
A Dimensional Comparison between Evolutionary Algorithm and Deep Reinforcement Learning Methodologies for Autonomous Surface Vehicles with Water Quality Sensors



Abstract
:1. Introduction
- A () Evolutionary Algorithm and a Deep Q Learning approach for the resolution of the Non-Homogeneous Patrolling problem in Ypacaraí Lake.
- A performance comparative analysis of the sample-efficiency metric and computation time using non-intensive computation resources.
- An analysis on the reactivity and generalization of the solutions provided by the tested methodologies for different resolutions, number of agents and changing environments.
2. Related Work
2.1. Deep Reinforcement Learning in Path Planning
2.2. Genetic Algorithms in Path Planning
2.3. DRL and EA Comparison Overview
3. Statement of the Problem
3.1. The Patrolling Problem
3.2. Simulator and Assumptions
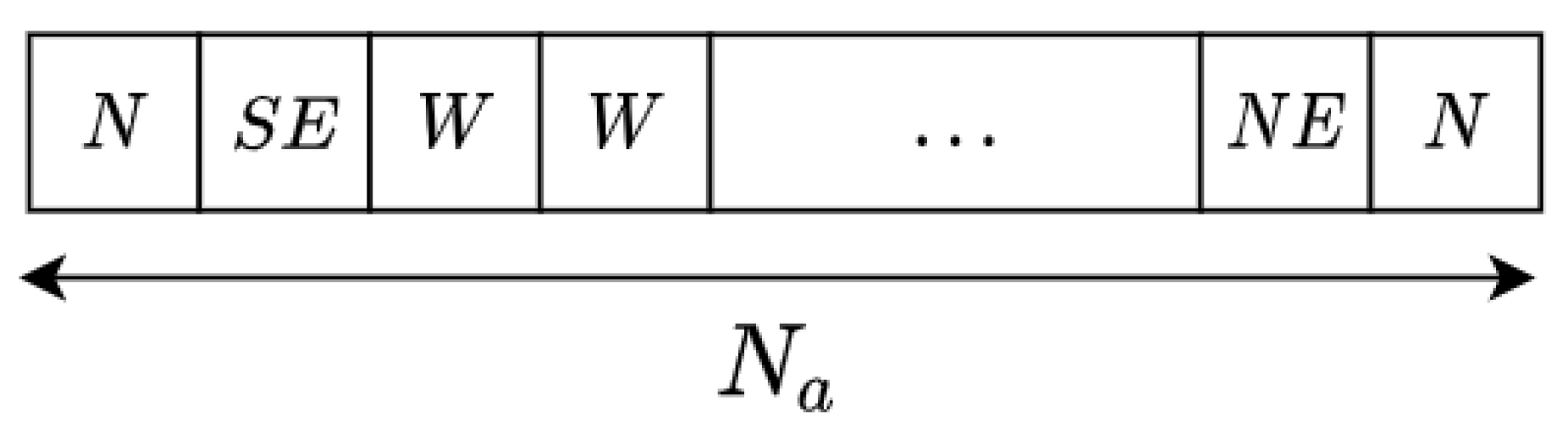
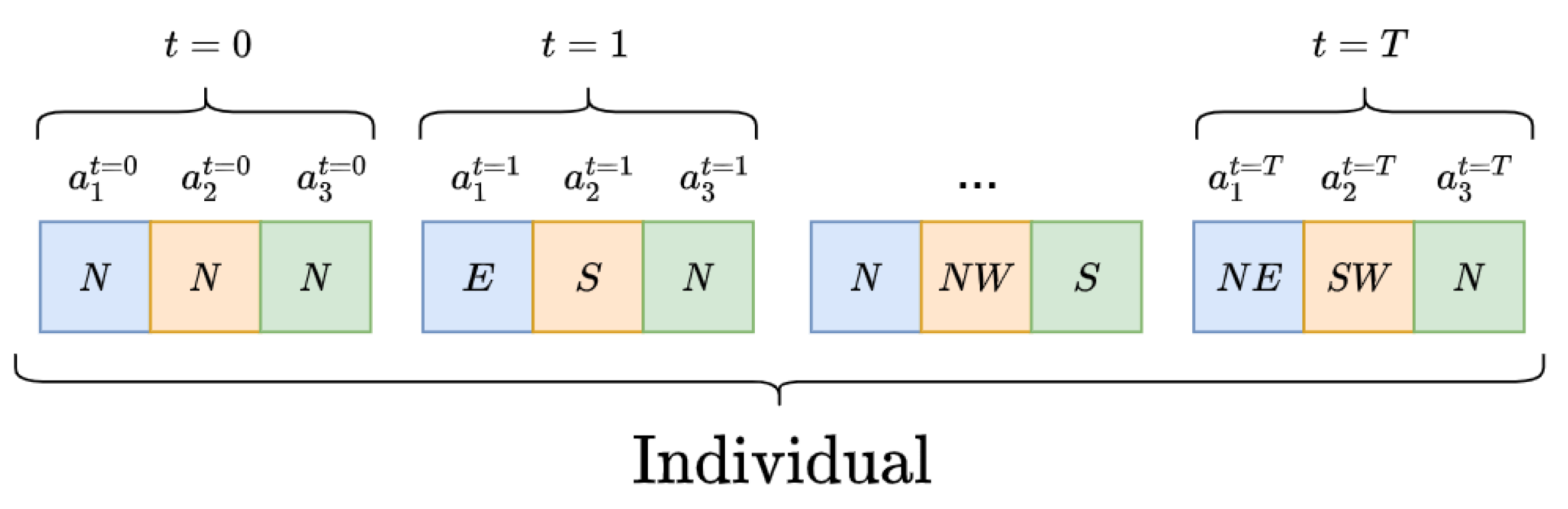
- The space action of the agent is defined by 8 different actions a. Every action, if possible, is equivalent to a waypoint in the adjacent cells. This way, the action space is defined as .
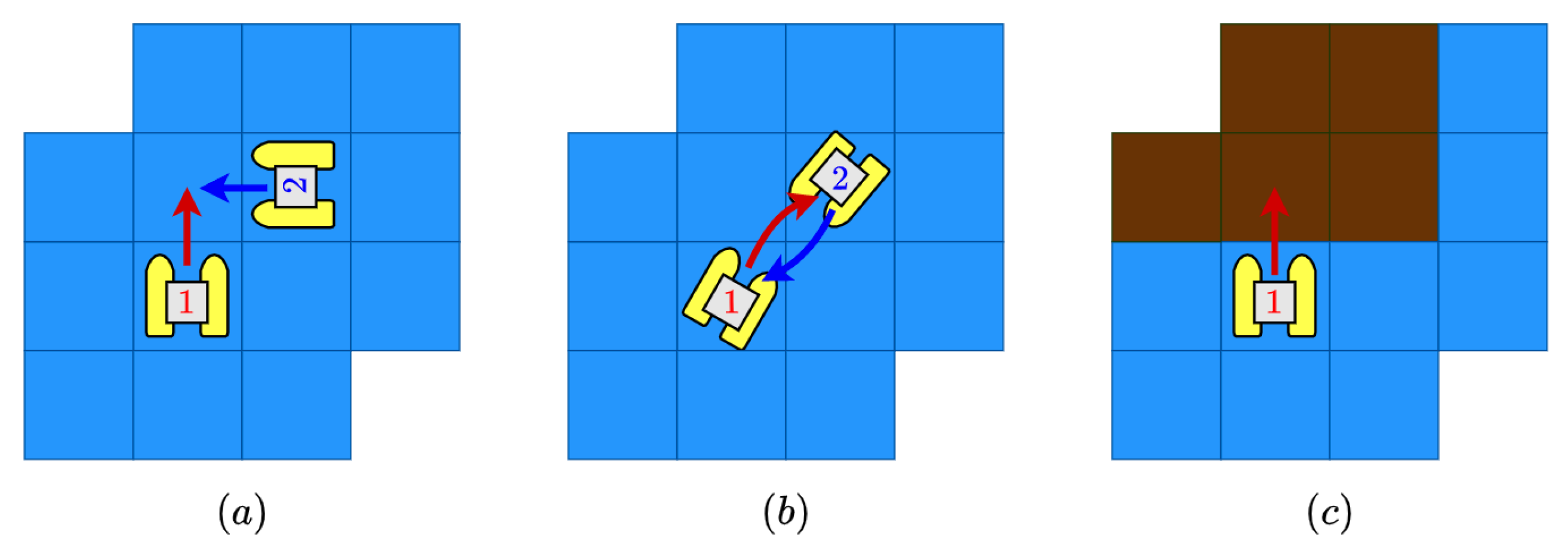
- In both the multi-agent and single-agent case, collision may occur. Three different possible collisions are considered: same-goal collision (two agents move to the same cell), in-way collision (two agents collide in the way to exchange its positions) and an non-navigable collision (the agent intent a movement outside the Lake). In Figure 5, a graphic example of these three possibilities is depicted.
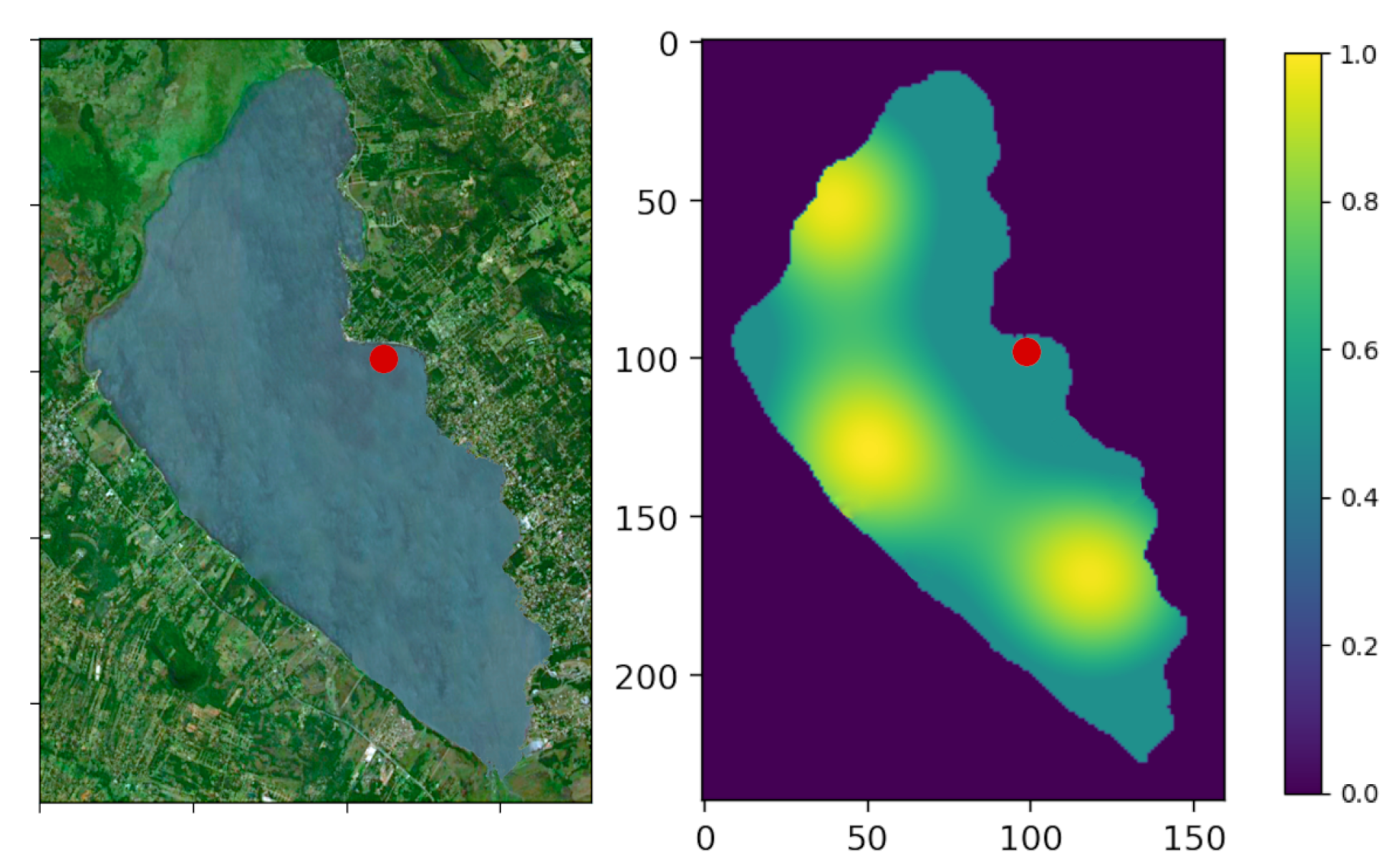
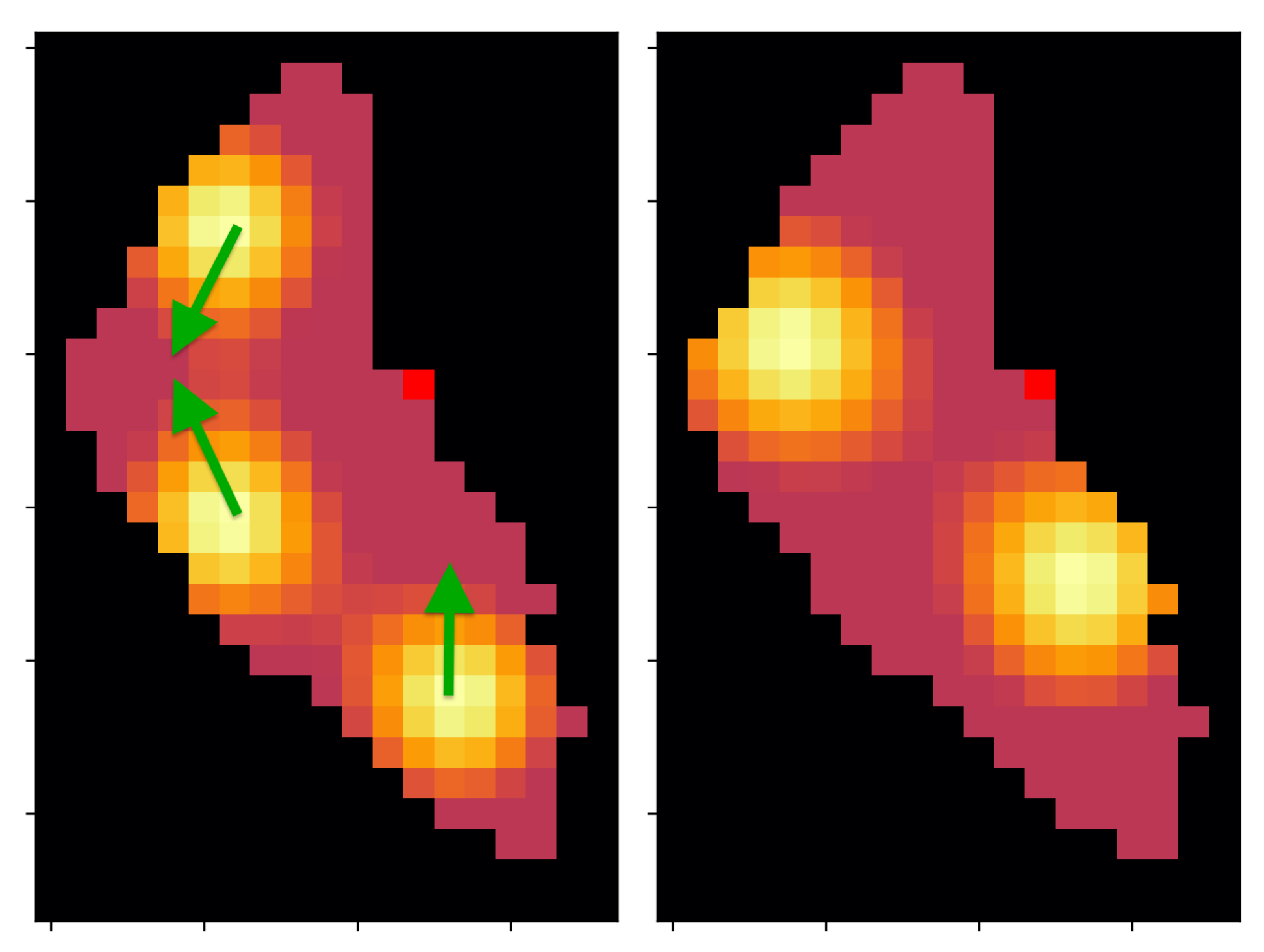
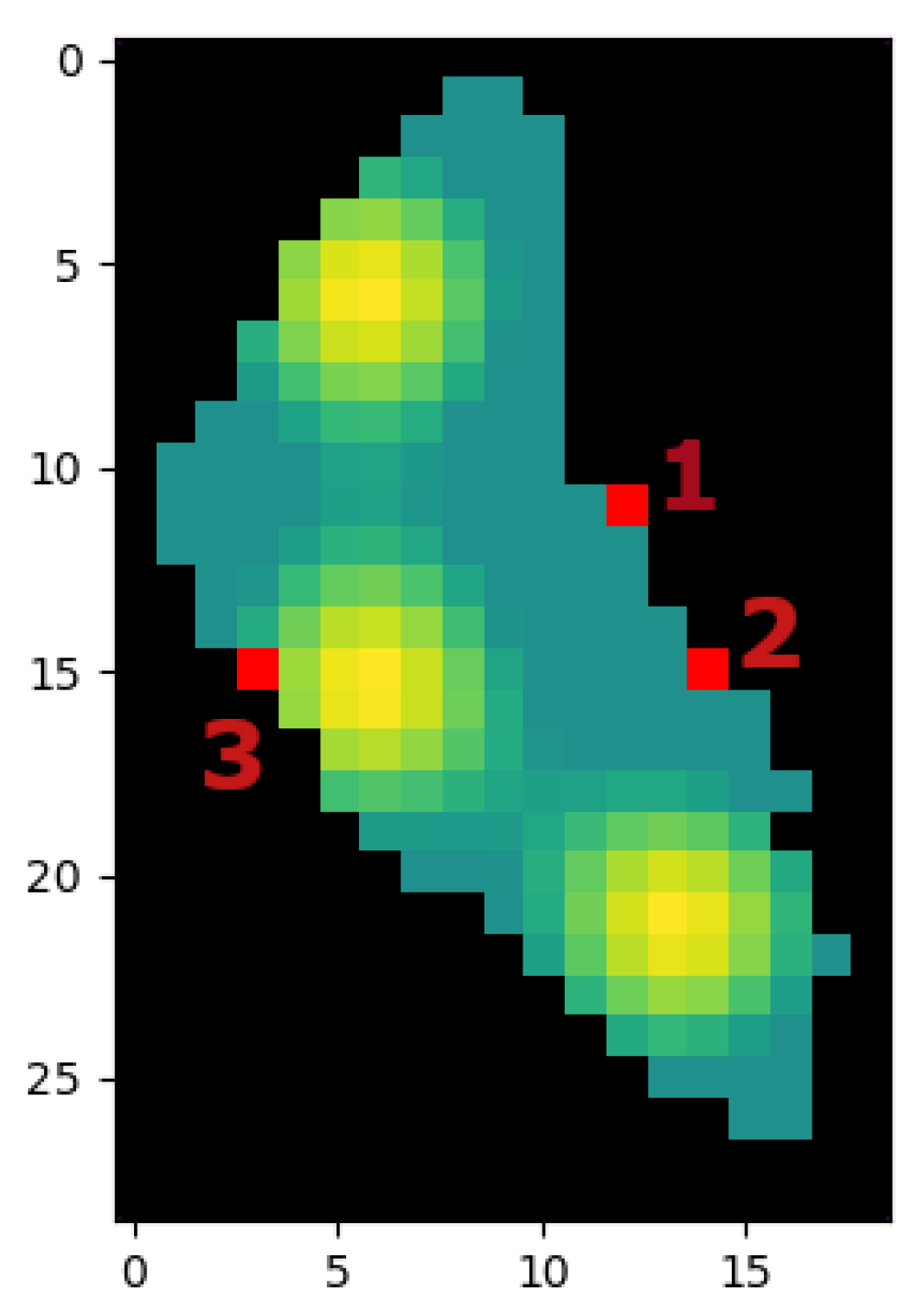
- The importance map is defined in Figure 3 and discretized depending on the resolution N.
- One deploy zone is defined for the agent to start (see Figure 3).
- Every ASV can travel along ∼39.5 km at full speed (2 m/s) considering the battery restrictions. This distance is translated to movements depending on the chosen resolution of the map.
- It is imposed that the local planner can lead the agent to another cell, different from the desired one, because of control errors and disturbances. There will be always a 5% probability to move to another cell different from the selected one.
4. Methodology
4.1. Reward Function
4.2. Evolutionary Algorithm
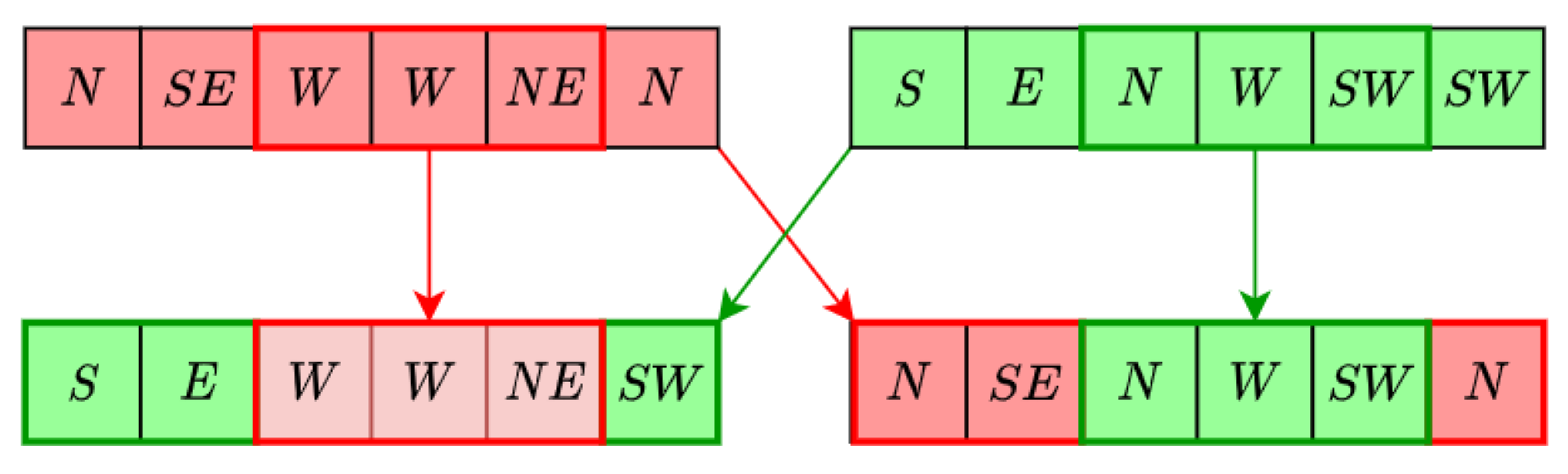
4.2.1. Algorithm
- A population of individuals is randomly initiated.
- top individuals are selected using a tournament method.
- From the extended population formed by , individuals are selected by tournament selection to pass to the following generation.
4.2.2. Multi-Agent EA
4.3. Double Deep Q-Learning
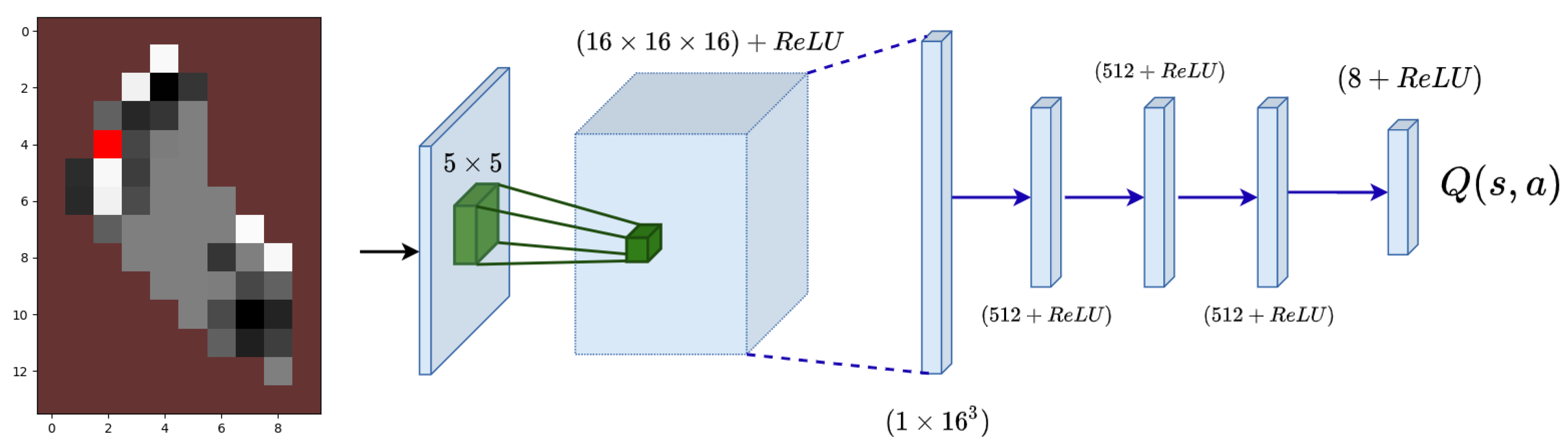
4.3.1. State and Deep Q-Network
| Algorithm 1:-Evolutionary Algorithm. |
 |
| Algorithm 2: DDQL with centralized learning. |
 |
4.3.2. Multi-Agent DDQL
5. Results and Discussions
5.1. Metrics
- Accumulated Episodic Reward (AER):The sum of every step reward at the end of a trajectory. When the dimension of the map grows, also does the total available reward.When addressing the multi-agent situation, the AER includes all the individual rewards obtained by the ASVs. Note that, as a higher number of agents causes the cells to be under a higher rate of visitation, the maximum possible reward is not proportional to the fleet size. This happens because the agents share the Lake idleness and the redundancy is inherently higher.
- Inverse sample-efficiency rate (ISER): This metric consider the number of states observations required for the method to obtain its best solution. It measures the amount of information needed to optimize the paths to a certain optimality level, so, the higher the ISER, the more inefficient is the method because it requires more evaluations of the environment.In the case of the EA, the number of samples is computed as: . In the case of the DDQL algorithm, it uses the buffer replay and needs extra evaluations of the same states. Considering the algorithm trains the network once every episode with experiences, the n° of samples is computed as:
- Computation time (CT): The time that the computer spends optimizing the given solution. On the one hand, for the EA we used 12 cores in a parallel pool to boost the speed. On the other hand, for the DRL approach, a GPU optimized the computation of the gradients. Note that all the available hardware is used to its maximum capacity to minimize the optimization time for the comparison.
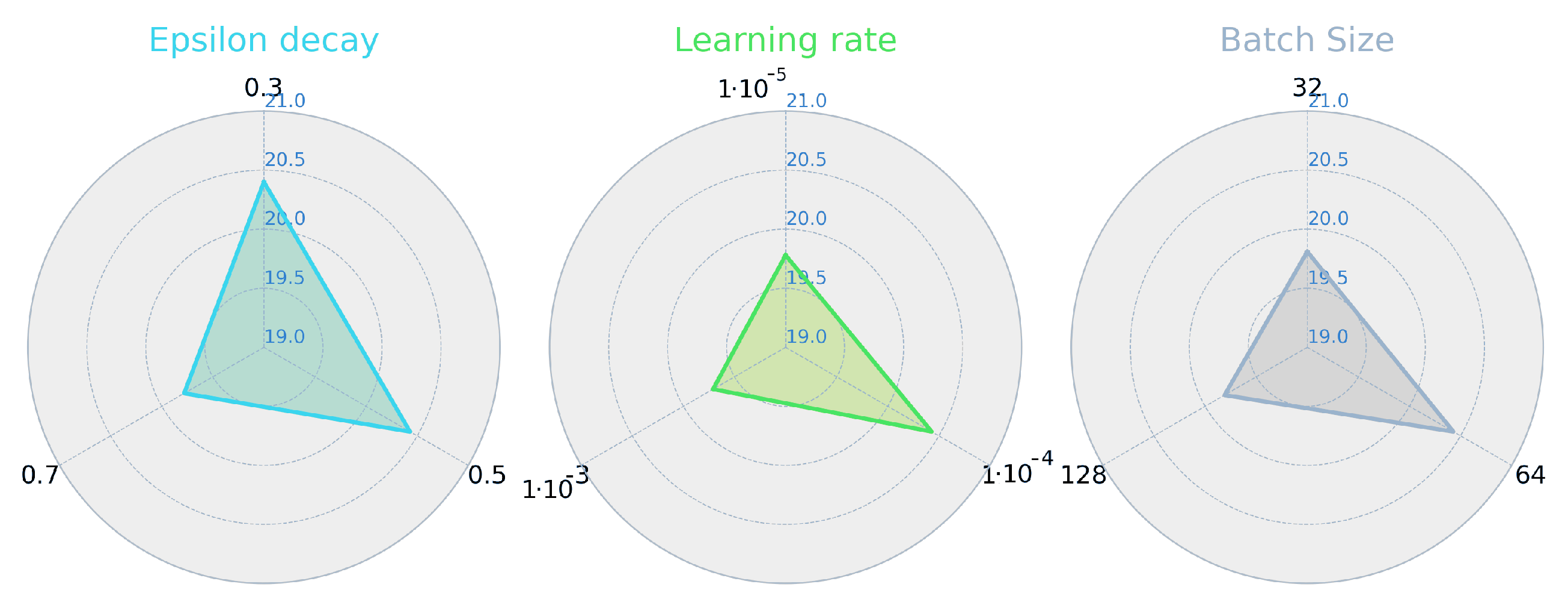
5.2. Parametrization
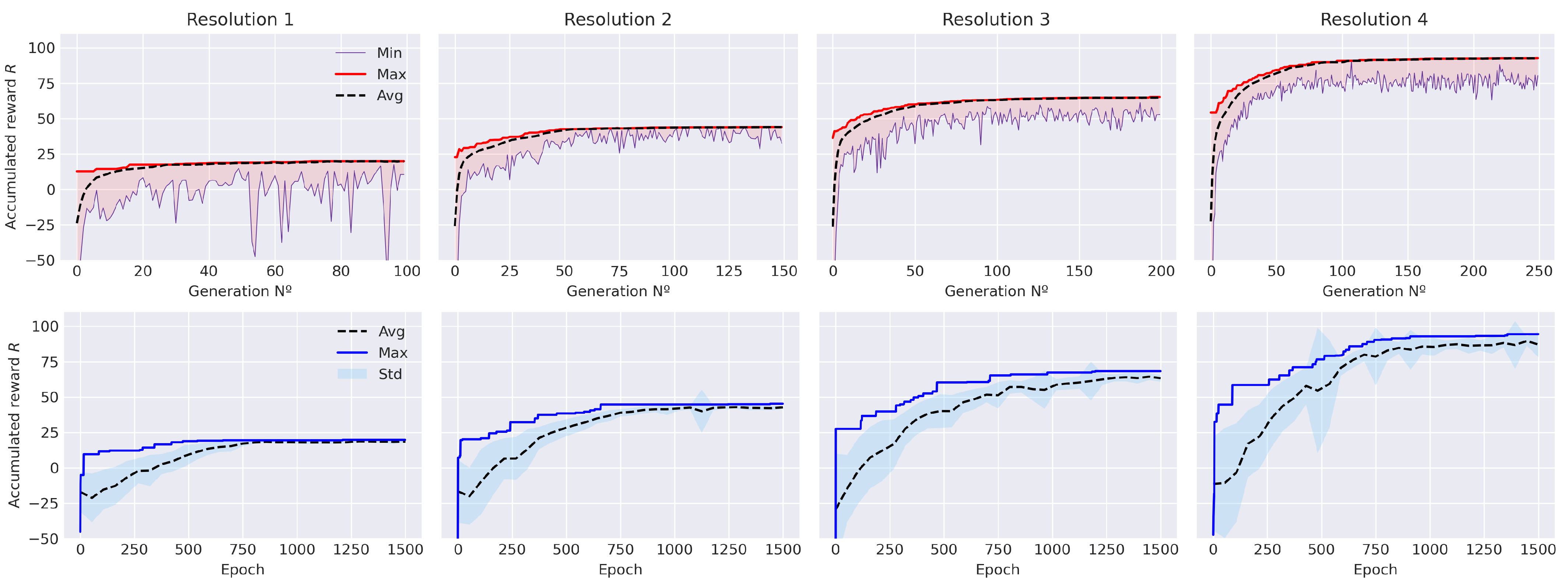
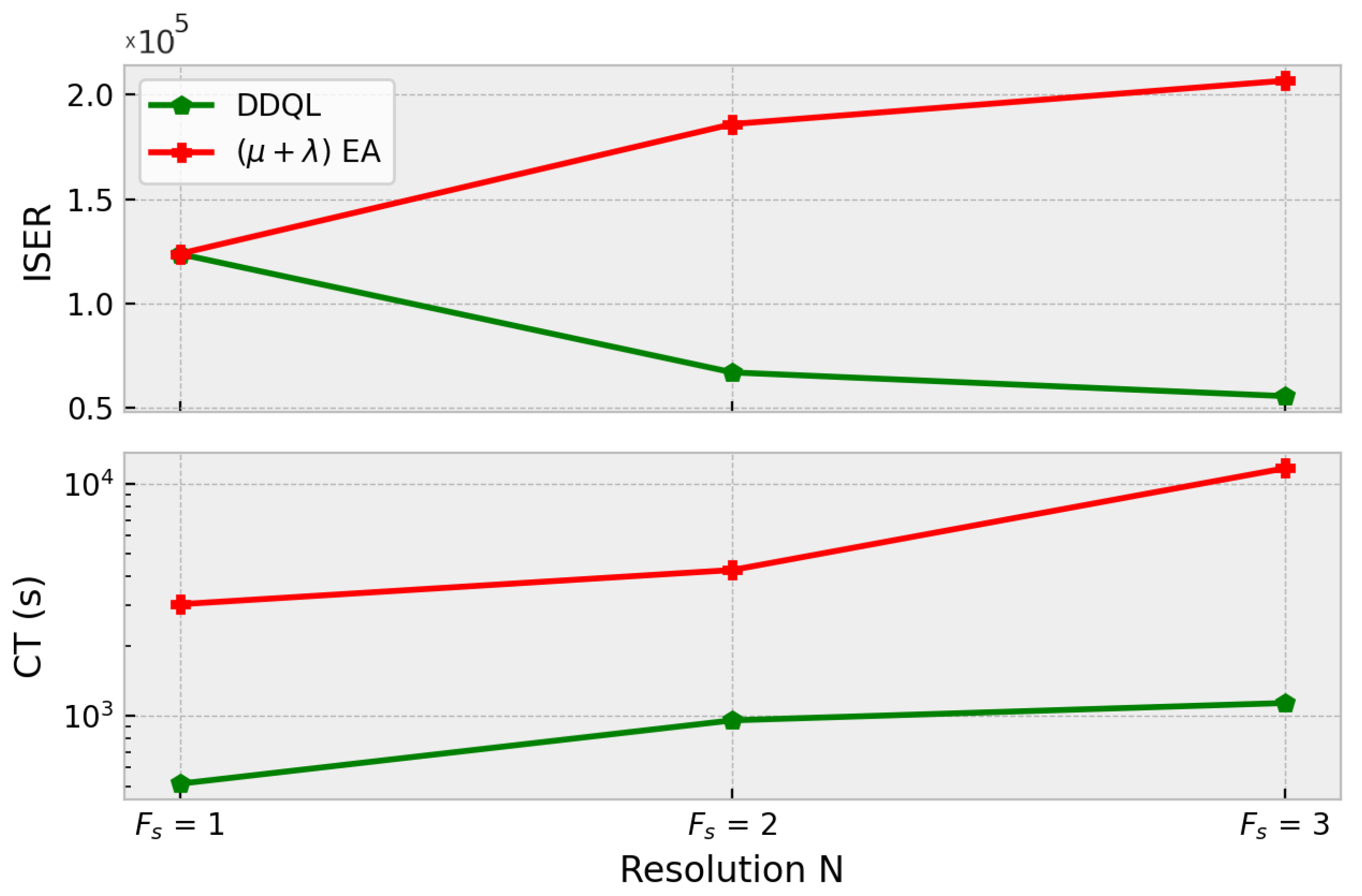
5.3. Resolution Comparison
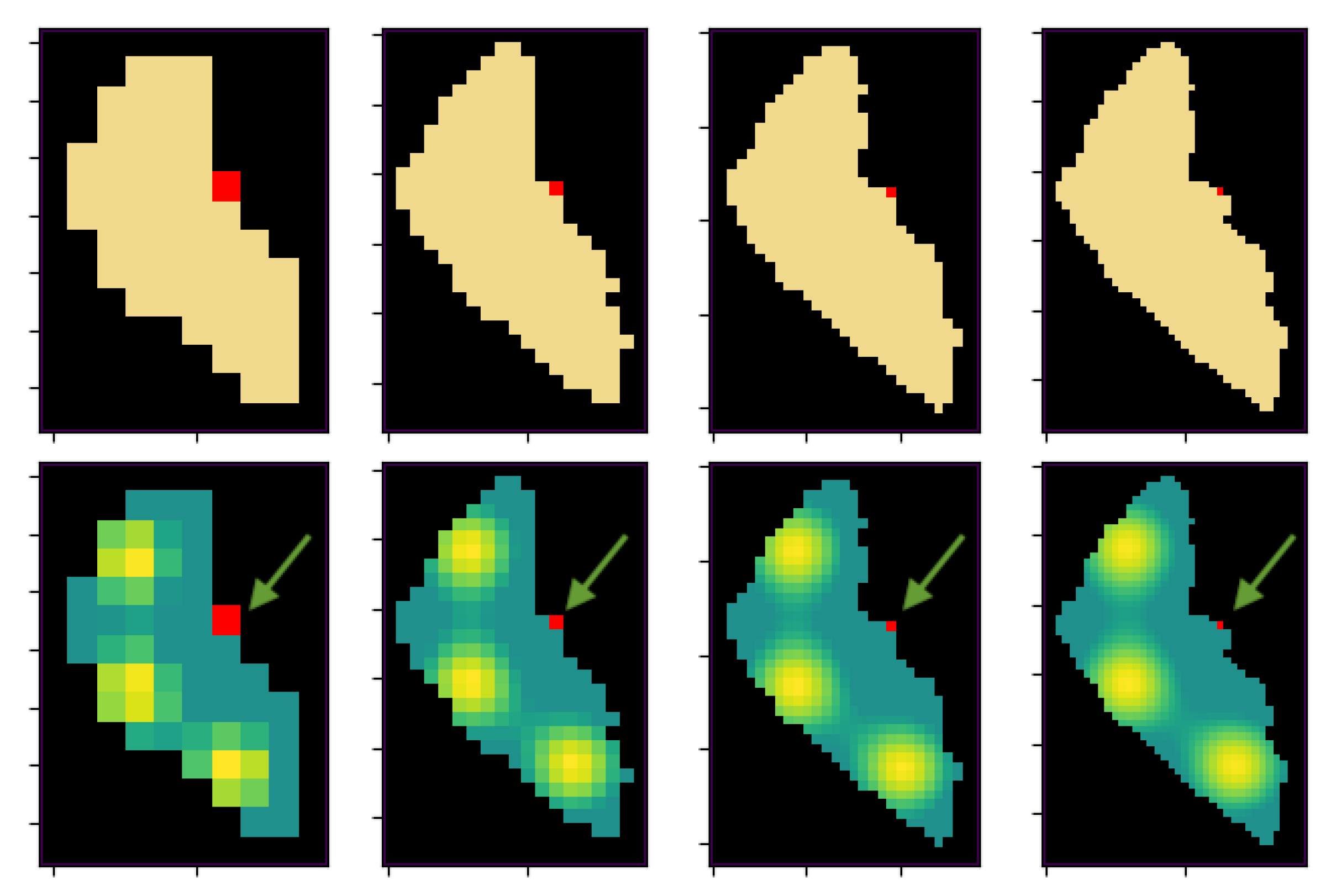
5.4. Scenario Reactivity
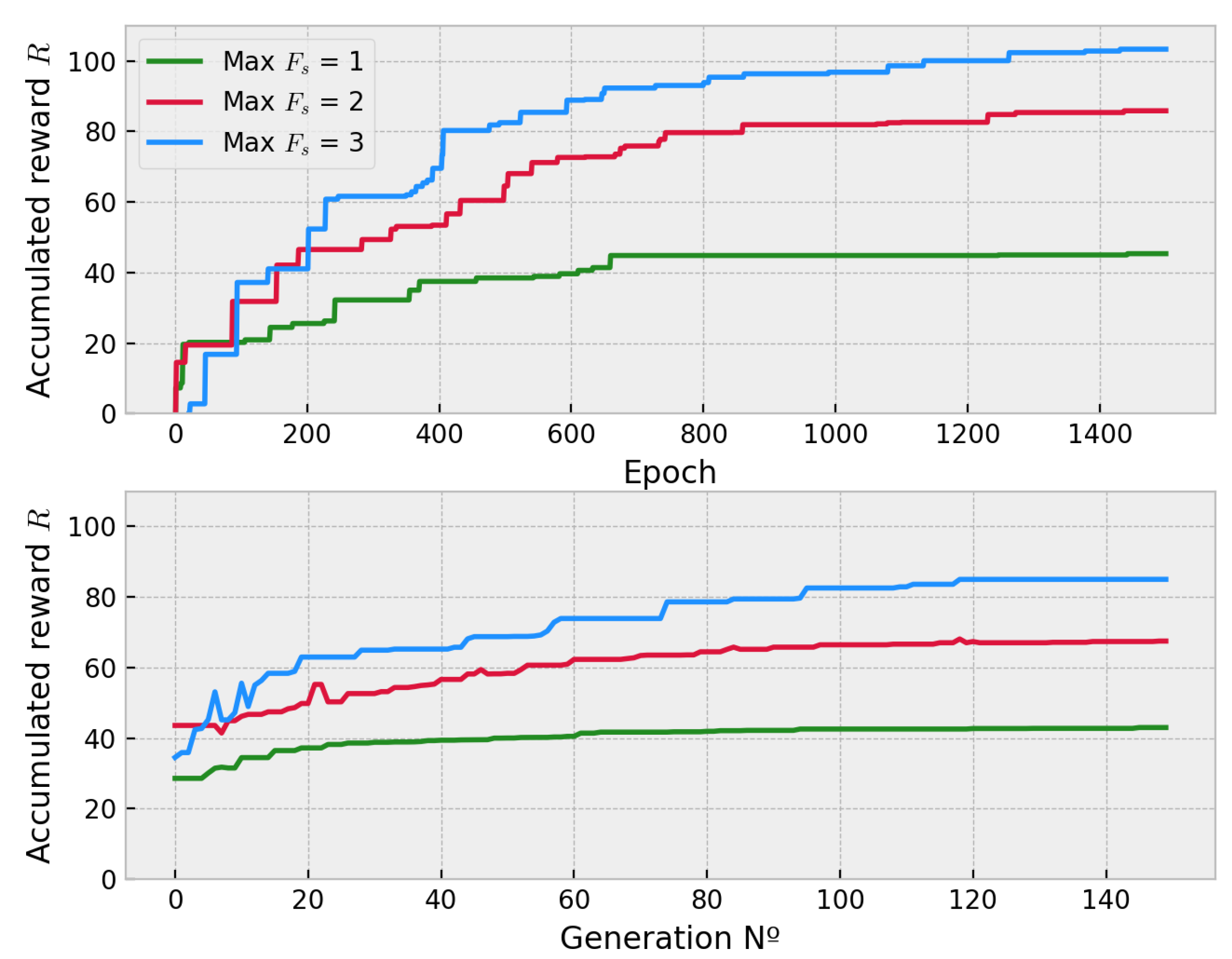
5.5. Multi-Agent Comparison
5.6. Fleet Size Generalization
5.7. Discussion of the Results
- Attending to the resolution of the map, both algorithms return acceptable results. It is noticeable that both algorithms obtain very similar maximum rewards. Nevertheless, the efficiency of the optimization changes depending on the size of the map. The results show that, for higher resolutions, EA algorithms tend to be slower and inefficient as the population size needs to be large and several generations are needed. DDQL is proven to perform great in every tested map, which indicates that is a very suitable methodology in high dimension problems. Hence, Figure 15 could serve to choose the methodology depending on the size of the environment in similar problems.
- As for the multi-agent case, it can be noticed how the number of agents affects more significantly than the map size. The DDQL outperforms the EA in approximately a 25%, which implies the former is a better algorithm to deal with multiple agents. As a matter of fact, the black box methodology of the EA cannot take any advantages from the scenario via the state, whilst the DDQL can effectively infer some amount of knowledge from every action taken.
- Comparing the robustness of the proposed solutions, the EA, in spite of returning worse paths, can provide a set of solutions with a much lower deviation. DDQL, as it uses a stochastic approach, tends to generate very bad paths sometimes in an example of the catastrophic forgetting phenomenon. The dispersion of the results aggravates when the shape of the map or the fleet size grows and more experiences are needed for a better policy convergence. Nonetheless, when the scenario changes, either because the interest map changes or the size of the fleet variates, the reactivity of the DDQL is able to adapt the policy better. This is because the DDQL method, as it learns from the data and not only the final outcome, learns to perform the task.not only the reward function, which implies a similar mission can be completed effectively.
- It is important to note that the convergence of the DDQL is not guaranteed in any case because of the use of non-linear estimators as Neural Networks [19]. Therefore, the DDQL depends on the suitable hyper-parameter selection, network architecture, etc, to optimize correctly the solutions. This is an important aspect to consider because, in spite of the good results, EA does not need a critic design to provide similar results in most cases.
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ASV | Autonomous Surface Vehicle |
| UAV | Unmanned Aerial Vehicle |
| DOF | Degree of Freedom |
| RL | Reinforcement Learning |
| EA | Evolutionary Algorithm |
| GA | Genetic Algorithm |
| DRL | Deep Reinforcement Learning |
| DQL | Deep Q-Learning |
| DDQL | Double Deep Q-Learning |
| NHPP | Non-Homogeneous Patrolling Problem |
| MUTPB | Mutation Probability |
| CXPB | Crossover Probability |
| CNN | Convolutional Neural Network |
| AER | Accumulated Episodic Reward |
| ISER | Inverse Sample-Efficiency Rate |
| CT | Computation Time |
| GPU | Graphic Processing Unit |
| CPU | Computer Processing Unit |
References
- Moreira, M.G.A.L.; Hinegk, L.; Salvadore, A.; Zolezzi, G.; Hölker, F.; Monte Domecq S., R.A.; Bocci, M.; Carrer, S.; Nat, L.D.; Escribá, J.; et al. Eutrophication, research and management history of the shallow Ypacaraí Lake (Paraguay). Sustainability 2018, 10, 2426. [Google Scholar] [CrossRef] [Green Version]
- López Arzamendia, M.E.; Espartza, I.; Reina, D.G.; Toral, S.L.; Gregor, D. Comparison of Eulerian and Hamiltonian circuits for evolutionary-based path planning of an autonomous surface vehicle for monitoring Ypacarai Lake. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 1495–1507. [Google Scholar] [CrossRef]
- Peralta Samaniego, F.; Reina, D.G.; Toral Marín, S.L.; Gregor, D.O.; Arzamendia, M. A Bayesian Optimization Approach for Water Resources Monitoring through an Autonomous Surface Vehicle: The Ypacarai Lake Case Study. IEEE Access 2021, 9, 9163–9179. [Google Scholar] [CrossRef]
- Sánchez-García, J.; García-Campos, J.; Arzamendia, M.; Reina, D.; Toral, S.; Gregor, D. A survey on unmanned aerial and aquatic vehicle multi-hop networks: Wireless communications, evaluation tools and applications. Comput. Commun. 2018, 119, 43–65. [Google Scholar] [CrossRef]
- Peralta, F.; Arzamendia, M.E.; Gregor, D.; Reina, D.G.; Toral, S. A Comparison of Local Path Planning Techniques of Autonomous Surface Vehicles for Monitoring Applications: The Ypacarai Lake Case-study. Sensors 2020, 20, 1488. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yanes, S.; Reina, D.G.; Toral Marín, S.L. A Deep Reinforcement Learning Approach for the Patrolling Problem of Water Resources Through Autonomous Surface Vehicles: The Ypacarai Lake Case. IEEE Access 2020, 8, 204076–204093. [Google Scholar] [CrossRef]
- Chevaleyre, Y. Theoretical analysis of the multi-agent patrolling problem. In Proceedings of the IEEE/WIC/ACM International Conference on Intelligent Agent Technology, Beijing, China, 20–24 September 2004; pp. 302–308. [Google Scholar] [CrossRef]
- Arzamendia, M.; Gregor, D.; Reina, D.; Toral, S. Evolutionary path planning of an autonomous surface vehicle for water quality monitoring. In Proceedings of the 2016 9th International Conference on Developments in eSystems Engineering (DeSE), Brussels, Belgium, 7–9 September 2016; pp. 245–250. [Google Scholar]
- Ferreira, H.; Almeida, C.; Martins, A.; Almeida, J.; Dias, N.; Dias, A.; Silva, E. Autonomous bathymetry for risk assessment with ROAZ robotic surface vehicle. In Proceedings of the Oceans 2009-Europe, Bremen, Germany, 11–14 May 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Eichhorn, M.; Ament, C.; Jacobi, M.; Pfuetzenreuter, T.; Karimanzira, D.; Bley, K.; Boer, M.; Wehde, H. Modular AUV System with Integrated Real-Time Water Quality Analysis. Sensors 2018, 18, 1837. [Google Scholar] [CrossRef] [Green Version]
- Chang, H.C.; Hsu, Y.L.; Hung, S.S.; Ou, G.R.; Wu, J.R.; Hsu, C. Autonomous Water Quality Monitoring and Water Surface Cleaning for Unmanned Surface Vehicle. Sensors 2021, 21, 1102. [Google Scholar] [CrossRef]
- Theile, M.; Bayerlein, H.; Nai, R.; Gesbert, D.; Caccamo, M. UAV Coverage Path Planning under Varying Power Constraints using Deep Reinforcement Learning. arXiv 2020, arXiv:2003.02609. [Google Scholar]
- Piciarelli, C.; Foresti, G.L. Drone patrolling with reinforcement learning. In Proceedings of the 13th International Conference on Distributed Smart Cameras, Trento, Italy, 9–11 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Lamini, C.; Benhlima, S.; Elbekri, A. Genetic Algorithm Based Approach for Autonomous Mobile Robot Path Planning. Procedia Comput. Sci. 2018, 127, 180–189. [Google Scholar] [CrossRef]
- Števo, S.; Sekaj, I.; Dekan, M. Optimization of Robotic Arm Trajectory Using Genetic Algorithm. IFAC Proc. Vol. 2014, 47, 1748–1753. [Google Scholar] [CrossRef] [Green Version]
- Arzamendia, M.; Gregor, D.; Reina, D.G.; Toral, S.L. An evolutionary approach to constrained path planning of an autonomous surface vehicle for maximizing the covered area of Ypacarai Lake. Soft Comput. 2019, 23, 1723–1734. [Google Scholar] [CrossRef]
- Krishna Lakshmanan, A.; Elara Mohan, R.; Ramalingam, B.; Vu Le, A.; Veerajagadeshwar, P.; Tiwari, K.; Ilyas, M. Complete coverage path planning using reinforcement learning for Tetromino based cleaning and maintenance robot. Autom. Constr. 2020, 112, 103078. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-Learning. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. Available online: http://xxx.lanl.gov/abs/1509.06461 (accessed on 15 January 2021).
- Apuroop, K.; Le, A.V.; Elara, M.R.; Sheu, B.J. Reinforcement Learning-Based Complete Area Coverage Path Planning for a Modified hTrihex Robot. Sensors 2021, 21, 1067. [Google Scholar] [CrossRef]
- Shi, W.; Li, J.; Wu, H.; Zhou, C.; Cheng, N.; Shen, X. Drone-cell Trajectory Planning and Resource Allocation for Highly Mobile Networks: A Hierarchical DRL Approach. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Anderlini, E.; Parker, G.G.; Thomas, G. Docking Control of an Autonomous Underwater Vehicle Using Reinforcement Learning. Appl. Sci. 2019, 9, 3456. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Wei, Z.; Liu, K.; Quan, Z.; Li, Y. Battery-Involved Energy Management for Hybrid Electric Bus Based on Expert-Assistance Deep Deterministic Policy Gradient Algorithm. IEEE Trans. Veh. Technol. 2020, 69, 12786–12796. [Google Scholar] [CrossRef]
- Wu, J.; Wei, Z.; Li, W.; Wang, Y.; Li, Y.; Sauer, D.U. Battery Thermal- and Health-Constrained Energy Management for Hybrid Electric Bus Based on Soft Actor-Critic DRL Algorithm. IEEE Trans. Ind. Inform. 2021, 17, 3751–3761. [Google Scholar] [CrossRef]
- Luis, S.Y.; Reina, D.G.; Toral Marín, S.L. A Multiagent Deep Reinforcement Learning Approach for Path Planning in Autonomous Surface Vehicles: The Ypacarai-Lake Patrolling Case. IEEE Access 2021, 9, 17084–17099. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 2017, 6380–6391. [Google Scholar]
- Chu, T.; Qu, S.; Wang, J. Large-scale multi-agent reinforcement learning using image-based state representation. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control, Las Vegas, NV, USA, 12–14 December 2016; pp. 7592–7597. [Google Scholar] [CrossRef]
- Qie, H.; Shi, D.; Shen, T.; Xu, X.; Li, Y.; Wang, L. Joint Optimization of Multi-UAV Target Assignment and Path Planning Based on Multi-Agent Reinforcement Learning. IEEE Access 2019, 7, 146264–146272. [Google Scholar] [CrossRef]
- Tran, Q.; Bae, S. An Efficiency Enhancing Methodology for Multiple Autonomous Vehicles in an Urban Network Adopting Deep Reinforcement Learning. Appl. Sci. 2021, 11, 1514. [Google Scholar] [CrossRef]
- Arzamendia, M.; Gregor, D.; Reina, D.G.; Toral, S.L. A Path Planning Approach of an Autonomous Surface Vehicle for Water Quality Monitoring Using Evolutionary Computation. In Technology for Smart Futures; Dastbaz, M., Arabnia, H., Akhgar, B., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 55–73. [Google Scholar] [CrossRef]
- Yu, X.; Li, C.; Zhou, J. A constrained differential evolution algorithm to solve UAV path planning in disaster scenarios. Knowl. Based Syst. 2020, 204, 106209. [Google Scholar] [CrossRef]
- Wang, L.; Guo, Q. Coordination of Multiple Autonomous Agents Using Naturally Generated Languages in Task Planning. Appl. Sci. 2019, 9, 3571. [Google Scholar] [CrossRef] [Green Version]
- Cabreira, T.M.; de Aguiar, M.S.; Dimuro, G.P. An Extended Evolutionary Learning Approach For Multiple Robot Path Planning In A Multi-Agent Environment. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 3363–3370. [Google Scholar] [CrossRef]
- Shibata, T.; Fukuda, T. Coordination in evolutionary multi-agent-robotic system using fuzzy and genetic algorithm. Control Eng. Pract. 1994, 2, 103–111. [Google Scholar] [CrossRef]
- Li, H.; Yi, F.; Elgazzar, K.; Paull, L. Path planning for multiple Unmanned Aerial Vehicles using genetic algorithms. In Proceedings of the 2009 Canadian Conference on Electrical and Computer Engineering, Vancouver, BC, Canada, 16–17 May 2009; pp. 1129–1132. [Google Scholar] [CrossRef]
- Drugan, M. Reinforcement learning versus evolutionary computation: A survey on hybrid algorithms. Swarm Evol. Comput. 2019, 44, 228–246. [Google Scholar] [CrossRef]
- Sutton, R.S.; Maei, H.; Szepesvári, C. A Convergent O(n) Temporal-difference Algorithm for Off-policy Learning with Linear Function Approximation. In Advances in Neural Information Processing Systems; Koller, D., Schuurmans, D., Bengio, Y., Bottou, L., Eds.; Curran Associates, Inc.: New York, NY, USA, 2009; Volume 21, pp. 1609–1616. [Google Scholar]
- Taylor, M.E.; Whiteson, S.; Stone, P. Comparing Evolutionary and Temporal Difference Methods in a Reinforcement Learning Domain. In Proceedings of the 8th Annual Conference on Genetic and Evolutionary Computation, Washington, DC, USA, 8–12 July 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 1321–1328. [Google Scholar] [CrossRef] [Green Version]
- Krawiec, K.; Jaśkowski, W.; Szubert, M. Evolving Small-Board Go Players using Coevolutionary Temporal Difference Learning with Archive. Int. J. Appl. Math. Comput. Sci. 2011, 21, 717–731. [Google Scholar] [CrossRef]
- Ter-Sarkisov, A.; Marsland, S.R.; Convergence Properties of Two (μ+λ) Evolutionary Algorithms On OneMax and Royal Roads Test Functions. CoRR 2011. Available online: http://xxx.lanl.gov/abs/1108.4080 (accessed on 22 January 2021).
- Wu, Y.H.; Sun, F.Y.; Chang, Y.Y.; Lin, S.D. ANS: Adaptive network scaling for deep rectifier reinforcement learning models. arXiv 2018, arXiv:1809.02112. [Google Scholar]
- Luke, S. Essentials of Metaheuristics, 2nd ed.; Lulu: Morrisville, NC, USA, 2013; Available online: http://cs.gmu.edu/sean/book/metaheuristics/ (accessed on 10 December 2020).
- Hassanat, A.; Almohammadi, K.; Alkafaween, E.; Abunawas, E.; Hammouri, A.; Prasath, V.B.S. Choosing mutation and crossover ratios for genetic algorithms-a review with a new dynamic approach. Information 2019, 10, 390. [Google Scholar] [CrossRef] [Green Version]
- Birattari, M. Tuning Metaheuristics: A Machine Learning Perspective, 2nd ed.; Springer Publishing Company: Berlin/Heidelberg, Germany, 2009; pp. 20–25. [Google Scholar]
- Liessner, R.; Schmitt, J.; Dietermann, A.; Bäker, B. Hyperparameter Optimization for Deep Reinforcement Learning in Vehicle Energy Management. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence, Prague, Czech Republic, 19–21 February 2019; Volume 2, pp. 134–144. [Google Scholar] [CrossRef]
- Li, H.; Chaudhari, P.; Yang, H.; Lam, M.; Ravichandran, A.; Bhotika, R.; Soatto, S. Rethinking the Hyperparameters for Fine-Tuning. 2020. Available online: http://xxx.lanl.gov/abs/2002.11770 (accessed on 10 April 2021).
- Buşoniu, L.; Babuška, R.; De Schutter, B. A comprehensive survey of multiagent reinforcement learning. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2008, 38, 156–172. [Google Scholar] [CrossRef] [Green Version]
- Young, M.T.; Hinkle, J.D.; Kannan, R.; Ramanathan, A. Distributed Bayesian optimization of deep reinforcement learning algorithms. J. Parallel Distrib. Comput. 2020, 139, 43–52. [Google Scholar] [CrossRef]
- Bottin, M.; Rosati, G.; Boschetti, G. Working Cycle Sequence Optimization for Industrial Robots. In Advances in Italian Mechanism Sciences; Vincenzo, N., Gasparetto, A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 228–236. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Objective | Methodology | Vehicle |
|---|---|---|---|
| [12] | Informative Path Planning. | Deep Q-Learning with CNNs. | single-agent UAV |
| [20] | Complete Surface Coverage in cleaning tasks. | DRL Actors Critic with Experience Replay | multi-body single ASV |
| [21] | Coverage Maximization with FANETs. | Deep Q-Learning. | single-agent UAV |
| [22] | Docking Control and Planning. | Deep Q-Learning and DDPG | single-agent ASV |
| [6] | Patrolling Problem. | Deep Q-Learning with CNNs | single-agent ASV |
| [25] | Multi-agent Patrolling Problem. | Deep Q-Learning with CNNs | multi-agent fleet of ASVs |
| [27] | Multi-agent Path Planning with obstacles avoidance. | Deep Q-Learning with CNNs | multi-agent fleet of UAVs |
| [28] | Multi-agent Path Planning with obstacles avoidance. | Deep Q-Learning with CNNs | multi-agent fleet of UAVs |
| [29] | Multi-agent Urban Path Planning. | Proximal Policy Optimization. | multi-agent fleet of unmanned cars |
| Ref. | Objective | Methodology | Vehicle |
|---|---|---|---|
| [2] | Coverage TSP global Path Planning. | Evolutionary Algorithm. | single-agent ASV |
| [7] | Homogeneous Patrolling Problem with grid-maps. | Evolutionary Algorithm. | single-agent and multi-agent robots. |
| [31] | 3D optimization of an UAV paths. | Evolutionary Algorithm. | 6-DOF single-agent UAV. |
| [15] | Multi-joint path-planning in manipulator robots. | Evolutionary Algorithm | single-agent robot. |
| [32] | Multi-agent cooperation in path planning. | Natural-Language Evolutionary Strategy. | multi-agent fleet of robots. |
| [33] | Multi-agent in path planning with dynamic scenario. | Evolutionary Algorithm. | multi-agent fleet of robots. |
| [34] | Multi-agent cooperation-competition in path planning. | Evolutionary Algorithm. | multi-agent fleet of robots. |
| [35] | Multi-agent goal-tracking in path planning. | Novel Genetic Algorithm. | multi-agent fleet of UAVs. |
| Hyper-Parameters | |
|---|---|
| DDQL | ()-EA |
| - - Batch Size * - -decay rate * - - Learning Rate () * - Target update rate () - Epochs - Buffer Replay Size (M) - Network Arquitecture | - MUTPB * - CXPB * - Tournament Size - - Population Size - Generations |
| CXPB | 0.9 | 0.8 | 0.7 | |
|---|---|---|---|---|
| MUTPB | ||||
| 0.05 | 18.02 | 18.41 | 18.66 | |
| 0.1 | 18.48 | 19.69 | 18.85 | |
| 0.2 | - | 19.98 | 19.96 | |
| 0.3 | - | - | 20.4 | |
| EA | DDQL | ||
|---|---|---|---|
| (300, 600, 900, 1200) | 0.95 | ||
| MUTPB | 0.3 | -decay | (0.5) |
| CXPB | 0.7 | Batch Size | 64 |
| Generations | (100, 150, 200, 250) | Episodes | 1500 |
| Population Size | (300, 600, 900, 1200) | Learning rate | |
| -EA | DDQL | |||||
|---|---|---|---|---|---|---|
| N = ×1 | 20.4 | 19.8 | 0.78 | 20.3 | 17.7 | 0.99 |
| N = ×2 | 43.2 | 42.7 | 0.56 | 46.6 | 43.9 | 1.81 |
| N = ×3 | 65.9 | 65.3 | 0.41 | 68.3 | 64.5 | 2.35 |
| N = ×4 | 93.6 | 92.2 | 0.63 | 94.7 | 89.7 | 3.78 |
| EA | DDQL | ||
|---|---|---|---|
| (600, 1200, 1800) | 0.99 | ||
| MUTPB | 0.3 | -decay | (0.5) |
| CXPB | 0.7 | Batch Size | 64 |
| Generations | 150 | Episodes | 1500 |
| Population Size | (600, 1200, 1800) | Learning rate | |
| -EA | DDQL | |||||
|---|---|---|---|---|---|---|
| = 1 | 43.6 | 42.7 | 0.56 | 46.6 | 43.9 | 1.81 |
| = 2 | 67.5 | 62.1 | 9.3 | 85.85 | 73.3 | 27.09 |
| = 3 | 85.01 | 75.1 | 27.7 | 103.32 | 75.2 | 32.26 |
| -EA | DDQL | |
|---|---|---|
| 36.4 | 41.9 | |
| 43.6 | 46.6 | |
| Recovery | 83.5% | 90% |
| DDQL | -EA | |
|---|---|---|
| Performance |
|
|
| Robustness |
|
|
| Sample-efficiency |
|
|
| Computation time |
|
|
| Reactivity |
|
|
| Parametrization |
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yanes Luis, S.; Gutiérrez-Reina, D.; Toral Marín, S. A Dimensional Comparison between Evolutionary Algorithm and Deep Reinforcement Learning Methodologies for Autonomous Surface Vehicles with Water Quality Sensors. Sensors 2021, 21, 2862. https://doi.org/10.3390/s21082862
Yanes Luis S, Gutiérrez-Reina D, Toral Marín S. A Dimensional Comparison between Evolutionary Algorithm and Deep Reinforcement Learning Methodologies for Autonomous Surface Vehicles with Water Quality Sensors. Sensors. 2021; 21(8):2862. https://doi.org/10.3390/s21082862
Chicago/Turabian StyleYanes Luis, Samuel, Daniel Gutiérrez-Reina, and Sergio Toral Marín. 2021. "A Dimensional Comparison between Evolutionary Algorithm and Deep Reinforcement Learning Methodologies for Autonomous Surface Vehicles with Water Quality Sensors" Sensors 21, no. 8: 2862. https://doi.org/10.3390/s21082862
APA StyleYanes Luis, S., Gutiérrez-Reina, D., & Toral Marín, S. (2021). A Dimensional Comparison between Evolutionary Algorithm and Deep Reinforcement Learning Methodologies for Autonomous Surface Vehicles with Water Quality Sensors. Sensors, 21(8), 2862. https://doi.org/10.3390/s21082862