Logic-in-Memory Computation: Is It Worth It? A Binary Neural Network Case Study



Abstract
:1. Introduction
- Realization of a reconfigurable OOM architecture implementing the XNOR-Net model and proposal of a possible design approach for a LiM alternative.
- Identification of strong and weak points of a LiM solution with many NN models of different sizes and complexities.
- Detailed performance evaluations with 45 nm @ 1.1 V CMOS technology. The estimations are performed with a synthesis and .vcd-based post place and route simulations for two models: a CNN and an MLP network respectively. The tools involved in this step are Synopsys Design Compiler for the synthesis, Mentor Modelsim for the simulation and Cadence Innovus for the place and route phase.
- Generalized performance estimations for both architectures by means of parametric sweeps obtained from several synthesis processes with 45 nm @ 1.1 V technology. The aim is to compare the implementations with several different parameters and to identify the main differences. Discussion of the obtained results are provided and a qualitative comparison between the implementations are reported in Section 6.3.1.
- A state-of-the-art comparison between our LiM and the Content addressable memory based implementation proposed in [8]. In our designs, memories are implemented as register files and each memory cell is a flip flop, since we didn’t have the possibility to implement a custom memory. Consequently, the performance values obtained represent an overestimation of a real case. To determine how a real memory model impacts the results obtained, parameters from [8] are taken into account. Reference [8] implements a XNOR-Net LiM design with 65 nm CMOS technology, so in our synthesis procedure we used CMOS 65 nm technology @ 1.0 V to have a fair comparison.
- Conclusions and discussions for future work.
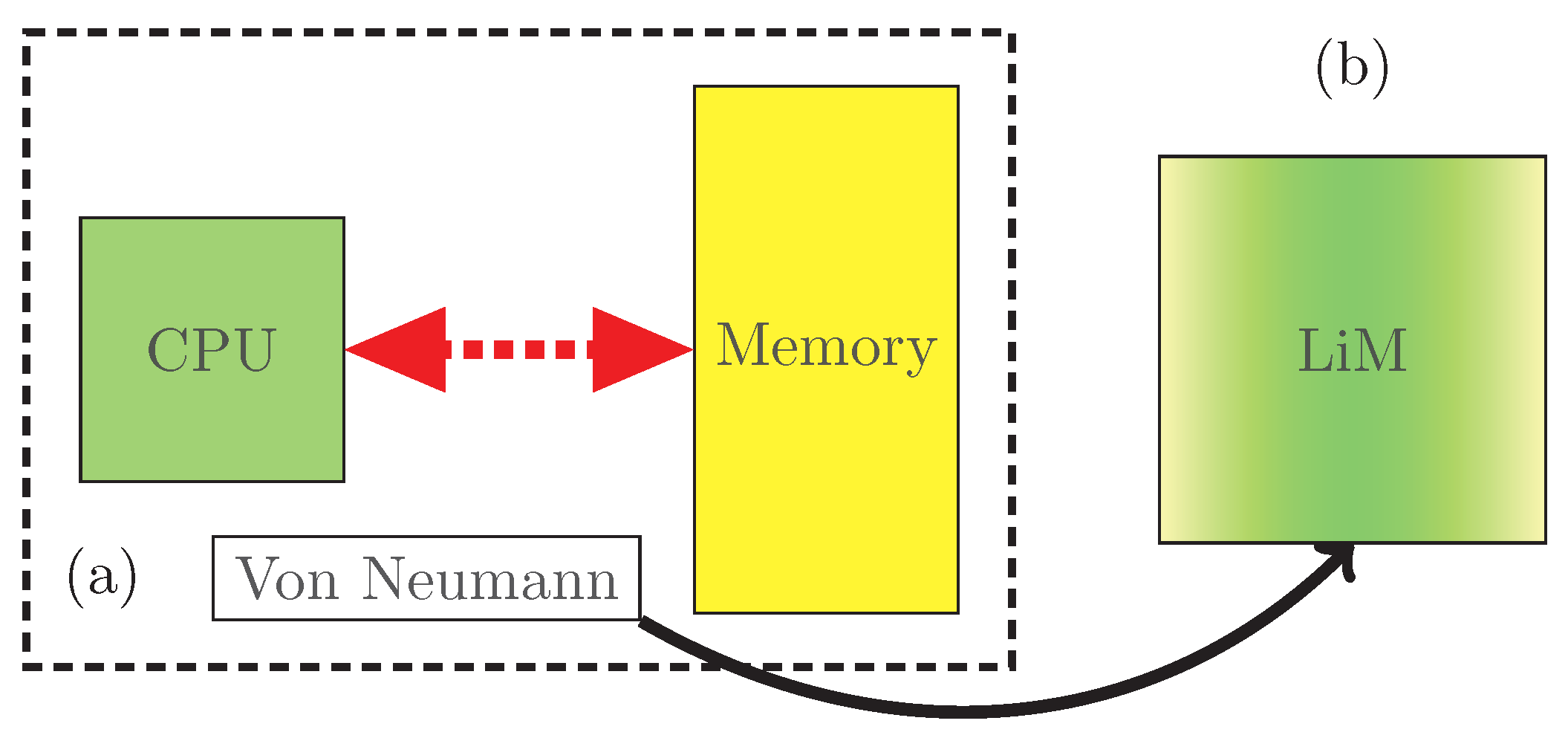
2. LiM Background
A Quick Overview
- Computation near Memory [9] where part of the computing blocks are moved in the memory proximity proposing solutions such as WIDE-IO2, which is a 3D stacked DRAM memory [10] with a logical layer placed at the bottom of the stack. Data are moved from the DRAM layers to the logical one employing Through-Silicon Vias (TSVs) and the result is then written back to one of the available DRAM layers. 3D stacked DRAM combined with TSVs allow to shorten the paths’ lengths that data have to travel to reach the computational core, reducing the Von Neumann bottlenecks and improving efficiency.
- Computation in Memory [9] paradigm is used in solutions with resistive arrays, based on technologies such as Magnetic Tunnel Junction (MTJ) devices [11]. MTJ is a component that can have two discrete resistance values, according to the direction of the magnetizations of its ferromagnets: if they are parallel, the MTJ is in low resistance state () meaning more current flowing through it, otherwise, they are in antiparallel configuration () with highest resistance. These resistance states can be mapped in a logic fashion as logic ‘0’ if they are antiparallel, logic ‘1’ otherwise. By arranging multiple MTJs in a matrix configuration, both memory and logic operations can be performed analogically. Several works use MTJ devices. In [12], Generative Adversarial Network (GAN) implementation has been proposed. This Neural Network consists of a discriminator (D), that works as a detective in the training process, and a generator (G) as a deceiver in a semi-supervised fashion. In these networks, training is a critical issue so hardware accelerators are demanded. Reference [12] improves the so-called adversarial training process by using an array made of MTJs which simplifies the calculation of multiply-accumulate operations with ternary weights (), transforming them into bulk In-Memory additions and subtractions. This work achieves remarkable results in term of efficiency and processing speed with respect to GPUs and ASICs. In [13], authors have developed a MTJ-based convolution accelerator in which the memory array is capable of performing bulk AND operations. They have included a small external logic which is in charge of computing the accumulations. Based on a similar working principle, Resistive Random-Access-Memory (RRAM) [14] are devices in which the logic data is encoded in two or multiple resistive states. Differently from MTJs, resistance is determined by the conductivity of a conduction path that can be broken (high resistance state) or reformed (low resistance state). Sometimes it is used in a 1 transistor 1 RRAM (1T1R) configuration, to avoid unwanted or sneak current paths. In [15], authors have presented a memristor-based implementation of a BNN able to achieve both high accuracy on MNIST and IRIS dataset and low power consumption. In some others, improvements in memristor architectures have been proposed that enable multiple bits per cell. Reference [16] has exploited the frequency dependence of GeSeSn-W memristor devices to obtain multiple conductance values representing different weights. In [17], the memory array has been modified, including up to 4 memristors arranged in parallel in the same cell, in order to have multiple resistance values and so higher precision weights. Based on a similar approach to [12], a GAN training accelerator has been discussed in [18] which is able to efficiently perform approximated add/sub operations in a memristor array, achieving both speed-up and high energy efficiency.
- Computation with Memory [9] concept consists of memory arrays that intrinsically perform calculations. Possible examples can be Content Addressable Memories (CAM) and Look-up tables.
- Logic-in-Memory [9] is the concept that we are analyzing in this work, in which small computational units are placed inside or near a memory cell, to perform distributed computation.
3. Neural Networks: An Introduction
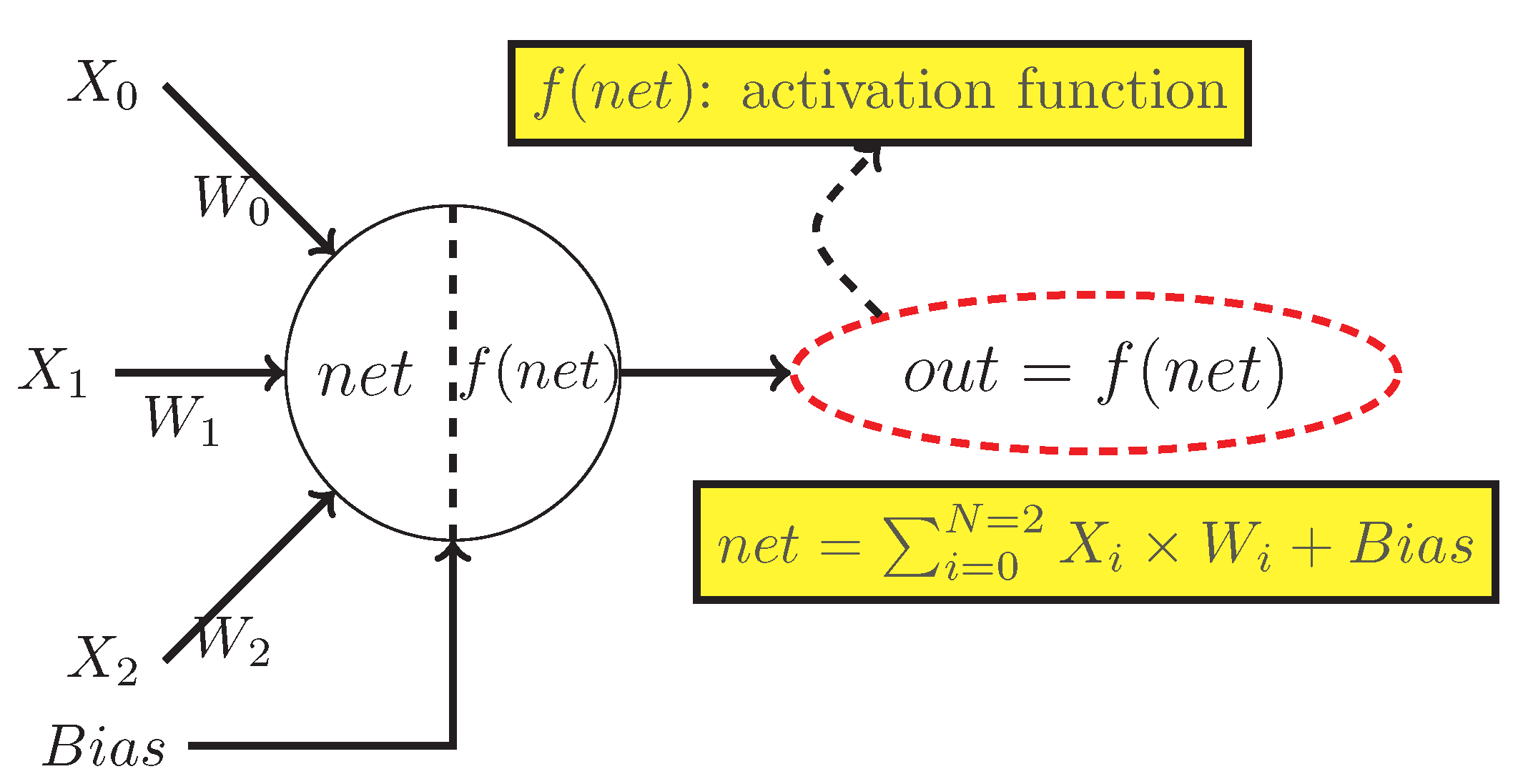
3.1. Neuron’s Model
3.2. Neural Network’s Structure
- Convolutional layers perform the convolution operation of the input feature map (IFMAP) with a set of weights called kernel. An example of a convolution computation is depicted in Figure 4. The parameter taken into account are the kernel’s weights, the input feature map and the stride. After the first convolution is finished, the kernel window is moved by a step equal to stride, and a new convolution can start. In this example, the convolution computation match perfectly the neuron’s equation reported in Equation (1), in fact after a convolutional layer is usually used an activation function to normalize the results. In the LeNet 5 CNN [1] example in Figure 3, all the convolutional layers have the same kernel sizes. The first one produces six output feature maps (OFMAPs), meaning that the same IFMAP has been convolved with six different kernels. The second convolutional layer instead produces 16 OFMAPs, starting from 6 IFMAPs: for each input, there are 16 kernels that produce 16 outputs, so 16 from the first IFMAP, 16 for the second IFMAP and so on. This implies a total number of OFMAPs equals toTo obtain 16 OFMAPs indicated by LeNet 5 scheme, the obtained OFMAPs of each layer are added together.These considerations bring to the following formula for a convolutional layer, derived from [21]:where are the indexes for the OFMAP corresponding pixel, is the input channel index, the total number of input channels, are the kernel’s matrix size indicating number of rows and columns respectively, o subscript refers to the OFMAP considered and are the kernel’s indexes.
- Pooling layers have a similar behavior to convolutional layers. In the literature, different kind of poolings are used such as average or max pooling [22]. They perform the maximum (or the average) of the selected input pixels and returns only one value, performing the so-called subsampling operation. Pooling, and more specifically max pooling, is widely used to reduce the size and the complexity of the CNN. In Figure 3, the kernel size is for all the cases.
- FC layers are MLP subnetworks included in the CNN to perform the classification operation. They are made of layers of fully interconnected neurons, as shown in Figure 3.
3.3. Binary Approximation
- BWN [7] binarizes only weights of the NN, keeping at full precision the activations and the inputs. By binarizing only weights, the convolution operation can be performed only with adds and subtractions, avoiding multiplication as reported in Equation (6) [7].An extra factor is multiplied to the convolution result, in order to compensate precision losses [7]:where is the considered full precision weight and N is the number of weights. BWN is a very good alternative useful to reduce CNN’s complexity. However it requires full precision inputs and activations.
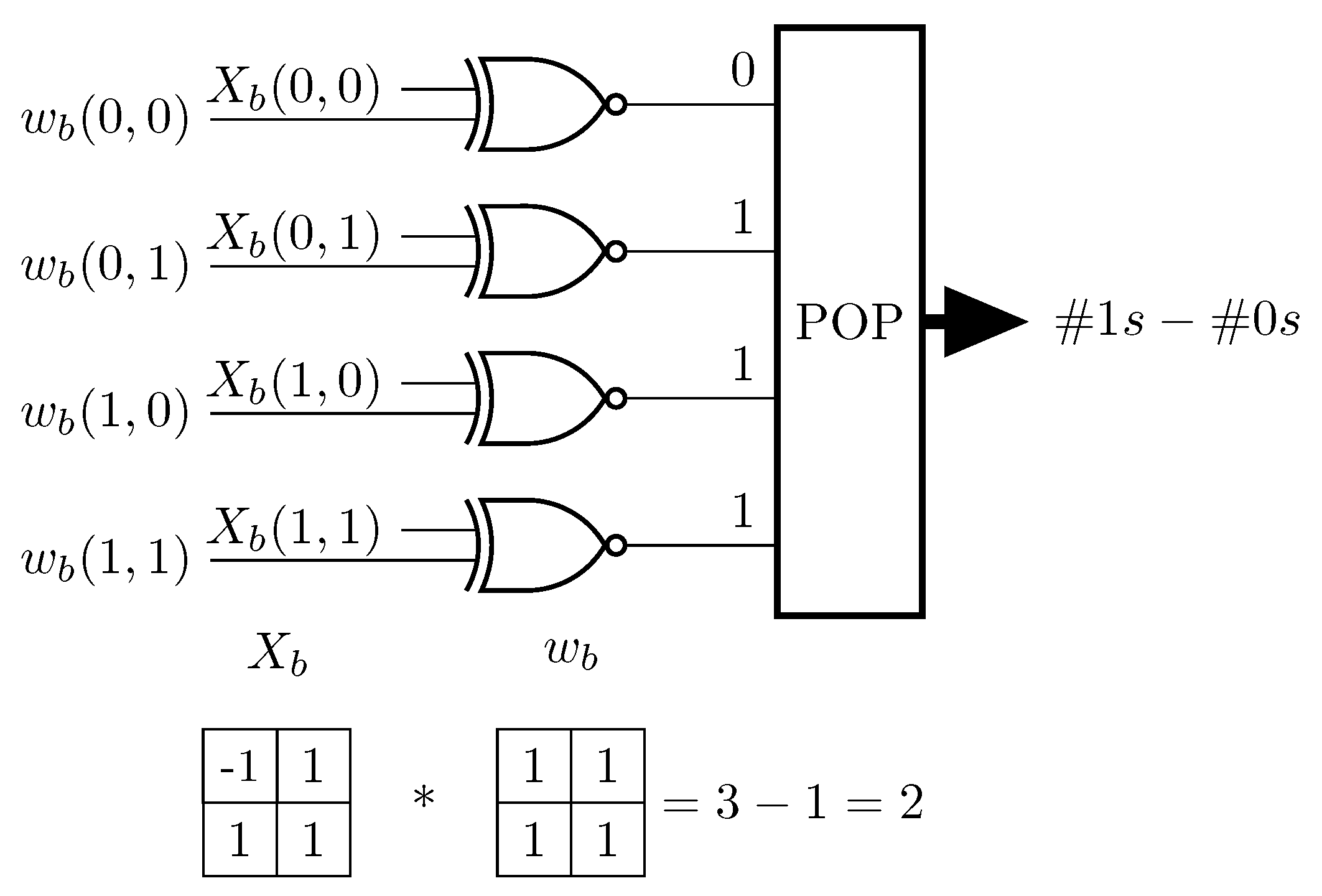
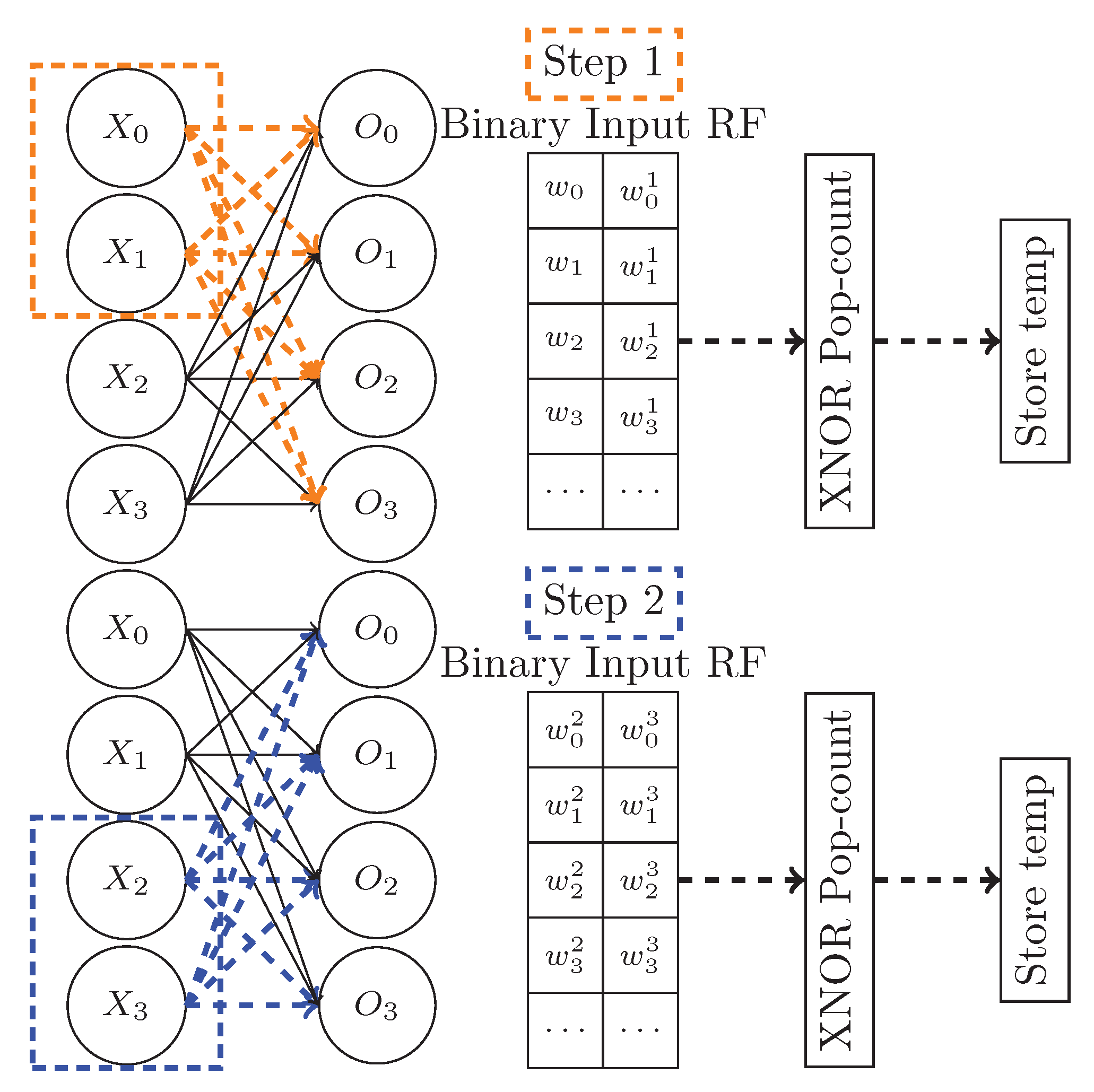
- XNOR-Net [7] binarizes both weights and inputs. The convolution result is obtained by performing the binary convolution and multiplying by a correction factor (the same in Equation (7)) and a matrix K. K is defined in Equation (8).In Equation (8), the first term indicates the absolute punctual sum of the multiple IFMAPs divided by the number of input channels, thus the number of IFMAPs. The second term is a regular matrix of size, which contains in all positions. Finally, the XNOR-Net convolution can be rewritten as [7]:where is the binarized input, ⊛ is the binary convolution, is punctual multiplication and × is a simple product. In [7] the binary convolution is performed considering the XNOR pop-counting of binary inputs/weights. XNOR truth table matches to the multiplication if −1 is mapped to logic ‘0’ and +1 is logic ‘1’. Pop-counting computes the difference between the number of 1s and the number of 0s of the input sample.
- BC [6] binarizes both inputs and weights, without applying any correction factor to the final convolutional equation. This implies less recognition accuracy as shown in Figure 5. Taking into account all the considerations on the binarization techniques, we chose XNOR-Net [7] as reference model since it represents a very good trade-off between accuracy and complexity.
3.4. NN Implementations Based on LiM Concept
4. OOM and LiM Architectures
- Design of a classical architecture, called OOM, capable of implementing the XNOR-Net model;
- Derive a LiM alternative, defining what are the building blocks inside a memory cell;
- Qualitative comparison of the architectures, describing the advantages and disadvantages of both of them;
- Performance estimation and comparison by means of synthesis and place and route procedures of two NN models;
- Performance estimation of different NN models.
4.1. OOM Architecture Design
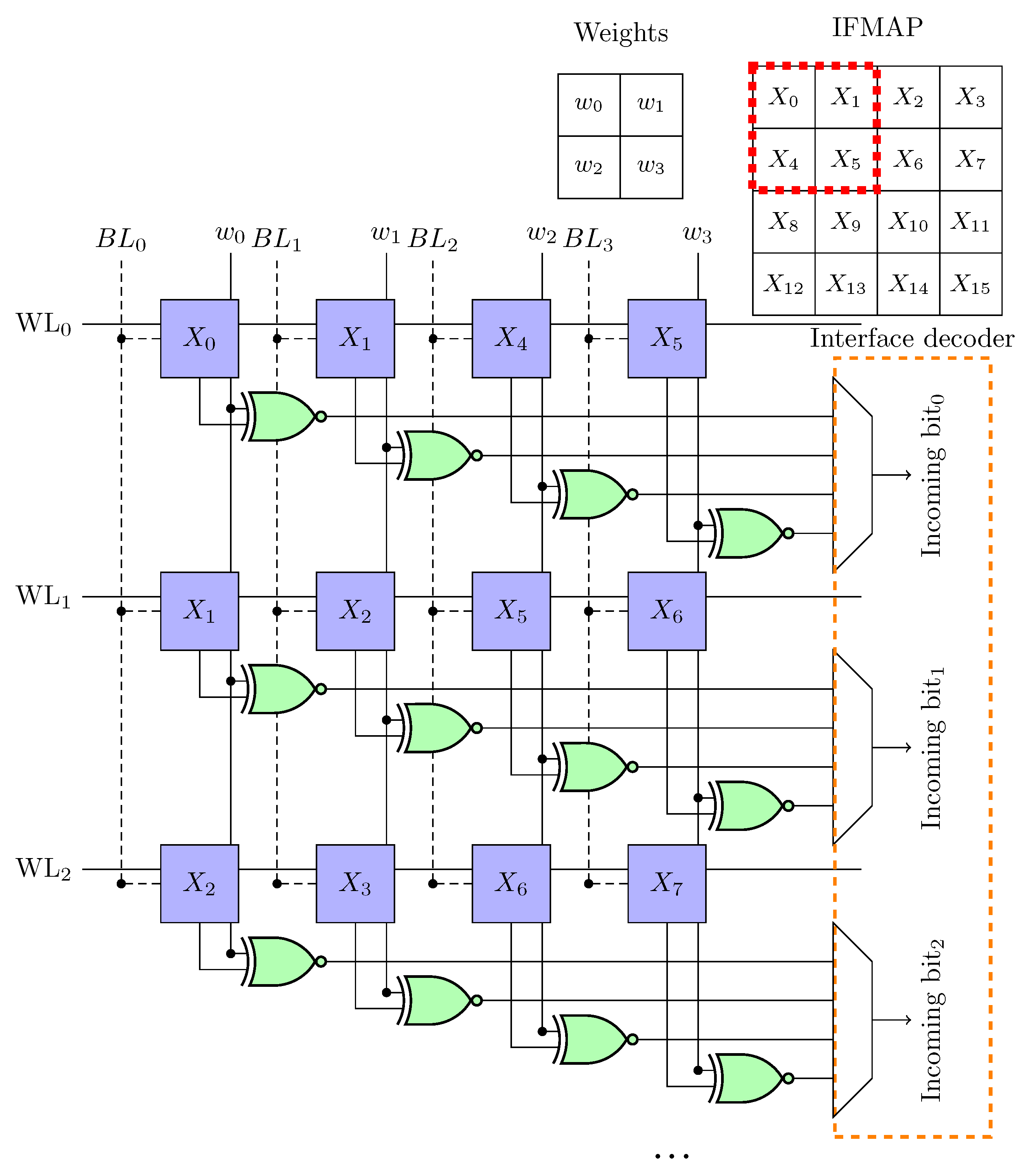
4.1.1. Single Input/Multiple Output Channels Design
4.1.2. Multiple Input Channels Design
4.1.3. FC Layer Integration
4.1.4. OOM Convolution-FC Unit
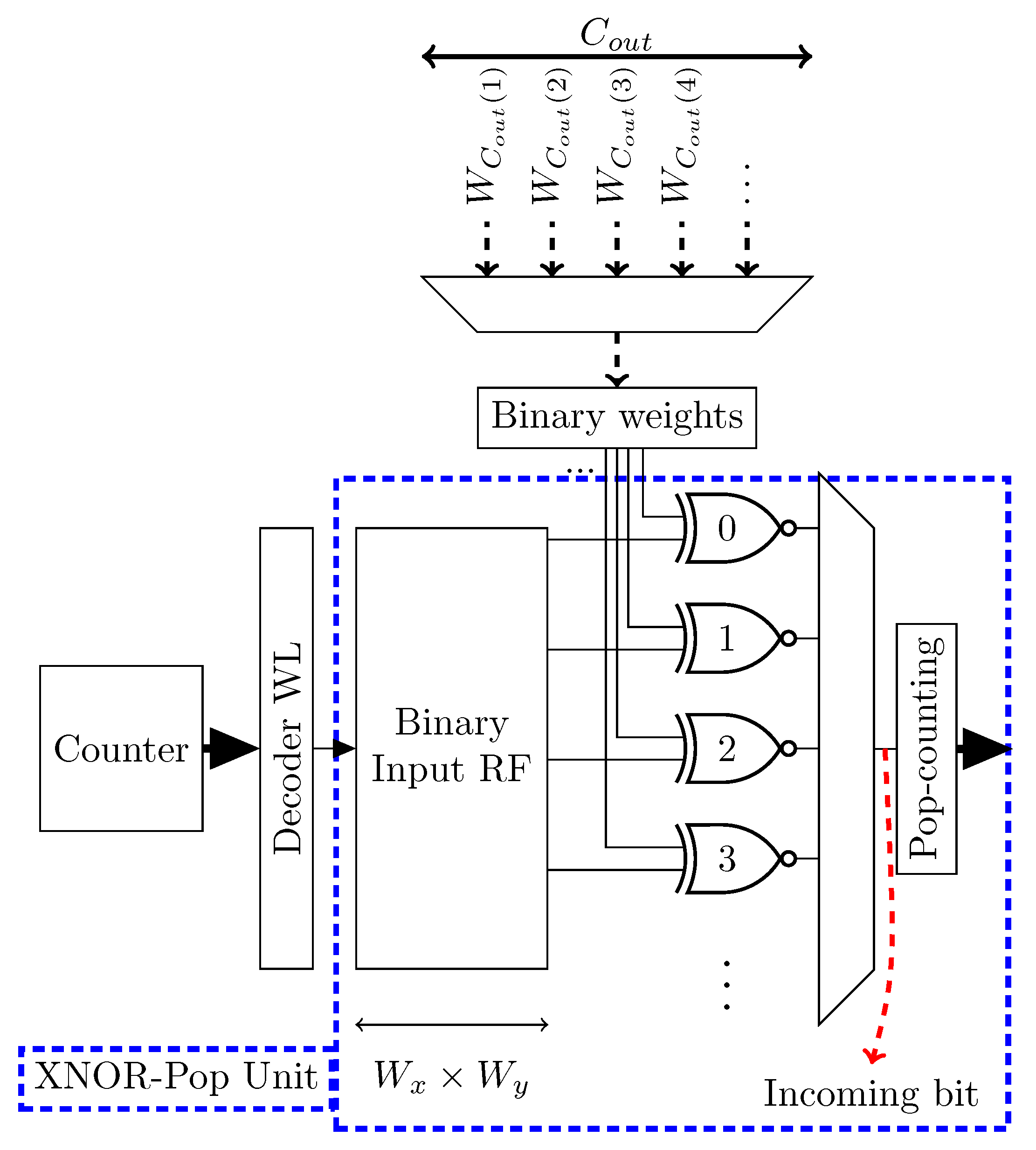
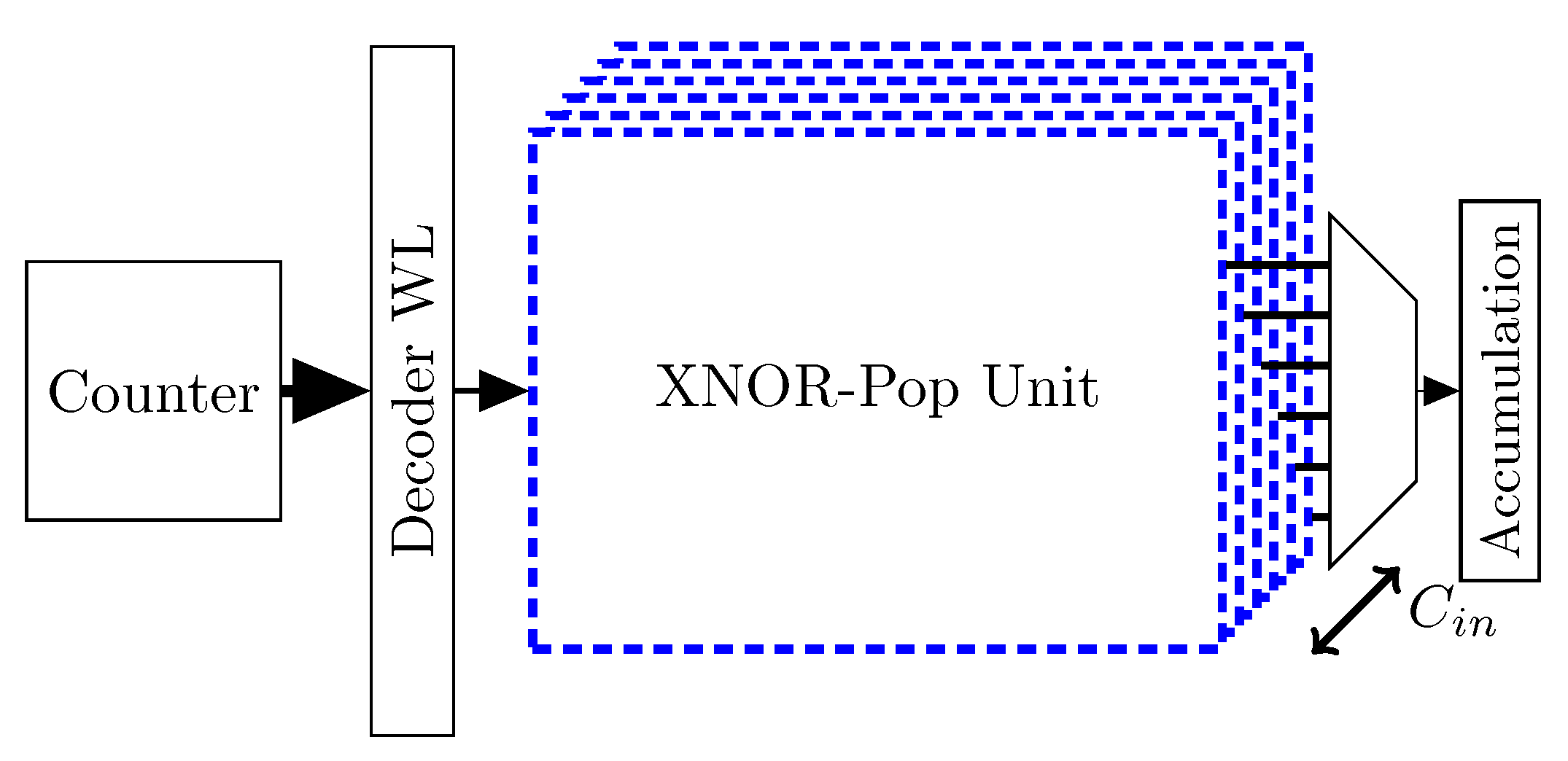
- XNOR-Pop Unit is the block described before, which takes Binarized weights/inputs and computes the resulting binary convolution;
- Store temp is a register file that holds the partial FC values, resulting from the scheduling described in Section 4.1.3. As the XNOR-Pop Unit’s Binary Input RF, which is depicted in Figure 7, it is addressed by the same counter, since only one neuron is processed per time. Only the output coming from the first XNOR-Pop Unit is taken, because FC requires only one input channel to be executed;
- K and units are in charge of computing K and values, as required by XNOR-Net convolution approximation expressed in Equation (9). Since K are matricial values, a register file has been inserted in the design to hold them;
- Convolution Computation Unit (CCU) performs the final calculation to provide the convolutional result, which is the formula reported in Equation (9). Moreover, it applies BatchNorm, if required by the algorithm: its coefficients are computed offline and provided by the external testbench.
4.2. LiM Architecture
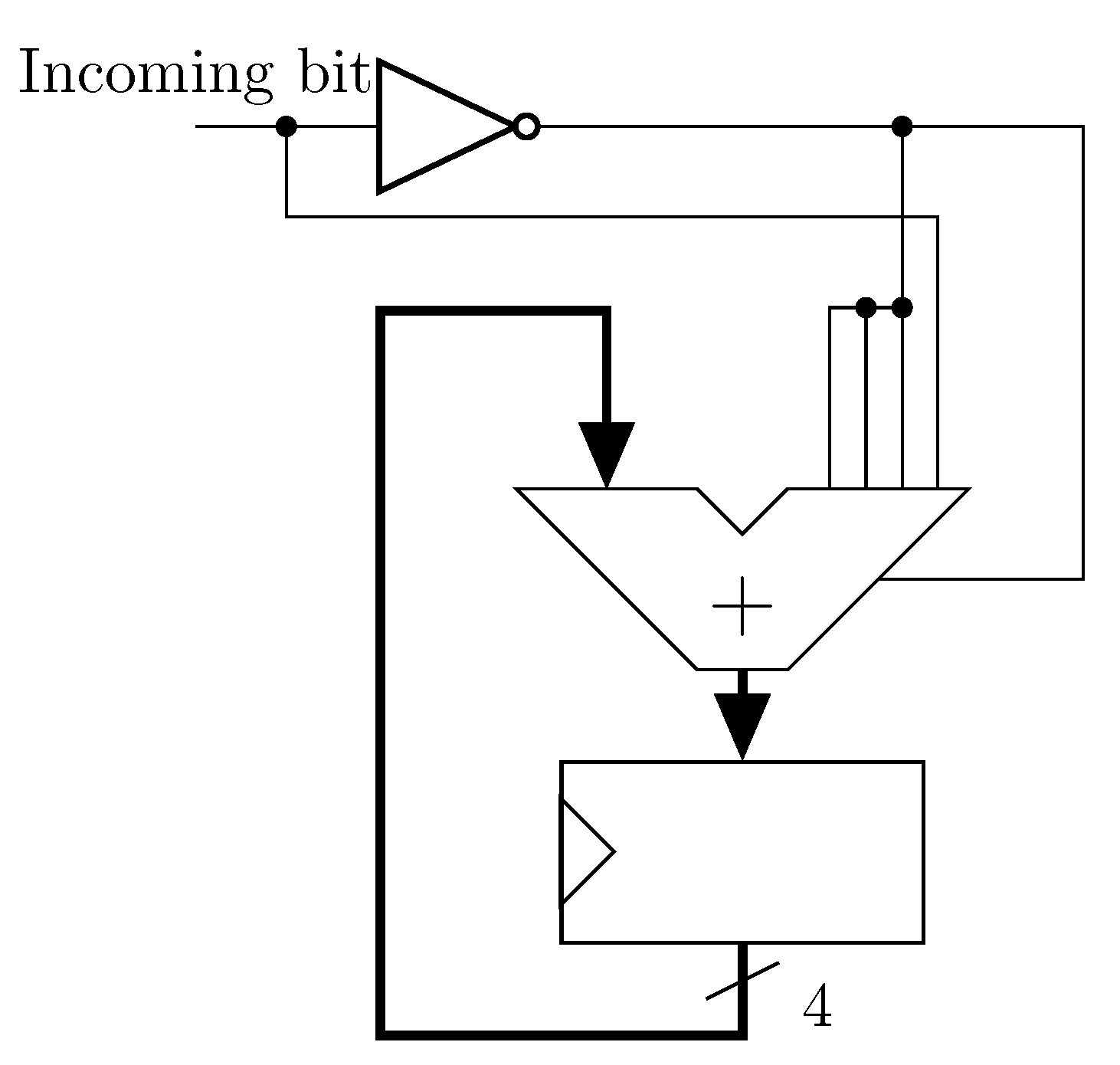
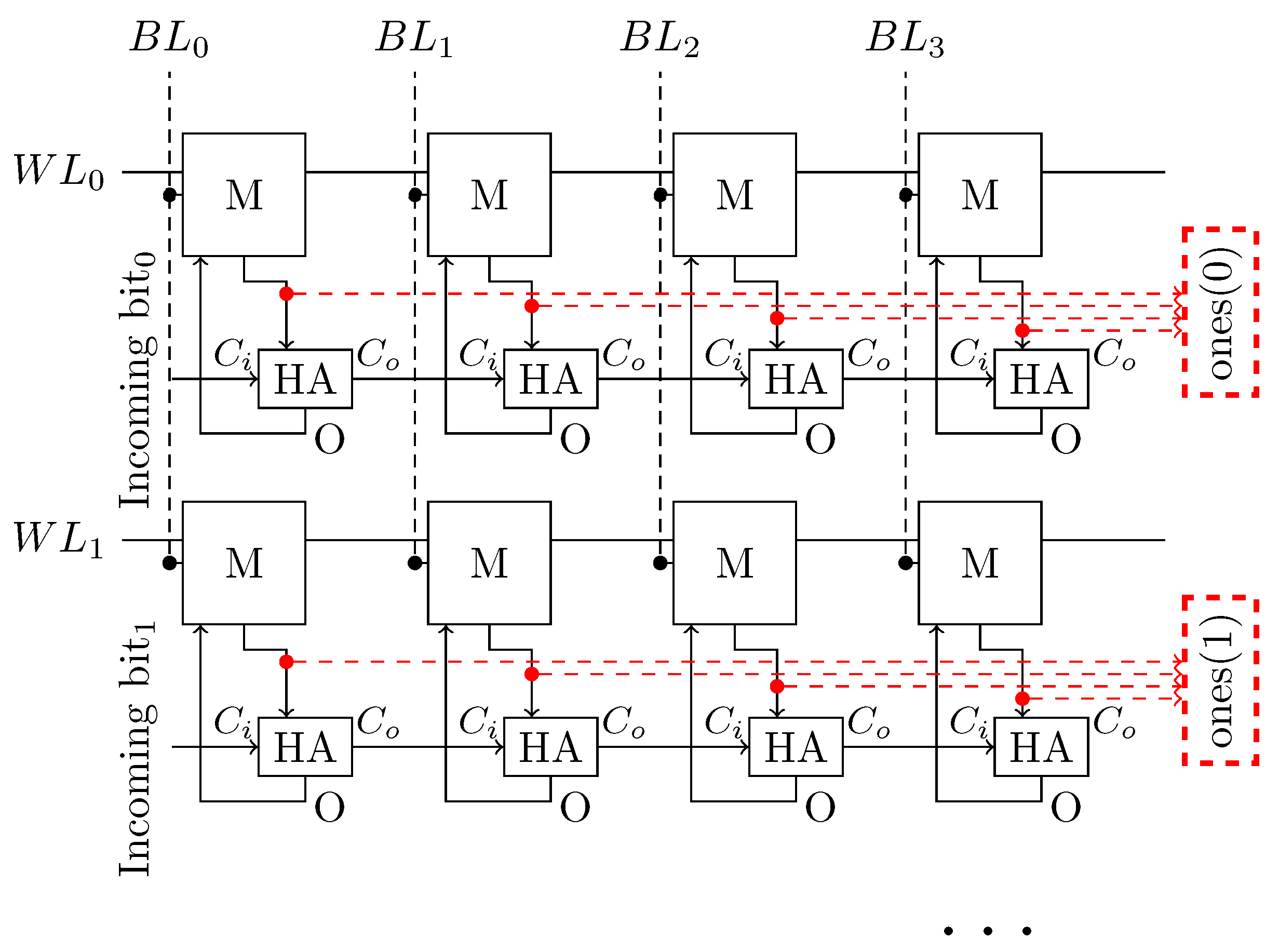
4.2.1. XNOR-Pop LiM Unit
4.2.2. LiM convolution-FC Unit
4.3. Top-Level Entity
5. Qualitative Comparison OOM-LiM Architectures
5.1. OOM Execution Time
5.1.1. Pooling Layer
5.1.2. Convolutional Layer
5.1.3. FC Layer
5.2. LiM Execution Time
5.2.1. Convolutional Layer
5.2.2. FC Layer
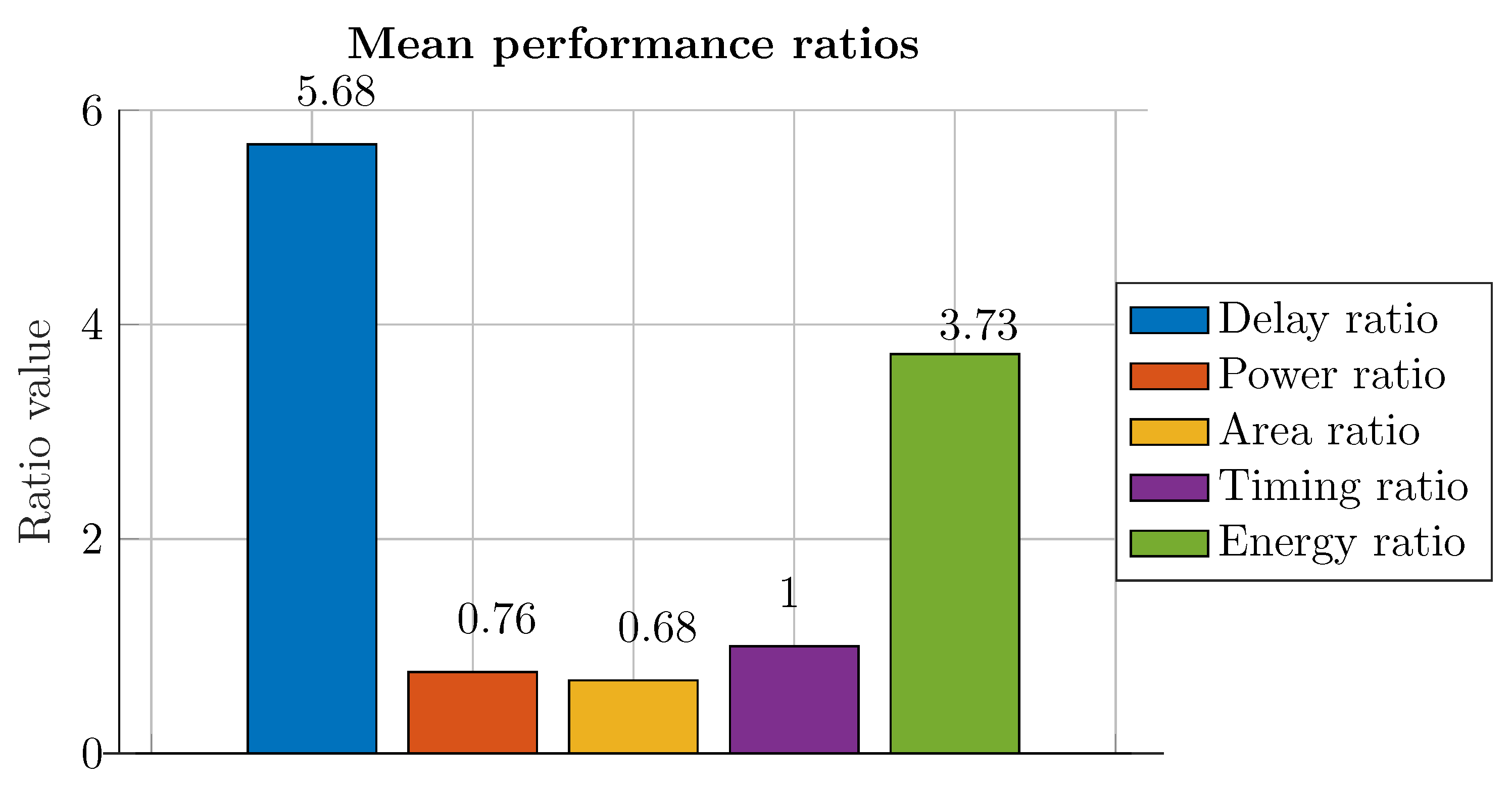
5.3. Comparison Results
- Delay ratio vs #Cin & Wx: the Delay ratio with respect to has a decreasing trend because, as shown in Figure 15, the Interface Decoder, the multiplexers placed after the LiM ones counter and the serial accumulation of the values of each channel represent a bottleneck for LiM architecture. As a result a higher execution time for higher values of is observed. In general, for high values of , the Delay ratio increases, because of the parallelization in LiM architecture.
- Delay ratio vs #Cin & #Cout: the trend for is the same as the previous case. For high values of , we can expect a very good Delay ratio efficiency, because LiM already has the values stored inside the array and it is sufficient to change the weights set by simply selecting it, following the same principle of the OOM case depicted in Figure 7.
- Delay ratio vs Wx & #Cout: in general, by increasing both and we have a higher Delay ratio. By looking to X-Z plane, it is possible to see that for higher the curve becomes steeper. It is a very good trend for very deep NNs, because usually output channels and filter sizes are high.
- Delay ratio vs Din & #Cin: is the IFMAP size, which indirectly determines the OFMAP size as reported in Equation (10). High values of imply much more complex NN but the Delay ratio remains almost constant, showing that LiM architecture latency is not degraded by the IFMAP’s complexity.
- Delay ratio vs Dout(FC) & niter: this last plot set reports an FC layer estimation. In this case the formula for the FC execution time of OOM and LiM is considered. As it can be seen, a higher could be beneficial for a LiM architecture, which has a small increasing trend, because the LiM array performs all the computations in parallel, so there is no need to fetch each data from the memory, compute the result and store inside the Store temp register file as in the OOM case. The predominant variable is , because by looking at Figure 7, the OOM architecture has the important drawback that everytime an FC step terminates, the entire Binary Input RF has to be scanned to perform the FC computation, requiring clock cycles. If the number of output neurons is huge (), becomes very large compared to the LiM case.
6. Perfomance Evaluation
- For both OOM and LiM implementations, two NN models were chosen and used as cases of study. These models were implemented, trained and validated by Keras framework [32] and a Matlab script respectively. Then, the architectures were synthesized with Synopsys Design Compiler with 45 nm CMOS technology @ 1.1 V, providing the values of power, area, Critical Path Delay (CPD), execution time and energy consumption. Regarding the power consumption, two kind of estimations are provided: the first is very straight forward and consists of a report power from Synopsys with worst case scenario of switching activity equals to 1 in all the nodes. The second, a post place&route power estimation with Cadence Innovus, using backannotation with .vcd file provided by Modelsim, in order to evaluate the effect of both switching activity and interconnections.
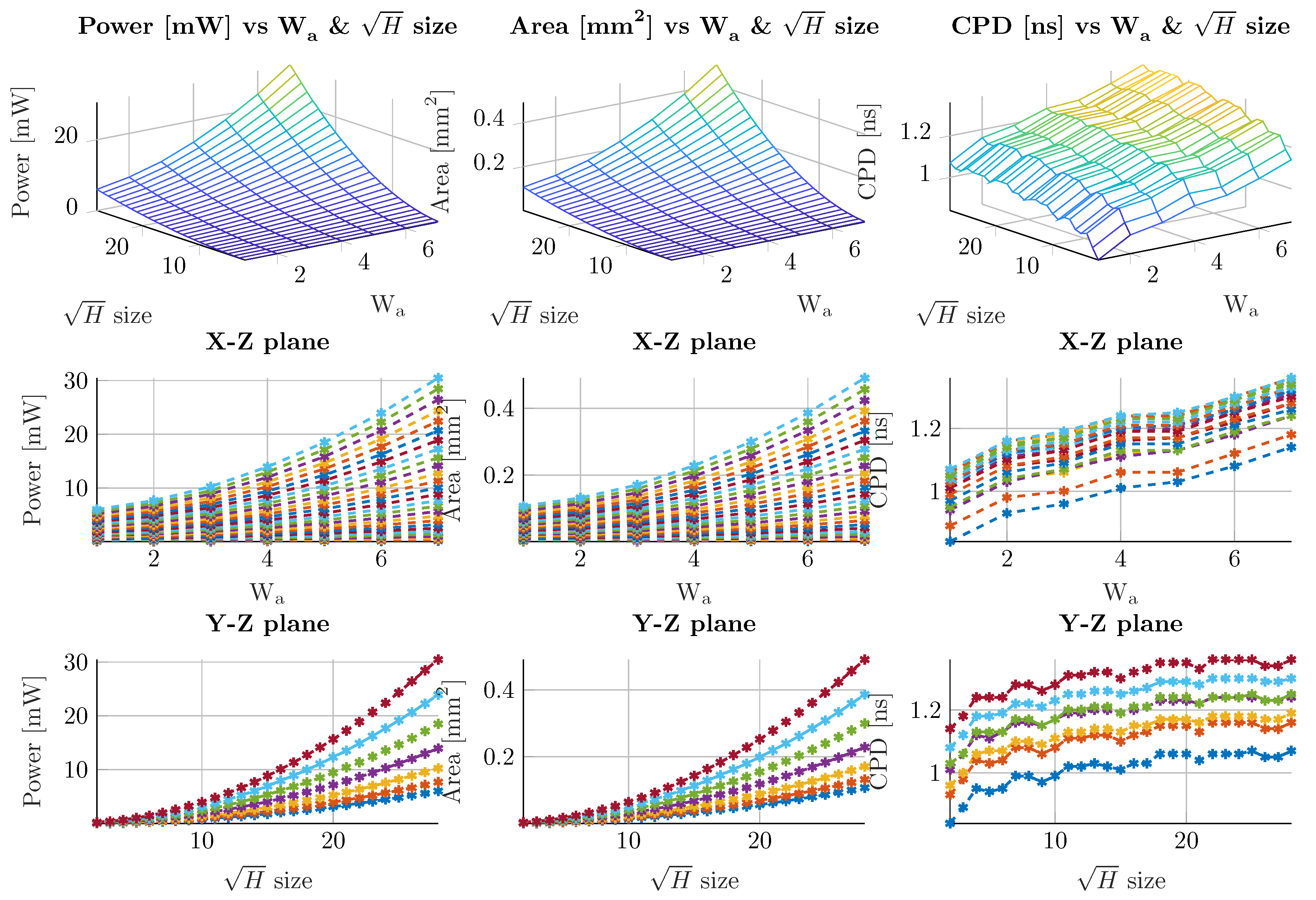
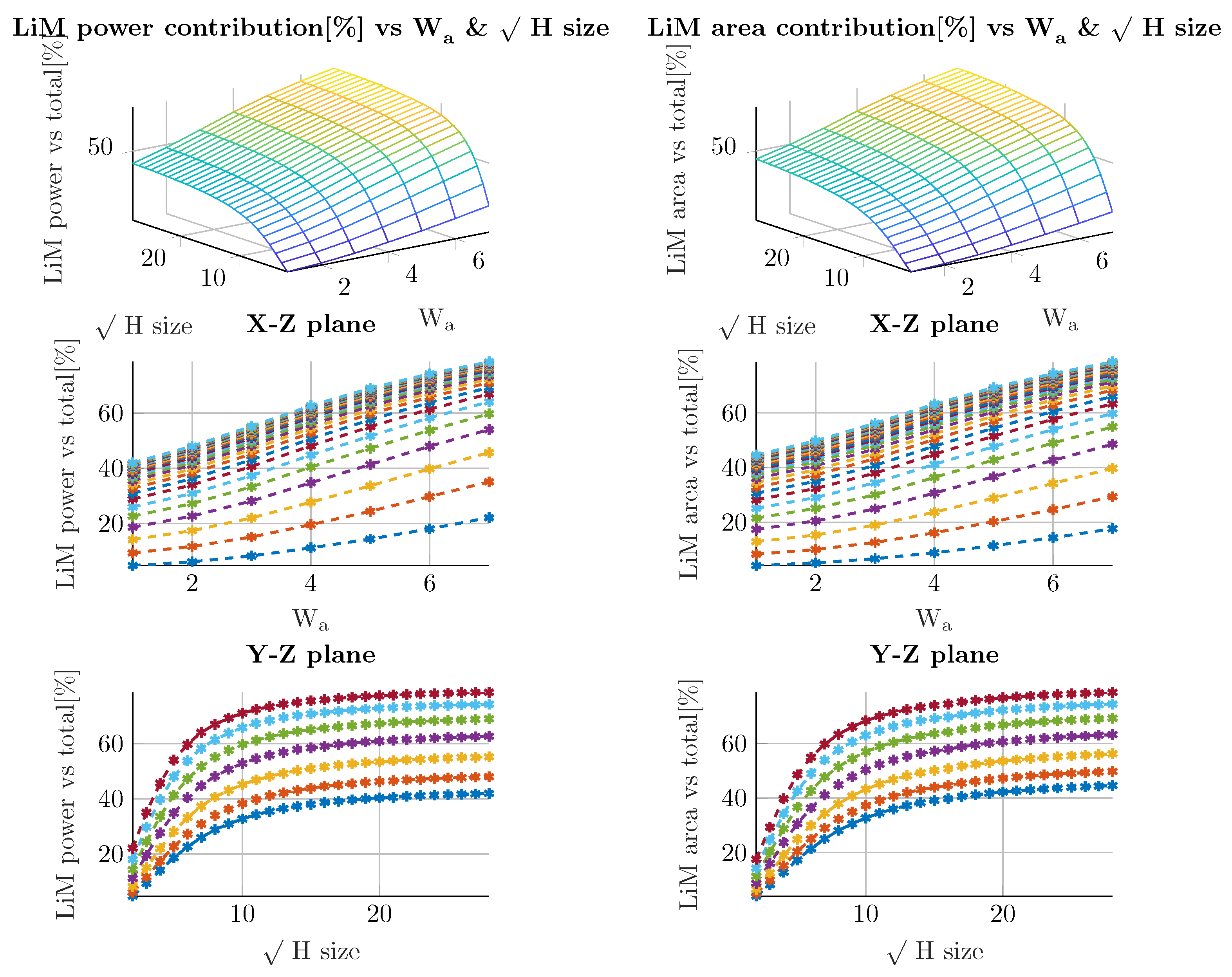
- Parametric sweeps are performed in order to evaluate the trend of the performance parameters in different cases. Power, Area, CPD and Energy ratios are computed between the OOM and LiM values, that are particularly useful to determine the main contributions of both architectures. To perform such procedure, a series of scripts are used to perform several synthesis processes with Synopsys Design Compiler and, everytime a synthesis ends, the performance values are stored in external files. Also in this case, the technology used is 45 nm CMOS @ 1.1 V.
- An analysis of the differences between our LiM, where memory elements are flip flops, and a LiM circuit with a custom memory is performed. In [8], a very similar XNOR-Net implementation has been implemented with a CAM memory-based XNOR-Pop procedure. Some useful results are provided, since authors have implemented a modified memory array with 65 nm CMOS technology. For this reason, a synthesis with 65 nm CMOS technology @ 1.0 V is performed, trying to use the same metrics as [8] to evaluate how a more real memory model can influence the results obtained.
6.1. Two NN Models Examined
6.1.1. Fashion-MNIST CNN Results
6.2. MNIST-MLP Network
6.3. Parametric Sweeps
6.3.1. Qualitative Estimation
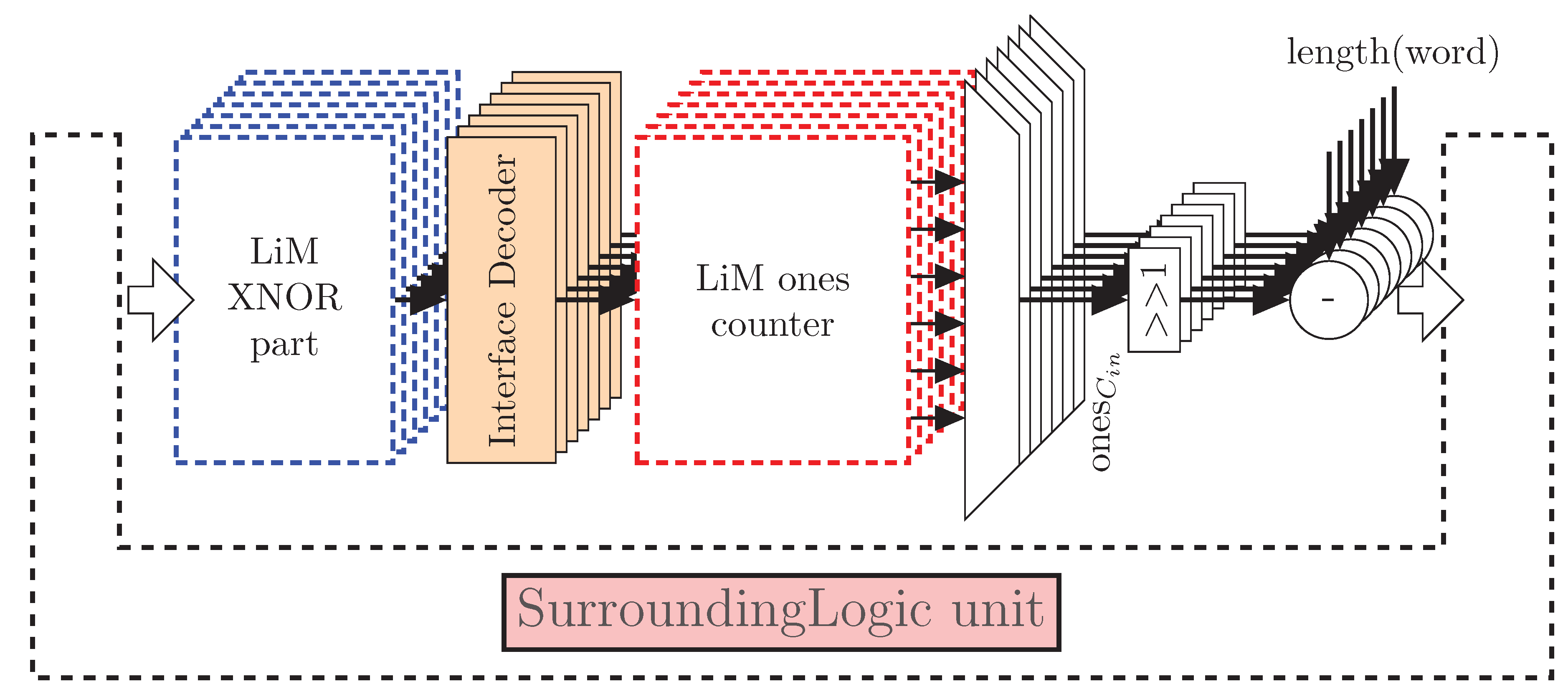
6.3.2. LiM Array Estimation: Impact on Perfomance
6.4. A More Detailed LiM Model
7. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LiM | Logic-in-Memory |
| OOM | Out-Of-Memory |
| RF | Register File |
References
- LeNet-5, Convolutional Neural Networks. Available online: http://yann.lecun.com/exdb/lenet (accessed on 10 January 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.P. Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2015; pp. 3123–3131. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 525–542. [Google Scholar]
- Choi, W.; Jeong, K.; Choi, K.; Lee, K.; Park, J. Content Addressable Memory Based Binarized Neural Network Accelerator Using Time-domain Signal Processing. In Proceedings of the 55th Annual Design Automation Conference (DAC ’18); ACM: New York, NY, USA, 2018; pp. 138:1–138:6. [Google Scholar] [CrossRef]
- Santoro, G.; Turvani, G.; Graziano, M. New Logic-In-Memory Paradigms: An Architectural and Technological Perspective. Micromachines 2019, 10, 368. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akin, B.; Franchetti, F.; Hoe, J.C. Data reorganization in memory using 3D-stacked DRAM. ACM SIGARCH Comput. Architect. News 2015, 43, 131–143. [Google Scholar] [CrossRef]
- Durlam, M.; Naji, P.; DeHerrera, M.; Tehrani, S.; Kerszykowski, G.; Kyler, K. Nonvolatile RAM based on magnetic tunnel junction elements. In Proceedings of the 2000 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 9 February 2000; pp. 130–131. [Google Scholar] [CrossRef]
- Rakin, A.S.; Angizi, S.; He, Z.; Fan, D. Pim-tgan: A processing-in-memory accelerator for ternary generative adversarial networks. In Proceedings of the 2018 IEEE 36th International Conference on Computer Design (ICCD), Orlando, FL, USA, 7–10 October 2018; pp. 266–273. [Google Scholar]
- Roohi, A.; Angizi, S.; Fan, D.; DeMara, R.F. Processing-In-Memory Acceleration of Convolutional Neural Networks for Energy-Efficiency, and Power-Intermittency Resilience. In Proceedings of the 20th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 6–7 March 2019; pp. 8–13. [Google Scholar]
- Wang, H.; Yan, X. Overview of Resistive Random Access Memory (RRAM): Materials, Filament Mechanisms, Performance Optimization, and Prospects. Phys. Status Solidi (RRL) Rapid Res. Lett. 2019, 13, 1900073. [Google Scholar] [CrossRef]
- Krestinskaya, O.; James, A.P. Binary weighted memristive analog deep neural network for near-sensor edge processing. In Proceedings of the 2018 IEEE 18th International Conference on Nanotechnology (IEEE-NANO), Cork, Ireland, 23–26 July 2018; pp. 1–4. [Google Scholar]
- Eshraghian, J.K.; Kang, S.M.; Baek, S.; Orchard, G.; Iu, H.H.C.; Lei, W. Analog weights in ReRAM DNN accelerators. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hsinchu, Taiwan, 18–20 March 2019; pp. 267–271. [Google Scholar]
- Lee, J.; Eshraghian, J.K.; Cho, K.; Eshraghian, K. Adaptive precision cnn accelerator using radix-x parallel connected memristor crossbars. arXiv 2019, arXiv:1906.09395. [Google Scholar]
- Roohi, A.; Sheikhfaal, S.; Angizi, S.; Fan, D.; DeMara, R.F. ApGAN: Approximate GAN for Robust Low Energy Learning from Imprecise Components. IEEE Trans. Comput. 2019. [Google Scholar] [CrossRef]
- Agatonovic-Kustrin, S.; Beresford, R. Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research. J. Pharm. Biomed. Anal. 2000, 22, 717–727. [Google Scholar] [CrossRef]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Wang, Y.; Lin, J.; Wang, Z. An Energy-Efficient Architecture for Binary Weight Convolutional Neural Networks. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 280–293. [Google Scholar] [CrossRef]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In International Conference on Artificial Neural Networks; Springer: Berlin, Germany, 2010; pp. 92–101. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Sari, E.; Belbahri, M.; Nia, V.P. How Does Batch Normalization Help Binary Training? Available online: http://xxx.lanl.gov/abs/1909.09139 (accessed on 20 December 2019).
- Whatmough, P.N.; Lee, S.K.; Wei, G.; Brooks, D. Sub-uJ deep neural networks for embedded applications. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 1912–1915. [Google Scholar] [CrossRef]
- Pan, Y.; Ouyang, P.; Zhao, Y.; Kang, W.; Yin, S.; Zhang, Y.; Zhao, W.; Wei, S. A Multilevel Cell STT-MRAM-Based Computing In-Memory Accelerator for Binary Convolutional Neural Network. IEEE Trans. Magnet. 2018, 54, 1–5. [Google Scholar] [CrossRef]
- Fan, D.; Angizi, S. Energy Efficient In-Memory Binary Deep Neural Network Accelerator with Dual-Mode SOT-MRAM. In Proceedings of the 2017 IEEE International Conference on Computer Design (ICCD), Boston, MA, USA, 5–8 November 2017; pp. 609–612. [Google Scholar] [CrossRef]
- Yonekawa, H.; Sato, S.; Nakahara, H.; Ando, K.; Ueyoshi, K.; Hirose, K.; Orimo, K.; Takamaeda-Yamazaki, S.; Ikebe, M.; Asai, T.; et al. In-memory area-efficient signal streaming processor design for binary neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 116–119. [Google Scholar] [CrossRef]
- Jiang, L.; Kim, M.; Wen, W.; Wang, D. XNOR-POP: A processing-in-memory architecture for binary Convolutional Neural Networks in Wide-IO2 DRAMs. In Proceedings of the 2017 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Taipei, Taiwan, 24–26 July 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Sun, X.; Yin, S.; Peng, X.; Liu, R.; Seo, J.; Yu, S. XNOR-RRAM: A scalable and parallel resistive synaptic architecture for binary neural networks. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1423–1428. [Google Scholar] [CrossRef]
- Wang, W.; Li, Y.; Wang, M.; Wang, L.; Liu, Q.; Banerjee, W.; Li, L.; Liu, M. A hardware neural network for handwritten digits recognition using binary RRAM as synaptic weight element. In Proceedings of the 2016 IEEE Silicon Nanoelectronics Workshop (SNW), Dresden, Germany, 19–23 March 2016; pp. 50–51. [Google Scholar] [CrossRef]
- Keras. Available online: https://github.com/fchollet/keras (accessed on 20 December 2019).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Number | Type | IFMAP Size | Kernel Size | Stride | ||
|---|---|---|---|---|---|---|
| 1 | Convolutional | 1 | 6 | 1 | ||
| 2 | Max Pooling | 6 | 6 | 1 | ||
| 3 | Convolutional | 6 | 6 | 1 | ||
| 4 | Max Pooling | 6 | 6 | 1 | ||
| 5 | FC | 96 | - | - | - | - |
| 6 | BatchNorm | - | - | - | - | - |
| 7 | FC | 120 | - | - | - | - |
| 8 | BatchNorm | - | - | - | - | - |
| 9 | FC | 84 | - | - | - | - |
| 10 | BatchNorm | - | - | - | - | - |
| 11 | FC | 10 | - | - | - | - |
| 12 | BatchNorm | - | - | - | - | - |
| 13 | ReLU | - | - | - | - | - |
| Type | Area (mm2) | Power (mW) | CPD (ns) |
|---|---|---|---|
| LiM | 1.68 | 254.50 | 4.11 |
| OOM | 1.10 | 193.30 | 4.14 |
| Type | Power (mW) | Execution Time (ms) | Energy (J) |
|---|---|---|---|
| LiM | 254.50 | 0.21 | 53.44 |
| OOM | 193.30 | 0.92 | 178.41 |
| Type | Area (mm2) | Power (mW) | CPD (ns) | Execution Time (ms) | Energy (J) |
|---|---|---|---|---|---|
| LiM | 1.70 | 328.3 | 4.11 | 0.21 | 68.9 |
| OOM | 1.07 | 142.3 | 4.14 | 0.92 | 130.91 |
| Layer Number | Type | IFMAP Size | Kernel Size | Stride | ||
|---|---|---|---|---|---|---|
| 1 | Dropout | - | - | - | - | |
| 2 | FC | 784 | - | - | - | - |
| 3 | BatchNorm | 196 | - | - | - | - |
| 4 | ReLU | 196 | - | - | - | - |
| 5 | Dropout | 196 | - | - | - | - |
| 6 | FC | 196 | - | - | - | - |
| 7 | BatchNorm | 196 | - | - | - | - |
| 8 | ReLU | 196 | - | - | - | - |
| 9 | Dropout | 196 | - | - | - | - |
| 10 | FC | 196 | - | - | - | - |
| 11 | BatchNorm | 10 | - | - | - | - |
| Type | Area (mm2) | Power (mW) | CPD (ns) | Execution Time (ms) | Energy (J) |
|---|---|---|---|---|---|
| LiM | 0.11 | 15.10 | 4.22 | 0.132 | 1.99 |
| OOM | 0.09 | 14.32 | 4.32 | 1.62 | 23.20 |
| Type | Area (mm2) | Power (mW) | CPD (ns) | Execution Time (ms) | Energy (J) |
|---|---|---|---|---|---|
| LiM | 0.1033 | 13.06 | 4.22 | 0.132 | 1.72 |
| OOM | 0.086 | 10.68 | 4.32 | 1.62 | 17.30 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coluccio, A.; Vacca, M.; Turvani, G. Logic-in-Memory Computation: Is It Worth It? A Binary Neural Network Case Study. J. Low Power Electron. Appl. 2020, 10, 7. https://doi.org/10.3390/jlpea10010007
Coluccio A, Vacca M, Turvani G. Logic-in-Memory Computation: Is It Worth It? A Binary Neural Network Case Study. Journal of Low Power Electronics and Applications. 2020; 10(1):7. https://doi.org/10.3390/jlpea10010007
Chicago/Turabian StyleColuccio, Andrea, Marco Vacca, and Giovanna Turvani. 2020. "Logic-in-Memory Computation: Is It Worth It? A Binary Neural Network Case Study" Journal of Low Power Electronics and Applications 10, no. 1: 7. https://doi.org/10.3390/jlpea10010007
APA StyleColuccio, A., Vacca, M., & Turvani, G. (2020). Logic-in-Memory Computation: Is It Worth It? A Binary Neural Network Case Study. Journal of Low Power Electronics and Applications, 10(1), 7. https://doi.org/10.3390/jlpea10010007