
Photonic Matrix Computing: From Fundamentals to Applications


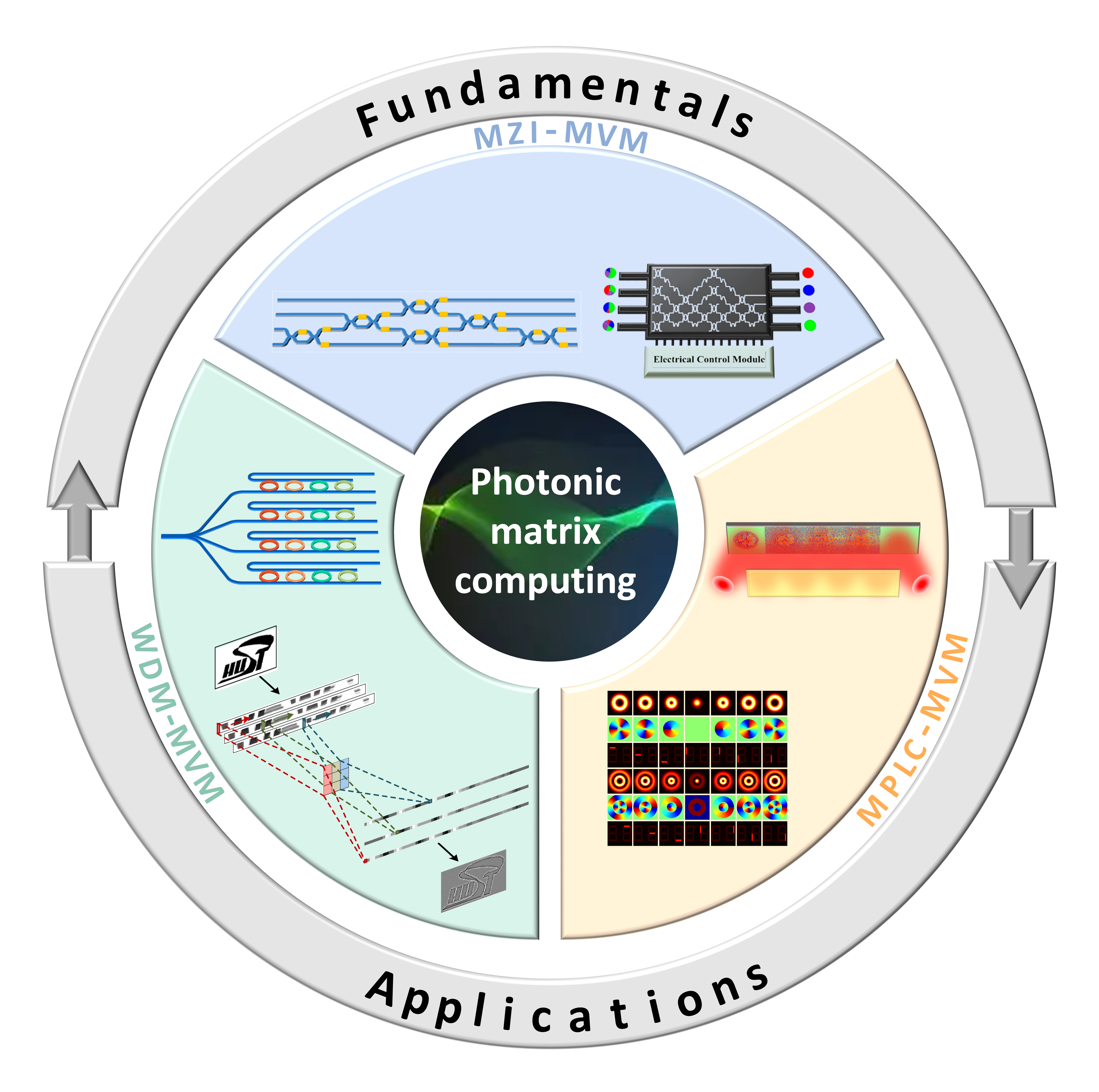
Abstract
: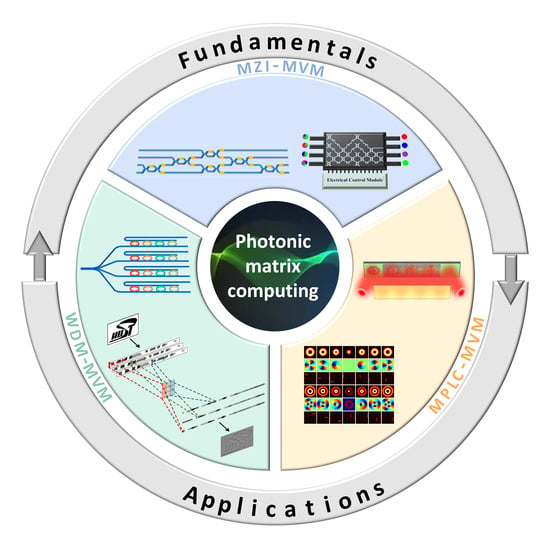
1. Introduction
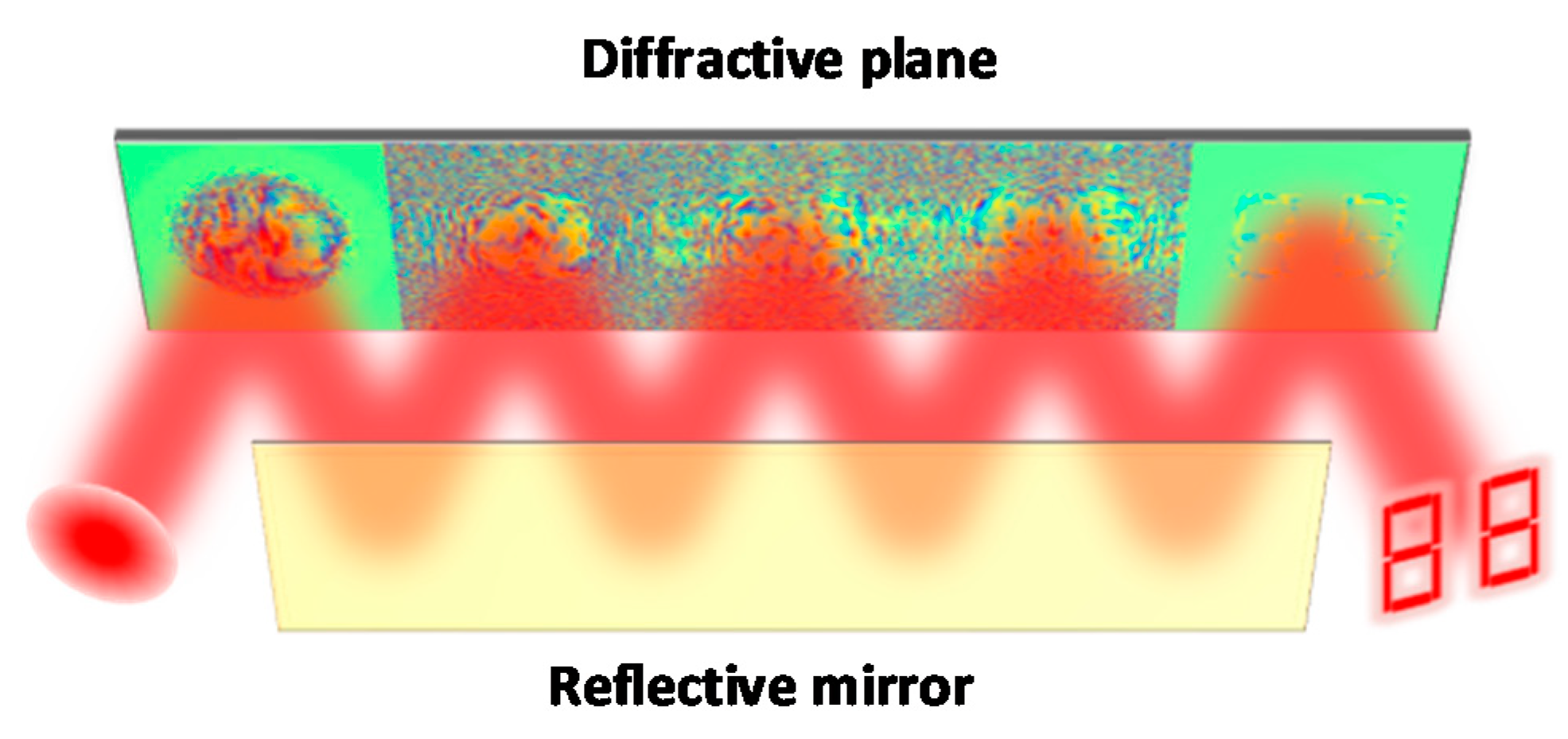
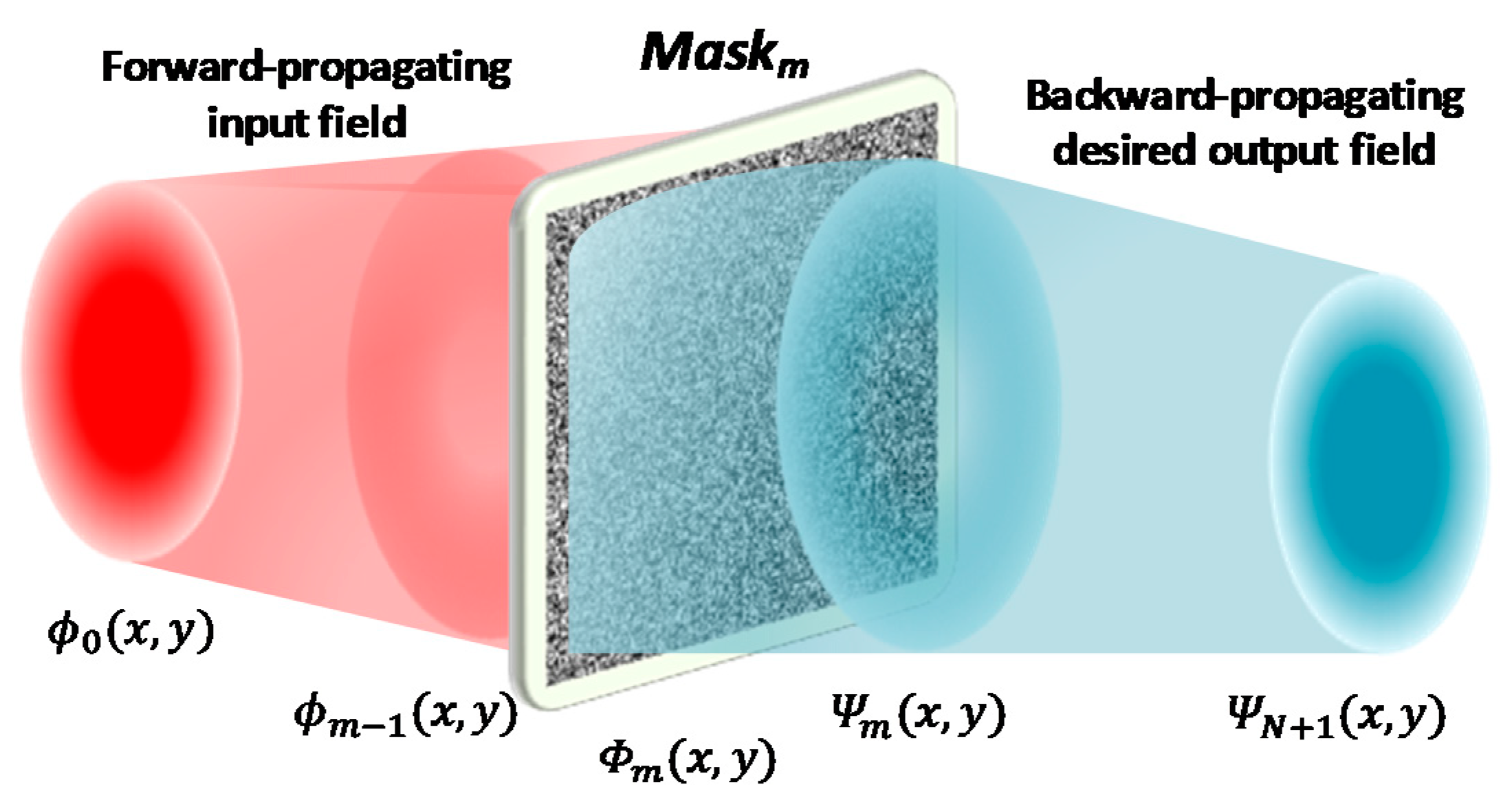
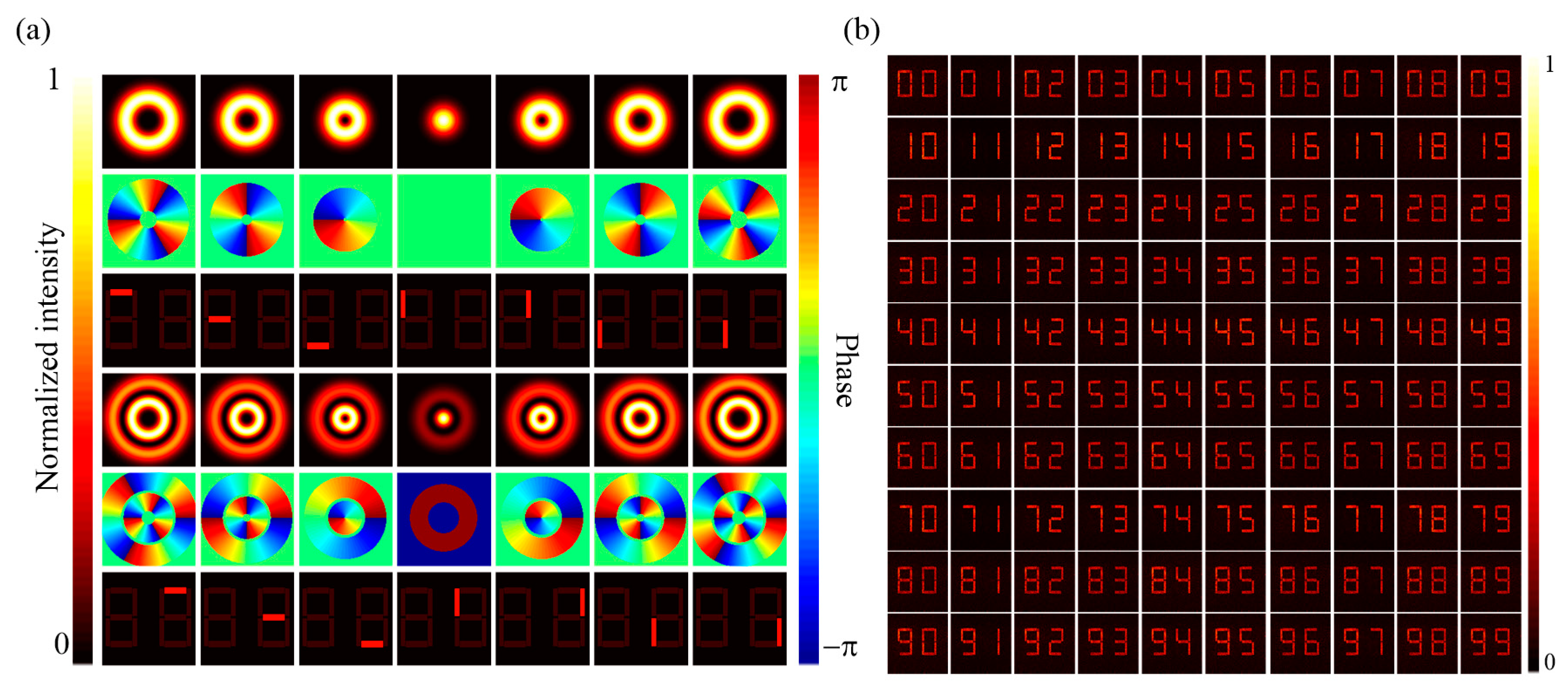
2. MPLC Matrix Core
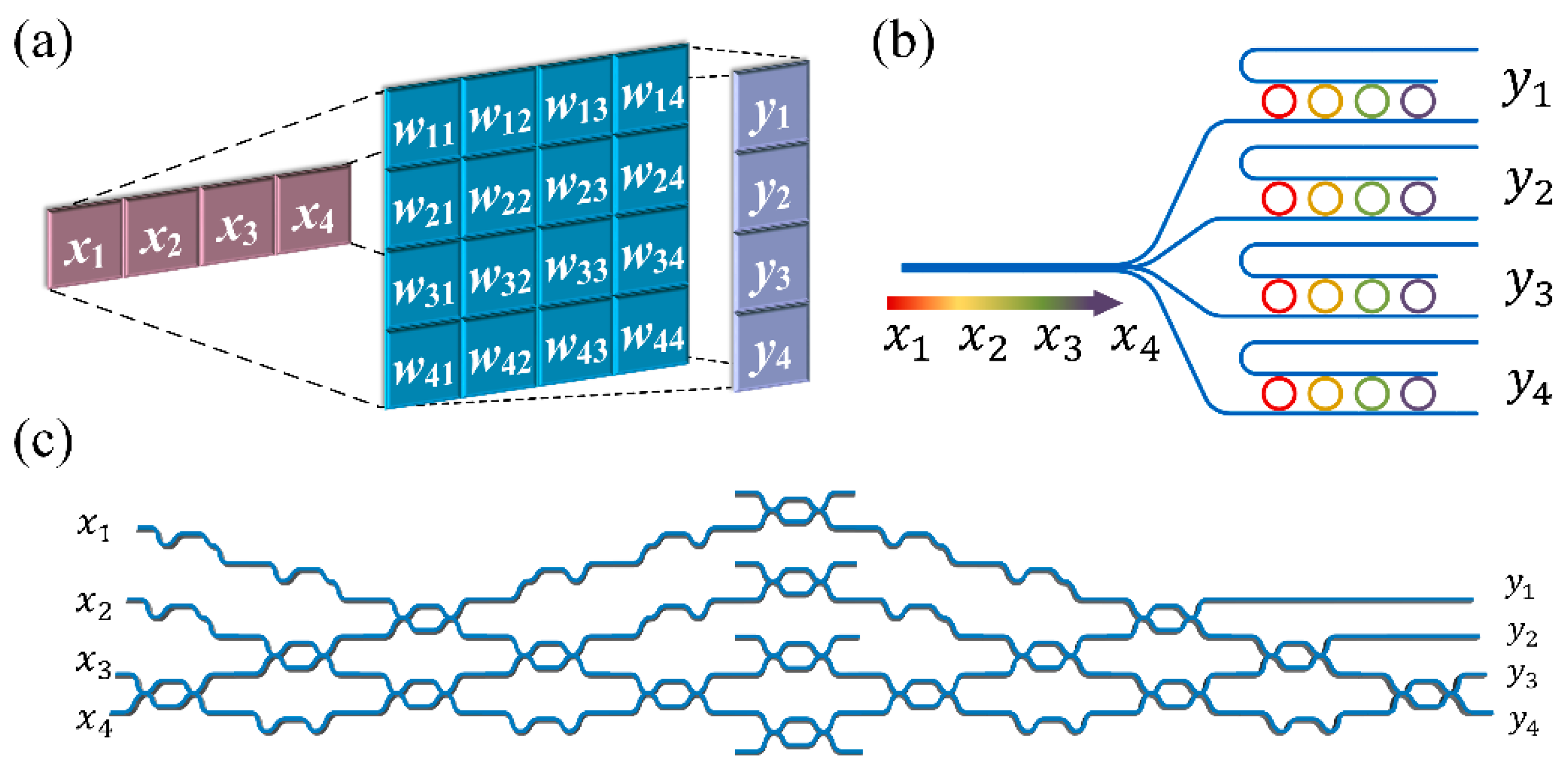
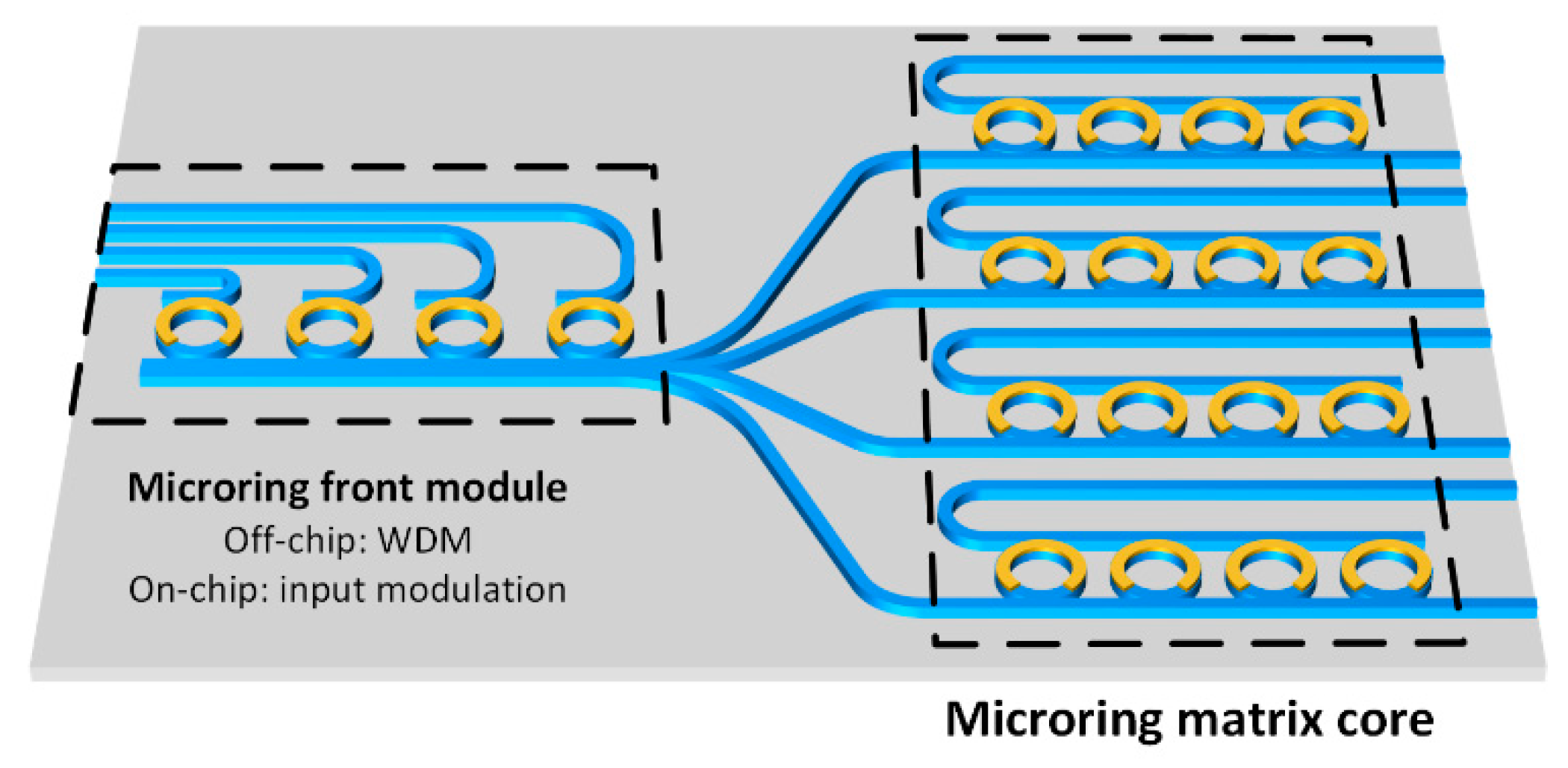
3. Microring Matrix Core
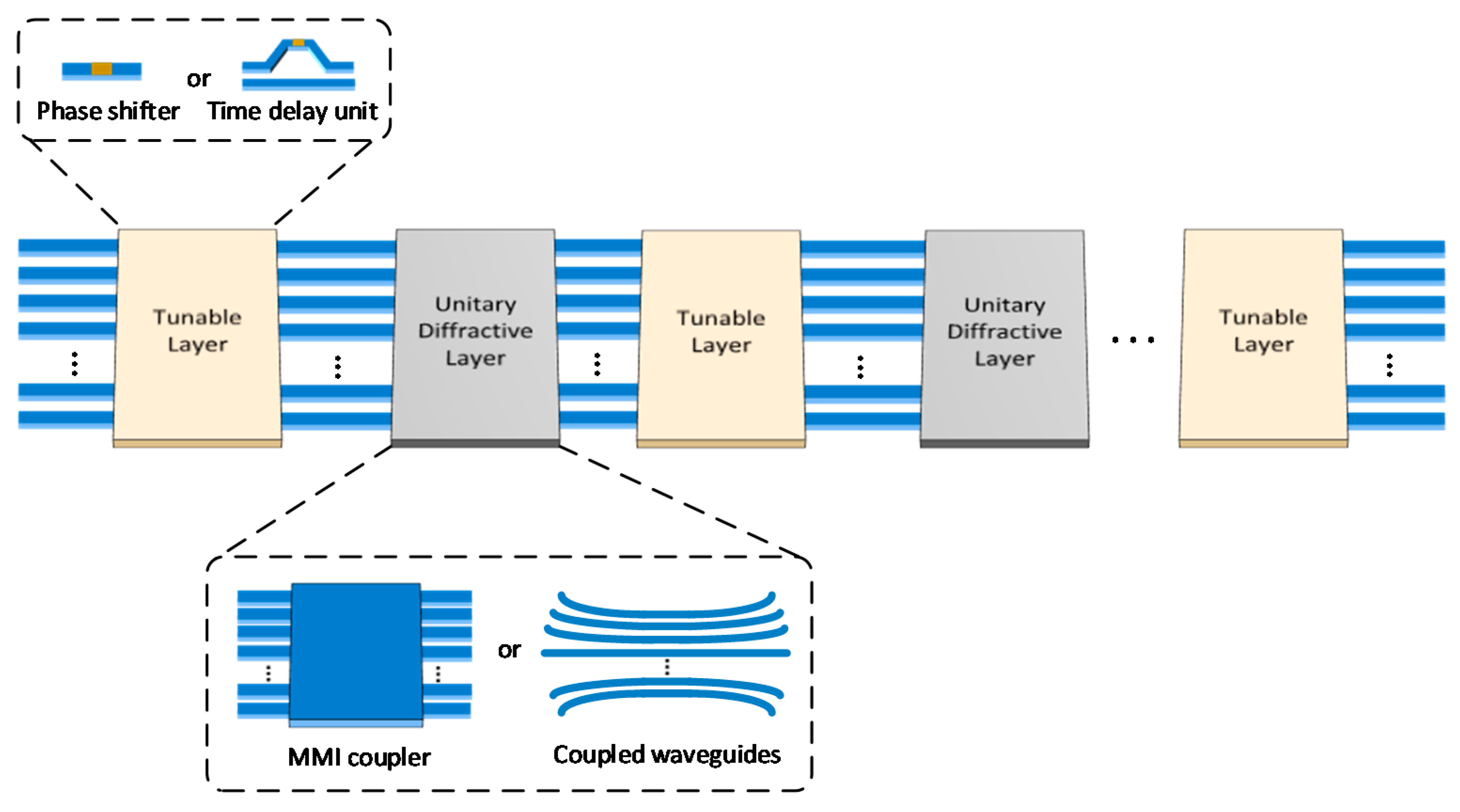
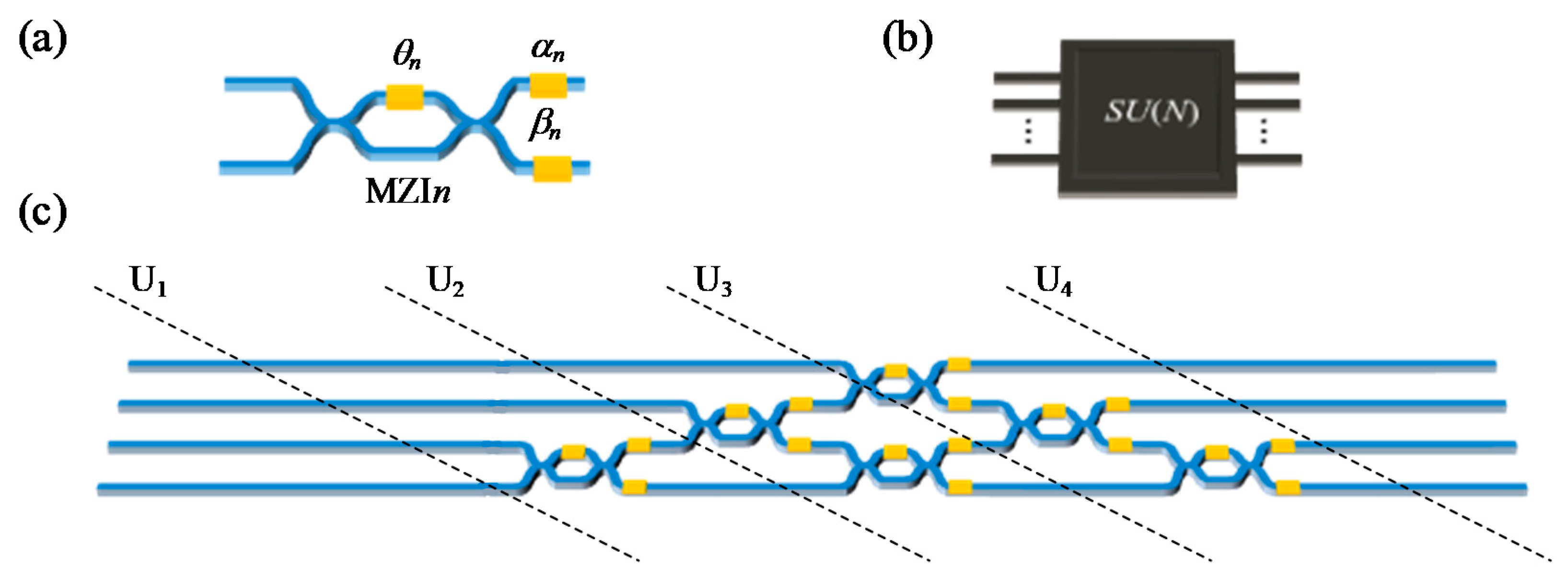
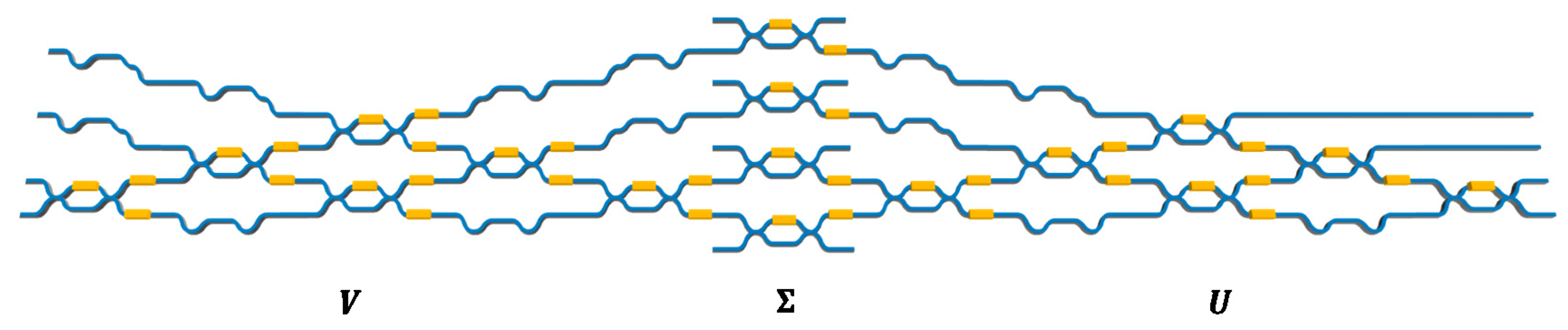
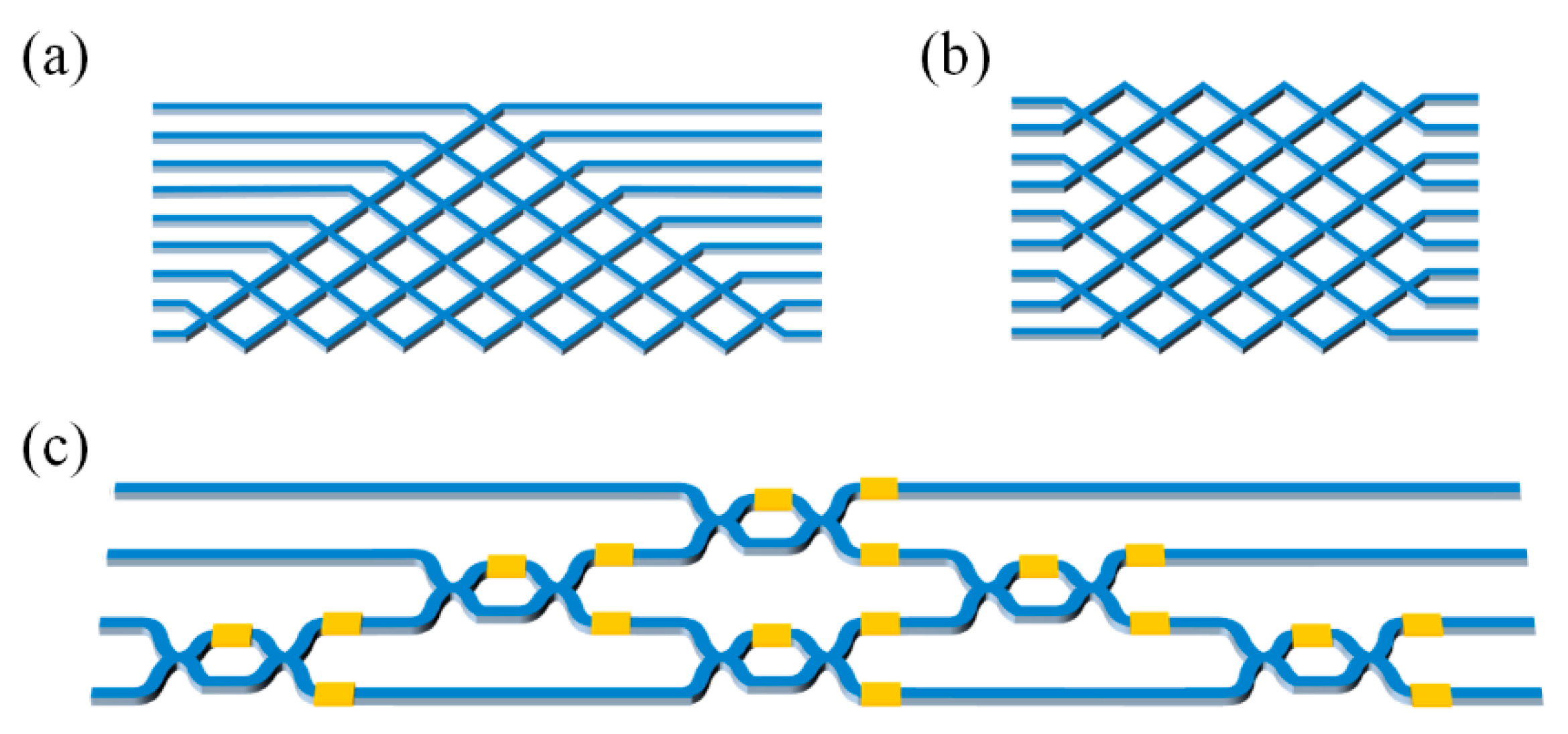
4. MZI Matrix Core
5. Discussion and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lundstrom, M. Moore’s law forever? Science 2003, 299, 210–211. [Google Scholar] [CrossRef] [PubMed]
- Shastri, B.J.; Tait, A.N.; Ferreira de Lima, T.; Pernice, W.H.P.; Bhaskaran, H.; Wright, C.D.; Prucnal, P.R. Photonics for artificial intelligence and neuromorphic computing. Nat. Photonics 2021, 15, 102–114. [Google Scholar] [CrossRef]
- Saade, A.; Caltagirone, F.; Carron, I.; Daudet, L.; Dremeau, A.; Gigan, S.; Krzakala, F. Random projections through multiple optical scattering: Approximating kernels at the speed of light. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016; pp. 6215–6219. [Google Scholar]
- Liutkus, A.; Martina, D.; Popoff, S.; Chardon, G.; Katz, O.; Lerosey, G.; Gigan, S.; Daudet, L.; Carron, I. Imaging with nature: Compressive imaging using a multiply scattering medium. Sci. Rep. 2014, 4, 5552. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, X.; Rivenson, Y.; Yardimei, N.T.; Veli, M.; Luo, Y.; Jarrahi, M.; Ozcan, A. All-optical machine learning using diffractive deep neural networks. Science 2018, 361, 1004–1008. [Google Scholar] [CrossRef] [Green Version]
- Chang, J.; Sitzmann, V.; Dun, X.; Heidrich, W.; Wetzstein, G. Hybrid optical-electronic convolutional neural networks with optimized diffractive optics for image classification. Sci. Rep. 2018, 8, 12324. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cartwright, S. New optical matrix-vector multiplier. Appl. Opt. 1984, 23, 1683–1684. [Google Scholar] [CrossRef]
- Bocker, R.P.; Clayton, S.R.; Bromley, K. Electrooptical matrix multiplication using the twos complement arithmetic for improved accuracy. Appl. Opt. 1983, 22, 2019–2021. [Google Scholar]
- Athale, R.A.; Collins, W.C. Optical matrix-matrix multiplier based on outer product decomposition. Appl. Opt. 1982, 21, 2089–2090. [Google Scholar] [CrossRef]
- Shuiying, X.; Yanan, H.; Ziwei, S.; Xingxing, G.; Yahui, Z.; Zhenxing, R.; Suhong, W.; Yuanting, M.; Weiwen, Z.; Bowen, M.; et al. A review: Photonics devices, architectures, and algorithms for optical neural computing. J. Semicond. 2021, 42, 023105. [Google Scholar]
- Li, X.; Zhang, G.; Huang, H.H.; Wang, Z.; Zheng, W. Performance Analysis of GPU-based Convolutional Neural Networks. In Proceedings of the 45th International Conference on Parallel Processing-ICPP, Philadelphia, PA, USA, 16–19 August 2016; pp. 67–76. [Google Scholar]
- Goodman, J.W.; Dias, A.R.; Woody, L.M. Fully parallel, high-speed incoherent optical method for performing discrete Fourier transforms. Opt. Lett. 1978, 2, 1–3. [Google Scholar] [CrossRef]
- Veli, M.; Mengu, D.; Yardimci, N.T.; Luo, Y.; Li, J.; Rivenson, Y.; Jarrahi, M.; Ozcan, A. Terahertz pulse shaping using diffractive surfaces. Nat. Comm. 2021, 12, 37. [Google Scholar] [CrossRef] [PubMed]
- Wen, H.; Liu, H.; Zhang, Y.; Zhang, P.; Li, G. Mode demultiplexing hybrids for mode-division multiplexing coherent receivers. Photon. Res. 2019, 7, 917–925. [Google Scholar] [CrossRef]
- Wen, H.; Liu, H.; Zhang, Y.; Sampson, R.; Fan, S.; Li, G. Scalable Hermite-Gaussian mode-demultiplexing hybrids. Opt. Lett. 2020, 45, 2219–2222. [Google Scholar] [CrossRef] [PubMed]
- Fontaine, N.K.; Ryf, R.; Chen, H.; Neilson, D.T.; Kim, K.; Carpenter, J. Laguerre-Gaussian mode sorter. Nat. Comm. 2019, 10, 1865. [Google Scholar] [CrossRef] [PubMed]
- Bueno, J.; Maktoobi, S.; Froehly, L.; Fischer, I.; Jacquot, M.; Larger, L.; Brunner, D. Reinforcement learning in a large-scale photonic recurrent neural network. Optica 2018, 5, 756–760. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Mengu, D.; Luo, Y.; Rivenson, Y.; Ozcan, A. Class-specific differential detection in diffractive optical neural networks improves inference accuracy. Adv. Photon. 2019, 1, 046001. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Lin, X.; Wu, J.; Chen, Y.; Xie, H.; Li, Y.; Fan, J.; Wu, H.; Fang, L.; Dai, Q. Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit. Nat. Photonics 2021, 15, 367–373. [Google Scholar] [CrossRef]
- Labroille, G.; Denolle, B.; Jian, P.; Genevaux, P.; Treps, N.; Morizur, J.-F. Efficient and mode selective spatial mode multiplexer based on multi-plane light conversion. Opt. Express 2014, 22, 15599–15607. [Google Scholar] [CrossRef] [PubMed]
- Sakamaki, Y.; Hashimoto, T.; Takahashi, H. New optical waveguide design based on wavefront matching method. J. Lightwave Technol. 2007, 25, 3511–3518. [Google Scholar] [CrossRef]
- Wei, H.; Huang, G.; Wei, X.; Sun, Y.; Wang, H. Comment on “All-optical machine learning using diffractive deep neural networks”. arXiv 2018, arXiv:1809.08360. Available online: https://arxiv.org/abs/1809.08360 (accessed on 22 June 2021).
- Rahman, M.S.S.; Li, J.X.; Mengu, D.; Rivenson, Y.; Ozcan, A. Ensemble learning of diffractive optical networks. Light-Sci. Appl. 2021, 10, 14. [Google Scholar] [CrossRef]
- Tang, R.; Tanemura, T.; Nakano, Y. Integrated reconfigurable unitary optical mode converter using MMI couplers. IEEE Photonics Technol. Lett. 2017, 29, 971–974. [Google Scholar] [CrossRef]
- Saygin, M.Y.; Kondratyev, I.V.; Dyakonov, I.V.; Mironov, S.A.; Straupe, S.S.; Kulik, S.P. Robust architecture for programmable universal unitaries. Phys. Rev. Lett. 2020, 124, 010501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Q.F.; Schmidt, B.; Pradhan, S.; Lipson, M. Micrometre-scale silicon electro-optic modulator. Nature 2005, 435, 325–327. [Google Scholar] [CrossRef] [PubMed]
- Dong, P.; Qian, W.; Liang, H.; Shafiiha, R.; Feng, N.-N.; Feng, D.; Zheng, X.; Krishnamoorthy, A.V.; Asghari, M. Low power and compact reconfigurable multiplexing devices based on silicon microring resonators. Opt. Express 2010, 18, 9852–9858. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Wang, J.; Zou, W. Optical patching scheme for optical convolutional neural networks based on wavelength-division multiplexing and optical delay lines. Opt. Lett. 2020, 45, 3689–3692. [Google Scholar] [CrossRef]
- Xu, S.F.; Wang, J.; Zou, W.W. Optical convolutional neural network with WDM-based optical patching and microring weighting banks. IEEE Photonics Technol. Lett. 2021, 33, 89–92. [Google Scholar] [CrossRef]
- Xu, L.; Hou, J.; Tang, H.; Yu, Y.; Yu, Y.; Shu, X.; Zhang, X. Silicon-on-insulator-based microwave photonic filter with widely adjustable bandwidth. Photon. Res. 2019, 7, 110–115. [Google Scholar] [CrossRef]
- Liu, X.; Yu, Y.; Tang, H.; Xu, L.; Dong, J.; Zhang, X. Silicon-on-insulator-based microwave photonic filter with narrowband and ultrahigh peak rejection. Opt. Lett. 2018, 43, 1359–1362. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Wang, X.; Gao, D.; Dong, J.; Zhang, X. On-chip programmable pulse processor employing cascaded MZI-MRR structure. Front. Optoelectron. 2019, 12, 148–156. [Google Scholar] [CrossRef]
- Qiang, Z.; Zhou, W.; Soref, R.A. Optical add-drop filters based on photonic crystal ring resonators. Opt. Express 2007, 15, 1823–1831. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Zhang, L.; Ji, R. On-chip optical matrix-vector multiplier. In Optics and Photonics for Information Processing Vii, Proceeding of the SPIE Optical Engineering + Applications, San Diego, CA, USA, 26 Septemeber 2013; Iftekharuddin, K.M., Awwal, A.A.S., Márquez, A., Eds.; SPIE: Bellingham, WA, USA, 2013; Volume 8855. [Google Scholar]
- Tait, A.N.; Wu, A.X.; Lima, T.F.d.; Zhou, E.; Shastri, B.J.; Nahmias, M.A.; Prucnal, P.R. Microring weight banks. IEEE J. Sel. Top. Quantum Electron. 2016, 22, 312–325. [Google Scholar] [CrossRef]
- Tait, A.N.; Nahmias, M.A.; Shastri, B.J.; Prucnal, P.R. Broadcast and weight: An integrated network for scalable photonic spike processing. J. Lightwave Technol. 2014, 32, 4029–4041. [Google Scholar] [CrossRef]
- Tait, A.N.; de Lima, T.F.; Zhou, E.; Wu, A.X.; Nahmias, M.A.; Shastri, B.J.; Prucnal, P.R. Neuromorphic photonic networks using silicon photonic weight banks. Sci. Rep. 2017, 7, 7430. [Google Scholar] [CrossRef]
- Tait, A.N.; de Lima, T.F.; Nahmias, M.A.; Shastri, B.J.; Prucnal, P.R. Continuous calibration of microring weights for analog optical networks. IEEE Photonics Technol. Lett. 2016, 28, 887–890. [Google Scholar] [CrossRef]
- Feldmann, J.; Youngblood, N.; Wright, C.D.; Bhaskaran, H.; Pernice, W.H.P. All-optical spiking neurosynaptic networks with self-learning capabilities. Nature 2019, 569, 208–214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feldmann, J.; Youngblood, N.; Karpov, M.; Gehring, H.; Li, X.; Stappers, M.; Le Gallo, M.; Fu, X.; Lukashchuk, A.; Raja, A.S.; et al. Parallel convolutional processing using an integrated photonic tensor core. Nature 2021, 589, 52–58. [Google Scholar] [CrossRef]
- Xu, X.; Tan, M.; Corcoran, B.; Wu, J.; Boes, A.; Nguyen, T.G.; Chu, S.T.; Little, B.E.; Hicks, D.G.; Morandotti, R.; et al. 11 TOPS photonic convolutional accelerator for optical neural networks. Nature 2021, 589, 44–51. [Google Scholar] [CrossRef] [PubMed]
- Liu, A.S.; Jones, R.; Liao, L.; Samara-Rubio, D.; Rubin, D.; Cohen, O.; Nicolaescu, R.; Paniccia, M. A high-speed silicon optical modulator based on a metal-oxide-semiconductor capacitor. Nature 2004, 427, 615–618. [Google Scholar] [CrossRef]
- Liao, L.; Samara-Rubio, D.; Morse, M.; Liu, A.S.; Hodge, D.; Rubin, D.; Keil, U.D.; Franck, T. High speed silicon Mach-Zehnder modulator. Opt. Express 2005, 13, 3129–3135. [Google Scholar] [CrossRef] [Green Version]
- Su, T.; Zhang, M.; Chen, X.; Zhang, Z.; Liu, M.; Liu, L.; Huang, S. Improved 10-Gbps uplink transmission in WDM-PON with RSOA-based colorless ONUs and MZI-based equalizers. Opt. Laser Technol. 2013, 51, 90–97. [Google Scholar] [CrossRef]
- Song, J.-I.; Song, H.-J. Simultaneous frequency conversion technique utilizing an SOA-MZI for full-duplex WDM radio over fiber applications. IEICE Trans. Electron. 2007, E90C, 351–358. [Google Scholar] [CrossRef]
- Shokraneh, F.; Geoffroy-Gagnon, S.; Nezami, M.S.; Liboiron-Ladouceur, O. A single layer neural network implemented by a 4 × 4 MZI-based optical processor. IEEE Photonics J. 2019, 11, 1–12. [Google Scholar] [CrossRef]
- Reck, M.; Zeilinger, A.; Bernstein, H.J.; Bertani, P. Experimental realization of any discrete unitary operator. Phy. Rev. Lett. 1994, 73, 58–61. [Google Scholar] [CrossRef] [PubMed]
- Thomson, D.J.; Hu, Y.; Reed, G.T.; Fedeli, J.-M. Low Loss MMI Couplers for high performance MZI modulators. IEEE Photonics Technol. Lett. 2010, 22, 1485–1487. [Google Scholar] [CrossRef] [Green Version]
- Lawson, C.L.; Hanson, R.J. Solving Least Squares Problems; SIAM: Philadelphia, PA, USA, 1995. [Google Scholar]
- Shen, Y.; Harris, N.C.; Skirlo, S.; Prabhu, M.; Baehr-Jones, T.; Hochberg, M.; Sun, X.; Zhao, S.; Larochelle, H.; Englund, D.; et al. Deep learning with coherent nanophotonic circuits. Nat. Photonics 2017, 11, 441–446. [Google Scholar] [CrossRef]
- Clements, W.R.; Humphreys, P.C.; Metcalf, B.J.; Kolthammer, W.S.; Walmsley, I.A. Optimal design for universal multiport interferometers. Optica 2016, 3, 1460–1465. [Google Scholar] [CrossRef]
- Hughes, T.W.; Minkov, M.; Shi, Y.; Fan, S. Training of photonic neural networks through in situ backpropagation and gradient measurement. Optica 2018, 5, 864–871. [Google Scholar] [CrossRef]
- Zhou, H.; Zhao, Y.; Wei, Y.; Li, F.; Dong, J.; Zhang, X. All-in-one silicon photonic polarization processor. Nanophotonics 2019, 8, 2257–2267. [Google Scholar] [CrossRef]
- Zhou, H.; Zhao, Y.; Wei, V.; Li, F.; Dong, J.; Zhang, X. Multipurpose photonic polarization processor chip. In Proceedings of the 2019 Asia Communications and Photonics Conference, Chengdu, China, 2–5 November 2019; pp. 1–2. [Google Scholar]
- Zhou, H.; Zhao, Y.; Xu, G.; Wang, X.; Tan, Z.; Dong, J.; Zhang, X. Chip-scale optical matrix computation for pagerank algorithm. IEEE J. Sel. Top. Quantum Electron. 2020, 26, 1–10. [Google Scholar] [CrossRef]
- Zhou, H.; Zhao, Y.; Wang, X.; Gao, D.; Dong, J.; Zhang, X. Self-configuring and reconfigurable silicon photonic signal processor. ACS Photonics 2020, 7, 792–799. [Google Scholar] [CrossRef]
- Perez-Lopez, D.; Sanchez, E.; Capmany, J. Programmable true time delay lines using integrated waveguide meshes. J. Lightwave Technol. 2018, 36, 4591–4601. [Google Scholar] [CrossRef] [Green Version]
- Perez, D.; Gasulla, I.; Fraile, F.J.; Crudgington, L.; Thomson, D.J.; Khokhar, A.Z.; Li, K.; Cao, W.; Mashanovich, G.Z.; Capmany, J. Silicon photonics rectangular universal interferometer. Laser Photonics Rev. 2017, 11, 1700219. [Google Scholar] [CrossRef] [Green Version]
- Perez, D.; Gasulla, I.; Crudgington, L.; Thomson, D.J.; Khokhar, A.Z.; Li, K.; Cao, W.; Mashanovich, G.Z.; Capmany, J. Multipurpose silicon photonics signal processor core. Nat. Comm. 2017, 8, 636. [Google Scholar] [CrossRef] [Green Version]
- Perez, D.; Gasulla, I.; Capmany, J. Field-programmable photonic arrays. Opt. Express 2018, 26, 27265–27278. [Google Scholar] [CrossRef]
- Perez, D.; Gasulla, I.; Capmany, J. Programmable multifunctional integrated nanophotonics. Nanophotonics 2018, 7, 1351–1371. [Google Scholar] [CrossRef]
- Zhuang, L.; Roeloffzen, C.G.H.; Hoekman, M.; Boller, K.-J.; Lowery, A.J. Programmable photonic signal processor chip for radiofrequency applications. Optica 2015, 2, 854–859. [Google Scholar] [CrossRef] [Green Version]
- Midolo, L.; Schliesser, A.; Fiore, A. Nano-opto-electro-mechanical systems. Nat. Nanotechnol. 2018, 13, 11–18. [Google Scholar] [CrossRef] [Green Version]
- Akihama, Y.; Hane, K. Single and multiple optical switches that use freestanding silicon nanowire waveguide couplers. Light-Sci. Appl. 2012, 1, e16. [Google Scholar] [CrossRef] [Green Version]
- Takahashi, K.; Kanamori, Y.; Kokubun, Y.; Hane, K. A wavelength-selective add-drop switch using silicon microring resonator with a submicron-comb electrostatic actuator. Opt. Express 2008, 16, 14421–14428. [Google Scholar] [CrossRef] [PubMed]
- Poot, M.; Tang, H.X. Broadband nanoelectromechanical phase shifting of light on a chip. Appl. Phys. Lett. 2014, 104, 061101. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Zhang, M.; Stern, B.; Lipson, M.; Loncar, M. Nanophotonic lithium niobate electro-optic modulators. Opt. Express 2018, 26, 1547–1555. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mercante, A.J.; Yao, P.; Shi, S.; Schneider, G.; Murakowski, J.; Prather, D.W. 110 GHz CMOS compatible thin film LiNbO3 modulator on silicon. Opt. Express 2016, 24, 15590–15595. [Google Scholar] [CrossRef] [PubMed]
- He, M.; Xu, M.; Ren, Y.; Jian, J.; Ruan, Z.; Xu, Y.; Gao, S.; Sun, S.; Wen, X.; Zhou, L.; et al. High-performance hybrid silicon and lithium niobate Mach-Zehnder modulators for 100 Gbit s−1 and beyond. Nat. Photonics 2019, 13, 359–364. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Fowers, J.; Ovtcharov, K.; Papamichael, M.; Massengill, T.; Liu, M.; Lo, D.; Alkalay, S.; Haselman, M.; Adams, L.; Ghandi, M.; et al. A Configurable Cloud-Scale DNN Processor for Real-Time AI. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture, Los Angeles, CA, USA, 1–6 June 2018; pp. 1–14. [Google Scholar]
- Tait, A.N.; de Lima, T.F.; Nahmias, M.A.; Miller, H.B.; Peng, H.-T.; Shastri, B.J.; Prucnal, P.R. Silicon photonic modulator neuron. Phys. Rev. Applied 2019, 11, 064043. [Google Scholar] [CrossRef] [Green Version]
- Mahmoodi, M.R.; Strukov, D. An ultra-low energy internally analog, externally digital vector-matrix multiplier based on NOR flash memory technology. In Proceedings of the 55 the Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018; pp. 1–6. [Google Scholar]
- Wang, C.; Zhang, M.; Chen, X.; Bertrand, M.; Shams-Ansari, A.; Chandrasekhar, S.; Winzer, P.; Loncar, M. Integrated lithium niobate electro-optic modulators operating at CMOS-compatible voltages. Nature 2018, 562, 101–104. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Computing Density (TMACs/s/mm2) | Energy/MAC | Latency | Precision (bits) |
|---|---|---|---|---|
| MPLC with a reconfigurable diffractive processing unit [19] | - | 0.82 fJ/MAC | - | 8 |
| Broadcast-and-weight based on WDM [72] | 50 | 2.1 fJ/MAC | <100 ps | 5.1+ |
| Photonic WDM/PCM in-memory computing [40] (220 nm SOI platform) | 81 | 17 fJ/MAC | 250 ps | 5 |
| Optical convolutional accelerator based on WDM [41] | - | 1.58 pJ/MAC | - | 8 |
| Coherent MZI mesh [50] | 0.56 | 30 fJ/MAC | <100 ps | 5.1+ |
| Google TPU (digital) [70] | 0.58 | 0.43 pJ/MAC | 1.4 ns | 8 |
| Flash (analog) [73] | 18 | 7 fJ/MAC | 15 ns | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, J.; Zhou, H.; Dong, J. Photonic Matrix Computing: From Fundamentals to Applications. Nanomaterials 2021, 11, 1683. https://doi.org/10.3390/nano11071683
Cheng J, Zhou H, Dong J. Photonic Matrix Computing: From Fundamentals to Applications. Nanomaterials. 2021; 11(7):1683. https://doi.org/10.3390/nano11071683
Chicago/Turabian StyleCheng, Junwei, Hailong Zhou, and Jianji Dong. 2021. "Photonic Matrix Computing: From Fundamentals to Applications" Nanomaterials 11, no. 7: 1683. https://doi.org/10.3390/nano11071683
APA StyleCheng, J., Zhou, H., & Dong, J. (2021). Photonic Matrix Computing: From Fundamentals to Applications. Nanomaterials, 11(7), 1683. https://doi.org/10.3390/nano11071683