A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images

 ,
,
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Data
2.2. Methods
2.2.1. Sample Generation
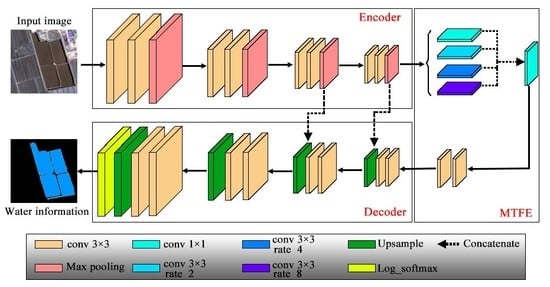
2.2.2. Multi-Scale Feature Extractor
2.2.3. Convolutional Neural Networks (CNNs) for Water Extraction
- Data augmentation: Date augmentation is performed before training. In this step, the input samples are randomly processed in three ways, including flipping, zooming, and panning. All samples in the training dataset are randomly processed before every training epoch, and the number of training samples for every training epoch does not change. The data augmentation results for the three samples are shown in Figure 6.
- Forward propagation: The normalized sample is fed into the CNN and a feature map is obtained after forward propagation. The output of the CNN is a feature map with a size of 512 × 512 × channels (where the channels are the number of classes). In this study, the number of channels is 2 (water bodies and backgrounds). Then, the feature map is activated by an activation function. The log softmax function is used as the activation function and the argmax function [34] is used to get the final water maps in this study. The formula of the activation function for each pixel in the feature maps is as follows:where is the data value of the pixel in channel . is the number of classes (2 in this study to reflect the water and background).
- Model training: The cross-entropy loss function [35] and the back propagation algorithm [36] are used when training the CNNs. The mean cross-entropy and the sparse categorical accuracy [37] are calculated between the labels and the predicted maps by the CNN forward propagation. To minimize the cross entropy, the Adam optimizer [38] is applied to identify the weights and biases in the back-propagation process. In this study, the weights of the CNNs model are trained on training dataset and weights with the highest parse categorical accuracies on the validation dataset are selected as the training results.
2.2.4. Accuracy Assessment
3. Results
3.1. Model Training
3.2. Water Extraction Results on the Test Dataset
3.3. Accuracy Analysis
3.3.1. Accuracy Comparisons via the Evaluation Metrics
3.3.2. Performance Comparison for MWEN and MWEN “Without Multi-Scale Feature Extractor (MTFE)”
3.3.3. Performance Comparison for Different Water Types
3.3.4. Performance Comparison for Confusing Areas
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Oki, T.; Kanae, S. Global hydrological cycles and world water resources. Science 2006, 313, 1068–1072. [Google Scholar] [CrossRef] [Green Version]
- Van Oost, K.; Quine, T.A.; Govers, G.; De Gryze, S.; Six, J.; Harden, J.W.; Ritchie, J.C.; McCarty, G.W.; Heckrath, G.; Kosmas, C.; et al. The impact of agricultural soil erosion on the global carbon cycle. Science 2007, 318, 626–629. [Google Scholar] [CrossRef]
- Wei, J.; Guojin, H.; Zhiguo, P.; Hongxiang, G.; Tengfei, L.; Yuan, N. Surface water map of china for 2015 (swmc-2015) derived from landsat 8 satellite imagery. Remote Sens. Lett. 2020, 11, 265–273. [Google Scholar]
- Ji, L.Y.; Gong, P.; Wang, J.; Shi, J.C.; Zhu, Z.L. Construction of the 500-m resolution daily global surface water change database (2001-2016). Water Resour. Res. 2018, 54, 10270–10292. [Google Scholar] [CrossRef]
- Fang, Y.; Ceola, S.; Paik, K.; McGrath, G.; Rao, P.S.C.; Montanari, A.; Jawitz, J.W. Globally universal fractal pattern of human settlements in river networks. Earths Future 2018, 6, 1134–1145. [Google Scholar] [CrossRef] [Green Version]
- Lv, W.; Yu, Q.; Yu, W. Water extraction in sar images using glcm and support vector machine. In Proceedings of the 2010 IEEE 10th International Conference on Signal Processing Proceedings (Icsp2010), Beijing, China, 24–28 October 2010; pp. 740–743. [Google Scholar]
- Xiao, Y.; Zhao, W.; Zhu, L. A study on information extraction of water body using band1 and band7 of tm imagery. Sci. Surv. Mapp. 2010, 35, 226–227. [Google Scholar]
- Song, X.F.; Duan, Z.; Jiang, X.G. Comparison of artificial neural networks and support vector machine classifiers for land cover classification in northern china using a spot-5 hrg image. Int. J. Remote Sens. 2012, 33, 3301–3320. [Google Scholar] [CrossRef]
- Ko, B.C.; Kim, H.H.; Nam, J.Y. Classification of potential water bodies using landsat 8 oli and a combination of two boosted random forest classifiers. Sensors 2015, 15, 13763–13777. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, L.; Wang, Z.; Tian, S.; Ye, F.; Ding, J.; Kong, J. Convolutional neural networks for water body extraction from landsat imagery. Int. J. Comput. Intell. and Appl. 2017, 16. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.S.; Yang, X.C.; Wang, J.X.; Latif, A. Extraction of urban water bodies from high-resolution remote-sensing imagery using deep learning. Water 2018, 10, 585. [Google Scholar] [CrossRef] [Green Version]
- Frazier, P.S.; Page, K.J. Water body detection and delineation with landsat tm data. Photogramm. Eng. Remote Sens. 2000, 66, 1461–1467. [Google Scholar]
- Gao, B.C. Ndwi—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Zhou, Y.A.; Luo, J.C.; Shen, Z.F.; Hu, X.D.; Yang, H.P. Multiscale water body extraction in urban environments from satellite images. IEEE J. Sel. Topics Appl. Earth.Observ. Remote Sens. 2014, 7, 4301–4312. [Google Scholar] [CrossRef]
- Acharya, T.D.; Lee, D.H.; Yang, I.T.; Lee, J.K. Identification of water bodies in a landsat 8 oli image using a j48 decision tree. Sensors 2016, 16, 1075. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. arXiv 2019, arXiv:1909.00133. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (Iccv), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Pan, H.D.; Chen, G.F.; Jiang, J. Adaptively dense feature pyramid network for object detection. Ieee Access 2019, 7, 81132–81144. [Google Scholar] [CrossRef]
- Wu, Z.; Gao, Y.; Li, L.; Xue, J.; Li, Y. Semantic segmentation of high-resolution remote sensing images using fully convolutional network with adaptive threshold. Connect. Sci. 2019, 31, 169–184. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.M.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.M.; Anders, K.; Gloaguen, R.; et al. Multisource and multitemporal data fusion in remote sensing a comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef] [Green Version]
- Li, L.W.; Yan, Z.; Shen, Q.; Cheng, G.; Gao, L.R.; Zhang, B. Water body extraction from very high spatial resolution remote sensing data based on fully convolutional networks. Remote Sens. 2019, 11, 1162. [Google Scholar] [CrossRef] [Green Version]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface water mapping by deep learning. IEEE J. Sel. Topics Appl. Earth.Observ. Remote Sens. 2017, 10. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Long, T.F.; Jiao, W.L.; He, G.J. Nested regression based optimal selection (nrbos) of rational polynomial coefficients. Photogramm. Eng. Remote Sens. 2014, 80, 261–269. [Google Scholar]
- Peng, Y.; Zhang, Z.M.; He, G.J.; Wei, M.Y. An improved grabcut method based on a visual attention model for rare-earth ore mining area recognition with high-resolution remote sensing images. Remote Sens. 2019, 11, 987. [Google Scholar] [CrossRef] [Green Version]
- Holschneider, M.; Kronland-Martinet, R.; Morlet, J.; Tchamitchian, P. A real-time algorithm for signal analysis with the help of the wavelet transform. In Wavelets; Springer: Berlin/Heidelberg, Germany, 1990; pp. 286–297. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Li, Y.; Qi, H.Z.; Dai, J.; Ji, X.Y.; Wei, Y.C. Fully convolutional instance-aware semantic segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (Cvpr 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Gould, S.; Fernando, B.; Cherian, A.; Anderson, P.; Cruz, R.S.; Guo, E. On differentiating parameterized argmin and argmax problems with application to bi-level optimization. arXiv 2016, arXiv:1607.05447. [Google Scholar]
- De Boer, P.-T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Leung, H.; Haykin, S. The complex backpropagation algorithm. IEEE Trans. Signal Process. 1991, 39, 2101–2104. [Google Scholar] [CrossRef]
- Von Davier, M. Bootstrapping goodness-of-fit statistics for sparse categorical data: Results of a monte carlo study. Methods Psychol. Res. Online 1997, 2, 29–48. [Google Scholar]
- Bello, I.; Zoph, B.; Vasudevan, V.; Le, Q.V. Neural optimizer search with reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 459–468. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. arXiv 2019, arXiv:1907.05740. [Google Scholar]
- Miao, Z.; Fu, K.; Sun, H.; Sun, X.; Yan, M. Automatic water-body segmentation from high-resolution satellite images via deep networks. IEEE Geosci. Remote Sens. Lett. 2018. [Google Scholar] [CrossRef]
- Yao, F.F.; Wang, C.; Dong, D.; Luo, J.C.; Shen, Z.F.; Yang, K.H. High-resolution mapping of urban surface water using zy-3 multi-spectral imagery. Remote Sens. 2015, 7, 12336–12355. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W.; He, G.; Long, T.; Ni, Y.; Liu, H.; Peng, Y.; Lv, K.; Wang, G. Multilayer perceptron neural network for surface water extraction in landsat 8 oli satellite images. Remote Sens. 2018, 10, 755. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images | Location | Acquisition Times | Water Types | Major Confusing Objects |
|---|---|---|---|---|
| a1-a8 | Tibet province | July, 2014 and August, 2016 | Plateau lake, Plateau river, Saline lake | Cloud shadows, Saline land |
| b1-b7 | Beijing-Tianjin-Hebei region | January, September and October, 2019 | Agricultural water, town water, city water | Building shadows, sports field, highways. |
| c1-c9 | Zhejiang province | April, 2017 and October, 2019 | Agricultural water, town water, woodland water, city water | Mountain shadows, wetland, roads |
| Evaluation Index | Definition | Formula |
|---|---|---|
| OA | The ratio of the correctly classified number of pixels and the total number of pixels | |
| TWR | The ratio of the number of properly classified water pixels and the number of labeled water pixels | |
| FWR | The ratio of the number of misclassified water pixels and the number of labeled water pixels | |
| WIoU | The ratio of the intersection and the union of the ground truth water and the predicted water area. | |
| MIoU | The average IoU for all classes (water and background) |
| CNN | MWEN | MWEN without MTFE | FCN | Unet | Deeplab V3+ |
|---|---|---|---|---|---|
| Highest validation accuracy | 0.987 | 0.981 | 0.978 | 0.983 | 0.957 |
| CNN | Number of Trainable Parameters (Million) | Training Time (s/epoch) |
|---|---|---|
| MWEN | 3.72 | 1343 |
| MWEN without MTFE | 1.57 | 1161 |
| FCN | 5.71 | 1345 |
| Unet | 3.11 | 1366 |
| Deeplab V3+ | 4.11 | 2161 |
| CNN | OA (%) | TWR (%) | FWR (%) | WIoU | MIoU |
|---|---|---|---|---|---|
| MWEN | 98.62 | 92.34 | 0.61 | 0.880 | 0.932 |
| MWEN without MTFE | 98.35 | 91.58 | 0.86 | 0.863 | 0.916 |
| FCN | 98.52 | 91.40 | 0.62 | 0.870 | 0.927 |
| Unet | 98.18 | 92.82 | 1.16 | 0.849 | 0.914 |
| Deeplab V3+ | 91.82 | 96.92 | 8.81 | 0.566 | 0.737 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; He, G.; Jiang, W.; Yin, R.; Yan, L.; Leng, W. A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2020, 9, 189. https://doi.org/10.3390/ijgi9040189
Guo H, He G, Jiang W, Yin R, Yan L, Leng W. A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images. ISPRS International Journal of Geo-Information. 2020; 9(4):189. https://doi.org/10.3390/ijgi9040189
Chicago/Turabian StyleGuo, Hongxiang, Guojin He, Wei Jiang, Ranyu Yin, Lei Yan, and Wanchun Leng. 2020. "A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images" ISPRS International Journal of Geo-Information 9, no. 4: 189. https://doi.org/10.3390/ijgi9040189
APA StyleGuo, H., He, G., Jiang, W., Yin, R., Yan, L., & Leng, W. (2020). A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images. ISPRS International Journal of Geo-Information, 9(4), 189. https://doi.org/10.3390/ijgi9040189