1. Introduction
With an increasingly complex flight environment and drastic target maneuvers, an interceptor is required to intercept the target accurately. This presents a great challenge for the interceptor. The guidance process is generally divided into initial guidance [
1], mid-course guidance [
2], and terminal guidance phases [
3]. The phase that mainly determines the interception accuracy is the terminal guidance phase (TGP). As such, guidance law for the TGP has become a significant supporting technology in guaranteeing the interception success and performance of an interception system.
Generally, the objectives of the interception in the TGP are to avoid the escape of the target and to achieve the minimum miss distance [
4]. To achieve these objectives, many works have been reported. Proportional navigation guidance (PNG) laws for non-maneuvering targets were proposed in [
5,
6]. Reference [
7] proposed a PNG law using delayed line-of-sight angular rate (LOSAR) information. Recently, parallel approaching guidance (PAG), a promising strategy that keeps the LOSAR at zero, has received increased attention [
8]. Under PAG, the interceptor possesses a flatter interception trajectory and, thus, requires less normal acceleration than the target. However, it still is a challenge to address unknown maneuvers of the target, and more research efforts are necessary.
To address the interception issue of maneuvering targets, many methods have been reported. To ensure a low sensitivity to the target maneuvers and other unknown factors, a proportional-integral (PI) control-based guidance law was adopted [
9]. According to the
robust control theory, the
guidance law [
10,
11] was used to solve the problem of intercepting a maneuvering target. In addition, an adaptive sliding mode guidance law was developed for the interception of high-speed and maneuvering targets [
12,
13]. However, all of the above were passive disturbance rejection methods. The robustness of these systems was realized at the expense of their nominal performance. When a system requires high performance, the aforementioned methods may struggle to meet the requirements.
Meanwhile, the active disturbance rejection method can efficiently estimate bounded unknown disturbances and compensate for observed disturbances, to reduce their impact on the system [
14]. Due to its advantages, the active disturbance rejection method is suitable for a system with good control accuracy. Among these methods, a nonlinear disturbance observer (NDO) is an effective method that has been used in a lot of systems [
15,
16,
17,
18]. Furthermore, the NDO was used in a guidance system to estimate unknown target maneuvers [
19,
20,
21]. However, the target maneuvers were treated as compound disturbances in the above works. With the relative distance decreasing rapidly during an interception, the estimation accuracy will be affected. In light of all of these factors, further research efforts to design an NDO with higher estimation accuracy are necessary.
In addition, during the interception of maneuvering targets, some constraints should be taken into consideration, to ensure the system performance. It is usually required that the line-of-sight angle (LOSA) remains within a bounded area, to guarantee the target remains in the seeker’s sight of view. To fulfill this requirement, some remarkable research results for an interceptor have been reported. An event-triggered (ET) backstepping-based guidance law was employed to ensure the LOSAR remained at zero [
8]. SMC was adopted to intercept a maneuvering target with a terminal LOSA constraint [
19,
20,
21,
22]. Nevertheless, the above works only considered the steady-state performance of the systems. More studies to simultaneously guarantee a steady state and transient performance are necessary.
As far as this is concerned, the prescribed performance control (PPC) proposed in [
23] can ensure the tracking error remains zero. Its maximum convergence time and the maximum overshoot do not exceed the preset values, which makes the transient performance better. Because of this feature, PPC has been employed to solve various kinds of control problem [
24,
25,
26,
27]. In particular, PPC was used to stabilize the LOSA and its rate [
28]. However, the traditional PPC guarantees that the system is stabilized as the control time goes to infinity. It is not an ideal method for solving control problems with a requirement for the convergence time, such as in interception. Recently, finite-time prescribed performance control (FPPC) was proposed to solve this problem [
29,
30,
31]. But the disadvantage of FPPC is that too large an overshoot makes the transient performance insufficient. To solve this problem, a novel FPPC that can adjust its bounds adaptively according to the positive or negative of the initial error was proposed, with a small overshoot [
32].
Based on the above motivation, this work proposes a PAG law to intercept a maneuvering target using FPPC. A target maneuver is estimated using a distance-scalar disturbance observer (DSDO), whose estimation accuracy is not affected by the relative distance. The objective is to stabilize the LOSAR in the specified finite time and to ensure a minimum distance. The contributions and advantages of this study are summarized in the following:
- 1.
FPPC is used to stabilize the LOSA to a small enough neighborhood of a given constant within a given time, so as to make the LOSAR converge to a small enough neighborhood of the origin within a given time. In this way, the time of the interception is shortened. With the help of the FPPC technique, there is a small overshoot in the convergence process;
- 2.
A DSDO is employed to estimate a target unknown maneuver without estimating the relative distance. Consequently, the estimation accuracy of the DSDO is improved. The estimation is introduced into the control input, so as to reduce the adverse influence on the interception accuracy;
- 3.
The system stability is analyzed, which shows that the LOSAR and the estimation error are uniformly ultimately bounded (UUB). The effectiveness of the PAG law proposed is ensured.
The arrangement of sections is as follows: The relative kinematics equations in two dimensions are introduced in
Section 2. The DSDO and the FPPC-based PAG law are proposed in
Section 3. The the ability of the signals of the interception system to guarantee the UUB is proven in
Section 4. To illustrate how the PAG law works, simulation results are given in
Section 5. Finally, the conclusions are given.
2. Problem Formulation and Preliminaries
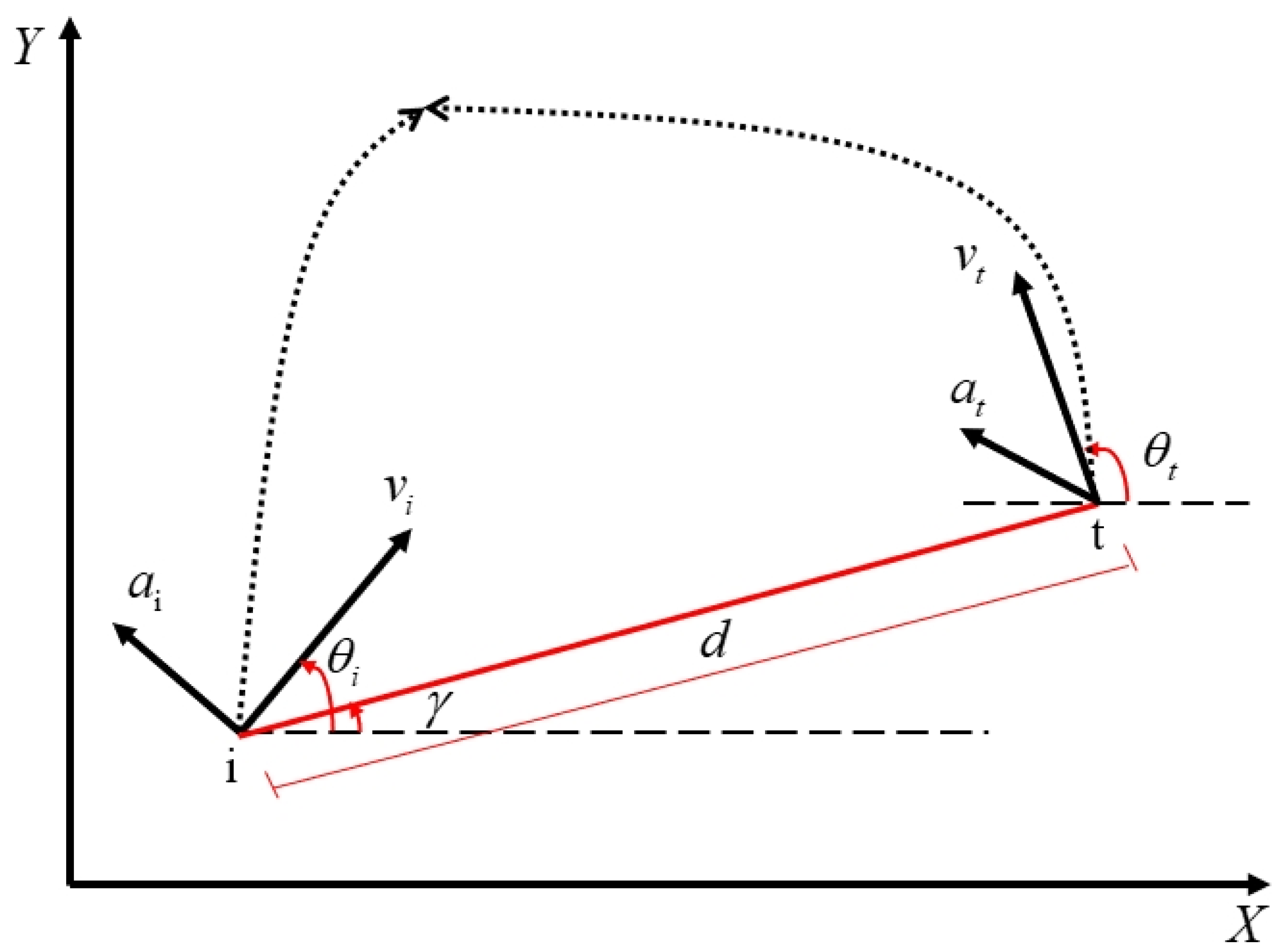
In order to simplify the derivation, both the interceptor and the target are considered as mass points. Both gravity and the aerodynamics model for them are ignored. Specifically, the interceptor and the target are denoted by the symbols of ‘i’ and ‘t’, respectively, and a schematic diagram is provided in
Figure 1. To describe the relative motion dynamics, the relative states consist of the LOSA
, the LOSAR
, the relative distance
, and the relative velocity
.
is the interceptor’s flight-path angles (FPA).
is the target’s FPA. The velocities of the interceptor and the target are represented by
and
, respectively. Both
and
are assumed to be constants. All of these are normal components contained in the horizontal plane and can be measured by the seeker of the interceptor.
In a horizontal plane without air and gravity, the relative kinematical equations for the interceptor–target are given as [
33]
The kinematical equations for the interceptor are given as [
33]
where
and
denote the
x-coordinate and
y-coordinate of the interceptor, respectively. The velocities along
and
are
and
, respectively. The variable
denotes the interceptor’s acceleration normal to its velocity. All of these are normal components contained in the horizontal plane.
In the same way, the kinematical equations of the target are given as [
33]
where
and
denote the
x-coordinate and
y-coordinate of the target, respectively. The velocities along
and
are
and
, respectively.
represents the target’s normal acceleration. It is important to point out that all the states mentioned above, except the target’s acceleration
, can be measured by the seeker of the interceptor. All of them are normal components contained in the horizontal plane.
Considering (1), (2), and (3), the derivative of
is given as [
34]
Thus, the relative kinematic equations are rewritten as [
34]
where
is the target’s acceleration normal to the LOSAR. Because
is unmeasurable,
is treated as a disturbance of the system.
The objective of this paper was to design the interceptor’s acceleration
as a control input that can guarantee
remains in a sufficiently small neighborhood to zero. In other words,
rapidly converges to a neighborhood of a suitable constant under the conditions of the LOSA constraint and simultaneously satisfies the performance indexes of the state and control input. Then, if the relative velocity is negative and the LOSAR is stabilized, the interceptor will finally intercept the target [
35]. Thus, to realize the PAG, we define the tracking error as
where
is the constant tracking command of
.
The derivative of the tracking error
with respect to time is given as
because of the derivative of the tracking command,
is zero for achieving PAG.
In order to carry out follow-up work and take into account the real situation, we made the following assumptions:
Assumption 1. The target’s normal acceleration is continuous, bounded, and differentiable. And satisfies , where is a constant;
Assumption 2 ([
8])
. For the system (5), the LOSAR is controllable when . Thus, in the guidance process, the LOSA γ and the FGA of the interceptor remain in the domain Π
defined by Remark 1 ([
8])
. The guidance system (5) is unavailable when the relative distance . In the TGP, considering the limitations of physical factors such as the interceptor seeker and the receiver overload, there is a minimum distance ; when , the guidance can be considered to end, then the interceptor and the target rely on their own inertia to complete the final guidance task. Remark 2. Considering the field of view of the interceptor’s seeker and the performance of the interception, the LOSA is required to be always in the feasible region , where and are the lower and upper bounds of the region. In this feasible domain, the seeker can measure the system state information at all times. If the LOSA is not in this region, this could cause the escape of the target and thus cause the failure of the interception mission.
3. Finite-Time Prescribed Performance and DSDO-Based Guidance
In this section, PAG is realized using a DSDO and FPPC. The unmeasured target maneuver is estimated by the DSDO and the estimation is fed forward into the system. To improve the interception accuracy, an DSDO is designed whose estimation accuracy is independent of the relative distance. A PAG law is proposed using the FPPC, so that the LOSAR converges to the neighborhood of zero in a specified finite time. The rapid performance and transient performance of the guidance system are ensured.
3.1. Finite-Time Prescribed Performance
The faster the LOSAR converges, the better the speed of the guidance system. Therefore, FPPC is a suitable method for designing a PAG law. In view of the disadvantage of a large overshoot affecting the performance, a finite-time performance function (FTPF) is employed. Considering the seeker’s measurement area and the quality of the PAG, the LOSA error
converges to a bounded region, constrained as follows:
where
and
are the FTPFs. Due to the advantages of PPC, the tracking error can be limited to the preset upper and lower bounds. During the whole guidance process, the LOSA error
is limited to the FTPFs
and
; that is,
. Thus, the LOSA is restricted between
and
. The LOSA is required to be within the region
to achieve a good performance for the guidance system, so the choice of FTPFs should satisfy the inequality, which is given as
Due to the advantages of PPC, the LOSA is maintained in the region during the guidance process. The escape of the target is avoided.
The FTPFs
and
are chosen as [
32]
where
,
,
,
,
,
and
are the constants to be determined, and
is the initial value of the LOSA error.
and
. Correct choice of the above parameters is required to ensure that the inequality (8) is valid.
Remark 3. The parameter τ determines the convergence speed of the FTPFs. The specified finite time determines the convergence time of the LOSAR. In this way, the speed of the guidance system is ensured.
Because of the requirement to ensure that the LOSA error can converge before the end of the guidance, attention should be paid to the selection of
. The time-to-go of the PAG is given as
where
is the minimum distance.
To make the LOSA error converge to a suitable time, the value of
is approximately chosen as
where
is the initial value of the time-to-go and
is a suitable constant.
Remark 4. Since the signs of the FTPFs are related to the initial LOSA error, the sign of the LOSA error remains unchanged in the process of realizing the PAG. This will not only give the system a smaller overshoot but also facilitates the seeker in measuring information during the interception process. This improvement in the measurement quality plays a pivotal role in the improvement in the interception accuracy.
To proceed further, the derivatives of
and
with respect to time are given as
The second-order derivatives of FTPFs are given as
Based on the design flow of the prescribed performance, we convert
into the unconstrained error
, which is expressed as [
32]
where
satisfies
,
. Considering that the
is a monotonically increasing function of the LOSA error, any LOSA error
uniquely corresponds to an unconstrained error
. The task of controlling the constrained error can be transformed into the task of controlling unconstrained error. In this regard, controlling an unconstrained error greatly reduces the difficulty of control. There is no need to worry about interception failure due to an excessive absolute value of LOSA.
The derivative of
respect to time is given as
with
.
Now, the objective to converge the constrained to the neighborhood of zero is transformed into stabilizing the unconstrained error .
3.2. Distance Scalar Disturbance Observer
Generally speaking, the unknown target maneuver is usually treated as the compound disturbance . However, when the interceptor nears the target, due to the extremely small relative distance, the derivative of the compound disturbance will approach infinity. Obviously, the estimation accuracy is seriously affected. Therefore, we project the target acceleration into the LOS coordinate frame and estimate the target’s acceleration normal to the LOSAR by designing an DSDO. The estimation accuracy is better, regardless of the relative distance.
The DSDO is designed as
where
is a constant,
z is an intermediate variable, and
.
The derivative of
z is given as
Substituting (5) into (18) yields
The derivative of the disturbance
is given as
and then, substituting (1) and (3) into (20) yields
Recalling that both
and
are constant and
, it is obtained that
Since the right side of the inequality sign consists of constant terms, the derivative of the disturbance is bounded.
Considering the stability of the DSDO, the error of estimation is defined as
The derivative of
is developed as
where
is bounded and
. Thus, the estimation error will converge to a bounded region, and the designed DSDO can track the unknown disturbance.
Remark 5. This paper provides a design idea for target maneuver estimation that is not limited to a two-dimensional coordinate system. When considering the interception problem of a maneuvering target in a three-dimensional coordinate system, the target acceleration can still be projected onto two components perpendicular to the line-of-sight (LOS) under the LOS frame. In this way, the decoupling of the disturbance and relative distance is realized, and the decline in the estimation accuracy is avoided when the interceptor is near the target.
3.3. Parallel Approaching Guidance Design
As above, the LOSA error
is converted to an unconstrained
using an error transformation function, and the projected target acceleration is estimated by the DSDO using the system states. In order to achieve PAG, we use the system states and the estimation
to design a PAG law that can stabilize
and then input the PAG law into the interception system. The structure of the interception system of this paper is shown in the
Figure 2. Considering the principle of the PAG making the LOSAR remain zero, the PAG law is obtained using the method of backstepping. To proceed further, we define
,
, where
is a virtual law to be designed. To stabilize the transformed error, just like in the common stability analysis process, we define
, and its derivative is given as
We design the stabilizing function
as
where
is a constant. In fact,
can be understood as the desired LOSAR, which can stabilize
.
Inserting (26) into (25) yields
We define the stability function as
To proceed further, the derivative of
is given as
The derivative of the variable
is given as
where
.
To stabilize the transformed error and the LOSAR, we design the PAG law as
where
is the stability term, which will be mentioned below, and
is a regulation factor.
In this way, the LOSAR is stabilized within the given time
and remains in a small enough neighborhood of zero until the end of guidance. The implementation mechanism of the PAG is shown in
Figure 3.
5. Simulation Results
To prove the feasibility of the PAG law, three scenarios were considered in this section. In addition, the guidance performances of the PAG law in the three scenarios were compared with those of PNG. The selections of the initial system states and the controller parameters are given in
Table 1 and
Table 2. The simulation results for the three Scenarios were as follows:
Scenario 1 (
Constant Acceleration): The acceleration of the target is given by
g. Considering the target for a circular maneuver,
g, when
. It is apparent that the LOSAR was not stabilized, and the minimum distance could not be reached, see
Figure 4. That means the interception was unsuccessful when
. Then, we fed the FPPC-based guidance law into the system. From
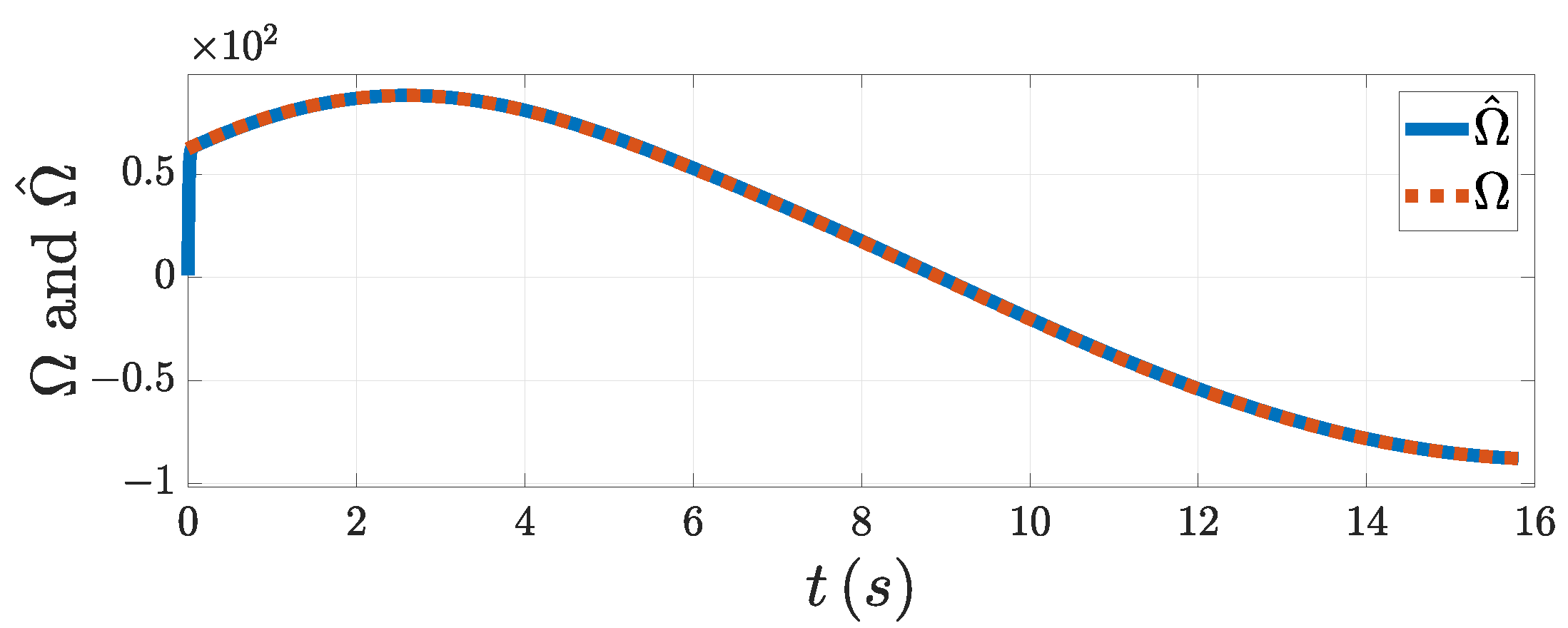
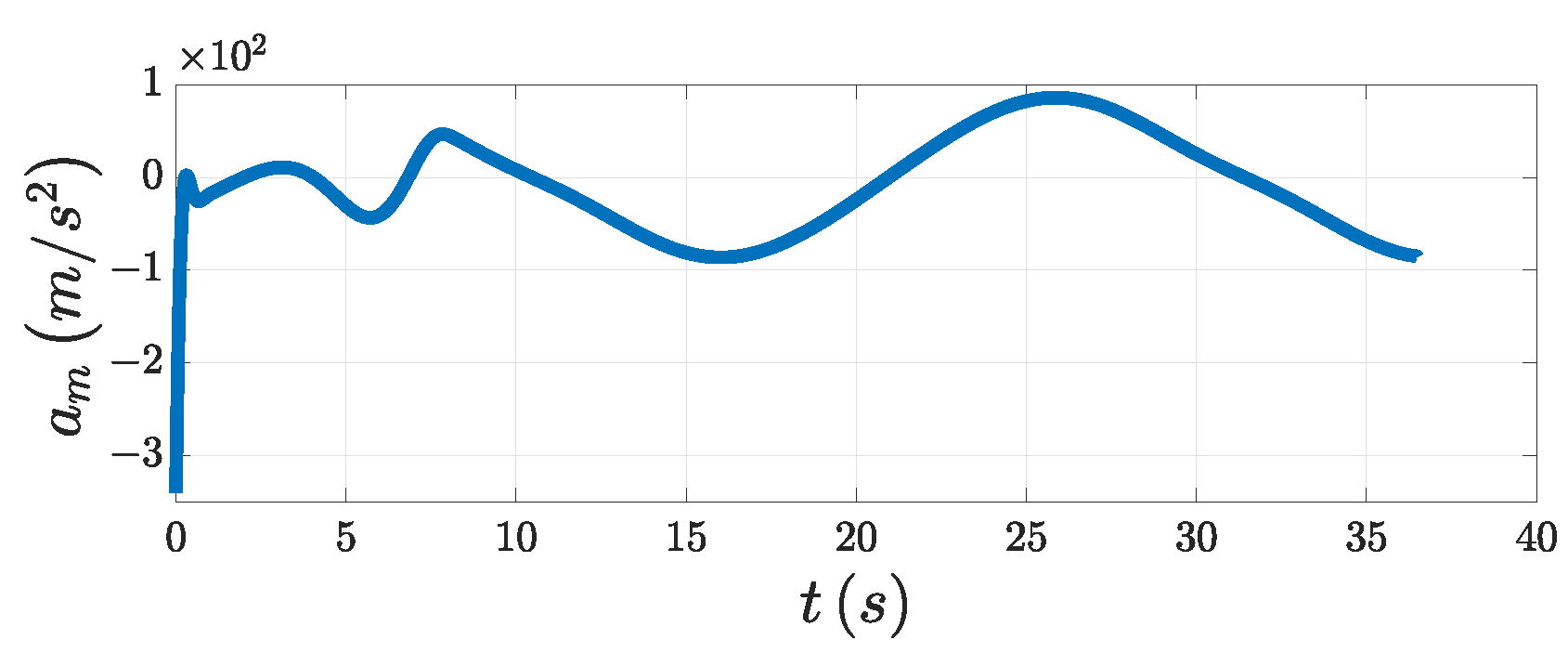
Figure 5, the DSDO could track the target’s maneuver well using the designed PAG law. This means that the influence of the target maneuver on the guidance accuracy could be compensated for well after the estimation of DSDO was input into the system. From
Figure 6a,c, both the tracking error and the LOSAR were stabilized with the FPPC in the specified finite time
. As can be seen in
Figure 4a, the overshoot of the tracking error was small. That means that the smooth change in LOSA gave the system a good performance. If the relative velocity is negative, that is,
, when the LOSAR remains in a small enough neighborhood of origin, PAG will be realized. From
Figure 6b, the relative velocity was negative when the LOSAR was stabilized. In
Figure 6d, the relative distance finally converged to the minimum distance. The miss distance is shown in
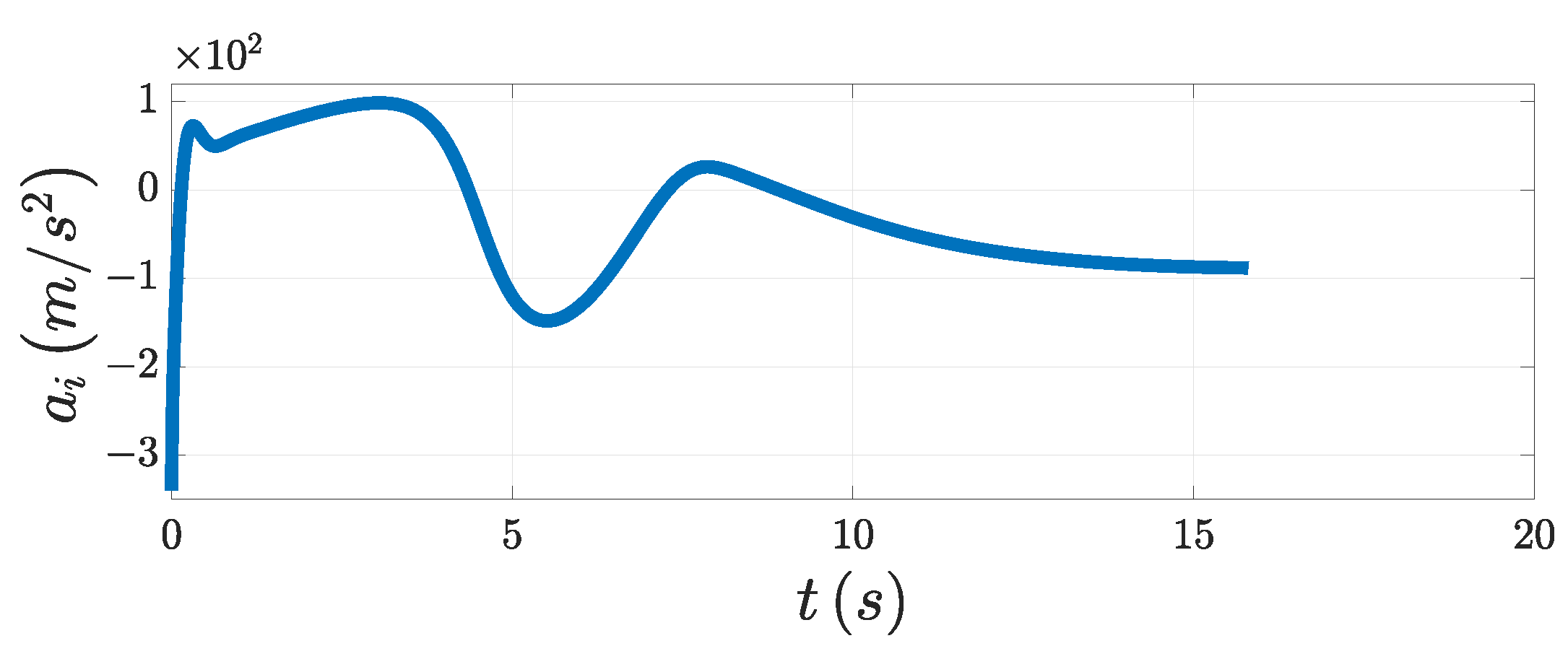
Table 3. The PAG law is presented in
Figure 7. In addition, in
Figure 8, we can see the trajectories of both the interceptor and the target. Therefore, the effectiveness of the PAG law was illustrated when the target performed a circular maneuver.
Scenario 2 (
Sine Acceleration): The acceleration of the target was set to
g
. For the follow-up comparison, we considered a situation where
. It is apparent that the LOSAR was not stabilized and the minimum distance could not be achieved, see
Figure 9. That means the interception was unsuccessful when
. From
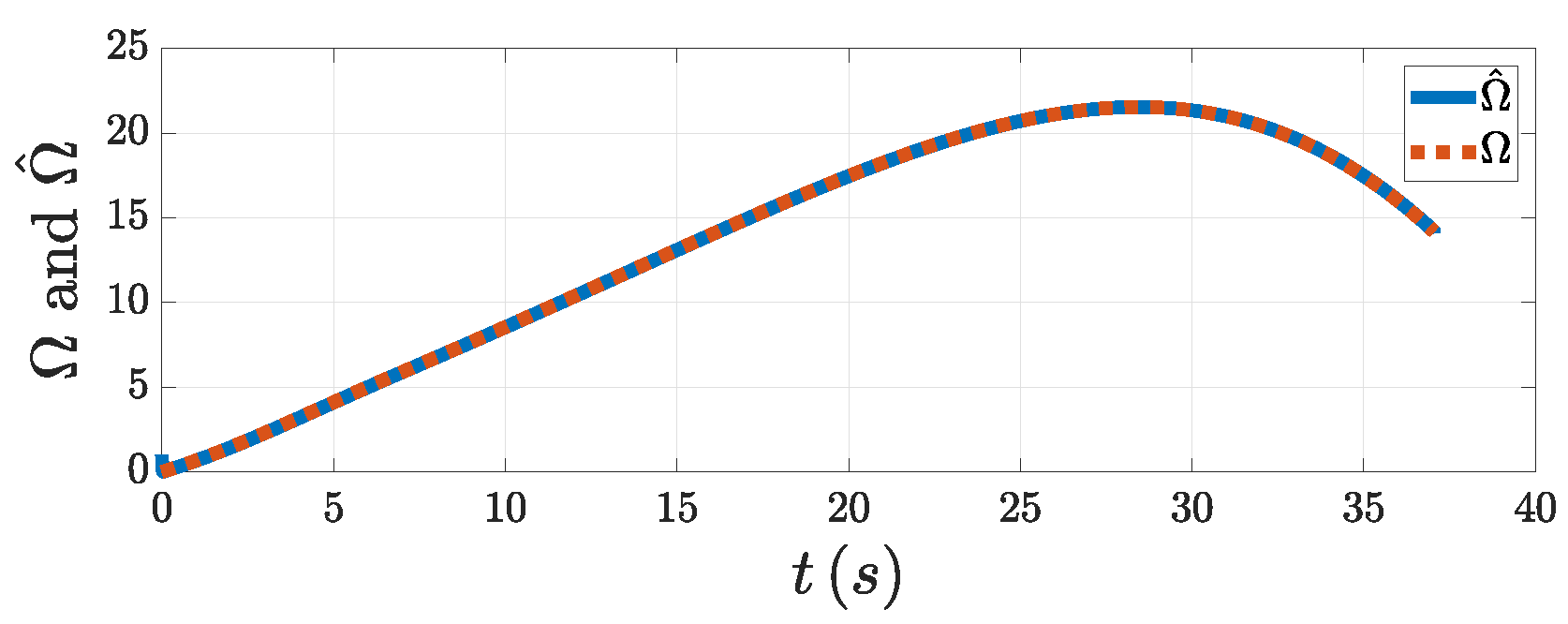
Figure 10, the DSDO could track the target’s maneuver well using the PAG law. That means that the influence of the target maneuver on the guidance accuracy could be well compensated for after the estimation of DSDO was input into the system. From
Figure 11a,c, both the tracking error and the LOSAR were stabilized with the FPPC within the specified finite time
. As can be seen in
Figure 11a, the overshoot of the tracking error was small. That means that the smooth change in LOSA gave the system a good performance. From
Figure 11b, the relative velocity was negative when the LOSAR remained in the neighborhood of zero. As seen in
Figure 11d, the relative distance finally converged to the minimum distance. The PAG law is shown in
Figure 12. In addition, from
Figure 13 we can see the trajectories of both the interceptor and the target. Therefore, the effectiveness of the PAG law is illustrated.
Scenario 3 (
Square-Like Acceleration): The acceleration of the target
was given by a square-like signal, the amplitude of the signal was 9 g, and the frequency was
rad/s. Considering the target for a square-like maneuver when
, the LOSAR and the relative distance were as shown in
Figure 14. The interception was unsuccessful when
. As seen in
Figure 15, the DSDO could track the target’s maneuver well using the PAG law. That means the influence of the target maneuver on the guidance accuracy could be well compensated for after the estimation of the DSDO was input into the system. From
Figure 16a,c, both the tracking error and the LOSAR were stabilized using the FPPC within the specified finite time
. As can be seen in
Figure 14a, the overshoot of the tracking error was small. That means that the smooth change in the LOSA gave the system a good performance. From
Figure 16b, the relative velocity was negative when the LOSAR remained in a small enough neighborhood to zero. In
Figure 16d, the relative distance finally converged to the minimum distance. The PAG law is shown in
Figure 17. In addition, in
Figure 18, we can see the trajectories of both the interceptor and the target. Therefore, the effectiveness of the guidance law was illustrated when the target performed a square-like maneuver.
In order to illustrate the guidance performance of the PAG law designed in this paper, we used the existing PNG method for a comparative analysis. The PNG law is given as [
36]
where
is the unitless coefficient of PNG. In this section,
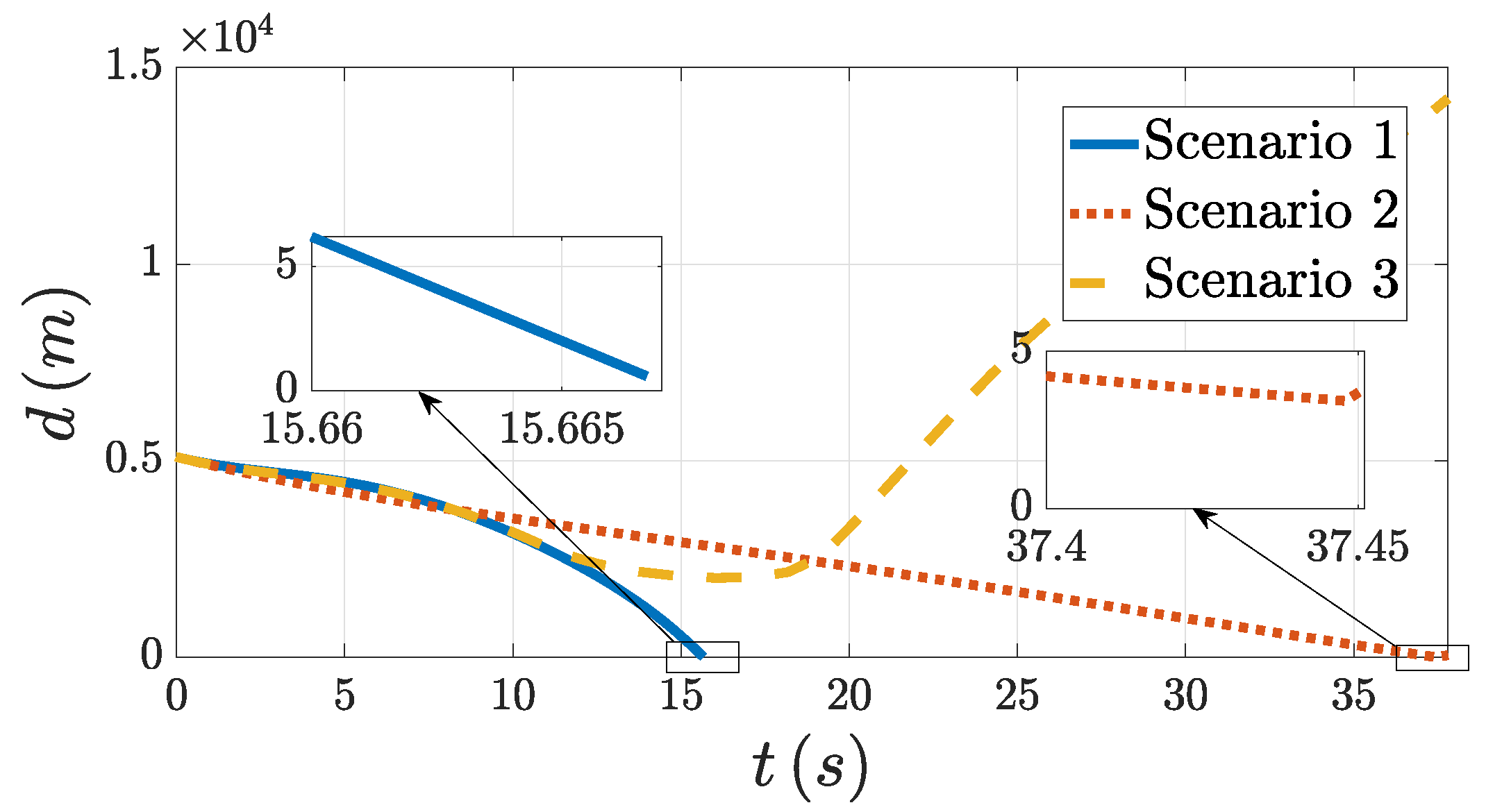
. Then, we input the PNG law into the system (5) and compared its guidance performance with the PAG law designed in this paper for Scenario 1, Scenario 2, and Scenario 3. The relative distance with the PNG law (40) is shown in
Figure 19.
The guidance accuracies of the interceptor with the PNG law (40) and the PAG law designed in this paper in the different scenarios are shown in
Table 3.
Through comparing the precision of PNG and PAG in the different scenarios, it was seen that the PAG law designed in this paper had a higher precision in the cases of intercepting the three kinds of target maneuvers. The precision of PNG in the three cases was inferior to that of the PAG. When intercepting a target performing a square wave maneuver, the interceptor even missed the target. Therefore, it is not difficult to see that the PAG law based on the FPPC had a stable accuracy when intercepting large maneuvering targets. This is because the designed DSDO can estimate the target maneuver well, and the FPPC is designed such that the LOSA error can be kept within the preset bounds during the guidance process.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
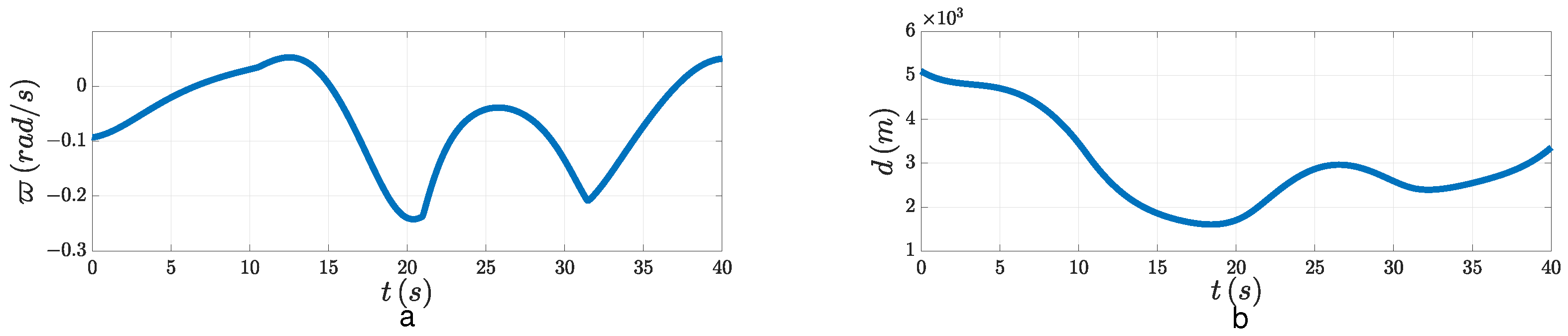{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}