
Inspecting Buildings Using Drones and Computer Vision: A Machine Learning Approach to Detect Cracks and Damages


 ,
, 
 and
and 
Abstract
:1. Introduction and Background
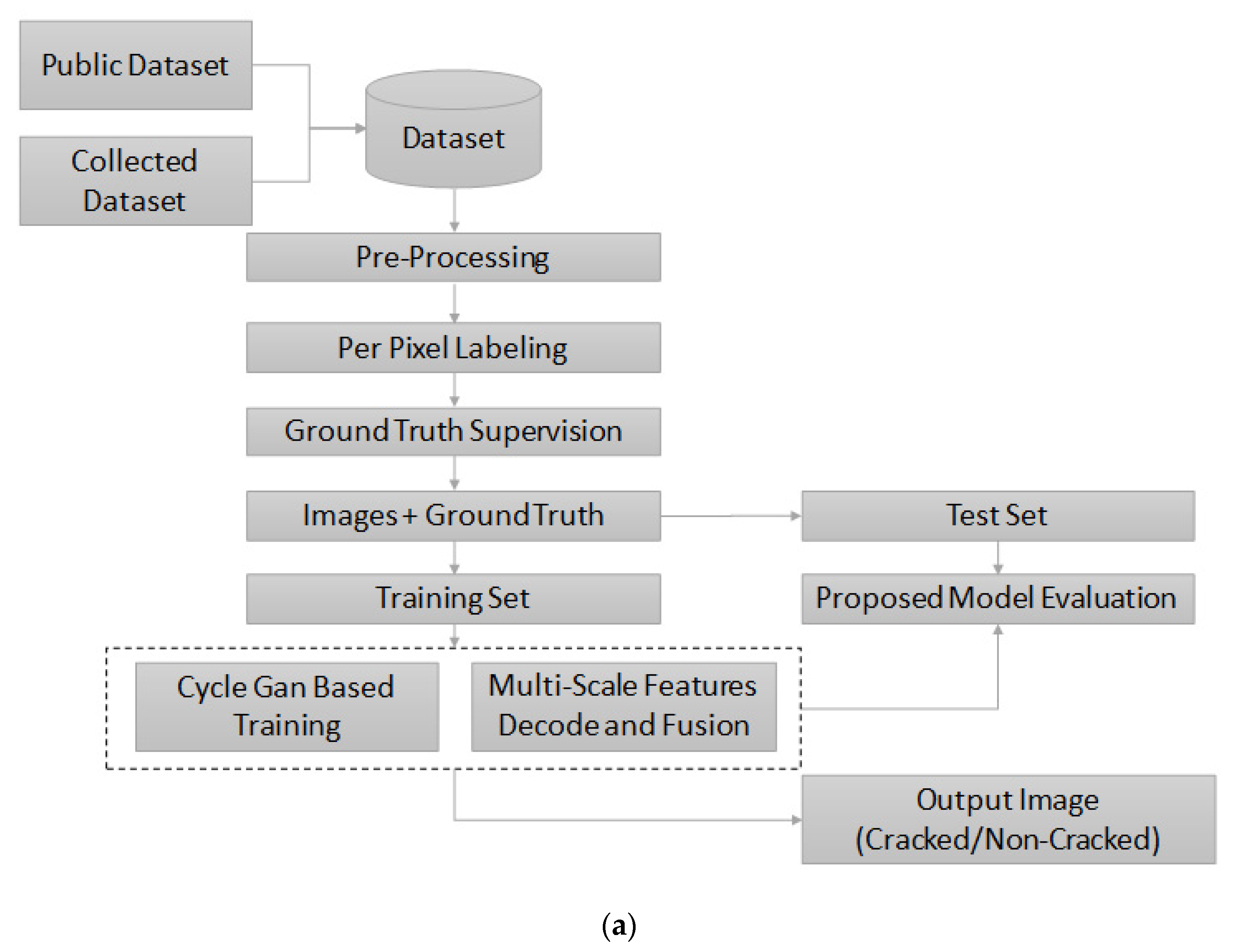
2. Methodology
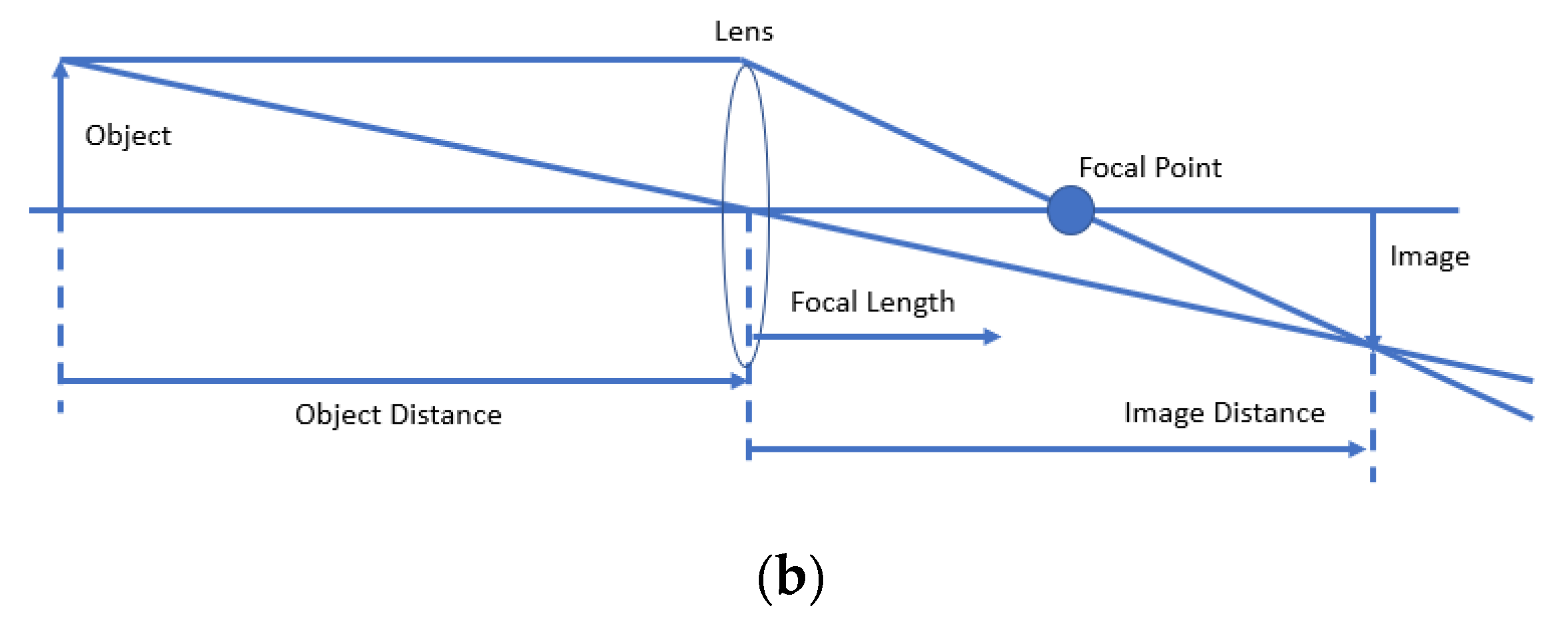
2.1. Data Collection and Pre-Processing of Crack Images
2.2. Per-Pixel Segmentation through SegNet
3. Development of the CNN
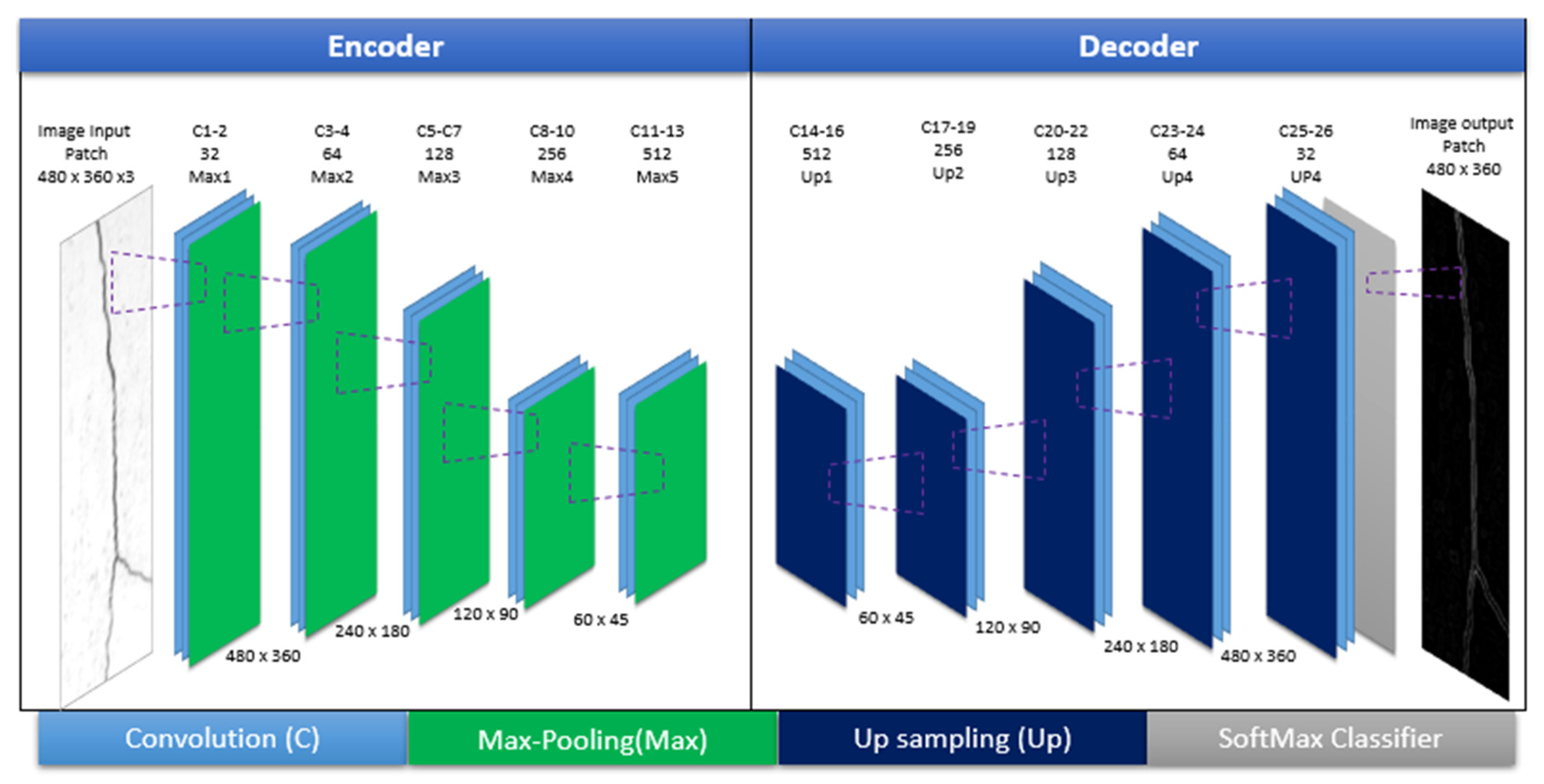
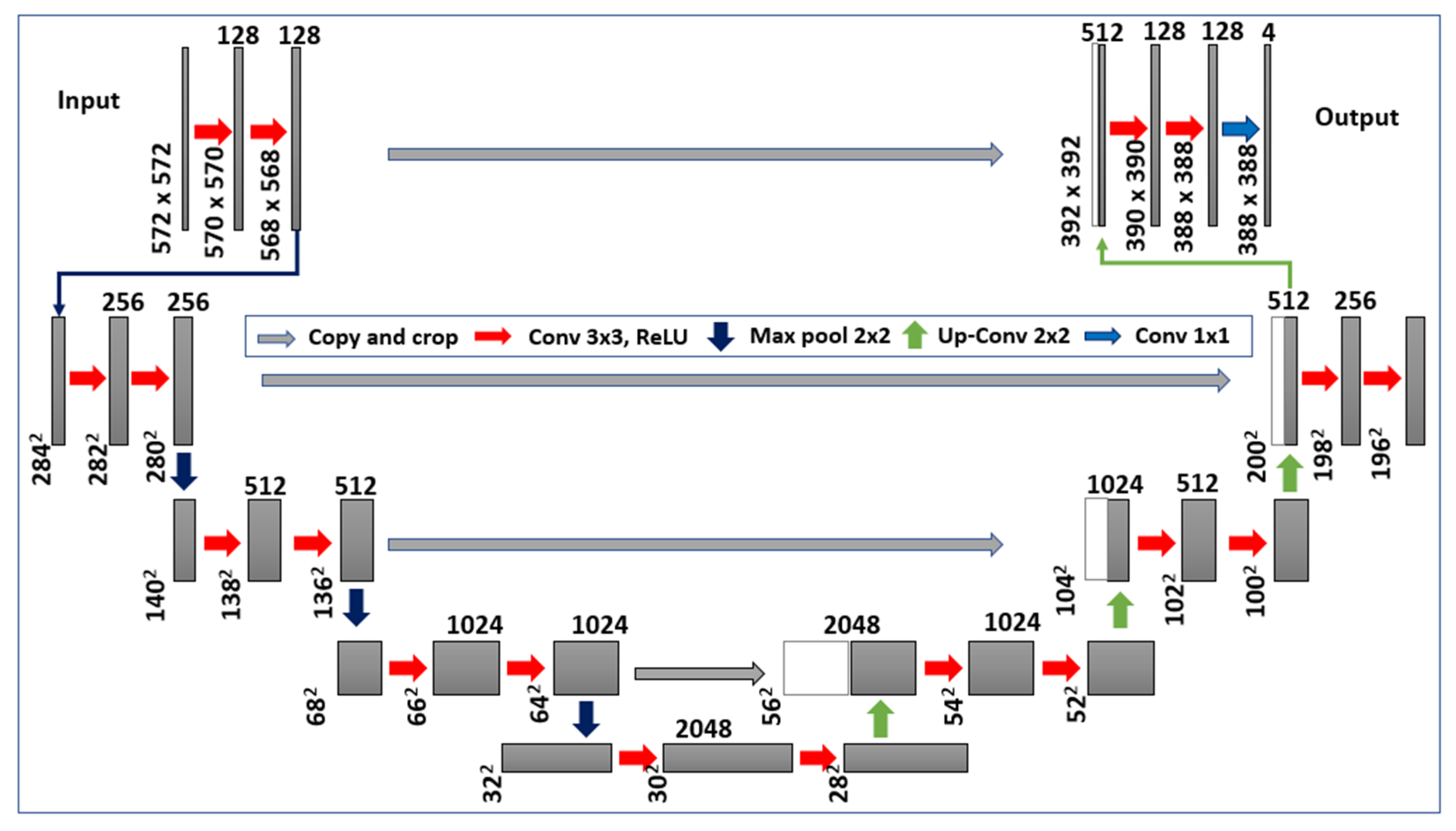
3.1. U-Net Model Architecture
3.2. Loss Formulation
3.2.1. Adversarial Loss
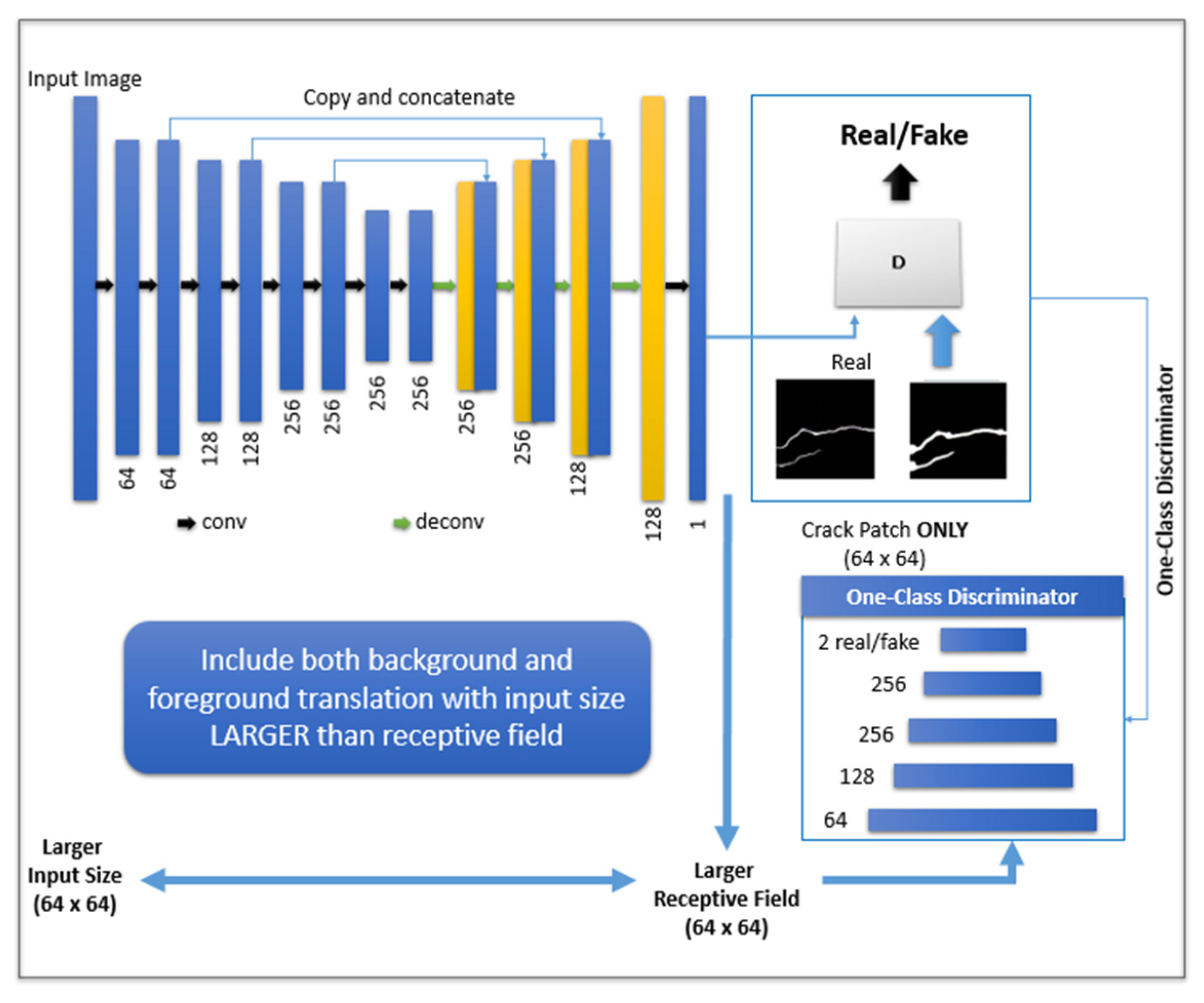
3.2.2. Cycle-Consistency Loss
4. Training of the Proposed CNN Model for Crack Detection
4.1. Model Training Using U-Net
4.2. Model Training Using CycleGAN
5. Performance Evaluation of the Training and Test Sets
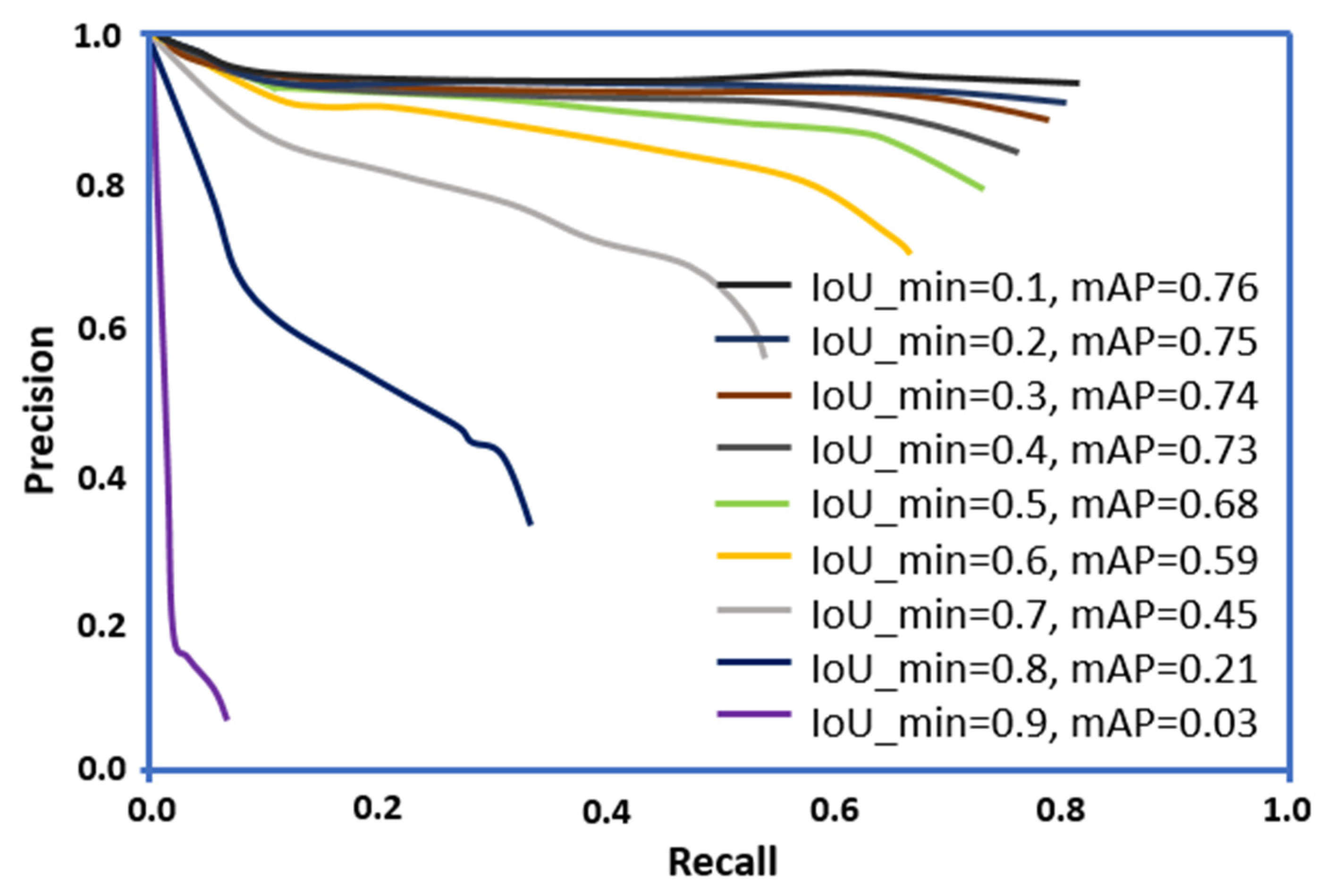
5.1. Evaluation Metrics
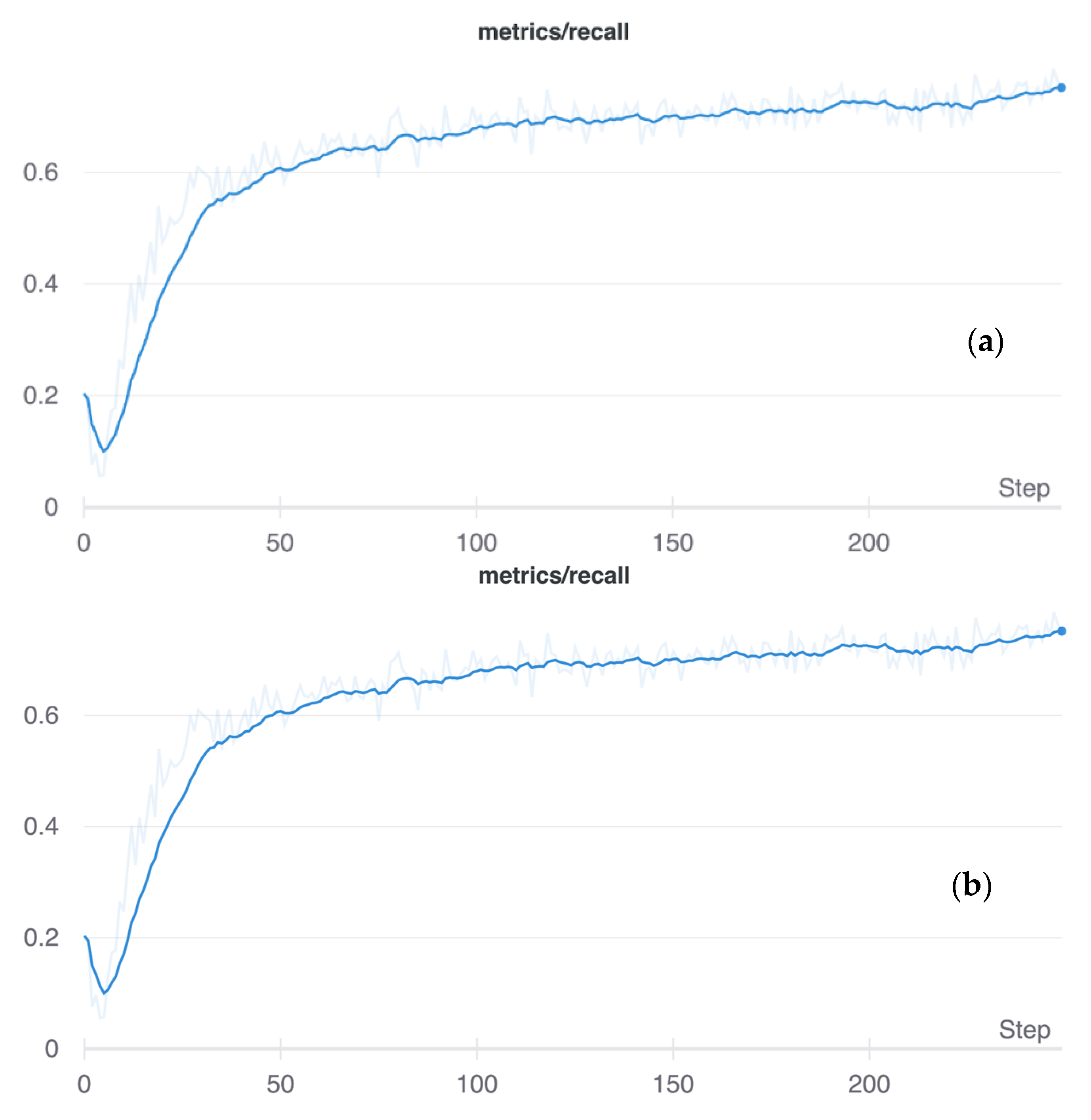
5.2. Training and Test Accuracy
5.3. Model Parameters
5.4. Data Augmentation
6. Model Application, Results, and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Abbreviation | Full Form |
|---|---|---|
| 1 | AI | Artificial Intelligence |
| 2 | ANNs | Artificial Neural Networks |
| 3 | CNNs | Convolutional Neural Networks |
| 4 | CycleGAN | Cycle Generative Adversarial Network |
| 5 | CRFs | Conditional Random Fields |
| 6 | CAC | Class Average Accuracy |
| 7 | FoV | Field of View |
| 8 | FCN | Fully Convolutional Network |
| 9 | FPR | False Positive Rate |
| 10 | GC | Global Accuracy |
| 11 | GNSS | Global Navigation Satellite System |
| 12 | HSV | Hue Saturation Value |
| 13 | HED | Holistically-Nested Edge Detection |
| 14 | KL | Kullback-Leibler |
| 15 | MMS | Mobile Measurement System |
| 16 | MB | Megabytes |
| 17 | ROC | Receiver Operating Characteristic |
| 18 | SGD | Stochastic Gradient Descent |
| 19 | TPR | True Positive Rate |
| 20 | UAV | Unmanned Aerial Vehicle |
| 21 | VGG | Visual Geometry Group |
| 22 | VTOL | Vertical Take-Off and Landing |
Appendix B
| Software | Hardware |
|---|---|
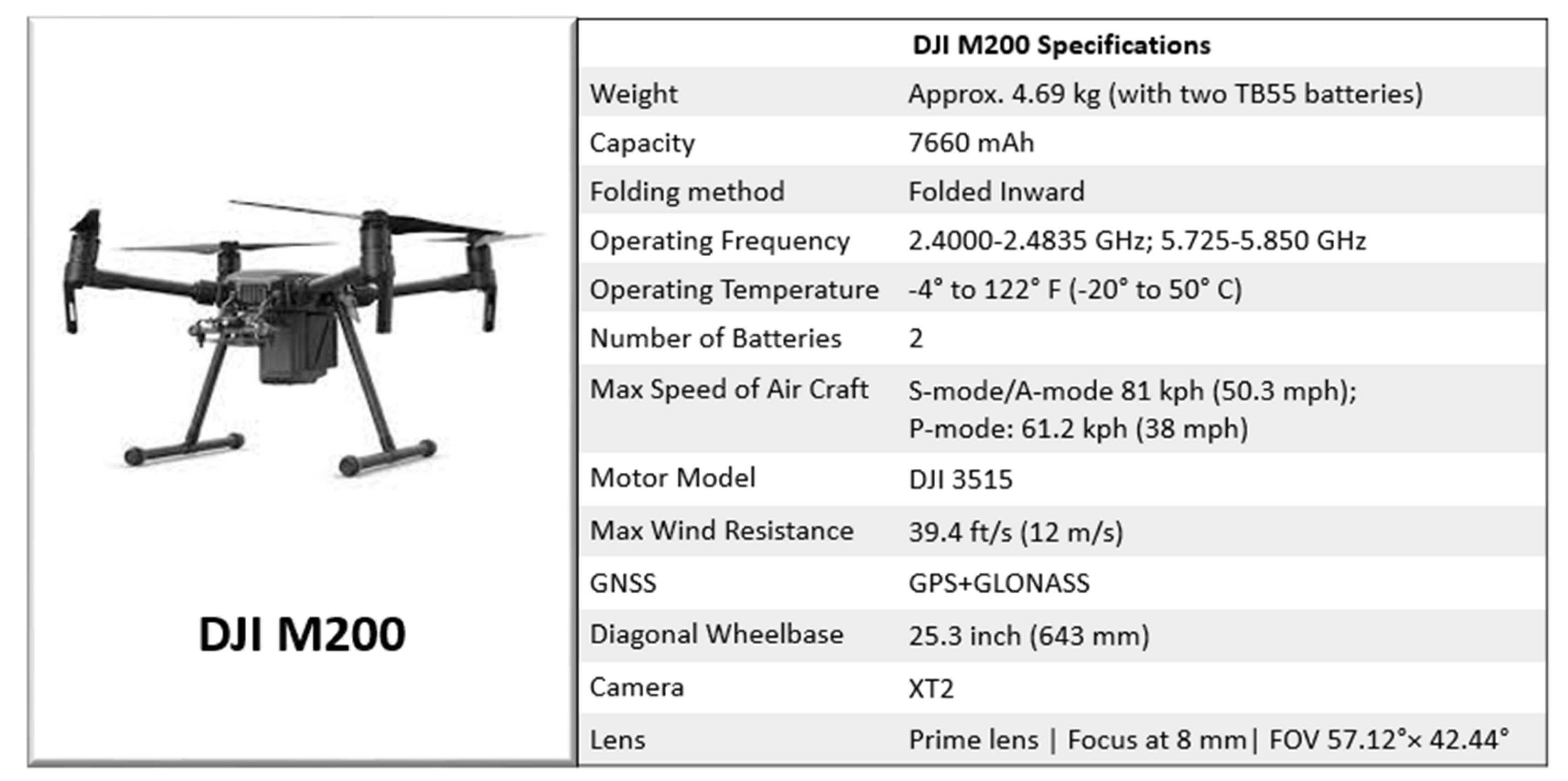
| Background Sessions of WanDB (Data Distribution) | Drone: DJI M200 |
| Library: PyTorch | Intel Core i9-10900KF (10 × 3.70 GHz, 20MB L3 cache, 125 W) |
| IDE: Anaconda 4.0 | GPU (GeForce RTX 2080 Ti). |
| Language: Python & MATLAB 2017 | Camera: XT2 |
References
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Liu, J.; Yang, X.; Lau, S.; Wang, X.; Luo, S.; Lee, V.C.S.; Ding, L. Automated pavement crack detection and segmentation based on two-step convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 1291–1305. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.M.; Wang, C. A systematic review of smart real estate technology: Drivers of, and barriers to, the use of digital disruptive technologies and online platforms. Sustainability 2018, 10, 3142. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Nishikawa, T.; Sugiyama, T.; Fujino, Y. Concrete crack detection by multiple sequential image filtering. Comput.-Aided Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar] [CrossRef]
- Brownjohn, J.M. Structural health monitoring of civil infrastructure. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2007, 365, 589–622. [Google Scholar] [CrossRef] [Green Version]
- Ullah, F.; Sepasgozar, S.M.; Thaheem, M.J.; Al-Turjman, F. Barriers to the digitalization and innovation of Australian Smart Real Estate: A managerial perspective on the technology non-adoption. Environ. Technol. Innov. 2021, 22, 101527. [Google Scholar] [CrossRef]
- Ullah, F.; Qayyum, S.; Thaheem, M.J.; Al-Turjman, F.; Sepasgozar, S.M. Risk management in sustainable smart cities governance: A TOE framework. Technol. Forecast. Soc. Chang. 2021, 167, 120743. [Google Scholar] [CrossRef]
- Fujita, Y.; Mitani, Y.; Hamamoto, Y. A method for crack detection on a concrete structure. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006. [Google Scholar]
- Cha, Y.J.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Liu, S.-W.; Huang, J.H.; Sung, J.-C.; Lee, C. Detection of cracks using neural networks and computational mechanics. Comput. Methods Appl. Mech. Eng. 2002, 191, 2831–2845. [Google Scholar] [CrossRef]
- Ali, M.L.; Thakur, K.; Atobatele, B. Challenges of cyber security and the emerging trends. In Proceedings of the 2019 ACM International Symposium on Blockchain and Secure Critical Infrastructure, Auckland, New Zealand, 8 July 2019. [Google Scholar]
- Cheng, H.; Chen, J.-R.; Glazier, C.; Hu, Y. Novel approach to pavement cracking detection based on fuzzy set theory. J. Comput. Civ. Eng. 1999, 13, 270–280. [Google Scholar] [CrossRef]
- El Adoui, M.; Mahmoudi, S.A.; Larhmam, M.A.; Benjelloun, M. MRI breast tumor segmentation using different encoder and decoder CNN architectures. Computers 2019, 8, 52. [Google Scholar] [CrossRef] [Green Version]
- Fan, Z.; Li, C.; Mascio, P.D.; Chen, X.; Zhu, G.; Loprencipe, G. Ensemble of deep convolutional neural networks for automatic pavement crack detection and measurement. Coatings 2020, 10, 152. [Google Scholar] [CrossRef] [Green Version]
- Kaseko, M.S.; Lo, Z.-P.; Ritchie, S.G. Comparison of traditional and neural classifiers for pavement-crack detection. J. Transp. Eng. 1994, 120, 552–569. [Google Scholar] [CrossRef]
- Ullah, F. Developing a Novel Technology Adoption Framework for Real Estate Online Platforms: Users’ Perception and Adoption Barriers. Ph.D. Thesis, University of New South Wales, Sydney, Australia, 2021. Available online: https://www.unsworks.unsw.edu.au/permalink/f/a5fmj0/unsworks_77811 (accessed on 10 November 2021).
- Ham, Y.; Kamari, M. Automated content-based filtering for enhanced vision-based documentation in construction toward exploiting big visual data from drones. Autom. Constr. 2019, 105, 102831. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. Image-based concrete crack detection using convolutional neural network and exhaustive search technique. Adv. Civ. Eng. 2019, 2019, 6520620. [Google Scholar] [CrossRef] [Green Version]
- Chen, M. Development and Evaluation of a Hydrological and Hydraulic Coupled Flood Prediction System Enabled by Remote Sensing, Numerical Weather Prediction, and Deep Learning Technologies. Ph.D. Thesis, University of Oklahoma, Norman, OK, USA, 2021. [Google Scholar]
- Fujita, Y.; Hamamoto, Y. A robust automatic crack detection method from noisy concrete surfaces. Mach. Vis. Appl. 2011, 22, 245–254. [Google Scholar] [CrossRef]
- Han, L.; Liang, H.; Chen, H.; Zhang, W.; Ge, Y. Convective precipitation nowcasting using U-Net Model. IEEE Trans. Geosci. Remote Sens. 2021, 1–8. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.M.; Shirowzhan, S.; Davis, S. Modelling users’ perception of the online real estate platforms in a digitally disruptive environment: An integrated KANO-SISQual approach. Telemat. Inform. 2021, 63, 101660. [Google Scholar] [CrossRef]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Ullah, F.; Al-Turjman, F. A conceptual framework for blockchain smart contract adoption to manage real estate deals in smart cities. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Ullah, F.; Al-Turjman, F.; Qayyum, S.; Inam, H.; Imran, M. Advertising through UAVs: Optimized path system for delivering smart real-estate advertisement materials. Int. J. Intell. Syst. 2021, 36, 3429–3463. [Google Scholar] [CrossRef]
- Dinh, T.H.; La, H.M. Computer vision-based method for concrete crack detection. In Proceedings of the 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), Phuket, Thailand, 13–15 November 2016. [Google Scholar]
- Hoang, N.-D. Image processing-based pitting corrosion detection using metaheuristic optimized multilevel image thresholding and machine-learning approaches. Math. Probl. Eng. 2020, 2020, 6765274. [Google Scholar] [CrossRef]
- Cheng, B.; Girshick, R.; Dollár, P.; Berg, A.C.; Kirillov, A. Boundary IoU: Improving object-centric image segmentation evaluation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Ahuja, S.K.; Shukla, M.K. A survey of computer vision based corrosion detection approaches. In International Conference on Information and Communication Technology for Intelligent Systems; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar] [CrossRef]
- Dinh, T.H.; Pham, M.T.; Phung, M.D.; Nguyen, D.M.; Tran, Q.V. Image segmentation based on histogram of depth and an application in driver distraction detection. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014. [Google Scholar]
- LeCun, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.M.; Thaheem, M.J.; Wang, C.C.; Imran, M. It’s all about perceptions: A DEMATEL approach to exploring user perceptions of real estate online platforms. Ain Shams Eng. J. 2021, 12, 4297–4317. [Google Scholar] [CrossRef]
- Maqsoom, A.; Aslam, B.; Gul, M.E.; Ullah, F.; Kouzani, A.Z.; Mahmud, M.; Nawaz, A. Using multivariate regression and ANN models to predict properties of concrete cured under hot weather: A case of rawalpindi pakistan. Sustainability 2021, 13, 10164. [Google Scholar] [CrossRef]
- Vu, M.; Jardani, A. Convolutional neural networks with SegNet architecture applied to three-dimensional tomography of subsurface electrical resistivity: CNN-3D-ERT. Geophys. J. Int. 2021, 225, 1319–1331. [Google Scholar] [CrossRef]
- Atha, D.J.; Jahanshahi, M.R. Evaluation of deep learning approaches based on convolutional neural networks for corrosion detection. Struct. Health Monit. 2018, 17, 1110–1128. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Zhu, D. On the learning property of logistic and softmax losses for deep neural networks. Proc. AAAI Conf. Artif. Intell. 2020, 34, 4739–4746. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Koch, C.; Brilakis, I. Pothole detection in asphalt pavement images. Adv. Eng. Inform. 2011, 25, 507–515. [Google Scholar] [CrossRef]
- Buckland, M.; Gey, F. The relationship between Recall and Precision. J. Am. Soc. Inf. Sci. 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Moss, D.J.; Nurvitadhi, E.; Sim, J.; Mishra, A.; Marr, D.; Subhaschandra, S.; Leong, P.H. High performance binary neural networks on the Xeon + FPGA™ platform. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, N.T.H.; Le, T.H.; Perry, S.; Nguyen, T.T. Pavement crack detection using convolutional neural network. In Proceedings of the Ninth International Symposium on Information and Communication Technology, Da Nang, Vietnam, 6–7 December 2018. [Google Scholar]
- Moss, T.; Figueroa, G.; Broen, S. Corrosion detection using AI: A comparison of standard computer vision techniques and deep learning model. In Proceedings of the Sixth International Conference on Computer Science, Engineering and Information Technology, Vienna, Austria, 21–22 May 2016. [Google Scholar]
- Sinha, S.K.; Fieguth, P.W. Automated detection of cracks in buried concrete pipe images. Autom. Constr. 2006, 15, 58–72. [Google Scholar] [CrossRef]
- Zhang, K. Deep Learning for Crack-like Object Detection; Utah State University: Logan, UT, USA, 2019. [Google Scholar]
- Prasanna, P.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated crack detection on concrete bridges. IEEE Trans. Autom. Sci. Eng. 2014, 13, 591–599. [Google Scholar] [CrossRef]
- Yokoyama, S.; Matsumoto, T. Development of an automatic detector of cracks in concrete using machine learning. Procedia Eng. 2017, 171, 1250–1255. [Google Scholar] [CrossRef]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Artificial Intelligence and Statistics; PMLR: San Diego, CA, USA, 2015. [Google Scholar]
- Stroia, I.; Itu, L.; Niţă, C.; Lazăr, L.; Suciu, C. GPU accelerated geometric multigrid method: Performance comparison on recent NVIDIA architectures. In Proceedings of the 2015 19th International Conference on System Theory, Control and Computing (ICSTCC), Cheile Gradistei, Romania, 14–16 October 2015. [Google Scholar]
- Wang, W.; Wang, K.C.; Braham, A.F.; Qiu, S. Pavement crack width measurement based on Laplace’s equation for continuity and unambiguity. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 110–123. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Kopsiaftis, G.; Doulamis, N.; Amditis, A. Crack identification via user feedback, convolutional neural networks and laser scanners for tunnel infrastructures. In Proceedings of the International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Rome, Italy, 27–29 February 2016. [Google Scholar] [CrossRef] [Green Version]
- Qayyum, S.; Ullah, F.; Al-Turjman, F.; Mojtahedi, M. Managing smart cities through six sigma DMADICV method: A review-based conceptual framework. Sustain. Cities Soc. 2021, 72, 103022. [Google Scholar] [CrossRef]
- Lee, B.Y.; Kim, Y.Y.; Kim, J.-K. Automated image processing technique for detecting and analyzing concrete surface cracks. Struct. Infrastruct. Eng. 2013, 9, 567–577. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X. Thermal image super-resolution: A novel architecture and dataset. In Proceedings of the 15th International Conference on Computer Vision Theory and Applications, Valletta, Malta, 27–29 February 2020. [Google Scholar]
- Yamaguchi, T.; Nakamura, S.; Saegusa, R.; Hashimoto, S. Image-based crack detection for real concrete surfaces. IEEJ Trans. Electr. Electron. Eng. 2008, 3, 128–135. [Google Scholar] [CrossRef]
- Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- Suh, G.; Cha, Y.-J. Deep faster R-CNN-based automated detection and localization of multiple types of damage. In Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2018; International Society for Optics and Photonics: Denver, CO, USA, 2018. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Liu, L.; Tan, E.; Zhen, Y.; Yin, X.J.; Cai, Z.Q. AI-facilitated coating corrosion assessment system for productivity enhancement. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018. [Google Scholar]
- Prasoon, A.; Igel, C.; Lauze, F.; Dam, E.; Nielsen, M. Deep feature learning for knee cartilage segmentation using a triplanar convolutional neural network. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Zhang, K.; Zhang, Y.; Cheng, H. Self-supervised structure learning for crack detection based on cycle-consistent generative adversarial networks. J. Comput. Civ. Eng. 2020, 34, 04020004. [Google Scholar] [CrossRef]
- Santos, B.O.; Valença, J.; Júlio, E. Classification of biological colonization on concrete surfaces using false colour HSV images, including near-infrared information. In Optical Sensing and Detection V; International Society for Optics and Photonics: Strasbourg, France, 2018. [Google Scholar]
- Su, C.; Wang, W. Concrete cracks detection using convolutional neuralnetwork based on transfer learning. Math. Probl. Eng. 2020, 2020, 7240129. [Google Scholar] [CrossRef]
- Yuan, M.; Liu, Z.; Wang, F. Using the wide-range attention U-Net for road segmentation. Remote Sens. Lett. 2019, 10, 506–515. [Google Scholar] [CrossRef]
- Qu, Z.; Ju, F.-R.; Guo, Y.; Bai, L.; Chen, K. Concrete surface crack detection with the improved pre-extraction and the second percolation processing methods. PLoS ONE 2018, 13, e0201109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Munawar, H.S.; Qayyum, S.; Khan, S.I.; Mojtahedi, M. UAVs in disaster management: Application of integrated aerial imagery and convolutional neural network for flood detection. Sustainability 2021, 13, 7547. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Qayyum, S.; Heravi, A. Application of deep learning on uav-based aerial images for flood detection. Smart Cities 2021, 4, 1220–1243. [Google Scholar] [CrossRef]
- Ullah, F.; Khan, S.I.; Munawar, H.S.; Qadir, Z.; Qayyum, S. UAV based spatiotemporal analysis of the 2019–2020 new south wales bushfires. Sustainability 2021, 13, 10207. [Google Scholar] [CrossRef]
- Soni, A.N. Crack detection in buildings using convolutional neural network. J. Innov. Dev. Pharm. Tech. Sci. 2019, 2, 54–59. [Google Scholar]












| Crack Pixels (%) | Non-Crack Pixels (%) | ||
|---|---|---|---|
| Significant | Weak | ||
| Total | 2.98 | 1.37 | 95.65 |
| Training | 3.13 | 0.55 | 96.30 |
| Testing | 4.25 | 1.06 | 94.68 |
| Serial No | Parameter | Value Tuned |
|---|---|---|
| 1 | Size of the input image | 544 × 384 × 3 |
| 2 | Ground truth size | 544 × 384 × 1 |
| 3 | Size of mini-batch | 1 |
| 4 | Learning Rate | 1 × 10−4 |
| 5 | Loss weight associated with each side-output layer | 1.0 |
| 6 | Loss weight associated with final fused layer 1.0 | 1.0 |
| 7 | Momentum | 0.9 |
| 8 | Weight decay | 2 × 10−4 |
| 9 | Training iterations | 2 × 105; reduce learning rate by 1/5 after 5 × 104 |
| Outputs | Global Accuracy | Class Average Accuracy | Mean IoU | Precision | Recall | F-Score |
|---|---|---|---|---|---|---|
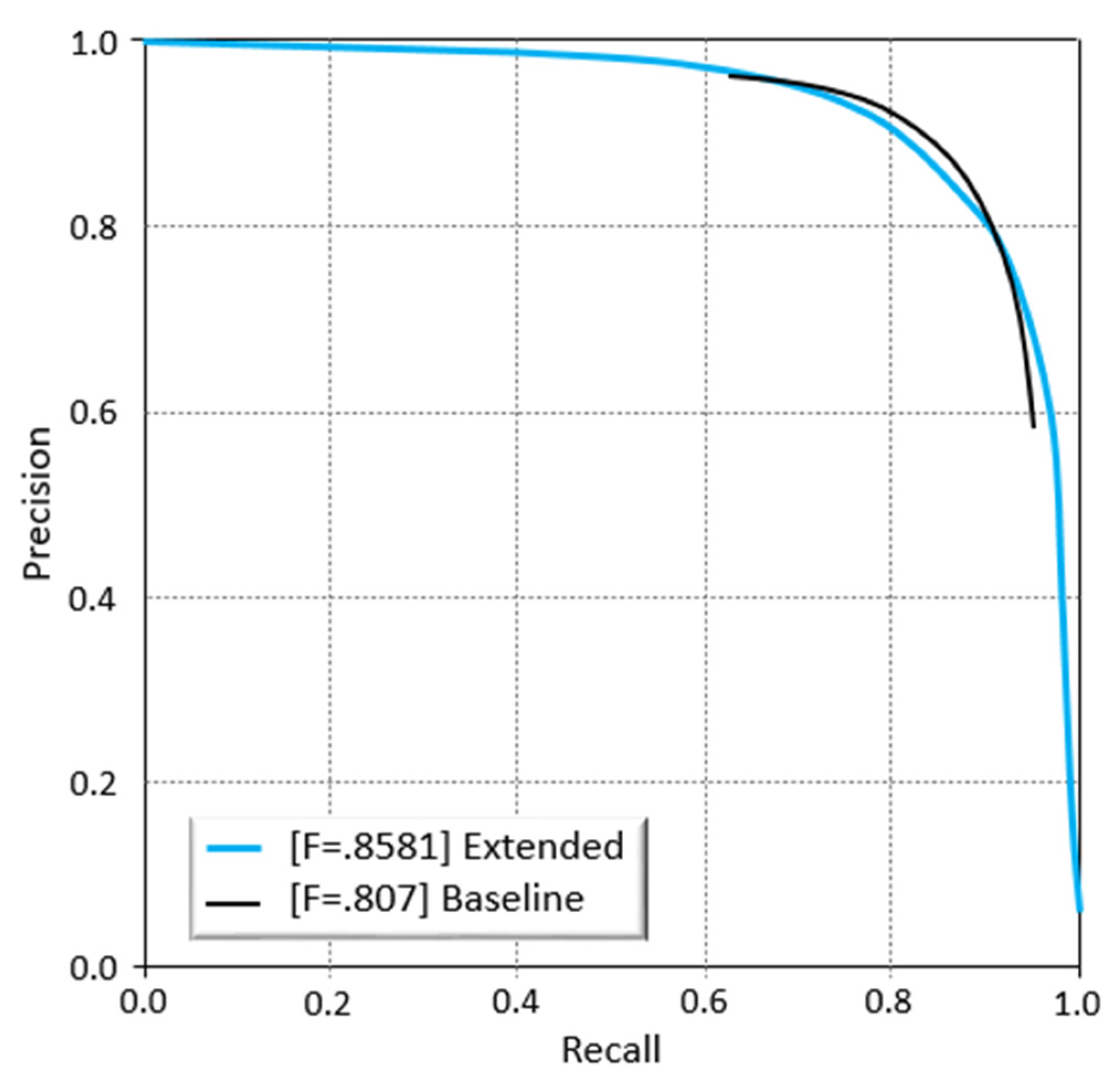
| Our Method with Guided Filter | 0.990 | 0.939 | 0.879 | 0.838 | 0.879 | 0.8581 |
| Our Baseline Method | 0.988 | 0.899 | 0.896 | 0.84 | 0.784 | 0.807 |
| DeepCrack-BN | 0.982 | 0.898 | 0.822 | 0.768 | 0.806 | 0.786 |
| DeepCrack-GF | 0.964 | 0.875 | 0.825 | 0.787 | 0.724 | 0.754 |
| SegNet | 0.871 | 0.819 | 0.649 | 0.626 | 0.66 | 0.643 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Munawar, H.S.; Ullah, F.; Heravi, A.; Thaheem, M.J.; Maqsoom, A. Inspecting Buildings Using Drones and Computer Vision: A Machine Learning Approach to Detect Cracks and Damages. Drones 2022, 6, 5. https://doi.org/10.3390/drones6010005
Munawar HS, Ullah F, Heravi A, Thaheem MJ, Maqsoom A. Inspecting Buildings Using Drones and Computer Vision: A Machine Learning Approach to Detect Cracks and Damages. Drones. 2022; 6(1):5. https://doi.org/10.3390/drones6010005
Chicago/Turabian StyleMunawar, Hafiz Suliman, Fahim Ullah, Amirhossein Heravi, Muhammad Jamaluddin Thaheem, and Ahsen Maqsoom. 2022. "Inspecting Buildings Using Drones and Computer Vision: A Machine Learning Approach to Detect Cracks and Damages" Drones 6, no. 1: 5. https://doi.org/10.3390/drones6010005
APA StyleMunawar, H. S., Ullah, F., Heravi, A., Thaheem, M. J., & Maqsoom, A. (2022). Inspecting Buildings Using Drones and Computer Vision: A Machine Learning Approach to Detect Cracks and Damages. Drones, 6(1), 5. https://doi.org/10.3390/drones6010005