Model Validation and Scenario Selection for Virtual-Based Homologation of Automated Vehicles

 , , and
, , and
Abstract
:1. Introduction
- an overview about methods to select test scenarios for AVs and methods to assign them to testing environments,
- a novel approach to select both scenarios for model validation and for safeguarding,
- a methodology for virtual-based safeguarding of AVs based on real and virtual tests,
- first implementation with a real and virtual prototype vehicle using the type approval of lane keeping systems as a representative safety assessment example.
2. Literature Overview
2.1. Type Approval of Lane-Keeping Systems
Simulation tool and mathematical models for verification of the safety concept may be used [...]. Manufacturers shall demonstrate [...] the validation performed for the simulation tool chain (correlation of the outcome with physical tests).[5] Section 4.2
2.2. Model Validation
2.3. Scenario Assignment Methods
2.4. Scenario Selection Methods
2.4.1. Knowledge-Based Methods
2.4.2. Data-Driven Methods
2.4.3. Coverage-Based Methods
2.4.4. Falsification-Based Methods
2.5. Analysis of the Literature
- focuses on exploration of the entire scenario space,
- requires relatively low effort,
- is suitable for execution in the real and virtual world,
- and offers several test repetitions for reproducibility.
3. Methodology
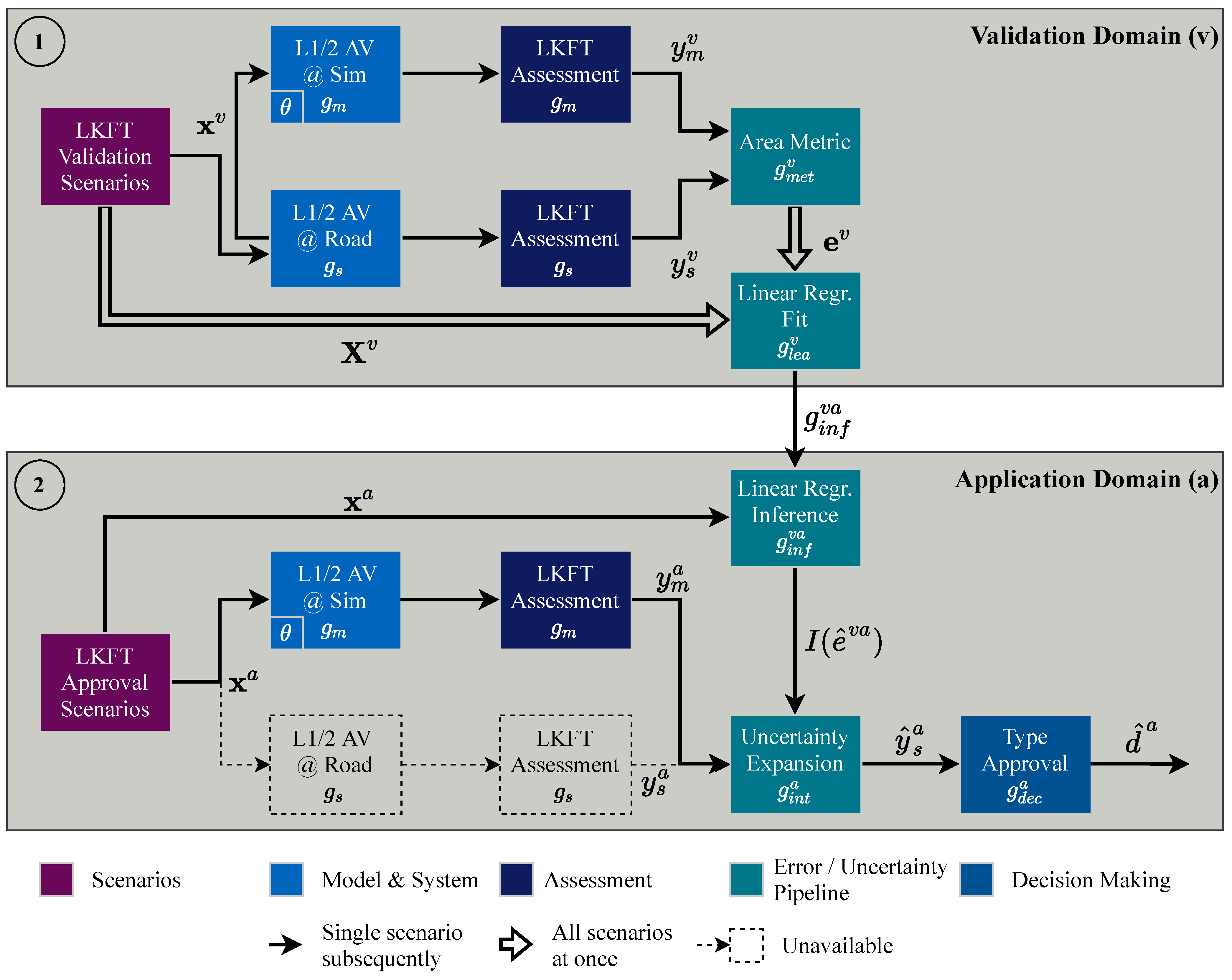
3.1. Virtual-Based Homologation Process
3.2. Data-Driven Application Scenarios
- It partitions the scenario space into 1D acceleration bins and contiguous velocities.
- It filters the noisy lateral acceleration signal using a Butterworth filter according to [17].
- It calculates a reference lateral acceleration signal.
- It transforms the continuous time signals via thresholds to binary masks by applying condition checks.
- It merges neighboring events of ones in the masks via a connected components algorithm [60].
- It combines all binary masks using Boolean algebra.
- It extracts events from the resulting mask and represents them with start and stop time indices.
- It transforms each binary event to a scenario with mean velocity and bin-centered lateral acceleration.
3.3. Coverage-Based Validation Scenarios
- It partitions the velocity and acceleration dimension into 1D bins and the scenario space into 2D bins.
- It takes full-factorial samples within each velocity bin.
- It calculates a reference lateral acceleration signal across the entire road for each velocity sample.
- It transforms the continuous signals into binary masks by comparison with the acceleration bins.
- It merges neighboring events of ones in the masks via a connected components algorithm [60].
- It combines all binary masks using Boolean algebra.
- It extracts events from the binary masks and represents them with start and stop time indices.
- It selects the longest event for each 2D bin over all velocity samples and all road curves.
- We manually select single 2D bins based on the event length and a coverage criterion.
- It represents each selected 2D bin with its center as scenario parameters.
3.4. Assessment
3.5. Model Validation
3.6. Type Approval
4. Results and Discussion
4.1. Data-Driven Application
4.2. Coverage-Based Validation Scenarios
4.3. Assessment
4.4. Model Validation
4.5. Type Approval
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2018; WHO: Geneva, Switzerland, 2018. [Google Scholar]
- SAE International. SAE J3016: Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles; SAE: Warrendale, PA, USA, 2018. [Google Scholar]
- European Commission. Road Safety: Commission Welcomes Agreement on New EU Rules to Help Save Lives; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- United Nations Economic Commission for Europe (UNECE). Addendum 78: UN Regulation No. 79—Uniform Provisions Concerning the Approval of Vehicles with Regard to Steering Equipment; UNECE: Geneva, Switzerland, 2018. [Google Scholar]
- United Nations Economic Commission for Europe (UNECE). Proposal for a New UN Regulation on Uniform Provisions Concerning the Approval of Vehicles with Regards to Automated Lane Keeping System (ECE/TRANS/WP.29/2020/81); UNECE: Geneva, Switzerland, 2020. [Google Scholar]
- German Aerospace Center. PEGASUS-Project; German Aerospace Center: Cologne, Germany, 2019. [Google Scholar]
- Leitner, A.; Akkermann, A.; Hjøllo, B.Å.; Wirtz, B.; Nickovic, D.; Möhlmann, E.; Holzer, H.; van der Voet, J.; Niehaus, J.; Sarrazin, M.; et al. ENABLE-S3: Testing & Validation of Highly Automated Systems: Summary of Results; Springer: Berlin, Germany, 2019. [Google Scholar]
- Kalra, N.; Paddock, S.M. Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability? Transp. Res. Part A Policy Pract. 2016, 94, 182–193. [Google Scholar] [CrossRef]
- Bagschik, G.; Menzel, T.; Maurer, M. Ontology based Scene Creation for the Development of Automated Vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1813–1820. [Google Scholar] [CrossRef]
- Langner, J.; Bach, J.; Ries, L.; Otten, S.; Holzäpfel, M.; Sax, E. Estimating the Uniqueness of Test Scenarios derived from Recorded Real-World-Driving-Data using Autoencoders. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1860–1866. [Google Scholar]
- Krajewski, R.; Moers, T.; Nerger, D.; Eckstein, L. Data-Driven Maneuver Modeling using Generative Adversarial Networks and Variational Autoencoders for Safety Validation of Highly Automated Vehicles. In Proceedings of the 2018 IEEE 21th International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2383–2390. [Google Scholar]
- Althoff, M.; Dolan, J.M. Reachability computation of low-order models for the safety verification of high-order road vehicle models. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 3559–3566. [Google Scholar]
- Beglerovic, H.; Ravi, A.; Wikström, N.; Koegeler, H.M.; Leitner, A.; Holzinger, J. Model-based safety validation of the automated driving function highway pilot. In 8th International Munich Chassis Symposium 2017; Pfeffer, P.E., Ed.; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2017; pp. 309–329. [Google Scholar]
- Riedmaier, S.; Ponn, T.; Ludwig, D.; Schick, B.; Diermeyer, F. Survey on Scenario-Based Safety Assessment of Automated Vehicles. IEEE Access 2020, 8, 87456–87477. [Google Scholar] [CrossRef]
- United Nations Economic Commission for Europe (UNECE). Addendum 139—Regulation No. 140—Uniform Provisions Concerning the Approval of Passenger Cars with Regard to Electronic Stability Control (ESC) Systems; UNECE: Geneva, Switzerland, 2017. [Google Scholar]
- Lutz, A.; Schick, B.; Holzmann, H.; Kochem, M.; Meyer-Tuve, H.; Lange, O.; Mao, Y.; Tosolin, G. Simulation methods supporting homologation of Electronic Stability Control in vehicle variants. Veh. Syst. Dyn. 2017, 55, 1432–1497. [Google Scholar] [CrossRef]
- United Nations Economic Commission for Europe. Proposal for Amendments to ECE/TRANS/WP.29/GRVA/2019/19; UNECE: Geneva, Switzerland, 2019. [Google Scholar]
- Schneider, D.; Huber, B.; Lategahn, H.; Schick, B. Measuring method for function and quality of automated lateral control based on high-precision digital ”Ground Truth” maps. In 34. VDI/VW-Gemeinschaftstagung Fahrerassistenzsysteme und Automatisiertes Fahren 2018; VDI-Berichte; VDI Verlag GmbH: Düsseldorf, Germany, 2018; pp. 3–16. [Google Scholar]
- Keidler, S.; Schneider, D.; Haselberger, J.; Mayannavar, K.; Schick, B. Development of lane-precise “Ground Truth” maps for the objective Quality Assessment of automated driving functions. In Proceedings of the 17 Internationale VDI-Fachtagung Reifen—Fahrwerk—Fahrbahn, Düsseldorf, Germany, 16–17 October 2019. [Google Scholar]
- Riedmaier, S.; Danquah, B.; Schick, B.; Diermeyer, F. Unified Framework and Survey for Model Verification, Validation and Uncertainty Quantification. Arch. Comput. Methods Eng. 2020. [Google Scholar] [CrossRef]
- Rosenberger, P.; Holder, M.; Zirulnik, M.; Winner, H. Analysis of Real World Sensor Behavior for Rising Fidelity of Physically Based Lidar Sensor Models. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 611–616. [Google Scholar]
- Schaermann, A.; Rauch, A.; Hirsenkorn, N.; Hanke, T.; Rasshofer, R.; Biebl, E. Validation of vehicle environment sensor models. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 405–411. [Google Scholar]
- Abbas, H.; O’Kelly, M.; Rodionova, A.; Mangharam, R. Safe At Any Speed: A Simulation-Based Test Harness for Autonomous Vehicles. In Proceedings of the Seventh Workshop on Design, Modeling and Evaluation of Cyber Physical Systems (CyPhy’17), Seoul, Korea, 15–20 October 2017; pp. 94–106. [Google Scholar]
- Viehof, M.; Winner, H. Research methodology for a new validation concept in vehicle dynamics. Automot. Engine Technol. 2018, 3, 21–27. [Google Scholar] [CrossRef]
- International Organization for Standardization. Passenger Cars—Validation of Vehicle Dynamic Simulation—Sine with Dwell Stability Control Testing; ISO: Geneva, Switzerland, 2016. [Google Scholar]
- Riedmaier, S.; Nesensohn, J.; Gutenkunst, C.; Düser, T.; Schick, B.; Abdellatif, H. Validation of X-in-the-Loop Approaches for Virtual Homologation of Automated Driving Functions. In Proceedings of the 11th Graz Symposium Virtual Vehicle (GSVF), Graz, Austria, 15–16 May 2018; pp. 1–12. [Google Scholar]
- Groh, K.; Wagner, S.; Kuehbeck, T.; Knoll, A. Simulation and Its Contribution to Evaluate Highly Automated Driving Functions. In WCX SAE World Congress Experience; SAE Technical Paper Series; SAE International400 Commonwealth Drive: Warrendale, PA, USA, 2019; pp. 1–11. [Google Scholar]
- Oberkampf, W.L.; Roy, C.J. Verification and Validation in Scientific Computing; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Ao, D.; Hu, Z.; Mahadevan, S. Dynamics Model Validation Using Time-Domain Metrics. J. Verif. Valid. Uncertain. Quantif. 2017, 2, 011004. [Google Scholar] [CrossRef]
- Voyles, I.T.; Roy, C.J. Evaluation of Model Validation Techniques in the Presence of Aleatory and Epistemic Input Uncertainties. In Proceedings of the 17th AIAA Non-Deterministic Approaches Conference, Kissimmee, FL, USA, 5–9 January 2015; American Institute of Aeronautics and Astronautics: College Park, MD, USA, 2015; pp. 1–16. [Google Scholar]
- Kennedy, M.C.; O’Hagan, A. Bayesian calibration of computer models. J. R. Stat. Soc. Ser. B 2001, 63, 425–464. [Google Scholar] [CrossRef]
- Sankararaman, S.; Mahadevan, S. Integration of model verification, validation, and calibration for uncertainty quantification in engineering systems. Reliab. Eng. Syst. Saf. 2015, 138, 194–209. [Google Scholar] [CrossRef]
- Hills, R.G. Roll-Up of Validation Results to a Target Application; Sandia National Laboratories: Albuquerque, NM, USA, 2013.
- Mullins, J.; Schroeder, B.; Hills, R.; Crespo, L. A Survey of Methods for Integration of Uncertainty and Model Form Error in Prediction; Probabilistic Mechanics & Reliability Conference (PMC): Albuquerque, NM, USA, 2016. [Google Scholar]
- Schuldt, F.; Menzel, T.; Maurer, M. Eine Methode für Die Zuordnung Von Testfällen für Automatisierte Fahrfunktionen auf X-In-The-Loop Simulationen im Modularen Virtuellen Testbaukasten; Workshop Fahrerassistenzsysteme: Garching, Germany, 2015; pp. 1–12. [Google Scholar]
- Böde, E.; Büker, M.; Ulrich, E.; Fränzle, M.; Gerwinn, S.; Kramer, B. Efficient Splitting of Test and Simulation Cases for the Verification of Highly Automated Driving Functions. In Computer Safety, Reliability, and Security; Gallina, B., Skavhaug, A., Bitsch, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 139–153. [Google Scholar]
- Morrison, R.E.; Bryant, C.M.; Terejanu, G.; Prudhomme, S.; Miki, K. Data partition methodology for validation of predictive models. Comput. Math. Appl. 2013, 66, 2114–2125. [Google Scholar] [CrossRef]
- Terejanu, G. Predictive Validation of Dispersion Models Using a Data Partitioning Methodology. In Model Validation and Uncertainty Quantification, Volume 3; Atamturktur, H.S., Moaveni, B., Papadimitriou, C., Schoenherr, T., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 151–156. [Google Scholar]
- Mullins, J.; Mahadevan, S.; Urbina, A. Optimal Test Selection for Prediction Uncertainty Reduction. J. Verif. Valid. Uncertain. Quantif. 2016, 1. [Google Scholar] [CrossRef]
- Forschungsgesellschaft für Straßen- und Verkehrswesen. Richtlinien für die Anlage von Autobahnen; FGSV: Cologne, Germany, 2008. [Google Scholar]
- Chen, W.; Kloul, L. An Ontology-based Approach to Generate the Advanced Driver Assistance Use Cases of Highway Traffic. In Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Seville, Spain, 18–20 September 2018; pp. 1–10. [Google Scholar]
- Li, Y.; Tao, J.; Wotawa, F. Ontology-based test generation for automated and autonomous driving functions. Inf. Softw. Technol. 2020, 117, 106200. [Google Scholar] [CrossRef]
- Beglerovic, H.; Schloemicher, T.; Metzner, S.; Horn, M. Deep Learning Applied to Scenario Classification for Lane-Keep-Assist Systems. Appl. Sci. 2018, 8, 2590. [Google Scholar] [CrossRef] [Green Version]
- Gruner, R.; Henzler, P.; Hinz, G.; Eckstein, C.; Knoll, A. Spatiotemporal representation of driving scenarios and classification using neural networks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–17 June 2017; pp. 1782–1788. [Google Scholar]
- Kruber, F.; Wurst, J.; Morales, E.S.; Chakraborty, S.; Botsch, M. Unsupervised and Supervised Learning with the Random Forest Algorithm for Traffic Scenario Clustering and Classification. In Proceedings of the 30th IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; pp. 2463–2470. [Google Scholar]
- Wang, W.; Zhao, D. Extracting Traffic Primitives Directly From Naturalistically Logged Data for Self-Driving Applications. IEEE Robot. Autom. Lett. 2018, 3, 1223–1229. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; del Re, L. Identification of critical cases of ADAS safety by FOT based parameterization of a catalogue. In Proceedings of the 2017 11th Asian Control Conference (ASCC), Gold Coast, Australia, 17–20 December 2017; pp. 453–458. [Google Scholar]
- de Gelder, E.; Paardekooper, J.P. Assessment of Automated Driving Systems using real-life scenarios. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–17 June 2017; pp. 589–594. [Google Scholar]
- Menzel, T.; Bagschik, G.; Maurer, M. Scenarios for Development, Test and Validation of Automated Vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Kim, B.; Jarandikar, A.; Shum, J.; Shiraishi, S.; Yamaura, M. The SMT-based automatic road network generation in vehicle simulation environment. In Proceedings of the 13th International Conference on Embedded Software—EMSOFT ’16, Grenoble, France, 12–16 October 2016; pp. 1–10. [Google Scholar]
- Rocklage, E.; Kraft, H.; Karatas, A.; Seewig, J. Automated scenario generation for regression testing of autonomous vehicles. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2017; pp. 476–483. [Google Scholar]
- Zhao, D. Accelerated Evaluation of Automated Vehicles. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 2016. [Google Scholar]
- Åsljung, D.; Nilsson, J.; Fredriksson, J. Using Extreme Value Theory for Vehicle Level Safety Validation and Implications for Autonomous Vehicles. IEEE Trans. Intell. Veh. 2017, 2, 288–297. [Google Scholar] [CrossRef]
- Stark, L.; Düring, M.; Schoenawa, S.; Maschke, J.E.; Do, C.M. Quantifying Vision Zero: Crash avoidance in rural and motorway accident scenarios by combination of ACC, AEB, and LKS projected to German accident occurrence. Traffic Inj. Prev. 2019, 20, 126–132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klischat, M.; Althoff, M. Generating Critical Test Scenarios for Automated Vehicles with Evolutionary Algorithms. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2352–2358. [Google Scholar]
- Ponn, T.; Müller, F.; Diermeyer, F. Systematic Analysis of the Sensor Coverage of Automated Vehicles Using Phenomenological Sensor Models. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1000–1006. [Google Scholar]
- Koren, M.; Alsaif, S.; Lee, R.; Kochenderfer, M.J. Adaptive Stress Testing for Autonomous Vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1898–1904. [Google Scholar]
- Beglerovic, H.; Stolz, M.; Horn, M. Testing of autonomous vehicles using surrogate models and stochastic optimization. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Tuncali, C.E.; Pavlic, T.P.; Fainekos, G. Utilizing S-TaLiRo as an Automatic Test Generation Framework for Autonomous Vehicles. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1470–1475. [Google Scholar]
- Dillencourt, M.B.; Samet, H.; Tamminen, M. A general approach to connected-component labeling for arbitrary image representations. J. ACM 1992, 39, 253–280. [Google Scholar] [CrossRef]
- Miller, R.G. Simultaneous Statistical Inference; Springer: New York, NY, USA, 1981. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | 2.153 | 2.188 | 2.179 | 2.025 |
| Standard deviation | 0.295 | 0.353 | 0.370 | 0.237 |
| Variance | 0.087 | 0.125 | 0.137 | 0.056 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riedmaier, S.; Schneider, D.; Watzenig, D.; Diermeyer, F.; Schick, B. Model Validation and Scenario Selection for Virtual-Based Homologation of Automated Vehicles. Appl. Sci. 2021, 11, 35. https://doi.org/10.3390/app11010035
Riedmaier S, Schneider D, Watzenig D, Diermeyer F, Schick B. Model Validation and Scenario Selection for Virtual-Based Homologation of Automated Vehicles. Applied Sciences. 2021; 11(1):35. https://doi.org/10.3390/app11010035
Chicago/Turabian StyleRiedmaier, Stefan, Daniel Schneider, Daniel Watzenig, Frank Diermeyer, and Bernhard Schick. 2021. "Model Validation and Scenario Selection for Virtual-Based Homologation of Automated Vehicles" Applied Sciences 11, no. 1: 35. https://doi.org/10.3390/app11010035
APA StyleRiedmaier, S., Schneider, D., Watzenig, D., Diermeyer, F., & Schick, B. (2021). Model Validation and Scenario Selection for Virtual-Based Homologation of Automated Vehicles. Applied Sciences, 11(1), 35. https://doi.org/10.3390/app11010035