
Neural Annealing and Visualization of Autoregressive Neural Networks in the Newman–Moore Model


Abstract
:1. Introduction
2. The Newman–Moore Model
3. Methods
3.1. The Recurrent Neural Network Ansatz
3.2. Variational Neural Annealing
| Algorithm 1 Variational neural annealing |
|
|
3.3. Loss Landscape Visualization
| Algorithm 2 Loss landscape visualization procedure |
|
|
4. Results and Discussion
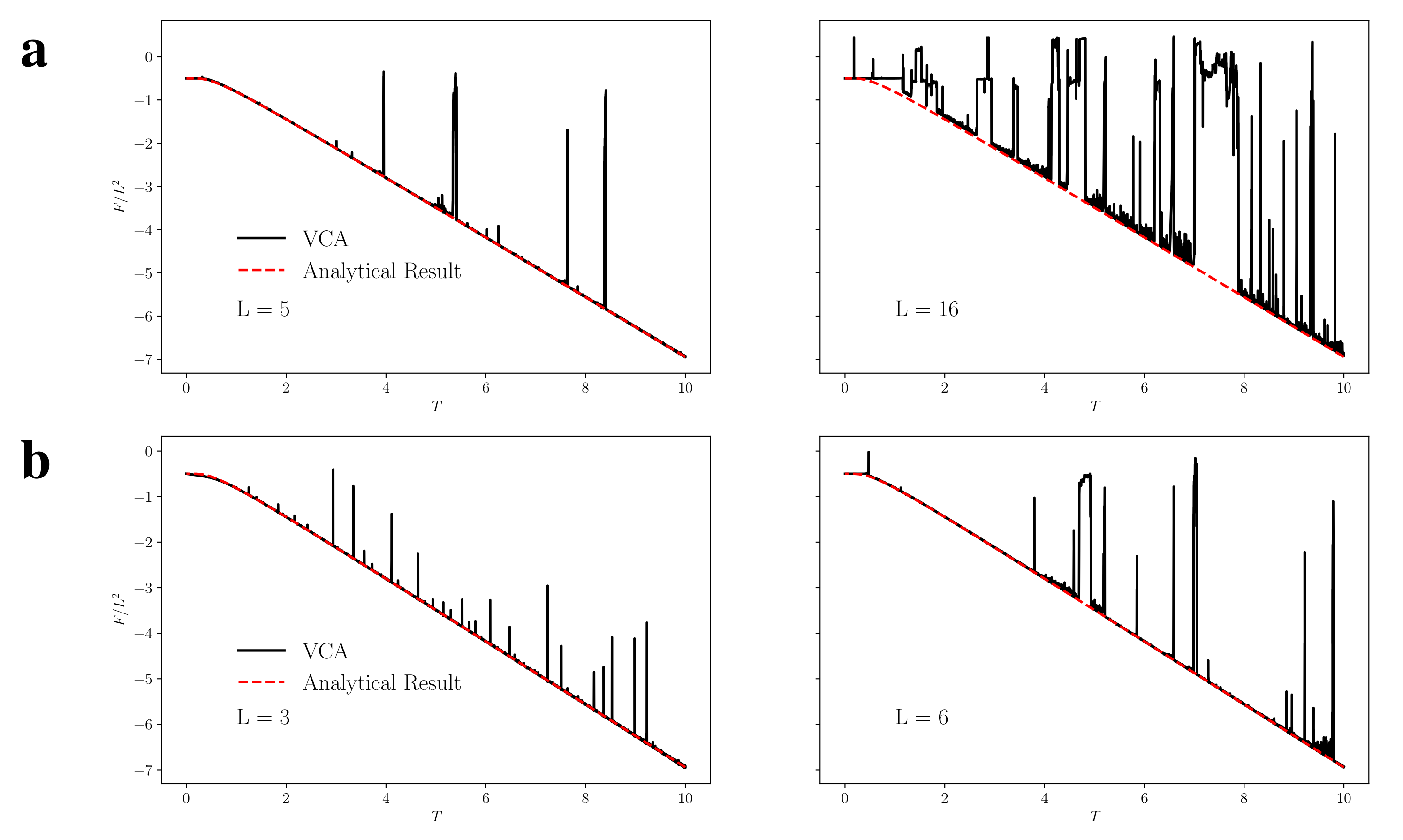
4.1. Variational Classical Annealing
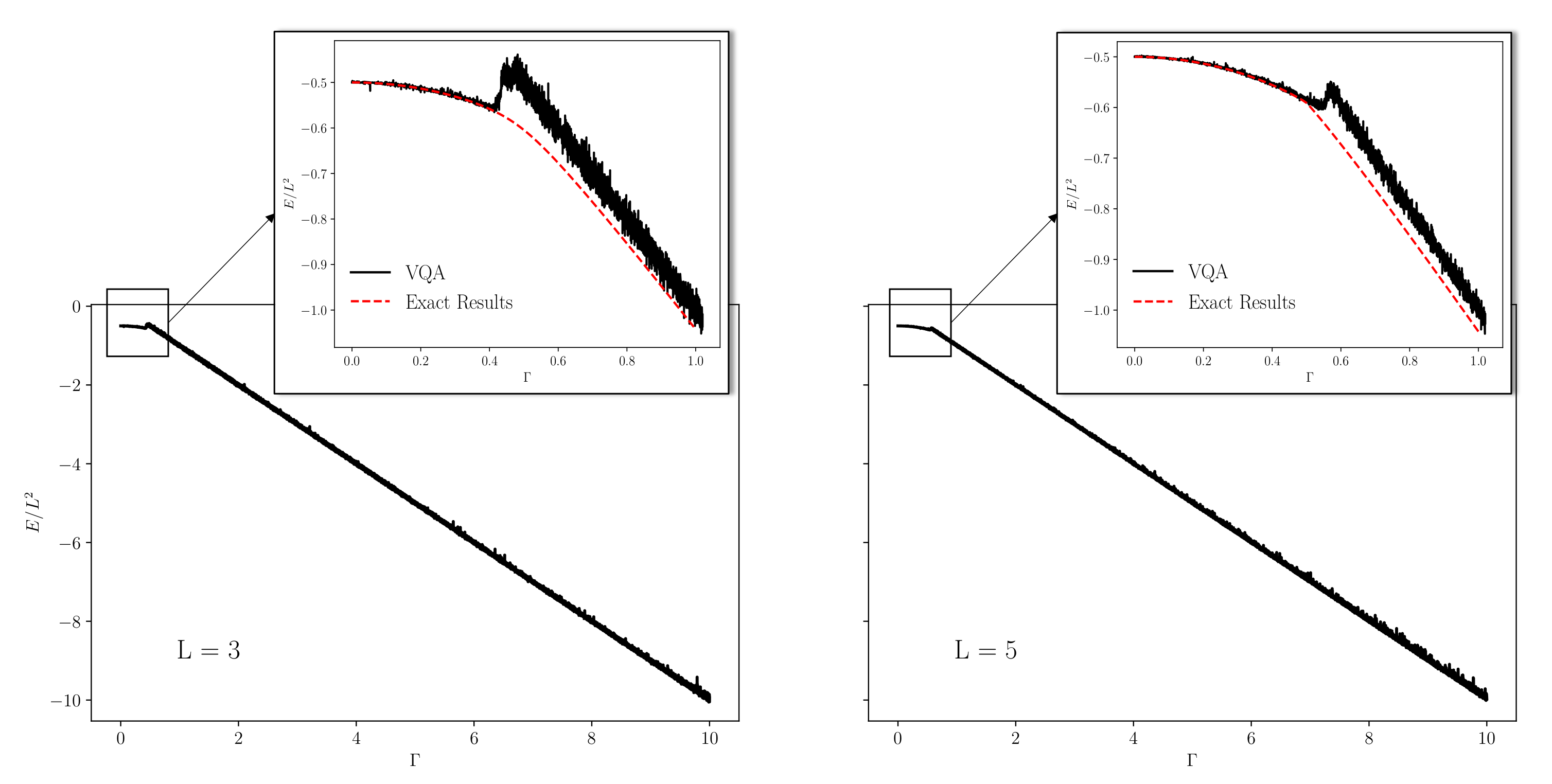
4.2. Variational Quantum Annealing
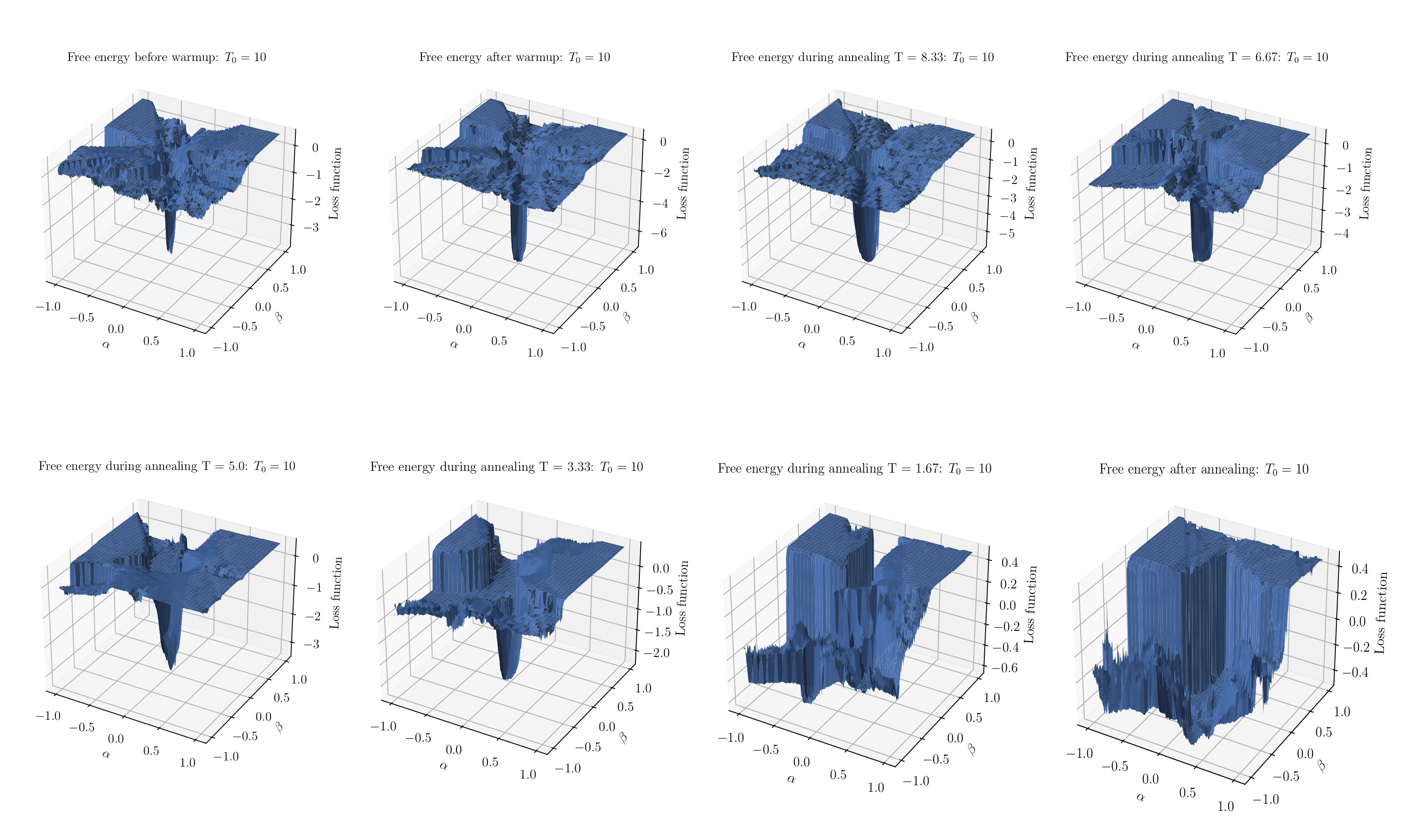
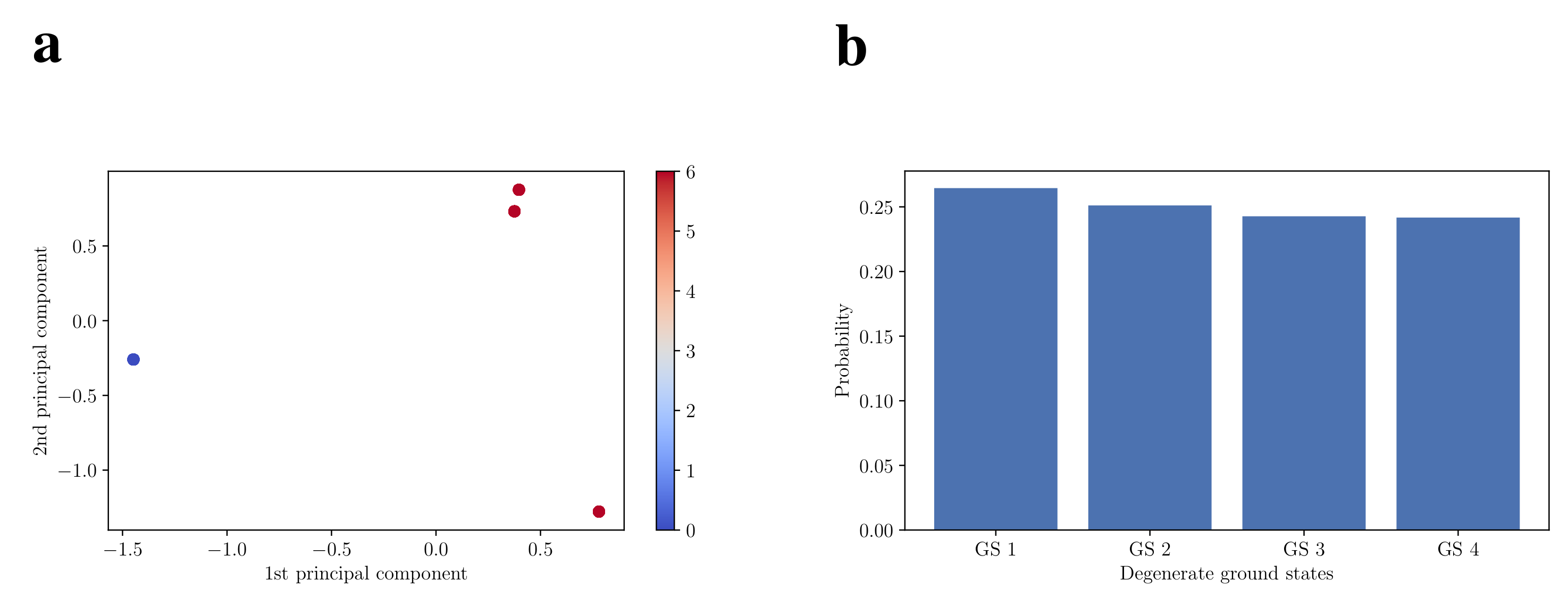
4.3. Loss Landscapes
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameters | Values |
|---|---|
| Initial temperature | |
| Initial transverse field | |
| Number of warmup steps | |
| Number of training steps | |
| Number of annealing steps | 10,000 |
| Number of samples | |
| Batch size | |
| Hidden state dimension | |
| Learning rate | |
| Number of grid points |
References
- LeCun, Y.G.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Carleo, G.; Cirac, I.; Cranmer, K.; Daudet, L.; Schuld, M.; Tishby, N.; Vogt-Maranto, L.; Zdeborová, L. Machine learning and the physical sciences. Rev. Mod. Phys. 2019, 91, 045002. [Google Scholar] [CrossRef] [Green Version]
- Torlai, G.; Melko, R.G. Learning thermodynamics with Boltzmann machines. Phys. Rev. B 2016, 94, 165134. [Google Scholar] [CrossRef] [Green Version]
- Wang, L. Discovering phase transitions with unsupervised learning. Phys. Rev. B 2016, 94, 195105. [Google Scholar] [CrossRef] [Green Version]
- Carrasquilla, J.; Melko, R. Machine learning phases of matter. Nat. Phys. 2017, 14, 431–434. [Google Scholar] [CrossRef] [Green Version]
- Van Nieuwenburg, E.; Liu, Y.; Huber, S. Learning phase transitions by confusion. Nat. Phys. 2017, 13, 435–439. [Google Scholar] [CrossRef] [Green Version]
- Deng, D.L.; Li, X.; Das Sarma, S. Machine learning topological states. Phys. Rev. B 2017, 96, 195145. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Qi, Y.; Meng, Z.Y.; Fu, L. Self-learning Monte Carlo method. Phys. Rev. B 2017, 95, 041101. [Google Scholar] [CrossRef] [Green Version]
- Inack, E.M.; Santoro, G.E.; Dell’Anna, L.; Pilati, S. Projective quantum Monte Carlo simulations guided by unrestricted neural network states. Phys. Rev. B 2018, 98, 235145. [Google Scholar] [CrossRef] [Green Version]
- Parolini, T.; Inack, E.M.; Giudici, G.; Pilati, S. Tunneling in projective quantum Monte Carlo simulations with guiding wave functions. Phys. Rev. B 2019, 100, 214303. [Google Scholar] [CrossRef] [Green Version]
- Pilati, S.; Inack, E.M.; Pieri, P. Self-learning projective quantum Monte Carlo simulations guided by restricted Boltzmann machines. Phys. Rev. E 2019, 100, 043301. [Google Scholar] [CrossRef] [Green Version]
- Albergo, M.S.; Kanwar, G.; Shanahan, P.E. Flow-based generative models for Markov chain Monte Carlo in lattice field theory. Phys. Rev. D 2019, 100, 034515. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Rossi, R.; Carleo, G. Unbiased Monte Carlo cluster updates with autoregressive neural networks. Phys. Rev. Res. 2021, 3, L042024. [Google Scholar] [CrossRef]
- Czischek, S.; Moss, M.S.; Radzihovsky, M.; Merali, E.; Melko, R.G. Data-Enhanced Variational Monte Carlo for Rydberg Atom Arrays. arXiv 2022, arXiv:2203.04988. [Google Scholar] [CrossRef]
- Carleo, G.; Troyer, M. Solving the quantum many-body problem with artificial neural networks. Science 2017, 355, 602–606. [Google Scholar] [CrossRef] [Green Version]
- Torlai, G.; Mazzola, G.; Carrasquilla, J.; Troyer, M.; Melko, R.; Carleo, G. Neural-network quantum state tomography. Nat. Phys. 2018, 14, 447–450. [Google Scholar] [CrossRef] [Green Version]
- Cai, Z.; Liu, J. Approximating quantum many-body wave functions using artificial neural networks. Phys. Rev. B 2018, 97, 035116. [Google Scholar] [CrossRef] [Green Version]
- Hibat-Allah, M.; Ganahl, M.; Hayward, L.E.; Melko, R.G.; Carrasquilla, J. Recurrent neural network wave functions. Phys. Rev. Res. 2020, 2, 023358. [Google Scholar] [CrossRef]
- Carrasquilla, J. Machine learning for quantum matter. Adv. Phys. X 2020, 5, 1797528. [Google Scholar] [CrossRef]
- Szabó, A.; Castelnovo, C. Neural network wave functions and the sign problem. Phys. Rev. Res. 2020, 2, 033075. [Google Scholar] [CrossRef]
- Westerhout, T.; Astrakhantsev, N.; Tikhonov, K.S.; Katsnelson, M.I.; Bagrov, A.A. Generalization properties of neural network approximations to frustrated magnet ground states. Nat. Commun. 2020, 11, 1593. [Google Scholar] [CrossRef] [Green Version]
- Park, C.Y.; Kastoryano, M.J. Expressive power of complex-valued restricted Boltzmann machines for solving non-stoquastic Hamiltonians. arXiv 2021, arXiv:2012.08889. [Google Scholar] [CrossRef]
- Bukov, M.; Schmitt, M.; Dupont, M. Learning the ground state of a non-stoquastic quantum Hamiltonian in a rugged neural network landscape. SciPost Phys. 2021, 10, 147. [Google Scholar] [CrossRef]
- Li, H.; Xu, Z.; Taylor, G.; Studer, C.; Goldstein, T. Visualizing the Loss Landscape of Neural Nets. arXiv 2018, arXiv:1712.09913. [Google Scholar]
- Huembeli, P.; Dauphin, A. Characterizing the loss landscape of variational quantum circuits. Quantum Sci. Technol. 2021, 6, 025011. [Google Scholar] [CrossRef]
- Rudolph, M.S.; Sim, S.; Raza, A.; Stechly, M.; McClean, J.R.; Anschuetz, E.R.; Serrano, L.; Perdomo-Ortiz, A. ORQVIZ: Visualizing High-Dimensional Landscapes in Variational Quantum Algorithms. arXiv 2021, arXiv:2111.04695. [Google Scholar]
- Hibat-Allah, M.; Inack, E.M.; Wiersema, R.; Melko, R.G.; Carrasquilla, J. Variational Neural Annealing. Nat. Mach. Intell. 2021, 3, 952–961. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Santoro, G.E.; Martoňák, R.; Tosatti, E.; Car, R. Theory of Quantum Annealing of an Ising Spin Glass. Science 2002, 295, 2427–2430. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J.; Moore, C. Glassy dynamics and aging in an exactly solvable spin model. Phys. Rev. E 1999, 60, 5068–5072. [Google Scholar] [CrossRef] [Green Version]
- Garrahan, J.P.; Newman, M.E.J. Glassiness and constrained dynamics of a short-range nondisordered spin model. Phys. Rev. E 2000, 62, 7670–7678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vasiloiu, L.M.; Oakes, T.H.E.; Carollo, F.; Garrahan, J.P. Trajectory phase transitions in noninteracting spin systems. Phys. Rev. E 2020, 101, 042115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Devakul, T.; You, Y.; Burnell, F.J.; Sondhi, S.L. Fractal Symmetric Phases of Matter. SciPost Phys. 2019, 6, 7. [Google Scholar] [CrossRef] [Green Version]
- Devakul, T.; Williamson, D.J. Fractalizing quantum codes. Quantum 2021, 5, 438. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, X.F.; Pollmann, F.; You, Y. Fractal Quantum Phase Transitions: Critical Phenomena Beyond Renormalization. arXiv 2021, arXiv:2105.05851. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A. Supervised sequence labelling. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 5–13. [Google Scholar]
- Siegelmann, H.; Sontag, E. On the Computational Power of Neural Nets. J. Comput. Syst. Sci. 1995, 50, 132–150. [Google Scholar] [CrossRef] [Green Version]
- Schäfer, A.M.; Zimmermann, H.G. Recurrent Neural Networks Are Universal Approximators. In Proceedings of the Artificial Neural Networks—ICANN 2006; Kollias, S.D., Stafylopatis, A., Duch, W., Oja, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 632–640. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Im, D.J.; Tao, M.; Branson, K. An empirical analysis of the optimization of deep network loss surfaces. arXiv 2017, arXiv:1612.04010. [Google Scholar]
- Becca, F.; Sorella, S. Quantum Monte Carlo Approaches for Correlated Systems; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar] [CrossRef]
- Deng, D.L.; Li, X.; Das Sarma, S. Quantum Entanglement in Neural Network States. Phys. Rev. X 2017, 7, 021021. [Google Scholar] [CrossRef]
- Sharir, O.; Shashua, A.; Carleo, G. Neural tensor contractions and the expressive power of deep neural quantum states. arXiv 2021, arXiv:2103.10293v3. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Inack, E.M.; Morawetz, S.; Melko, R.G. Neural Annealing and Visualization of Autoregressive Neural Networks in the Newman–Moore Model. Condens. Matter 2022, 7, 38. https://doi.org/10.3390/condmat7020038
Inack EM, Morawetz S, Melko RG. Neural Annealing and Visualization of Autoregressive Neural Networks in the Newman–Moore Model. Condensed Matter. 2022; 7(2):38. https://doi.org/10.3390/condmat7020038
Chicago/Turabian StyleInack, Estelle M., Stewart Morawetz, and Roger G. Melko. 2022. "Neural Annealing and Visualization of Autoregressive Neural Networks in the Newman–Moore Model" Condensed Matter 7, no. 2: 38. https://doi.org/10.3390/condmat7020038
APA StyleInack, E. M., Morawetz, S., & Melko, R. G. (2022). Neural Annealing and Visualization of Autoregressive Neural Networks in the Newman–Moore Model. Condensed Matter, 7(2), 38. https://doi.org/10.3390/condmat7020038