2.1. The Equipment
The propagation of infrared light requires a medium, and when the propagation medium is a uniform medium, the propagation of infrared light is a straight line. When infrared light needs to pass through two media with different refractive indices, its propagation path will change due to the refraction phenomenon. The reverse saturation current of the infrared photodiode depends on the intensity of the infrared light it receives at a fixed frequency. When the intensity changes, the reverse saturation current of the infrared photodiode also changes. Therefore, in the process of infusion, it is only necessary to fix a device which can emit infrared light with fixed frequency and intensity at one end of the transparent infusion tube, such as an infrared light-emitting diode, and fix another infrared photodiode at its relative position to detect the change of light transmission medium in the infusion tube. When there is no drop, there is only air in the infusion tube as a light propagation medium, and the infrared light propagates in a straight line. At this time, the infrared photodiode can receive infrared light of a certain intensity. When the liquid drops in the infusion tube, the light propagation medium in the infusion tube becomes air and water droplets. Due to the refraction phenomenon, the infrared ray propagation path emitted by the infrared light-emitting diode changes, so the infrared ray intensity received by the infrared receiving photodiode will change.
Figure 1 shows the schematic of the infusion monitor while it is in operation.
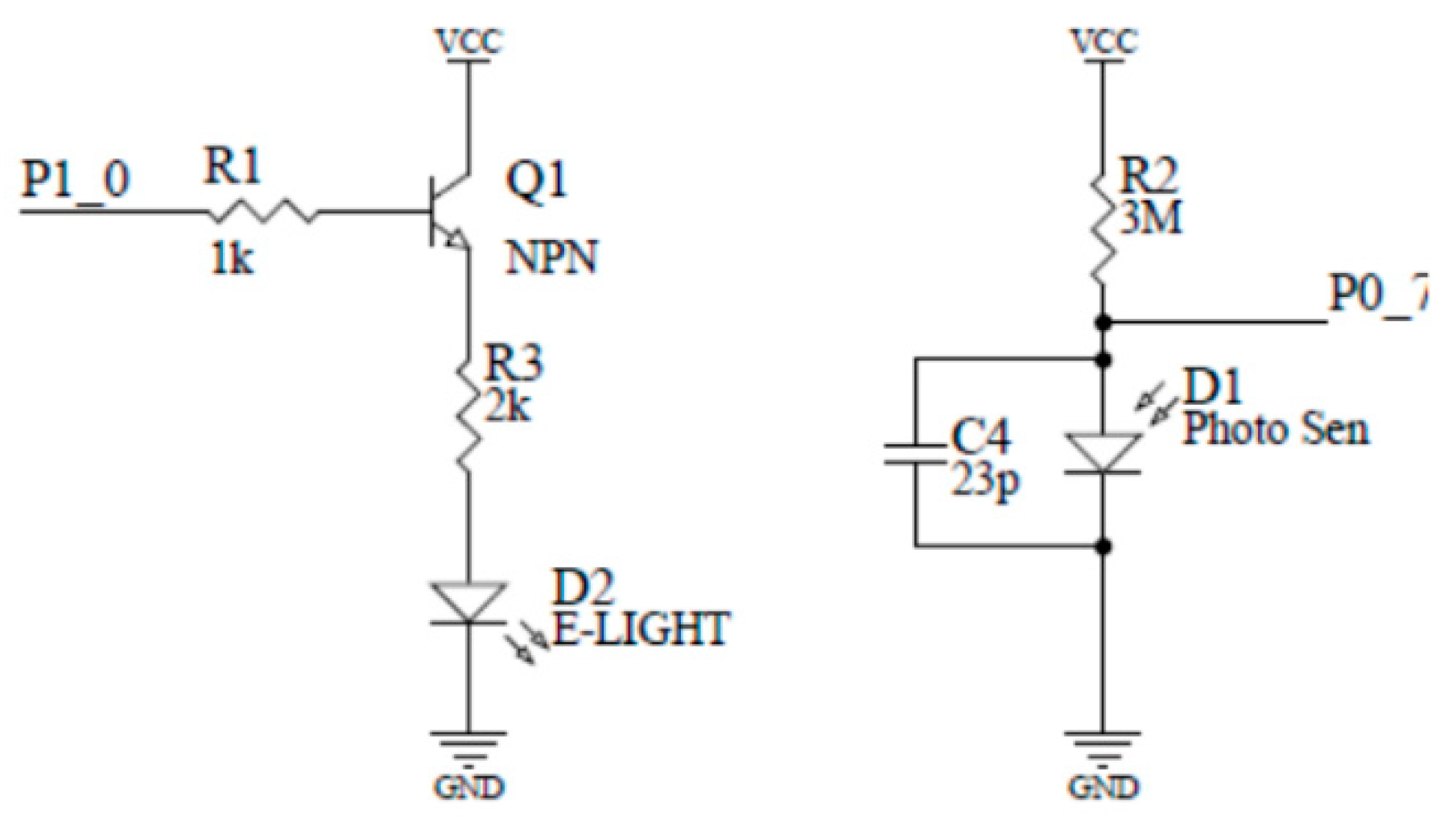
Infrared light-emitting diodes require a constant current to emit a constant intensity of light. In addition, infrared photodiodes need to convert current changes into digital signals and send them to the processor. There are a lot of active devices that can well meet the performance requirements of this circuit, but it will cause a significant increase in power and cost. The circuit shown in
Figure 2 uses a bipolar junction transistor (BJT) constant current drive circuit and a passive resistor–capacitor op amp circuit to complete the relevant design requirements.
BLE4.0 is a wireless communication method widely used in embedded devices, so this paper chose the chip CC2540 that supports BLE4.0 as the MCU of the device.
Figure 3 shows the MCU and wireless communication circuitry of the device. The infusion monitor device needs to receive the data sent by the host computer while transmitting the signal detected by itself to the upper computer, so the control of the system and the realization of the wireless communication are all required. The CC2540 is a wireless RF micro-controller that can communicate wirelessly with the host computer via the BLE4.0 communication protocol and the onboard inverted-F antenna [
21] while completing system control. The PIN10 on the CC2540 is used to control the on and off of the BJT current to achieve LED illumination control to reduce power consumption. The PIN07 converts the analog voltage signal output from the infrared photodiode circuit into a digital signal through the ADC. The antenna section contains a balun circuit [
22] to ensure that the inverted F antenna operates in a better state.
The core of the infusion monitor is to judge the drop of the droplet by the characteristics of the collected voltage signal and calculate the infusion speed and the infusion volume according to the correlation coefficient of the droplet tube. However, since the ambient light and temperature have a great influence on the characteristics of the infrared photodiode, a simple voltage shaping circuit cannot output a correct counting pulse. At the same time, the influence of temperature on the reverse saturation current of the photodiode makes the threshold judgment mode not well applied. The environmental noise will cause a large counting error in the edge judgment mode. The complex signal processing circuit will bring higher cost and energy consumption, which has a bad influence on the application prospect of the device.
What we can be sure of is that there is at least one inflection point in the voltage waveform of each droplet—of course, this does not mean that an inflection point is a droplet. Therefore, the inflection point of the voltage waveform can be used as one of the features for further judging whether or not there is a drop. At this point, our problem becomes judging whether the inflection point of a voltage signal represents the landing of a droplet. This is a typical two-category problem.
2.2. The Data Reduction Method
Logistics classifiers are a very common two-classification method. However, with the general logistics classification method, it is difficult to find a set of parameters applicable to different environments; if the environmental conditions are compensated, it is necessary to add new sensors, but such practice will still increase the cost and energy consumption of equipment. Considering that the environmental change of the equipment is continuous and gradual, the rate of change of infusion speed should be within a certain range. Therefore, the voltage characteristic and the last drop time characteristic can help judge the environment, and this change compensates. In this way, we can control the accuracy error caused by environmental changes within the first drop. Once the first drop is judged to be accurate, our equipment can work with high performance in a variety of environments.
However, the CC2540 chip used in this design has limited computing power and storage space, and it also needs to be responsible for wireless communication control, so it is difficult for it to carry out large-scale computation and excessive data storage.
Data dimensionality reduction is a compression of data. To correctly reduce the dimension of data, the first thing is to ensure that the data after the dimension reduction can also carry the information carried by the original data. Since CC2540′s computing power is not strong, the dimension reduction method used in this paper can not be too complex. This paper uses a one-step operation to compress the data and uses the data collected by the device to automatically train the parameters of this step. In order to ensure that the compressed data can carry the information expressed by the original data when training the compression operation parameters, it must be ensured that the compressed data can be restored to the original data through a one-step operation.
Through observation and summary, it is found that the data of at least seven sampling points near the inflection point should be used to represent the waveform changes caused by droplets. That is to say, the voltage input signal
is a seven-dimensional vector. In order to simplify the calculation, this paper uses a three-dimensional vector to represent its hidden features. So, this paper proposed the following two steps:
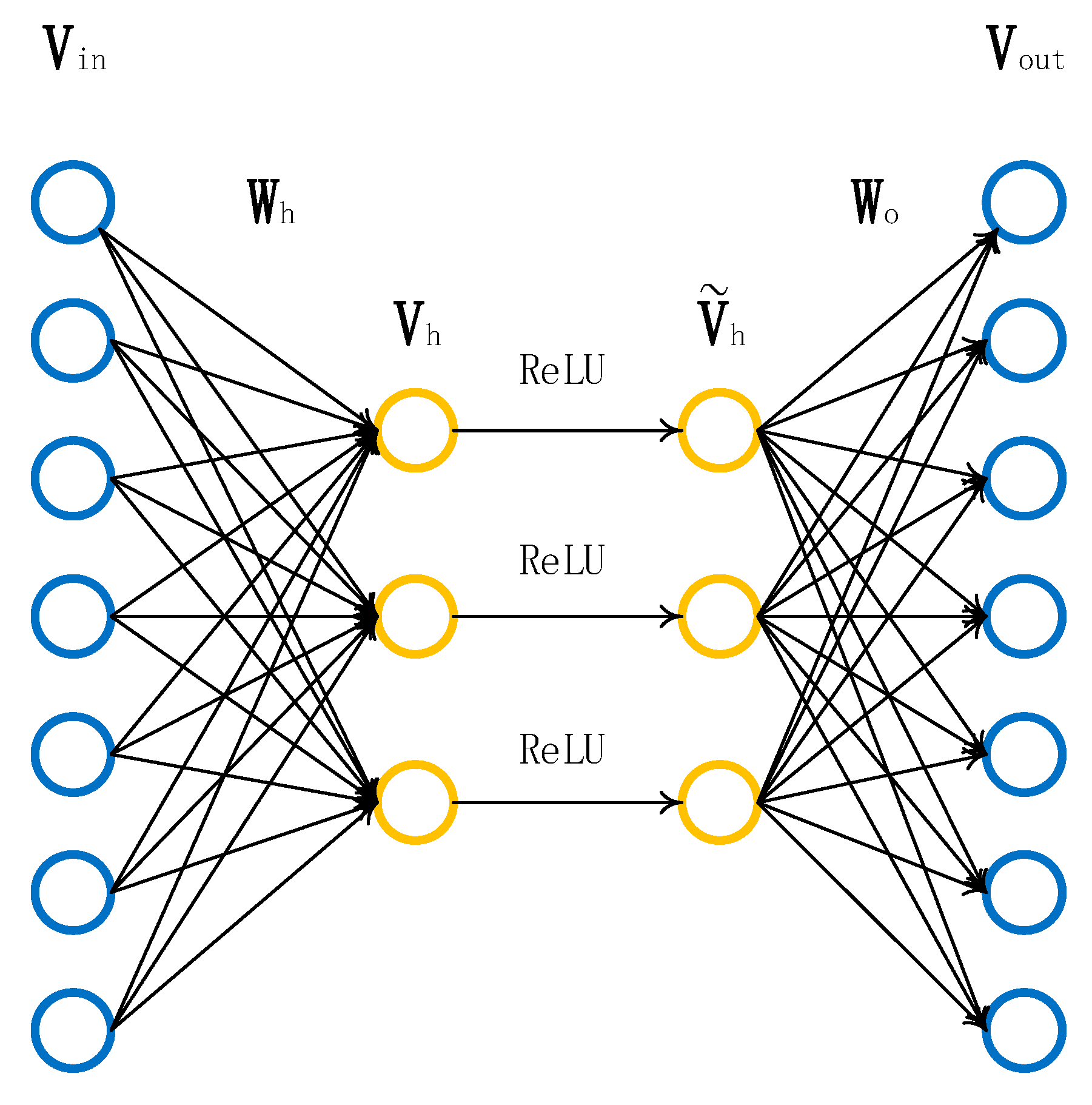
The intermediate variable is the feature that we want to extract, and the output signal is the vector equal to the input signal . For these two operations, we do not care about the specific form of the output signal and its mapping mode because they just reproduce the input signal. What is really needed is as the intermediate variable and its mapping method, , because under the premise that the intermediate variable is different from the input signal , the system can also restore the input signal through the intermediate variable , which indicates that the intermediate variable has all the information input signal carries, but it is expressed in a different form. This shows that the intermediate variable has completed the task of data dimensionality reduction.
For mapping
and mapping
, the most intuitive and efficient operation is linear transformation:
However, the intermediate variable
obtained by this method has a serious problem. Since there is only a linear link in the operation process, when the weight matrix
and the offset matrix
are acquired, there may be a problem that the feature expression is insufficient. So, this paper adds a nonlinear transformation between
and
, and make its output
as the final voltage characteristic. The expression for
is
Figure 4 shows the node calculation diagram after adding a nonlinear transformation, in which the constant bias term is omitted.
The following shows how to get the parameters
and
from the data samples. First, this paper takes the actual voltage data that needs to be extracted by the model as the sample data set and ensures that the data volume of this data set enables us to obtain the optimal parameters. After taking the samples, first, assign the weight matrices
and
to a set of values in a random manner and initialize the bias matrices
and
to zero vectors. Obviously,
is completely different from
and has a big difference. In order to narrow the difference between the two, it is needed to define a function to measure this difference; here, we use the mean square function:
The constant coefficient 1/2 makes the constant coefficient after deriving the squared term is 1, which makes the formula form in the parameter optimization process simpler. Obviously, the smaller the error, the closer the output value
is to the input value
, and the error is zero when the two are equal. In a given sample data set, this error is only related to the parameters of the model, so it can be recorded as a function with the model parameters as parameters. In addition, this paper measures the quality of the model parameters using the average of all sample errors in the sample data set:
In the optimization process, we want to find a set of model parameters, denoted as, to minimize the mean square function of the training samples:
In addition, the next step is iterate over the parameters of the model so that each iteration may reduce the value of the mean squared function. In each iteration, a small batch of B is randomly selected at first, which contains a fixed number of training samples. Then, the mean square error of the derivative of the data samples with respect to the model parameters is calculated. Then, you take the product of that with a positive number reduction as model parameters in this iteration.
After the iteration is complete, this paper takes another dataset from outside the training dataset and names it the test dataset. The test data set is also the actual voltage data from the device. The test data is taken as the input of the model, the mean square error function value of the model is calculated, and the quality of the model parameters is evaluated by the magnitude of the function value. If the mean squared function value is close to 0, the model parameters meet the requirements; otherwise, iterate again.
Logistics classifiers have a good performance in the two-class problem and have been widely used in various fields such as medicine, the environment, and society. In this design, to complete the task of droplet counting, the first thing to do is whether there is a drop at a point in time. For a sampling time point, there are two states of “with droplets” and “without droplets”. The formula for the logistic classifier is
The value of the voltage on both sides of the transfer voltage inflection point and the time interval between it and the inflection point indicated by the droplet before are used to judge whether the droplet exists. Therefore, the voltage characteristic signal and time interval signal are used as the input of logistic regression, and the probability of occurrence of these two states is taken as the output of logistic regression.
The content of the function
h is trained by the sample data. The gradient descent optimization method is still used when training the weight matrix [
23,
24]. The difference from the general regression problem is that it does not need the prediction probability to be exactly equal to the label probability. Only the predicted value of the correct result is greater than the other result, so the mean squared loss will no longer apply. The cross-entropy loss is very suitable for measuring the difference between two probability distributions. Therefore, this paper used the cross-entropy loss as the loss function of the model when optimizing the weight matrix of logistic regression. The specific formula for cross-entropy loss in this model is
In the above formula, represents the tag value of the sample data, and its elements and must be one for 0 and the other for 1; is a probability prediction value obtained after the sample data is calculated, and the elements and are values between 0 and 1.
The node calculation diagram of the actual application of the data dimensionality reduction model and the logistics classifier designed in this paper is shown in
Figure 5.
For its briefness, efficient and accuracy. Other machine learning methods would be too complicated for this equipment; it is hard to classify the pseudo-code in this situation, as shown in Algorithm 1, where
is the step size,
is the specific gravity of the sliding gradient,
is a constant for stability,
is a small sample size.
| Algorithm 1 Data reduction algorithm |
Input: Data set:
Number of small batch samples:
Training super parameters:
Iteration times:
Output: and
Process:
fordo for do ) = end for end for;
|
2.3. Logistic Classifier
When the droplet falls, the voltage signal will appear in a waveform that rises first and then falls. According to this feature, the inflection point of the voltage signal, especially the inflection point from rise to fall, can be used as the characteristic point. However, since there may be such a turning point in the noise, it is not directly believed that such a turning point is a drop of water. Therefore, this paper inputs the voltage value at the inflection point, the voltage values of the first three inversion points, and the latter three sampling points into the model of feature extraction to obtain a three-dimensional voltage feature vector.
In order to make the equipment adapt to the changes of the environment, it is necessary to ensure that the logistic classifier has higher accuracy for the sample data in different environments. However, it has been found through experiments that if only one voltage value at the inflection point is used as the input variable, it is difficult to adapt the voltage signal in different environments through one set of parameters. Therefore, before the current inflection point, the knee voltage characteristic which is judged to have a drop point is used as a reference for the input signal. In addition, considering that the droplet velocity change of the droplet should be in a certain range, the interval between the droplets also has a certain influence on the confidence of the droplet existence, so this paper puts the interval between the current inflection point and the previous droplet. The time interval and the time interval of the last drop are separately inputted into the classifier as time influence factors. When the system has not yet collected the droplets during the startup, this paper burns a set of pre-set data with the appropriate droplet data into the program as the data of the 0th droplet. This approach can only control the interference caused by environmental changes in the judgment of the first droplet. Once the first droplet is judged, the system can start executing the high-precision droplet judgment algorithm.
Summarizing the above steps, the droplet detection algorithm proposed in this paper is shown in
Figure 6.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}