A New Multi-Bit Flip-Flop Merging Mechanism for Power Consumption Reduction in the Physical Implementation Stage of ICs Conception

 , ,
, ,
Abstract
:1. Introduction
- An enhanced multi-bit flip-flop (MBFF) merging mechanism that allows for optimal MBFF merging at the IC physical implementation phase is proposed.
- This enhanced model adds value by creating acceptable routing congestion for a clean final routing.
- The model was tested on a real, high-speed design made with the most advanced technology node (7 nm).
- The benefit of MBFF merging on power reduction in the clock tree network was proven.
- A significant power reduction during the IC physical conception process, while maintaining good timing and routing convergence, was achieved.
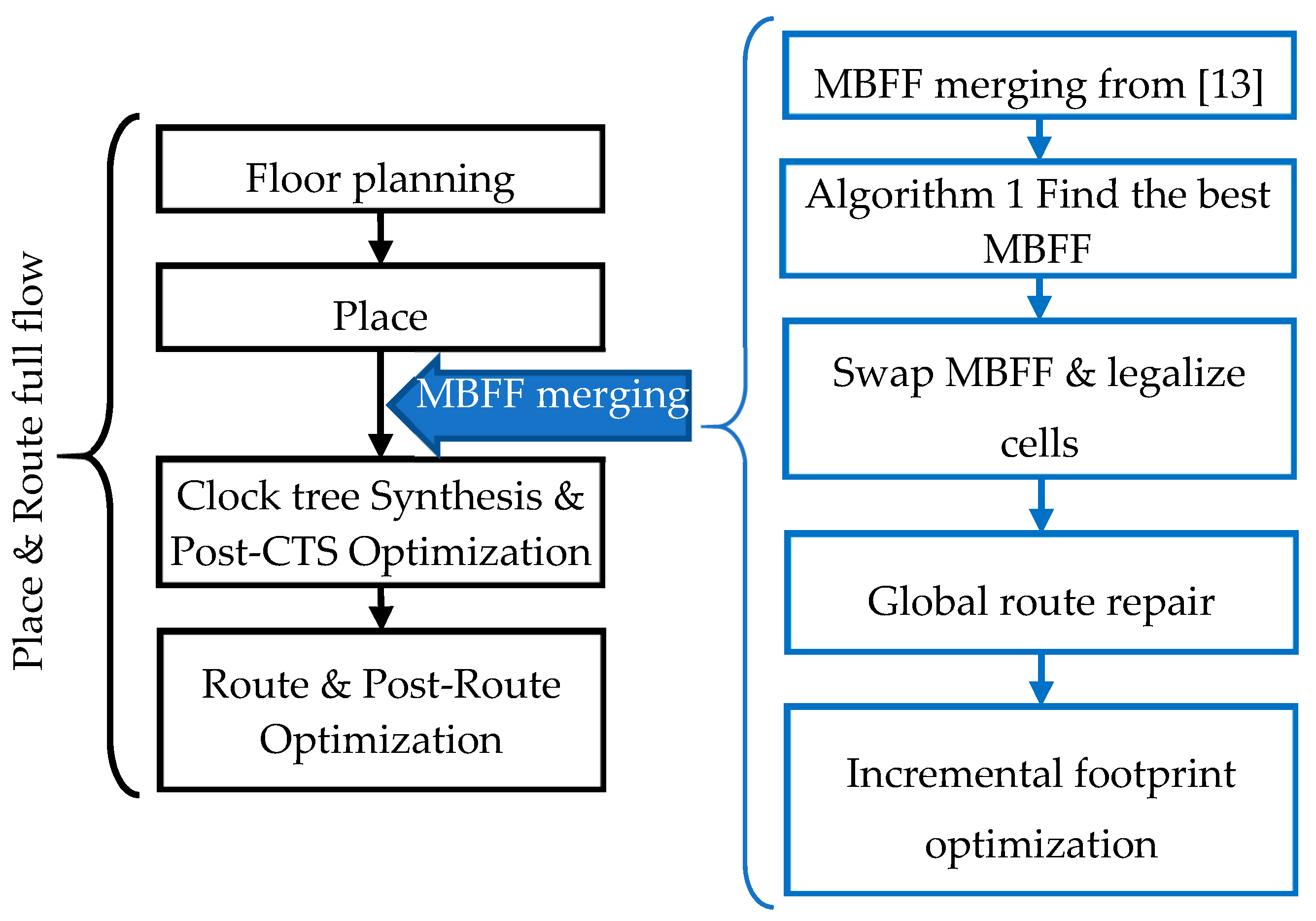
2. MBFF Merging Technique Integration in the Low-Power Place and Route Stage
- Start with the MBFF merging solution from [13];
- Identify the best multi-bit flip-flop among all the available, equivalent MBFFs. The best MBFF is a flip-flop that has a smaller area and consumes less power without causing timing degradation. In order to do so, the following Algorithm 1 is used:
Algorithm 1. Find the best MBFF foreach cell in MBFF cell do get cell initial lib_cell “init_lib_cell” set best_lib_cell init_lib_cell get initial cell power “init_power” get initial max timing slack “init_max_slack.” get initial min timing slack “init_min_slack.” get initial max transition slack “init_transition_slack.” if init_max_slacks > 0 then foreach new_lib_cell in equivalent lib_cells Swap cell to new_lib_cell get new cell power “new_power” get new max timing slack “new_max_slack.” get new min timing slack “new_min_slack.” get new max transition slack “new_transition_slack.” if new_power < init_power AND new_max_slack ≥ 0 AND new_min_slack ≥ init_min_slack AND new_transition_slack ≥ init_transition_slack Then set best_lib_cell new_lib_cell set init_power new_power set init_max_slack new_max_slack set init_min_slack new_min_slack set init_transition_slack new_transition_slack END if END foreach Swap cell to best_lib_cell END if END foreach - Run global route with timing high effort for timing recovery on all nets;
- An incremental light timing optimization may be needed after having the accurate and updated net extraction;
- Report QoR (Timing, Power and Congestion).
3. Results and Analysis
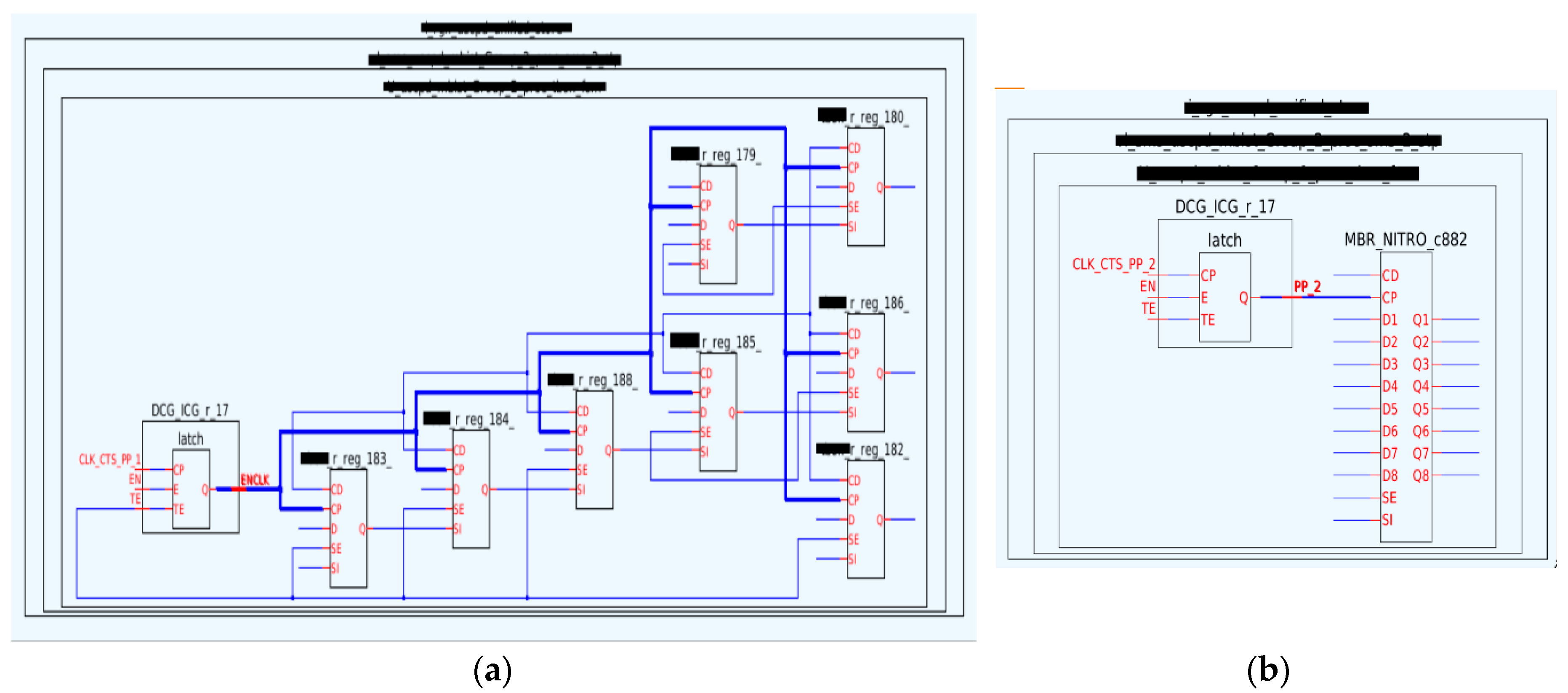
3.1. New Solution’s Results Compared with the Prior Solution
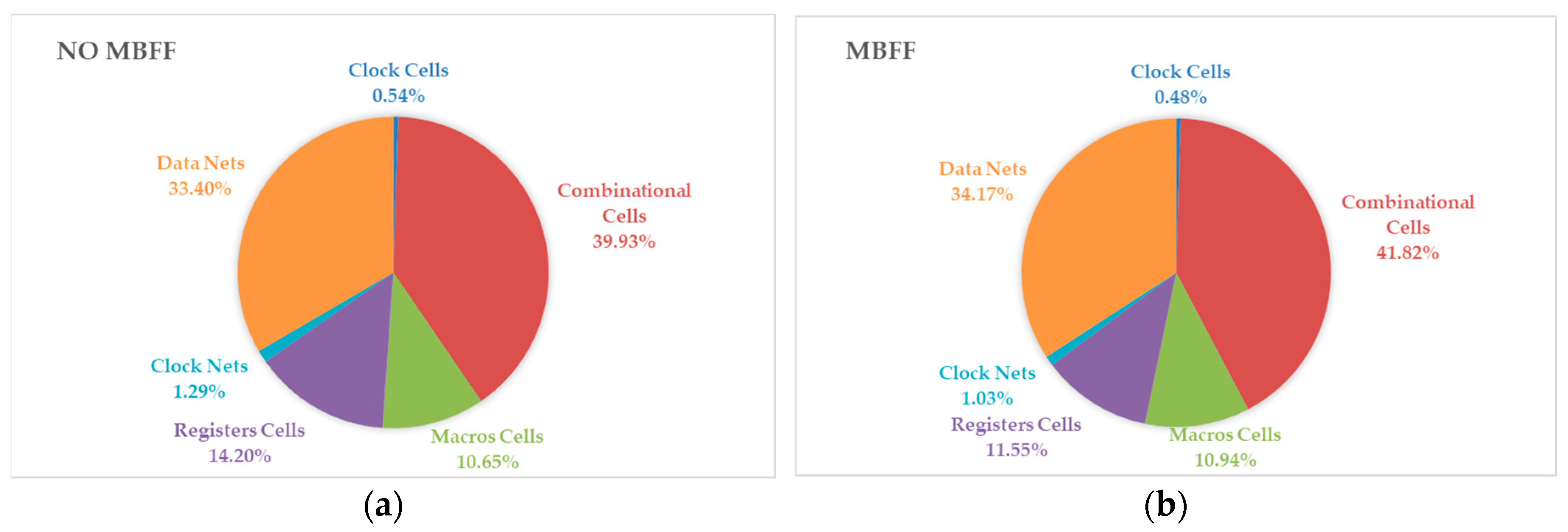
3.2. Impact on Performance, Power Consumption and Area in the Full Physical Implementation Process
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Radack, D.J.; Zolper, J.C. A Future of Integrated Electronics: Moving Off the Roadmap. Proc. IEEE 2008, 96, 198–200. [Google Scholar] [CrossRef]
- Lee, I.; Lee, K. The Internet of Things (IoT): Applications, investments and challenges for enterprises. Bus. Horiz. 2015, 58, 431–440. [Google Scholar] [CrossRef]
- Flynn, D.; Aitken, R.; Gibbons, A.; Shi, K. Low Power Methodology Manual: For System-On-Chip Design, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2007; p. 13. [Google Scholar]
- Rahman, M.; Afonso, R.; Tennakoon, H.; Sechen, C. Design automation tools and libraries for low power digital design. In Proceedings of the 2010 IEEE Dallas Circuits and Systems Workshop, Richardson, TX, USA, 17–18 October 2010. [Google Scholar]
- Lin, G.J.Y.; Hsu, C.B.; Kuo, J.B. Critical-path aware power consumption optimization methodology (CAPCOM) using mixed-VTH cells for low-power SOC designs. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, VIC, Australia, 1–5 June 2014; pp. 1740–1743. [Google Scholar]
- Gautam, S. Analysis of multi-bit flip flop low power methodology to reduce area and power in physical synthesis and clock tree synthesis in 90nm CMOS technology. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Greater Noida, New Delhi, 24–27 September 2014; pp. 570–574. [Google Scholar]
- Lin, M.P.H.; Hsu, C.C.; Chen, Y.C. Clock-Tree Aware Multibit Flip-Flop Generation During Placement for Power Optimization. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2015, 34, 280–292. [Google Scholar] [CrossRef]
- Prakash, G.; Sathishkumar, K.; Sakthibharathi, B.; Saravanan, S.; Vijaysai, R. Achieving reduced area by Multi-bit Flip flop design. In Proceedings of the 2013 International Conference on Computer Communication and Informatics, Coimbatore, India, 4–6 January 2013; pp. 1–4. [Google Scholar]
- Lin, M.P.; Hsu, C.; Chang, Y. Post-Placement Power Optimization With Multi-Bit Flip-Flops. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2011, 30, 1870–1882. [Google Scholar] [CrossRef]
- Hou, W.; Liu, D.; Ho, P.-H. Automatic register banking for low-power clock trees. In Proceedings of the 2009 10th International Symposium on Quality Electronic Design, San Jose, CA, USA, 16–18 March 2009; pp. 647–652. [Google Scholar]
- Feng, C.; Yue, D.; Zhao, Z.; Liao, Z. A parameterized timing-aware flip-flop merging algorithm for clock power reduction. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018. [Google Scholar]
- Seitanidis, I.; Dimitrakopoulos, G.; Matheakis, P.; Masse-Navete, L.; Chinnery, D. Timing Driven Incremental Multi-Bit Register Composition Using a Placement-Aware ILP formulation. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017. [Google Scholar]
- Cherif, L.; Chentouf, M.; Benallal, J.; Darmi, M.; Elgouri, R.; Hmina, N. Usage and impact of multi-bit flip-flops low power methodology on physical implementation. In Proceedings of the 2018 4th International Conference on Optimization and Applications (ICOA), Mohammedia, Morocco, 26–27 April 2018; pp. 1–5. [Google Scholar]
- Nitro-SoC™ and Olympus-SoC™ User’s Manual; Software Version 2017; Mentor Graphics Corporation: Wilsonville, OR, USA, August 2017.
- Nitro-SoC™ and Olympus-SoC™ Advanced Design Flows Guide; Software Version 2017; Mentor Graphics Corporation: Wilsonville, OR, USA, August 2017.
- Nitro-SoC™ and Olympus-SoC™; Software Version 2017.1.R2; Mentor Graphics Corporation: Wilsonville, OR, USA, August 2017.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design Characteristic | Value |
|---|---|
| Instances count | 313,982 |
| Macros count | 12 |
| Flip-flops count | 41,095 |
| Nets count | 335,736 |
| Silicon Area | 115,737 µm2 |
| Frequency | 2 GHz |
| Technology | 7 nm |
| Place Stage Gain = %((Solution-NoMBFF)/NoMBFF) | WNS (ps) | TNS (ps) | #Violated End-Points | STD Cells Utilization (%) | STD Cells Area (µm2) | Overflow (%) | Total Wirelength (mm) |
|---|---|---|---|---|---|---|---|
| No MBFF | −38.7 | −803.2 | 72 | 52.02 | 42678 | 0.00000 | 3819.54 |
| Solution in Reference [13] | −31.2 | −523.2 | 44 | 51.89 | 42565.6 | 0.0035 | 3852.64 |
| Gain | −19% | −35% | −39% | −0.25% | 0.26% | −1% | |
| New solution | −31.2 | −523.2 | 44 | 51.53 | 42276.1 | 0.00007 | 3814.85 |
| Gain | −19% | −35% | −39% | −1% | −1% | −0.12% |
| Clock Tree Synthesis Gain = %((MBFF-NoMBFF)/NoMBFF) | Number of Clock Nets | Clock Wirelength (mm) | Number of Clock Tree Elements |
|---|---|---|---|
| No MBFF | 2357 | 75.63 | 983 |
| MBFF | 2267 | 66.57 | 893 |
| Gain | 3.82% | −11.98% | −9.16% |
| Place and Route Steps Gain = %((MBFF-NoMBFF)/NoMBFF) | Registers (mW) | Clock Nets (mW) | Clock Cells (mW) | Total Dynamic Power (mW) | Total Power (mW) | |
|---|---|---|---|---|---|---|
| Place | No MBFF | 48.74 | 0.05 | 0.08 | 314.56 | 351.65 |
| MBFF | 40.77 | 0.05 | 0.08 | 309.4 | 345.57 | |
| Gain | −16.35% | 0.00% | 0.00% | −1.64% | −1.73% | |
| Clock tree synthesis (CTS) | No MBFF | 49.24 | 4.86 | 1.98 | 321.47 | 358.78 |
| MBFF | 40.91 | 3.87 | 1.74 | 313.71 | 350.08 | |
| Gain | −16.92% | −20.37% | −12.12% | −2.41% | −2.42% | |
| Post-CTS | No MBFF | 53.25 | 4.87 | 2.06 | 334.63 | 373.96 |
| MBFF | 42.24 | 3.87 | 1.81 | 325.12 | 364.3 | |
| Gain | −20.68% | −20.53% | −12.14% | −2.84% | −2.58% | |
| Route | No MBFF | 53.3 | 4.82 | 2.04 | 327.35 | 367.55 |
| MBFF | 42.18 | 3.81 | 1.79 | 317.57 | 357.72 | |
| Gain | −20.86% | −20.95% | −12.25% | −2.99% | −2.67% | |
| Post-Route | No MBFF | 53.3 | 4.84 | 2.02 | 335.18 | 375.34 |
| MBFF | 42.19 | 3.77 | 1.77 | 325.2 | 365.33 | |
| Gain | −20.84% | −22.11% | −12.38% | −2.98% | −2.67% | |
| Place and Route Steps Gain = %((MBFF-NoMBFF)/NoMBFF) | Utilization (%) | #Buffers + Inverters | #STD Cells | STD Cell Area (µm2) | |
|---|---|---|---|---|---|
| Place | No MBFF | 52.02 | 58,667 | 314,032 | 42,678 |
| MBFF | 51.53 | 58,650 | 306,487 | 42,276.1 | |
| Gain | −0.94% | −0.03% | −2.40% | −0.94% | |
| CTS | No MBFF | 52.14 | 59,650 | 315,015 | 42,777.6 |
| MBFF | 51.64 | 59,543 | 307,380 | 42,363.4 | |
| Gain | −0.96% | −0.18% | −2.42% | −0.97% | |
| Post-CTS | No MBFF | 53.79 | 65,910 | 321,275 | 44,123.4 |
| MBFF | 53.37 | 65,460 | 313,300 | 43,779 | |
| Gain | −0.78% | −0.68% | −2.48% | −0.78% | |
| Route | No MBFF | 55.06 | 67,712 | 323,077 | 45,168.6 |
| MBFF | 54.55 | 66,923 | 314,763 | 44,749 | |
| Gain | −0.93% | −1.17% | −2.57% | −0.93% | |
| Post-Route | No MBFF | 55.11 | 68,369 | 700,239 | 45,207.3 |
| MBFF | 54.58 | 67,367 | 687,673 | 44,774.2 | |
| Gain | −0.96% | −1.47% | −1.79% | −0.96% | |
| Post-Route | WNS (ps) | TNS (ps) | WHS (ps) | THS (ps) |
|---|---|---|---|---|
| No MBFF | −7.8 | −8.4 | −48.1 | −142.8 |
| MBFF | −3.4 | −7.6 | −55.9 | −190.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cherif, L.; Chentouf, M.; Benallal, J.; Darmi, M.; Elgouri, R.; Hmina, N. A New Multi-Bit Flip-Flop Merging Mechanism for Power Consumption Reduction in the Physical Implementation Stage of ICs Conception. J. Low Power Electron. Appl. 2019, 9, 3. https://doi.org/10.3390/jlpea9010003
Cherif L, Chentouf M, Benallal J, Darmi M, Elgouri R, Hmina N. A New Multi-Bit Flip-Flop Merging Mechanism for Power Consumption Reduction in the Physical Implementation Stage of ICs Conception. Journal of Low Power Electronics and Applications. 2019; 9(1):3. https://doi.org/10.3390/jlpea9010003
Chicago/Turabian StyleCherif, Lekbir, Mohamed Chentouf, Jalal Benallal, Mohammed Darmi, Rachid Elgouri, and Nabil Hmina. 2019. "A New Multi-Bit Flip-Flop Merging Mechanism for Power Consumption Reduction in the Physical Implementation Stage of ICs Conception" Journal of Low Power Electronics and Applications 9, no. 1: 3. https://doi.org/10.3390/jlpea9010003
APA StyleCherif, L., Chentouf, M., Benallal, J., Darmi, M., Elgouri, R., & Hmina, N. (2019). A New Multi-Bit Flip-Flop Merging Mechanism for Power Consumption Reduction in the Physical Implementation Stage of ICs Conception. Journal of Low Power Electronics and Applications, 9(1), 3. https://doi.org/10.3390/jlpea9010003