


Analytics 2024, 3(4), 461-475; https://doi.org/10.3390/analytics3040026 - 11 Nov 2024
Abstract
►
Show Figures
Breast cancer is the most prevalent type of disease among women. It has become one of the foremost causes of death among women globally. Early detection plays a significant role in administering personalized treatment and improving patient outcomes. Mammography procedures are often used
[...] Read more.
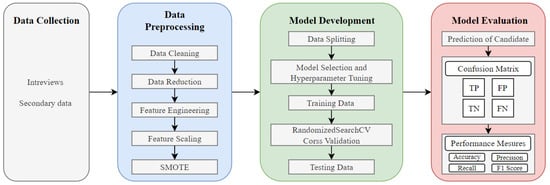
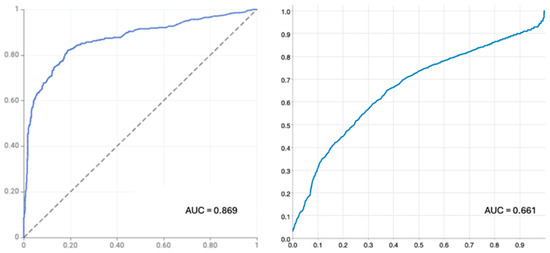
Breast cancer is the most prevalent type of disease among women. It has become one of the foremost causes of death among women globally. Early detection plays a significant role in administering personalized treatment and improving patient outcomes. Mammography procedures are often used to detect early-stage cancer cells. This traditional method of mammography while valuable has limitations in its potential for false positives and negatives, patient discomfort, and radiation exposure. Therefore, there is a probe for more accurate techniques required in detecting breast cancer, leading to exploring the potential of machine learning in the classification of diagnostic images due to its efficiency and accuracy. This study conducted a comparative analysis of pre-trained CNNs (ResNet50 and VGG16) and vision transformers (ViT-base and SWIN transformer) with the inclusion of ViT-base trained from scratch model architectures to effectively classify mammographic breast cancer images into benign and malignant cases. The SWIN transformer exhibits superior performance with 99.9% accuracy and a precision of 99.8%. These findings demonstrate the efficiency of deep learning to accurately classify mammographic breast cancer images for the diagnosis of breast cancer, leading to improvements in patient outcomes.
Full article
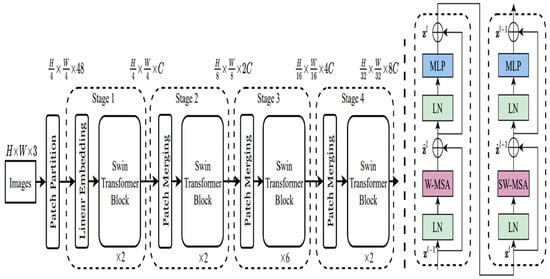
Figure 1



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}