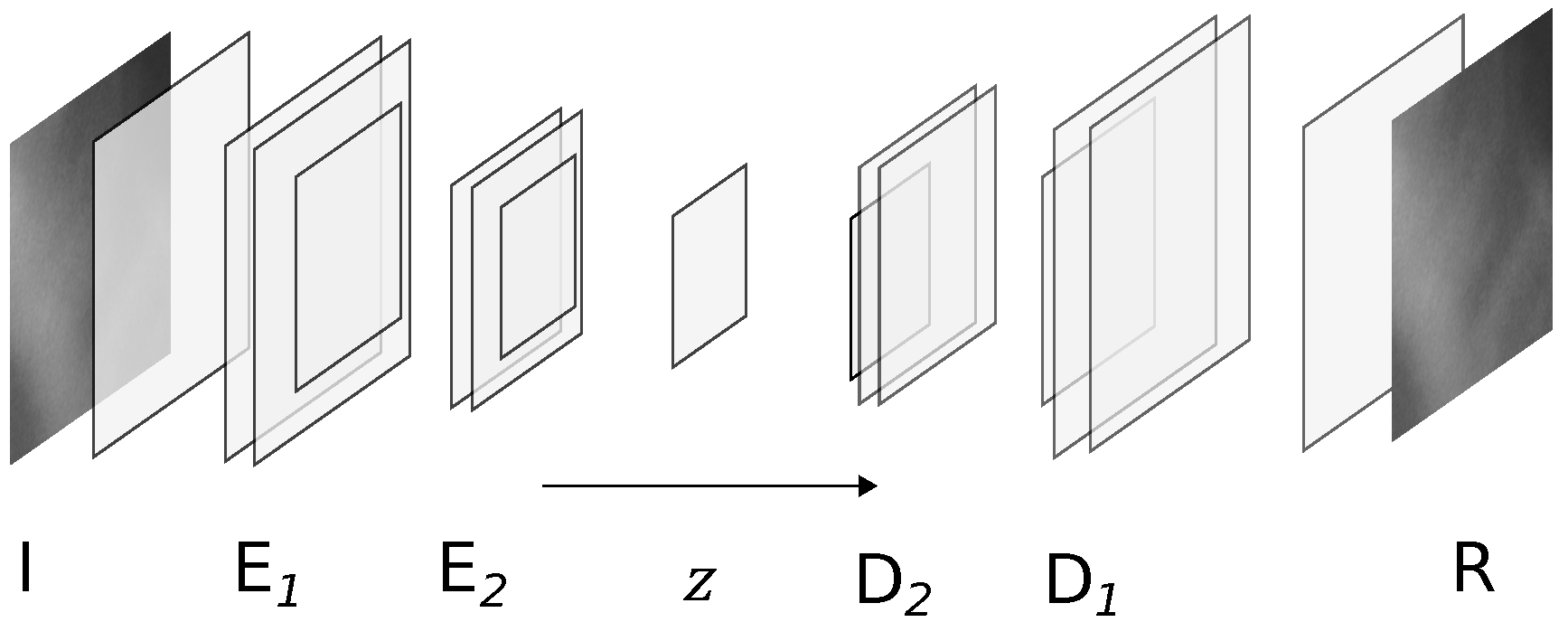
3.1. OOD Detector Model
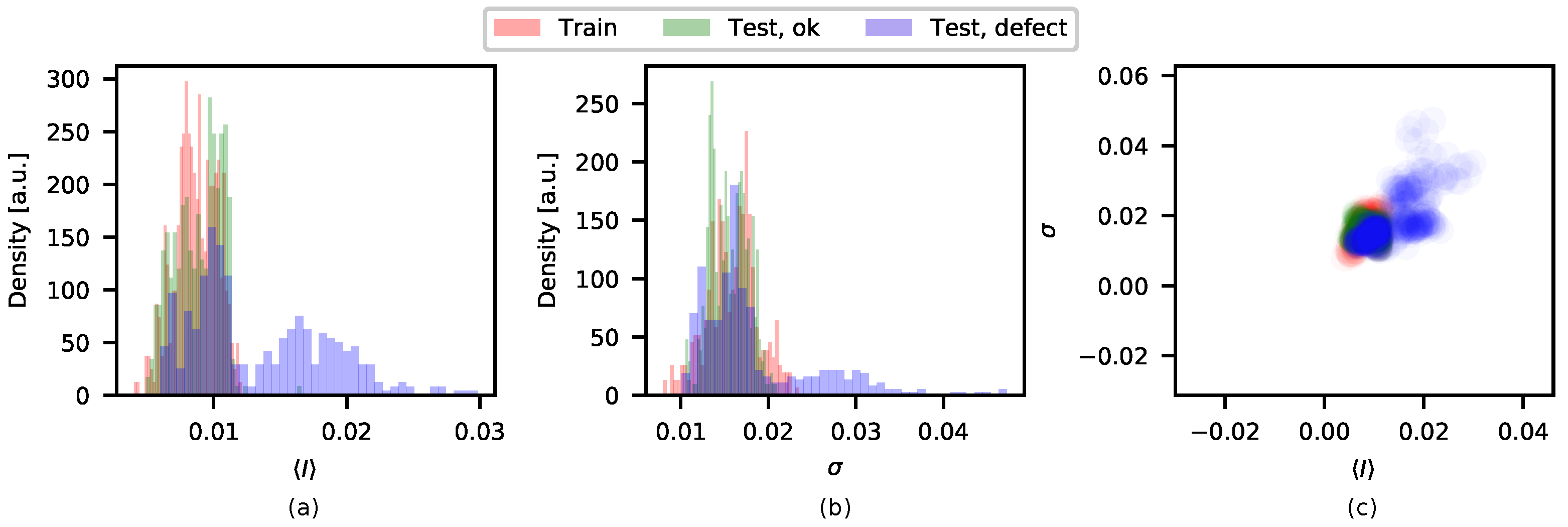
Residual Image Analysis
3.2. Binary Classifier Model Trained with Supervised-Learning
3.3. Datasets
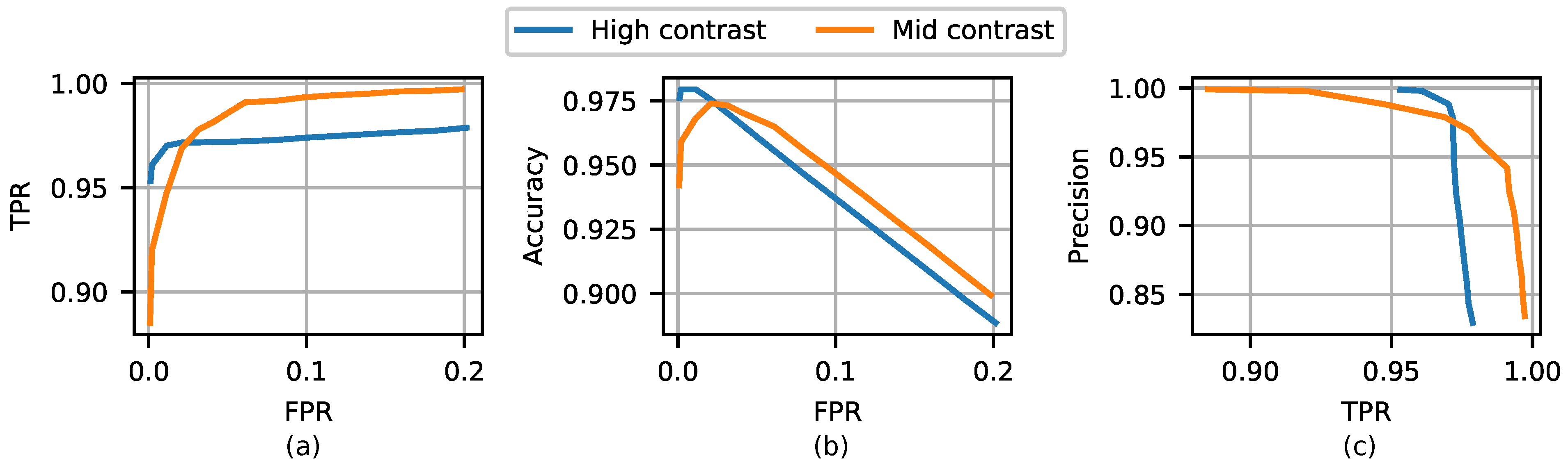
4. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, G.; Liao, W. Automatic identification of different types of welding defects in radiographic images. NDT&E Int. 2002, 35, 519–528. [Google Scholar]
- Dang, C.; Gao, J.; Wang, Z.; Xiao, Y.; Zhao, Y. A novel method for detecting weld defects accurately and reliably in radiographic images. Insight-Non-Destr. Test. Cond. Monit. 2016, 58, 28–34. [Google Scholar] [CrossRef]
- Silva, R.R.; Mery, D. State-ofthe-Art of Weld Seam Inspection by Radiographic Testing: Part I—Image Processing. Mater. Eval. 2007, 65, 643–647. [Google Scholar]
- Rathod, V.; Anand, R. A Comparative Study of Different Segmentation Techniques for Detection of Flaws in NDE Weld Images. J. Nondestruct. Eval. 2011, 31, 1–16. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kaftandjian, V.; Dupuis, O.; Babot, D.; Min Zhu, Y. Uncertainty modelling using Dempster–Shafer theory for improving detection of weld defects. Pattern Recognit. Lett. 2003, 24, 547–564. [Google Scholar] [CrossRef]
- Lashkia, V. Defect detection in X-ray images using fuzzy reasoning. Image Vis. Comput. 2001, 19, 261–269. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Lv, P.; Wang, H. Detection of line weld defects based on multiple thresholds and support vector machine. NDT&E Int. 2008, 41, 517–524. [Google Scholar]
- Vilar, R.; Zapata, J.; Ruiz, R. An automatic system of classification of weld defects in radiographic images. NDT&E Int. 2009, 42, 467–476. [Google Scholar]
- Kumar, J.; Anand, R.; Srivastava, S. Flaws Classification using ANN for Radiographic Weld Images. In Proceedings of the International Conference on Signal Processing and Integrated Networks, Noida, India, 20–21 February 2014; pp. 145–150. [Google Scholar]
- Dong, X.; Taylor, C.J.; Cootes, T.F. Automatic Inspection of Aerospace Welds Using X-ray Images. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2002–2007. [Google Scholar]
- Nacereddine, N.; Goumeidane, A.B.; Ziou, D. Unsupervised weld defect classification in radiographic images using multivariate generalized Gaussian mixture model with exact computation of mean and shape parameters. Comput. Ind. 2019, 108, 132–149. [Google Scholar] [CrossRef]
- Mery, D.; Arteta, C. Automatic Defect Recognition in X-ray Testing using Computer Vision. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1026–1035. [Google Scholar]
- Mu, Y.; Yan, S.; Liu, Y.; Huang, T.; Zhou, B. Discriminative local binary patterns for human detection in personal album. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Hou, W.; Wei, Y.; Guo, J.; Jin, Y.; Zhu, C. Automatic Detection of Welding Defects using Deep Neural Network. J. Physics Conf. Ser. 2018, 933, 012006. [Google Scholar] [CrossRef]
- Hou, W.; Wei, Y.; Jin, Y.; Zhu, C. Deep features based on a DCNN model for classifying imbalanced weld flaw types. Measurement 2019, 131, 482–489. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:cs.CV/1505.04597. Available online: https://arxiv.org/abs/1505.04597 (accessed on 14 November 2022).
- Tokime, R.B.; Maldague, X.; Perron, L. Automatic Defect Detection for X-ray inspection: Semantic segmentation with deep convolutional network. In Proceedings of the International Industrial Radiology and Computed Tomography DIR2019, Fürth, Germany, 2–4 July 2019. [Google Scholar]
- Tyystjärvi, T.; Virkkunen, I.; Fridolf, P.; Rosell, A.; Barsoum, Z. Automated defect detection in digital radiography of aerospace welds using deep learning. Weld. World 2022, 66, 643–671. [Google Scholar] [CrossRef]
- Yang, L.; Jiang, H. Weld defect classification in radiographic images using unified deep neural network with multi-level features. J. Intell. Manuf. 2021, 32, 459–469. [Google Scholar] [CrossRef]
- Mery, D. Aluminum Casting Inspection Using Deep Learning: A Method Based on Convolutional Neural Networks. J. Nondestruct. Eval. 2020, 39, 12. [Google Scholar] [CrossRef]
- Fuchs, P.; Kröger, T.; Dierig, T.; Garbe, C. Generating Meaningful Synthetic Ground Truth for Pore Detection in Cast aluminum Parts. In Proceedings of the 9th Conference on Industrial Computed Tomography, Padova, Italy, 13–15 February 2019. [Google Scholar]
- Cogranne, R.; Retraint, F. Statistical detection of defects in radiographic images using an adaptive parametric model. Signal Process. 2014, 96, 173–189. [Google Scholar] [CrossRef]
- Grandin, R.; Gray, J. Implementation of automated 3D defect detection for low signa-to noise features in NDE data. Aip Conf. Proc. 2014, 1581, 1840–1847. [Google Scholar] [CrossRef]
- Kazantsev, I.; Lemahieu, I.; Salov, G.; Denys, R. Statistical detection of defects in radiographic images in nondestructive testing. Signal Process. 2002, 82, 791–801. [Google Scholar] [CrossRef]
- Tošić, I.; Frossard, P. Dictionary Learning. IEEE Signal Process. Mag. 2011, 28, 27–38. [Google Scholar] [CrossRef]
- Chen, B.; Fang, Z.; Xia, Y.; Zhang, L.; Huang, Y.; Wang, L. Accurate defect detection via sparsity reconstruction for weld radiographs. NDT&E Int. 2018, 94, 62–69. [Google Scholar]
- Presenti, A.; Liang, Z.; Pereira, L.F.A.; Sijbers, J.; Beenhouwer, J.D. Automatic anomaly detection from X-ray images based on autoencoder. Nondestruct. Test. Eval. 2022, 37, 552–565. [Google Scholar] [CrossRef]
- Tang, W.; Vian, C.M.; Tang, Z.; Yang, B. Anomaly detection of core failures in die-casting X-ray inspection images using a convolutional autoencoder. Mach. Vis. Appl. 2021, 32, 102. [Google Scholar] [CrossRef]
- Meyendorf, N.G.; Bond, L.J.; Curtis-Beard, J.; Heilmann, S.; Pal, S.; Schallert, R.; Scholz, H.; Wunderlich, C. NDE 4.0—NDE for the 21st Century—The Internet of Things and Cyber Physical Systems will Revolutionize NDE. In Proceedings of the Proceedings of the 15th Asia Pacific Conference for Non-Destructive Testing (APCNDT 2017), Singapore, 13–17 November 2017. [Google Scholar]
- Rummel, W.D. Nondestructive inspection reliability history, status and future path. In Proceedings of the 18th World Conference on Nondestructive Testing, Durban, South Africa, 16–20 April 2010. [Google Scholar]
- Lindgren, E.; Forsyth, D.; Aldrin, J.; Spencer, F. ASM Handbook, Volume 17, Nondestructive Evaluation of Materials; ASM International: Almere, The Netherlands, 2018. [Google Scholar]
- Ewert, U.; Zscherpel, U.; Jechow, M. Essential Parameters and Conditions for Optimum Image Quality in Digital Radiology. In Proceedings of the 18th World Conference on Nondestructive Testing, Durban, South Africa, 16–20 April 2012. [Google Scholar]
- Kanzler, D.; Ewert, U.; Müller, C.; Pitkänen, J. Observer POD for radiographic testing. AIP Conf. Proc. 2015, 1650, 562. [Google Scholar]
- Bertović, M. Human Factors in Non-Destructive Testing (NDT): Risks and Challenges of Mechanised NDT. PhD Thesis, Technische Universitaet Berlin, Berlin, Germany, 1 September 2015. [Google Scholar]
- Aldrin, J.C.; Lindgren, E.; Forsyth, D. Intelligence augmentation in nondestructive evaluation. Aip Conf. Proc. 2019, 2102, 020028. [Google Scholar]
- Lindgren, E.; Zach, C. Autoencoder-Based Anomaly Detection in Industrial X-ray Images. In Proceedings of the 2021 48th Annual Review of Progress in Quantitative Nondestructive Evaluation, Virtual, 28–30 July 2021. [Google Scholar] [CrossRef]
- Richter, C.; Roy, N. Safe Visual Navigation via Deep Learning and Novelty Detection. In Proceedings of the Robotics Science and Systems, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1050–1059. [Google Scholar]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6405–6416. [Google Scholar]
- Seeböck, P.; Waldstein, S.; Klimscha, S.; Gerendas, B.S.; Donner, R.; Schlegl, T.; Schmidt-Erfurth, U.; Langs, G. Identifying and Categorizing Anomalies in Retinal Imaging Data. arXiv 2016, arXiv:cs.LG/1612.00686. Available online: https://arxiv.org/abs/1612.00686 (accessed on 14 November 2022).
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.C.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. arXiv 2017, arXiv:cs.CV/1703.05921. Available online: https://arxiv.org/abs/1703.05921 (accessed on 14 November 2022).
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:stat.ML/1406.2661. Available online: https://arxiv.org/abs/1406.2661 (accessed on 14 November 2022). [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef]
- Tang, Y.; Tang, Y.; Han, M.; Xiao, J.; Summers, R.M. Abnormal Chest X-ray Identification With Generative Adversarial One-Class Classifier. arXiv 2019, arXiv:cs.CV/1903.02040. Available online: https://arxiv.org/abs/1903.02040 (accessed on 14 November 2022).
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training. arXiv 2018, arXiv:cs.CV/1805.06725. Available online: https://arxiv.org/abs/1805.06725 (accessed on 14 November 2022).
- Lindgren, E.; Zach, C. Analysis of industrial x-ray computed tomography data with deep neural networks. In Proceedings of the Developments in X-ray Tomography XIII. International Society for Optics and Photonics, San Diego, CA, USA, 1–5 August 2021; SPIE: Bellingham, WA, USA, 2021; Volume 11840, p. 118400B. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2015, arXiv:cs.LG/1412.6806. [Google Scholar]
- Hou, X.; Shen, L.; Sun, K.; Qiu, G. Deep feature consistent variational autoencoder. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1133–1141. [Google Scholar]
- Vincent, P. A connection between score matching and denoising autoencoders. Neural Comput. 2011, 23, 1661–1674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hyvärinen, A.; Dayan, P. Estimation of non-normalized statistical models by score matching. J. Mach. Learn. Res. 2005, 6, 95–709. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 14 November 2022).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:cs.LG/1412.6980. [Google Scholar]
- Eckel, S.; Huthwaite, P.; Zscherpel, U.; Schumm, A.; Paul, N. Realistic Film Noise Generation Based on Experimental Noise Spectra. Trans. Imge Proc. 2020, 29, 2987–2998. [Google Scholar] [CrossRef]
- Lindgren, E.; Wirdelius, H. X-ray modeling of realistic synthetic radiographs of thin titanium welds. Ndt&E Int. 2012, 51, 111–119. [Google Scholar]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragón, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The Database of X-ray Images for Nondestructive Testing. J. Nondestruct. Eval. 2015, 34, 42. [Google Scholar] [CrossRef]
- Roy, P.; Ghosh, S.; Bhattacharya, S.; Pal, U. Effects of Degradations on Deep Neural Network Architectures. arXiv 2018, arXiv:1807.10108. Available online: https://arxiv.org/abs/1807.10108 (accessed on 14 November 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Original Sample Count | Augmented Sample Count |
|---|---|---|
| Train weld okay | 27,454 | 164,724 |
| Train defects | 11,705 | 70,230 |
| Train synthetic natural image indications | 112,000 | |
| Train synthetic, circular indication | 5000 | |
| Train synthetic, partial circle inclusion | 5000 | |
| Test weld okay | 3480 | |
| Test defect, high contrast | 3396 | |
| Test defect, mid-contrast | 2898 | |
| Test defect, low contrast | 1830 | |
| Test, synthetic, five different types | 200 |
| TPR Average and Spread | ||||
|---|---|---|---|---|
| Training Data | D | D + SC | D + SC + SPC | D + SNI |
| Test Dataset | ||||
| Defects high contrast | ||||
| Defects mid-contrast | ||||
| Defects low contrast | ||||
| Synthetic circular hollow inclusion | ||||
| Synthetic dogbone inclusion | ||||
| Synthetic elongated inclusion | ||||
| Synthetic partial circle inclusion | ||||
| Synthetic raster | ||||
| TPR Average and Spread | |||
|---|---|---|---|
| Perturbation Dataset | None | D | SNI |
| Test Dataset | |||
| Defects high contrast | |||
| Defects mid-contrast | |||
| Defects low contrast | |||
| Synthetic circular hollow inclusion | |||
| Synthetic dogbone inclusion | |||
| Synthetic elongated inclusion | |||
| Synthetic partial circle inclusion | |||
| Synthetic raster | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lindgren, E.; Zach, C. Industrial X-ray Image Analysis with Deep Neural Networks Robust to Unexpected Input Data. Metals 2022, 12, 1963. https://doi.org/10.3390/met12111963
Lindgren E, Zach C. Industrial X-ray Image Analysis with Deep Neural Networks Robust to Unexpected Input Data. Metals. 2022; 12(11):1963. https://doi.org/10.3390/met12111963
Chicago/Turabian StyleLindgren, Erik, and Christopher Zach. 2022. "Industrial X-ray Image Analysis with Deep Neural Networks Robust to Unexpected Input Data" Metals 12, no. 11: 1963. https://doi.org/10.3390/met12111963
APA StyleLindgren, E., & Zach, C. (2022). Industrial X-ray Image Analysis with Deep Neural Networks Robust to Unexpected Input Data. Metals, 12(11), 1963. https://doi.org/10.3390/met12111963