AxCEM: Designing Approximate Comparator-Enabled Multipliers



Abstract
:1. Introduction
2. Background and Related Work
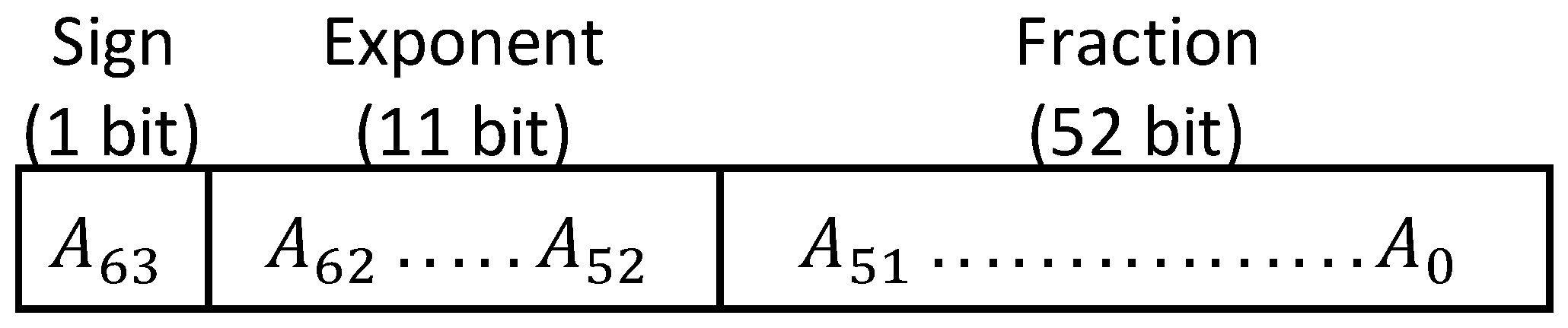
2.1. IEEE 754
2.2. Related Work
3. Proposed Method
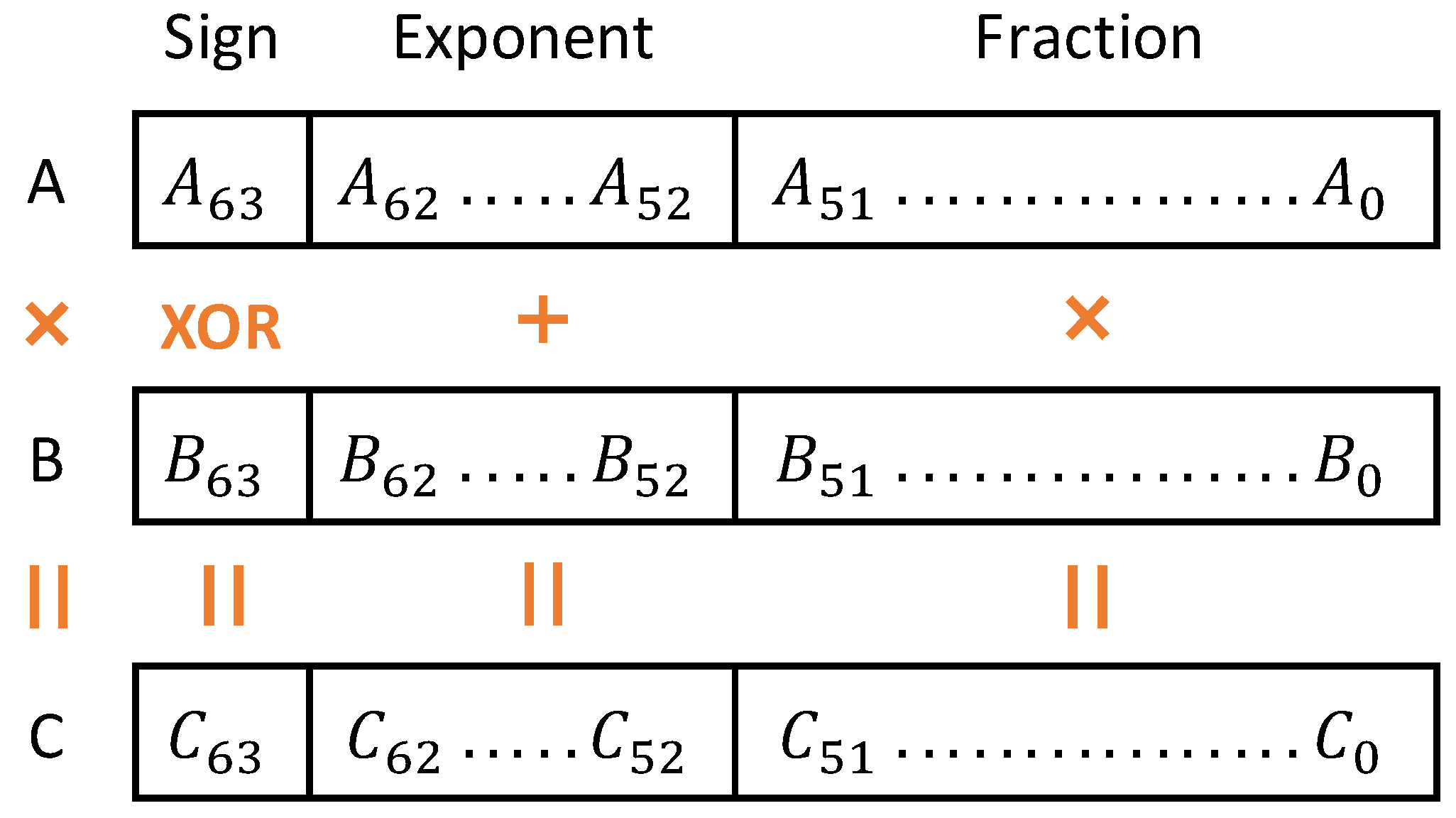
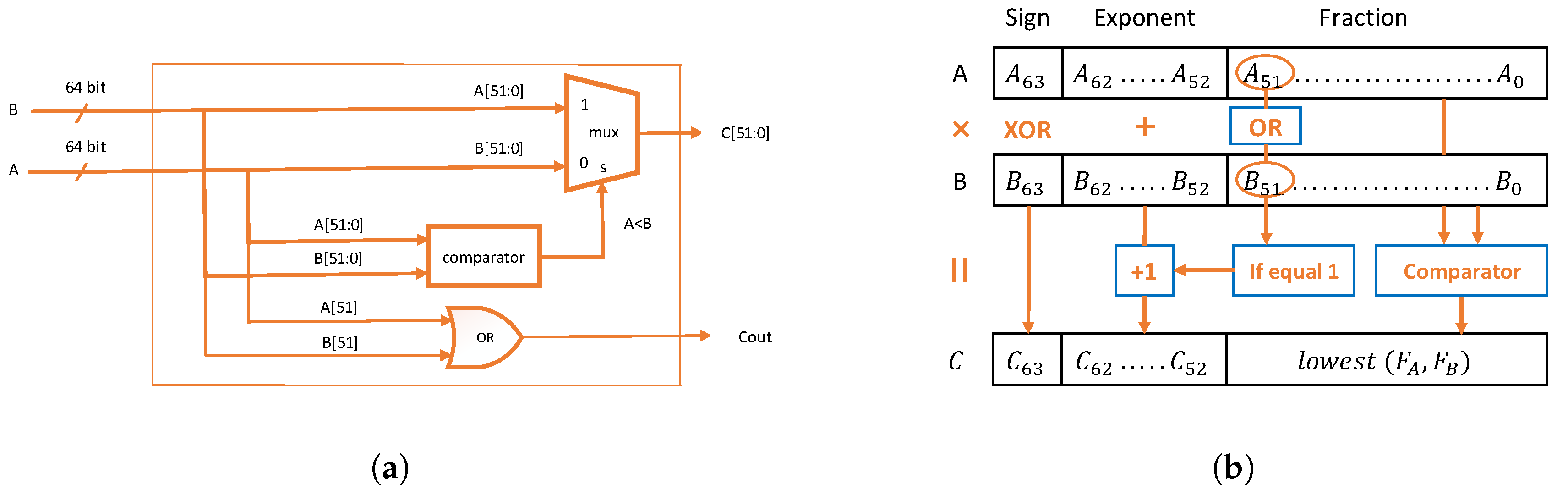
3.1. Approximate Mantissa Product Computation: The Comparator-Enabled Multipliers (CEM)
3.2. AxCEM: Approximate Comparator-Enabled Multipliers
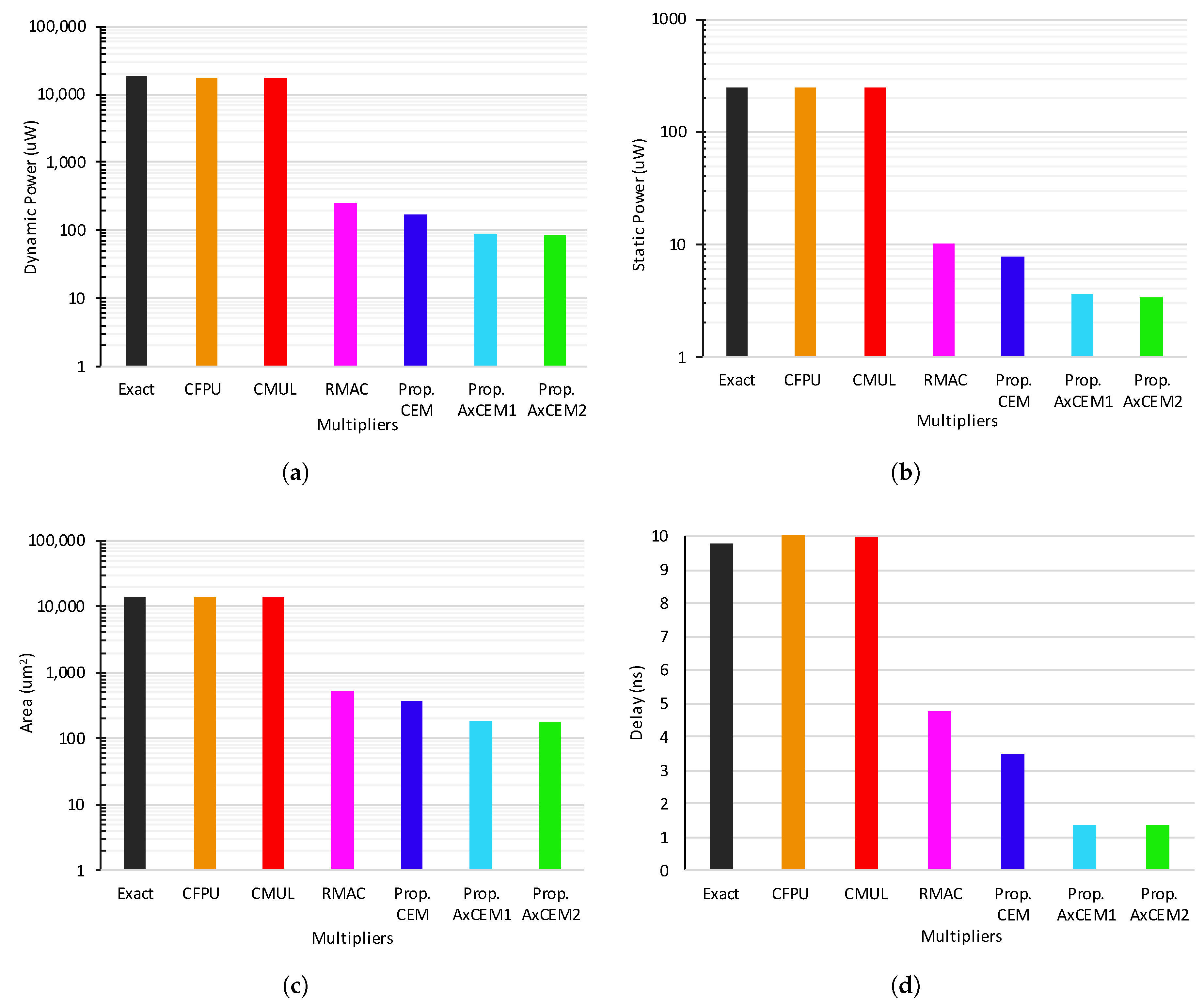
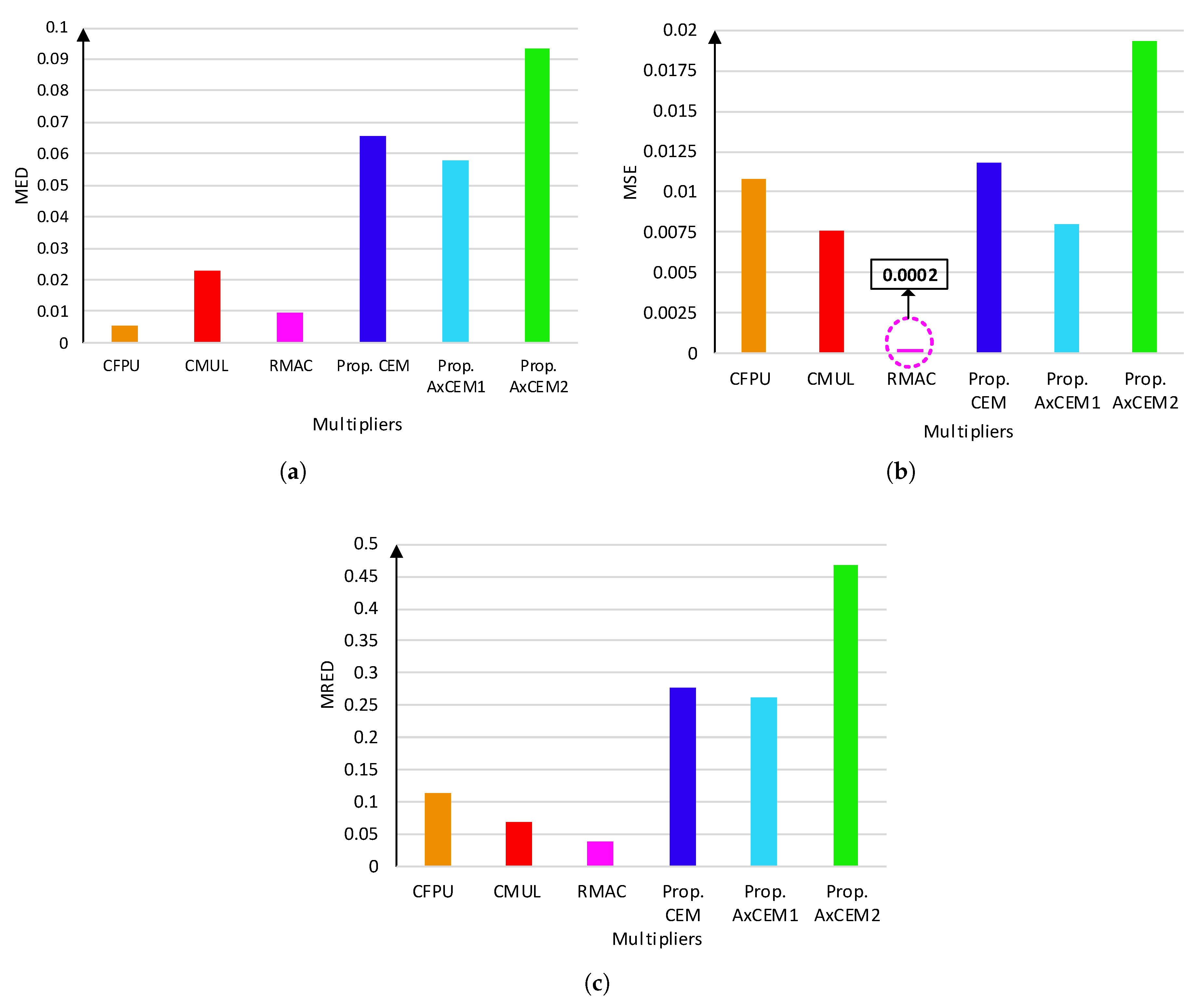
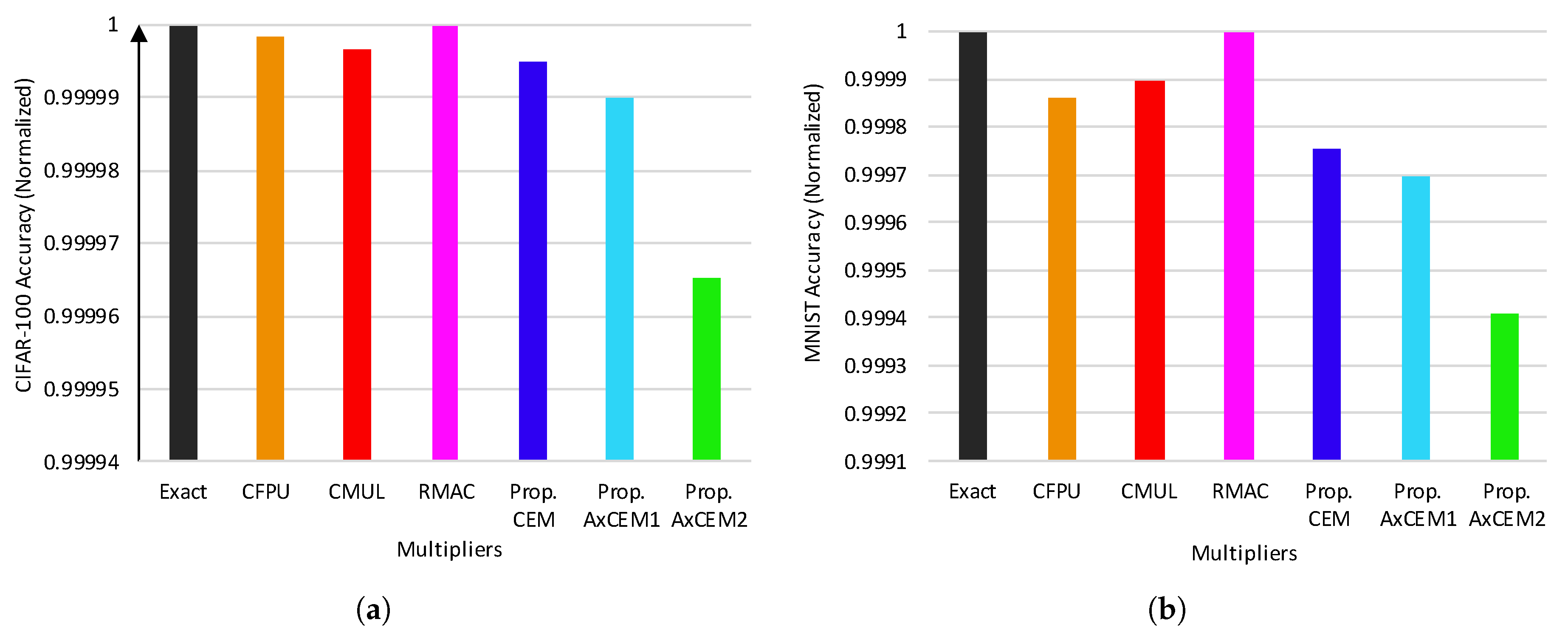
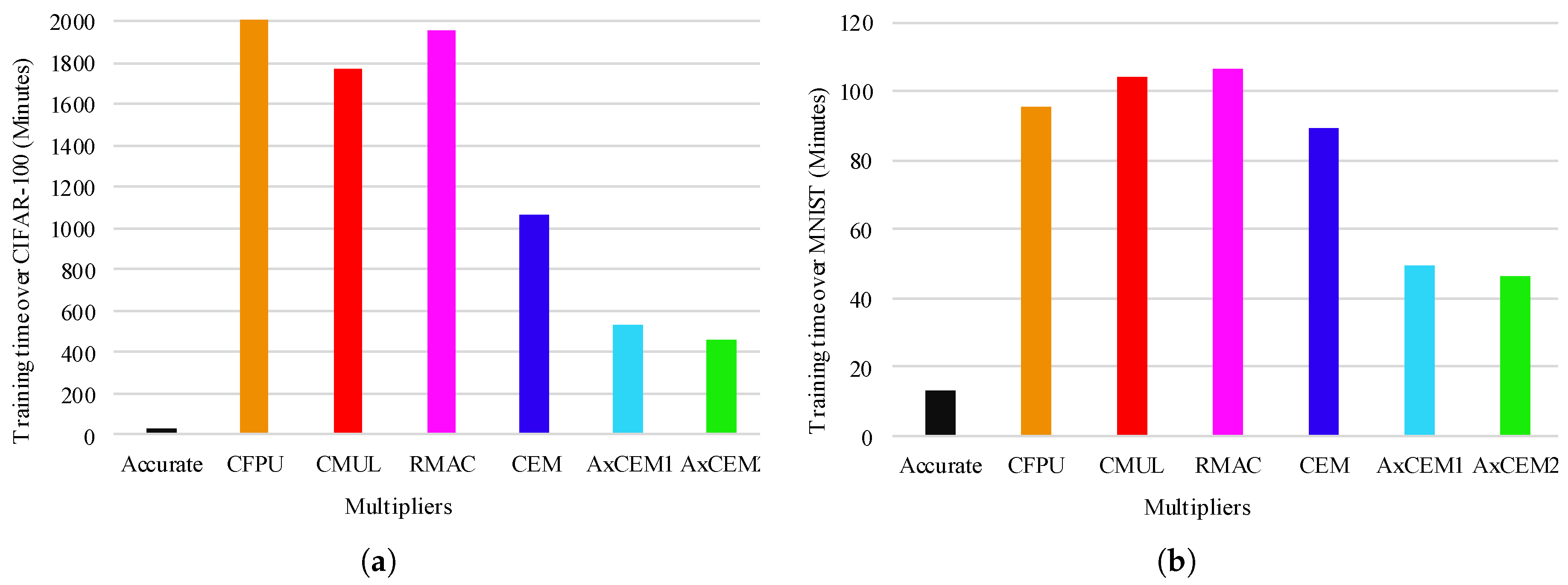
4. Evaluation
4.1. Experiment Setup
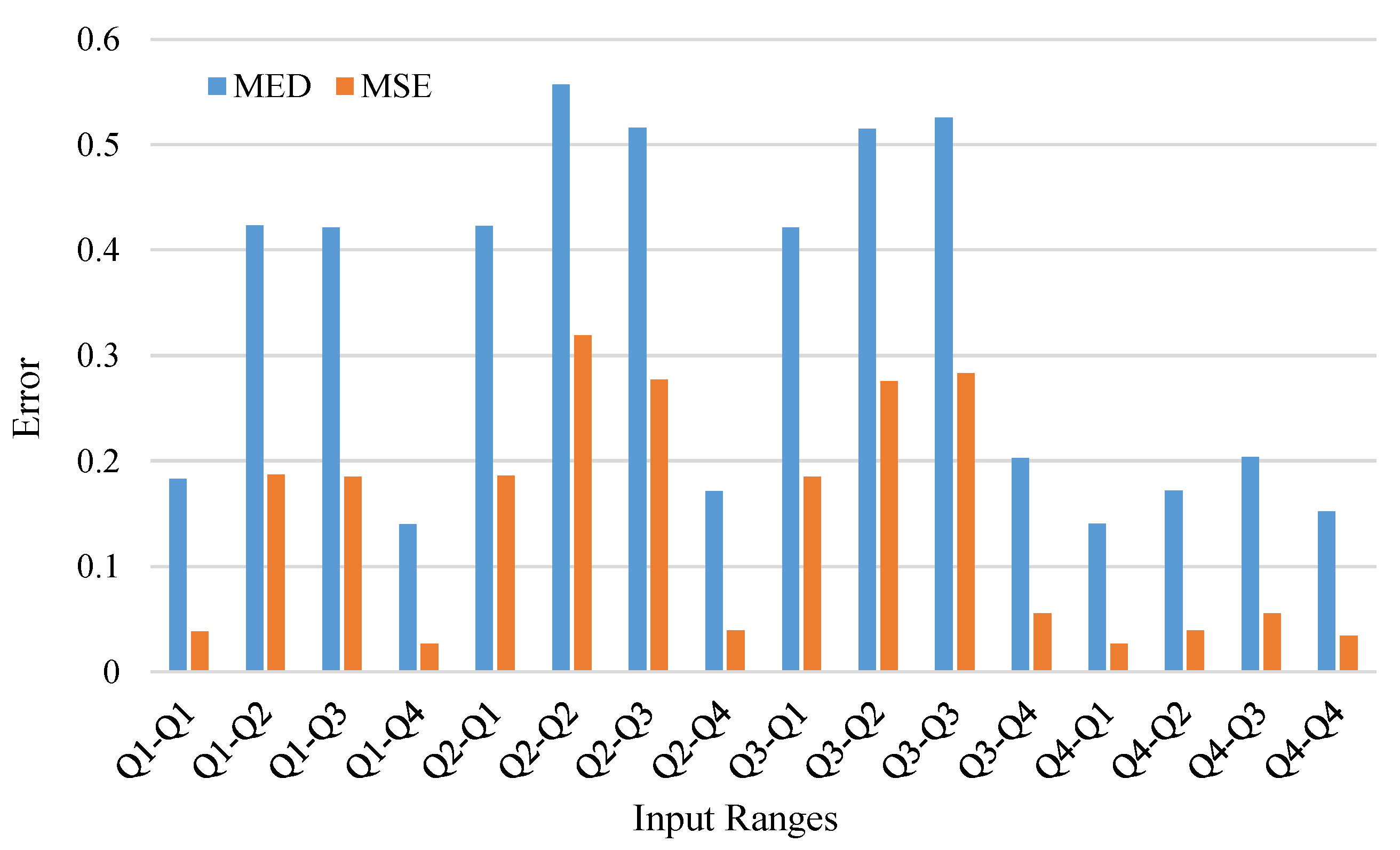
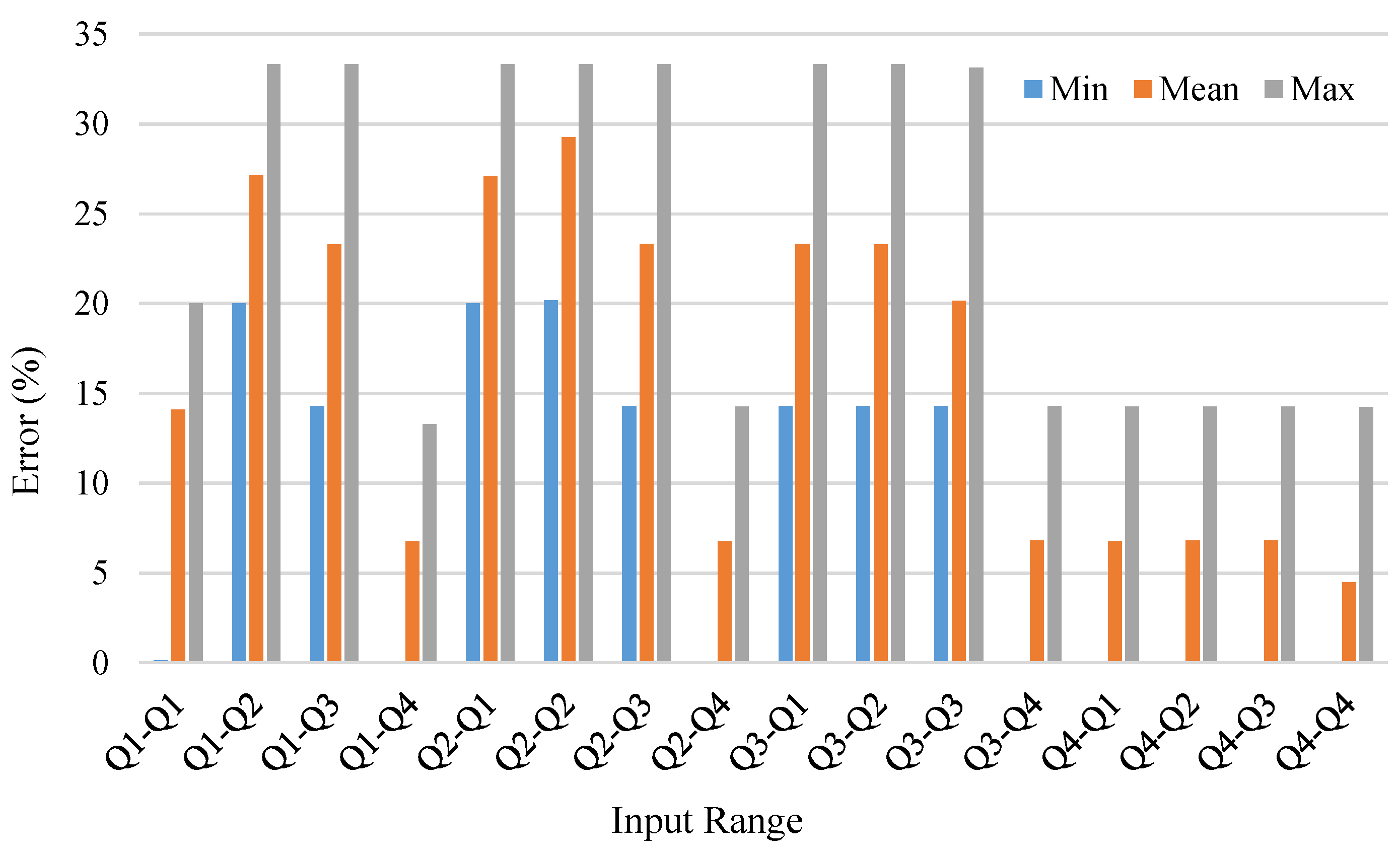
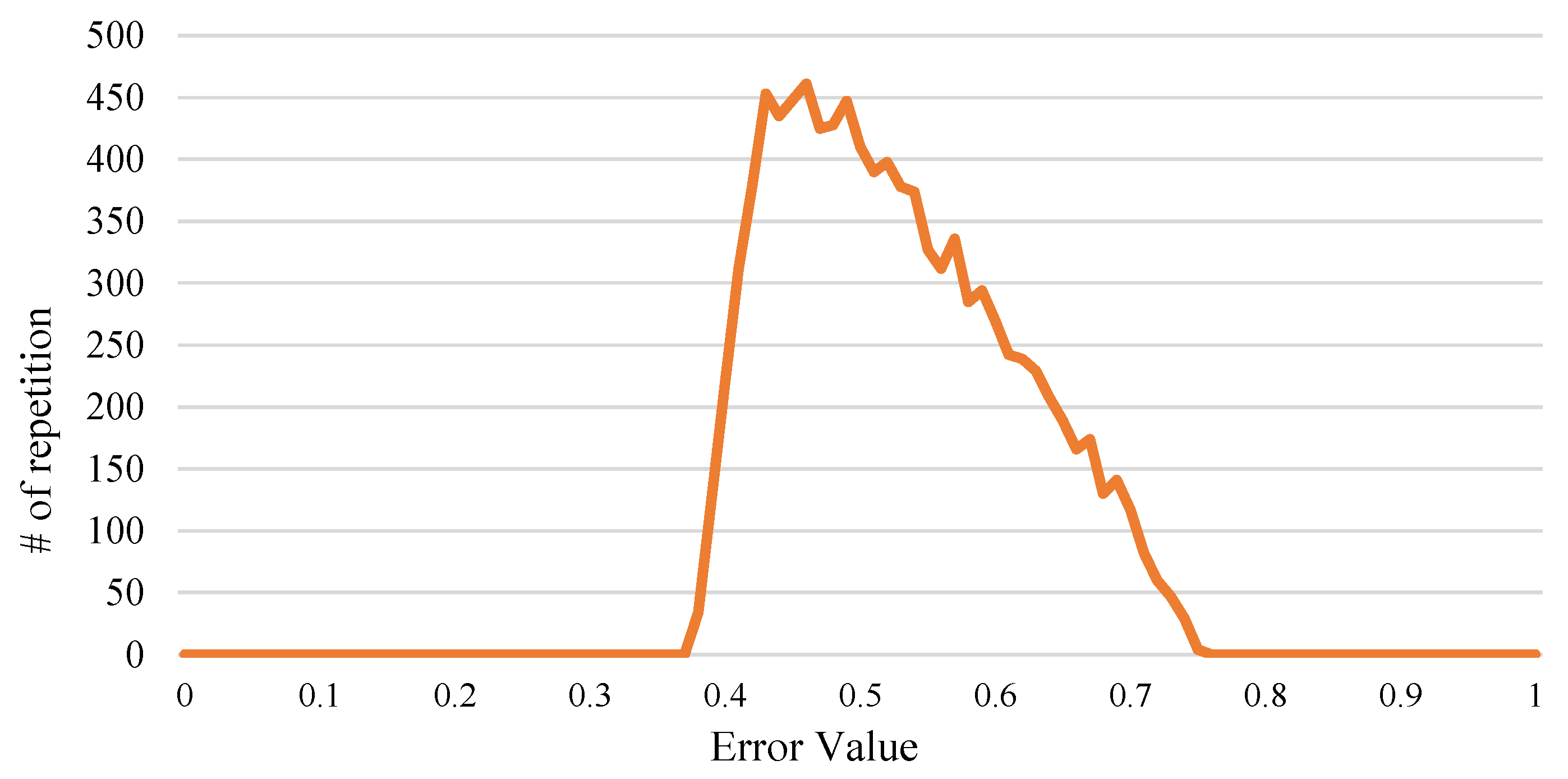
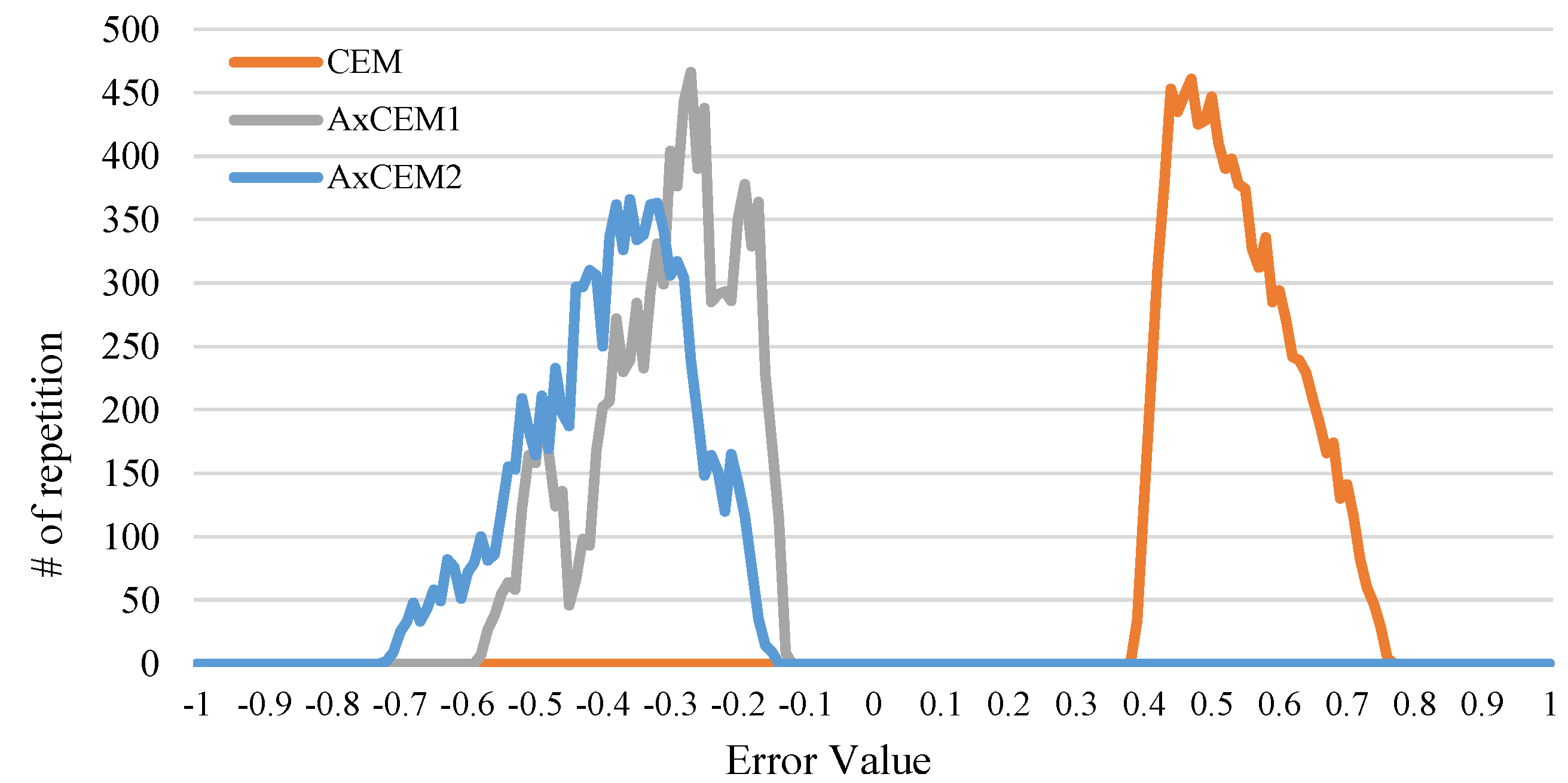
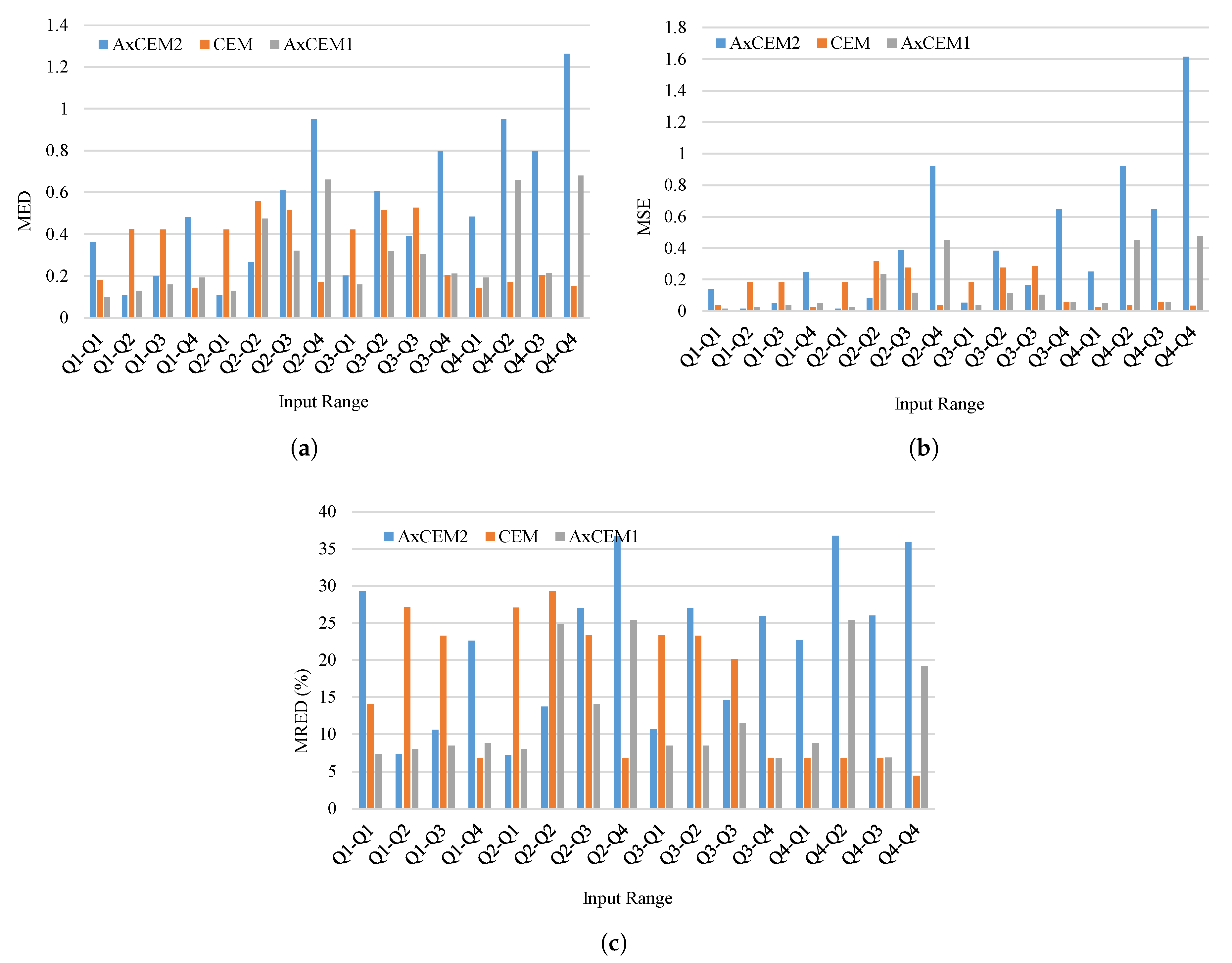
4.2. Circuit and Error Metrics
4.3. CNN Performance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sekanina, L. Introduction to approximate computing: Embedded tutorial. In Proceedings of the 2016 IEEE 19th International Symposium on Design and Diagnostics of Electronic Circuits & Systems (DDECS), Kosice, Slovakia, 20–22 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Liang, J.; Han, J.; Lombardi, F. New metrics for the reliability of approximate and probabilistic adders. IEEE Trans. Comput. 2012, 62, 1760–1771. [Google Scholar] [CrossRef]
- Yin, P.; Wang, C.; Liu, W.; Lombardi, F. Design and Performance Evaluation of Approximate Floating-Point Multipliers. In Proceedings of the 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, PA, USA, 11–13 July 2016; pp. 296–301. [Google Scholar] [CrossRef]
- Qiqieh, I.; Shafik, R.; Tarawneh, G.; Sokolov, D.; Yakovlev, A. Energy-efficient approximate multiplier design using bit significance-driven logic compression. In Proceedings of the Conference on Design, Automation & Test in Europe, Lausanne, Switzerland, 27–31 March 2017; European Design and Automation Association: Leuven, Belgium; pp. 7–12. [Google Scholar]
- Hashemi, S.; Bahar, R.; Reda, S. DRUM: A dynamic range unbiased multiplier for approximate applications. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design, Austin, TX, USA, 2–6 November 2015; IEEE Press: Piscataway, NJ, USA, 2015; pp. 418–425. [Google Scholar]
- Rizzo, R.G.; Calimera, A. Implementing Adaptive Voltage Over-Scaling: Algorithmic Noise Tolerance vs. Approximate Error Detection. J. Low Power Electron. Appl. 2019, 9, 17. [Google Scholar] [CrossRef] [Green Version]
- Kulkarni, P.; Gupta, P.; Ercegovac, M. Trading accuracy for power with an underdesigned multiplier architecture. In Proceedings of the 2011 24th Internatioal Conference on VLSI Design, Chennai, India, 2–7 January 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 346–351. [Google Scholar]
- Huang, J.; Lach, J.; Robins, G. A methodology for energy-quality tradeoff using imprecise hardware. In Proceedings of the 49th Annual Design Automation Conference, San Francisco, CA, USA, 3–7 June 2012; ACM: New York, NY, USA, 2012; pp. 504–509. [Google Scholar]
- Mohapatra, D.; Chippa, V.K.; Raghunathan, A.; Roy, K. Design of voltage-scalable meta-functions for approximate computing. In Proceedings of the 2011 Design, Automation Test in Europe, Grenoble, France, 14–18 March 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Vahdat, S.; Kamal, M.; Afzali-Kusha, A.; Pedram, M. TOSAM: An Energy-Efficient Truncation- and Rounding-Based Scalable Approximate Multiplier. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1161–1173. [Google Scholar] [CrossRef]
- Lin, C.; Lin, I. High accuracy approximate multiplier with error correction. In Proceedings of the 2013 IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013; pp. 33–38. [Google Scholar] [CrossRef]
- Yang, T.; Ukezono, T.; Sato, T. A low-power high-speed accuracy-controllable approximate multiplier design. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju Island, Korea, 22–25 January 2018; pp. 605–610. [Google Scholar] [CrossRef]
- Baba, H.; Yang, T.; Inoue, M.; Tajima, K.; Ukezono, T.; Sato, T. A Low-Power and Small-Area Multiplier for Accuracy-Scalable Approximate Computing. In Proceedings of the 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Hong Kong, China, 8–11 July 2018; pp. 569–574. [Google Scholar] [CrossRef]
- Yang, T.; Ukezono, T.; Sato, T. Low-Power and High-Speed Approximate Multiplier Design with a Tree Compressor. In Proceedings of the 2017 IEEE International Conference on Computer Design (ICCD), Boston, MA, USA, 5–8 November 2017; pp. 89–96. [Google Scholar] [CrossRef]
- Imani, M.; Peroni, D.; Rosing, T. CFPU: Configurable floating point multiplier for energy-efficient computing. In Proceedings of the 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Imani, M.; Garcia, R.; Gupta, S.; Rosing, T. Hardware-Software Co-design to Accelerate Neural Network Applications. J. Emerg. Technol. Comput. Syst. 2019, 15, 21:1–21:18. [Google Scholar] [CrossRef]
- Imani, M.; Garcia, R.; Gupta, S.; Rosing, T. RMAC: Runtime Configurable Floating Point Multiplier for Approximate Computing. In Proceedings of the International Symposium on Low Power Electronics and Design, Seattle, WA, USA, 23–25 July 2018; ACM: New York, NY, USA, 2018. ISLPED ’18. pp. 12:1–12:6. [Google Scholar] [CrossRef]
- Jiao, X.; Akhlaghi, V.; Jiang, Y.; Gupta, R.K. Energy-efficient neural networks using approximate computation reuse. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1223–1228. [Google Scholar] [CrossRef]
- Venkataramani, S.; Ranjan, A.; Roy, K.; Raghunathan, A. AxNN: Energy-efficient neuromorphic systems using approximate computing. In Proceedings of the 2014 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), La Jolla, CA, USA, 11–13 August 2014; pp. 27–32. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, T.; Tian, Y.; Yuan, F.; Xu, Q. ApproxANN: An approximate computing framework for artificial neural network. In Proceedings of the 2015 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 701–706. [Google Scholar]
- Sarwar, S.S.; Venkataramani, S.; Raghunathan, A.; Roy, K. Multiplier-less Artificial Neurons exploiting error resiliency for energy-efficient neural computing. In Proceedings of the 2016 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 145–150. [Google Scholar]
- Neshatpour, K.; Behnia, F.; Homayoun, H.; Sasan, A. ICNN: An iterative implementation of convolutional neural networks to enable energy and computational complexity aware dynamic approximation. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 551–556. [Google Scholar] [CrossRef]
- NanGate, Inc. NanGate FreePDK45 Open Cell Library; NanGate, Inc.: Santa Clara, CA, USA, 2008. [Google Scholar]
- Ye, R.; Wang, T.; Yuan, F.; Kumar, R.; Xu, Q. On reconfiguration-oriented approximate adder design and its application. In Proceedings of the 2013 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 18–21 November 2013; pp. 48–54. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Remark | Activation Function |
|---|---|---|
| Input | nodes | – |
| Convolution | 20 convolution filters () | ReLU |
| Pooling | Mean Pooling () | – |
| Hidden | 100 nodes | ReLU |
| Output | 10 nodes | Softmax |
| Layer | Remark | Activation Function |
|---|---|---|
| Input | nodes | – |
| Convolution | 128 convolution filters () | ReLU |
| Pooling | Mean Pooling () | – |
| Hidden | 256 nodes | ReLU |
| Output | 100 nodes | Softmax |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghabraei, S.; Rezaalipour, M.; Dehyadegari, M.; Nazm Bojnordi, M. AxCEM: Designing Approximate Comparator-Enabled Multipliers. J. Low Power Electron. Appl. 2020, 10, 9. https://doi.org/10.3390/jlpea10010009
Ghabraei S, Rezaalipour M, Dehyadegari M, Nazm Bojnordi M. AxCEM: Designing Approximate Comparator-Enabled Multipliers. Journal of Low Power Electronics and Applications. 2020; 10(1):9. https://doi.org/10.3390/jlpea10010009
Chicago/Turabian StyleGhabraei, Samar, Morteza Rezaalipour, Masoud Dehyadegari, and Mahdi Nazm Bojnordi. 2020. "AxCEM: Designing Approximate Comparator-Enabled Multipliers" Journal of Low Power Electronics and Applications 10, no. 1: 9. https://doi.org/10.3390/jlpea10010009
APA StyleGhabraei, S., Rezaalipour, M., Dehyadegari, M., & Nazm Bojnordi, M. (2020). AxCEM: Designing Approximate Comparator-Enabled Multipliers. Journal of Low Power Electronics and Applications, 10(1), 9. https://doi.org/10.3390/jlpea10010009