Diverse Decoding for Abstractive Document Summarization



Abstract
:Featured Application
Abstract
1. Introduction
- We introduce a Diversity-Promoting Beam Search approach (DPBS) in the sequence-to-sequence neural model to generate multiple diversified candidate sequences for abstractive document summarization. This search method covers a much larger search space than the standard beam search, thus increasing the probability of generating better summary sequences.
- We design a selection algorithm that considers extensive factors for the outputs of diverse beam search to locate the optimal sequence. The essential part of this method is using the attention mechanism as a bridge between the input document and the generated summary to estimate the salient information preservation, providing a novel and viable approach for saliency estimation.
- We combine these methods in a unified neural summarization system and achieve state-of-the-art performance.
2. Related Work
3. Neural Abstractive Summarization with Diverse Decoding
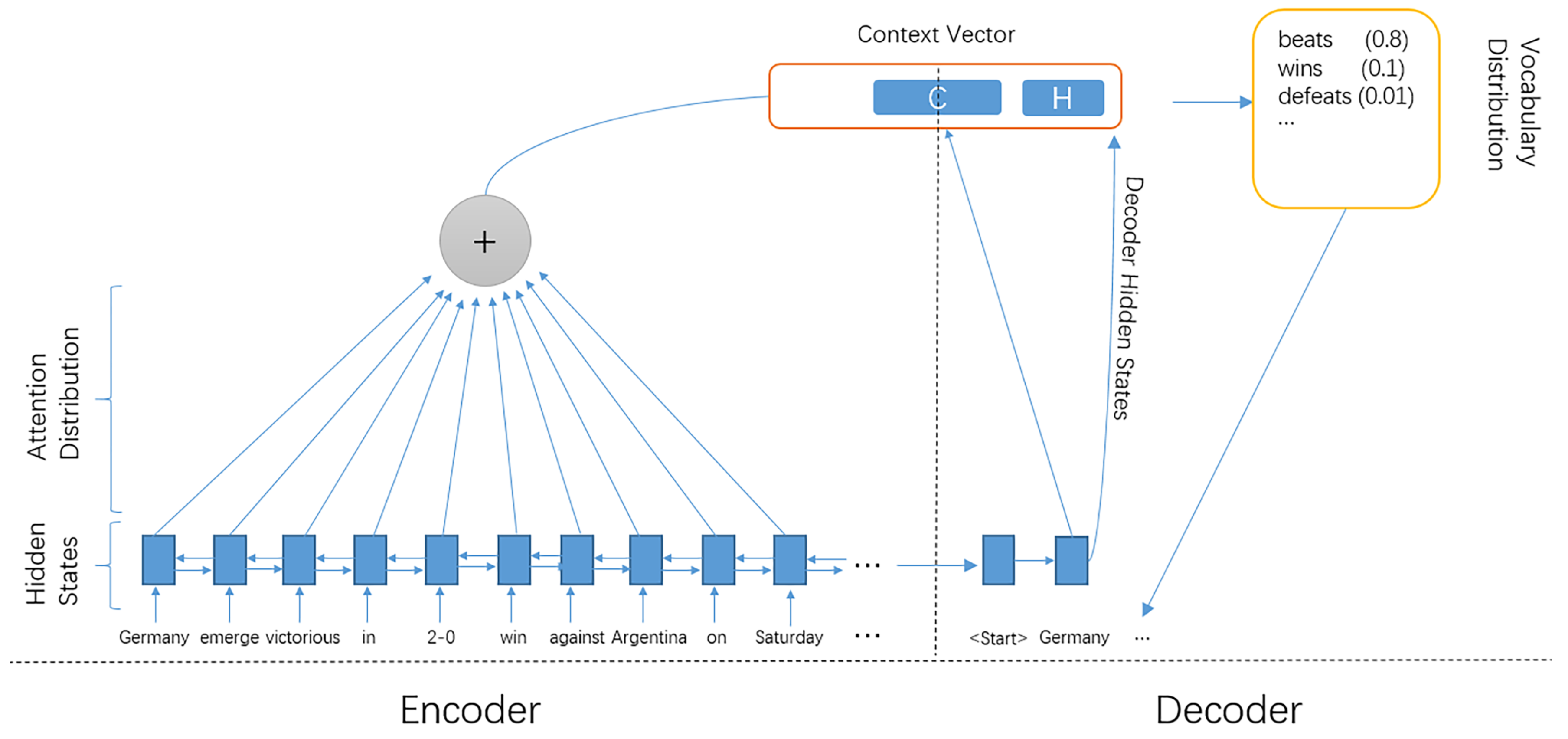
3.1. Structure of the Neural Network Model
3.2. Diversity-Promoting Beam Search Method
3.2.1. Decoding Problem
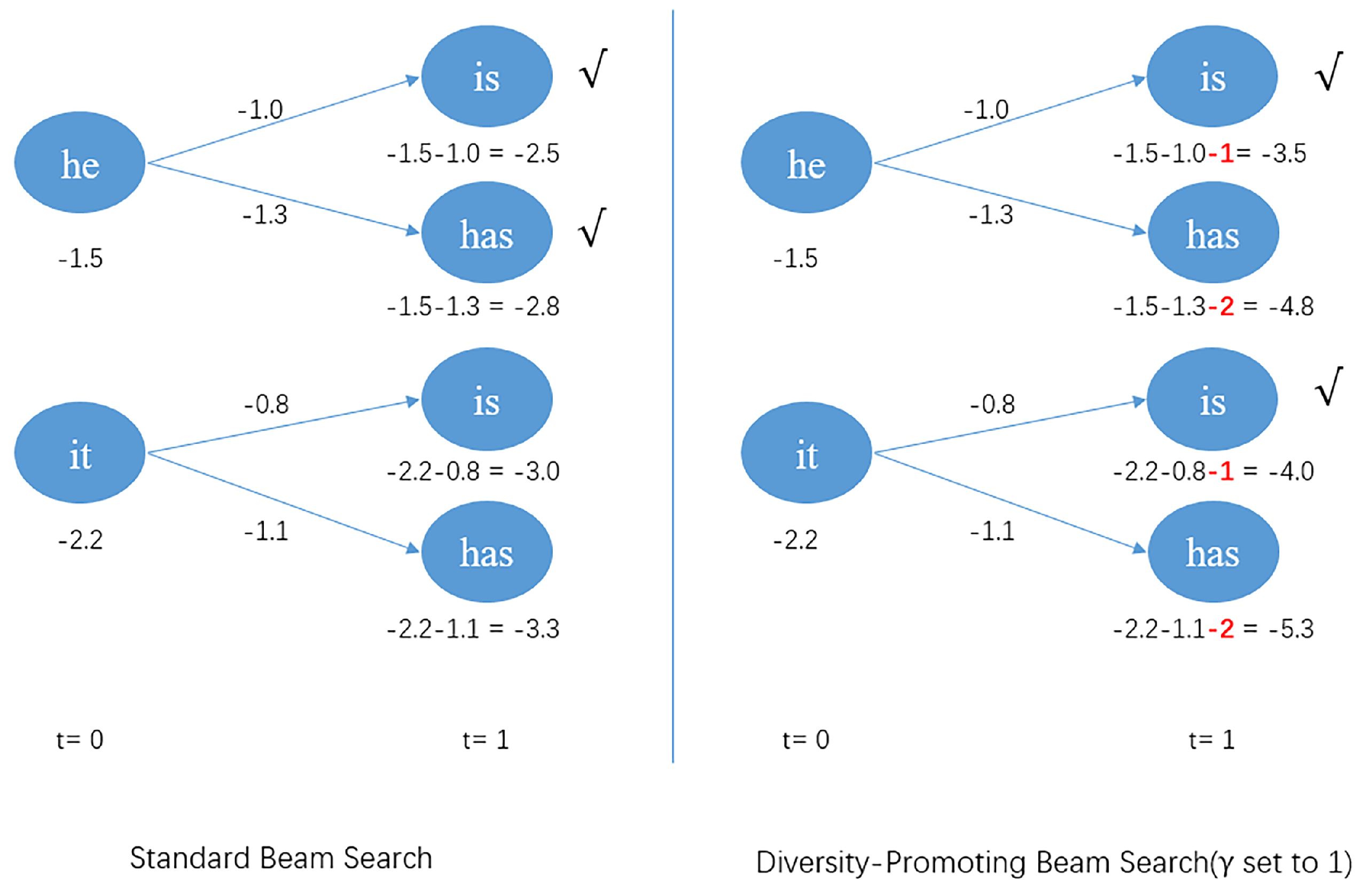
3.2.2. Standard Beam Search and Its Problem
3.2.3. Diversity-Promoting Beam Search
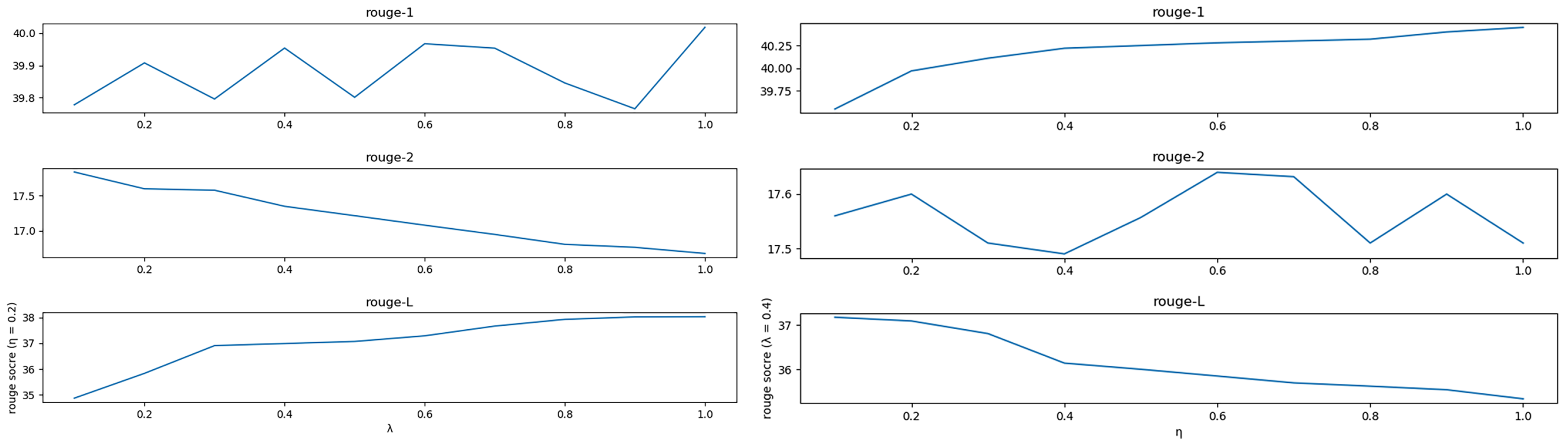
3.3. Optimal Sequence Selection Method
4. Experiment
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Implementation
4.1.3. Performance Measurement
4.1.4. Baseline Methods
4.2. Experiment Results
- Can the DPBS method effectively improve diversity?
- Can the optimal sequence-selection method locate the ideal sequences?
- Does the NASDD method achieve state-of-the-art performance on the abstractive summarization task?
4.2.1. DPBS Evaluation
4.2.2. Selection Method Evaluation
4.2.3. Overall Summarization Performance
5. Conclusions and Future Work
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Schwenk, H. Continuous space translation models for phrase-based statistical machine translation. In Proceedings of the COLING 2012: Posters, Mumbai, India, 8–15 December 2012; pp. 1071–1080. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv, 2014; arXiv:1409.0473. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- Chopra, S.; Auli, M.; Rush, A.M. Abstractive sentence summarization with attentive recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2016; pp. 93–98. [Google Scholar]
- Nallapati, R.; Zhou, B.; Santos, C.N.D.; Gulcehre, C.; Xiang, B. Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond. In Proceedings of the Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 280–290. [Google Scholar]
- Sankaran, B.; Mi, H.; Al-Onaizan, Y.; Ittycheriah, A. Temporal attention model for neural machine translation. arXiv, 2016; arXiv:1608.02927. [Google Scholar]
- Cao, Z.; Li, W.; Li, S.; Wei, F.; Li, Y. AttSum: Joint Learning of Focusing and Summarization with Neural Attention. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 547–556. [Google Scholar]
- Zeng, W.; Luo, W.; Fidler, S.; Urtasun, R. Efficient summarization with read-again and copy mechanism. arXiv, 2016; arXiv:1611.03382. [Google Scholar]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H. Distraction-based neural networks for modeling documents. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2754–2760. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Zhou, M. Selective Encoding for Abstractive Sentence Summarization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1095–1104. [Google Scholar]
- Nema, P.; Khapra, M.M.; Laha, A.; Ravindran, B. Diversity driven attention model for query-based abstractive summarization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1063–1072. [Google Scholar]
- Khan, A.; Salim, N.; Farman, H.; Khan, M.; Jan, B.; Ahmad, A.; Ahmed, I.; Paul, A. Abstractive Text Summarization based on Improved Semantic Graph Approach. Int. J. Parallel Programm. 2018, 46, 1–25. [Google Scholar] [CrossRef]
- Torres-Moreno, J.M. Automatic Text Summarization; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Tan, J.; Wan, X.; Xiao, J. Abstractive document summarization with a graph-based attentional neural model. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1171–1181. [Google Scholar]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Nenkova, A.; Vanderwende, L.; McKeown, K. A compositional context sensitive multi-document summarizer: exploring the factors that influence summarization. In Proceedings of the 29th Annual International ACM SIGIR Conference On Research and Development in Information Retrieval, Seattle, DC, USA, 6–11 August 2006; pp. 573–580. [Google Scholar]
- Mihalcea, R. Language independent extractive summarization. In Proceedings of the ACL 2005 on Interactive Poster and Demonstration Sessions, Ann Arbor, MI, USA, 25–30 June 2005; pp. 49–52. [Google Scholar]
- Gillick, D.; Favre, B. A scalable global model for summarization. In Proceedings of the Workshop on Integer Linear Programming for Natural Langauge Processing, Boulder, CO, USA, 4 June 2009; pp. 10–18. [Google Scholar]
- Shen, D.; Sun, J.T.; Li, H.; Yang, Q.; Chen, Z. Document Summarization Using Conditional Random Fields. In Proceedings of the IJCAI 2007, Hyderabad, India, 6–12 January 2007; pp. 2862–2867. [Google Scholar]
- Conroy, J.M.; O’leary, D.P. Text summarization via hidden markov models. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001; pp. 406–407. [Google Scholar]
- Knight, K.; Marcu, D. Summarization beyond sentence extraction: A probabilistic approach to sentence compression. Artif. Intell. 2002, 139, 91–107. [Google Scholar] [CrossRef] [Green Version]
- Clarke, J.; Lapata, M. Global inference for sentence compression: An integer linear programming approach. J. Artif. Intell. Res. 2008, 31, 399–429. [Google Scholar] [CrossRef]
- Banko, M.; Mittal, V.O.; Witbrock, M.J. Headline generation based on statistical translation. In Proceedings of the 38th Annual Meeting on Association for Computational Linguistics, Hong Kong, China, 3–6 October 2000; pp. 318–325. [Google Scholar]
- Kobayashi, H.; Noguchi, M.; Yatsuka, T. Summarization based on embedding distributions. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1984–1989. [Google Scholar]
- Yin, W.; Pei, Y. Optimizing Sentence Modeling and Selection for Document Summarization. In Proceedings of the IJCAI 2015, Buenos Aires, Argentina, 25–31 July 2015; pp. 1383–1389. [Google Scholar]
- Cao, Z.; Wei, F.; Dong, L.; Li, S.; Zhou, M. Ranking with Recursive Neural Networks and Its Application to Multi-Document Summarization; AAAI: Menlo Park, CA, USA, 2015; pp. 2153–2159. [Google Scholar]
- Cao, Z.; Wei, F.; Li, S.; Li, W.; Zhou, M.; Houfeng, W. Learning summary prior representation for extractive summarization. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 2, pp. 829–833. [Google Scholar]
- Cheng, J.; Lapata, M. Neural summarization by extracting sentences and words. arXiv, 2016; arXiv:1603.07252. [Google Scholar]
- Nallapati, R.; Zhai, F.; Zhou, B. SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documents; AAAI: Menlo Park, CA, USA, 2017; pp. 3075–3081. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O.K. Incorporating Copying Mechanism in Sequence-to-Sequence Learning. In Proceedings of the Meeting of the Association for Computational Linguistics, Toulouse, France, 6–11 July 2001; pp. 1631–1640. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2692–2700. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1693–1701. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A deep reinforced model for abstractive summarization. arXiv, 2017; arXiv:1705.04304. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get To The Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1073–1083. [Google Scholar]
- Gulcehre, C.; Ahn, S.; Nallapati, R.; Zhou, B.; Bengio, Y. Pointing the Unknown Words. In Proceedings of the Meeting of the Association for Computational Linguistics, Toulouse, France, 6–11 July 2001; pp. 140–149. [Google Scholar]
- Tu, Z.; Lu, Z.; Liu, Y.; Liu, X.; Li, H. Modeling Coverage for Neural Machine Translation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 76–85. [Google Scholar]
- Mi, H.; Sankaran, B.; Wang, Z.; Ittycheriah, A. Coverage Embedding Models for Neural Machine Translation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 955–960. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A Diversity-Promoting Objective Function for Neural Conversation Models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 110–119. [Google Scholar]
- Li, J.; Jurafsky, D. Mutual information and diverse decoding improve neural machine translation. arXiv, 2016; arXiv:1601.00372. [Google Scholar]
- Vijayakumar, A.K.; Cogswell, M.; Selvaraju, R.R.; Sun, Q.; Lee, S.; Crandall, D.; Batra, D. Diverse beam search: Decoding diverse solutions from neural sequence models. arXiv, 2016; arXiv:1610.02424. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Post Conference Workshop of ACL 2004, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Ranking Sentences for Extractive Summarization with Reinforcement Learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 1747–1759. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distinct-1 | Distinct-2 | Distinct-3 | |
|---|---|---|---|
| Standard Beam Search | 0.1714 | 0.3627 | 0.4344 |
| DPBS | 0.1953 | 0.4476 | 0.6389 |
| Rouge | |||
|---|---|---|---|
| 1 | 2 | L | |
| lead-3 | 40.34 | 17.70 | 36.57 |
| REFRESH | 40.0 | 18.2 | 36.6 |
| SummaRuNNer | 39.6 | 16.2 | 35.3 |
| Graph-Abs | 38.1 | 13.9 | 34.0 |
| PGN | 38.15 | 16.46 | 35.37 |
| NASDD (w/o selection) | 39.03 | 16.02 | 35.71 |
| NASDD | 39.97 | 17.58 | 37.91 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, X.-W.; Zheng, H.-T.; Chen, J.-Y.; Zhao, C.-Z. Diverse Decoding for Abstractive Document Summarization. Appl. Sci. 2019, 9, 386. https://doi.org/10.3390/app9030386
Han X-W, Zheng H-T, Chen J-Y, Zhao C-Z. Diverse Decoding for Abstractive Document Summarization. Applied Sciences. 2019; 9(3):386. https://doi.org/10.3390/app9030386
Chicago/Turabian StyleHan, Xu-Wang, Hai-Tao Zheng, Jin-Yuan Chen, and Cong-Zhi Zhao. 2019. "Diverse Decoding for Abstractive Document Summarization" Applied Sciences 9, no. 3: 386. https://doi.org/10.3390/app9030386
APA StyleHan, X. -W., Zheng, H. -T., Chen, J. -Y., & Zhao, C. -Z. (2019). Diverse Decoding for Abstractive Document Summarization. Applied Sciences, 9(3), 386. https://doi.org/10.3390/app9030386