3.1. Clustering Impacted Areas Using ANFIS
By clustering the impacted areas, response strategies for sending shelters to impacted areas can be accelerated. Therefore, this study uses
Adaptive Neuro-Fuzzy Inference System (
ANFIS), which has shown acceptable performance in clustering problems [
36].
ANFIS combines the FIS with a backpropagation algorithm used for neural network training [
37]. This inference-based structure has three components depending on the selection of fuzzy rules, database (i.e., membership determination), and argument or inference on rules and obtaining the appropriate output [
38]. Chu [
39] proposed a neural learning method with an adaption for the FIS modelling process for information learning (i.e.,
ANFIS), which is the best generator for FIS. This structure is a multi-layer feed-forward network that uses neural network learning algorithms and fuzzy logic for mapping an input space to an output space, and by embedding this adapted network in the Sugeno fuzzy model, the model learning is facilitated [
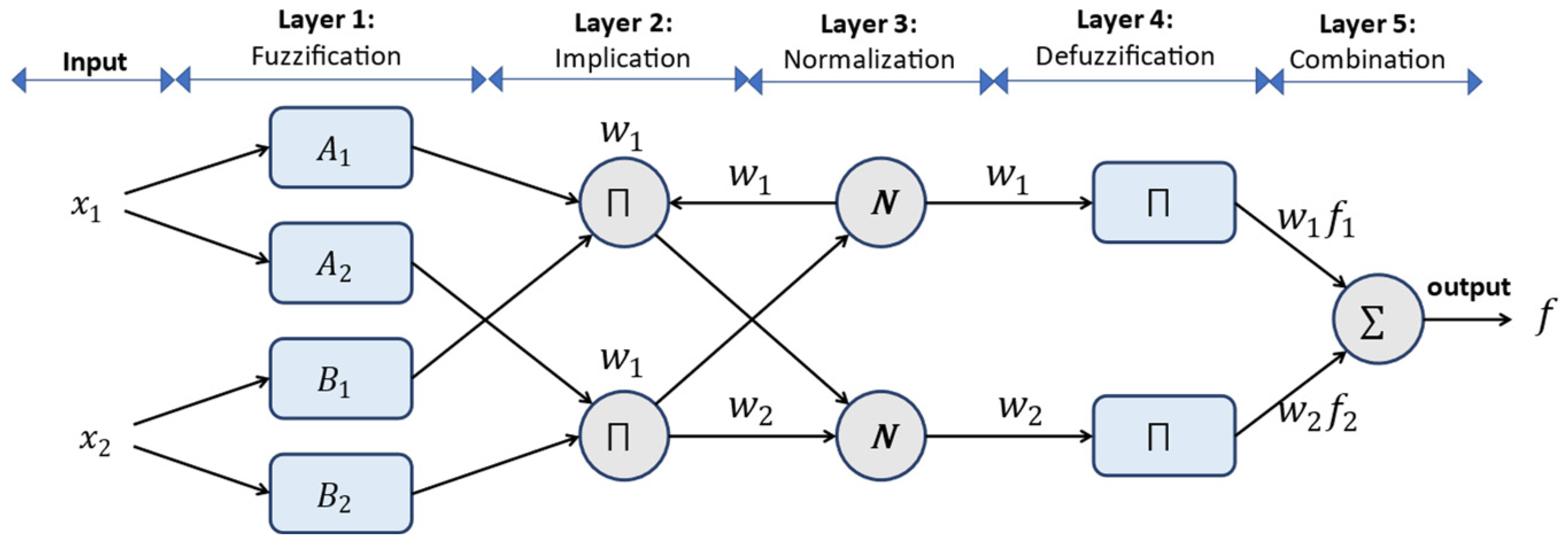
40]. The general structure of this method is shown in
Figure 2.
In this structure, the adapted nodes (i.e., squares) are the set of adjustable parameters, while fixed nodes (i.e., circles) present constant parameters in the model. The previous layer’s output is used as input of the next layer [
40]. According to
Figure 2, two input variables
and
and output y are considered to define two rules as follows [
41]
In the current paper, for example, the first rule states that if the road slope is low, the weather is normal, the crisis severity is high, and the road risk is moderate, then the intended damaged point belongs to cluster 1. If the road slope is moderate, the weather is normal, the crisis severity is very high, and the road risk is moderate, the intended damaged point falls into cluster 2, and so on. The ANFIS determines the output value using five layers.
Layer 1. This layer maps input variables
and
to fuzzy sets
through the fuzzification method (A and B are verbal tags, like high and low). Each node in this layer is an adapted node with n function nodes that the bell or Gaussian membership function can produce. In fact, each node is used for one membership function [
41].
Layer 2. After generating membership functions, each node in this layer is a fixed (i.e., constant) node, and the output is the multiplication of all inputted signals that represent the Firing Strength of each fuzzy rule. In this layer, after the combination of fuzzy sets of each input, the Firing Strength is applied, and determination of output is used from
operator or the fuzzy letter “and” [
40].
Layer 3. Each node in this layer is a fixed layer that calculates the Firing Strength rate for each rule and divides it by all rules’ Firing Strengths. Actually, the rate of the
-th rule is calculated.
Layer 4. Each node in this layer represents an adapted node with a function node, and the contribution of each rule to the total output is calculated. It means that the output of the previous layer is multiplied by a function of the Sugeno fuzzy rule. In other words, defuzzification is done, and the output values are obtained from fuzzy inference rules, in which
are consequent parameters.
Layer 5. The single node of this layer is a fixed layer that indicates the total output to the sum of all signals. Actually, this non-adapted node obtains the total output by summing all signals [
38]
The parameters in the
ANFIS network are non-linear (in the premise section) and linear (in the consequent section). There are different methods for optimisation of these parameters, such as the gradient or slope descent. Of course, the blended learning method is more efficient in this technique. The layer output forward to layer four and least square estimation is used for consequent parameter adjustment in feed-forward movement. However, in backward movement, the error signals return to layer one and update premise parameters by using gradient descent [
41]. Sometimes, the
ANFIS method has constraints for large-scale data and is not efficient. Hence, we seek newly developed algorithms that resolve this deficiency. The fuzzy c-mean (FCM) can be mentioned as an alternative method [
42]. This unsupervised algorithm is applied for clustering the
data points to
clusters by initialisation. Its purpose is to minimise the existing errors (i.e., the weighted distance of each point with all c means of clusters) [
43]. Then, it is applied for minimising the following objective function:
where
is the fuzzifier operator,
is the number of data points,
is the number of clusters,
is the measure of belonging data point
to cluster
,
is the cluster mean, and
is the input data.
is computed by [
44].
The cluster means are recalculated at the next stage of initialisation using the following formula:
Finally, the algorithm reaches convergence condition stops [
38]. To summarise, this algorithm is carried out in four steps: (1) random selection of a cluster centre from among the n points, (2) calculation of the membership function, (3) calculation of the cost function using the above formula and terminating the procedure if this value is less than a specified threshold, and (4) calculation of new cluster centres (recalculation). Finally, the termination condition is convergence; otherwise, it returns to Step 2 [
43].
This paper employs an ANFIS method with ten neurones in a hidden layer for 20 damaged points and a binary output (i.e., cluster 1 or cluster 2). The output layer’s transformation function is linear, while the hidden layer’s function is tangent sigmoid. The type of training algorithm, on the other hand, is LM-BP.
Table 1 shows an example of the above-mentioned data. This table also includes verbal tags for the membership functions for each input variable.
Table 1 shows how 20 damaged points are divided into two clusters. Cluster 1 includes the points where the corresponding road is in good condition, and the relief operation takes place on the ground or in the air. Cluster 2, on the other hand, contains points where the corresponding road is broken down, and the relief operation can only take place in the air mode.
Table 1 lists the clustering measures, some of which are deterministic and some of which are fuzzy. This table also includes the clustering results of 20 damaged points.
3.2. Reliable Route Selection
Road networks now require a high degree of reliability to ensure drivers’ travel and avoid delays because of disruption in the network [
45]. In the present paper, applying a permanent matrix in a graph theory and MCDM, we determine the most reliable route. Rao and Padmanabhan [
46] presented a graph theory and its applications in the field of decision making and application of the graph theory. The graph theory and matrix method include graph representation, matrix representation, and permanent function representation. That is, first, the representation of variables and their dependencies is presented and then formulated mathematically and finally, a numerical index is identified by a permanent function [
47]. Clusters obtained by the ANFIS method are prioritised by affecting factors on route reliability to find the most reliable route for distributing temporary shelters to these points using this theory. Road type (e.g., autobahn and highway), mountainous rate, and geographical characteristics all have an impact on the reliability of cluster 1 (i.e., ground and air relief). The severity of the crisis, the regional context (rural or urban), the conditional weather, the population of the region, and the distance of the air vehicle depot and damaged points all have an impact on the reliability of cluster 2 (i.e., air relief).
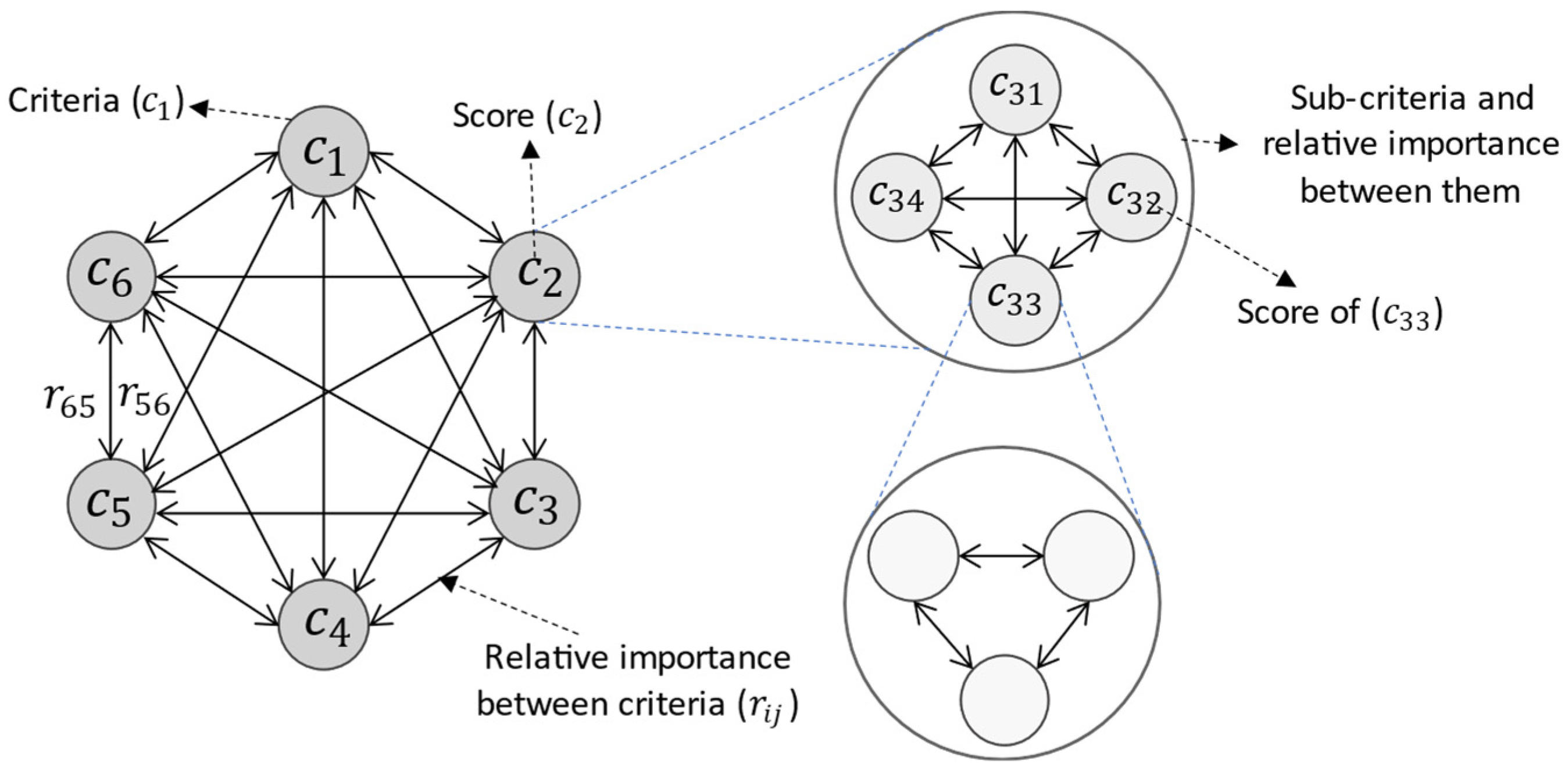
Step 1 (identification of criteria, sub-criteria, and alternatives of the problem): Identification of the affecting factor on the process using the available data in the literature or conducting a survey of experts [
48] is presented by representing graph and their dependencies. The reliability affecting factors have been described before. In the representation of the graph, as shown in
Figure 3, there is a set of nodes and a set of directed edges. Each node
is the identifier of the
-th criterion for alternative selection and the edges represent the relative importance of criteria, in which the number of nodes and alternatives are identical. In alternative selection, if node
is more important than node
, a directed edge is drawn from
to
(
) and vice versa [
46]. An example of the decision-making structure by the use of the permanent matrix is given in
Figure 3.
Step 2 (definition of the relative importance of criteria and alternatives score): In this step, if the criterion is qualitative, the values of the alternatives score can be calculated by rating a scale from zero to one [
30], as shown in
Table 2.
If the criterion is quantitative, it should be normalised. Therefore, if
is the criteria value of alternative
and
is the criteria value of alternative
,
should be normalised [
47]. After calculating all the criteria values for each alternative, we define the ratio criteria matrix for them.
On the other hand, the relative importance between criteria (
) can get the values between zero and one. The relationship between
and
is not necessarily a compensatory relationship. It can be
as shown in
Table 3.
The relative importance matrix is defined at the end of this step as:
Step 3 (calculation of the alternative evaluation matrix): In this step, after identifying
and
, the alternative evaluation matrix
is calculated by:
The permanent of this matrix is the criteria function of alternative selection [
30]. This value gives a grade for the alternatives that must be dissentingly sorted, and the alternative with the largest permanent value will be the best alternative (the most reliable route) [
49]. The following equation represents the function for calculating the permanent value.
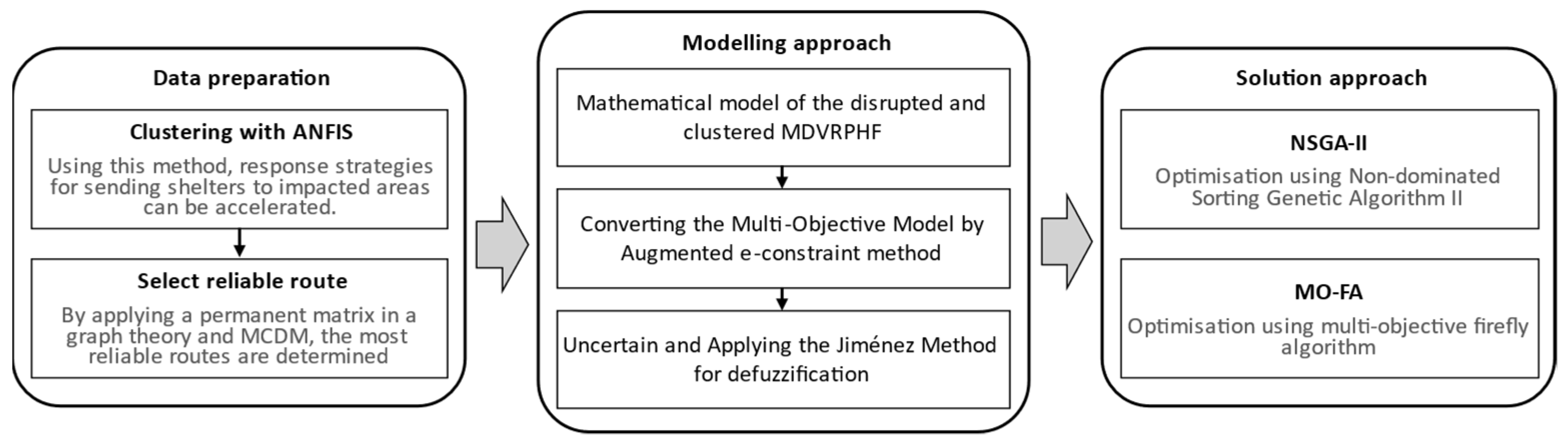
3.3. Modelling and the Proposed Solving Method
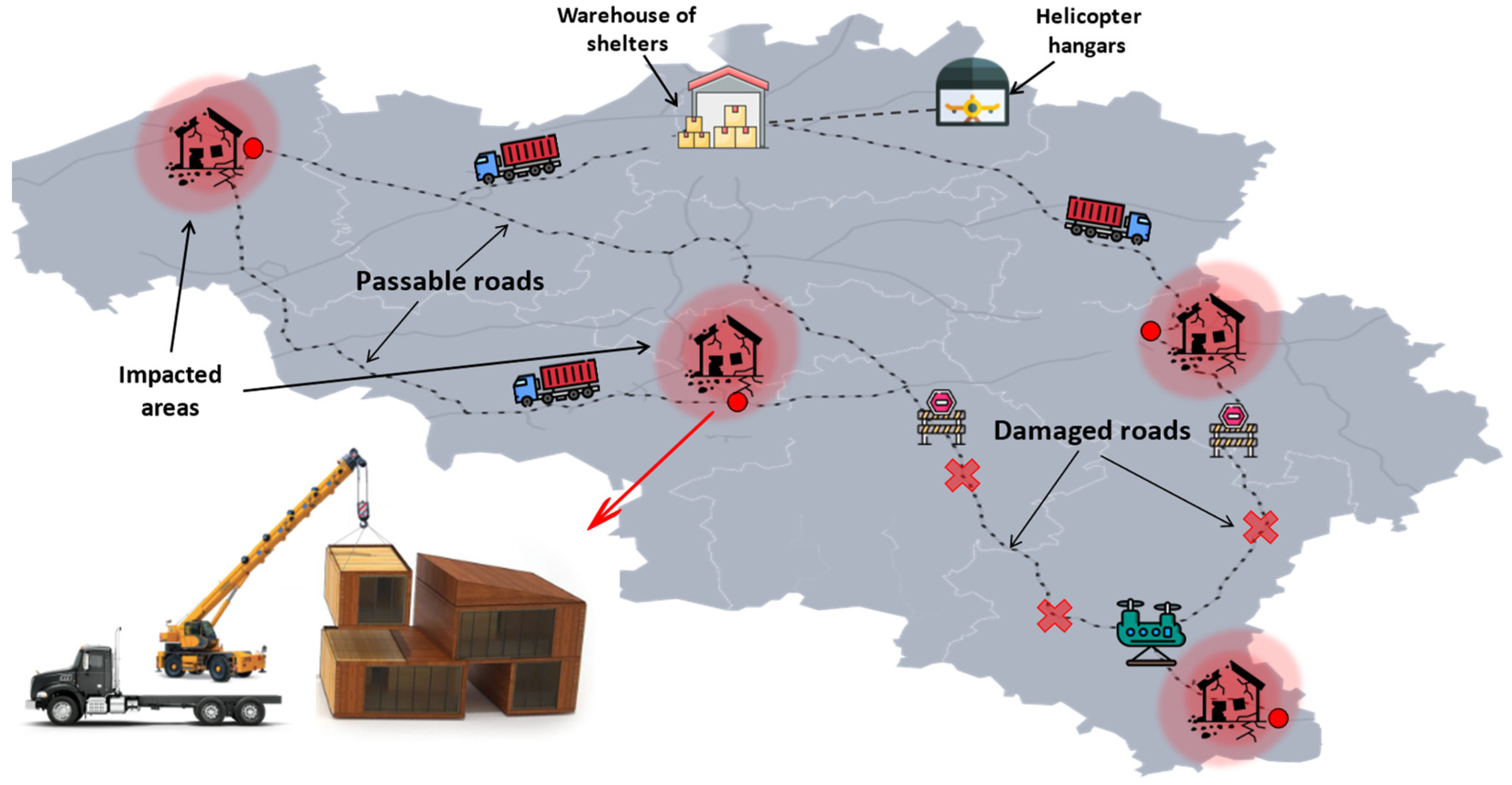
Consider a disaster-affected area. Humanitarian organisations have a plan to send temporary shelters to the affected areas using trucks and helicopters in response to this disaster. Multiple depots are considered in response operations, including the depot of heterogeneous trucks and the hangers of heterogeneous helicopters. It should be noted that the vehicle depot also serves as a shelter warehouse. These vehicles should deliver temporary shelters to demand points. However, due to the severity of the disaster, some infrastructures, including access roads to some of these points, have been disrupted, making ground delivery to these points impossible. As a result, the affected areas have been divided into two clusters in order to reduce the time it takes to send shelters. Because of the disruptions in the access roads, the affected points in one cluster can receive shelters in both ground and air modes, while the points in the other cluster can only receive shelters in an air mode due to the breakdown of their road. The points in each cluster are then prioritised separately by the key factors on route reliability. That is, in each cluster, the shelters are distributed first to the most reliable route, and the vehicles serve from the most reliable routes. On the other hand, during the distribution of shelters, the ground vehicle (e.g., truck) breaks down, causing its service areas to be served late and causing disruption in the distribution system (
Figure 4 shows a schematic sample of the problem).
Mathematical modelling approaches can effectively condense and highlight the most important aspects of our understanding of real-world decision-making problems. These problems, however, are frequently complex. Real-world problems can be too complex or challenging to model if all details are taken into account, so it is important to keep this in mind when developing models. Therefore, effective models rely heavily on assumptions that reduce complexity while retaining the system’s fundamental properties. Because of this, it is crucial to simplify assumptions in order to keep models tractable and true to the underlying system. These assumptions lead to a highly effective mathematical model, as shown by the following:
There is a limitation in the number of vehicles, and various types are used to transport shelters to affected areas.
All vehicles’ starting points are known and defined, as is which vehicle belongs to which depot.
All vehicles should be utilised in the event of a large-scale disaster.
Each affected point is served by a single-vehicle.
The depot inventory is sufficient to respond to the affected areas.
The location of any affected area is known, as is its distance from depots.
The amount of demand is known at each affected point.
Each vehicle returns to its starting place at the end of the operation.
The affected points are divided into two clusters, and all impacted areas in each cluster are prioritised based on reliability-affecting factors.
The broken-down vehicle cannot be repaired in a reasonable amount of time so that it can be used again.
The problem is scenario-based, and the vehicle’s failure time is known under various scenarios.
If the product is delivered to the affected point, the service is completed, and the shortage is avoided. After the vehicle fails, the other vehicle should not perform its serving duties and must follow their specified plan.
The affected areas’ demand is fuzzy, with a triangular fuzzy number.
Each affected area’s demand can be partially met, and a shortage is acceptable.
3.3.1. Mathematical Model of the Disrupted and Clustered MDVRPHF
The mathematical model is developed using the variables and parameters listed below.
Notations and sets | Set of land vehicles |
| Set of aerial vehicles |
| Set of the impacted areas with a passable road |
| Set of the impacted areas with a damaged road |
| Set of the ground vehicle depots |
| Set of the helicopter hangars |
| Set of vehicles |
| Set of scenarios |
| Number of all nodes |
| Number of trucks |
| Number of helicopters |
| Number of impacted areas with a passable road |
| Number of impacted areas with a damaged road |
| Number of truck depots |
| Number of helicopter hangars |
Parameters | The capacity of vehicle v |
| The demand of shelters for node (impacted area) |
| Travel time from node to for vehicle |
| The permanent value of node to based on the reliability index |
| The auxiliary and sequential variable that shows the number of nodes being visited with vehicle in sub-tour elimination constraints |
| Arrival time of vehicle to node |
| Travel time of a vehicle from node to node |
Model Formulation
The following is a mathematical formulation of the suggested model:
The objective function (14) minimises the maximum of the transportation time of vehicle v between nodes i and j. The objective function (15) maximises the reliability of routes by maximising the sum of the permanent of each route. The objective function (16) minimises the unmet demand at impacted area i under scenario s. Constraint (17) guarantees the flow balance for the impacted areas with reliable road and ground vehicles. That is, each truck, after entering the node and servicing the area, leaves the node. Constraint (18) guarantees the balance of flow for healthy and not-healthy areas and for helicopters. In other words, the helicopters leave the node after its entrance. Constraint (19) indicates that the start point of any truck is known to be from what depot, while constraint (20) is the constraint on the start point of helicopters. Constraints (21) and (22) guarantees that any vehicles (i.e., truck and helicopter) after servicing any nodes must come back to the start point and the route is closed. Constraint (23) ensures that each vehicle (i.e., helicopter or truck) only serve one node (for points that their leading road is healthy). Consequently, constraint (24) identifies that each vehicle (i.e., helicopter) serve only one not healthy node (the impacted area that its leading road is damaged). Constraints (25) and (26) are the capacity limitation of trucks and helicopters. The part considered as a sub-tour constraint is represented in Constraints (27) to (32), in which Constraints (27) and (28) are the sub-tour elimination constraints for trucks and helicopters. Following that, Constraints (29) and (30) are the sub-tour elimination constraints for axillary variables and for trucks. Constraints (31) and (32) are the sub-tour elimination constraints for axillary variables and for helicopters. Constraint (33) ensures that all vehicles depart from the depots. Constraint (34) calculates the reaching time of the vehicle to the demand centre or impacted areas. Constraint (35) identifies whether the shortage is present under the given scenarios or not. In other words, whether the shelters delivered to impacted areas under the different scenarios or not (if the product has been delivered to the impacted area means that the vehicle has not been failed before serving the impacted area and the shortage has not incurred). If means that the failure time of vehicle is after the failure time at scenario s. Consequently, the shortage will occur, and the vehicle is not arrived to the impacted area. Otherwise, the vehicle has break downed after serving and all the goods are delivered to the affected areas and are not faced with shortage (to identify the shortage, we calculate the time of serving each point). Constraints (36) and (37) refer to the sequential and binary variables , respectively. Constraint (38) implies to the arriving time of vehicle v to node i, which is a non-negative value. Constraint (39) implies the failure time of vehicle v under scenario s that is a non-negative. Constraint (40) identifies the vehicle travel time and transfers from node i to node j, a non-negative value. Constraint (41) is a binary variable that identifies the presence or absence of shortage.
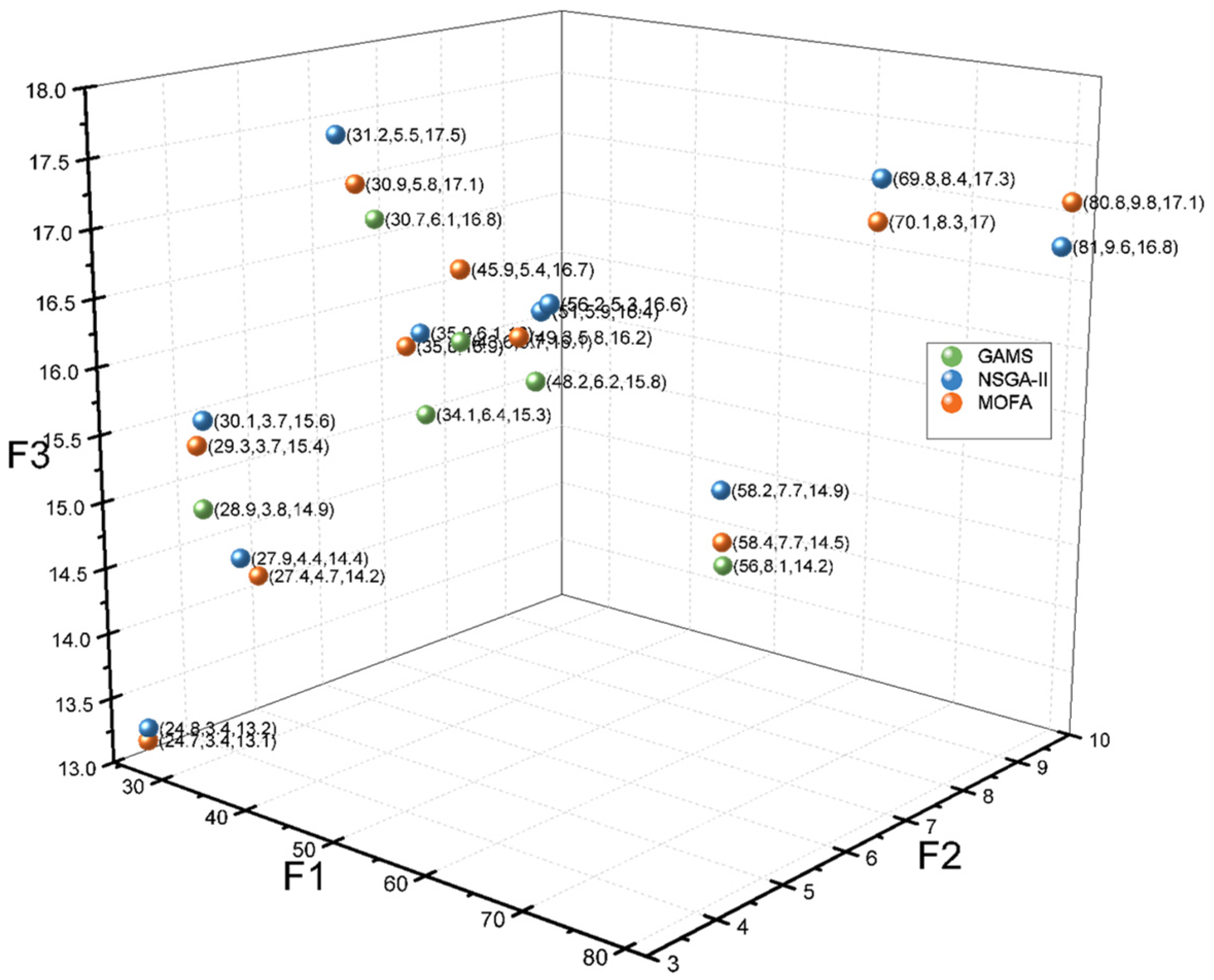
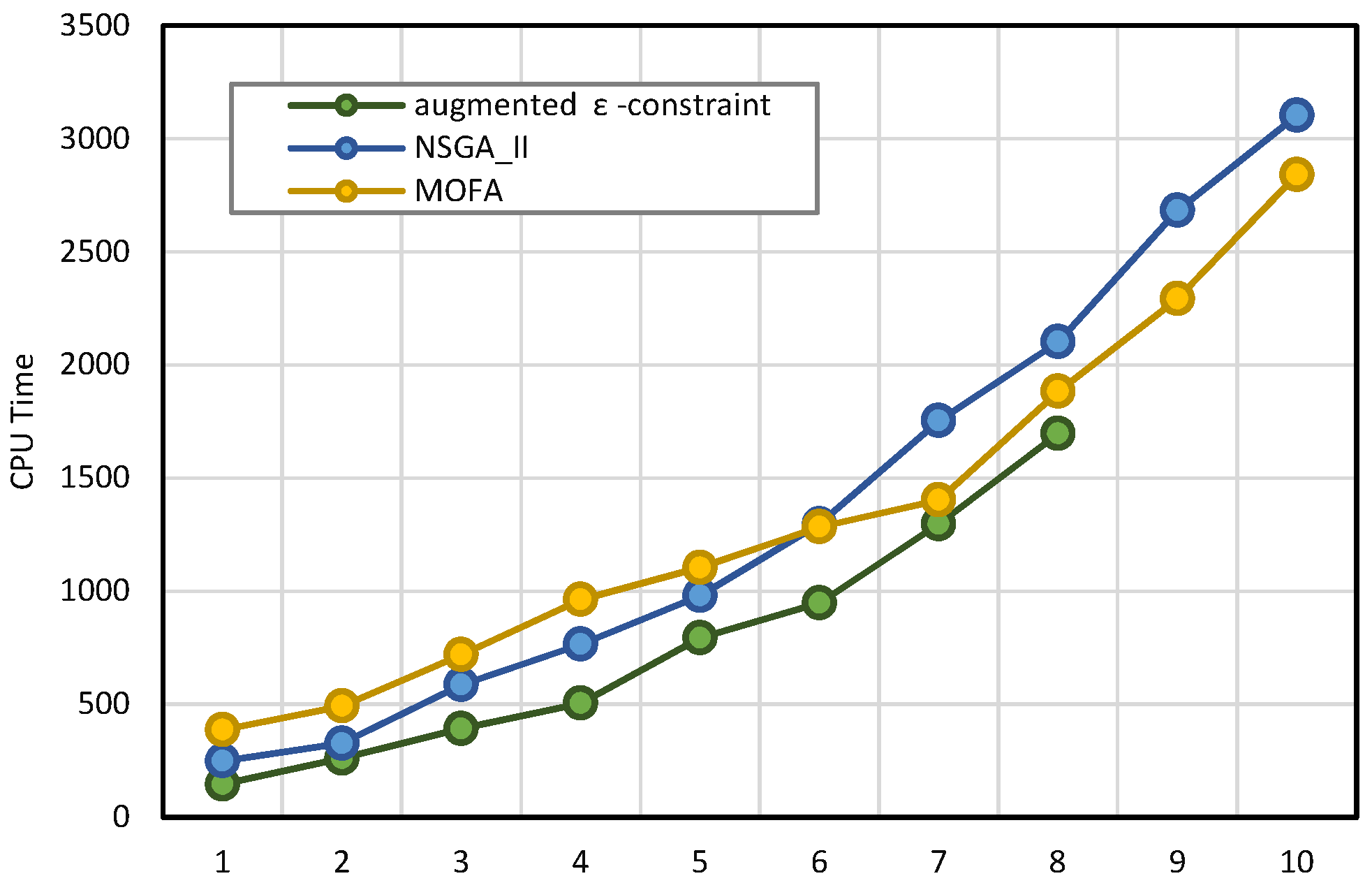
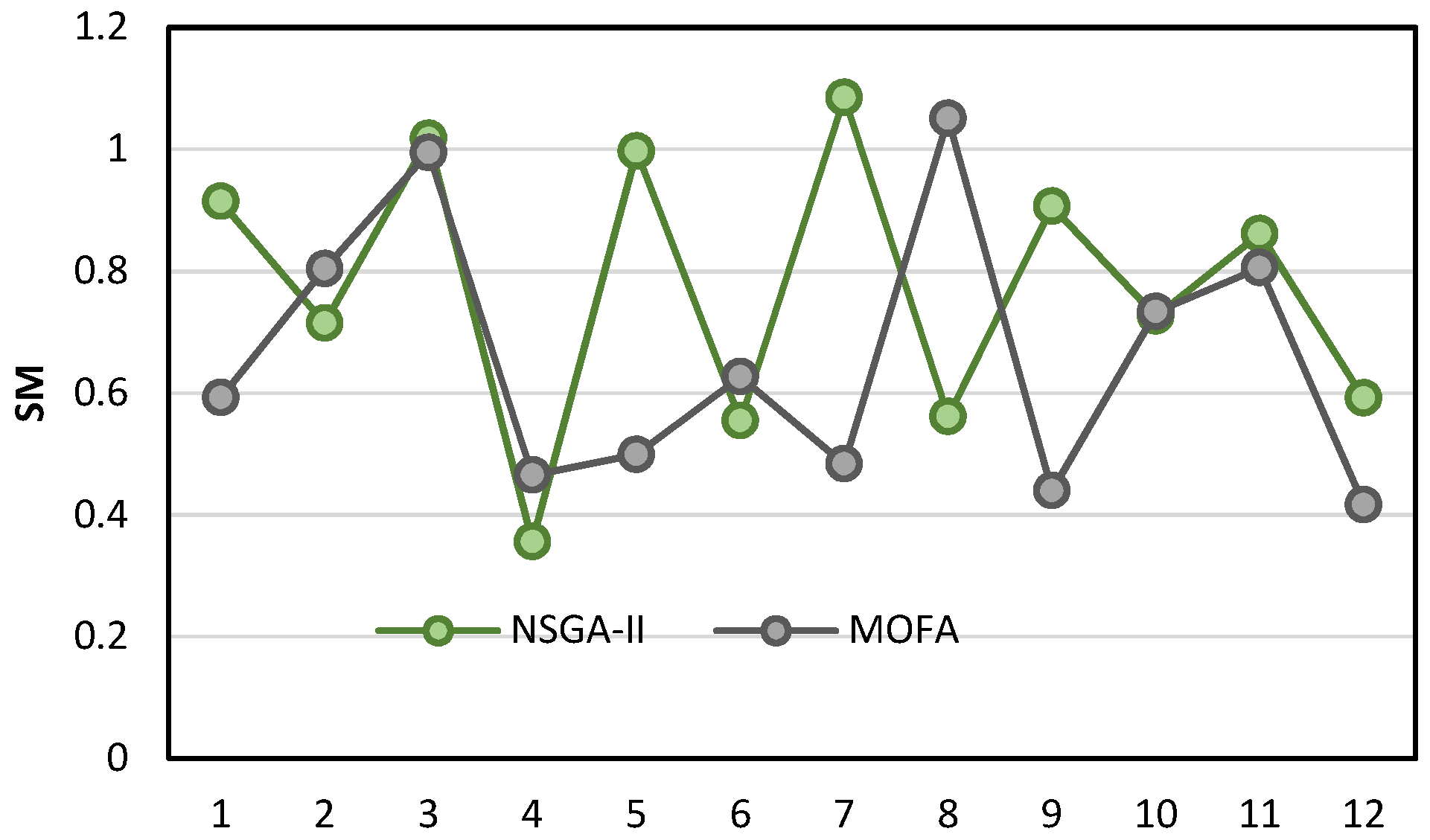
3.3.2. Converting the Multi-Objective Model to a Single Objective Model by the Augmented ε-Constraint Method
Among the available techniques in the transformation of the multi-objective problem to a single objective problem, the augmented ε-constraint method is applied. This method is one of the efficient methods in looking for Pareto optimised solutions, in which the first objective function is optimised, and other objectives are being added to the constraints [
50]. In the general, the other name of the ε-constraint method is a trade-off or ε-constraint method [
51]. Consider a multi-objective programming, where
p is the number objectives,
and
is the decision variable, which
S is the feasible space. Now, we suppose that all objective functions are maximisation without a loss of generality. When we apply the ε-constraint method, we must consider one of the objective functions as the main objective and add others to the constraints. Following is the structure of Formula (41) [
52].
The other objective functions with permissible values
, are constrained (so that
is the index of the main objective function) [
51]. The Pareto-optimal values are obtained by adding the right-hand side of new constraints (ε vector) [
53]. When this method is used, the region of at least p-1 objective function, for the definition of grid points, must be defined for each
. An efficient method for identification of this region is to apply a payoff table for each objective function, which the difference between the minimum value (
) and the maximum value (
) constitute the region.
Then, this region for each objective function is divided into equal intervals and according to the following formula: the set of
grid points is calculated.
single optimisation sub-problem must be produced from the multi-objective problem, which any sub-problem has a Pareto-optimal solution. Because of adding objective functions, the constraints may be infeasible. One drawback of this method is that it may produce inefficient solutions [
52]. Different versions of the ε-constraint method are developed for producing more efficient solutions. To overcome this drawback, an augmented ε-constraint method is proposed, in which changing the constraints of the objective functions, by using of slack or surplus variables, is suggested, and the main objective function is augmented by the sum of slack or surplus values. We have the following model [
53]:
where the δ value is a small number between 10
−6 and 10
−3.
3.3.3. Uncertainty and Defuzzification
In the proposed model, due to the uncertainty in an emergency situation and becoming closer to reality, the demand of the impacted areas is fuzzy numbers (parameter
is considered a triangle fuzzy number). Because of the applicability and simplicity in calculations, a symmetrical triangle distribution is considered for specifying of the fuzzy parameter [
54,
55]. To transform a linear mathematical model to its corresponding deterministic model, the Jimenez method is applied because of the high efficiency [
56]. The membership function of the fuzzy parameter is as follows [
57]:
Also, for fuzzy number
and
the degree of being greater is defined by:
Identifies the degree that
is greater than
. When
, it is said that
is greater than
at least by degree α” [
56]. Consider the mathematical model with fuzzy parameters as follows:
where
= (
,
, …,
),
= (
,
, …,
) and
=
are the objective functions and constraints’ parameters [
58]. Applying the Jimenez method, the above model is transformed to the deterministic parametric linear programming method.
where α is the possibility level of non-deterministic data and expected interval (EI(
)) and expected value (EV(
)) are defined by [
28].
And, if the fuzzy number c is a triangle fuzzy number, the expected interval can be easily stated by [
56].
If the equation has smaller than and equal constraints, its augmented model can be displayed as follows:
And, if the relationship has equal constraints, we have:
According to what we have discussed, changes in the objective function and constraints take place according to the following equations:
The Jimenez method is implemented in three stages described below:
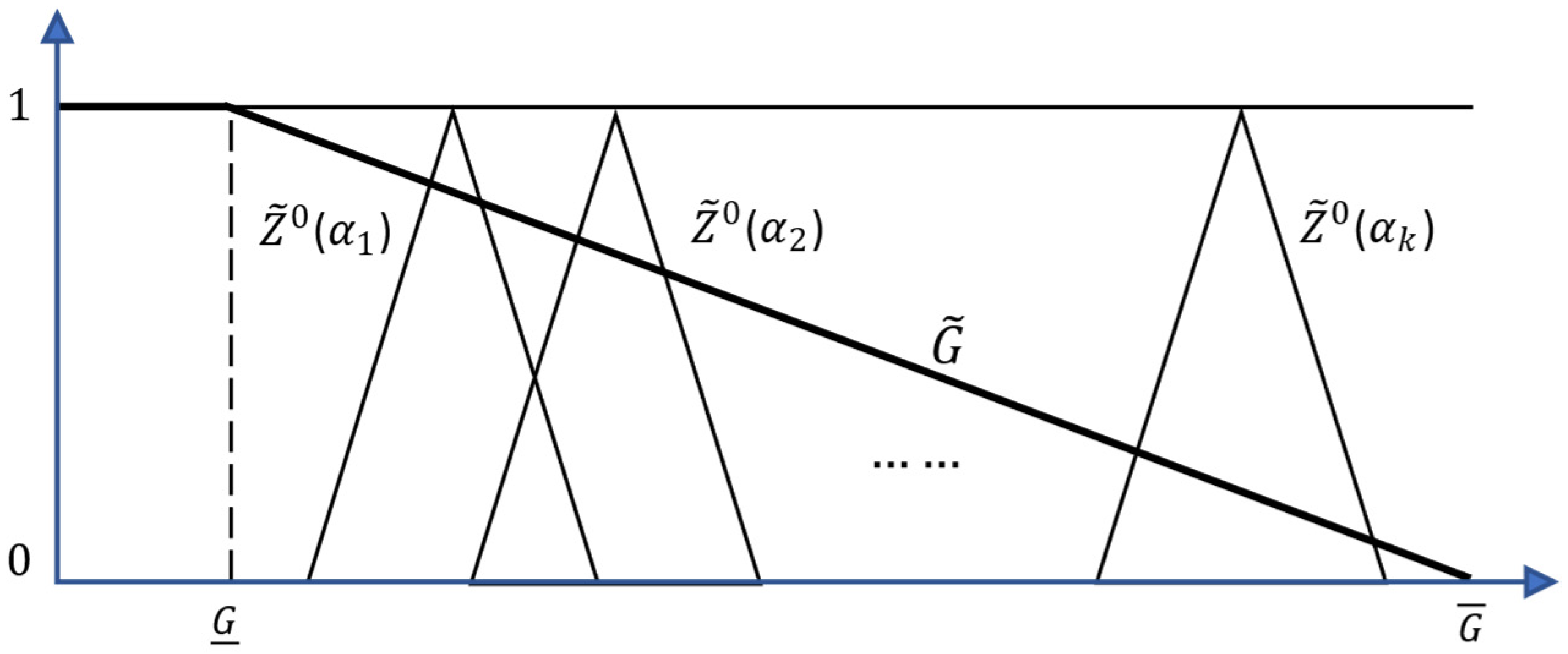
Stage 1: The provided auxiliary deterministic model (Equation (71)) is solved for each
. In this way, space
is obtained from the optimal solution with degree
and corresponding possibility distribution with objective value
, which is shown in
Figure 5.
For acquiring a decision vector that satisfies the decision maker’s expectation, two factors must be considered: (1) the degree of feasibility and (2) reaching the acceptable value for the objective function. After the observation of the obtained information of
, the decision-maker is asked to select an objective G and tolerance limit
. Accordingly, if
, is totally satisfactory; however, if
, its satisfaction level is zero. The objective is stated by fuzzy set
, whose membership function is as follows:
The decision-maker wants to acquire the maximum satisfaction level. However, a lower level of constraint establishment is obtained for the optimal objective value. With this explanation, the decision-maker may want a lower level of satisfaction to better establish the constraints.
Figure 5 show the different
and objective
. The objective is to find a definitive solution
* so that the decision maker’ expectation is satisfied.
Stage 2: The satisfaction level of the fuzzy objective
under each optimal solution with acceptance degree α, which the membership function of each fuzzy number
to the fuzzy set
that the method was proposed by [
59] is applied here.
In this equation, the dominator identifies the area under the curve and the numerator is the possibility of for any deterministic value Z weighted by its satisfaction level.
Stage 3: We search for finding a balanced solution between the degree of feasibility and satisfaction. Hence, the optimal solution space with acceptance degree α and two fuzzy sets
and
is considered, whose membership function is as follows:
Therefore, the fuzzy decision vector
is defined by [
60]:
where * is a
that can be minimised. Hence, when we have a deterministic decision vector and, it will be known as a solution for the main fuzzy linear model in Equation (70) if
is the solution with the most membership degree in the fuzzy decision vectors:
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}