In this section, we walk the reader through the analysis and results of the analysis strategy outlined above.
3.1. Clustering Structure in the Original Space
Since we are interested in exploring the similarity of the usage of MATCH-ADTC modules (via the count profile over the patients) and finding clusters based on module usage, we first start with looking at an OPTICS analysis of the data in the original space. For this, we use the implementation
optics from package
dbscan [
39] and
cordillera from
cordillera [
12].
We are especially interested in clusters that comprise at least three modules (that is the parameter
k, the minimum number of points per cluster specified as
minPts = 3). This was inspired partly by the FIRST principles ([
7], see also
Section 3.3), a theoretical category system for treatment techniques. Theoretically classifying the MATCH modules based on FIRST leads to categories that comprise at least three modules (with the exception of FeelingCalm comprising two). Together with the consideration that allowing for clusters with less than three modules is likely to generate a large number of clusters with 32 modules, leading to fragmentation, we chose
. We do not expect any of the modules to be “just noise”, so the
parameter that defines the neighborhood around a point in which to look for other points just needs to be set sufficiently high to consider each point as a possible neighbor of every other point; we use
eps=10 (10 times the maximum possible
-distance). Setting a smaller
has the effect of letting points in sparsely populated regions be labeled as noise, which can make sense if we cannot take the data at face value because we suspect, e.g., contamination, error-prone measurement or similar in the data. For the
via
cordillera, we use the same setup as for
optics (so,
eps=10 and
minpts=3) and measure it in terms of the
-norm (Euclidean), so
q=2. As
, we will use the function default, which is the
, making the
a goodness-of-clustering index relative to the largest reachability observed for the distance matrix.
We run OPTICS with this setup and also calculate the OPTICS Cordillera by
R> o1 <− dbscan :: optics (as.dist (distM), minPts=3, eps=10)
R> c1 <− cordillera :: cordillera (as.dist (distM), minpts=3, eps=10,q=2)
The is around , which suggests that the modules are not very clustered based on the -distance and minpts=3.
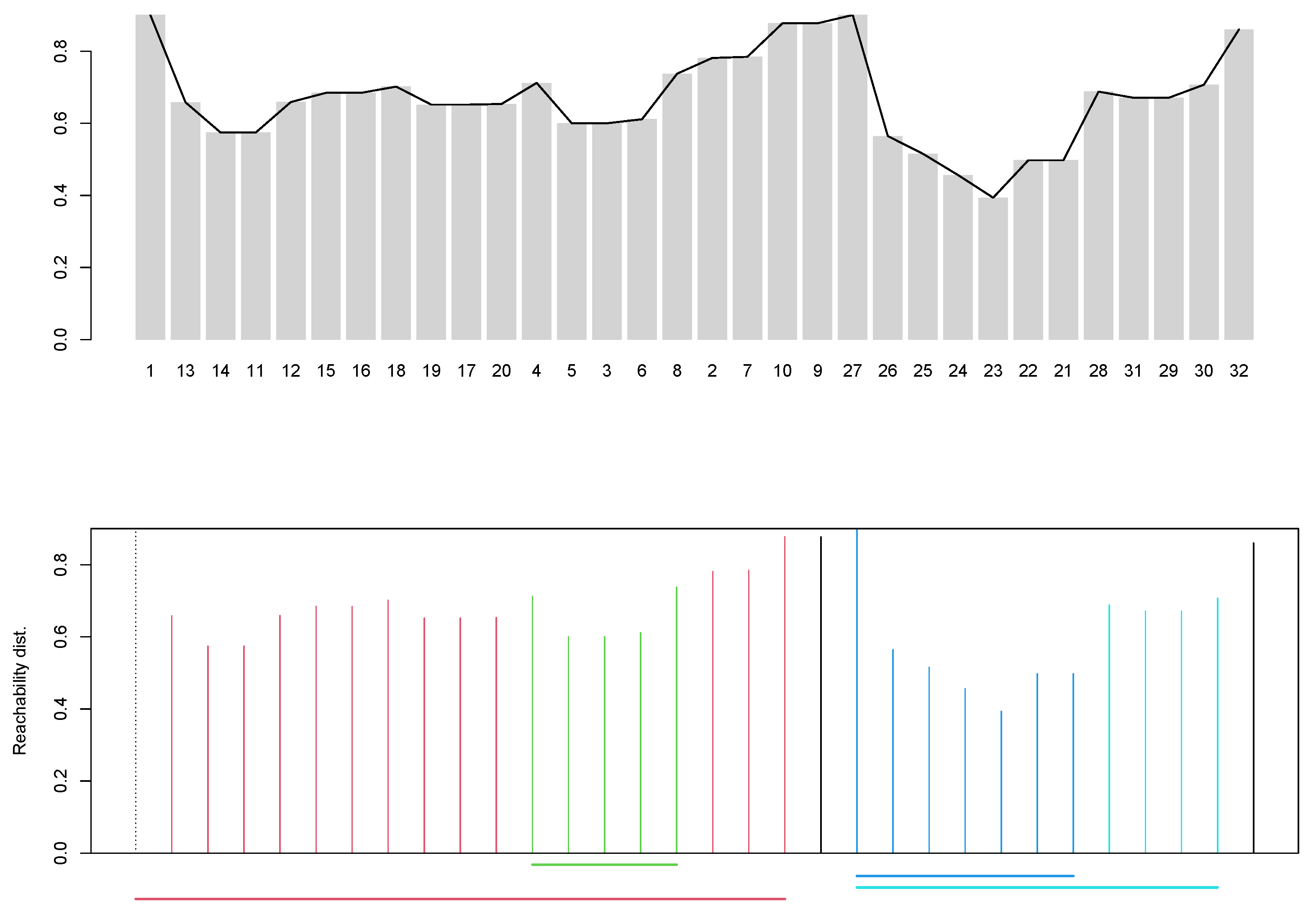
The corresponding reachability plot with the
(black line) is shown in the top panel of
Figure 2. We see there is some but not much up and down as captured by the
; mostly the reachabilities are relatively high, which means points are relatively far from their closest neighbors, and the valleys are not very deep meaning that the clusters existing in the original space are not very dense, with the two closest objects being modules “Praise” (module 24) and “OneOnOne” (23). They seem to belong to a cluster with modules “GivingEffInst” (26), “ActiveIgnoring” (25), “LearningAboutBehavior” (22) and “EngagingParents” (21). From visual inspection of the reachability plot, it looks as though there may be 4 or 5 clusters (valleys) in the original space, but these clusters are neither well-separated (average within cluster reachability is not much lower than the peaks) nor very cohesive (valleys are not deep). It also appears that the clusters are nested within bigger clusters (in
Figure 2 to the left and right of the module “SafetyPlanning” (9)). Overall, the picture suggested in the original space is one of a relatively regular distribution of the modules, with little clustering information.
The already suggested that the clusteredness of the modules in the original space is not great. We will now use the -strategy on our OPTICS result to suggest clusters (function extractXi); for this, we set the xi parameter to , which is just shy of the minimum reachability between modules 23 and 24. The xi parameter can be interpreted as detecting clusters in the reachability plot if there is a change of more than in relative cluster density or in the steepness in the reachability plot. This may signal a new cluster. The value for xi needs to be specified by the user and often one has to try a few values to find one that is working well; in general the smaller it is, the more clusters are found.
The
-strategy with
xi=0.039 suggests that there are four clusters of at least 3 points with two modules not assigned (noise, the modules “Booster” (32) and “Safety Planning” (9)). The bottom panel in
Figure 2 shows the reachabilities colored with the cluster assignment (black is noise) and the nested clusters as color lines in the lower part of the plot. There is a big cluster (red) containing a denser cluster (green); the latter are modules “LearningAnxChild” (4), “LearningAnxParent” (5), “FearLadder” (3), “Practicing” (6), and “CognitiveSTOP” (8) and they are nested within the larger red cluster additionally comprising modules “GettingAcquainted” (1), “PbmSolving” (13), “ActivitySelection” (14), “LearningDepChild” (11), “LearningDepParent” (12), “LearningToRelax” (15), “QuickCalming” (16), “CognitiveBLUE” (18) “CognitiveTLC” (19), “PositiveSelf” (17), “PlansForCoping” (20) (to the right of green cluster) and “WrapUp” (2), “Maintenance” (7), and “Narrative” (10) (to the left of green). The blue cluster comprises “Rewards” (27), 26, 25, 24, 23, 22, 21 and is nested in the turquoise one that additionally comprises “timeOut” (28), “LookingAhead” (31), “MakingAPlan” (29) and “DailyRptCard” (30) on lower density.
So far, we have learned the following: In the original space, clusteredness is not high and the clustering is not particularly suggestive, with two large clusters containing two nested clusters each. The large cluster (red) contains roughly two-thirds of the modules, those that are anxiety-, trauma- and depression-related, as well as the modules that are used for starting and ending a treatment. Within that cluster, “LearningAnxParent”, “LearningAnxChild”, “FearLadder”, “Practicing” and “CognitiveSTOP” form a denser cluster. The other cluster (turquoise) comprises roughly the other one-third of the modules, which are the conduct-based modules with the dense cluster around “OneOnOne” and “Praise”.
3.2. Scaling with COPS
While the OPTICS analysis leaves us wanting a bit, we now turn to scaling the modules in a reduced space. This allows us not only to visualize the spatial arrangement of the modules in a Cartesian space, but perhaps suggests clusterings that we have not been able to detect before.
With the R package cops, we can fit two instances of the COPS framework: First, COPS-C with the fitting function copstressMin or using cops and specifying variant = ’COPS-C’. Second, we can also fit P-COPS (returning optimal parameter for p-stress), either with the fitting function pcops or cops with variant=’P-COPS’. In this article, we will focus on the COPS-C functionality.
Each variant’s fitting function has a number of arguments to allow for many different types of models to be fitted. We give a short overview of the main ones in this article; a more comprehensive discussion is available in the package vignette to cops (obtainable in R via vignette(’cops’)).
In copstressMin, we can choose the optimal scaling transformation with the argument type to be ’ratio’, ’interval’ or ’ordinal’. If a p-stress COPS (or any of its special cases) should be fitted, we can set the kappa, lambda and/or nu parameters to the desired values in copstressMin; note then only ratio transformations are allowed, so type = ’ratio’ only. In what follows, we will use COPS with the following stresses: First, we look at a ratio COPS-C with (corresponding to standard ratio MDS as reference). We then fit a ratio COPS-C (type = ’ratio’), interval COPS-C (type = ’interval’) and two specific p-stress models, multiscale COPS-C (with distM2 = log(1 + distM), type = ’ratio’ and kappa = 0.1) and s-stress COPS-C (type = ’ratio’, kappa = 2, lambda = 2). We also run a P-COPS with loss = ’powermds’ (i.e., p-stress without weights) and select an optimal for p-stress. We then refit a p-stress COPS-C (type = ’ratio’) with the optimal and as respective arguments for kappa and lambda.
For COPS models, we can set the weight
of the stress measure with
stressweight and the weight
for the
with
cordweight. We use
(
stressweight = 0.975) and
(
cordweight = 0.025) in all subsequent COPS-C models apart from standard ratio MDS, so essentially we are willing to sacrifice up to
of fit for a more clustered appearance. This is a fairly low value (and the default), so this will lead to a configuration that is still very close to the optimal one for the corresponding standard MDS (which can be obtained by setting
). The choice of
and
is up to the user, but we recommend to use relatively high values of
(e.g.,
and
). We also point out that in terms of optimization, a
that is close to 0 makes the complicated optimization of COPS problem less difficult. The weighting for P-COPS works a bit differently, but there is a smart default (see [
1] for details).
The number of dimensions of the target space can be changed with
ndim. It is also possible to specify a symmetric weight matrix
weightmat and an initial configuration
init, which can be used to try out different starting configurations. The minimization of (
5) is complicated and there are many different heuristics implemented; the optimization strategy can be changed with the argument
optimmethod. The default strategy usually works well, so we stick to that one. We let the solver in COPS-C use up to
itmax=50000 iterations, which will likely allow convergence of the optimizer at the default convergence criterion. We note that such a high
itmax is used for illustration here and is overkill in most applications; normally we use between 5000 and 10,000.
What is left are the arguments for measuring clusteredness with the . These are the same ones as in cordillera and mainly are minpts (minimum number of points k to make up a cluster) and dmax the maximum reference distance and winsorization limit. The decision on k must be made on substantive grounds; we will use minpts = 3. As dmax, we set 1, which corresponds to around times the maximum reachability in the standard ratio MDS; this provides robustness to the against noise points or outliers that have larger reachabilities than that. We may also set q, which we keep at 2 and epsilon, but that can just be set to some high number (in our case the default, which is 10). Note we now want to compare different , so we need to have one that defines the maximal clusteredness for all; then, the is the clusteredness achieved relative to that maximum for all . When looking at only one , one can just use the default for goodness-of-clustering, but that default is likely to change between different . So, when comparing different we should use the same .
So, let us set up the control parameters in R.
R> ## OC parameters
R> minpts <− 3
R> dmax <− 1
R> q <− 2
R> ##iterations
R> itm <− 50000
Our starting point is the standard ratio MDS solution, which we can obtain by setting stressweight = 1 and cordweight = 0 in the call to copstressMin.
| R> ## Standard MDS |
| R> MDSM0 <− cops :: copstressMin (distM, | #distance object |
| | type="ratio", | #MDS type |
| | dmax=dmax, minpts=minpts, q=q, | #metaparameters |
| | stressweight=1, cordweight=0, | #v1 and v2 |
| | itmax=itm) | |
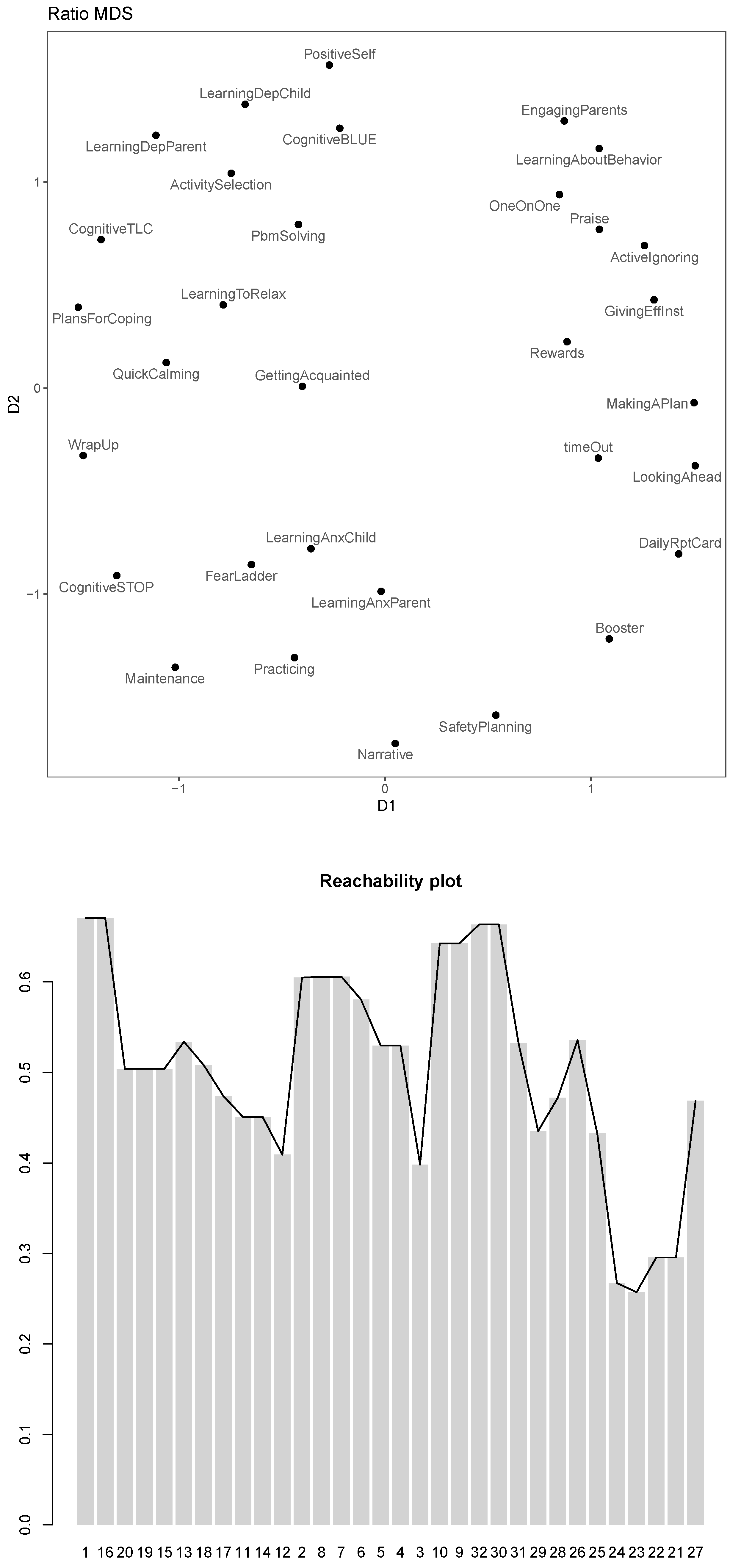
This solution has a stress-1 (square root of stress) of and an for the respective Cordillera parameters. As before with our OPTICS investigation in the original space, in terms of clusteredness this is relatively low.
The configuration plot and the corresponding reachability plot with stylized
can be found in
Figure 3. They corroborate that the clusteredness obtained for this result is not very high and that the arrangement of modules has a relatively low density for all. Nevertheless, we can already see which modules seem to be used similarly over the patients: In the top left quadrant, we find modules that are related to depression, whereas in the bottom left quadrant we find modules related to anxiety. In the top right and bottom right quadrant, we have modules that are related to conduct problems. The trauma related modules are located between the anxiety modules and the conduct modules. The icebreaker module (“GettingAcquainted”) and the finisher (“WrapUp”) are located between the depression and anxiety modules. Still, the modules are not arranged in a way that allows us to identify a more detailed organizing principle.
To change that, we now put some more weight on the Cordillera as described above by setting stressweight=sw and cordweight=cw.
R> ## Weights
R> cw <− 0.025
R> sw <− 0.975
The change in clusteredness is quite drastic: Stress-1 became only slightly worse (
), but the
more than quadrupled to
. This is also easy to discern in the configuration plot and the corresponding reachability plot, which can be found in
Figure 4. The reachability plot is much more rugged now, reflecting the higher clusteredness and clearer clustering structure as seen in the configuration plot.
This result opens up many new avenues for interpretation: The basic quadrant structure we already identified in the standard MDS is upheld. Within those, however, we now find new and clearer clusters of modules. For example, it seems that “GettingAcquainted” has a similar profile to the relaxation modules, suggesting that they are used similarly over the youths. The anxiety module “FearLadder” and the learning about anxiety modules now cluster more strongly and “Practicing” is moved closer to them. The trauma modules are still separated clearly from the anxiety modules, but are close. We find additional clusters also for the conduct modules, which seem to group in three clusters: the clusters of “EngagingParents”, “LearningAboutBehavior” and “OneOnOne”, a cluster of “GivingEffInst”, “Praise”, “Rewards”, “ActiveIgnoring” and one comprising “timeOut”, “MakingAPlan”, “LookingAhead” and “DailyRptCard”. “Booster” appears removed from any clusters. Among the depression modules, the modules are separated into two more obvious clusters, each with a denser sub-cluster: the aforementioned “GettingAcquainted” and relaxation module cluster on the one hand and “LearningDepChild”,“LearningDepParent” and “ActivitySelection” on the other. There is already much to be hypothesized from this result, but we will look at whether there are any changes if we use other stress models as well.
We next use COPS-C with the interval transformation. Compared to ratio MDS, this essentially removes shared absolute information in the proximities from the fitted distances in the configuration due to allowing a constant in the disparities. A fitted distance of 0 then represents the shared absolute information and the fitted distances only approximate the information that is left, therefore emphasizing the dissimilarity difference more strongly; this increases the coefficient of variation of the and we expect a clearer clustering structure.
| R> ## Interval COPS-C |
| R> MDSMint <− cops::copstressMin (distM, type="interval", |
| | dmax=dmax, minpts=minpts, q=q, |
| | stressweight=sw, cordweight=cw, |
| | itmax=itm) |
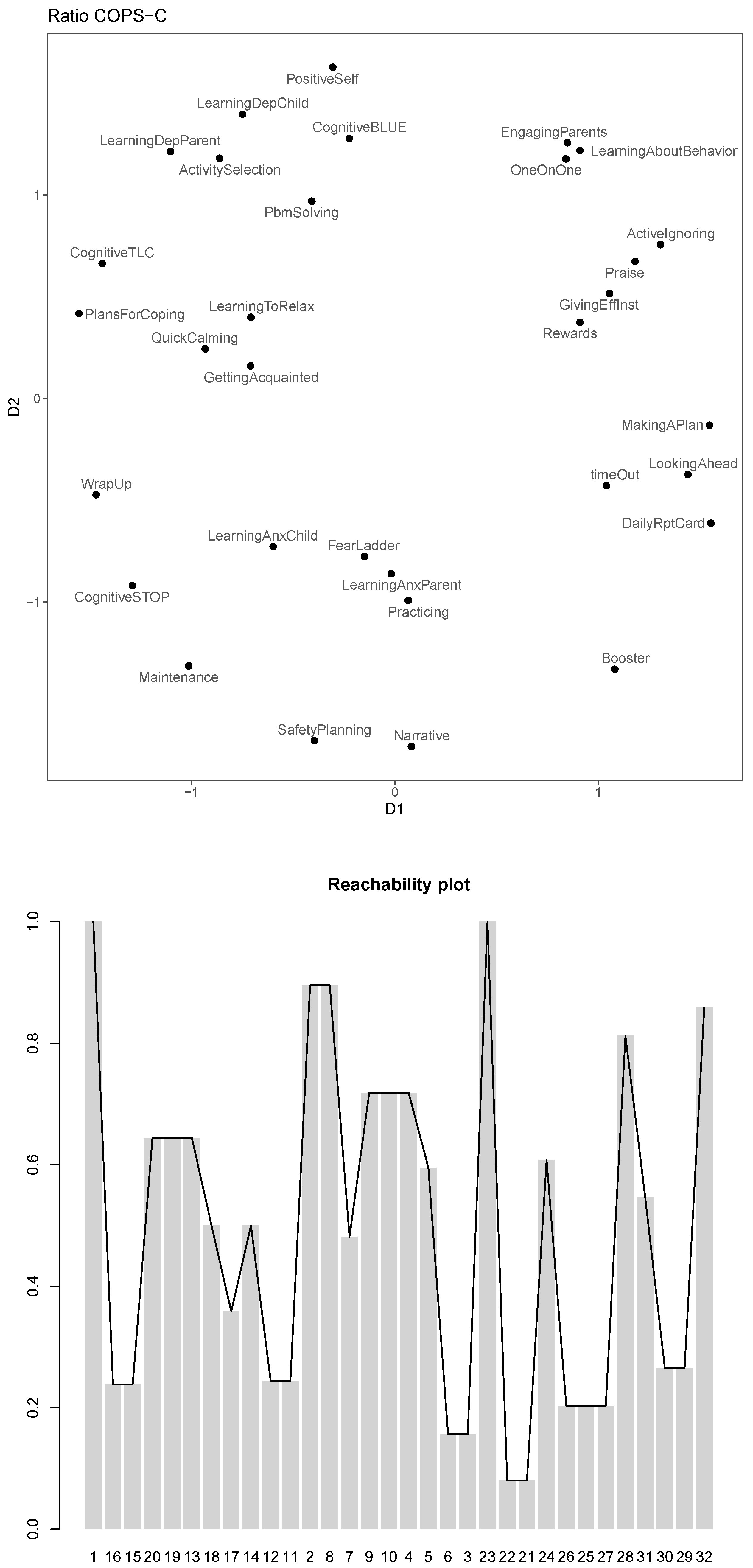
This solution has a stress-1 of
and
. The configuration plot and the corresponding reachability plot can be found in
Figure 5. Notice the winsorization effect of
for the reachabilities for modules
.
The clustering has indeed become clearer. In particular, clusters are now much denser than they were in the ratio solution owing to the interval transformation. We also see that within the overall organizing principle we identified before, clusters of modules are emphasized or new ones are revealed. For example, “Quick Calming” and “LearningToRelax” are now still close to “GettingAcquainted” but form their own tuple. They are also located in between depression and anxiety modules. The conduct modules “EngagingParents”, “LearningAboutBehavior”, “OneOnOne”, “Praise”, “ActiveIgnoring”, “Rewards” and “GivingEffInst” form a dense cluster and so do “MakingAPlan”, “timeOut”, and “LookingAhead”. The two trauma modules are now more clearly separated from the anxiety modules, but still relatively close. The anxiety modules form a bigger cluster with a denser nested cluster of “FearLadder”, “LearnAnxParent”, “LearnAnxChild” and “Practicing”. The non-relaxation related depression modules can be separated into two groups: “LearningDepChild”, “LearningDepParent”, “ActivitySelection”, “PbmSolving” on the one hand and “PositiveSelf”, “CognitiveBLUE”, “CognitiveTLC”, “PlansForCoping” on the other.
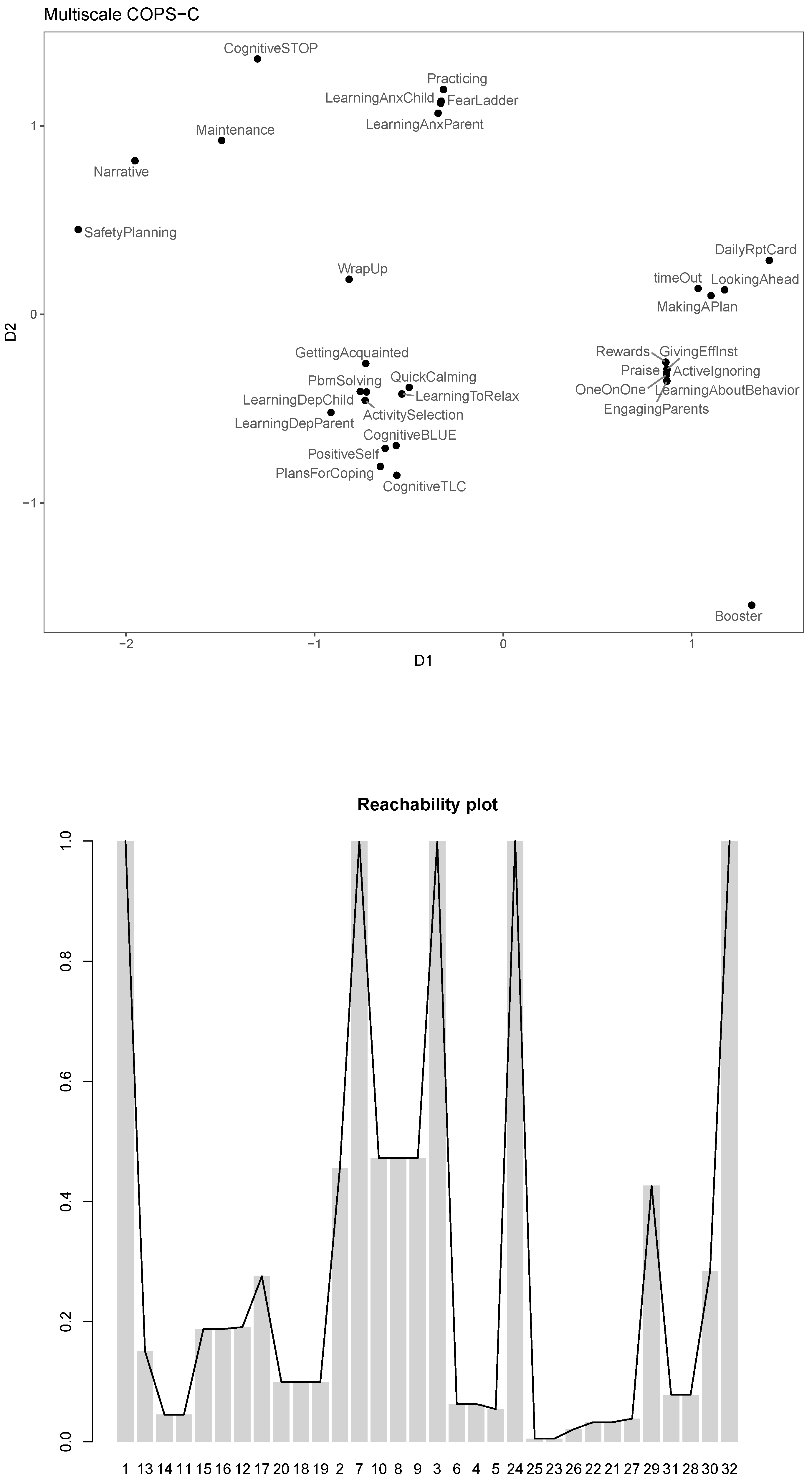
We now turn to see if there is additional insight we can gain from fitting other stresses. We first fit an s-stress COPS-C model, which emphasizes larger distances more strongly as ratio or interval COPS-C did; this may allow us to learn something new by focusing mostly on the modules with the largest profile distances. We then fit a multiscale COPS-C that does basically the opposite of s-stress by emphasizing local distances and variation more strongly because smaller distances are made relatively larger and larger distances are made relatively smaller by the log transformation. The respective configuration plots and the corresponding reachability plots can be found in
Figure 6 and
Figure 7.
We start with s-stress.
| R> ## S-Stress COPS-C |
| R> MDSMsst <− cops :: copstressMin (distM, type="ratio", kappa=2, lambda=2, |
| | dmax=dmax, minpts=minpts, q=q, |
| | stressweight=sw, cordweight=cw, |
| | itmax=itm) |
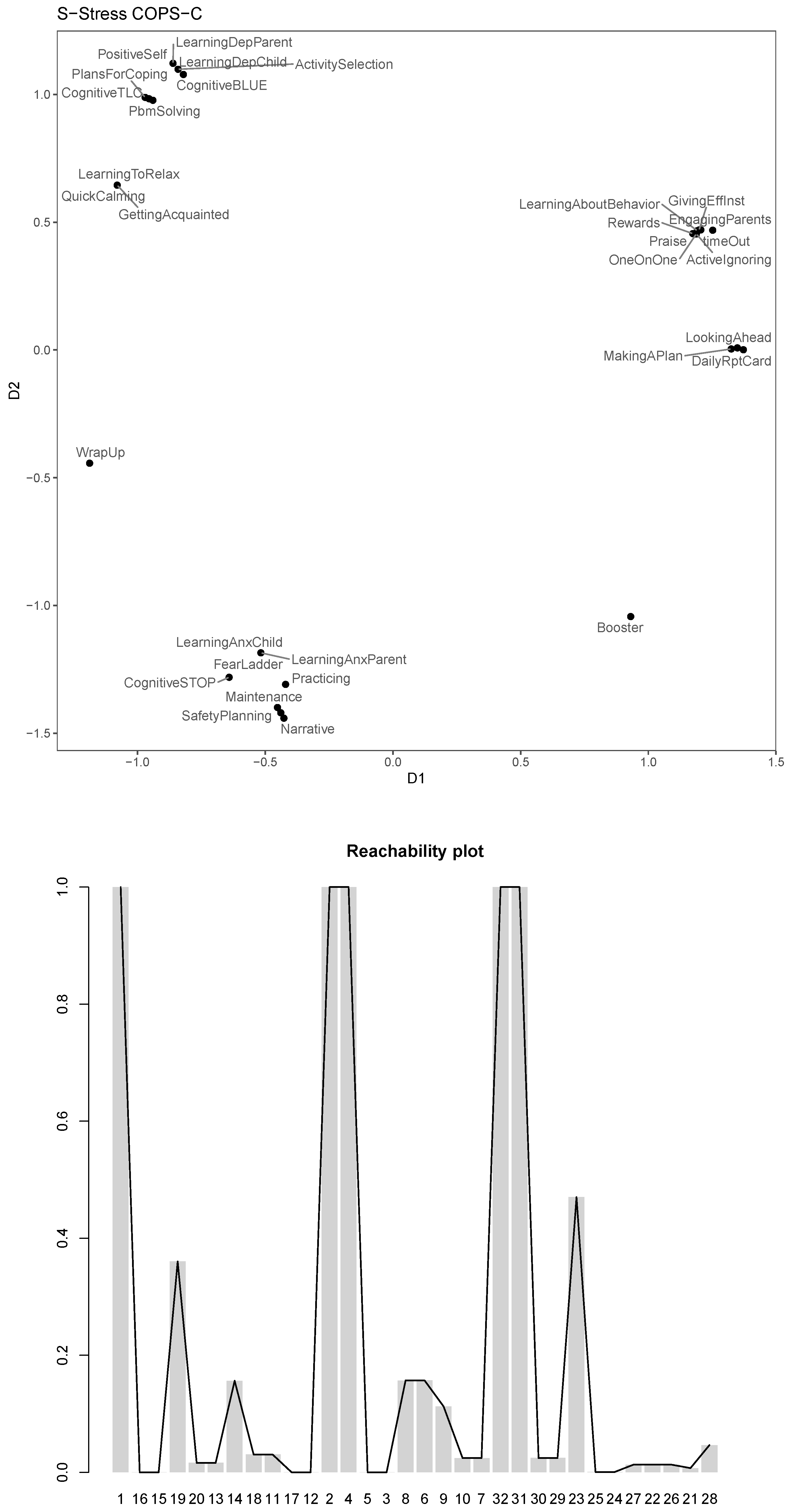
The s-stress COPS-C gives a stress-1 of
and an
. In
Figure 6, we see that clusteredness is high for the s-stress model (0.52), leading to many dense clusters of around 3 modules, which are often also nested within a larger cluster. The general story that we discussed in ratio and interval COPS-C is largely reproduced here, but emphasized: The conduct and depression modules cluster together and are organized in a number of similar clusters to what we had before, but the clusters are much denser. What is new is that with s-stress the trauma and anxiety modules now form one cluster with two very dense nested ones. “Booster” and “WrapUp” are individually singled out as being used differently to all other modules.
For multiscale COPS-C, we manually transform the to because they lie between 0 and 1, and we need non-negative dissimilarities. We further use the p-stress approximation to multiscale stress with .
| R> distM2 <− log (1 + distM) |
| R> diag (distM2) <− 0 |
| R> MDSMmsc <− cops :: copstressMin (distM2, type="ratio", kappa=0.1, |
| | dmax=dmax, minpts=minpts, q=q, |
| | stressweight=sw, cordweight=cw, |
| | itmax=itm) |
For multiscale COPS-C (see
Figure 7), we again have high clusteredness (0.51). While confirming some of the already established patterns, we also find new things: Of note is that “WrapUp” takes the center stage and is less close to “GettingAcquainted” as in the ratio and interval. The anxiety modules seem to fall into one cluster apart from “CognitiveSTOP” and “Maintenance”, the latter now bridging the anxiety and trauma modules. “Booster” seems to be used very differently to all the other modules, even the related conduct modules. To a certain degree, this was already suggested by prior analyses, but only in multiscale is “Booster” heavily represented as an outlier, mirroring the results from the OPTICS analysis, where it was considered to be a noise point.
Ratio, s-stress, and multiscale MDS are all special cases of p-stress resulting from different exponents of the power transformations
and
. The COPS framework also allows us to use this to search for optimal power transformations to obtain an MDS model that is highly clustered, without having to penalize the fit itself when looking for the configuration (as in COPS-C). This method is called P-COPS and is a special case of a larger framework, the STOPS framework, which allows us to select parameters in MDS based on structural considerations [
2]. We can run P-COPS for our data and see which
is suggested. We use a p-stress without weights (
loss=‘powermds‘) as the badness-of-fit measure. We specify to search for an optimal
in the region
for each parameter (thus encompassing ratio, s-stress and multiscale). This is done with the arguments
lower and
upper that take a numeric vector of the same length as
(here 2) with the lower and upper boundaries for the parameters, respectively.
| R> ## P-COPS (powermds loss) |
| R> MDSMpco <− cops :: pcops (distM, loss="powermds", |
| | minpts=minpts, rang=c (0, dmax), |
| | upper=c (5, 5), lower=c (0.01, 0.01), |
| | itmaxi=10000) |
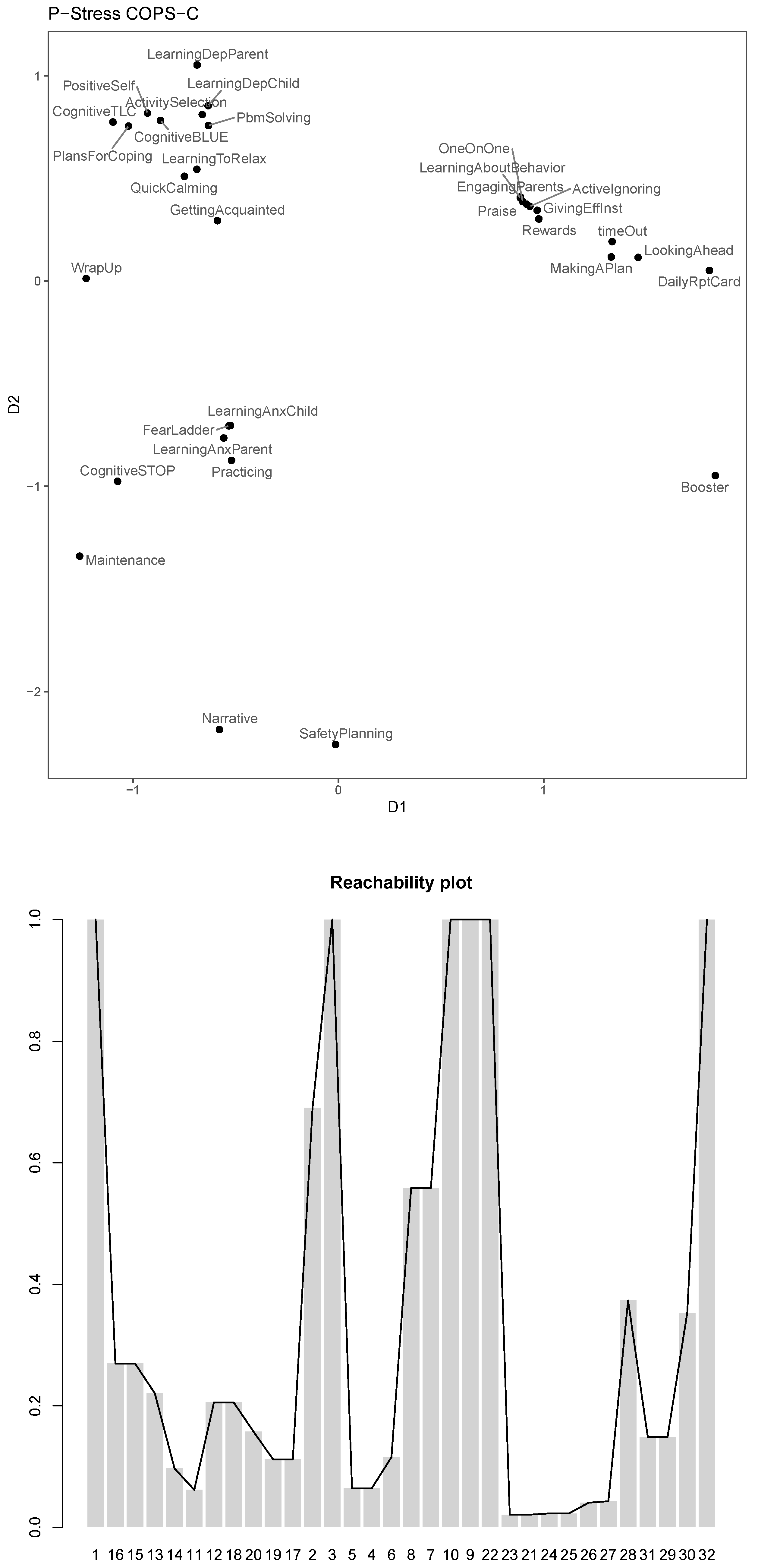
The optimal found is , which are in MDSMpco$par. Note that this means that the ratio, multiscale or s-stress models were not selected as optimal; rather the selected MDS model is close to and , which means it puts a lot of emphasis on the large dissimilarities and maps them to a concave function of the Euclidean distances emphasizing the variation in the smaller distances. The for this MDS model is 0.37, which is quite high given that we only achieved it by changing the transformation parameters and not by penalizing the configuration.
Nevertheless, we can combine the two: We can use the parameters found with P-COPS and fit a p-stress COPS-C with said and to further improve the clusteredness of that configuration. We also use the P-COPS configuration as the starting configuration init.
| R> ## Power Stress COPS-C |
| R> MDSMpst <− cops :: copstressMin (distM, |
| | kappa=MDSMpco$par[1], lambda=MDSMpco$par[2], |
| | stressweight=sw, cordweight=cw, |
| | itmax=itm) |
The stress-1 for this p-stress COPS-C is
and the
. The resulting configuration plot and the corresponding reachability plots can be found in
Figure 8.
We see that this configuration seems like a compromise of the results of the ratio, multiscale and s-stress models: dense and well separated clusters, “GettingAcquainted” and “WrapUp” are again scaled closer together, the conduct, depression, anxiety and trauma modules are grouped in well-separated clusters and within these clusters the scaling seems to suggest the nested subclusters already mentioned. “Booster” is once again clearly singled out as an outlier.
3.3. Faceting with COPS and SVM
We already alluded numerous times to a congruence between the spatial arrangement of the modules in the COPS results and the behavioral health concerns that MATCH-ADTC was developed for. Note that we arrived on that in an exploratory fashion; in this section, we formally analyze this congruence with the facet framework of [
14].
We use SVM to identify facets in the reduced space corresponding to the problems that MATCH addresses (called protocols): anxiety (ANX), depression (DEP), trauma (TRA) and conduct (CON). We also define the protocol General (GEN) to capture the cross-protocol modules “GettingAcquainted” and “WrapUp”.
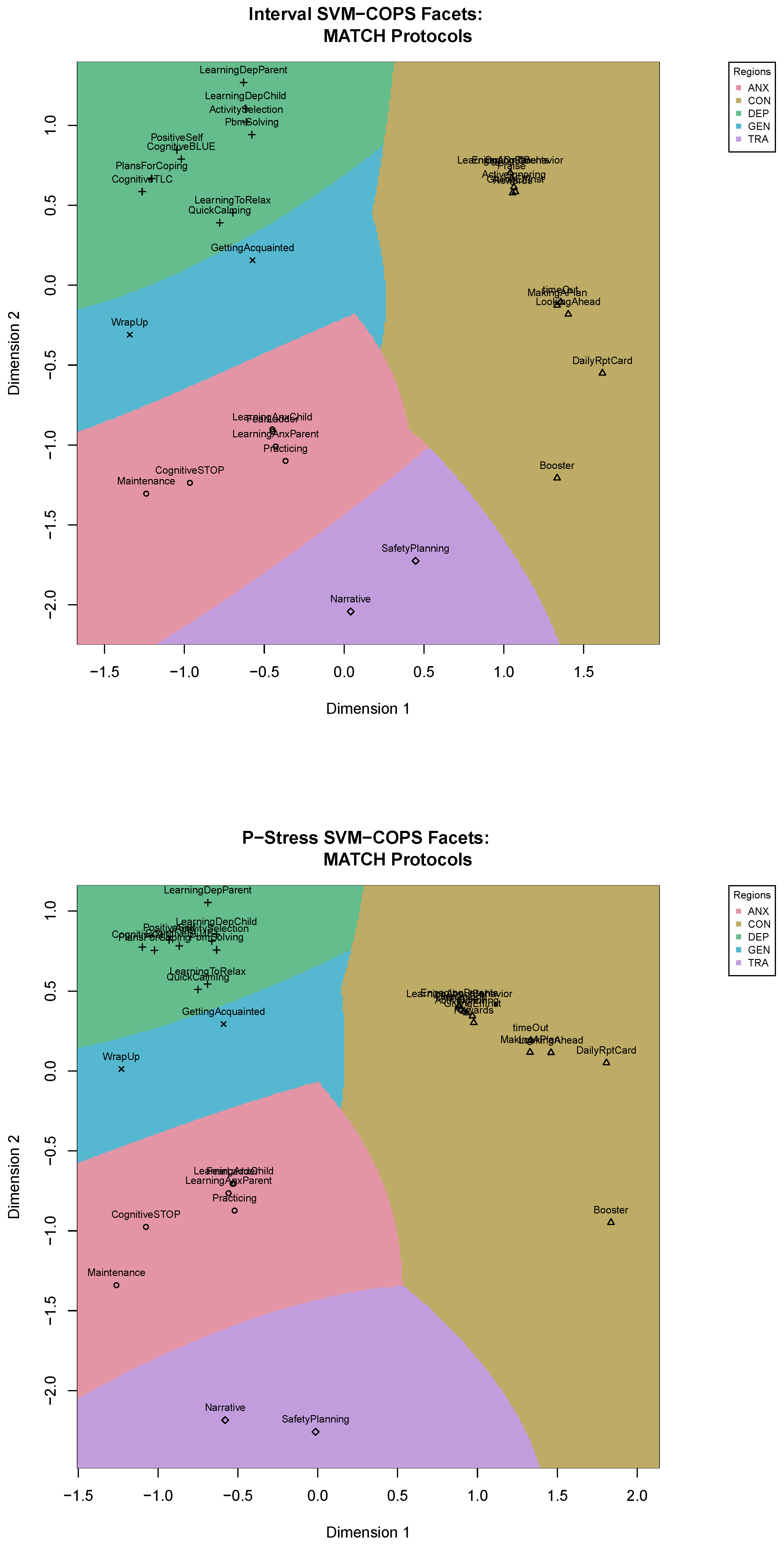
We will use the results of the interval COPS-C and of the p-stress COPS-C to derive our facets. We fit SVM with a radial kernel. We tune the SVM over costs of a constraint violation of 10 to 100 in steps of 2. The optimal cost parameter of the SVM is selected via a 10-fold cross-validation. For the best SVMs (optimal cost parameters of 16 and 18 for interval and p-stress COPS, respectively) we obtain perfect predictions: The partitioning of the COPS space allows us to perfectly allocate each module to its respective protocol. This is displayed in
Figure 9, where we used
svm_mdsplot from
smacof, which also works for objects returned by
cops. The most important information in this plot are the colored regions. To read the labels that are overplotted, one can refer to the configuration of points in
Figure 4 and
Figure 8, respectively, as they are the same ones.
Each protocol has a region associated with it in the respective COPS-C space, and each module’s assignment to its corresponding facet is perfect. There is also a circumplex-type structure of the protocol facets, meaning that trauma is located next to anxiety, anxiety next to depression and depression next to conduct. Conduct then also borders on trauma, although the modules of each protocol are further apart (especially in the p-stress result).
When exploring the configurations with the facets in
Figure 9, we see that the scaling results suggest clusters within each facet. To explore this further, we made use of the FIRST principles [
7] that provide a theory-based categorization of the modules into empirically supported principles of change (ESPCs), or common cross-cutting treatment techniques in evidence-based youth psychotherapies. These ESPCs were derived via a review of relevant literature, e.g., [
40,
41], and subsequently by a panel of experts consisting of both researchers and practitioners [
7]. These ESPCs include “Relationship Building” (e.g., get-to-know-you activities and psycho-education; RelBuild), “Future Planning” (e.g., discussing how a skill might be used in the future and how to identify relapses; FutPlan), “Trying the Opposite” (e.g., exposure to feared stimuli and behavioral activation; TTO), “Repairing Thoughts” (e.g., working to change hostile attributions and excessively negative thinking patterns; RepThou), “Solve Problems” (e.g., naming the problem and thinking of possible solutions; SolvProb), “Increasing Motivation” (e.g., rewards for desired behaviors or time outs; IncMot) and “Feeling Calm” (e.g., deep, slow breathing and calming imagery; FeelCalm). Each module belongs to one ESPC. We thus classify the modules based on protocol and ESPC into a combined category. For example, “Practicing” is ANX-TTO and “Narrative” is TRA-TTO. We are interested in two aspects: a) within each protocol are there modules that are used similarly and are of the same ESPC or b) within each protocol, do the similar modules vary with respect to ESPCs, so do clinicians use modules from different EPSC similarly?
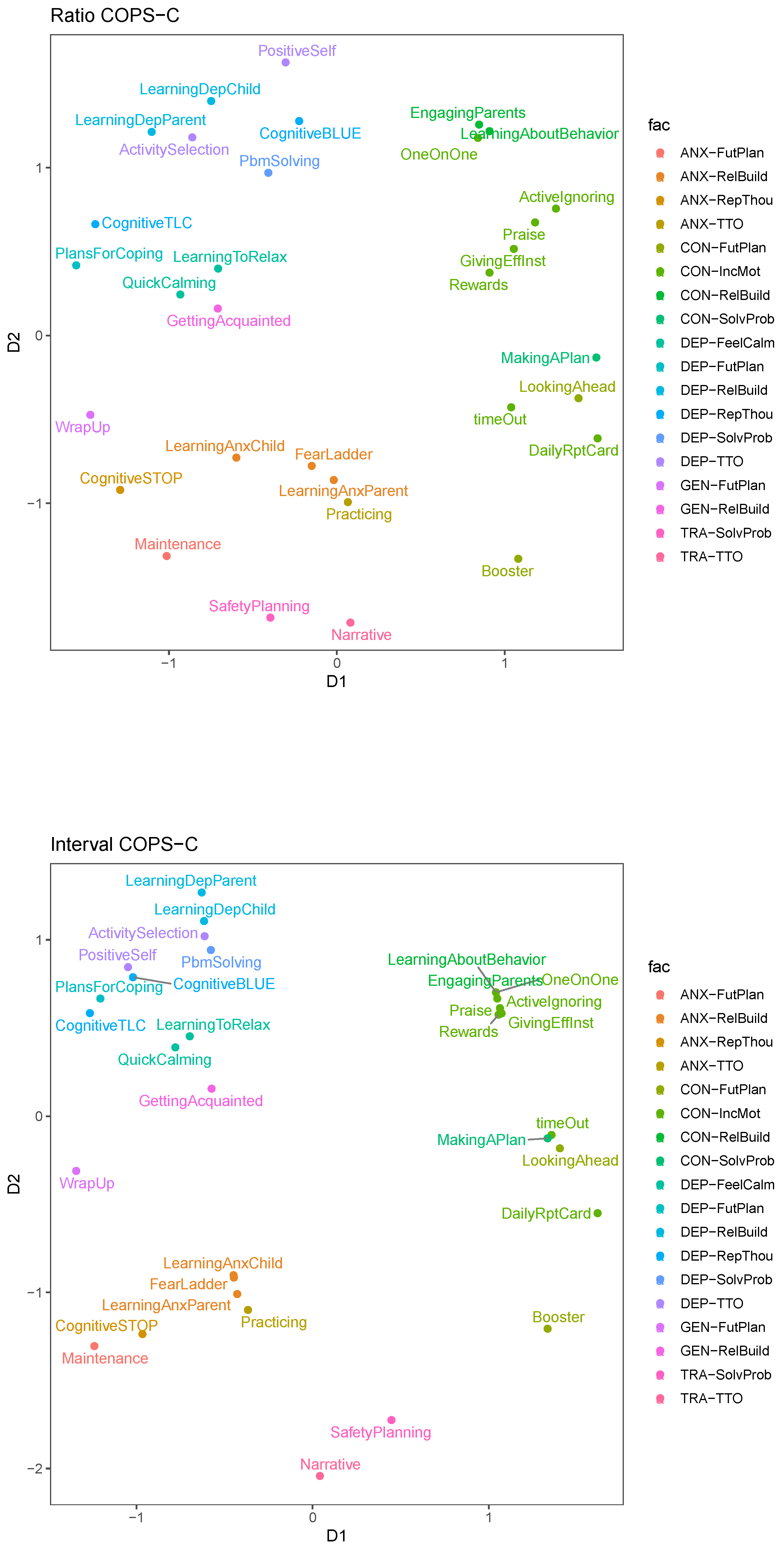
To that end, we use the results from ratio and interval COPS-C and color the modules based on their combined Protocol-ESPC categorization. This is shown in
Figure 10, where in both results we see that in the top left quadrant, the depression facet, modules of different ESPC cluster together (e.g., for interval COPS-C “LearningDepChild” and “LearningDepParent”, which are RelBuild with “ActivitySelection”, which is TTO and “PbmSolving”, which is SolveProb). The use of the modules in this facet appears relatively diverse; if we look at the ratio COPS-C result then the depression facet shows a fairly equidistant use of modules from six different ESPCs (RelBuild, TTO, RepThou, FutPlan, FeelCalm and SolvProb). In the interval COPS-C there is fragmentation into more homogeneous subclusters, but there are still at least three ESPCs per cluster (out of four modules). The one exception are the FeelCalm modules, which are of the same ESPC.
For anxiety, the picture is a bit different. In both COPS-C results, there is a cluster with three RelBuild modules (“LearningAnxChild”, “LearningAnxParent”, “FearLadder”) and also “Practicing” (TTO). “Maintenance” and “CognitiveSTOP” are a bit removed and form a relatively dispersed cluster with the RelBuild ones. Overall, in the anxiety facet, the use of the modules is less diverse than it was with depression. This is partially attributable to the anxiety facet only comprising modules of four ESPCs, but still the anxiety modules show a more homogeneous picture due to the ANX-RelBuild modules scaled close together.
For conduct modules, we find two dense clusters of at least three modules (interval COPS-C) or three clusters of at least three modules (ratio COPS-C) with varying densities. In the ratio COPS-C, we see that two out of three clusters are relatively homogeneous with respect to the ESPCs. The cluster of “ActiveIgnoring”, “Praise”, “Rewards” and “GivingEffInst” is perfectly homogeneous with instances of the IncMot ESPC. The other dense cluster contains “LearningAboutBehavior” and “EngagingParents”, which are both RelBuild and they cluster with “OneOnOne”, which is IncMot. In the interval COPS-C, these two clusters are merged into one very dense cluster, making this a relatively homogeneous cluster comprising seven modules of only two ESPCs (IncMot and RelBuild). There is also a relatively diverse dense cluster in the conduct facet, which is the one comprising “MakingAPlan” (SolvProb), “timeOut” (IncMot), “LookingAhead” (FutPlan) in interval COPS-C, which presents as a dispersed cluster enhanced with “DailyRptCard” (IncMot) in the ratio COPS-C.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









