Feature Papers in Information Theory
Share This Topical Collection
Editors
 Prof. Dr. Raúl Alcaraz
Prof. Dr. Raúl Alcaraz
Prof. Dr. Raúl Alcaraz
E-Mail
Website
Collection Editor
Research Group in Electronic, Biomedical and Telecommunication Engineering, Universidad de Castilla-La Mancha, Campus Universitario s/n, 16071 Cuenca, Spain
Interests: entropy; complexity; information theory; information geometry; nonlinear dynamics; computational mathematics and statistics in medicine; biomedical time series analysis; cardiac signal processing
Special Issues, Collections and Topics in MDPI journals
 Prof. Dr. Luca Faes
Prof. Dr. Luca Faes
Prof. Dr. Luca Faes
E-Mail
Website
Collection Editor
Department of Energy, Information Engineering and Mathematical models (DEIM), University of Palermo, 90128 Palermo, Italy
Interests: time series analysis; information dynamics; network physiology; cardiovascular neuroscience; brain connectivity
Special Issues, Collections and Topics in MDPI journals
Prof. Dr. Leandro Pardo
Prof. Dr. Leandro Pardo
E-Mail
Website
Collection Editor
Department of Statistics and O.R., Complutense University of Madrid, 28040 Madrid, Spain
Interests: minimum divergence estimators: robustness and efficiency; robust test procedures based on minimum divergence estimators; robust test procedures in composite likelihood, empirical likelihood, change point, and time series
Special Issues, Collections and Topics in MDPI journals
 Prof. Dr. Boris Ryabko
Prof. Dr. Boris Ryabko
Prof. Dr. Boris Ryabko
E-Mail
Website
Collection Editor
1. Federal Research Center for Information and Computational Technologies, 630090 Novosibirsk, Russia
2. Department of Information Technologies, Novosibirsk State University, 630090 Novosibirsk, Russia
Interests: information theory; cryptography and steganography; mathematical statistics and prediction; complexity of algorithms and mathematical biology
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
This Topical Collection aims at assembling high quality and high influential research and review articles in all the fields of Information Theory. The collecion aims to delineate, through selected works, frontier research in Information Theory. Hence, we encourage Editorial Board Members of the Information Theory, Statistical and Probability Section of the Entropy to contribute papers reflecting the latest progress in their research field, or to invite relevant experts and colleagues to do so.
Topics include, but are not limited to:
- Communications and communication networks
- Coding Theory, source coding, coding techniques
- Quantum Information Theory
- Shannon Theory
- Statistical Learning, Machine Learning, and Deep Learning
- Complexity and Cryptography
- Detection and Estimation
- Probability and Statistics
- Information-theoretic signal analysis
- Relevant applications of Information Theory to fields such as health, economy, biology, physiology, climatology, industry, etc.
Dr. Raúl Alcaraz
Prof. Dr. Luca Faes
Prof. Dr. Leandro Pardo
Prof. Boris Ryabko
Guest Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Entropy is an international peer-reviewed open access monthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2600 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Published Papers (24 papers)
Open AccessArticle
Influence of Explanatory Variable Distributions on the Behavior of the Impurity Measures Used in Classification Tree Learning
by
Krzysztof Gajowniczek and Marcin Dudziński
Abstract
The primary objective of our study is to analyze how the nature of explanatory variables influences the values and behavior of impurity measures, including the Shannon, Rényi, Tsallis, Sharma–Mittal, Sharma–Taneja, and Kapur entropies. Our analysis aims to use these measures in the interactive
[...] Read more.
The primary objective of our study is to analyze how the nature of explanatory variables influences the values and behavior of impurity measures, including the Shannon, Rényi, Tsallis, Sharma–Mittal, Sharma–Taneja, and Kapur entropies. Our analysis aims to use these measures in the interactive learning of decision trees, particularly in the tie-breaking situations where an expert needs to make a decision. We simulate the values of explanatory variables from various probability distributions in order to consider a wide range of variability and properties. These probability distributions include the normal, Cauchy, uniform, exponential, and two beta distributions. This research assumes that the values of the binary responses are generated from the logistic regression model. All of the six mentioned probability distributions of the explanatory variables are presented in the same graphical format. The first two graphs depict histograms of the explanatory variables values and their corresponding probabilities generated by a particular model. The remaining graphs present distinct impurity measures with different parameters. In order to examine and discuss the behavior of the obtained results, we conduct a sensitivity analysis of the algorithms with regard to the entropy parameter values. We also demonstrate how certain explanatory variables affect the process of interactive tree learning.
Full article
►▼
Show Figures
Open AccessArticle
Two New Families of Local Asymptotically Minimax Lower Bounds in Parameter Estimation
by
Neri Merhav
Viewed by 415
Abstract
We propose two families of asymptotically local minimax lower bounds on parameter estimation performance. The first family of bounds applies to any convex, symmetric loss function that depends solely on the difference between the estimate and the true underlying parameter value (i.e., the
[...] Read more.
We propose two families of asymptotically local minimax lower bounds on parameter estimation performance. The first family of bounds applies to any convex, symmetric loss function that depends solely on the difference between the estimate and the true underlying parameter value (i.e., the estimation error), whereas the second is more specifically oriented to the moments of the estimation error. The proposed bounds are relatively easy to calculate numerically (in the sense that their optimization is over relatively few auxiliary parameters), yet they turn out to be tighter (sometimes significantly so) than previously reported bounds that are associated with similar calculation efforts, across many application examples. In addition to their relative simplicity, they also have the following advantages: (i) Essentially no regularity conditions are required regarding the parametric family of distributions. (ii) The bounds are local (in a sense to be specified). (iii) The bounds provide the correct order of decay as functions of the number of observations, at least in all the examples examined. (iv) At least the first family of bounds extends straightforwardly to vector parameters.
Full article
Open AccessArticle
Contrast Information Dynamics: A Novel Information Measure for Cognitive Modelling
by
Steven T. Homer, Nicholas Harley and Geraint A. Wiggins
Viewed by 928
Abstract
We present
contrast information, a novel application of some specific cases of relative entropy, designed to be useful for the cognitive modelling of the sequential perception of continuous signals. We explain the relevance of entropy in the cognitive modelling of sequential phenomena
[...] Read more.
We present
contrast information, a novel application of some specific cases of relative entropy, designed to be useful for the cognitive modelling of the sequential perception of continuous signals. We explain the relevance of entropy in the cognitive modelling of sequential phenomena such as music and language. Then, as a first step to demonstrating the utility of constrast information for this purpose, we empirically show that its discrete case correlates well with existing successful cognitive models in the literature. We explain some interesting properties of constrast information. Finally, we propose future work toward a cognitive architecture that uses it.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
The State-Dependent Channel with a Rate-Limited Cribbing Helper
by
Amos Lapidoth and Yossef Steinberg
Cited by 1 | Viewed by 867
Abstract
The capacity of a memoryless state-dependent channel is derived for a setting in which the encoder is provided with rate-limited assistance from a cribbing helper that observes the state sequence causally and the past channel inputs strictly causally. Said cribbing may increase capacity
[...] Read more.
The capacity of a memoryless state-dependent channel is derived for a setting in which the encoder is provided with rate-limited assistance from a cribbing helper that observes the state sequence causally and the past channel inputs strictly causally. Said cribbing may increase capacity but not to the level achievable by a message-cognizant helper.
Full article
►▼
Show Figures
Open AccessArticle
Refinements and Extensions of Ziv’s Model of Perfect Secrecy for Individual Sequences
by
Neri Merhav
Viewed by 694
Abstract
We refine and extend Ziv’s model and results regarding perfectly secure encryption of individual sequences. According to this model, the encrypter and the legitimate decrypter share a common secret key that is not shared with the unauthorized eavesdropper. The eavesdropper is aware of
[...] Read more.
We refine and extend Ziv’s model and results regarding perfectly secure encryption of individual sequences. According to this model, the encrypter and the legitimate decrypter share a common secret key that is not shared with the unauthorized eavesdropper. The eavesdropper is aware of the encryption scheme and has some prior knowledge concerning the individual plaintext source sequence. This prior knowledge, combined with the cryptogram, is harnessed by the eavesdropper, who implements a finite-state machine as a mechanism for accepting or rejecting attempted guesses of the plaintext source. The encryption is considered perfectly secure if the cryptogram does not provide any new information to the eavesdropper that may enhance their knowledge concerning the plaintext beyond their prior knowledge. Ziv has shown that the key rate needed for perfect secrecy is essentially lower bounded by the finite-state compressibility of the plaintext sequence, a bound that is clearly asymptotically attained through Lempel–Ziv compression followed by one-time pad encryption. In this work, we consider some more general classes of finite-state eavesdroppers and derive the respective lower bounds on the key rates needed for perfect secrecy. These bounds are tighter and more refined than Ziv’s bound, and they are attained using encryption schemes that are based on different universal lossless compression schemes. We also extend our findings to the case where side information is available to the eavesdropper and the legitimate decrypter but may or may not be available to the encrypter.
Full article
Open AccessArticle
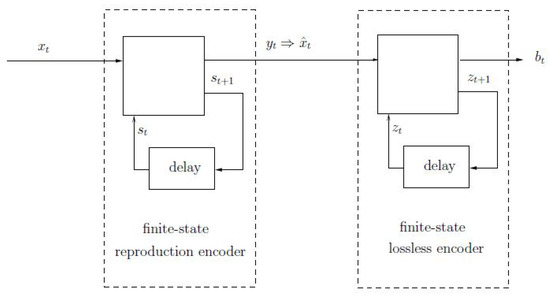
Lossy Compression of Individual Sequences Revisited: Fundamental Limits of Finite-State Encoders
by
Neri Merhav
Viewed by 1052
Abstract
We extend Ziv and Lempel’s model of finite-state encoders to the realm of lossy compression of individual sequences. In particular, the model of the encoder includes a finite-state reconstruction codebook followed by an information lossless finite-state encoder that compresses the reconstruction codeword with
[...] Read more.
We extend Ziv and Lempel’s model of finite-state encoders to the realm of lossy compression of individual sequences. In particular, the model of the encoder includes a finite-state reconstruction codebook followed by an information lossless finite-state encoder that compresses the reconstruction codeword with no additional distortion. We first derive two different lower bounds to the compression ratio, which depend on the number of states of the lossless encoder. Both bounds are asymptotically achievable by conceptually simple coding schemes. We then show that when the number of states of the lossless encoder is large enough in terms of the reconstruction block length, the performance can be improved, sometimes significantly so. In particular, the improved performance is achievable using a random-coding ensemble that is universal, not only in terms of the source sequence but also in terms of the distortion measure.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
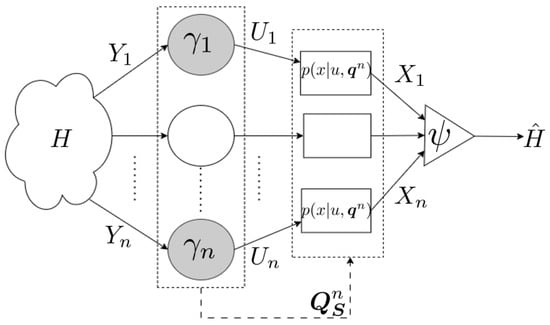
Joint Detection and Communication over Type-Sensitive Networks
by
Joni Shaska and Urbashi Mitra
Viewed by 969
Abstract
Due to the difficulty of decentralized inference with conditional dependent observations, and motivated by large-scale heterogeneous networks, we formulate a framework for decentralized detection with coupled observations. Each agent has a state, and the empirical distribution of all agents’ states or the type
[...] Read more.
Due to the difficulty of decentralized inference with conditional dependent observations, and motivated by large-scale heterogeneous networks, we formulate a framework for decentralized detection with coupled observations. Each agent has a state, and the empirical distribution of all agents’ states or the type of network dictates the individual agents’ behavior. In particular, agents’ observations depend on both the underlying hypothesis as well as the empirical distribution of the agents’ states. Hence, our framework captures a high degree of coupling, in that an individual agent’s behavior depends on both the underlying hypothesis and the behavior of all other agents in the network. Considering this framework, the method of types, and a series of equicontinuity arguments, we derive the error exponent for the case in which all agents are identical and show that this error exponent depends on only a single empirical distribution. The analysis is extended to the multi-class case, and numerical results with state-dependent agent signaling and state-dependent channels highlight the utility of the proposed framework for analysis of highly coupled environments.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
A Universal Random Coding Ensemble for Sample-Wise Lossy Compression
by
Neri Merhav
Cited by 4 | Viewed by 931
Abstract
We propose a universal ensemble for the random selection of rate–distortion codes which is asymptotically optimal in a sample-wise sense. According to this ensemble, each reproduction vector,
, is selected independently at random under the probability distribution that is proportional to
[...] Read more.
We propose a universal ensemble for the random selection of rate–distortion codes which is asymptotically optimal in a sample-wise sense. According to this ensemble, each reproduction vector,
, is selected independently at random under the probability distribution that is proportional to
, where
is the code length of
pertaining to the 1978 version of the Lempel–Ziv (LZ) algorithm. We show that, with high probability, the resulting codebook gives rise to an asymptotically optimal variable-rate lossy compression scheme under an arbitrary distortion measure, in the sense that a matching converse theorem also holds. According to the converse theorem, even if the decoder knew the
ℓ-th order type of source vector in advance (
ℓ being a large but fixed positive integer), the performance of the above-mentioned code could not have been improved essentially for the vast majority of codewords pertaining to source vectors in the same type. Finally, we present a discussion of our results, which includes among other things, a clear indication that our coding scheme outperforms the one that selects the reproduction vector with the shortest LZ code length among all vectors that are within the allowed distortion from the source vector.
Full article
Open AccessArticle
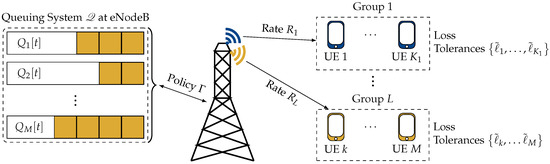
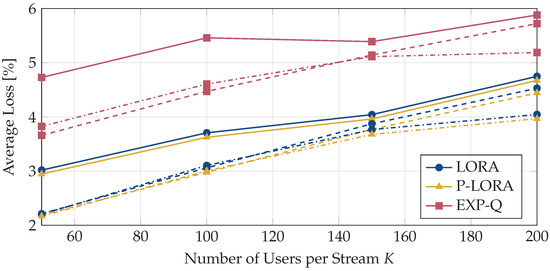
Optimal Resource Allocation for Loss-Tolerant Multicast Video Streaming
by
Sadaf ul Zuhra, Karl-Ludwig Besser, Prasanna Chaporkar, Abhay Karandikar and H. Vincent Poor
Cited by 1 | Viewed by 1612
Abstract
In video streaming applications, especially during live streaming events, video traffic can account for a significant portion of the network traffic and can lead to severe network congestion. For such applications, multicast provides an efficient means to deliver the same content to a
[...] Read more.
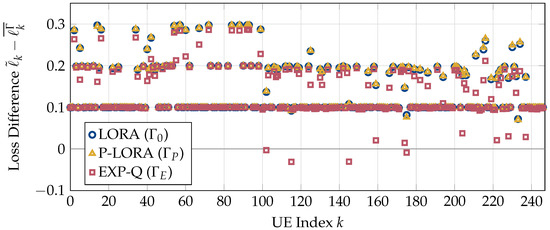
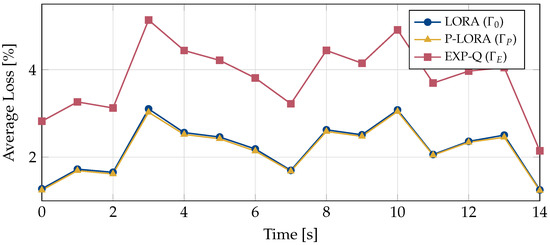
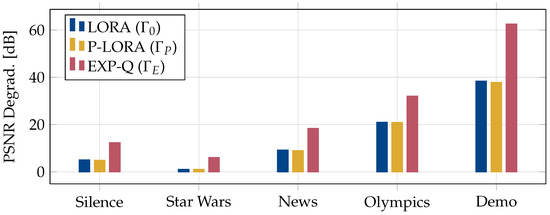
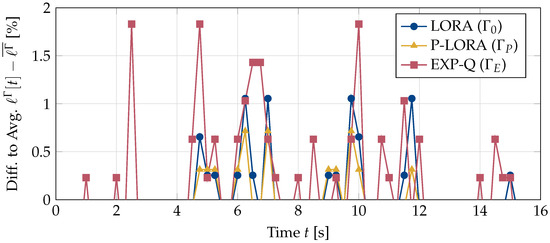
In video streaming applications, especially during live streaming events, video traffic can account for a significant portion of the network traffic and can lead to severe network congestion. For such applications, multicast provides an efficient means to deliver the same content to a large number of users simultaneously. However, in multicast, if the base station transmits content at rates higher than what can be decoded by users with the worst channels, these users will experience outages. This makes the multicast system’s performance dependent on the weakest users in the system. Interestingly, video streams can tolerate some packet loss without a significant degradation in the quality experienced by the users. This property can be leveraged to improve the multicast system’s performance by reducing the dependence of the multicast transmissions on the weakest users. In this work, we design a loss-tolerant video multicasting system that allows for some controlled packet loss while satisfying the quality requirements of the users. In particular, we solve the resource allocation problem in a multimedia broadcast multicast services (MBMS) system by transforming it into the problem of stabilizing a virtual queuing system. We propose two loss-optimal policies and demonstrate their effectiveness using numerical examples with realistic traffic patterns from real video streams. It is shown that the proposed policies are able to keep the loss encountered by every user below its tolerable loss. The proposed policies are also able to achieve a significantly lower peak SNR degradation than the existing schemes.
Full article
►▼
Show Figures
Open AccessArticle
Some Families of Jensen-like Inequalities with Application to Information Theory
by
Neri Merhav
Viewed by 1792
Abstract
It is well known that the traditional Jensen inequality is proved by lower bounding the given convex function,
, by the tangential affine function that passes through the point
[...] Read more.
It is well known that the traditional Jensen inequality is proved by lower bounding the given convex function,
, by the tangential affine function that passes through the point
, where
is the expectation of the random variable
X. While this tangential affine function yields the tightest lower bound among all lower bounds induced by affine functions that are tangential to
f, it turns out that when the function
f is just part of a more complicated expression whose expectation is to be bounded, the tightest lower bound might belong to a tangential affine function that passes through a point different than
. In this paper, we take advantage of this observation by optimizing the point of tangency with regard to the specific given expression in a variety of cases and thereby derive several families of inequalities, henceforth referred to as “Jensen-like” inequalities, which are new to the best knowledge of the author. The degree of tightness and the potential usefulness of these inequalities is demonstrated in several application examples related to information theory.
Full article
►▼
Show Figures
Open AccessArticle
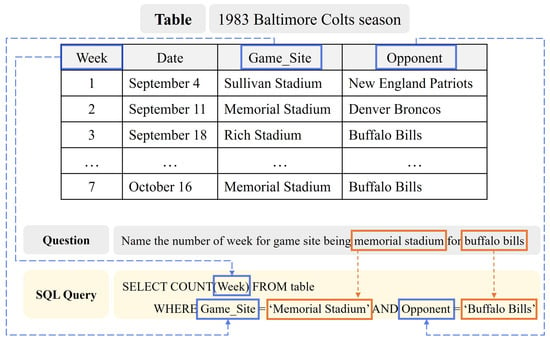
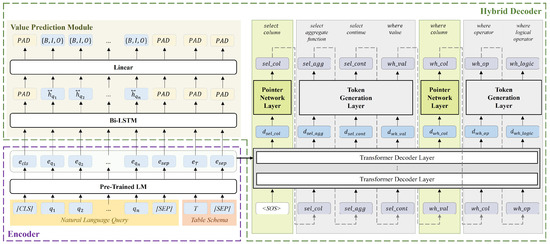
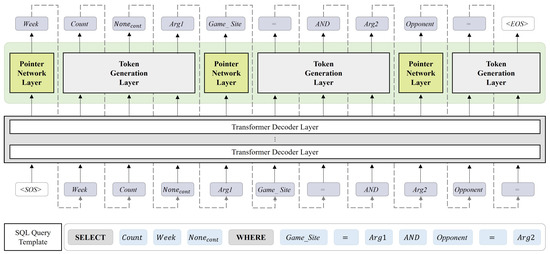
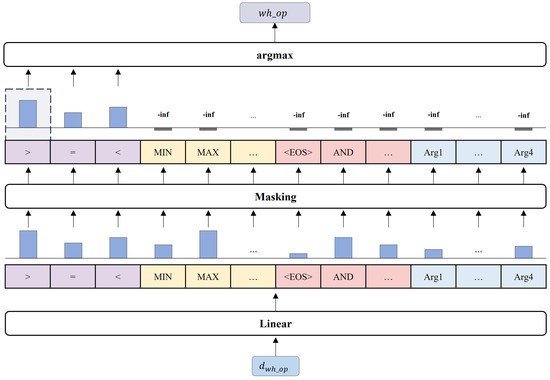
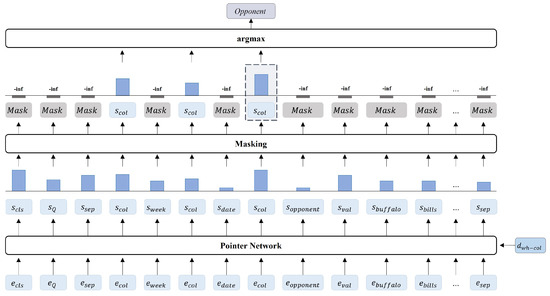
Improving Text-to-SQL with a Hybrid Decoding Method
by
Geunyeong Jeong, Mirae Han, Seulgi Kim, Yejin Lee, Joosang Lee, Seongsik Park and Harksoo Kim
Cited by 2 | Viewed by 3517
Abstract
Text-to-SQL is a task that converts natural language questions into SQL queries. Recent text-to-SQL models employ two decoding methods: sketch-based and generation-based, but each has its own shortcomings. The sketch-based method has limitations in performance as it does not reflect the relevance between
[...] Read more.
Text-to-SQL is a task that converts natural language questions into SQL queries. Recent text-to-SQL models employ two decoding methods: sketch-based and generation-based, but each has its own shortcomings. The sketch-based method has limitations in performance as it does not reflect the relevance between SQL elements, while the generation-based method may increase inference time and cause syntactic errors. Therefore, we propose a novel decoding method, Hybrid decoder, which combines both methods. This reflects inter-SQL element information and defines elements that can be generated, enabling the generation of syntactically accurate SQL queries. Additionally, we introduce a Value prediction module for predicting values in the WHERE clause. It simplifies the decoding process and reduces the size of vocabulary by predicting values at once, regardless of the number of conditions. The results of evaluating the significance of Hybrid decoder indicate that it improves performance by effectively incorporating mutual information among SQL elements, compared to the sketch-based method. It also efficiently generates SQL queries by simplifying the decoding process in the generation-based method. In addition, we design a new evaluation measure to evaluate if it generates syntactically correct SQL queries. The result demonstrates that the proposed model generates syntactically accurate SQL queries.
Full article
►▼
Show Figures
Open AccessEditor’s ChoiceArticle
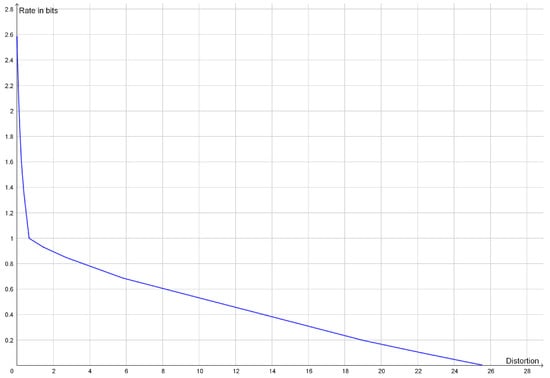
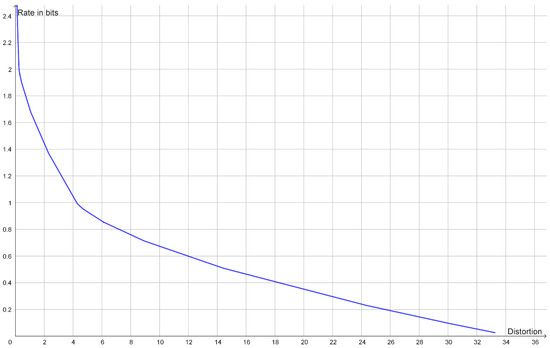
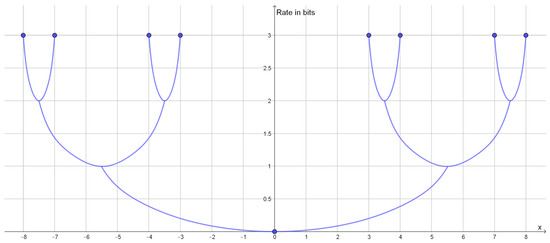
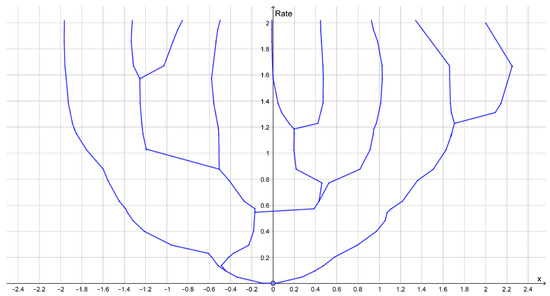
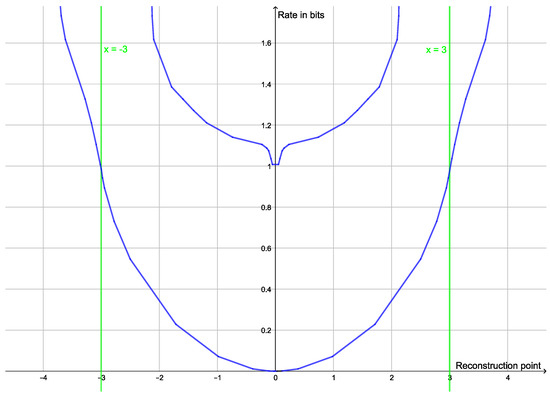
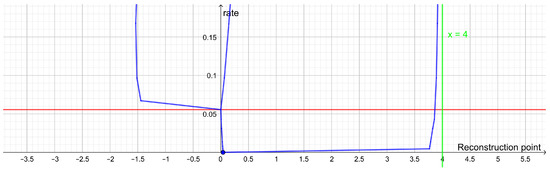
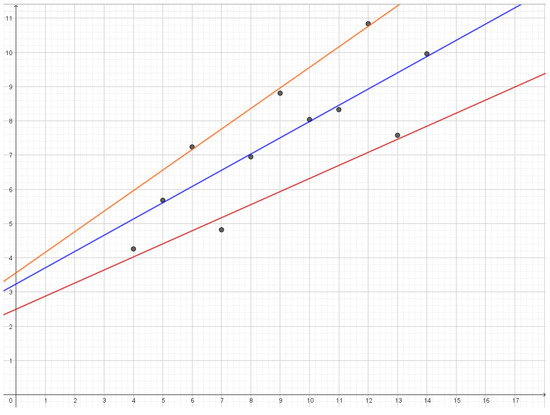
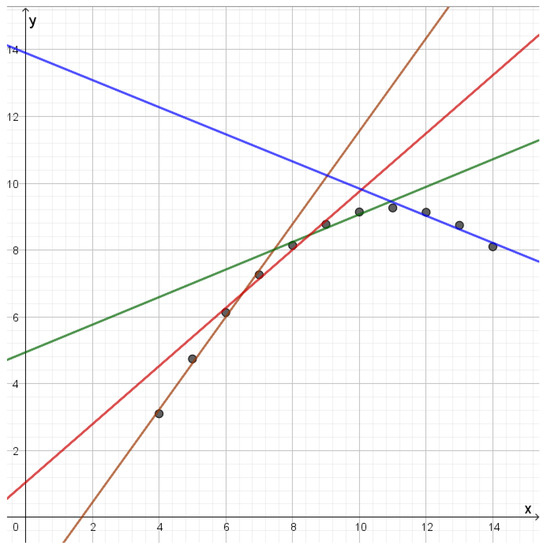
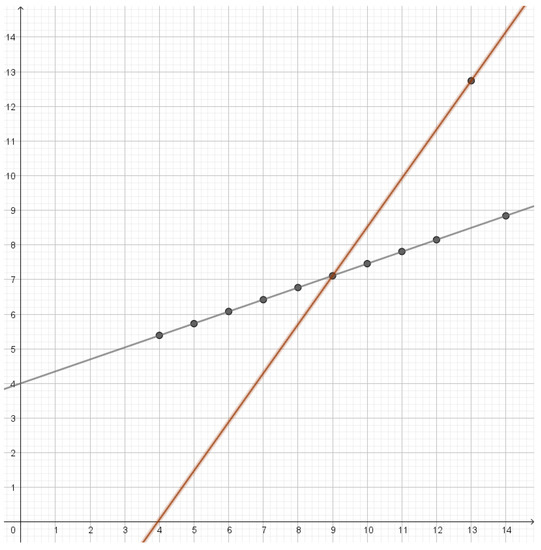
Rate Distortion Theory for Descriptive Statistics
by
Peter Harremoës
Cited by 2 | Viewed by 2341
Abstract
Rate distortion theory was developed for optimizing lossy compression of data, but it also has applications in statistics. In this paper, we illustrate how rate distortion theory can be used to analyze various datasets. The analysis involves testing, identification of outliers, choice of
[...] Read more.
Rate distortion theory was developed for optimizing lossy compression of data, but it also has applications in statistics. In this paper, we illustrate how rate distortion theory can be used to analyze various datasets. The analysis involves testing, identification of outliers, choice of compression rate, calculation of optimal reconstruction points, and assigning “descriptive confidence regions” to the reconstruction points. We study four models or datasets of increasing complexity: clustering, Gaussian models, linear regression, and a dataset describing orientations of early Islamic mosques. These examples illustrate how rate distortion analysis may serve as a common framework for handling different statistical problems.
Full article
►▼
Show Figures
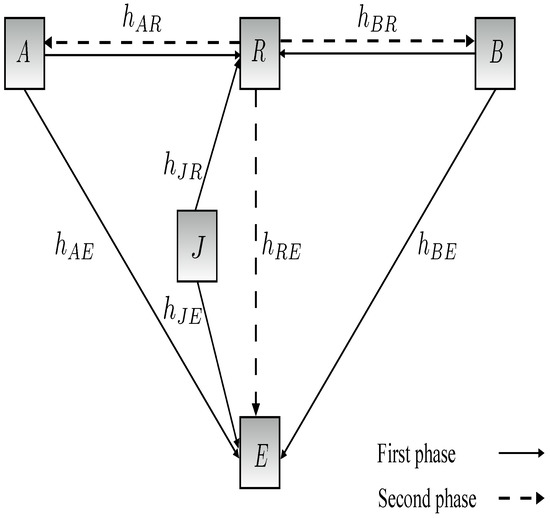
Open AccessArticle
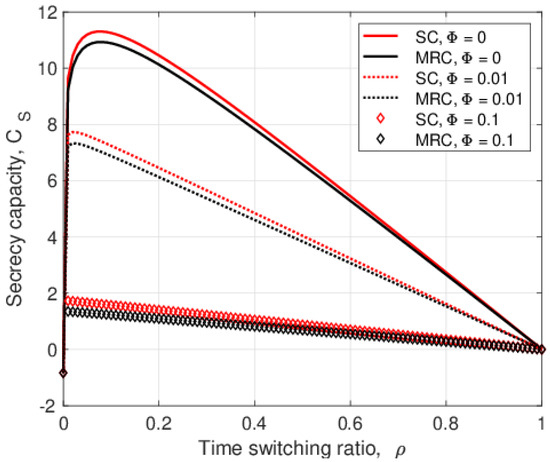
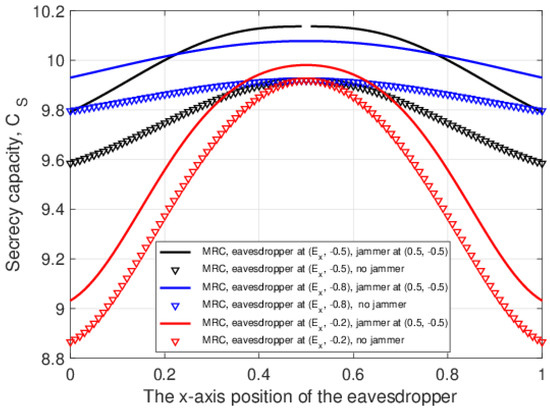
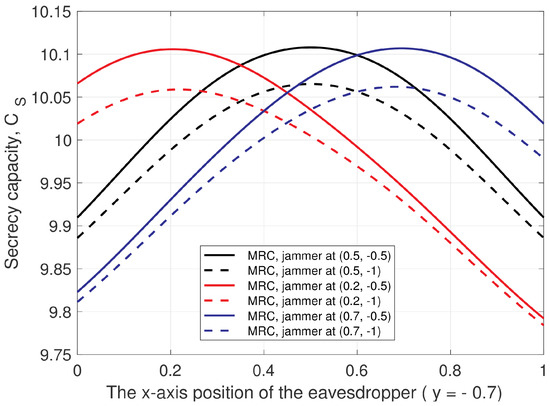
Physical Layer Security in Two-Way SWIPT Relay Networks with Imperfect CSI and a Friendly Jammer
by
Maymoona Hayajneh and Thomas Aaron Gulliver
Cited by 3 | Viewed by 2007
Abstract
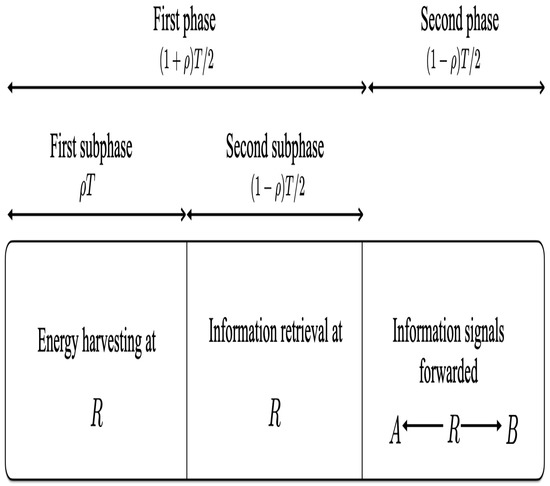
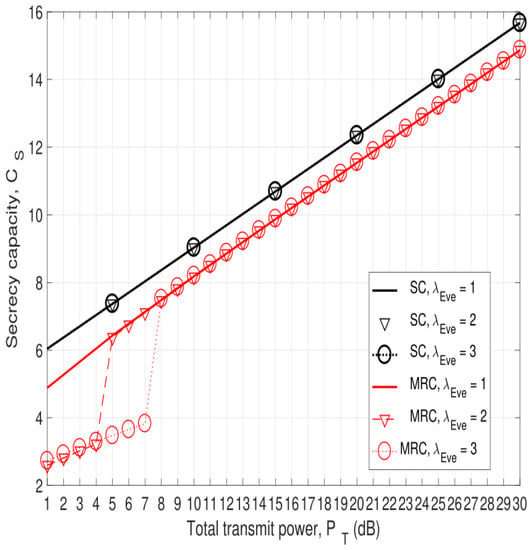
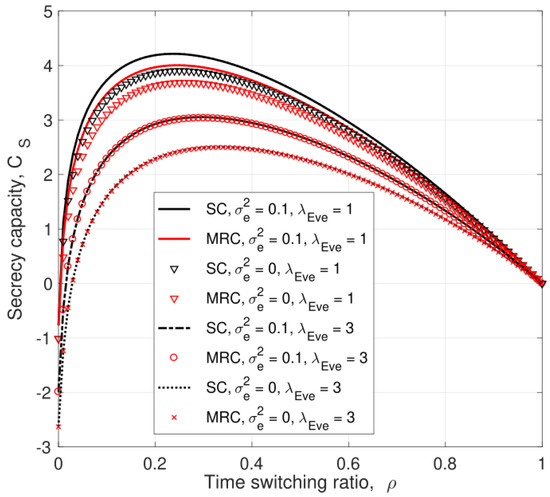
In this paper, the security of two-way relay communications in the presence of a passive eavesdropper is investigated. Two users communicate via a relay that depends solely on energy harvesting to amplify and forward the received signals. Time switching is employed at the
[...] Read more.
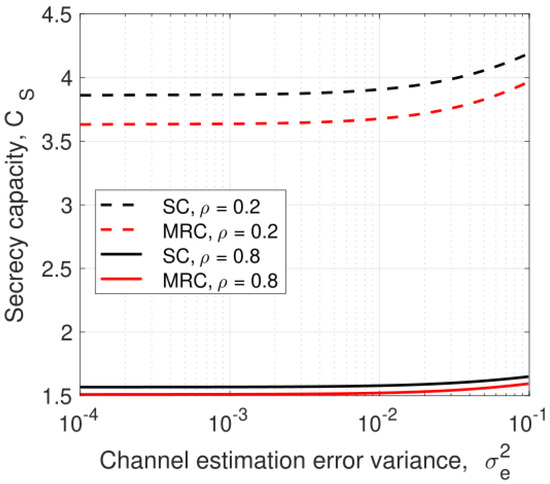
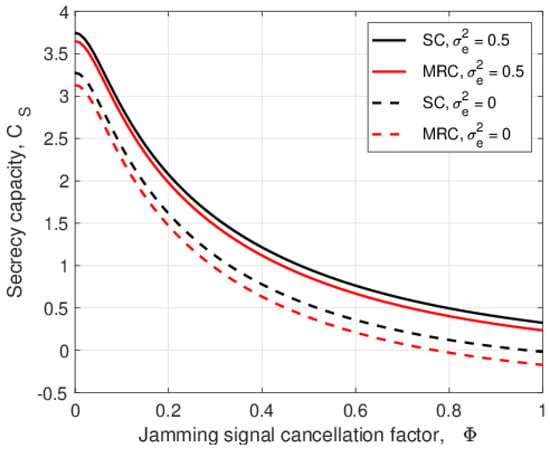
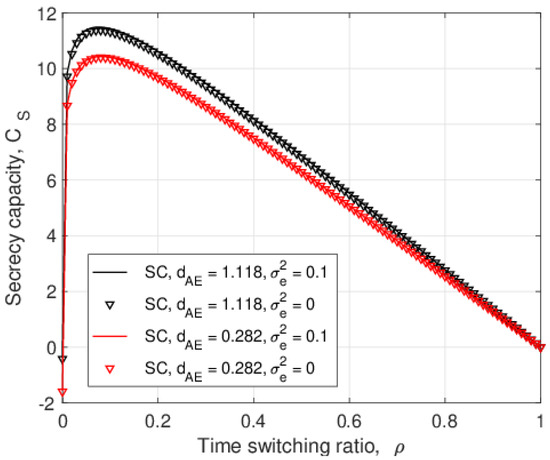
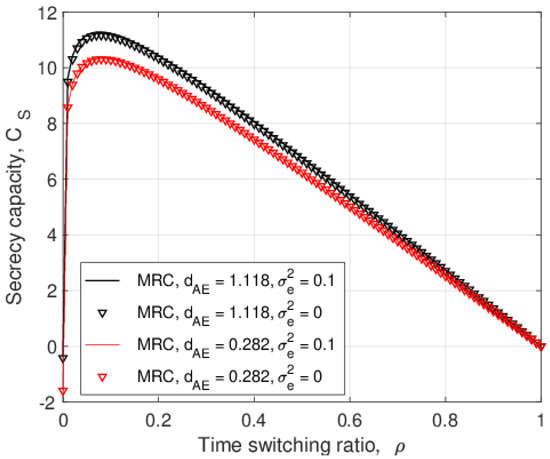
In this paper, the security of two-way relay communications in the presence of a passive eavesdropper is investigated. Two users communicate via a relay that depends solely on energy harvesting to amplify and forward the received signals. Time switching is employed at the relay to harvest energy and obtain user information. A friendly jammer is utilized to hinder the eavesdropping from wiretapping the information signal. The eavesdropper employs maximal ratio combining and selection combining to improve the signal-to-noise ratio of the wiretapped signals. Geometric programming (GP) is used to maximize the secrecy capacity of the system by jointly optimizing the time switching ratio of the relay and transmit power of the two users and jammer. The impact of imperfect channel state information at the eavesdropper for the links between the eavesdropper and the other nodes is determined. Further, the secrecy capacity when the jamming signal is not perfectly cancelled at the relay is examined. The secrecy capacity is shown to be greater with a jammer compared to the case without a jammer. The effect of the relay, jammer, and eavesdropper locations on the secrecy capacity is also studied. It is shown that the secrecy capacity is greatest when the relay is at the midpoint between the users. The closer the jammer is to the eavesdropper, the higher the secrecy capacity as the shorter distance decreases the signal-to-noise ratio of the jammer.
Full article
►▼
Show Figures
Open AccessArticle
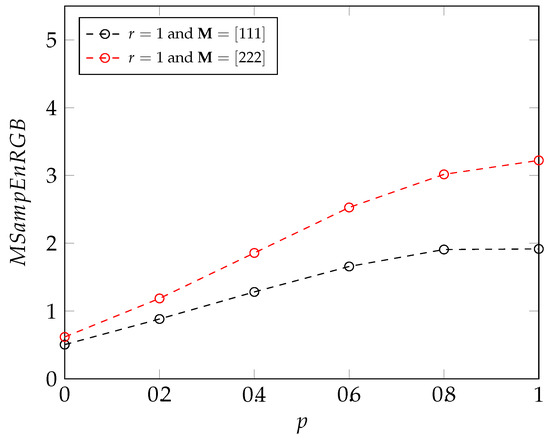
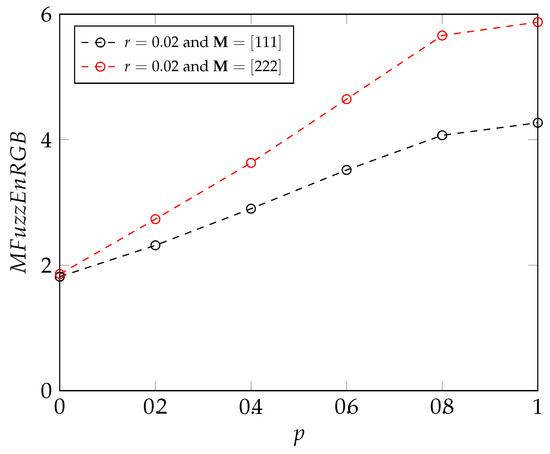
Deep Learning and Entropy-Based Texture Features for Color Image Classification
by
Emma Lhermitte, Mirvana Hilal, Ryan Furlong, Vincent O’Brien and Anne Humeau-Heurtier
Cited by 8 | Viewed by 3334
Abstract
In the domain of computer vision, entropy—defined as a measure of irregularity—has been proposed as an effective method for analyzing the texture of images. Several studies have shown that, with specific parameter tuning, entropy-based approaches achieve high accuracy in terms of classification results
[...] Read more.
In the domain of computer vision, entropy—defined as a measure of irregularity—has been proposed as an effective method for analyzing the texture of images. Several studies have shown that, with specific parameter tuning, entropy-based approaches achieve high accuracy in terms of classification results for texture images, when associated with machine learning classifiers. However, few entropy measures have been extended to studying color images. Moreover, the literature is missing comparative analyses of entropy-based and modern deep learning-based classification methods for RGB color images. In order to address this matter, we first propose a new entropy-based measure for RGB images based on a multivariate approach. This multivariate approach is a bi-dimensional extension of the methods that have been successfully applied to multivariate signals (unidimensional data). Then, we compare the classification results of this new approach with those obtained from several deep learning methods. The entropy-based method for RGB image classification that we propose leads to promising results. In future studies, the measure could be extended to study other color spaces as well.
Full article
►▼
Show Figures
Open AccessArticle
Cross-Subject Emotion Recognition Using Fused Entropy Features of EEG
by
Xin Zuo, Chi Zhang, Timo Hämäläinen, Hanbing Gao, Yu Fu and Fengyu Cong
Cited by 6 | Viewed by 3135
Abstract
Emotion recognition based on electroencephalography (EEG) has attracted high interest in fields such as health care, user experience evaluation, and human–computer interaction (HCI), as it plays an important role in human daily life. Although various approaches have been proposed to detect emotion states
[...] Read more.
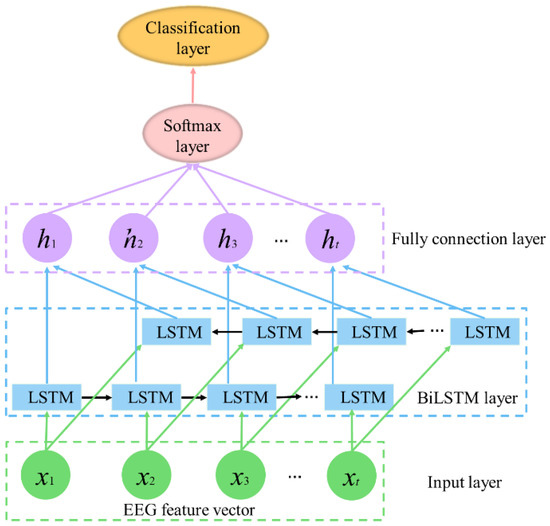
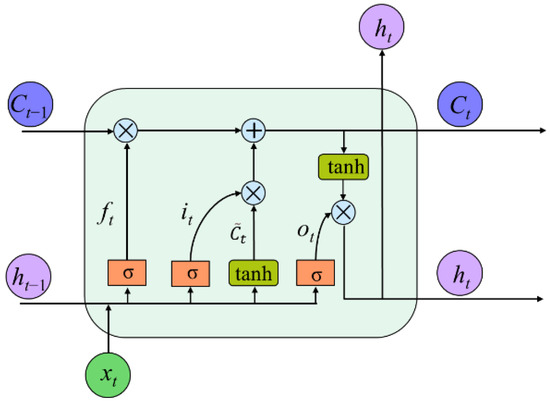
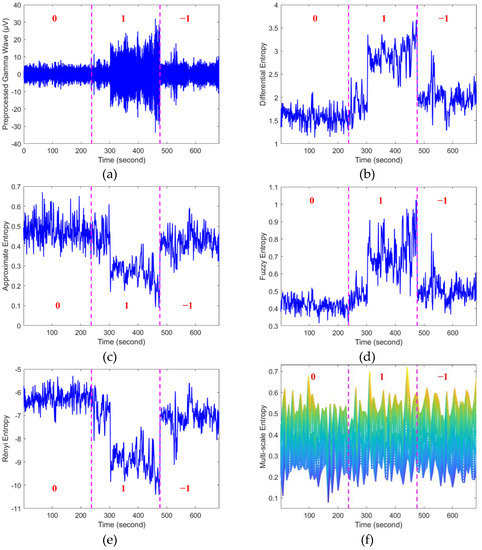
Emotion recognition based on electroencephalography (EEG) has attracted high interest in fields such as health care, user experience evaluation, and human–computer interaction (HCI), as it plays an important role in human daily life. Although various approaches have been proposed to detect emotion states in previous studies, there is still a need to further study the dynamic changes of EEG in different emotions to detect emotion states accurately. Entropy-based features have been proved to be effective in mining the complexity information in EEG in many areas. However, different entropy features vary in revealing the implicit information of EEG. To improve system reliability, in this paper, we propose a framework for EEG-based cross-subject emotion recognition using fused entropy features and a Bidirectional Long Short-term Memory (BiLSTM) network. Features including approximate entropy (AE), fuzzy entropy (FE), Rényi entropy (RE), differential entropy (DE), and multi-scale entropy (MSE) are first calculated to study dynamic emotional information. Then, we train a BiLSTM classifier with the inputs of entropy features to identify different emotions. Our results show that MSE of EEG is more efficient than other single-entropy features in recognizing emotions. The performance of BiLSTM is further improved with an accuracy of 70.05% using fused entropy features compared with that of single-type feature.
Full article
►▼
Show Figures
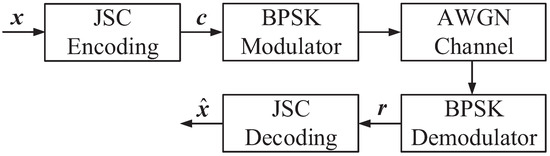
Open AccessArticle
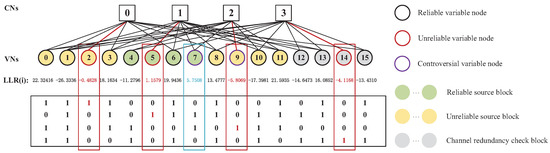
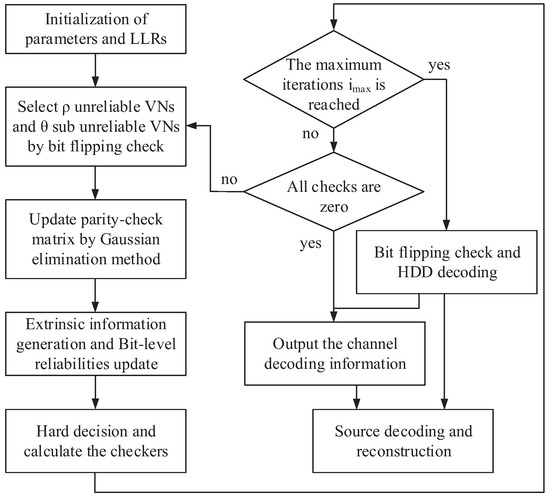
Controversial Variable Node Selection-Based Adaptive Belief Propagation Decoding Algorithm Using Bit Flipping Check for JSCC Systems
by
Hao Wang, Wei Zhang, Yizhe Jing, Yanyan Chang and Yanyan Liu
Cited by 1 | Viewed by 2202
Abstract
An end-to-end joint source–channel (JSC) encoding matrix and a JSC decoding scheme using the proposed bit flipping check (BFC) algorithm and controversial variable node selection-based adaptive belief propagation (CVNS-ABP) decoding algorithm are presented to improve the efficiency and reliability of the joint source–channel
[...] Read more.
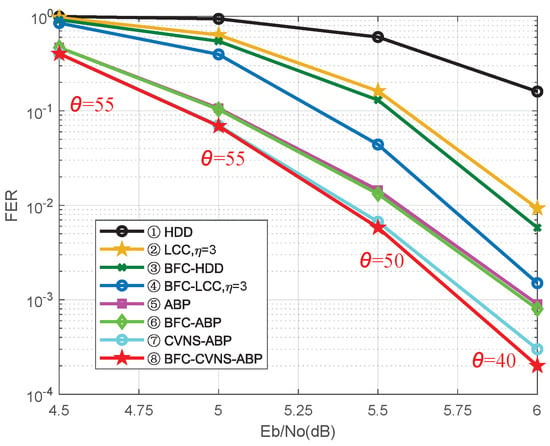
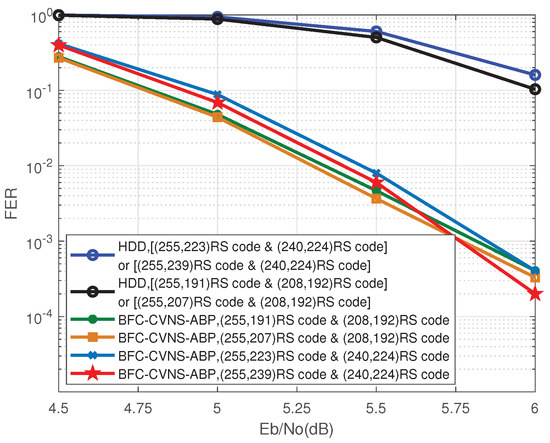
An end-to-end joint source–channel (JSC) encoding matrix and a JSC decoding scheme using the proposed bit flipping check (BFC) algorithm and controversial variable node selection-based adaptive belief propagation (CVNS-ABP) decoding algorithm are presented to improve the efficiency and reliability of the joint source–channel coding (JSCC) scheme based on double Reed–Solomon (RS) codes. The constructed coding matrix can realize source compression and channel coding of multiple sets of information data simultaneously, which significantly improves the coding efficiency. The proposed BFC algorithm uses channel soft information to select and flip the unreliable bits and then uses the redundancy of the source block to realize the error verification and error correction. The proposed CVNS-ABP algorithm reduces the influence of error bits on decoding by selecting error variable nodes (VNs) from controversial VNs and adding them to the sparsity of the parity-check matrix. In addition, the proposed JSC decoding scheme based on the BFC algorithm and CVNS-ABP algorithm can realize the connection of source and channel to improve the performance of JSC decoding. Simulation results show that the proposed BFC-based hard-decision decoding (BFC-HDD) algorithm (
= 1) and BFC-based low-complexity chase (BFC-LCC) algorithm (
= 1,
= 3) can achieve about 0.23 dB and 0.46 dB of signal-to-noise ratio (SNR) defined gain over the prior-art decoding algorithm at a frame error rate (FER) =
. Compared with the ABP algorithm, the proposed CVNS-ABP algorithm and BFC-CVNS-ABP algorithm achieve performance gains of 0.18 dB and 0.23 dB, respectively, at FER =
.
Full article
►▼
Show Figures
Open AccessArticle
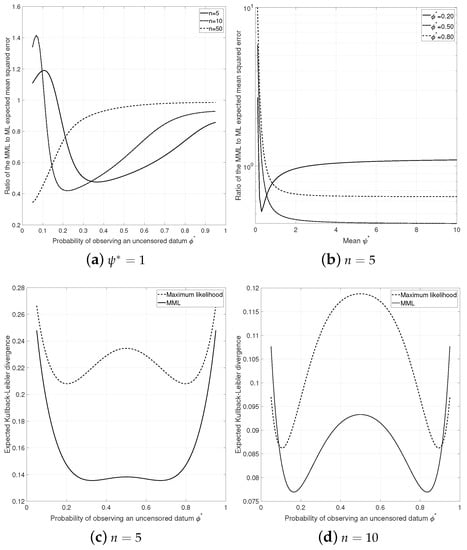
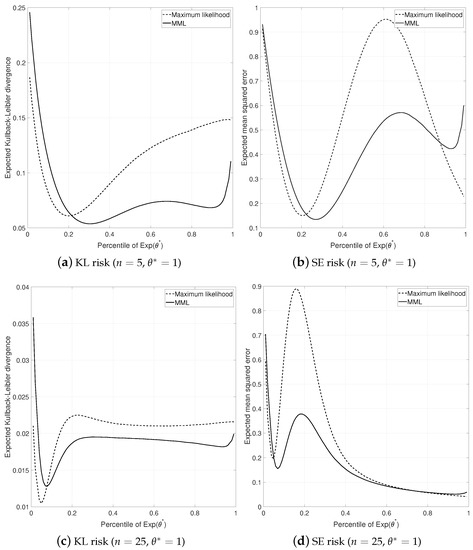
Minimum Message Length Inference of the Exponential Distribution with Type I Censoring
by
Enes Makalic and Daniel Francis Schmidt
Cited by 2 | Viewed by 1814
Abstract
Data with censoring is common in many areas of science and the associated statistical models are generally estimated with the method of maximum likelihood combined with a model selection criterion such as Akaike’s information criterion. This manuscript demonstrates how the information theoretic minimum
[...] Read more.
Data with censoring is common in many areas of science and the associated statistical models are generally estimated with the method of maximum likelihood combined with a model selection criterion such as Akaike’s information criterion. This manuscript demonstrates how the information theoretic minimum message length principle can be used to estimate statistical models in the presence of type I random and fixed censoring data. The exponential distribution with fixed and random censoring is used as an example to demonstrate the process where we observe that the minimum message length estimate of mean survival time has some advantages over the standard maximum likelihood estimate.
Full article
►▼
Show Figures
Open AccessArticle
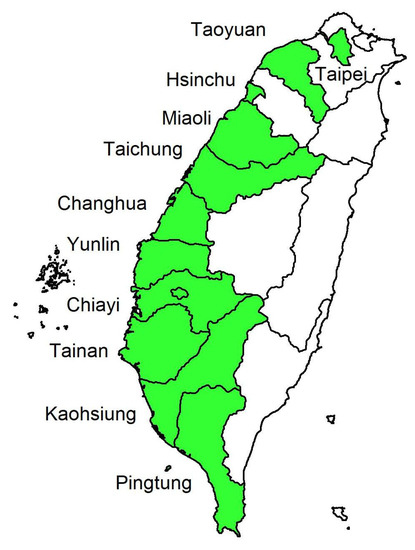
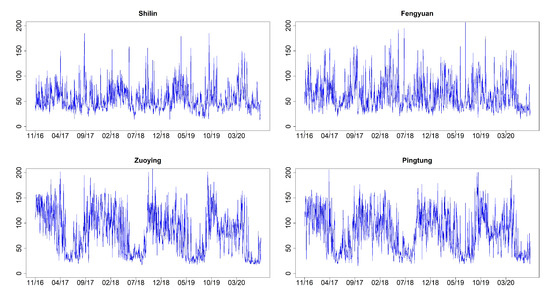
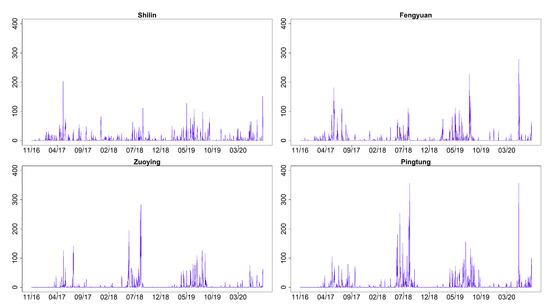
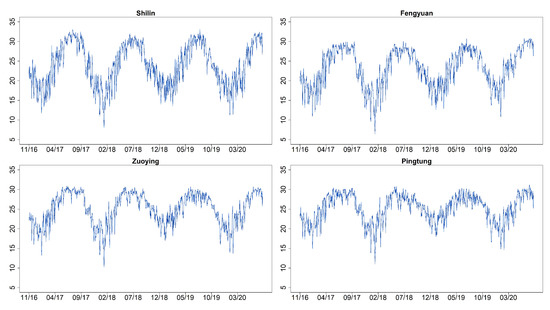
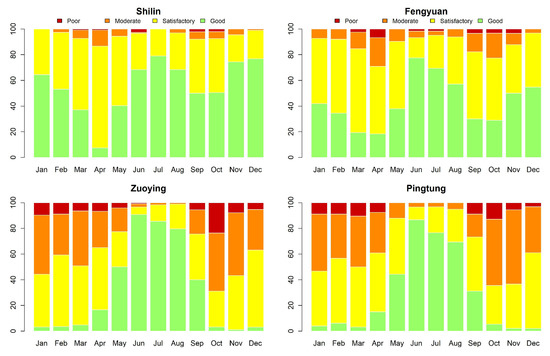
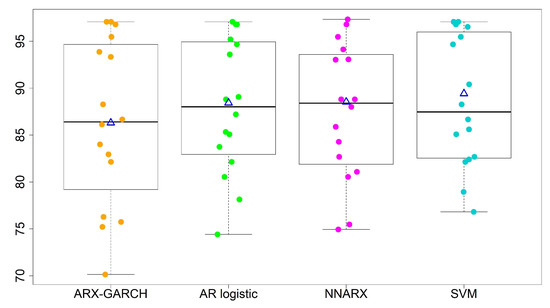
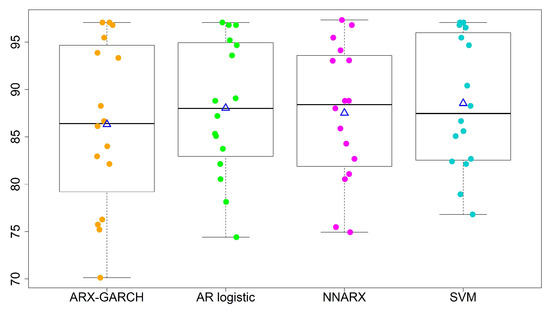
Ordinal Time Series Forecasting of the Air Quality Index
by
Cathy W. S. Chen and L. M. Chiu
Cited by 20 | Viewed by 4449
Abstract
This research models and forecasts daily AQI (air quality index) levels in 16 cities/counties of Taiwan, examines their AQI level forecast performance via a rolling window approach over a one-year validation period, including multi-level forecast classification, and measures the forecast accuracy rates. We
[...] Read more.
This research models and forecasts daily AQI (air quality index) levels in 16 cities/counties of Taiwan, examines their AQI level forecast performance via a rolling window approach over a one-year validation period, including multi-level forecast classification, and measures the forecast accuracy rates. We employ statistical modeling and machine learning with three weather covariates of daily accumulated precipitation, temperature, and wind direction and also include seasonal dummy variables. The study utilizes four models to forecast air quality levels: (1) an autoregressive model with exogenous variables and GARCH (generalized autoregressive conditional heteroskedasticity) errors; (2) an autoregressive multinomial logistic regression; (3) multi-class classification by support vector machine (SVM); (4) neural network autoregression with exogenous variable (NNARX). These models relate to lag-1 AQI values and the previous day’s weather covariates (precipitation and temperature), while wind direction serves as an hour-lag effect based on the idea of nowcasting. The results demonstrate that autoregressive multinomial logistic regression and the SVM method are the best choices for AQI-level predictions regarding the high average and low variation accuracy rates.
Full article
►▼
Show Figures
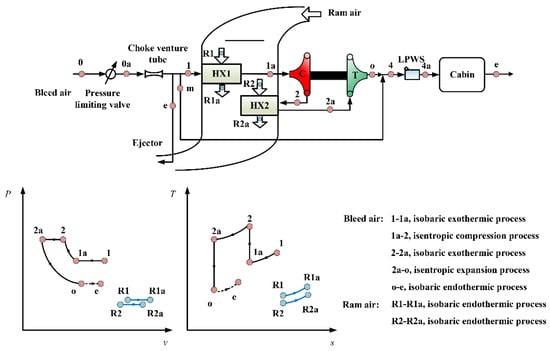
Open AccessEditor’s ChoiceArticle
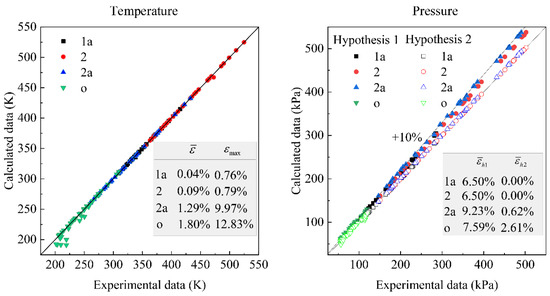
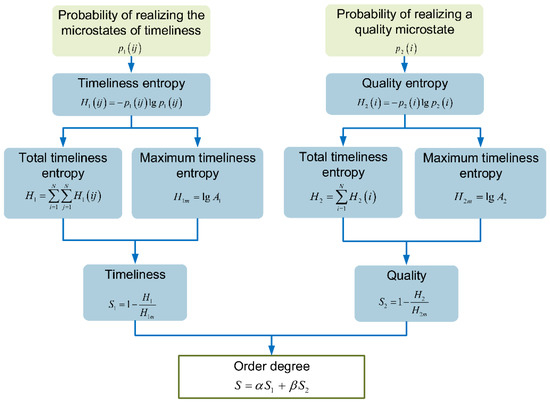
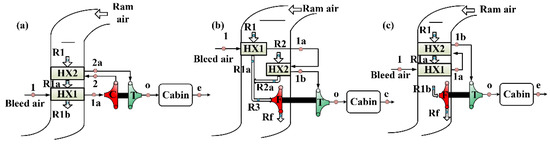
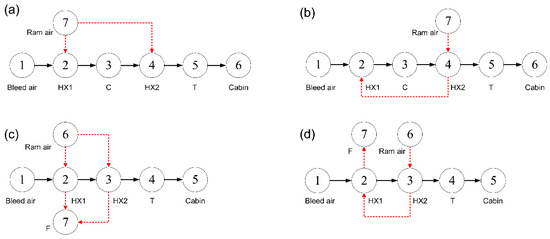
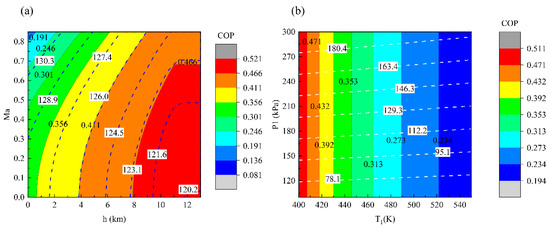
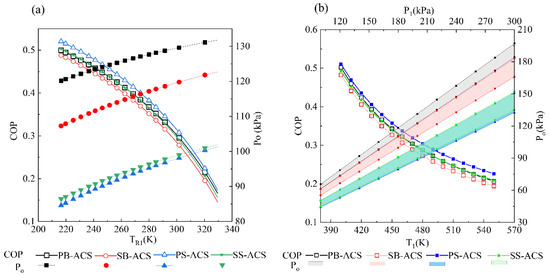
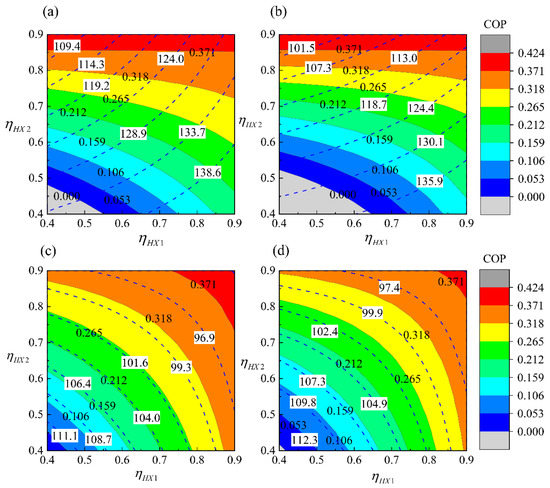
Influences of Different Architectures on the Thermodynamic Performance and Network Structure of Aircraft Environmental Control System
by
Han Yang, Chunxin Yang, Xingjuan Zhang and Xiugan Yuan
Cited by 12 | Viewed by 3189
Abstract
The environmental control system (ECS) is one of the most important systems in the aircraft used to regulate the pressure, temperature and humidity of the air in the cabin. This study investigates the influences of different architectures on the thermal performance and network
[...] Read more.
The environmental control system (ECS) is one of the most important systems in the aircraft used to regulate the pressure, temperature and humidity of the air in the cabin. This study investigates the influences of different architectures on the thermal performance and network structure of ECS. The refrigeration and pressurization performances of ECS with four different architectures are analyzed and compared by the endoreversible thermodynamic analysis method, and their external and internal responses have also been discussed. The results show that the connection modes of the heat exchanger have minor effects on the performance of ECSs, but the influence of the air cycle machine is obvious. This study attempts to abstract the ECS as a network structure based on the graph theory, and use entropy in information theory for quantitative evaluation. The results provide a theoretical basis for the design of ECS and facilitate engineers to make reliable decisions.
Full article
►▼
Show Figures
Open AccessArticle
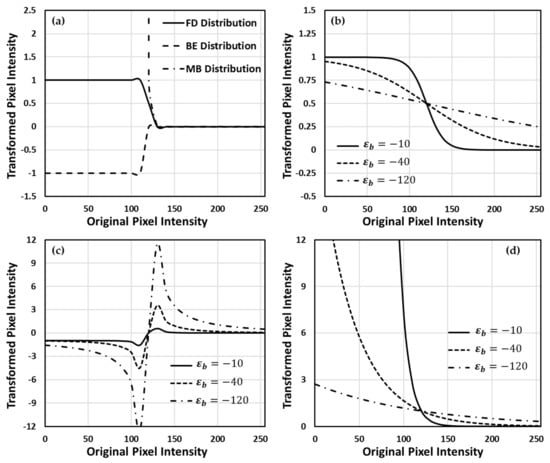
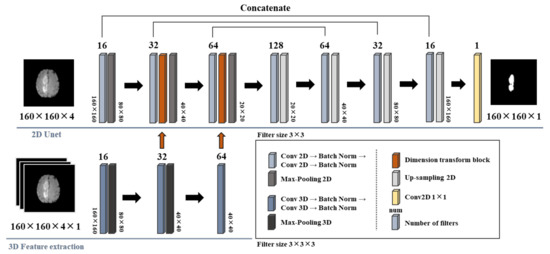
Computational Complexity Reduction of Neural Networks of Brain Tumor Image Segmentation by Introducing Fermi–Dirac Correction Functions
by
Yen-Ling Tai, Shin-Jhe Huang, Chien-Chang Chen and Henry Horng-Shing Lu
Cited by 11 | Viewed by 3473
Abstract
Nowadays, deep learning methods with high structural complexity and flexibility inevitably lean on the computational capability of the hardware. A platform with high-performance GPUs and large amounts of memory could support neural networks having large numbers of layers and kernels. However, naively pursuing
[...] Read more.
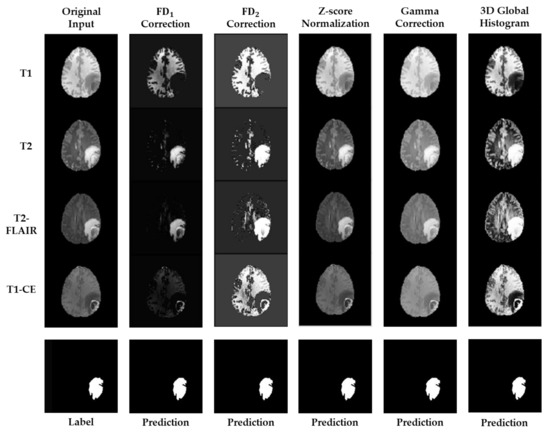
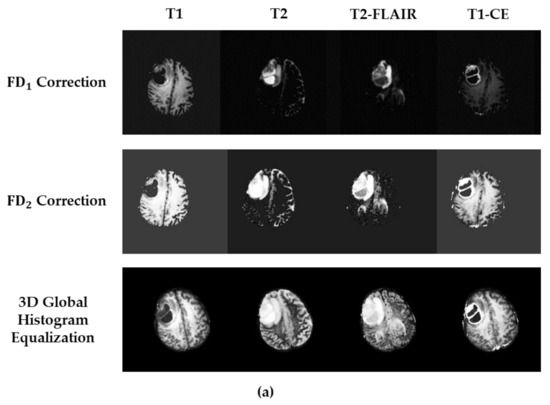
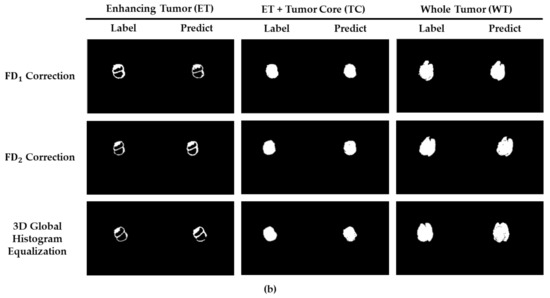
Nowadays, deep learning methods with high structural complexity and flexibility inevitably lean on the computational capability of the hardware. A platform with high-performance GPUs and large amounts of memory could support neural networks having large numbers of layers and kernels. However, naively pursuing high-cost hardware would probably drag the technical development of deep learning methods. In the article, we thus establish a new preprocessing method to reduce the computational complexity of the neural networks. Inspired by the band theory of solids in physics, we map the image space into a noninteraction physical system isomorphically and then treat image voxels as particle-like clusters. Then, we reconstruct the Fermi–Dirac distribution to be a correction function for the normalization of the voxel intensity and as a filter of insignificant cluster components. The filtered clusters at the circumstance can delineate the morphological heterogeneity of the image voxels. We used the BraTS 2019 datasets and the dimensional fusion U-net for the algorithmic validation, and the proposed Fermi–Dirac correction function exhibited comparable performance to other employed preprocessing methods. By comparing to the conventional z-score normalization function and the Gamma correction function, the proposed algorithm can save at least 38% of computational time cost under a low-cost hardware architecture. Even though the correction function of global histogram equalization has the lowest computational time among the employed correction functions, the proposed Fermi–Dirac correction function exhibits better capabilities of image augmentation and segmentation.
Full article
►▼
Show Figures
Open AccessArticle
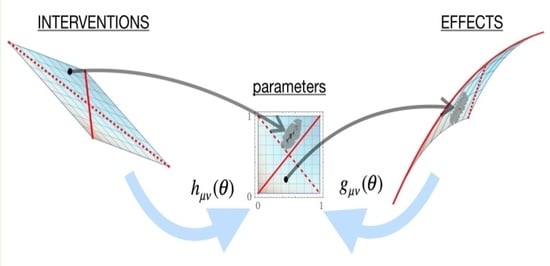
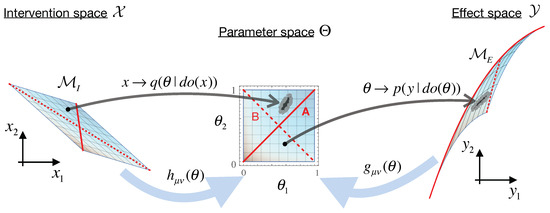
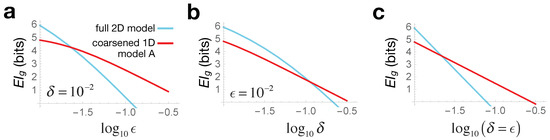
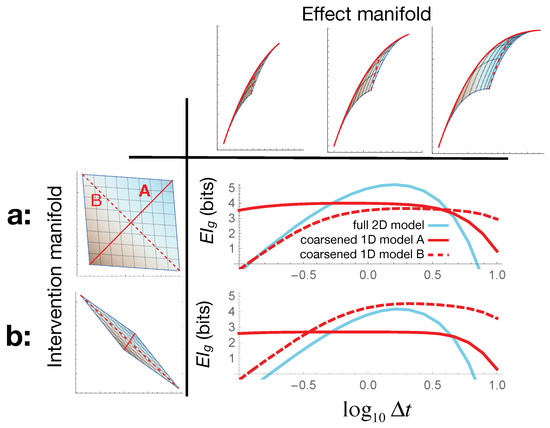
Causal Geometry
by
Pavel Chvykov and Erik Hoel
Cited by 4 | Viewed by 4471
Abstract
Information geometry has offered a way to formally study the efficacy of scientific models by quantifying the impact of model parameters on the predicted effects. However, there has been little formal investigation of causation in this framework, despite causal models being a fundamental
[...] Read more.
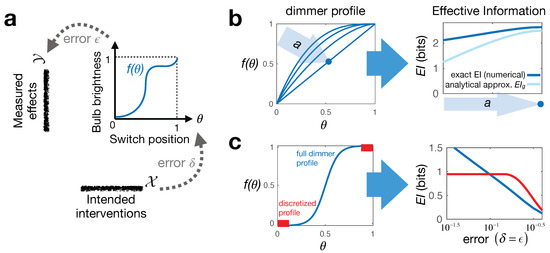
Information geometry has offered a way to formally study the efficacy of scientific models by quantifying the impact of model parameters on the predicted effects. However, there has been little formal investigation of causation in this framework, despite causal models being a fundamental part of science and explanation. Here, we introduce causal geometry, which formalizes not only how outcomes are impacted by parameters, but also how the parameters of a model can be intervened upon. Therefore, we introduce a geometric version of “effective information”—a known measure of the informativeness of a causal relationship. We show that it is given by the matching between the space of effects and the space of interventions, in the form of their geometric congruence. Therefore, given a fixed intervention capability, an effective causal model is one that is well matched to those interventions. This is a consequence of “causal emergence,” wherein macroscopic causal relationships may carry more information than “fundamental” microscopic ones. We thus argue that a coarse-grained model may, paradoxically, be more informative than the microscopic one, especially when it better matches the scale of accessible interventions—as we illustrate on toy examples.
Full article
►▼
Show Figures
Open AccessArticle
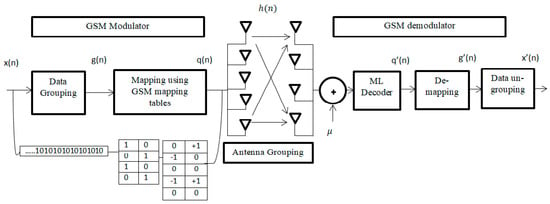
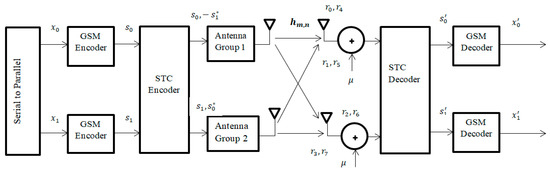
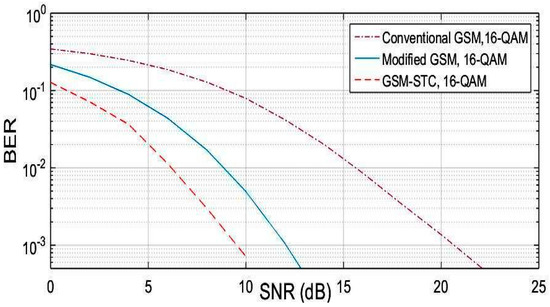
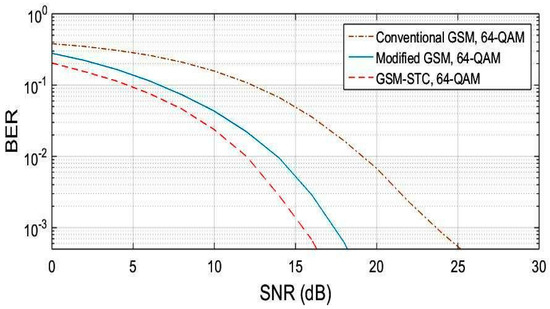
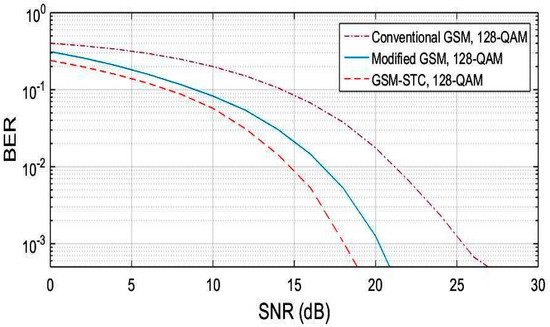
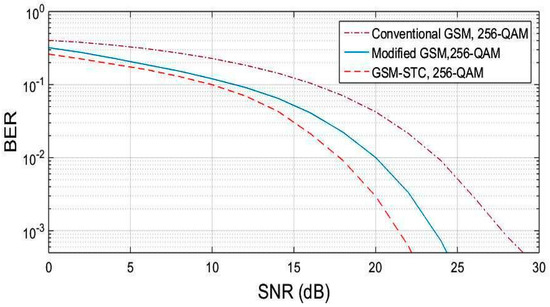
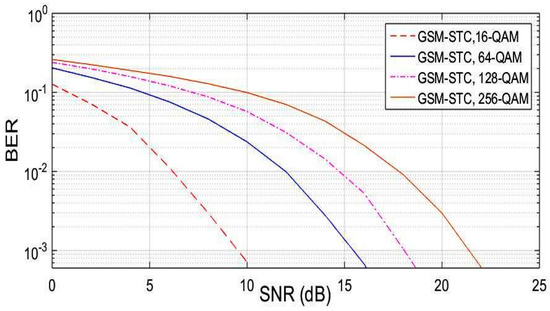
A Generalized Spatial Modulation System Using Massive MIMO Space Time Coding Antenna Grouping
by
Amira I. Zaki, Mahmoud Nassar, Moustafa H. Aly and Waleed K. Badawi
Cited by 6 | Viewed by 3814
Abstract
Massive multiple input multiple output (MIMO), also known as a very large-scale MIMO, is an emerging technology in wireless communications that increases capacity compared to MIMO systems. The massive MIMO communication technique is currently forming a major part of ongoing research. The main
[...] Read more.
Massive multiple input multiple output (MIMO), also known as a very large-scale MIMO, is an emerging technology in wireless communications that increases capacity compared to MIMO systems. The massive MIMO communication technique is currently forming a major part of ongoing research. The main issue for massive MIMO improvements depends on the number of transmitting antennas to increase the data rate and minimize bit error rate (BER). To enhance the data rate and BER, new coding and modulation techniques are required. In this paper, a generalized spatial modulation (GSM) with antenna grouping space time coding technique (STC) is proposed. The proposed GSM-STC technique is based on space time coding of two successive GSM-modulated data symbols on two subgroups of antennas to improve data rate and to minimize BER. Moreover, the proposed GSM-STC system can offer spatial diversity gains and can also increase the reliability of the wireless channel by providing replicas of the received signal. The simulation results show that GSM-STC achieves better performance compared to conventional GSM techniques in terms of data rate and BER, leading to good potential for massive MIMO by using subgroups of antennas.
Full article
►▼
Show Figures
Open AccessArticle
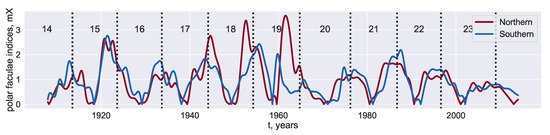
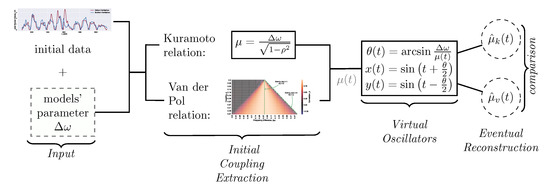
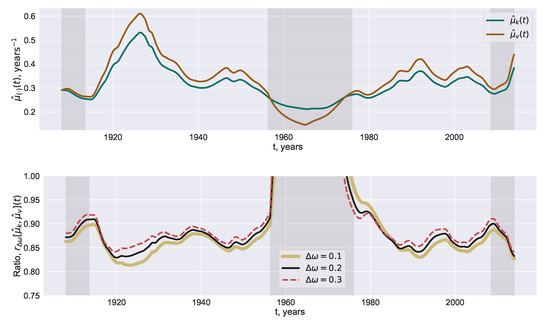
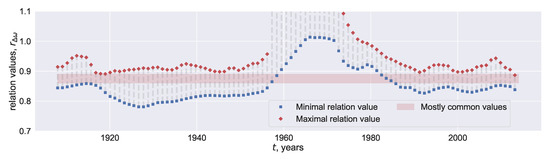
Dynamics of Phase Synchronization between Solar Polar Magnetic Fields Assessed with Van Der Pol and Kuramoto Models
by
Anton Savostianov, Alexander Shapoval and Mikhail Shnirman
Cited by 5 | Viewed by 2819
Abstract
We establish the similarity in two model-based reconstructions of the coupling between the polar magnetic fields of the Sun represented by the solar faculae time series. The reconstructions are inferred from the pair of the coupled oscillators modelled with the Van der Pol
[...] Read more.
We establish the similarity in two model-based reconstructions of the coupling between the polar magnetic fields of the Sun represented by the solar faculae time series. The reconstructions are inferred from the pair of the coupled oscillators modelled with the Van der Pol and Kuramoto equations. They are associated with the substantial simplification of solar dynamo models and, respectively, a simple ad hoc model reproducing the phenomenon of synchronization. While the polar fields are synchronized, both of the reconstruction procedures restore couplings, which attain moderate values and follow each other rather accurately as the functions of time. We also estimate the evolution of the phase difference between the polar fields and claim that they tend to move apart more quickly than approach each other.
Full article
►▼
Show Figures
Open AccessArticle
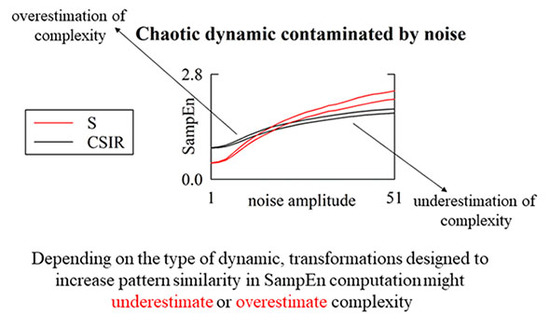
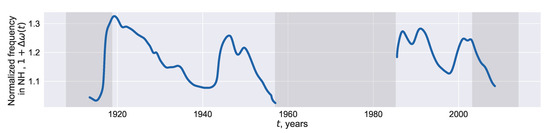
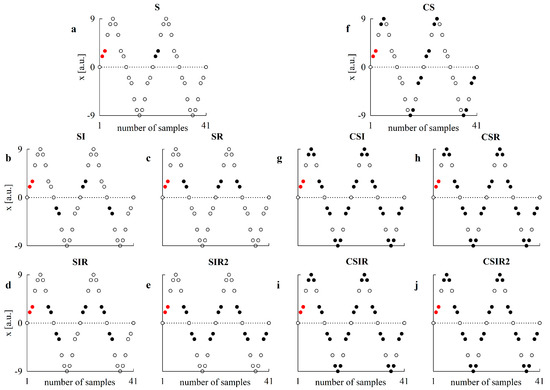
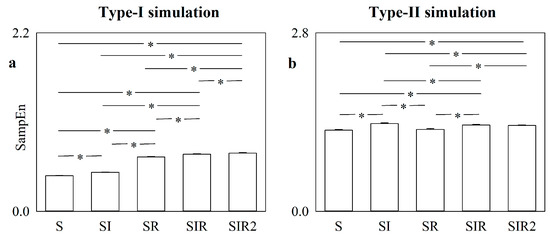
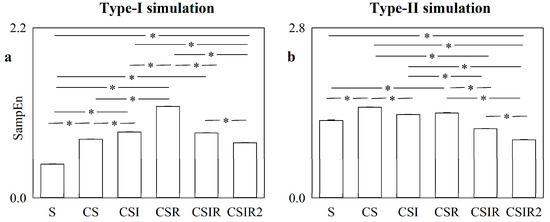
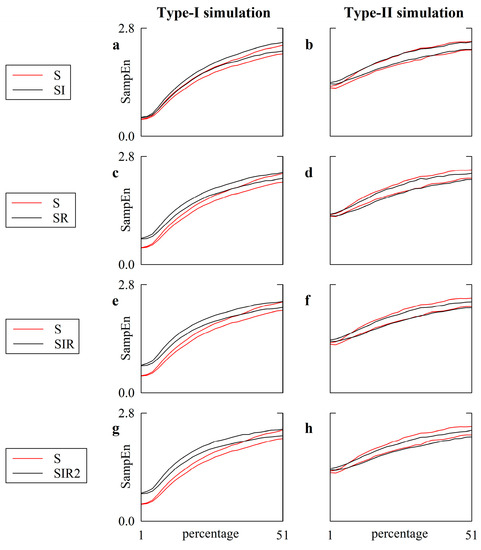
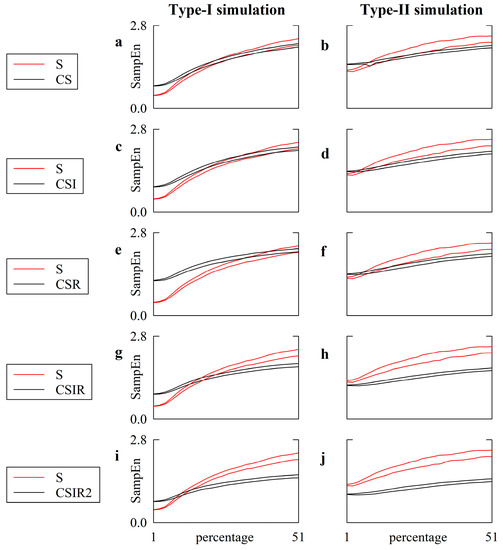
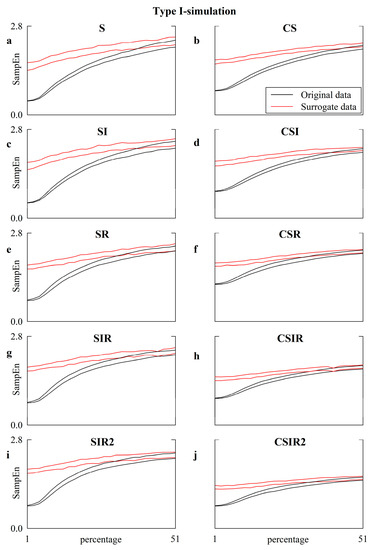
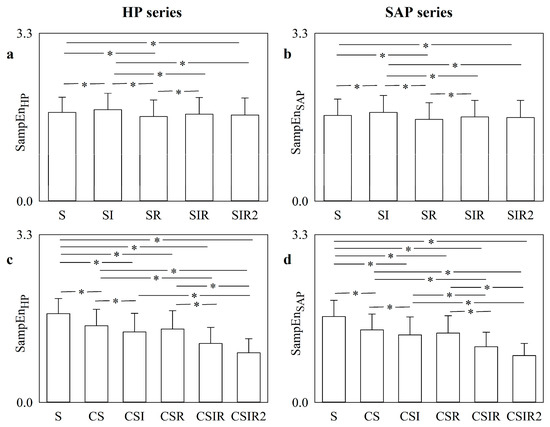
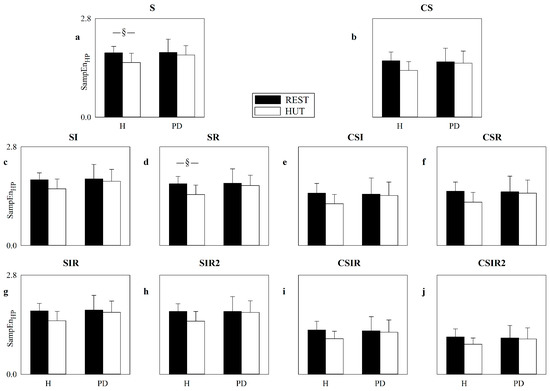
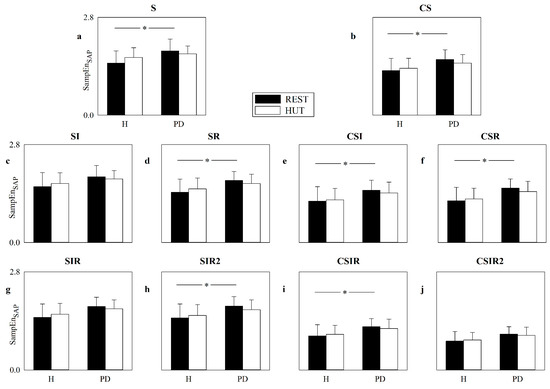
Are Strategies Favoring Pattern Matching a Viable Way to Improve Complexity Estimation Based on Sample Entropy?
by
Alberto Porta, José Fernando Valencia, Beatrice Cairo, Vlasta Bari, Beatrice De Maria, Francesca Gelpi, Franca Barbic and Raffaello Furlan
Cited by 4 | Viewed by 3180
Abstract
It has been suggested that a viable strategy to improve complexity estimation based on the assessment of pattern similarity is to increase the pattern matching rate without enlarging the series length. We tested this hypothesis over short simulations of nonlinear deterministic and linear
[...] Read more.
It has been suggested that a viable strategy to improve complexity estimation based on the assessment of pattern similarity is to increase the pattern matching rate without enlarging the series length. We tested this hypothesis over short simulations of nonlinear deterministic and linear stochastic dynamics affected by various noise amounts. Several transformations featuring a different ability to increase the pattern matching rate were tested and compared to the usual strategy adopted in sample entropy (SampEn) computation. The approaches were applied to evaluate the complexity of short-term cardiac and vascular controls from the beat-to-beat variability of heart period (HP) and systolic arterial pressure (SAP) in 12 Parkinson disease patients and 12 age- and gender-matched healthy subjects at supine resting and during head-up tilt. Over simulations, the strategies estimated a larger complexity over nonlinear deterministic signals and a greater regularity over linear stochastic series or deterministic dynamics importantly contaminated by noise. Over short HP and SAP series the techniques did not produce any practical advantage, with an unvaried ability to discriminate groups and experimental conditions compared to the traditional SampEn. Procedures designed to artificially increase the number of matches are of no methodological and practical value when applied to assess complexity indexes.
Full article
►▼
Show Figures








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}