




Appl. Sci. 2022, 12(15), 7541; https://doi.org/10.3390/app12157541 - 27 Jul 2022
Cited by 1 | Viewed by 2440
Abstract
►
Show Figures
Advances in data generation and acquisition have resulted in a volume of available data of such magnitude that our ability to interpret and extract valuable knowledge from them has been surpassed. Our capacity to analyze data is hampered not only by their amount
[...] Read more.
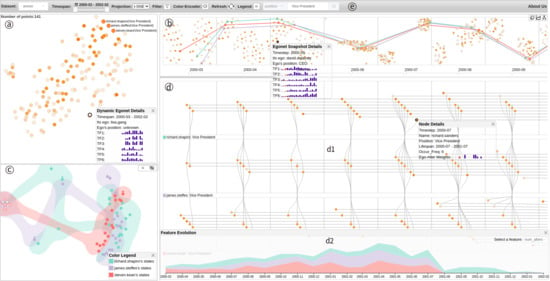
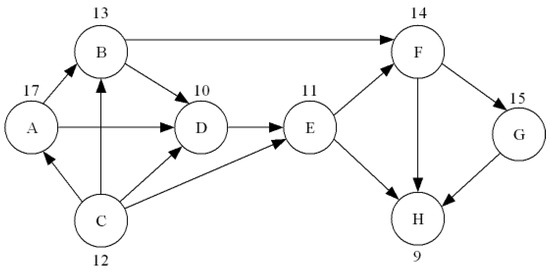
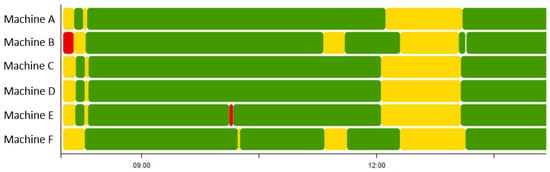
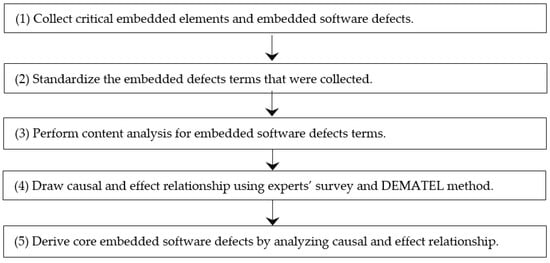
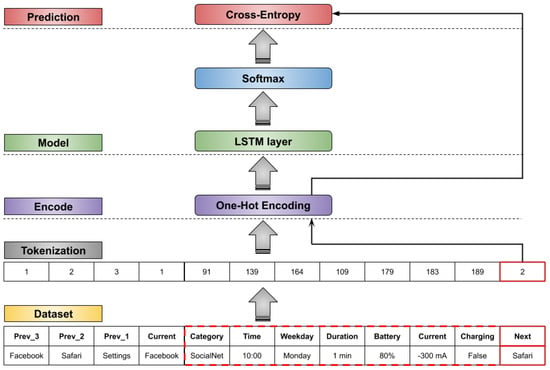
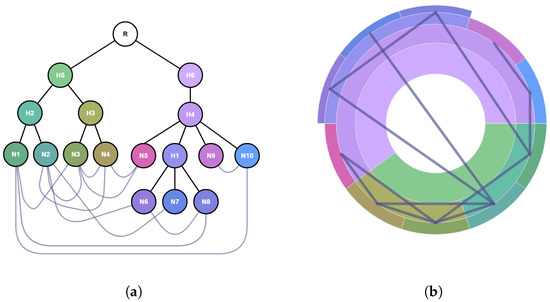
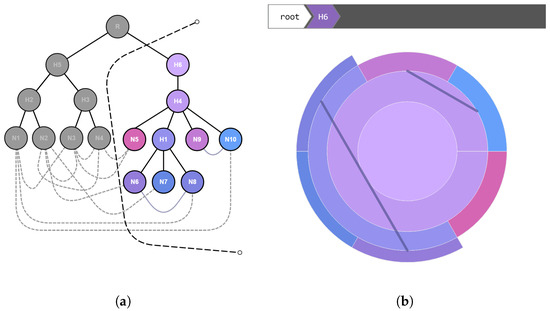
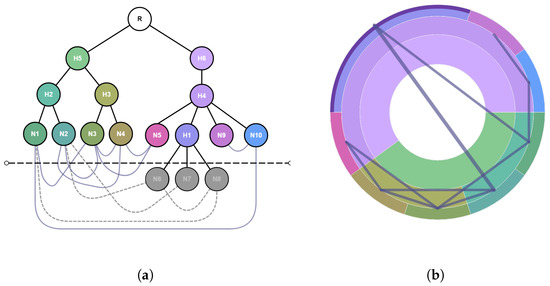
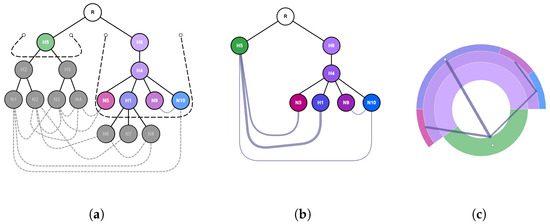
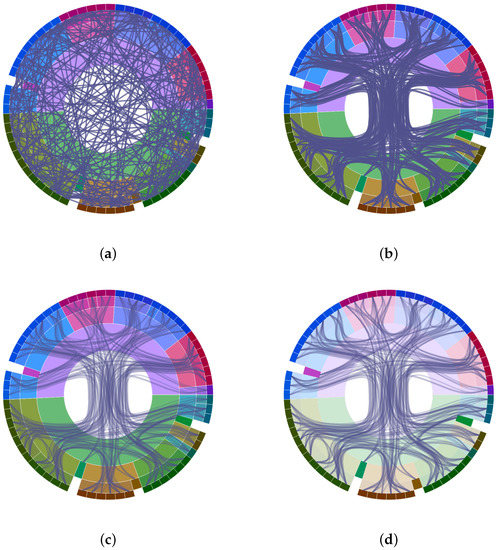
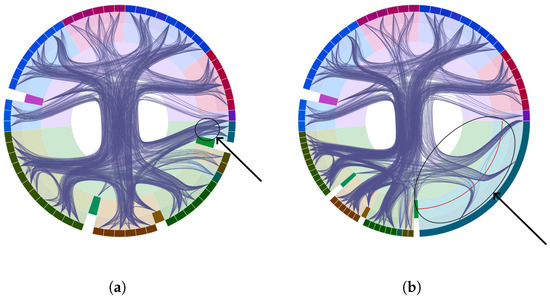
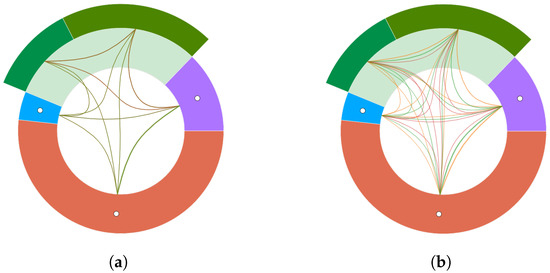
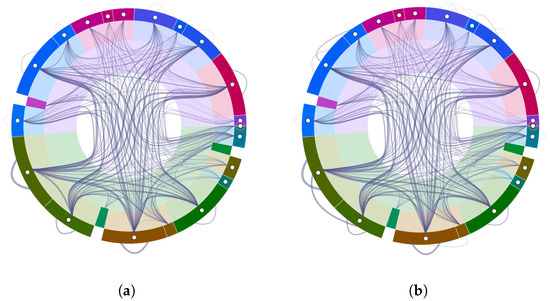
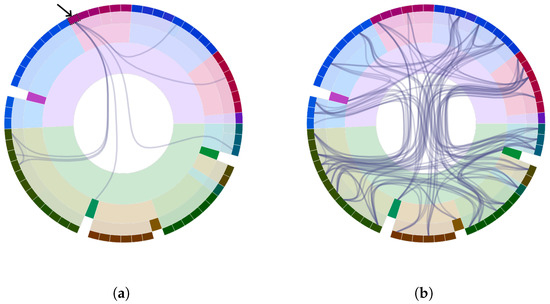
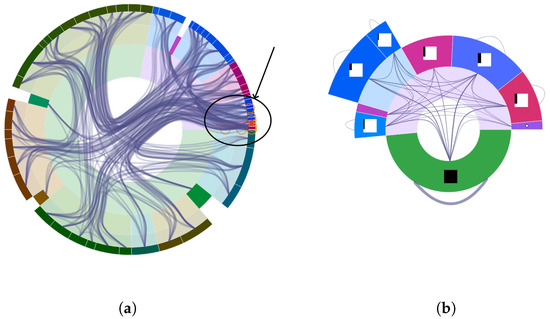
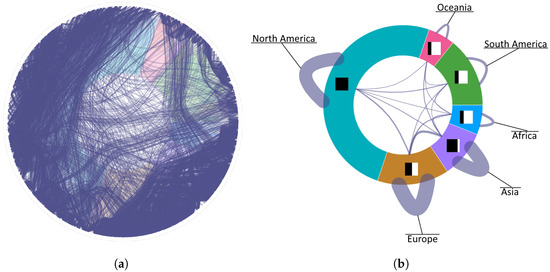
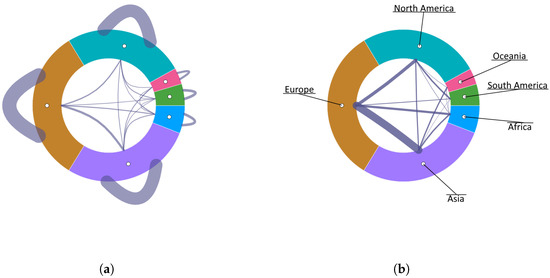
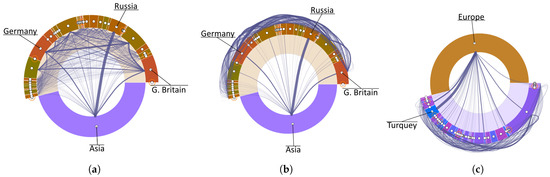
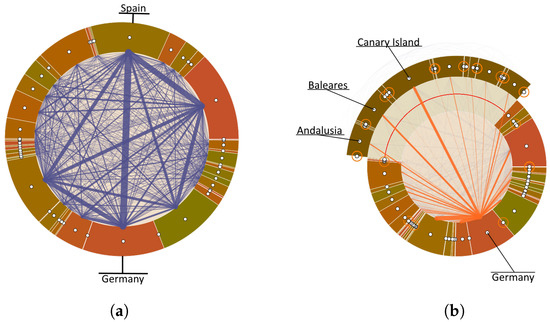
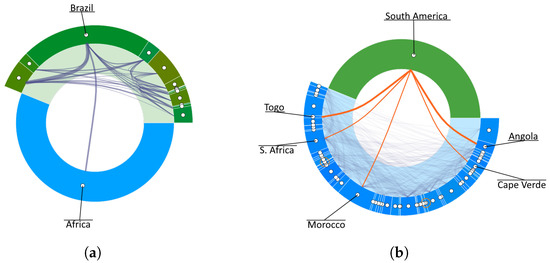
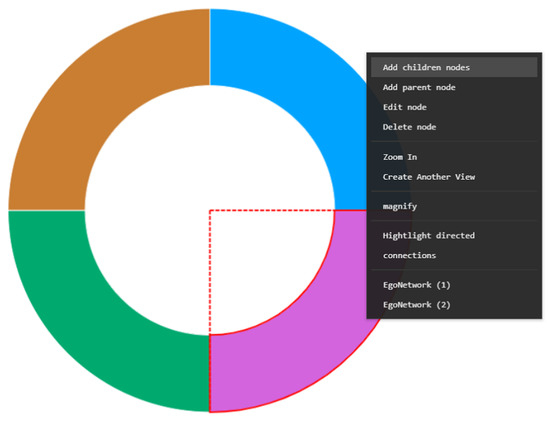
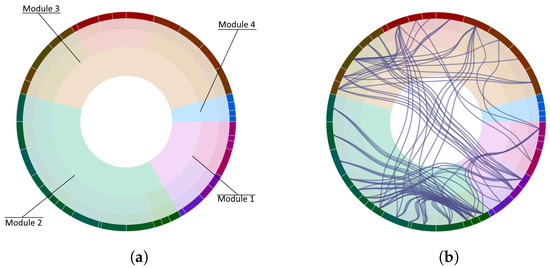
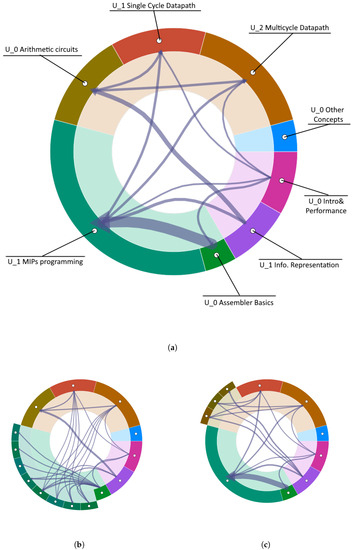
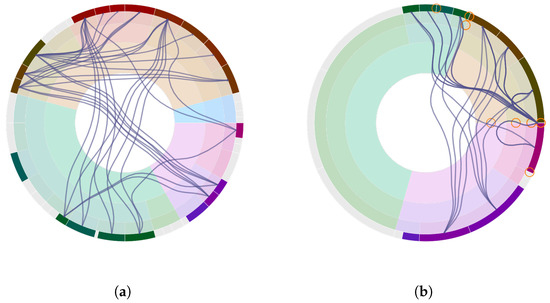
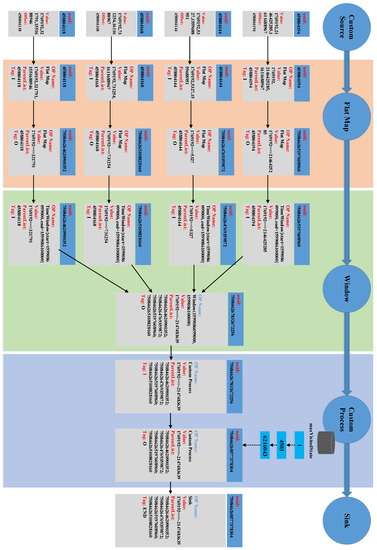
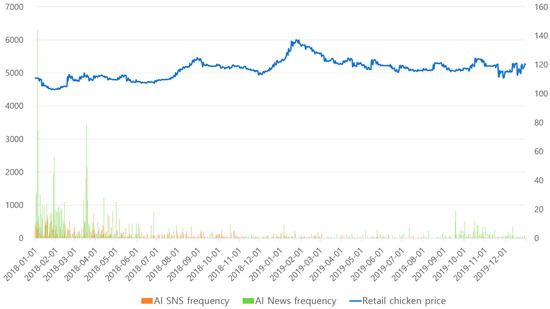
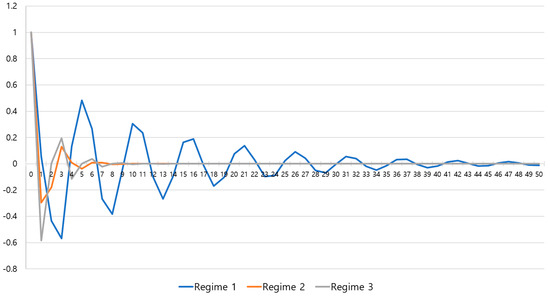
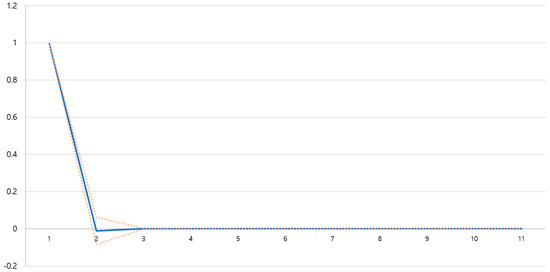
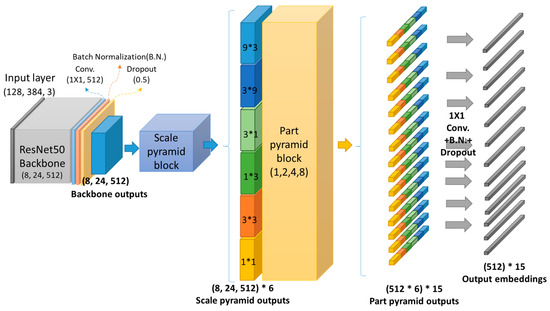
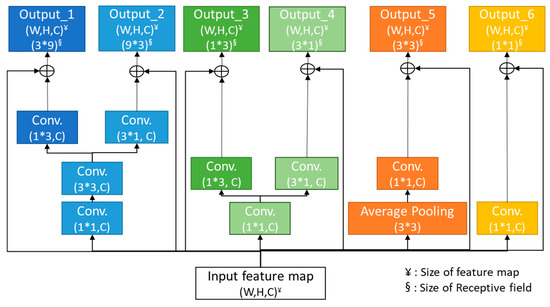
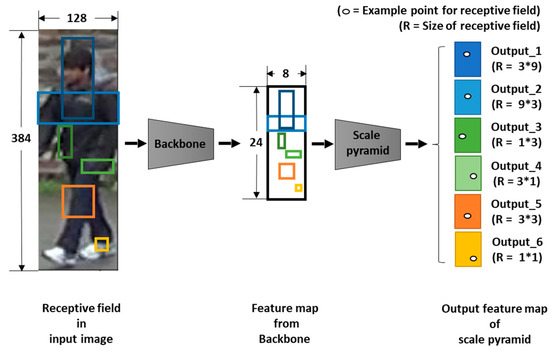
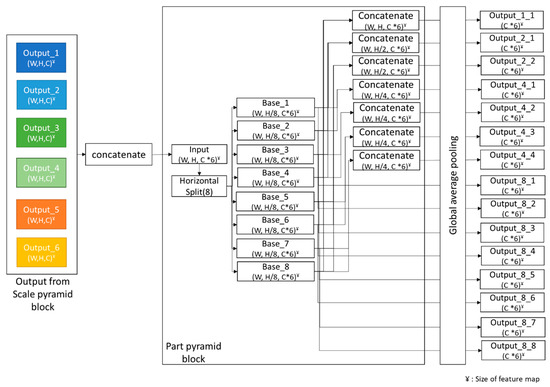
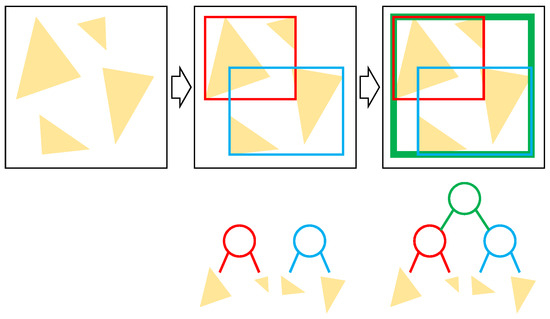
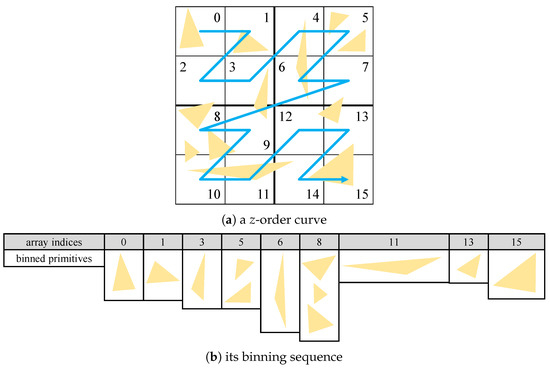
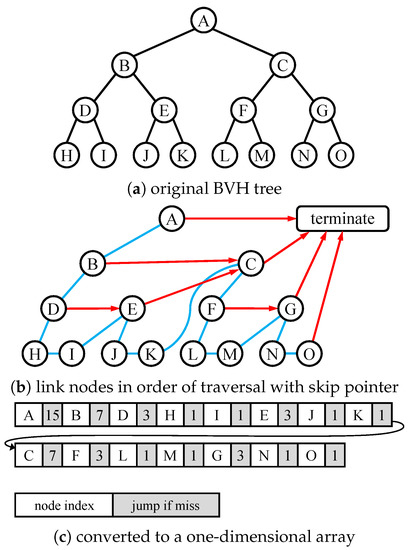
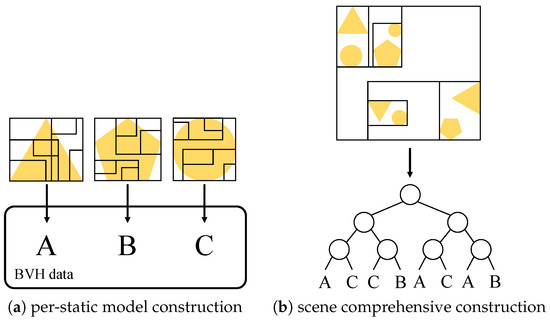
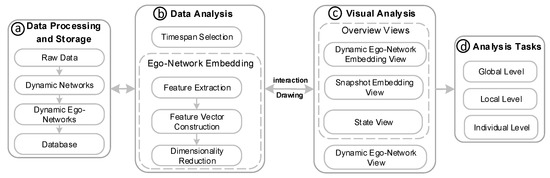
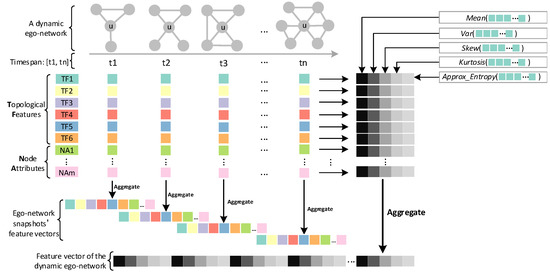
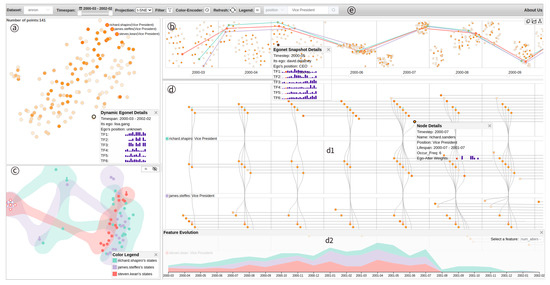
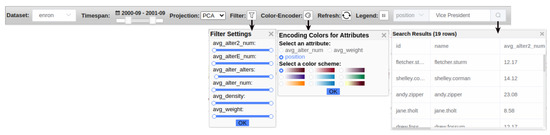
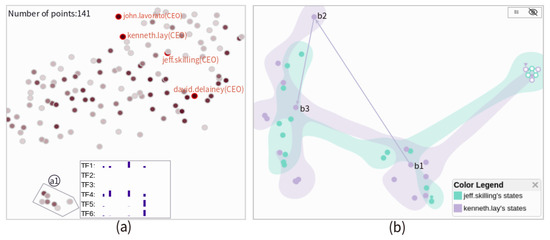
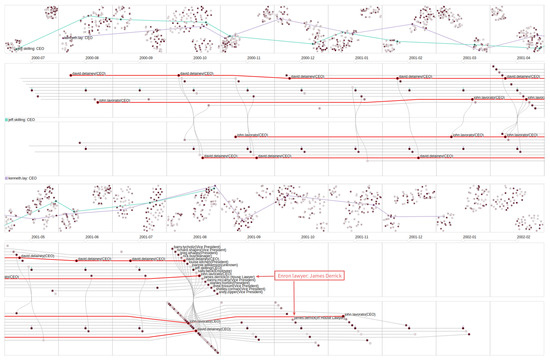
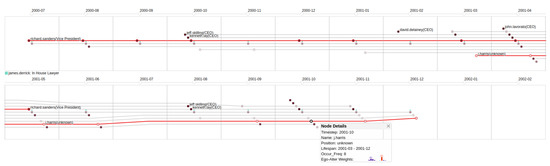
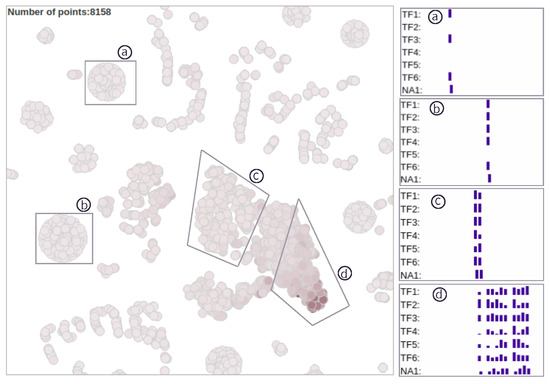
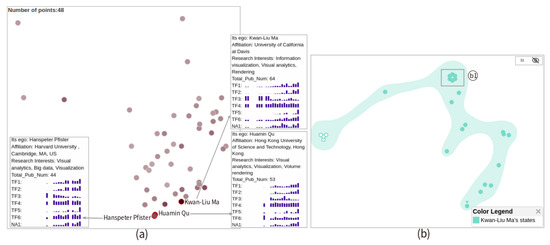
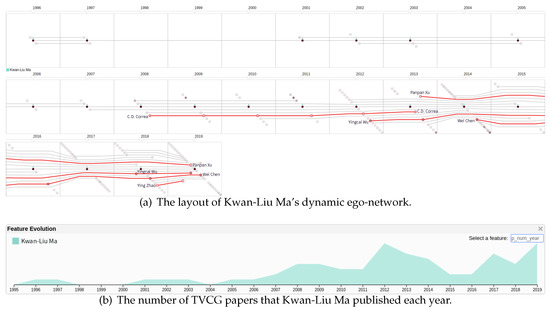
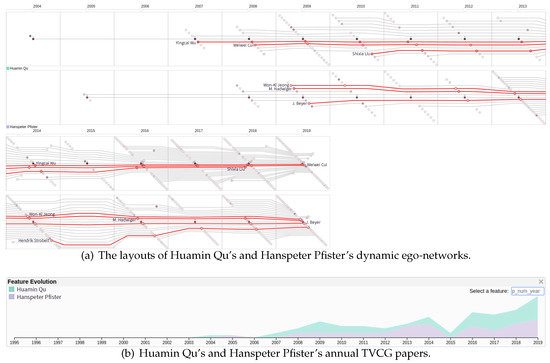
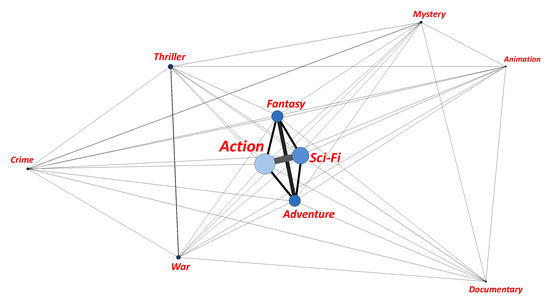
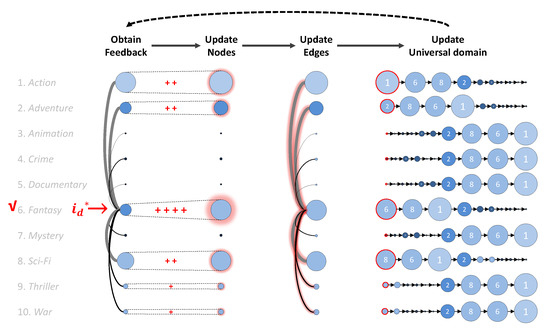
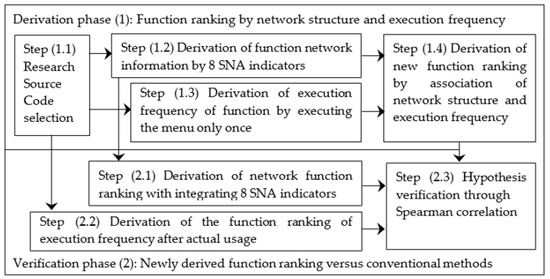
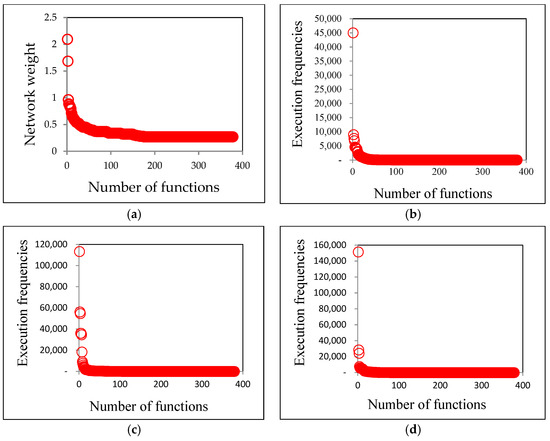
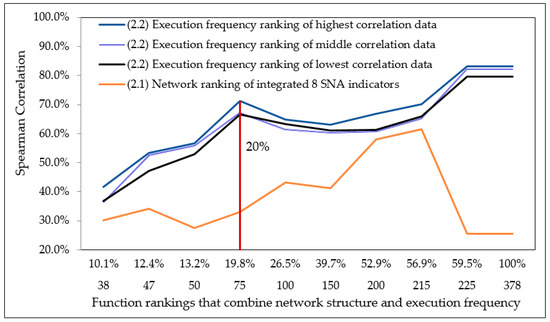
Advances in data generation and acquisition have resulted in a volume of available data of such magnitude that our ability to interpret and extract valuable knowledge from them has been surpassed. Our capacity to analyze data is hampered not only by their amount or their dimensionality, but also by their relationships and by the complexity of the systems they model. Compound graphs allow us to represent the existing relationships between nodes that are themselves hierarchically structured, so they are a natural substrate to support multiscale analysis of complex graphs. This paper presents Carbonic, a framework for interactive multiscale visual exploration and editing of compound graphs that incorporates several strategies for complexity management. It combines the representation of graphs at multiple levels of abstraction, with techniques for reducing the number of visible elements and for reducing visual cluttering. This results in a tool that allows both the exploration of existing graphs and the visual creation of compound graphs following a top-down approach that allows simultaneously observing the entities and their relationships at different scales. The results show the applicability of the developed framework to two use cases, demonstrating the usefulness of Carbonic for moving from information to knowledge.
Full article
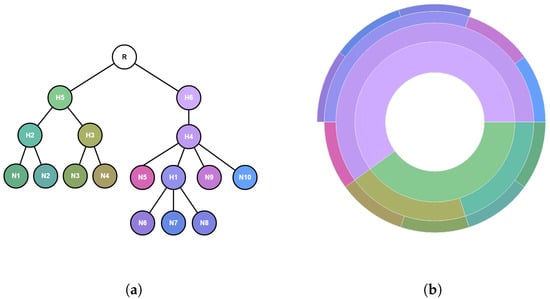
Figure 1



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
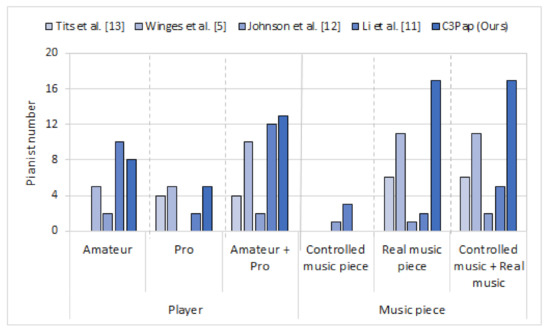{kind=link}
{kind=link}
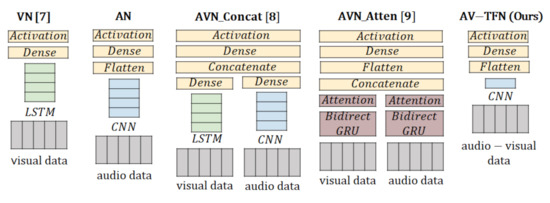{kind=link}
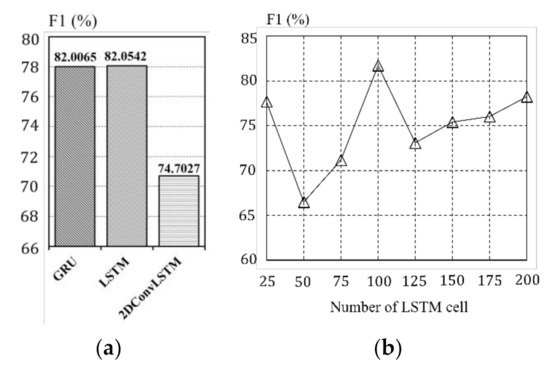{kind=link}
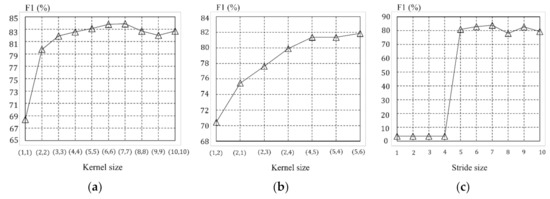{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}