
Deep Reinforcement Learning-Based Adaptive Controller for Trajectory Tracking and Altitude Control of an Aerial Robot


Abstract
:1. Introduction
1.1. Control Problem of Aerial Robots
1.2. Related Works
1.3. Research Objectives
2. Aerial Robot Dynamics
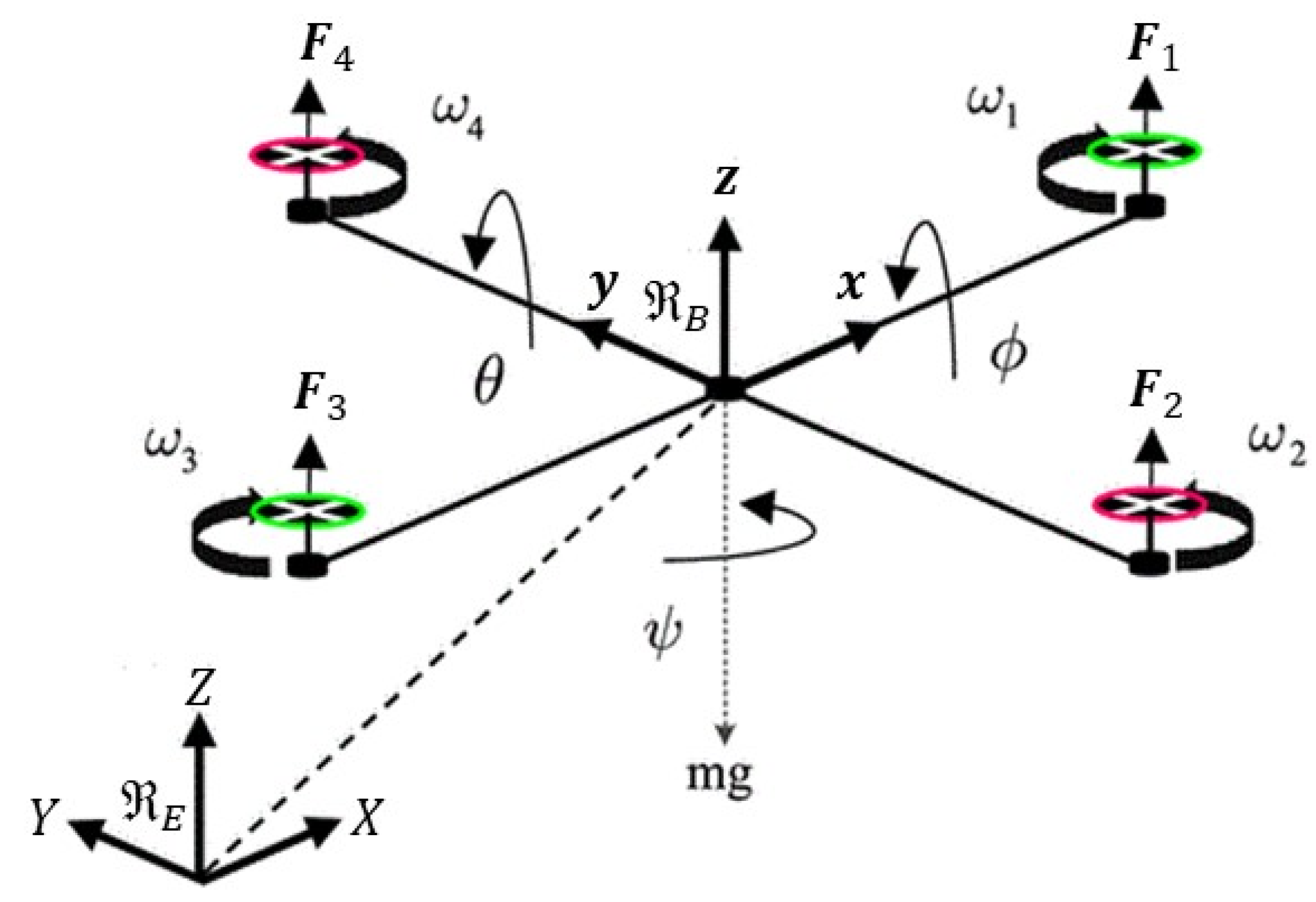
2.1. Quadcopter Coordinate Frames, Forces, and Torques
- The aerial robot consists of a stiff body with a symmetrical structure.
- The geometrical center of the robot is the same as its center of gravity and mass.
- The moment of inertia of the propellers has been overlooked.
2.2. Translational Dynamics
- The total weight of the vehicle, as expressed in Equation (1).
- The generated thrust of rotors, which can be calculated using Equation (2).
- As indicated in Equation (3), the drag force and air friction.
2.3. Rotational Dynamics
2.4. Dynamics Model of the Quadcopter
3. Quadcopter Control
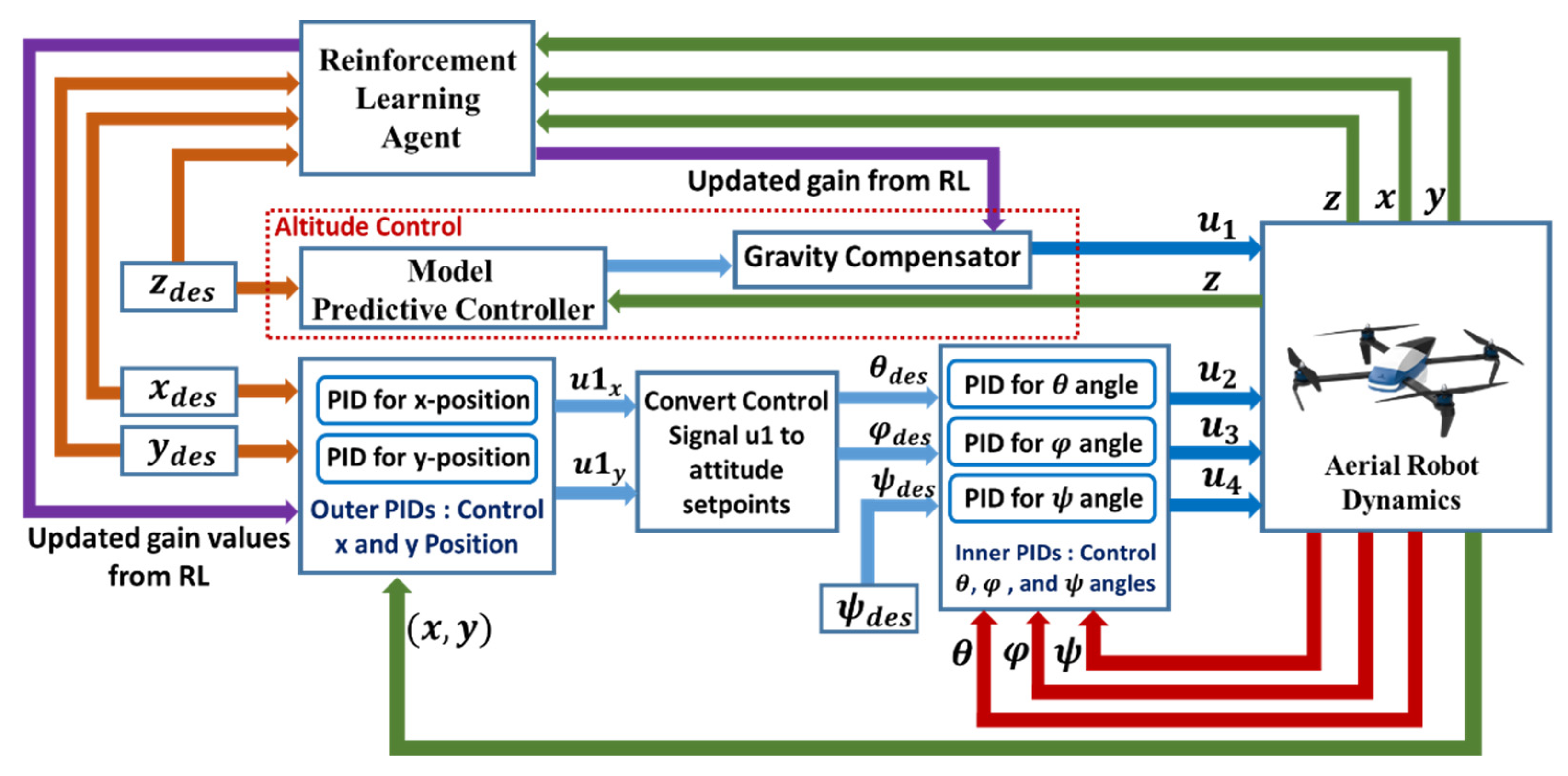
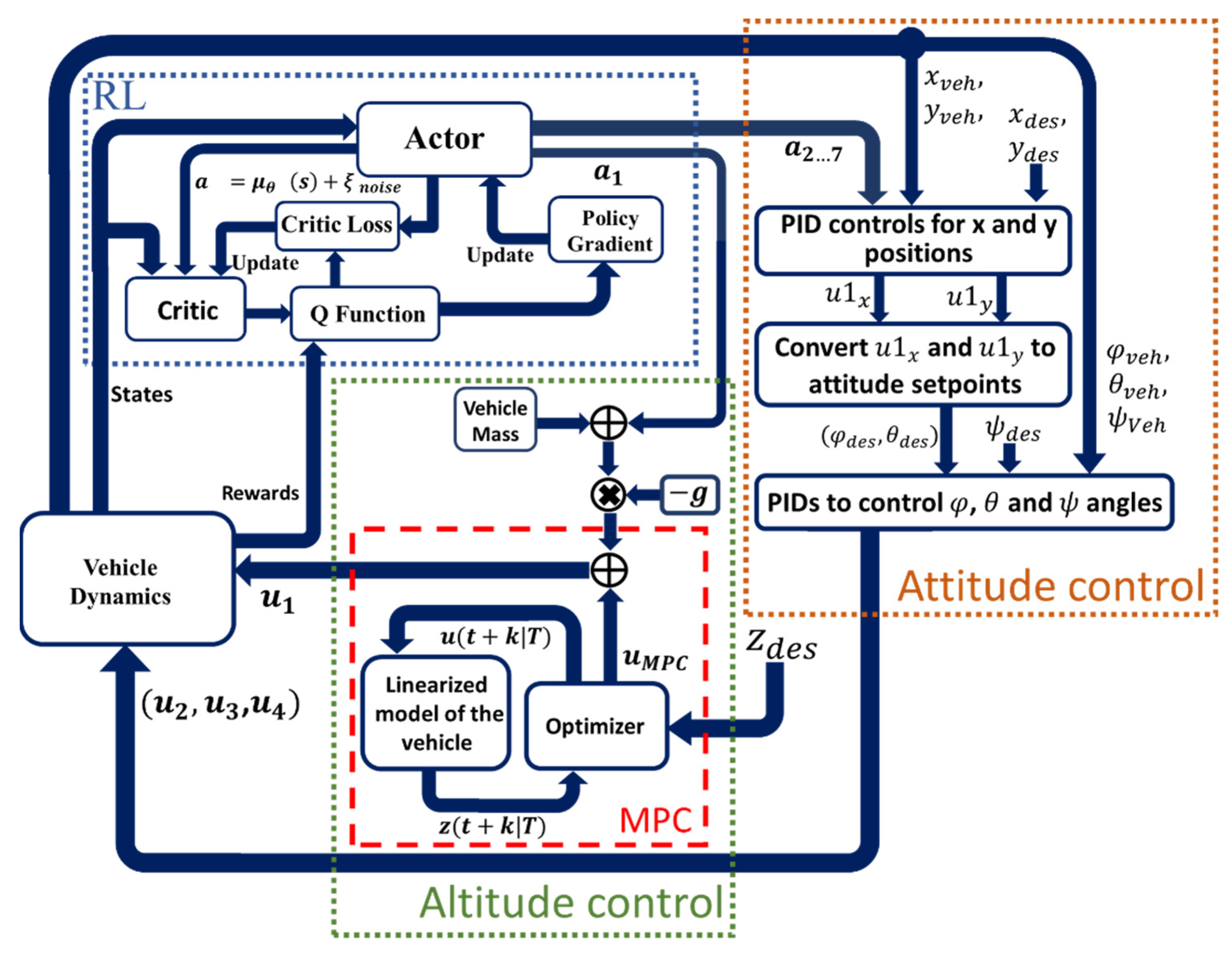
3.1. Controller Framework
3.2. Attitude Control
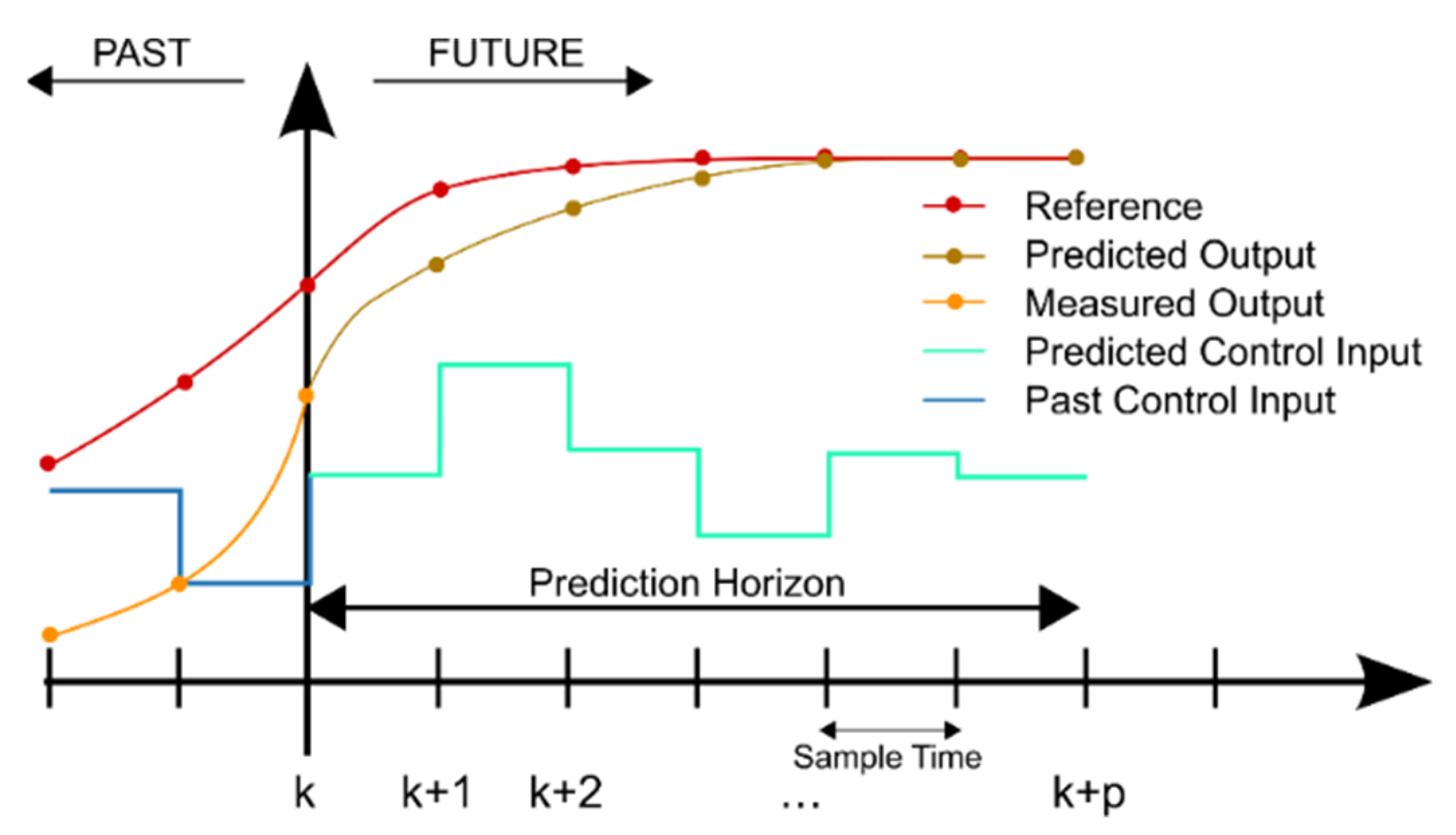
3.3. Altitude Control
- A dynamics model of the system under control.
- A cost function J.
- An optimization mechanism. The optimal manipulated variable () is computed by minimizing the cost function J using the optimization algorithm.
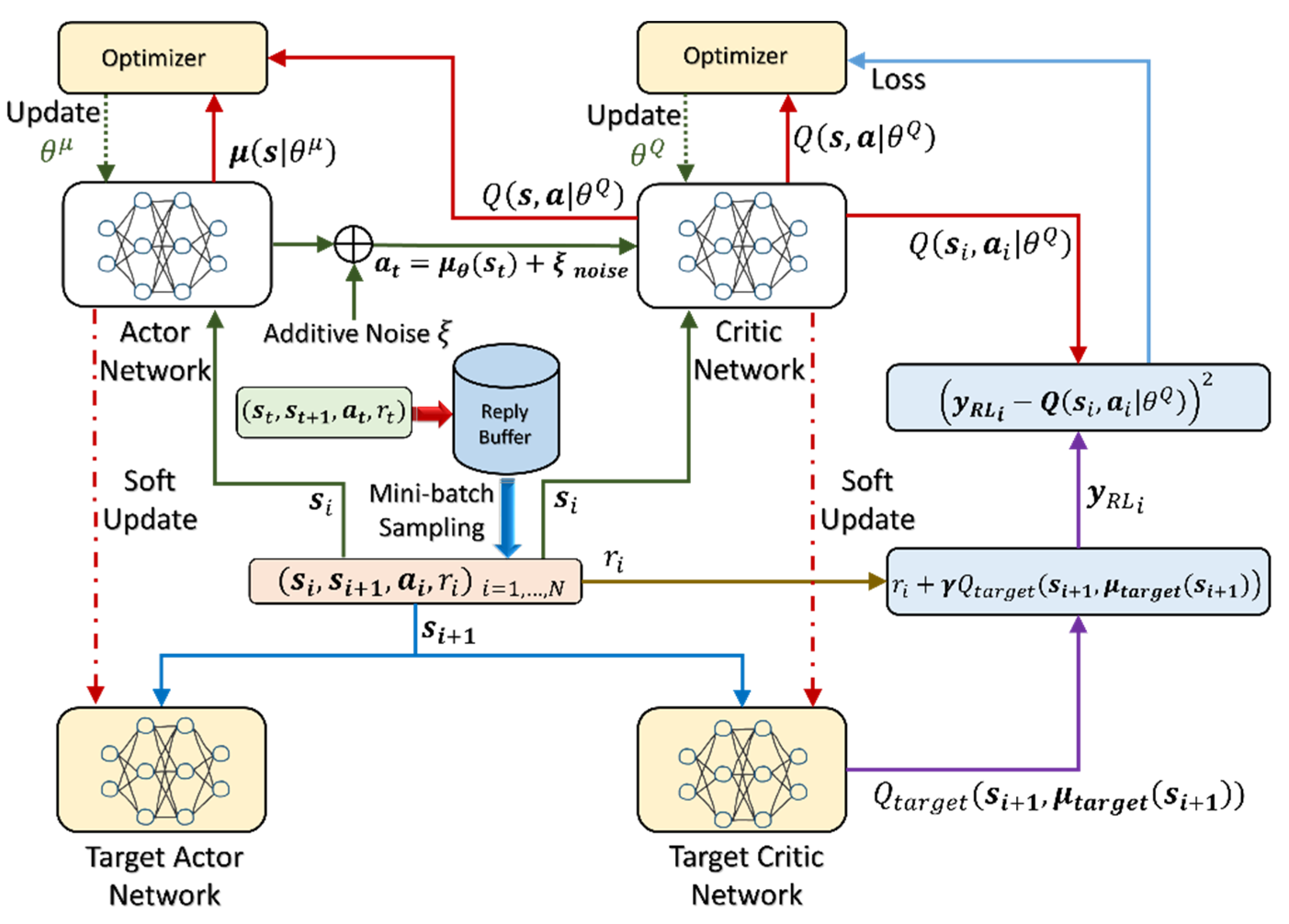
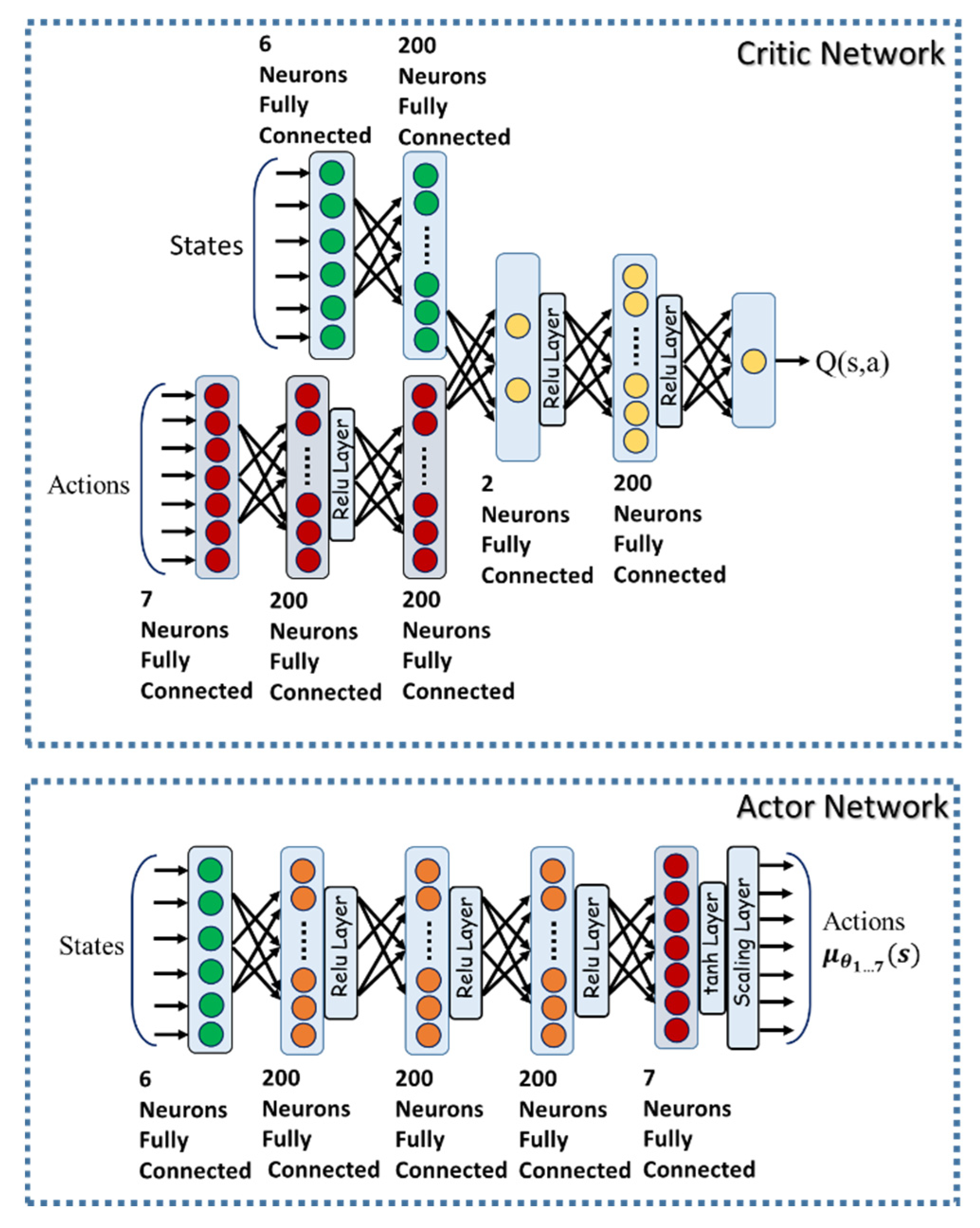
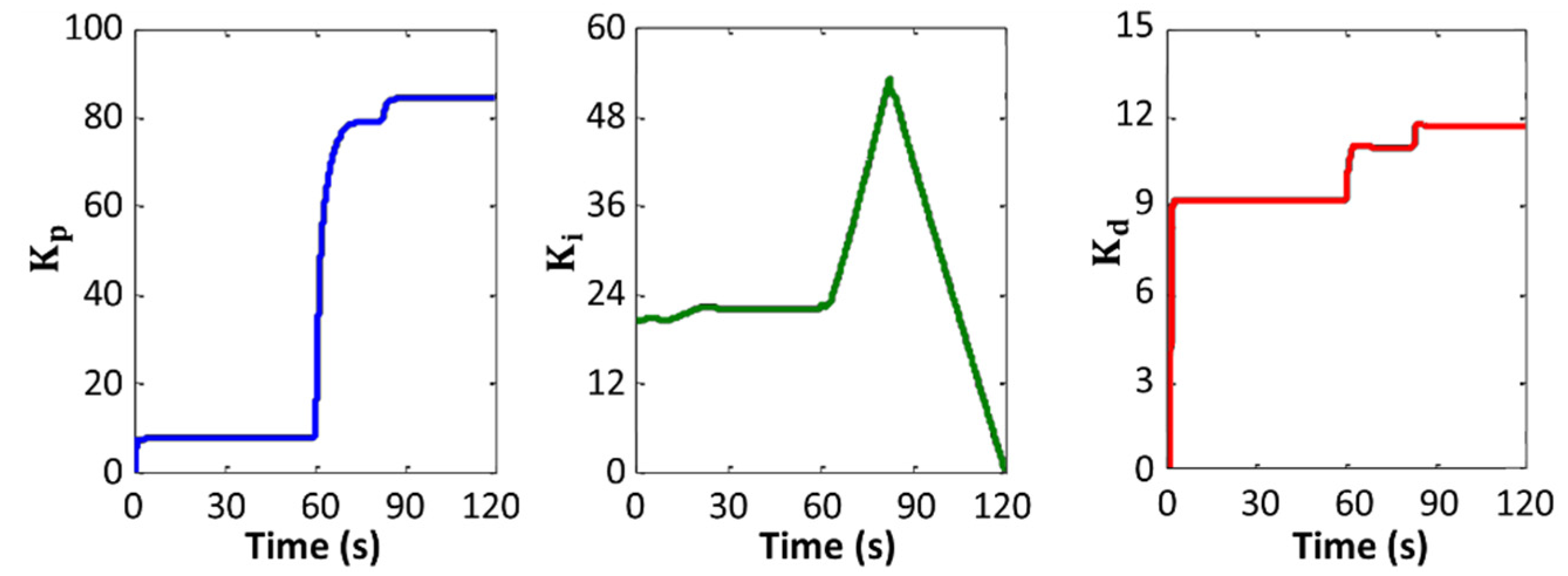
3.4. Deep Reinforcement Learning for Online Parameter Estimation and Tuning
- An experience reply memory to store past transitions and learn off-policy.
- Target networks to stabilize learning.
| Algorithm 1. The proposed algorithm. | |||||
| 1: | Initial policy network and critic network with weights respectively. | ||||
| 2: | Set target policy network and target critic network with weights | ||||
| 3: | Set target parameters weights equal to main parameters weights: | ||||
| 4: | for episode = 1, M do | ||||
| 5: | Initialize a random process noise for action exploration. | ||||
| 6: | Receive initial observation state . | ||||
| 7: | for t = 1, T do | ||||
| 8: | Select actions where | ||||
| 9: | Observe a vector of states s | ||||
| 10: | Apply actions ( to outer loop PID controllers as follow: | ||||
| 11: | Use the updated and to generate | ||||
| 12: | Use as setpoints for inner loop PIDs and generate , and . | ||||
| 13: | Compute by minimizing the MPC cost function. | ||||
| 14: | Compute using the generated namipulated variable from MPC and the scalling factor of the compensator ) | ||||
| 15: | Apply control inputs ,, and to the drone dynamics model. | ||||
| 16: | Observe the next vector of states , and the next reward r | ||||
| 17: | Store () in reply buffer D. | ||||
| 18: | Randomly sample a minibatch of N transitions () from D. | ||||
| 19: | Compute targets: | ||||
| 20: | Update critic by minimizing the loss: | ||||
| 21: | Update the actor policy using a sampled policy gradient: | ||||
| 22: | Update the target networks: | ||||
| 23: | | ||||
| 24: | end for | ||||
| 25: | end for | ||||
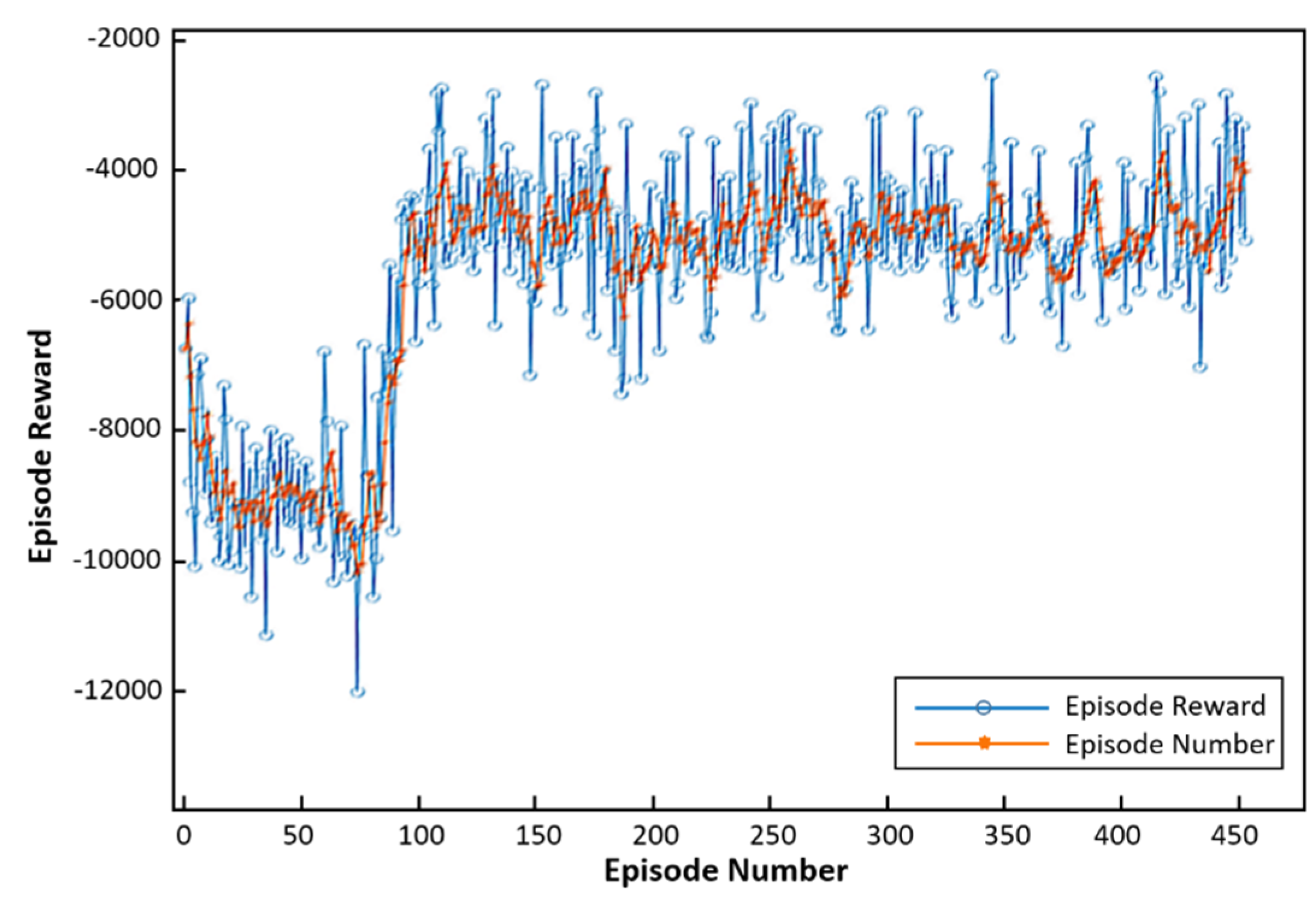
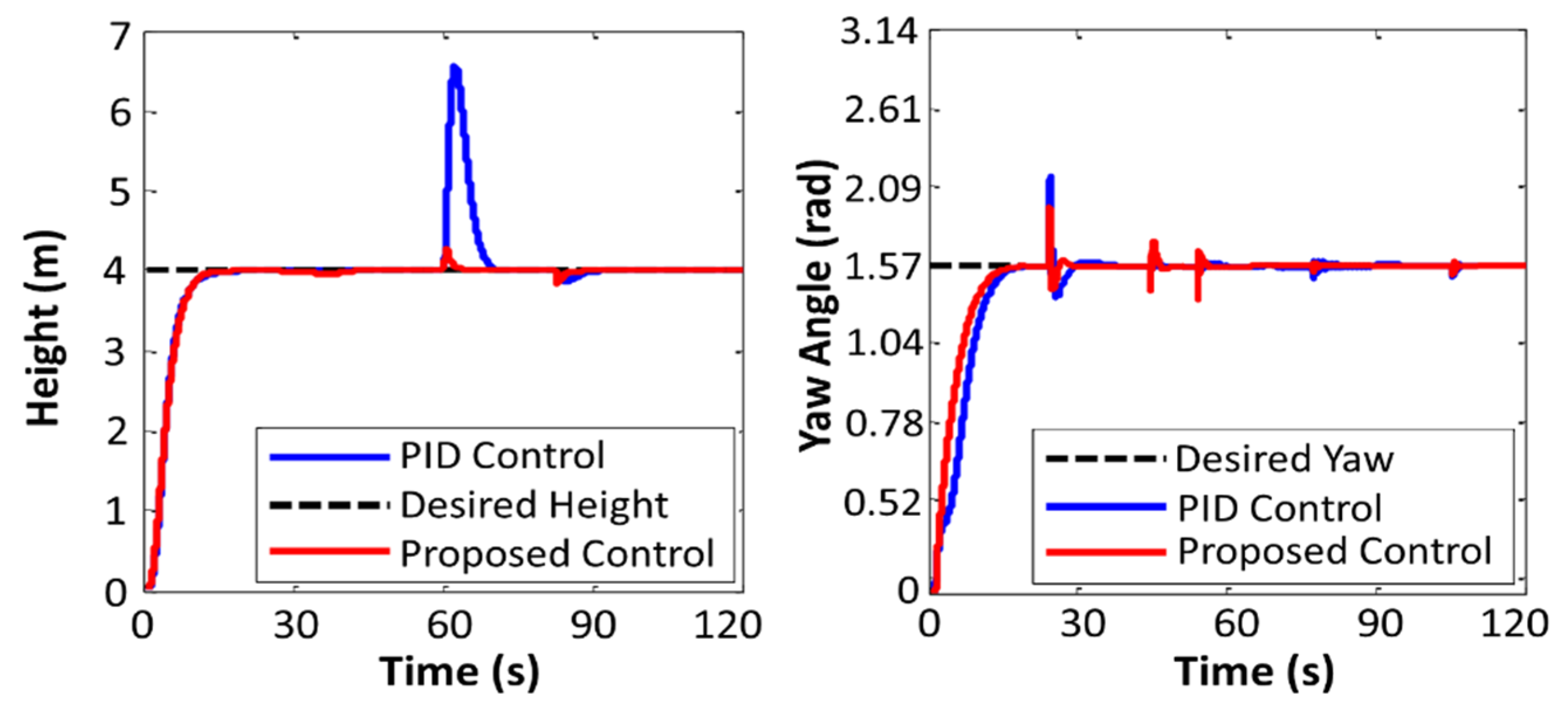
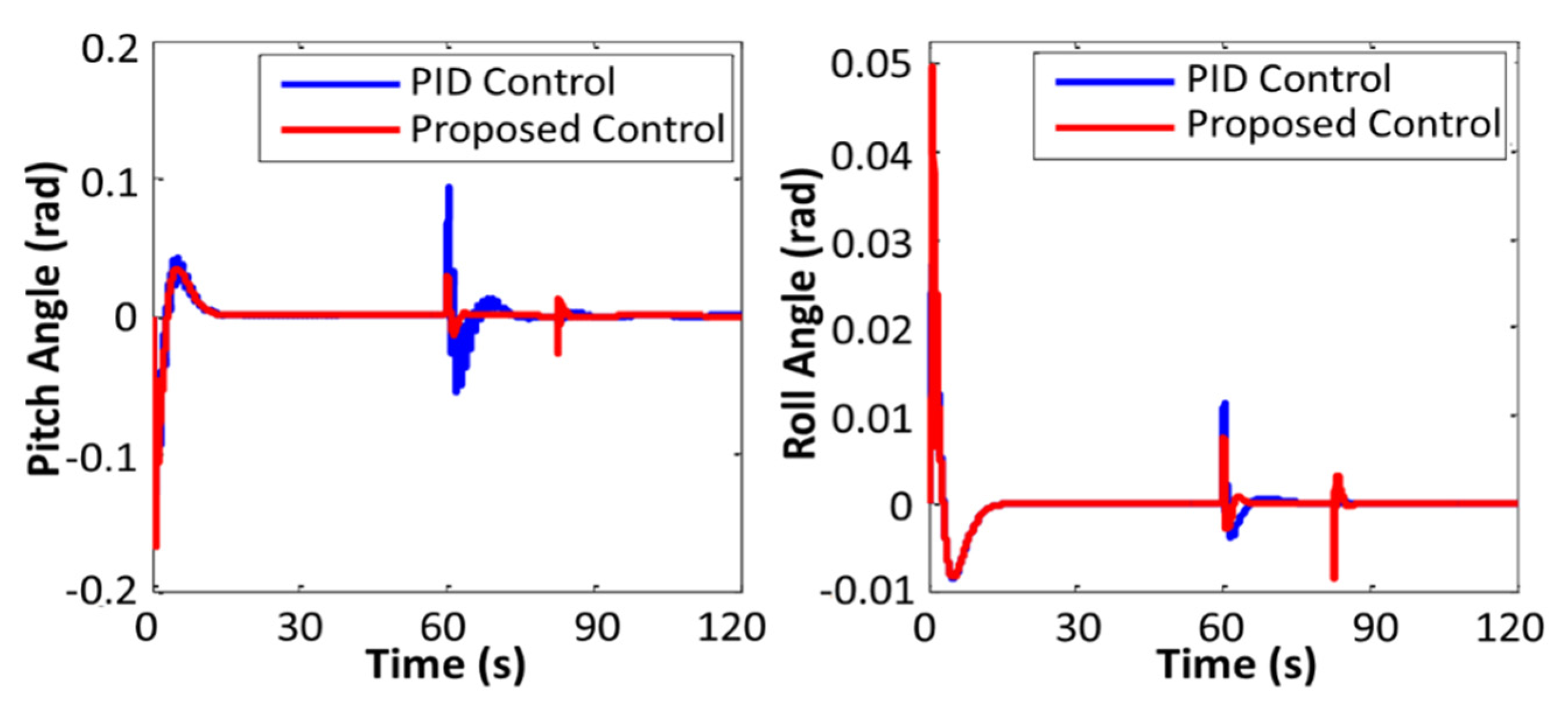
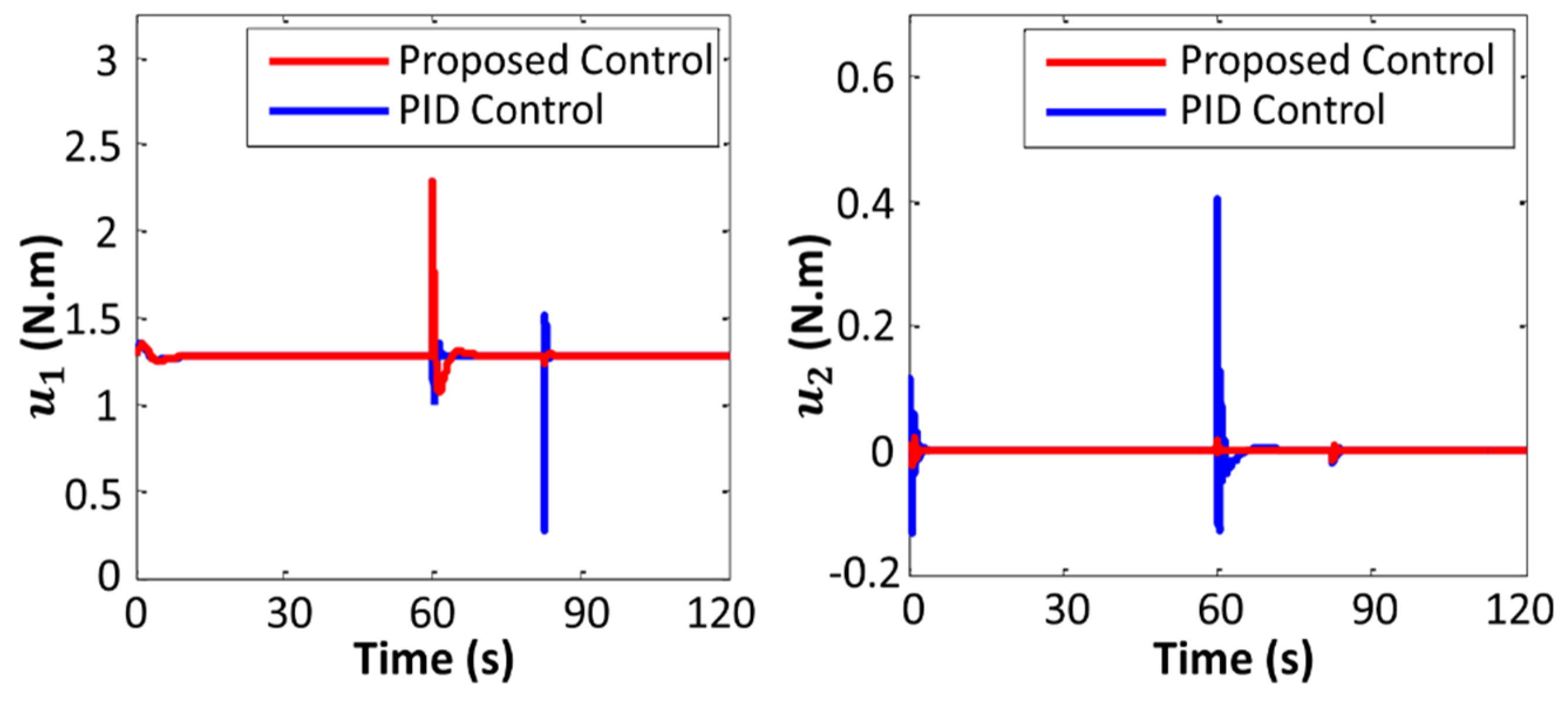
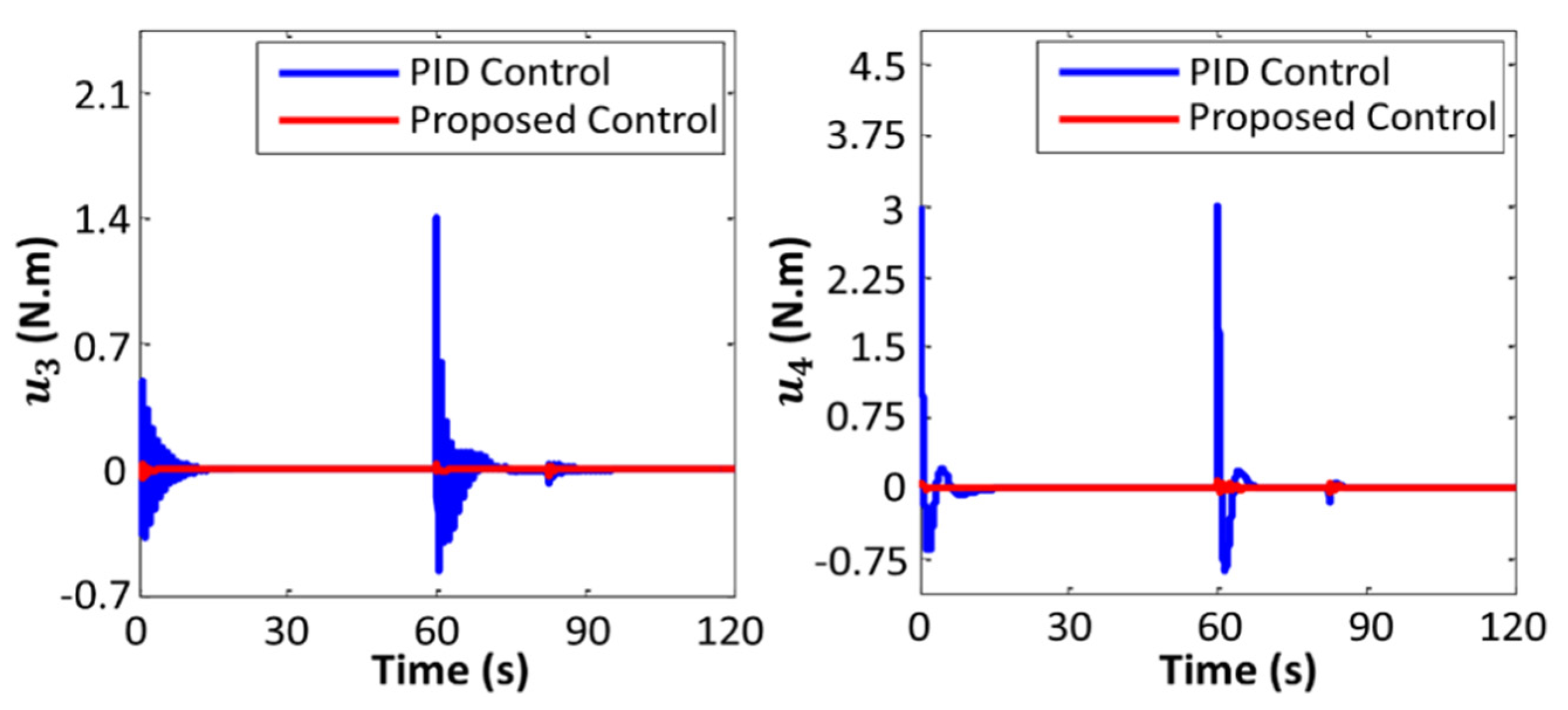
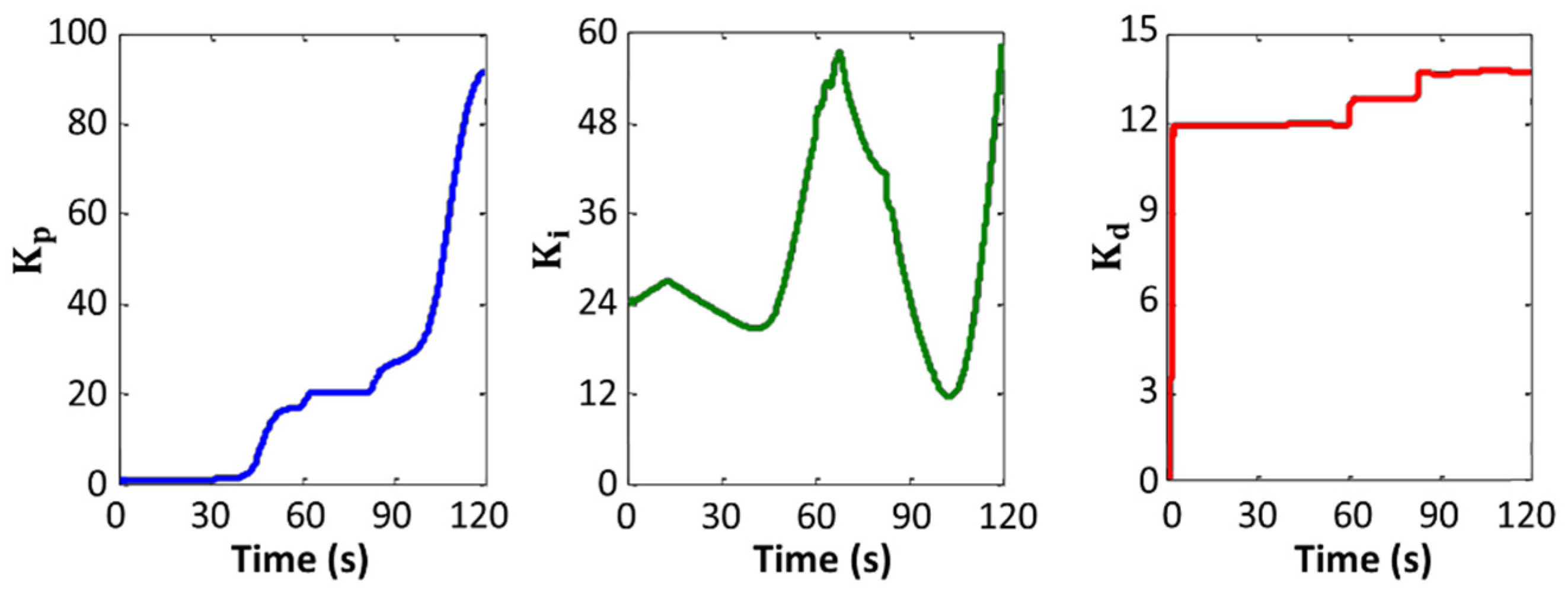
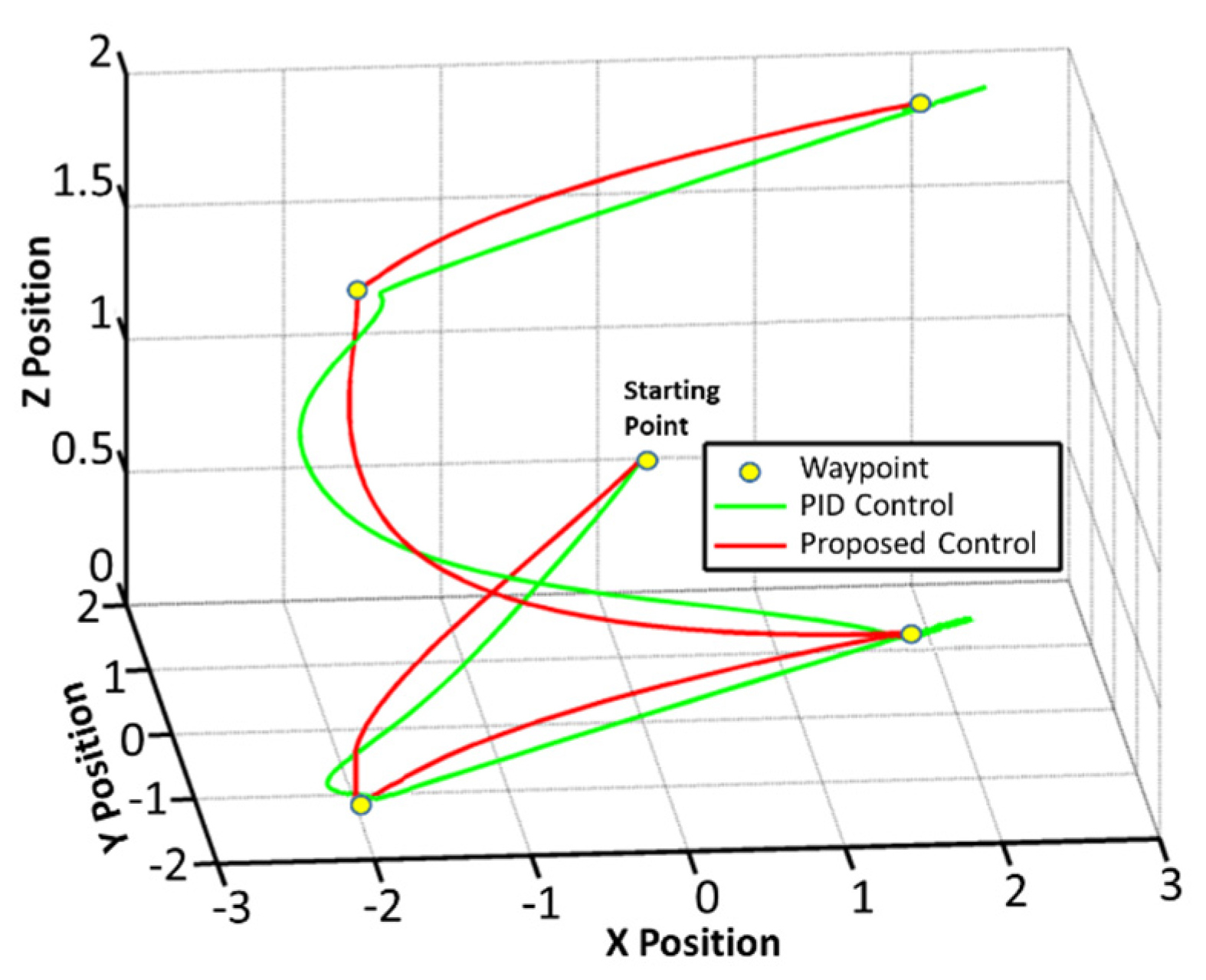
4. Simulations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Saunders, J.; Saeedi, S.; Li, W. Autonomous Aerial Delivery Vehicles, a Survey of Techniques on how Aerial Package Delivery is Achieved. arXiv 2021, arXiv:2110.02429. [Google Scholar]
- Joshi, G.; Virdi, J.; Chowdhary, G. Design and flight evaluation of deep model reference adaptive controller. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 1336. [Google Scholar]
- Balcazar, R.; Rubio, J.D.J.; Orozco, E.; Cordova, D.A.; Ochoa, G.; Garcia, E.; Pacheco, J.; Gutierrez, G.J.; Mujica-Vargas, D.; Aguilar-Ibañez, C. The Regulation of an Electric Oven and an Inverted Pendulum. Symmetry 2022, 14, 759. [Google Scholar] [CrossRef]
- Rubio, J.D.J.; Orozco, E.; Cordova, D.A.; Islas, M.A.; Pacheco, J.; Gutierrez, G.J.; Zacarias, A.; Soriano, L.A.; Meda-Campana, J.A.; Mujica-Vargas, D. Modified Linear Technique for the Controllability and Observability of Robotic Arms. IEEE Access 2022, 10, 3366–3377. [Google Scholar] [CrossRef]
- Aguilar-Ibanez, C.; Moreno-Valenzuela, J.; García-Alarcón, O.; Martinez-Lopez, M.; Acosta, J.Á.; Suarez-Castanon, M.S. PI-Type Controllers and Σ–Δ Modulation for Saturated DC-DC Buck Power Converters. IEEE Access 2021, 9, 20346–20357. [Google Scholar] [CrossRef]
- Soriano, L.A.; Rubio, J.D.J.; Orozco, E.; Cordova, D.A.; Ochoa, G.; Balcazar, R.; Cruz, D.R.; Meda-Campaña, J.A.; Zacarias, A.; Gutierrez, G.J. Optimization of Sliding Mode Control to Save Energy in a SCARA Robot. Mathematics 2021, 9, 3160. [Google Scholar] [CrossRef]
- Vosoogh, M.; Piltan, F.; Mirshekaran, A.M.; Barzegar, A.; Siahbazi, A.; Sulaiman, N. Integral Criterion-Based Adaptation Control to Vibration Reduction in Sensitive Actuators. Int. J. Hybrid Inf. Technol. 2015, 8, 11–30. [Google Scholar] [CrossRef]
- Soriano, L.A.; Zamora, E.; Vazquez-Nicolas, J.M.; Hernández, G.; Madrigal, J.A.B.; Balderas, D. PD Control Compensation Based on a Cascade Neural Network Applied to a Robot Manipulator. Front. Neurorobotics 2020, 14, 78. [Google Scholar] [CrossRef]
- Kada, B.; Ghazzawi, Y. Robust PID controller design for an UAV flight control system. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 19–21 October 2011; Volume 2, pp. 1–6. [Google Scholar]
- Silva-Ortigoza, R.; Hernández-Márquez, E.; Roldán-Caballero, A.; Tavera-Mosqueda, S.; Marciano-Melchor, M.; García-Sánchez, J.R.; Hernández-Guzmán, V.M.; Silva-Ortigoza, G. Sensorless Tracking Control for a “Full-Bridge Buck Inverter–DC Motor” System: Passivity and Flatness-Based Design. IEEE Access 2021, 9, 132191–132204. [Google Scholar] [CrossRef]
- Mirshekaran, A.M.; Piltan, F.; Sulaiman, N.; Siahbazi, A.; Barzegar, A.; Vosoogh, M. Design Intelligent Model-free Hybrid Guidance Controller for Three Dimension Motor. Int. J. Inf. Eng. Electron. Bus. 2014, 6, 29–35. [Google Scholar] [CrossRef] [Green Version]
- Barzegar, A.; Piltan, F.; Mirshekaran, A.M.; Siahbazi, A.; Vosoogh, M.; Sulaiman, N. Research on Hand Tremors-Free in Active Joint Dental Automation. Int. J. Hybrid Inf. Technol. 2015, 8, 71–96. [Google Scholar] [CrossRef]
- He, X.; Kou, G.; Calaf, M.; Leang, K.K. In-Ground-Effect Modeling and Nonlinear-Disturbance Observer for Multirotor Unmanned Aerial Vehicle Control. J. Dyn. Syst. Meas. Control 2019, 141, 071013. [Google Scholar] [CrossRef] [Green Version]
- Barzegar, A.; Doukhi, O.; Lee, D.J.; Jo, Y.H. Nonlinear Model Predictive Control for Self-Driving cars Tra-jectory Tracking in GNSS-denied environments. In Proceedings of the 2020 20th International Conference on Control, Automation and Systems (ICCAS), Busan, Korea, 13–16 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 750–755. [Google Scholar]
- Cao, G.; Lai, E.M.-K.; Alam, F. Gaussian Process Model Predictive Control of an Unmanned Quadrotor. J. Intell. Robot. Syst. 2017, 88, 147–162. [Google Scholar] [CrossRef] [Green Version]
- Mehndiratta, M.; Kayacan, E. Gaussian Process-based Learning Control of Aerial Robots for Precise Visualization of Geological Outcrops. In Proceedings of the 2020 European Control Conference (ECC), St. Petersburg, Russia, 12–15 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10–16. [Google Scholar] [CrossRef]
- Caldwell, J.; Marshall, J.A. Towards Efficient Learning-Based Model Predictive Control via Feedback Lineari-zation and Gaussian Process Regression. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4306–4311. [Google Scholar]
- Chee, K.Y.; Jiahao, T.Z.; Hsieh, M.A. KNODE-MPC: A Knowledge-Based Data-Driven Predictive Control Framework for Aerial Robots. IEEE Robot. Autom. Lett. 2022, 7, 2819–2826. [Google Scholar] [CrossRef]
- Richards, A.; How, J. Decentralized model predictive control of cooperating UAVs. In Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC) (IEEE Cat. No. 04CH37601), Nassau, Bahamas, 14–17 December 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 4, pp. 4286–4291. [Google Scholar]
- Scholte, E.; Campbell, M. Robust Nonlinear Model Predictive Control With Partial State Information. IEEE Trans. Control Syst. Technol. 2008, 16, 636–651. [Google Scholar] [CrossRef]
- Mathisen, S.H.; Gryte, K.; Johansen, T.; Fossen, T.I. Non-linear Model Predictive Control for Longitudinal and Lateral Guidance of a Small Fixed-Wing UAV in Precision Deep Stall Landing. In Proceedings of the AIAA Infotech@ Aerospace, San Diego, CA, USA, 4–8 January 2016; p. 0512. [Google Scholar] [CrossRef] [Green Version]
- Barzegar, A.; Doukhi, O.; Lee, D.-J. Design and Implementation of an Autonomous Electric Vehicle for Self-Driving Control under GNSS-Denied Environments. Appl. Sci. 2021, 11, 3688. [Google Scholar] [CrossRef]
- Iskandarani, M.; Givigi, S.N.; Fusina, G.; Beaulieu, A. Unmanned Aerial Vehicle formation flying using Linear Model Predictive Control. In Proceedings of the 2014 IEEE International Systems Conference Proceedings, Ottawa, ON, Canada, 31 March–3 April 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 18–23. [Google Scholar] [CrossRef]
- Britzelmeier, A.; Gerdts, M. A Nonsmooth Newton Method for Linear Model-Predictive Control in Tracking Tasks for a Mobile Robot with Obstacle Avoidance. IEEE Control Syst. Lett. 2020, 4, 886–891. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, A.; Sun, H.Y. MPC and SADE for UAV real-time path planning in 3D environment. In Proceedings 2014 IEEE International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Wuhan, China, 18–19 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 130–133. [Google Scholar] [CrossRef]
- Pan, Z.; Li, D.; Yang, K.; Deng, H. Multi-Robot Obstacle Avoidance Based on the Improved Artificial Potential Field and PID Adaptive Tracking Control Algorithm. Robotica 2019, 37, 1883–1903. [Google Scholar] [CrossRef]
- Doukhi, O.; Fayjie, A.R.; Lee, D.J. Intelligent Controller Design for Quad-Rotor Stabilization in Presence of Parameter Variations. J. Adv. Transp. 2017, 2017, 4683912. [Google Scholar] [CrossRef] [Green Version]
- Rosales, C.D.; Tosetti, S.R.; Soria, C.M.; Rossomando, F.G. Neural Adaptive PID Control of a Quadrotor using EFK. IEEE Lat. Am. Trans. 2018, 16, 2722–2730. [Google Scholar] [CrossRef]
- Rosales, C.; Soria, C.M.; Rossomando, F.G. Identification and adaptive PID Control of a hexacopter UAV based on neural networks. Int. J. Adapt. Control Signal Process. 2018, 33, 74–91. [Google Scholar] [CrossRef] [Green Version]
- Sarhan, A.; Qin, S. Adaptive PID Control of UAV Altitude Dynamics Based on Parameter Optimization with Fuzzy Inference. Int. J. Model. Optim. 2016, 6, 246–251. [Google Scholar] [CrossRef] [Green Version]
- Siahbazi, A.; Barzegar, A.; Vosoogh, M.; Mirshekaran, A.M.; Soltani, S. Design Modified Sliding Mode Controller with Parallel Fuzzy Inference System Compensator to Control of Spherical Motor. Int. J. Intell. Syst. Appl. 2014, 6, 12–25. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Liu, J. Research on uav balance control based on expert-fuzzy adaptive pid. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 787–789. [Google Scholar]
- Barzegar, A.; Piltan, F.; Vosoogh, M.; Mirshekaran, A.M.; Siahbazi, A. Design Serial Intelligent Modified Feedback Linearization like Controller with Application to Spherical Motor. Int. J. Inf. Technol. Comput. Sci. 2014, 6, 72–83. [Google Scholar] [CrossRef] [Green Version]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; PMLR: London, UK, 2016; pp. 1329–1338. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Claus, C.; Boutilier, C. The dynamics of reinforcement learning in cooperative multiagent systems. In Proceedings of the Fifteenth National/Tenth Conference on Artificial Intelligence/Innovative Applications of Artificial Intelligence, Madison, WI, USA, 26–30 July 1998; pp. 746–752. [Google Scholar]
- Bernstein, A.V.; Burnaev, E.V. Reinforcement learning in computer vision. In Proceedings of the Tenth International Conference on Machine Vision (ICMV 2017), Vienna, Austria, 13–15 November 2048; Volume 10696, pp. 458–464. [Google Scholar]
- Bohn, E.; Coates, E.M.; Moe, S.; Johansen, T.A. Deep Reinforcement Learning Attitude Control of Fixed-Wing UAVs Using Proximal Policy optimization. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 523–533. [Google Scholar] [CrossRef] [Green Version]
- Koch, W.; Mancuso, R.; West, R.; Bestavros, A. Reinforcement Learning for UAV Attitude Control. ACM Trans. Cyber-Phys. Syst. 2019, 3, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Polvara, R.; Patacchiola, M.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R.; Cangelosi, A. Toward End-to-End Control for UAV Autonomous Landing via Deep Reinforcement Learning. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 115–123. [Google Scholar] [CrossRef]
- Passalis, N.; Tefas, A. Continuous drone control using deep reinforcement learning for frontal view person shooting. Neural Comput. Appl. 2019, 32, 4227–4238. [Google Scholar] [CrossRef]
- Zheng, L.; Zhou, Z.; Sun, P.; Zhang, Z.; Wang, R. A novel control mode of bionic morphing tail based on deep reinforcement learning. arXiv 2020, arXiv:2010.03814. [Google Scholar]
- Botvinick, M.; Ritter, S.; Wang, J.X.; Kurth-Nelson, Z.; Blundell, C.; Hassabis, D. Reinforcement learning, fast and slow. Trends Cogn. Sci. 2019, 23, 408–422. [Google Scholar] [CrossRef] [Green Version]
- Pi, C.-H.; Ye, W.-Y.; Cheng, S. Robust Quadrotor Control through Reinforcement Learning with Disturbance Compensation. Appl. Sci. 2021, 11, 3257. [Google Scholar] [CrossRef]
- Shi, Q.; Lam, H.-K.; Xuan, C.; Chen, M. Adaptive neuro-fuzzy PID controller based on twin delayed deep deterministic policy gradient algorithm. Neurocomputing 2020, 402, 183–194. [Google Scholar] [CrossRef]
- Dooraki, A.R.; Lee, D.-J. An innovative bio-inspired flight controller for quad-rotor drones: Quad-rotor drone learning to fly using reinforcement learning. Robot. Auton. Syst. 2020, 135, 103671. [Google Scholar] [CrossRef]
- Quan, Q. Introduction to Multicopter Design and Control, 1st ed.; Springer Nature: Singapore, 2017; pp. 99–120. [Google Scholar]
- Hernandez, A.; Copot, C.; De Keyser, R.; Vlas, T.; Nascu, I. Identification and path following control of an AR. Drone quadrotor. In Proceedings of the 2013 17th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 11–13 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 583–588. [Google Scholar]
- Fan, J.; Wang, Z.; Xie, Y.; Yang, Z. A theoretical analysis of deep Q-learning. In Proceedings of the Learning for Dynamics and Control, Virtual, 7–8 June 2020; PMLR: London, UK, 2020; pp. 486–489. [Google Scholar]
- Jesus, C., Jr.; Bottega, J.A.; Cuadros, M.A.S.L.; Gamarra, D.F.T. Deep deterministic policy gradient for navigation of mobile robots in simulated environments. In Proceedings of the 2019 19th International Conference on Advanced Robotics (ICAR), Belo Horizonte, Brazil, 2–6 December 2019; pp. 362–367. [Google Scholar]
- Sandipan, S.; Wadoo, S. Linear optimal control of a parrot AR drone 2.0. In Proceedings of the 2017 IEEE MIT Undergraduate Research Technology Conference (URTC), Cambridge, MA, USA, 3–5 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Glazkov, T.V.; Golubev, A.E. Using Simulink Support Package for Parrot Minidrones in nonlinear control education. AIP Conf. Proc. 2019, 2195, 020007. [Google Scholar] [CrossRef]
- Kaplan, M.R.; Eraslan, A.; Beke, A.; Kumbasar, T. Altitude and Position Control of Parrot Mambo Minidrone with PID and Fuzzy PID Controllers. In Proceedings of the 2019 11th International Conference on Electrical and Electronics Engineering (ELECO), Bursa, Turkey, 28–30 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 785–789. [Google Scholar] [CrossRef]
- Gill, J.S.; Velashani, M.S.; Wolf, J.; Kenney, J.; Manesh, M.R.; Kaabouch, N. Simulation Testbeds and Frameworks for UAV Performance Evaluation. In Proceedings of the 2021 IEEE International Conference on Electro Information Technology (EIT), Mt. Pleasant, MI, USA, 14–15 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 335–341. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PID Control | |||
|---|---|---|---|
| 0.021 | 0.011 | 0.003 | |
| 0.014 | 0.03 | 0.001 | |
| 0.002 | 0.07 | 0.013 |
| Specification | Parameter | Unit | Value |
|---|---|---|---|
| Drone Mass | m | kg | 0.063 |
| Lateral Moment Arm | l | m | 0.0624 |
| Thrust Coefficient | b | N∙s2 | 0.0107 |
| Drag Coefficient | d | N∙m∙s2 | 0.7826 × 10−3 |
| Rolling Moment of Inertia | Ix | Kg∙m2 | 5.82857 × 10−5 |
| Pitching Moment of Inertia | Iy | Kg∙m2 | 7.16914 × 10−5 |
| Yawing Moment of Inertia | Iz | Kg∙m2 | 0.0001 |
| Rotor Moment of Inertia | Ir | Kg∙m2 | 0.1021 × 10−6 |
| Parameter | Value |
|---|---|
| A | |
| B | |
| C | |
| D |
| Hyperparameter | Value |
|---|---|
| Critic Learning Rate | 0.0001 |
| Actor Learning Rate | 0.00001 |
| Critic Gradient Threshold | 1 |
| Actor Gradient Threshold | 4 |
| Variance | 0.3 |
| Variance Decay Rate | 0.00001 |
| Experience Buffer | 1,000,000 |
| Mini-Batch Size | 64 |
| Target Smooth Factor | 0.001 |
| Critic Learning Rate | Actor Grad Threshold | Critic Grad Threshold | Variance (Noise) | Mini Batch Size | Steady State Error |
|---|---|---|---|---|---|
| 4 | 1 | 0.3 | 64 | 0.00064 | |
| inf | 1 | 0.3 | 64 | 0.00093 | |
| 1 | 4 | 0.3 | 64 | 0.00011 | |
| 1 | inf | 0.3 | 64 | 0.00008 | |
| 1 | 1 | 0 | 64 | 0.00435 | |
| 1 | 1 | 0.5 | 64 | 0.00010 | |
| 1 | 1 | 0.3 | 128 | 0.00045 | |
| 4 | 1 | 0.3 | 64 | 0.00001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barzegar, A.; Lee, D.-J. Deep Reinforcement Learning-Based Adaptive Controller for Trajectory Tracking and Altitude Control of an Aerial Robot. Appl. Sci. 2022, 12, 4764. https://doi.org/10.3390/app12094764
Barzegar A, Lee D-J. Deep Reinforcement Learning-Based Adaptive Controller for Trajectory Tracking and Altitude Control of an Aerial Robot. Applied Sciences. 2022; 12(9):4764. https://doi.org/10.3390/app12094764
Chicago/Turabian StyleBarzegar, Ali, and Deok-Jin Lee. 2022. "Deep Reinforcement Learning-Based Adaptive Controller for Trajectory Tracking and Altitude Control of an Aerial Robot" Applied Sciences 12, no. 9: 4764. https://doi.org/10.3390/app12094764
APA StyleBarzegar, A., & Lee, D. -J. (2022). Deep Reinforcement Learning-Based Adaptive Controller for Trajectory Tracking and Altitude Control of an Aerial Robot. Applied Sciences, 12(9), 4764. https://doi.org/10.3390/app12094764