Suggestions for Standardized Identifiers for Fatty Acyl Compounds in Genome Scale Metabolic Models and Their Application to the WormJam Caenorhabditis elegans Model


Abstract
:1. Introduction
2. Materials and Methods
2.1. Caenorhabditis elegans Models
2.2. BiGG Metabolites
2.3. WormJam Reaction and Metabolite Curation
3. Results and Discussion
3.1. Evaluation of BiGG IDs and Naming for Acyl-Based Metabolites
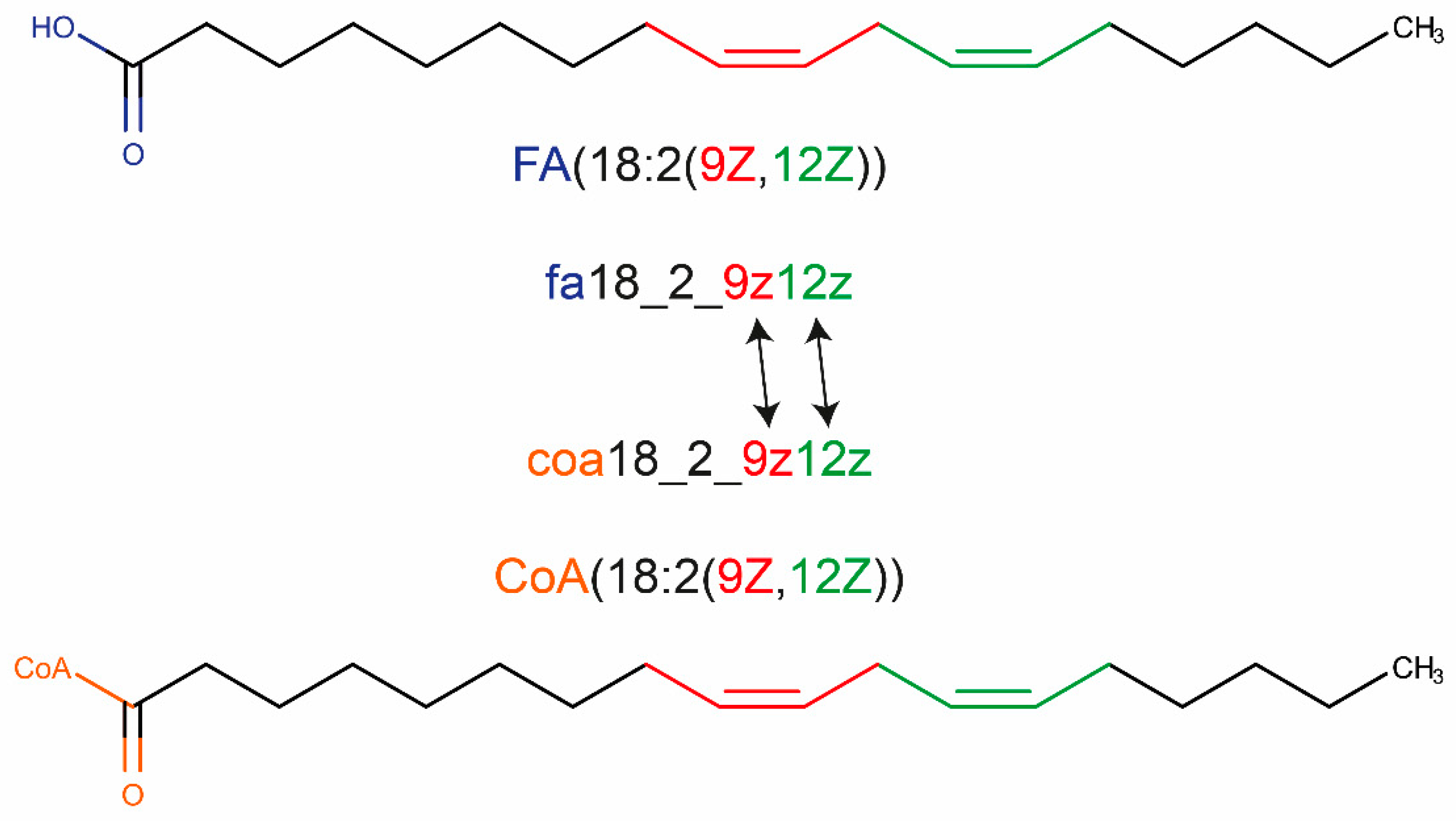
3.2. Use of A Systematic Shorthand Notation to Generate IDs
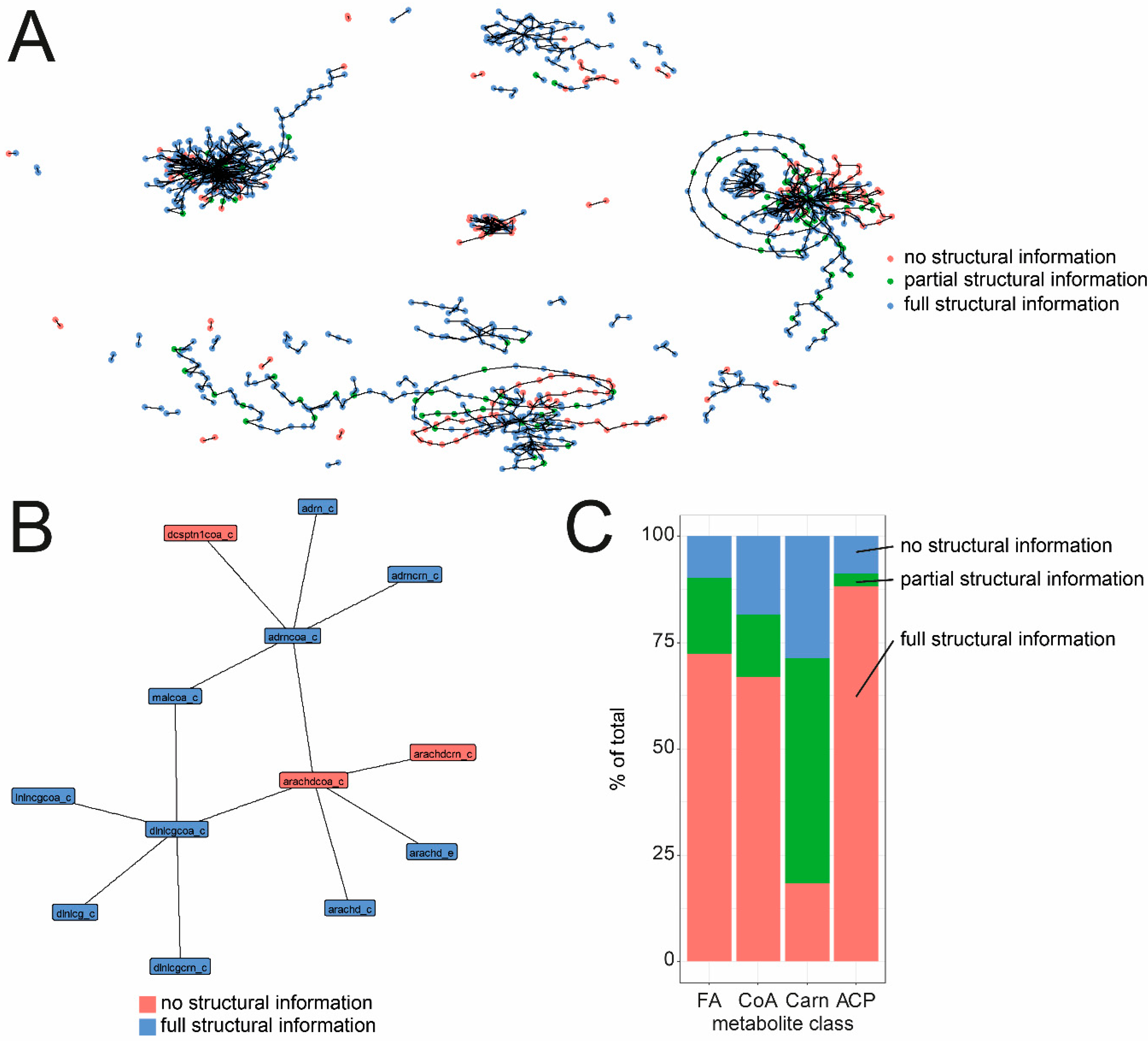
3.3. Comparison of Fatty Acid, Acyl-ACP and Acyl-CoA ID Naming in C. elegans GSMs
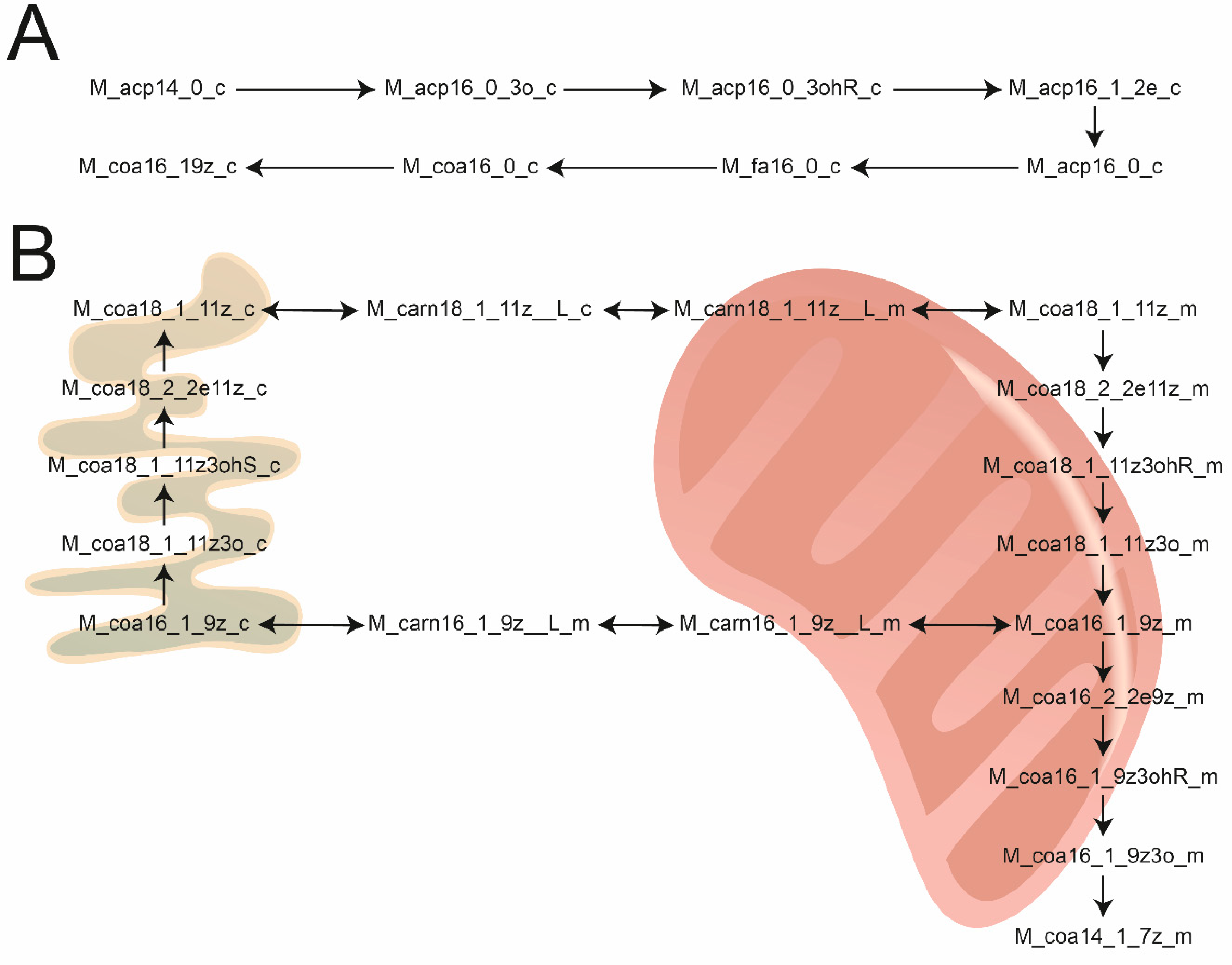
3.4. Updating the WormJam Fatty Acid Related Reactions
4. Conclusions
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
References
- Gu, C.; Kim, G.B.; Kim, W.J.; Kim, H.U.; Lee, S.Y. Current status and applications of genome-scale metabolic models. Genome Boil. 2019, 20, 121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mendoza, S.N.; Olivier, B.G.; Molenaar, D.; Teusink, B. A systematic assessment of current genome-scale metabolic reconstruction tools. Genome Boil. 2019, 20, 158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thiele, I.; Palsson, B.O. A protocol for generating a high-quality genome-scale metabolic reconstruction. Nat. Protoc. 2010, 5, 93–121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ravikrishnan, A.; Raman, K. Critical assessment of genome-scale metabolic networks: The need for a unified standard. Briefings Bioinform. 2015, 16, 1057–1068. [Google Scholar] [CrossRef] [Green Version]
- Carey, M.; Dräger, A.; Papin, J.A.; Palsson, B.O.; Draeger, A. Community standards to facilitate development and address challenges in metabolic modeling. bioRxiv 2019, 700112. [Google Scholar]
- Christian, L.; Moritz, E.; Beber, G.; Olivier, T.; Bergmann, A.; Parizad, B.; Jennifer, B.; Lars, B.; Siddharth, C.; Kevin, C.; et al. MEMOTE for standardized genome-scale metabolic model testing. Nat. Biotechnol. 2020, 38, 272–276. [Google Scholar]
- Gebauer, J.; Gentsch, C.; Mansfeld, J.; Schmeißer, K.; Waschina, S.; Brandes, S.; Klimmasch, L.; Zamboni, N.; Zarse, K.; Schuster, S.; et al. A Genome-Scale Database and Reconstruction of Caenorhabditis elegans Metabolism. Cell Syst. 2016, 2, 312–322. [Google Scholar] [CrossRef] [Green Version]
- Yilmaz, L.S.; Walhout, A.J.M. A Caenorhabditis elegans Genome-Scale Metabolic Network Model. Cell Syst. 2016, 2, 297–311. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Chan, A.H.C.; Hattwell, J.; Ebert, P.; Schirra, H.J. Systems biology analysis using a genome-scale metabolic model shows that phosphine triggers global metabolic suppression in a resistant strain of C. elegans. bioRxiv 2017, 144386. [Google Scholar]
- Witting, M.; Hastings, J.; Rodriguez, N.; Joshi, C.J.; Hattwell, J.; Ebert, P.; Van Weeghel, M.; Gao, A.; Wakelam, M.; Houtkooper, R.H.; et al. Modeling Meets Metabolomics—The WormJam Consensus Model as Basis for Metabolic Studies in the Model Organism Caenorhabditis elegans. Front. Mol. Biosci. 2018, 5, 96. [Google Scholar] [CrossRef]
- Hastings, J.; Mains, A.; Artal-Sanz, M.; Bergmann, S.; Braeckman, B.P.; Bundy, J.G.; Cabreiro, F.; Dobson, P.; Ebert, P.; Hattwell, J.; et al. WormJam: A consensus C. elegans Metabolic Reconstruction and Metabolomics Community and Workshop Series. Worm 2017, 6, e1373939. [Google Scholar] [CrossRef] [Green Version]
- King, Z.A.; Lu, J.; Dräger, A.; Miller, P.; Federowicz, S.; Lerman, J.; Ebrahim, A.; Palsson, B.O.; Lewis, N.E. BiGG Models: A platform for integrating, standardizing and sharing genome-scale models. Nucleic Acids Res. 2015, 44, D515–D522. [Google Scholar] [CrossRef] [PubMed]
- Moretti, S.; Martin, O.; Tran, T.V.D.; Bridge, A.; Morgat, A.; Pagni, M. MetaNetX/MNXref—Reconciliation of metabolites and biochemical reactions to bring together genome-scale metabolic networks. Nucleic Acids Res. 2015, 44, D523–D526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oh, Y.-K.; Palsson, B.O.; Park, S.M.; Schilling, C.H.; Mahadevan, R. Genome-scale Reconstruction of Metabolic Network inBacillus subtilisBased on High-throughput Phenotyping and Gene Essentiality Data. J. Boil. Chem. 2007, 282, 28791–28799. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liebisch, G.; Vizcaíno, J.A.; Köfeler, H.; Trötzmüller, M.; Griffiths, W.J.; Schmitz, G.; Spener, F.; Wakelam, M. Shorthand notation for lipid structures derived from mass spectrometry. J. Lipid Res. 2013, 54, 1523–1530. [Google Scholar] [CrossRef] [Green Version]
- Lubitz, T.; Hahn, J.; Bergmann, F.; Noor, E.; Klipp, A.; Liebermeister, W. SBtab: A flexible table format for data exchange in systems biology. Bioinformatics 2016, 32, 2559–2561. [Google Scholar] [CrossRef] [Green Version]
- Hastings, J.; De Matos, P.; Dekker, A.; Ennis, M.; Harsha, B.; Kale, N.; Muthukrishnan, V.; Owen, G.; Turner, S.; Williams, M.; et al. The ChEBI reference database and ontology for biologically relevant chemistry: Enhancements for 2013. Nucleic Acids Res. 2012, 41, D456–D463. [Google Scholar] [CrossRef]
- Wishart, D.S.; Feunang, Y.D.; Marcu, A.; Guo, A.C.; Liang, K.; Vázquez-Fresno, R.; Sajed, T.; Johnson, D.; Li, C.; Karu, N.; et al. HMDB 4.0: The human metabolome database for 2018. Nucleic Acids Res. 2018, 46, D608–D617. [Google Scholar] [CrossRef]
- Kanehisa, M.; Goto, S.; Sato, Y.; Kawashima, M.; Furumichi, M.; Tanabe, M. Data, information, knowledge and principle: Back to metabolism in KEGG. Nucleic Acids Res. 2013, 42, D199–D205. [Google Scholar] [CrossRef] [Green Version]
- O’Donnell, V.B.; Dennis, E.A.; Wakelam, M.; Subramaniam, S. LIPID MAPS: Serving the next generation of lipid researchers with tools, resources, data, and training. Sci. Signal. 2019, 12, eaaw2964. [Google Scholar] [CrossRef] [Green Version]
- Heller, S.; McNaught, A.; Pletnev, I.; Stein, S.; Tchekhovskoi, D. InChI, the IUPAC International Chemical Identifier. J. Cheminform. 2015, 7, 23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Iersel, M.; Pico, A.R.; Kelder, T.; Gao, J.; Ho, I.Y.; Hanspers, K.; Conklin, B.R.; Evelo, C.T. The BridgeDb framework: Standardized access to gene, protein and metabolite identifier mapping services. BMC Bioinform. 2010, 11, 5. [Google Scholar] [CrossRef] [PubMed]
- Orth, J.D.; Conrad, T.M.; Na, J.; Lerman, J.; Nam, H.; Feist, A.M.; Palsson, B.O. A comprehensive genome-scale reconstruction of Escherichia coli metabolism—2011. Mol. Syst. Boil. 2011, 7, 535. [Google Scholar] [CrossRef] [PubMed]
- Brunk, E.; Sahoo, S.; Zielinski, D.C.; Altunkaya, A.; Dräger, A.; Mih, N.; Gatto, F.; Nilsson, A.; Gonzalez, G.A.P.; Aurich, M.K.; et al. Recon3D enables a three-dimensional view of gene variation in human metabolism. Nat. Biotechnol. 2018, 36, 272–281. [Google Scholar] [CrossRef] [PubMed]
- Hefzi, H.; Ang, K.S.; Hanscho, M.; Bordbar, A.; Ruckerbauer, D.; Lakshmanan, M.; Orellana, C.A.; Baycin-Hizal, D.; Huang, Y.; Ley, D.; et al. A Consensus Genome-scale Reconstruction of Chinese Hamster Ovary Cell Metabolism. Cell Syst. 2016, 3, 434–443.e8. [Google Scholar] [CrossRef] [Green Version]
- Watts, J.L.; Browse, J. Genetic dissection of polyunsaturated fatty acid synthesis in Caenorhabditis elegans. Proc. Natl. Acad. Sci. USA 2002, 99, 5854–5859. [Google Scholar] [CrossRef] [Green Version]
- Perez, C.L.; Van Gilst, M.R. A 13C Isotope Labeling Strategy Reveals the Influence of Insulin Signaling on Lipogenesis in C. elegans. Cell Metab. 2008, 8, 266–274. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Shen, H.; Sewell, A.K.; Kniazeva, M.; Han, M. A novel sphingolipid-TORC1 pathway critically promotes postembryonic development in Caenorhabditis elegans. eLife 2013, 2, e00429. [Google Scholar] [CrossRef]
- Hänel, V.; Pendleton, C.; Witting, M. The sphingolipidome of the model organism Caenorhabditis elegans. Chem. Phys. Lipids 2019, 222, 15–22. [Google Scholar] [CrossRef]
- Hannich, J.T.; Mellal, D.; Feng, S.; Zumbuehl, A.; Riezman, H. Structure and conserved function of iso-branched sphingoid bases from the nematode Caenorhabditis elegans. Chem. Sci. 2017, 8, 3676–3686. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Pairing | Count |
|---|---|
| no structural information<-> no structural information | 135 |
| partial structural information <-> no structural information | 8 |
| Partial structural information <-> partial structural information | 36 |
| Full structural information <-> no structural information | 96 |
| Full structural information <-> partial structural information | 161 |
| Full structural information <-> full structural information | 897 |
| Name | Shorthand Notation | Old | New |
|---|---|---|---|
| Oleyl-l-carnitine | Carn(18:1(9Z)) | ocdce9crn | carn18_1_9z__L |
| Oleyl-CoA | CoA(18:1(9Z)) | odecoa | coa18_1_9z |
| (2E,9Z-Octadecenoyl-CoA | CoA(18:2(2E,9Z)) | od29coa | coa18_2_2e9z |
| (S)-3-Hydroxyl-Oleoyl-CoA | CoA(18:1(9Z,3OH[S])) | 3hod9coa | coa18_1_9z3oh__S |
| 3-Oxo-Oleoyl-coA | CoA(18:1(9Z,3O) | 3ood9coa | coa18_1_9z3o |
| (7Z)-Hexadecenoyl-CoA | CoA(16:1(7Z)) | hd7coa | coa16_1_7z |
| iCel1273 | ElegCyc | WormJam | BiGG | New ID | |
|---|---|---|---|---|---|
| Tetradecanoic acid (Myristic acid) | ttdca | ttdca | ttdca | ttdca | fa14_0 |
| Tetradecanoyl-Acyl-Carrier Protein (Myristoyl-ACP) | Myristoyl_ACPs | --- | myrsACP | myrsACP | acp14_0 |
| Tetradecanoyl-Coenzyme A (Myristoyl-CoA) | tdcoa | tdcoa | tdcoa | tdcoa | coa14_0 |
| Tetradecanoyl-Carnitine (Myristoyl-Carnitine) | ttdcrn | CPD909_16 | ttdcrn | Ttdcrn M02973 | crn14_0__L |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Witting, M. Suggestions for Standardized Identifiers for Fatty Acyl Compounds in Genome Scale Metabolic Models and Their Application to the WormJam Caenorhabditis elegans Model. Metabolites 2020, 10, 130. https://doi.org/10.3390/metabo10040130
Witting M. Suggestions for Standardized Identifiers for Fatty Acyl Compounds in Genome Scale Metabolic Models and Their Application to the WormJam Caenorhabditis elegans Model. Metabolites. 2020; 10(4):130. https://doi.org/10.3390/metabo10040130
Chicago/Turabian StyleWitting, Michael. 2020. "Suggestions for Standardized Identifiers for Fatty Acyl Compounds in Genome Scale Metabolic Models and Their Application to the WormJam Caenorhabditis elegans Model" Metabolites 10, no. 4: 130. https://doi.org/10.3390/metabo10040130
APA StyleWitting, M. (2020). Suggestions for Standardized Identifiers for Fatty Acyl Compounds in Genome Scale Metabolic Models and Their Application to the WormJam Caenorhabditis elegans Model. Metabolites, 10(4), 130. https://doi.org/10.3390/metabo10040130