
Context-Aware Querying, Geolocalization, and Rephotography of Historical Newspaper Images



Abstract
:1. Introduction
1.1. Dataset
1.2. Main Contributions
- Identification of the location information of a newspaper illustration based on its captions.
- Context-aware geolocalization of building images from KBR’s newspaper collections.
- Computational rephotography of historical urban scenes captured at different timestamps.
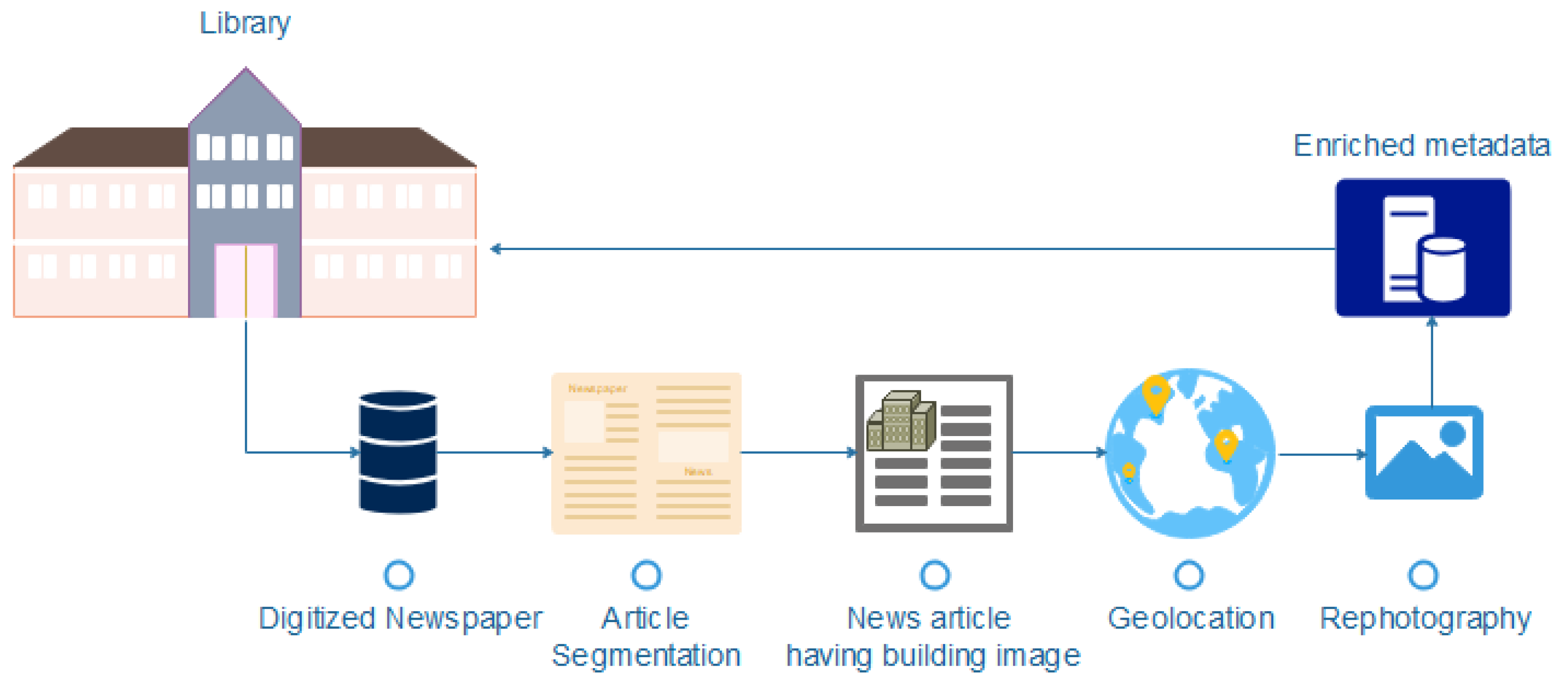
1.3. General Workflow
1.4. Limitations
1.5. Organization of Research Paper
2. Literature Review
2.1. Digitization and Extraction
2.2. Feature Extraction
2.3. Feature Matching for Geolocalization
2.4. Rephotography
3. Geolocalization of Historical Image Collections
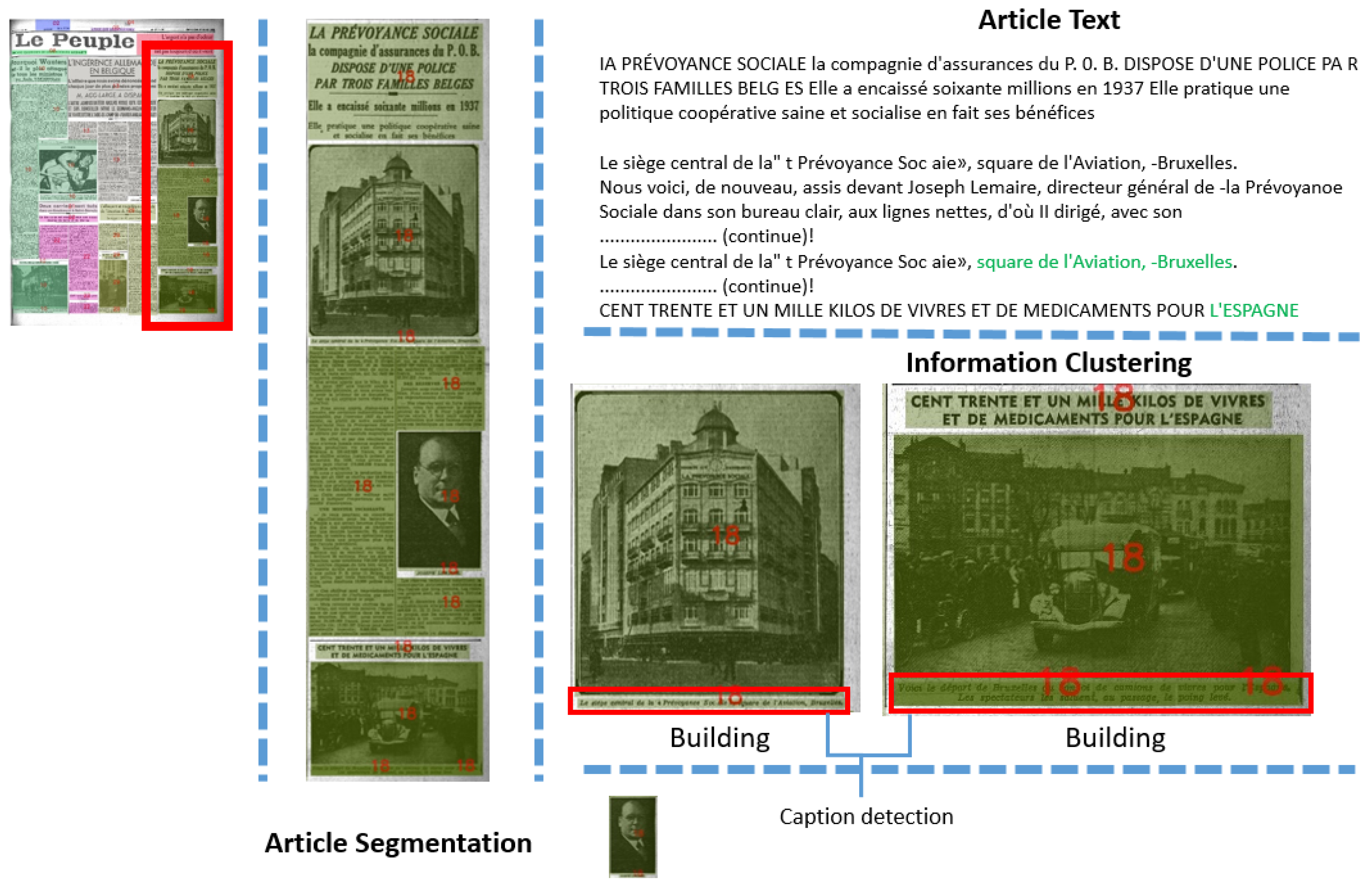
3.1. Article-Level Segmentation
3.2. Context-Aware Article Extraction
3.3. Caption Detection
3.4. Location Information Extraction
3.5. Geolocalization
4. Rephotography of Historical Image Collections
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Batista, G.E.; Monard, M.C. A study of K-nearest neighbour as an imputation method. His 2002, 87, 48. [Google Scholar]
- Hughes, L.M. Digitizing Collections: Strategic Issues for the Information Manager; Facet Publishing: London, UK, 2004; Volume 2. [Google Scholar]
- Nielsen, E.K. Digitisation of library material in Europe: Problems, obstacles and perspectives anno 2007. Liber Q. J. Assoc. Eur. Res. Libr. 2008, 18, 20–27. [Google Scholar] [CrossRef] [Green Version]
- Ehrmann, M.; Bunout, E.; Duering, M. Survey of Digitized Newspaper Interfaces; InfoScience: Lausanne, Switzerland, 2019. [Google Scholar]
- Bingham, A. The digitization of newspaper archives: Opportunities and challenges for historians. Twent. Century Br. Hist. 2010, 21, 225–231. [Google Scholar] [CrossRef]
- Traub, M.C.; Ossenbruggen, J.v.; Hardman, L. Impact analysis of OCR quality on research tasks in digital archives. In Proceedings of the International Conference on Theory and Practice of Digital Libraries, Poznań, Poland, 14–19 September 2015; pp. 252–263. [Google Scholar]
- Ali, D.; Verstockt, S. Challenges in Extraction and Classification of News Articles from Historical Newspapers. In Proceedings of the What is Past is Prologue: The NewsEye International Conference 2021, Virtual, 16–17 March 2021; pp. 8–9. [Google Scholar]
- James-Gilboe, L. The challenge of digitization: Libraries are finding that newspaper projects are not for the faint of heart. Ser. Libr. 2005, 49, 155–163. [Google Scholar] [CrossRef]
- Hill, M.J.; Hengchen, S. Quantifying the impact of dirty OCR on historical text analysis: Eighteenth Century Collections Online as a case study. Digit. Scholarsh. Humanit. 2019, 34, 825–843. [Google Scholar] [CrossRef]
- Jarlbrink, J.; Snickars, P. Cultural heritage as digital noise: Nineteenth century newspapers in the digital archive. J. Doc. 2017, 73, 1228–1243. [Google Scholar] [CrossRef]
- Fugini, M.; Finocchi, J. Data and Process Quality Evaluation in a Textual Big Data Archiving System. ACM J. Comput. Cult. Herit. 2022, 15, 1–19. [Google Scholar] [CrossRef]
- Lu, T.; Ilic, D.; Dooms, A. Noise characterization for historical documents with physical distortions. In Proceedings of the Optics, Photonics and Digital Technologies for Imaging Applications VI. International Society for Optics and Photonics, Online, 6–10 April 2020; Volume 11353, p. 113530F. [Google Scholar]
- BelgicaPress Platform. Available online: https://www.belgicapress.be/?lang=EN (accessed on 26 May 2022).
- Michalakis, K.; Caridakis, G. Context Awareness in Cultural Heritage Applications: A Survey. ACM J. Comput. Cult. Herit. 2022, 15, 1–31. [Google Scholar] [CrossRef]
- Dahroug, A.; Vlachidis, A.; Liapis, A.; Bikakis, A.; Lopez-Nores, M.; Sacco, O.; Pazos-Arias, J.J. Using dates as contextual information for personalised cultural heritage experiences. J. Inf. Sci. 2021, 47, 82–100. [Google Scholar] [CrossRef]
- Chaudhury, K.; Jain, A.; Thirthala, S.; Sahasranaman, V.; Saxena, S.; Mahalingam, S. Google newspaper search–image processing and analysis pipeline. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 621–625. [Google Scholar]
- Pekárek, A.; Willems, M. The europeana newspapers—A gateway to european newspapers online. In Proceedings of the Euro-Mediterranean Conference, Limassol, Cyprus, 29 October–3 November 2012; pp. 654–659. [Google Scholar]
- Lee, B.C.G.; Mears, J.; Jakeway, E.; Ferriter, M.; Adams, C.; Yarasavage, N.; Thomas, D.; Zwaard, K.; Weld, D.S. The newspaper navigator dataset: Extracting and analyzing visual content from 16 million historic newspaper pages in chronicling America. arXiv 2020, arXiv:2005.01583. [Google Scholar]
- Ali, D.; Millivellie, K.; van den Broeck, A.; Verstockt, S. NewspAIper: AI-Based Metadata Enrichment of Historical Newspaper Collections. 2022. Available online: https://zenodo.org/record/6593028/export/dcat (accessed on 23 October 2022).
- Kemman, M.; Claeyssens, S. User demand for supporting advanced analysis of historical text collections. In Proceedings of the DH Benelux 2022—ReMIX: Creation and alteration in DH (hybrid), Belval Campus, Esch-sur-Alzette, Luxembourg, Online, 1–3 June 2022. [Google Scholar] [CrossRef]
- Kestemont, M.; Karsdorp, F.; Düring, M. Mining the twentieth century’s history from the time magazine corpus. In Proceedings of the 8th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (LaTeCH), Gothenburg, Sweden, 26 April 2014; pp. 62–70. [Google Scholar]
- Bikakis, A.; Hyvönen, E.; Jean, S.; Markhoff, B.; Mosca, A. Special issue on Semantic Web for Cultural Heritage. Semant. Web 2021, 12, 163–167. [Google Scholar] [CrossRef]
- Baqués, X.G.; Mosca, A.; Rondelli, B.; Fort, G.R. Roman Open Data: A semantic based Data Visualization & Exploratory Interface. In Arqueología y Téchne: Métodos Formales, Nuevos Enfoques: Archaeology and Techne: Formal Methods, New Approaches; Archaeopress Publishing: Oxford, UK, 2022. [Google Scholar]
- Roffo, G.; Giorgetta, C.; Ferrario, R.; Riviera, W.; Cristani, M. Statistical analysis of personality and identity in chats using a keylogging platform. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 224–231. [Google Scholar]
- Gao, Q.; Shu, X.; Wu, X. Deep restoration of vintage photographs from scanned halftone prints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 4120–4129. [Google Scholar]
- Smits, T. Illustrations to Photographs: Using computer vision to analyse news pictures in Dutch newspapers, 1860–1940. In Proceedings of the DH, Montréal, QC, Canada, 8–11 August 2017. [Google Scholar]
- Tahmasebzadeh, G.; Kacupaj, E.; Müller-Budack, E.; Hakimov, S.; Lehmann, J.; Ewerth, R. GeoWINE: Geolocation based Wiki, Image, News and Event Retrieval. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 2565–2569. [Google Scholar]
- Bae, S.; Agarwala, A.; Durand, F. Computational rephotography. ACM Trans. Graph. 2010, 29, 24. [Google Scholar] [CrossRef] [Green Version]
- Ali, D.; Verstockt, S.; Van de Weghe, N. Single Image Façade Segmentation and Computational Rephotography of House Images Using Deep Learning. J. Comput. Cult. Herit. 2021, 14, 1–17. [Google Scholar] [CrossRef]
- Idowu, A. How ‘Rephotography’ is Capturing Chicago in the Age of COVID-19. 2020. Available online: https://news.wttw.com/2020/04/21/how-rephotography-capturing-chicago-age-covid-19 (accessed on 6 June 2022).
- Hersch, M. Time After Time, Rephotography in the Midst of a Pandemic. 2020. Available online: https://www.markhersch.com/rephotography-in-the-midst-of-a-pandemic (accessed on 6 June 2022).
- Huang, H.; Gartner, G.; Krisp, J.M.; Raubal, M.; Van de Weghe, N. Location based services: Ongoing evolution and research agenda. J. Locat. Based Serv. 2018, 12, 63–93. [Google Scholar] [CrossRef] [Green Version]
- Harrach, M.; Devaux, A.; Brédif, M. Interactive image geolocalization in an immersive web application. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2019, 42, 377–380. [Google Scholar] [CrossRef] [Green Version]
- KBR Collections. Available online: https://www.kbr.be/en/collections/ (accessed on 26 May 2022).
- Chambers, S.; Lemmers, F.; Pham, T.A.; Birkholz, J.M.; Ducatteeuw, V.; Jacquet, A.; Dillen, W.; Ali, D.; Milleville, K.; Verstockt, S. Collections as Data: Interdisciplinary experiments with KBR’s digitised historical newspapers: A Belgian case study. In Proceedings of the 7th DH Benelux: The Humanities in a Digital World (DH Benelux 2021), Belgium, The Netherlands, 2–4 June 2021. [Google Scholar]
- Gao, L.; Tang, Z.; Lin, X.; Wang, Y. A graph-based method of newspaper article reconstruction. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 1566–1569. [Google Scholar]
- Naoum, A.; Nothman, J.; Curran, J. Article segmentation in digitised newspapers with a 2D Markov model. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1007–1014. [Google Scholar]
- Chen, M.; Ding, X.; Liang, J. Analysis, Understanding and Representation of Chinese newspaper with complex layout. In Proceedings of the Proceedings 2000 International Conference on Image Processing (Cat. No. 00CH37101), Vancouver, BC, Canada, 10–13 September 2000; Volume 2, pp. 590–593. [Google Scholar]
- Reynar, J.C. An automatic method of finding topic boundaries. arXiv 1994, arXiv:cmp-lg/9406017. [Google Scholar]
- Hadjar, K.; Hitz, O.; Ingold, R. Newspaper page decomposition using a split and merge approach. In Proceedings of the Sixth International Conference on Document Analysis and Recognition, Seattle, WA, USA, 13 September 2001; pp. 1186–1189. [Google Scholar]
- Doerr, M.; Markakis, G.; Theodoridou, M.; Tsikritzis, M. DIATHESIS: OCR based semantic annotation of newspapers. In Proceedings of the Third SEEDI International Conference: Digitization of Cultural and Scientific Heritage, Cetinje, Montenegro, 13–15 September 2007. [Google Scholar]
- Meier, B.; Stadelmann, T.; Stampfli, J.; Arnold, M.; Cieliebak, M. Fully convolutional neural networks for newspaper article segmentation. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 414–419. [Google Scholar]
- Paaß, G.; Konya, I. Machine learning for document structure recognition. In Modeling, Learning, and Processing of Text Technological Data Structures; Springer: Berlin/Heidelberg, Germany, 2011; pp. 221–247. [Google Scholar]
- Almutairi, A.; Almashan, M. Instance segmentation of newspaper elements using mask R-CNN. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning Furthermore, Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1371–1375. [Google Scholar]
- Bhatt, J.; Hashmi, K.A.; Afzal, M.Z.; Stricker, D. A survey of graphical page object detection with deep neural networks. Appl. Sci. 2021, 11, 5344. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhai, C. A survey of text clustering algorithms. In Mining Text Data; Springer: Berlin/Heidelberg, Germany, 2012; pp. 77–128. [Google Scholar]
- Aggarwal, C.C.; Reddy, C.K. Data clustering. Algorithms and Applications; Chapman&Hall/CRC Data Mining and Knowledge Discovery Series; Chapman&Hall/CRC: London, UK, 2014. [Google Scholar]
- Aletras, N.; Stevenson, M.; Clough, P. Computing similarity between items in a digital library of cultural heritage. J. Comput. Cult. Herit. 2013, 5, 1–19. [Google Scholar] [CrossRef]
- Linhares Pontes, E.; Cabrera-Diego, L.A.; Moreno, J.G.; Boros, E.; Hamdi, A.; Sidère, N.; Coustaty, M.; Doucet, A. Entity Linking for Historical Documents: Challenges and Solutions. In Proceedings of the International Conference on Asian Digital Libraries, Kyoto, Japan, 30 November–1 December 2020; pp. 215–231. [Google Scholar]
- DiMaggio, P.; Nag, M.; Blei, D. Exploiting affinities between topic modeling and the sociological perspective on culture: Application to newspaper coverage of US government arts funding. Poetics 2013, 41, 570–606. [Google Scholar] [CrossRef]
- Aker, A.; Kurtic, E.; Balamurali, A.; Paramita, M.; Barker, E.; Hepple, M.; Gaizauskas, R. A graph-based approach to topic clustering for online comments to news. In Proceedings of the European Conference on Information Retrieval, Padua, Italy, 20–23 March 2016; pp. 15–29. [Google Scholar]
- Mele, I.; Bahrainian, S.A.; Crestani, F. Event mining and timeliness analysis from heterogeneous news streams. Inf. Process. Manag. 2019, 56, 969–993. [Google Scholar] [CrossRef]
- Zhong, X.; Tang, J.; Jimeno Yepes, A. PubLayNet: Largest dataset ever for document layout analysis. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Li, M.; Xu, Y.; Cui, L.; Huang, S.; Wei, F.; Li, Z.; Zhou, M. DocBank: A Benchmark Dataset for Document Layout Analysis. arXiv 2020, arXiv:cs.CL/2006.01038. [Google Scholar]
- Zhu, W.; Sokhandan, N.; Yang, G.; Martin, S.; Sathyanarayana, S. DocBed: A multi-stage OCR solution for documents with complex layouts. Proc. Conf. AAAI Artif. Intell. 2022, 36, 12643–12649. [Google Scholar] [CrossRef]
- Clausner, C.; Papadopoulos, C.; Pletschacher, S.; Antonacopoulos, A. The ENP image and ground truth dataset of historical newspapers. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Antonacopoulos, A.; Clausner, C.; Papadopoulos, C.; Pletschacher, S. Icdar 2013 competition on historical newspaper layout analysis (hnla). In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1454–1458. [Google Scholar]
- Düring, M.; Kalyakin, R.; Bunout, E.; Guido, D. Impresso inspect and Compare. Visual comparison of semantically enriched historical newspaper articles. Information 2021, 12, 348. [Google Scholar] [CrossRef]
- Manovich, L. Data science and digital art history. Int. J. Digit. Art Hist. 2015. [Google Scholar] [CrossRef]
- Lowe, G. Sift-the scale invariant feature transform. Int. J. 2004, 2, 91–110. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2564–2571. [Google Scholar]
- Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Large-scale image retrieval with attentive deep local features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3456–3465. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. CNN image retrieval learns from BoW: Unsupervised fine-tuning with hard examples. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 3–20. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers-A Tutorial. ACM Comput. Surv. 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Y.; Feng, J. On the Euclidean distance of images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1334–1339. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Mitotes, W. Then and Now: The Time Portals Into a World War II. 2010. Available online: http://weramitotes.blogspot.com/2010/08/then-and-now-time-portals-into-world.html (accessed on 26 May 2022).
- Lee, K.T.; Luo, S.J.; Chen, B.Y. Rephotography using image collections. Comput. Graph. Forum 2011, 30, 1895–1901. [Google Scholar] [CrossRef]
- Mac Kim, S.; Cassidy, S. Finding names in trove: Named entity recognition for Australian historical newspapers. In Proceedings of the Australasian Language Technology Association Workshop 2015, Melbourne, Australia, 8–9 December 2015; pp. 57–65. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Each Subsection | Full Pipeline | |||
|---|---|---|---|---|
| Location Information | Geolocalization | Rephotography | ||
| Correctly processed | 32 | 26 | 21 | |
| Accuracy per section | 80% | 81% | 81% | |
| Accuracy full pipeline | 52.5% | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, D.; Blyau, T.; Van de Weghe, N.; Verstockt, S. Context-Aware Querying, Geolocalization, and Rephotography of Historical Newspaper Images. Appl. Sci. 2022, 12, 11063. https://doi.org/10.3390/app122111063
Ali D, Blyau T, Van de Weghe N, Verstockt S. Context-Aware Querying, Geolocalization, and Rephotography of Historical Newspaper Images. Applied Sciences. 2022; 12(21):11063. https://doi.org/10.3390/app122111063
Chicago/Turabian StyleAli, Dilawar, Thibault Blyau, Nico Van de Weghe, and Steven Verstockt. 2022. "Context-Aware Querying, Geolocalization, and Rephotography of Historical Newspaper Images" Applied Sciences 12, no. 21: 11063. https://doi.org/10.3390/app122111063
APA StyleAli, D., Blyau, T., Van de Weghe, N., & Verstockt, S. (2022). Context-Aware Querying, Geolocalization, and Rephotography of Historical Newspaper Images. Applied Sciences, 12(21), 11063. https://doi.org/10.3390/app122111063